
Abstract
Digital images often undergo through various processing and distortions which subsequently impacts the perceived image quality. Predicting image quality can be a crucial step to tune certain parameters for designing more effective acquisition, transmission, and storage multimedia systems. With the huge number of images captured and exchanged everyday, automatic prediction of image quality that correlates well with human judgment is steadily gaining increased importance. In this paper, we investigate the performance of three combinations of objective metrics for image quality prediction with an adaptive neuro-fuzzy inference system (ANFIS). Images are processed to extract various attributes which are then used to build a predictive model to estimate a differential mean opinion score for different types of distortions. Using a publicly available and subjectively rated image database, the proposed method is evaluated and compared to individual metrics and an existing technique based on correlation and error measures. The results prove that the proposed method can be a promising approach for predicting subjective quality of images.
E.M. El-Alfy—On leave from the College of Engineering, Tanta University, Egypt.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Image quality assessment
- Adaptive neuro-fuzzy inference system
- ANFIS
- Differential mean opinion score
- Human visual system
- Subjective assessment
- Objective assessment
1 Introduction
Digital images are gaining great importance in the domain of electronic technology in recent years. However, images can be corrupted due to various reasons during acquisition, processing, storage and transmission. With the increasing use of digital imaging systems such as digital cameras, high definition cameras, monitors and printers, Image Quality Assessment (IQA) has attracted great attention in image processing applications [11]. Moreover, a variety of image processing techniques can benefit from image quality assessment for adaptive parameter tuning and prediction of required resources, e.g. [29].
Image quality assessment methods can be classified into two broad categories: subjective and objective. The subjective assessment is based on the human perception of image quality and it is preferred when human beings are the ultimate recipients of the image processing applications [27]. To reduce subjectivity, it is typically conducted through a number of human observers who are asked to visually judge the perceived quality of a target image in the presence (full-reference) or absence (no-reference) of its original image. This judgement can be in the form of a rank or score. The results of different observers are averaged and the resulting aggregated metric is called Mean Opinion Score (MOS). This score can be scaled to be in the range from 0 (very low quality) to 1 (very high quality). In the presence of a reference, another evaluation metric is known as DMOS which is the difference between the MOSs assigned to the reference and target images. If we assume the reference image has perfect quality, i.e. its MOS is 1, then the range for DMOS assigned to the target image will be from 0 (very high quality) to 1 (very low quality). Notice that it is the opposite of MOS.
The automation of subjective quality assessment is difficult as it depends on modelling the human visual system (HVS); which is a complex task especially when considering high-level cognitions. In contrast, objective quality assessments use numeric measures to quantify the degree of quality degradation and can benefit from the low-level models of certain features of HVS. Hence, it can be automated to replace the way a human assesses the quality of an image. The majority of objective quality assessment methods are based on pixel difference metrics due to their low computational complexity [2]. However, these methods can suffer from some limitations in dealing with the wide spectrum of image distortion types. Hence, a number of other quality metrics have been proposed in the literature for various situations by different researchers [7].
Whether subjective or objective, image quality assessment techniques can be also classified as no-reference, full-reference or reduced-reference. This classification depends on the availability of information from the original image besides the target or query image. In a no-reference technique, the assessor has only access to the query image; hence it is also termed as blind assessment, e.g. [5, 15]. But when the original image is available with the target image, it is termed as full-reference; e.g. [14]. In some applications, only partial information about the original image can made be available, e.g. due restricted bandwidth or storage space, besides the query image and hence it is termed reduced-reference [19].
