
Abstract
In an urban city, its transportation network supports efficient flow of people between different parts of the city. Failures in the network can cause major disruptions to commuter and business activities which can result in both significant economic and time losses. In this paper, we investigate the use of centrality measures to determine critical nodes in a transportation network so as to improve the design of the network as well as to devise plans for coping with the network failures. Most centrality measures in social network analysis research unfortunately consider only topological structure of the network and are oblivious of transportation factors. This paper proposes new centrality measures that incorporate travel time delay and commuter flow volume. We apply the proposed measures on the Singapore’s subway network involving 89 stations and about 2 million commuter trips per day, and compare them with traditional topology based centrality measures. Several interesting insights about the network are derived from the new measures. We further develop a visual analytics tool to explore the different centrality measures and their changes over time.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Network centrality
- Commuter flow centrality
- Delay flow centrality
- Visual analytics
- Transportation network
1 Introduction
Motivation Transportation network is an important part of a complex urban city system. Each transportation network is expected to support efficient flow of people between different parts of the city. Failures in the network can cause major disruptions to commuter and business activities which result in both significant economic and time losses. As the transportation network continues to grow and interact with other parts of urban city, it is imperative to study how the network can cope with increase in human flow, new network nodes and connections, as well as new city developments.
One way to study the transportation network is to identify the centralities in the network which represent the more critical nodes whose degrees of reliability have major impact to the network efficiency. Network centrality is a concept introduced in social science to analyze important nodes in social networks [8, 13]. The key examples of network centrality measures include degree centrality, closeness centrality, betweenness centrality [7], and pagerank [3]. In a recent study by Derrible [5] on metro networks represented by transfer stations, terminal stations and their connections only, it was shown that betweenness is more evenly distributed among stations when the metro network is large. This hopefully will allow the stations to share commuter load more equally.
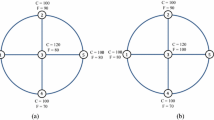
All the above traditional network centrality measures nevertheless consider network topology only but not factors associated with transportation. A node identified to be important topologically does not need to be important from the commuter flow and delay perspective. Consider the network example in Fig. 1, node A has the highest degree, closeness and betweenness values by topology. If we know that the commuter flow between B and D far exceeds those of other connections, B and D should be deemed to be more central than the other nodes. If we further know that many commuters will take much longer travel time should B fails, one may even consider B to be more central than D.

Example network
Research Objectives and Contributions In this paper, we therefore aim to devise new centrality measures that incorporate commuter flow and travel time delay, the two transportation related factors. The objective of our research is to determine critical nodes in a transportation network so as to improve the design of the network as well as to devise plans for coping with the network failures. Unlike network topology, commuter flow and travel time delay may change dynamically with time, allowing us to study the evolving node importance. This time-dependent approach to measure node importance permits us to study a transportation network system in a much finer time granularity. As a result, the insights gained can also be readily associated with time in addition to topology.
In the following, we summarize the contributions of this paper:
-
We propose Commuter Flow, Time Delay and DelayFlow centrality measures that incorporate commuter flow and travel time delay unique to transportation networks . To compute these measures, we develop methods to compute commuter flow and travel time delay from a network with trip transaction data and a public web service that offers travel time information respectively.
-
We apply the proposed measures on the Singapore’s subway network involving 89 stations and more than 2 million commuter trips per day, and compare them with traditional centrality measures. Both time-independent and time-dependent analyses of the various centrality measures are conducted.
-
We derived several interesting insights about the network using the new measures. Our experiments show our proposed centrality measures are different from the traditional centrality measures. The commuter flow and DelayFlow centrality values of stations can vary a lot throughout a day. They can also be very different between weekdays and weekends. This also justifies the usefulness of the new measures.
-
Finally, we have developed a visual analytics tool to evaluate the newly proposed centrality measures and other traditional ones. The tool allows users to select centrality measure, time of the day and other factors to be analyzed easily. The visual presentation gives users a very friendly and quick way to examine and compare the different centrality measures.
Paper Outline The rest of the paper is organized as follows. Section 2 describes several works related to our study. Section 3 introduces our proposed centrality measures. We describe the Singapore subway network dataset in Sect. 4. Our experiments on the various measure are covered in Sect. 5. We present our visual analytics tool in Sect. 6 before concluding the paper in Sect. 7.
2 Related Work
Transportation network analysis has been an active area of research. De Montis et al. [4], conducted an analysis of an interurban transportation network involving 375 municipalities and 1.6 million commuters. In their work, a weighted network is used to model the traffic flow between municipalities and several properties, e.g., weighted degree distribution, cluster coefficients, heterogeneity of commuter flows, etc., about the network are derived. Berche et al. also studied the resilience of transportation networks due to attacks on nodes [1]. In the context of air transportation, Guimera et al., found the worldwide air transportation network demonstrating scale-free small world properties [11]. This finding is interesting as this illustrates that transportation networks may evolve in an organic way similar to social networks [12].
For the purpose of city planning and building design, Sevtsuk and Mekonnen proposed a set of network centrality measures including Reach, Gravity Index, and Straightness in addition to the traditional ones to determine how easy one can reach other locations in a city from a given location [15]. In this paper, we however focus on centrality measures relevant to transportation networks where time delay and commuter flow are the major factors.
There are very few works on applying network centrality measures to analyze transportation networks. Derrible studied the betweenness centrality in several subway networks of different countries [5]. His work however focuses on transfer and interchange stations and does not introduce new centrality measures considering transportation related factors. Our work is quite similar to that of Scheurer et al. [14], who also proposed a set of centrality measures for transportation networks. Unlike ours, their measures do not consider commuter flow and travel time of alternative means between stations.
In the literature, there is a large body of works on the robustness of networks which include transportation networks [2]. Goh et al. [10], found out that the betweenness centrality of scale-free networks follows power law distribution with an exponent that determines the robustness of the network. Gao et al. [9], proposed to use graph energy to measure robustness of very large networks in an efficient way. These works however do not use network centrality to identify important stations when failures occur.
3 Centrality Measures
In this section, we first provide the definitions of the traditional network centrality measures. This is followed by our proposed centrality measures which take two factors into consideration: (i) commuter flow of the node, and (ii) the amount of time delayed that will incur due to failure of the node.
3.1 Overview of Network Centrality
We model a transportation network as an undirected graph \(\langle V, E \rangle \) with node set V representing stations and edge set E representing the connections between stations. Every node \(i \in V\) is associated with two numbers, in(i) and out(i), that refers to the number of commuters entering and exiting the station of node i respectively. Given that the total numbers of commuters entering and exiting the stations of the network are the same, the equality \(\sum _{i \in V} in(i) = \sum _{i \in V} out(i)\) holds.
We now review the definitions of some existing network centrality measures used in social network analysis.
Degree Centrality The degree centrality of a node i, \(C_{deg}(i)\), is defined as:
Closeness Centrality We denote the shortest path distance between two nodes i and j by d(i, j). The closeness centrality of a node i, \(C_{cls}(i)\), is defined as:
where \(d(i)=\sum _{j \in V, j \ne i}d(i,j)\).
Betweenness Centrality Let \(g_{jk}\) denote the number of shortest paths between nodes j and k, \(g_{jk}(i)\) denote the number of shortest paths between nodes j and k through node i. The betweenness centrality of a node i, \(C_{btw}(i)\), is defined as:
3.2 DelayFlow Centrality
Commuter Flow Centrality The commuter flow centrality of a node i, \