This paper therefore investigates the ability of the adaptive neuro-fuzzy inference system (ANFIS) approach in predicting the subjective quality of images. It is implemented to estimate an aggregated score from a set of objective metrics for image quality assessment. We consider five types of distortion at different levels including JPEG compression, JPEG 2000 compression, additive pink Gaussian noise (APGN), additive white Gaussian noise (AWGN) and Gaussian blurring (Blur). To evaluate its performance, the predicted value is compared to the actual difference mean opinion score (DMOS). Four performance measures and subsequently computed, namely Pearson’s correlation coefficient, Spearman’s rank order correlation coefficient, mean absolute error (MAE), and root mean square error (RMSE). This work is a revised and extended version of our earlier work published at the international conference on agents and artificial intelligence [6].
The rest of the paper is structured as follows. Section 2 gives a brief background of the main ANFIS characteristics and how it can be used for function approximation and prediction. The related work is reviewed in Sect. 3. Section 4 provides more details on image quality assessment and defines the quality metrics that are used in this work. Section 5 describes the evaluation dataset and discusses the experimental work and results. Finally, Sect. 6 concludes the paper and highlights future work.
2 ANFIS Background
In the case of fuzzy logic based systems, the mapping of prior human knowledge or experience into the inference process using linguistic variables is an advantage but a cumbersome task. No standard procedure is found to provide an efficient way of this transformation. Usually, a trial and error approach determines the type, size and settings of the input and output membership functions (MFs). Effective tuning methods for the input and output membership functions and reduction of the rule base to the least necessary rules have always been on the list of significant issues to be explored.
Adaptive neuro-fuzzy inference system or ANFIS is emerged to mitigate the above mentioned issues by providing a learning capability to the fuzzy system through its integration with a neural network [8]. Thus, ANFIS combines the advantages of both the fuzzy inference system and the neural network. ANFIS has been widely used to solve several problems in different domains [1, 10, 17, 18].

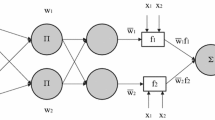
An illustrative example of ANFIS model architecture and reasoning.
Typically, the ANFIS system works in two distinct phases. The first phase is a neural-network phase, where a system classifies data and finds patterns. The other phase develops a fuzzy expert system through adaptive tuning of membership functions [10]. Figure 1 shows an illustrative example of a Sugeno-type ANFIS system, with two inputs X and Y, one output F, and two rules. Each input variable is assumed to have two linguistic terms (e.g. small and large). The computations are performed in five layers; where the output from each node in every layer is represented by \(O_i^l\), where l denotes the layer number and i denotes the specific neuron within that layer. The purpose of the first layer is to fuzzify the crisp input values using a set of linguistic terms (e.g., small, medium, and large). Membership functions of these linguistic terms determine the output of this layer as given by:
where \(\mu _{A_i}(x)\) and \(\mu _{B_i}(y)\) represent the membership functions that establish the degree to which the given input values x and y satisfy the quantifiers \(A_i\) and \(B_i\). A variety of membership functions exists such as bell-shaped, trapezoidal, triangular, Gaussian, and sigmoidal. The firing strength for each rule quantifies the extent that any input data belongs to that rule, and is computed in the second layer as the multiplication of all the incoming signals at each node as follows:
The nodes in the third layer perform normalization operation by calculating the ratio of the i-th rule’s firing strength to the sum of all rules’ firing strengths as follows:
In Sugeno-type ANFIS system, the consequent part of each rule is expressed as a linear combination of the inputs. The fourth layer has square-shaped nodes with node functions given as:
Finally, the last layer node conducts summation of all incoming signals to generate the output as a weighted sum of all node inputs:
The objective of a learning algorithm is to update the consequent and premise parameters in order to achieve the least error between the predicted and the desired target output. A hybrid training algorithm is normally applied to tune the parameters of an ANFIS network. Such a learning technique is composed of least square estimates and a gradient descend (back-propagation) algorithm. The first stage updates the consequent parameters through least-square estimates by passing signals forward until layer 4. In the second stage, the error rates are propagated backward which helps in updating the premise parameters by a gradient descent algorithm.
3 Related Work
In the past, various methods and metrics have been proposed in the literature for assessing the image quality in agreement with human judgments; whether full reference, restricted reference, or no-reference. In this section, we briefly review relevant recent work for mainly full-reference image quality assessment. An extensive comparison of several full-reference single-metric algorithms is presented in [22] using a single database with a total of 779 distorted images judged by more than 24 human observers. The highest correlation with average human judgments was approximately 0.95. A more recent and comprehensive performance comparison is provided in [13] for 18 full-reference quality metrics over six benchmark databases and four types of distortions (JPEG compression, JPEG 2000 compression, additive Gaussian noise, and Gaussian blurring). The results showed that the performance varied widely after nonlinear regression with superior capability for the visual information fidelity (VIF) metric in terms of its correlation to the subjective human ratings.
In [2], the authors proposed a neural network approach for the assessment of image quality. The neural network measured the quality of an image by predicting the mean opinion score (MOS) with the help of six key features extracted from both the reference and target images. These features are the two means, two standard deviations, covariance and mean-square error. The experimental work was carried out using 352 images compressed by JPEG/JPEG2000. The resulting correlation is about 0.9744 between the predicted and actual MOS values. Similar work has been conducted in [9] where a neural network approach is used to predict the subjective image quality score DMOS using statistical features extracted from both the reference and target images. In 2011, Li et al. developed a no-reference image quality assessment using regression neural networks to approximate the functional relationship between a range of distortion types and the human subjective judgment [15].
In [27], the authors developed an image quality assessment method based on structural distortion and image definition. They carried out their experiments on Lena and Barbara original and distorted images. In their work, it was shown that the proposed method is more consistent with human perception. In [12], the authors used characteristics of structural similarity index and artificial neural network for image quality assessment. The experimental results showed that their proposed approach can achieve adaptability for image quality of different types. In [16], the authors conducted a survey on perceptual visual quality metrics, in which they compared 6 image metrics using seven public image databases. In [26], a new full-reference quality assessment metric is proposed to automate the quality assessment of an image in the discrete orthogonal moment domain. This metric was constructed by using image spatial information in terms of low-order moments.
Concerning the recent use of ANFIS approach in the literature, in [1] the authors worked on classifying greenery and non-greenery image classification using an ANFIS technique. They used a hybrid set of parameters which involved texture and color coherence vector (CCV). More recently in [17], ANFIS was used for classification and detection purposes for the brain Magnetic Resonance (MR) images and tumor detection. The decision making was performed in two stages. The first stage involved using feature extraction using principal component analysis (PCA) and in the second stage, ANFIS was trained. The authors mentioned that ANFIS, as a fuzzy logic based paradigm, grasps the learning abilities of neural network to improve the performance of the intelligent system using a priori knowledge. The authors demonstrated that ANFIS can be a promising approach for image classification in the field of medical sciences. In [5], ANFIS is used to assess quality of distorted/decompressed images without reference to the original image using three statistical features as inputs expressed as linguistic variables, namely area, extent and eccentricity.
4 Proposed Approach for Quality Assessment
In this paper, we have developed a full-reference image quality assessment model. The outline of the proposed predictive model is shown in Fig. 2. As a full-reference method, the quality of a query image is compared with a reference image of perfect quality. Image quality is determined through various image quality metrics computed based on features extracted from both the reference and the target images. These features are based on existing studies, e.g. [3, 16]. Here, we considered only seven significant full-reference objective quality metrics as follows:
-
Peak Signal-to-Noise Ratio (PSNR)
-
Universal Quality Index (UQI)
-
Mean Structural Similarity Index (MSSIM)
-
Weighted Signal to Noise Ratio (WSNR)
-
Visual Information Fidelity (VIF)
-
Noise Quality Measure (NQM)
-
Information Fidelity Criterion(IFC)
These quality metrics are discussed briefly in the following subsections.

Outline of the proposed ANFIS-based quality assessment system.
4.1 Peak Signal-to-Noise Ratio (PSNR)
The traditional and most widely-used objective image quality metric for many years is the peak signal to noise ratio (PSNR). PSNR is a pixel-based method, which means that the distorted image is compared to the reference image pixel by pixel. Perhaps, it wide spread use can be attributed to its simplicity and power to assess white noise distortion. However, it has been lately demonstrated that it can be inconsistent to human subjective perception [23]. Moreover, it may not capture the wide spectrum of distortion types.
The peak-signal-to-noise ratio is computed by utilizing the mean square error (MSE) between the reference image and the target image. For a reference image A and a target image B each of size \(N \times M\), the mean square error is computed by averaging the squared intensity differences of the pixels of the two images as follows:
where \(a_{ij}\) and \(b_{ij}\) are the intensities of the pixels at location (i, j) in the reference and target images, respectively. If we assume 8-bit encoding for each pixel, i.e. intensity values represent gray levels in the range from 0 to 255. The maximum gray level of 255 is then used as a scaling factor in computing the PSNR which is defined as:
4.2 Universal Quality Index (UQI)
This metric was suggested by Wang et al. [24, 25] by utilizing first and second order statistics of both the reference and the target images. It is based on luminance, contrast, and structural comparisons of both images. The luminance comparison l(a, b) between a reference image A and a target image B is determined in terms of mean values \(\mu _a\) and \(\mu _b\) by the relation:
The contrast comparison c(a, b) is performed utilizing the standard deviations for images A and B as:
Utilizing covariance between the images A and B, the structural comparison s(a, b) is given by:
Subsequently, the universal quality index is defined as:
where the value of \(UQI \in [-1, 1]\). It serves as an improved metric when compared to the PSNR. However, when the denominator is too small, UQI can become unstable and badly correlate with the subjective evaluations.
4.3 Mean Structural Similarity Index (MSSIM)
An improved metric was later proposed known as structural similarity index (SSIM) [25], which is computed in a similar way but adding some constants to overcome the instability of UQI as follows:
where \(C_1=(K_1 L)^2\), \(C_2=(K_2 L)^2\), L denotes the dynamic range of pixel values (255 in our case), and \(K_1\) and \(K_2\) are small positive constants. The SSIM index is calculated for the whole image as one block and its value is scaled to the range [0, 1]. When features are highly spatially non-stationary, SSIM can be calculated within local windows and the overall image quality is measured by the mean SSIM index as given by:
where K is the total number of local SSIM indices.
4.4 Weighted Signal-to-Noise Ratio (WSNR)
In [4], a different approach to signal-to-noise ratio was used. It is known as weighted signal-to-noise ratio (WSNR). This measure is defined as the ratio of average weighted signal power to the average weighted noise power. Here, the contrast sensitivity functions (CSF) are used as weights.
4.5 Visual Information Fidelity (VIF)
VIF metric was proposed in [20]. In this metric the image quality assessment depends upon the amount of information shared between the source (reference) image and the distorted image. A fundamental limit is imposed on how much information can flow from the source image through the channel (i.e., the image distortion process) to the receiver (i.e., human being). VIF is distinctive over traditional image quality assessment methods.
4.6 Noise Quality Measure (NQM)
NQM metric [4] was proposed as a better measure for visual quality than PSNR. It considers variation in contrast sensitivity with distance, image dimensions and spatial frequency. It also considers the variation in local luminance, mean and contrast interaction between spatial frequencies, and masking effects. NQM is given by:
where \(a_{ij}\) and \(b_{ij}\) denote the (i, j) pixels in the reference and distorted images.
4.7 Information Fidelity Criterion(IFC)
IFC image quality assessment was proposed by [21]. This metric is based on natural scene statistics. The IFC is the mutual information between the source and distorted images. Firstly, the mutual information is derived for one sub-band and then generalized for multiple sub-bands. The IFC quantifies the perceptual quality of the image.
5 Evaluation
The images used in our study are collected from the a recent database released from the Oklahoma State University, Computational Perception and Image Quality Lab. This database is known as Categorical Subjective Image Quality (CSIQ) database [14]. This image database is chosen for our experiments because it has a relatively large number of images distorted with a variety of types. In addition, it was previously used in several image quality assessments in the literature, e.g. [14, 28, 29].
The adopted dataset has 30 original images and 750 distorted versions of the original images. We chose 5 types of distortions each is taken at five levels (This means there is a total of \(5 \times 30 = 150\) images for each distortion type). The considered distortions are JPEG compression, JPEG 2000 compression, additive pink Gaussian noise (APGN), additive white Gaussian noise (AWGN) and Gaussian blurring. Each image in the database is of \(512 \times 512\) RGB pixels and each color has 256 levels (from 0 to 255); a total of 24 bits per pixel. Examples of the images in this database are shown in Fig. 3.

Examples of the images in CSIQ database for two types of distortions JPEG 2000 and Gaussian Blur.
Each distorted image in the database has a subjective rating in the form of DMOS (Difference Mean Opinion Score) ranging from 0 (no distortion or lightly distorted) to 1 (highly distorted). Ratings are conducted by 35 male and female observers with ages from 21 to 35 years. The actual DMOS score for each image pair is also taken from the Oklahoma State University CSIQ image database website. Figure 4 shows distorted images with top ten and bottom ten DMOS ratings including distortion name and index, image name, distortion level, standard deviation of DMOS, and DMOS. It is clear that rating is high when the level of distortion is high and vice versa.
We paired each distorted image with the corresponding original image as a reference. This gave us 750 pairs. Out of the 750 image pairs, we used 600 pairs for training the model, 50 pairs for validating the model and 100 pairs for testing the model. Using MATLAB, we computed the seven image quality measures under consideration (see Sect. 4) using the code developed by their inventors.
We then built different ANFIS models using subsets of these measures and evaluated their performances. The desired output of the ANFIS network was the crisp DMOS values. The first ANFIS model has only three inputs (PSNR, UQI and MSSIM) whereas the second ANFIS model has five inputs (PSNR, UQI, MSSIM, WSNR and VIF). The last ANFIS model has seven inputs (PSNR, UQI, MSSIM, WSNR, VIF, NQM, and IFC). Table 1 shows the ANFIS parameters and their values used for training with 7 input variables. Figure 5 shows a snapshot of the corresponding ANFIS model for the 7 input variables. The other two models use similar parameter types but the values for input and output MFs differs accordingly.
For the purpose of evaluating the performance of each model, we used four measures. The Pearson’s linear correlation coefficient \(\rho \) is given by:
where \(DMOS_i^a\) and \(DMOS_i^p\) are the actual and predicted values for DMOS for the i-th image.
where \(DMOS^a\) and \(DMOS^p\) are vectors containing the actual and predicted values for DMOS. To assess the monotonicity relationship between predicted value and actual value for a particular model, we used Spearman’s rank order coefficient \(\rho _s\). This measure is computed suing the same equation for Pearson’s coefficient but replacing the raw scores by their ranks. In order to find the error of the model, we used Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) which as calculated as follows:

Distorted images with top ten and bottom ten DMOS ratings.

ANFIS model with 7 inputs.

Average Pearson’s and Spearman’s correlation results for JPEG/JPEG 2000 distortion types for the proposed ANFIS-based with 7 inputs as compared to neural network (NN) and MSSIM, as reported in [2].
We started with the three features metrics PSNR, UQI and MSSIM, selected arbitrarily as inputs to the ANFIS network. The results of our experiment are given in Table 2. In order to study the performance as more features become available, we added two more feature metrics, i.e. WSNR and VIF, and repeated the experiment with a 5-input ANFIS network. The corresponding results are shown in Table 3. We again added two more feature metrics, i.e. NQM and IFC, and repeated the experiment with a 7-input ANFIS network and the yielded results are shown in Table 4. The rationale behind repeating the experiments was to judge the performance of the ANFIS network by increasing the feature metrics incrementally and document the results.
Considering the results in Tables 1, 2 and 3, we can see that the predicted DMOS values are highly correlated with the actual DMOS values for all distortion types except APGN. The correlation improves as more inputs become available. Similar conclusions can be made regarding MAE and RMSE.
For the sake of comparison, Fig. 6 shows the average values for the correlation of two types of distortion JPEG/JPEG 2000 for our method and two other methods from the literature: neural network [2] and MSSIM [25]; as reported in [2]. We should mention that the authors for the other works used a different image database and provided the results for only these two types of distortions. For a more relevant comparison on the same dataset (CSIQ), Figure 7 compares the Spearman’s correlation resulting from the proposed approach to that individual metrics on the four types of distortions reported in [13]. This figures demonstrates that the proposed approach has consistently higher correlation.

Comparing the Spearman’s correlation results for four distortion types on the same dataset (CSIQ) of individual metrics, as reported in [13] and the proposed ANFIS-Based model with 7 inputs.
6 Conclusion
In this paper, we explored the application of an adaptive neuro-fuzzy inference system (ANFIS) for subjective quality prediction by fusing a number of objective metrics. The experimental results showed that ANFIS network can be trained using image quality assessment metrics to predict the differential mean opinion score (DMOS) with high correlation coefficients and low errors. The ANFIS results compare favourably with two other methods in the literature. As a future work, the proposed method can be intensively tested on other databases and compared to other metrics. More quality assessment metrics can be considered as inputs to the predictive model and in this case the selection of the most relevant features for building the predictive models will be of interest.
References
Balamurugan, P., Rajesh, R.: Greenery image and non-greenery image classification using adaptive neuro-fuzzy inference system. In: International Conference on Computational Intelligence and Multimedia Applications, 2007, vol. 3, pp. 431–435 (2007)
Bouzerdoum, A., Havstad, A., Beghdadi, A.: Image quality assessment using a neural network approach. In: Proceedings of the Fourth IEEE International Symposium on Signal Processing and Information Technology, pp. 330–333 (2004)
Chetouani, A., Beghdadi, A., Deriche, M.: Image distortion analysis and classification scheme using a neural approach. In: 2nd European Workshop on Visual Information Processing (EUVIP) 2010, pp. 183–186 (2010)
Damera-Venkata, N., Kite, T.D., Geisler, W.S., Evans, B.L., Bovik, A.C.: Image quality assessment based on a degradation model. IEEE Trans, Image Process. 9(4), 636–650 (2000)
De, I., Sil, J.: No-reference quality prediction of distorted/decompressed images using ANFIS. In: International Conference on Computer Technology and Development, ICCTD 2009, vol. 2, pp. 90–94 (2009)
El-Alfy, E.S., Riaz, M.: Image quality assessment using ANFIS approach. In: Proceedings of the 6th International Conference on Agents and Artificial Intelligence (ICAART), vol. 1, pp. 169–177 (2014)
He, L., Gao, F., Hou, W., Hao, L.: Objective image quality assessment: a survey. Int. J. Comput. Math. 91(11), 1–15 (2013)
Jang, J.S.: ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 23(3), 665–685 (1993)
Kaya, S., Milanova, M., Talburt, J., Tsou, B., Altynova, M.: Subjective image quality prediction based on neural network. In: Proceedings of the 16th International Conference on Information Quality (2011)
Khuntia, S.R., Panda, S.: ANFIS approach for SSSC controller design for the improvement of transient stability performance. Math. Comput. Model. 57(12), 289–300 (2013)
Kudelka Jr, M.: Image quality assessment. In: Proceedings of Contributed Papers, WDS 2012 Part I. pp. 94–99 (2012)
Kung, C.H., Yang, W.S., Huang, C.Y., Kung, C.M.: Investigation of the image quality assessment using neural networks and structure similarity. In: Proceedings of the 3rd International Symposium Computer Science and Computational Technology (2010)
Lahoulou, A., Bouridane, A., Viennet, E., Haddadi, M.: Full-reference image quality metrics performance evaluation over image quality databases. Arab. J. Sci. Eng. 38(9), 2327–2356 (2013)
Larson, E.C., Chandler, D.M.: Most apparent distortion: full-reference image quality assessment and the role of strategy. J. Electron. Imaging 19(1), 011006–011006 (2010)
Li, C., Bovik, A.C., Wu, X.: Blind image quality assessment using a general regression neural network. IEEE Trans. Neural Networks 22(5), 793–799 (2011)
Lin, W.: Jay Kuo, C.C.: Perceptual visual quality metrics: a survey. J. Vis. Commun. Image Represent. 22(4), 297–312 (2011)
Sri Meena, R., Revathi, P., Reshma Begum, H.M., Singh, A.B.: Performance analysis of neural network and ANFIS in brain MR image classification. In: Patnaik, S., Yang, Y.-M. (eds.) Soft Computing Techniques in Vision Sci. SCI, vol. 395, pp. 101–113. Springer, Heidelberg (2012)
Meharrar, A., Tioursi, M., Hatti, M., Stambouli, A.B.: A variable speed wind generator maximum power tracking based on adaptive neuro-fuzzy inference system. Expert Syst. Appl. 38(6), 7659–7664 (2011)
Rehman, A., Wang, Z.: Reduced-reference image quality assessment by structural similarity estimation. IEEE Trans. Image Process. 21(8), 3378–3389 (2012)
Sheikh, H.R., Bovik, A.C.: Image information and visual quality. IEEE Trans. Image Process. 15(2), 430–444 (2006)
Sheikh, H.R., Bovik, A.C., De Veciana, G.: An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Trans. Image Process. 14(12), 2117–2128 (2005)
Sheikh, H.R., Sabir, M.F., Bovik, A.C.: A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 15(11), 3440–3451 (2006)
Wang, Z., Bovik, A.: Mean squared error: love it or leave it? a new look at signal fidelity measures. IEEE Signal Process. Mag. 26(1), 98–117 (2009)
Wang, Z., Bovik, A.C.: A universal image quality index. IEEE Signal Process. Lett. 9(3), 81–84 (2002)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Wee, C.Y., Paramesran, R., Mukundan, R., Jiang, X.: Image quality assessment by discrete orthogonal moments. Pattern Recogn. 43(12), 4055–4068 (2010)
Yi, Y., Yu, X., Wang, L., Yang, Z.: Image quality assessment based on structural distortion and image definition. In: Proceedings of the International Conference on Computer Science and Software Engineering, 6, 253–256 (2008)
Zhang, F., Ma, L., Li, S., Ngan, K.N.: Practical image quality metric applied to image coding. IEEE Trans. Multimedia 13(4), 615–624 (2011)
Zhu, X., Milanfar, P.: Automatic parameter selection for denoising algorithms using a no-reference measure of image content. IEEE Trans. Image Process. 19(12), 3116–3132 (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
El-Alfy, ES.M., Riaz, M.R. (2015). Full-Reference Predictive Modeling of Subjective Image Quality Assessment with ANFIS. In: Duval, B., van den Herik, J., Loiseau, S., Filipe, J. (eds) Agents and Artificial Intelligence. ICAART 2014. Lecture Notes in Computer Science(), vol 8946. Springer, Cham. https://doi.org/10.1007/978-3-319-25210-0_18
Download citation
DOI: https://doi.org/10.1007/978-3-319-25210-0_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-25209-4
Online ISBN: 978-3-319-25210-0
eBook Packages: Computer ScienceComputer Science (R0)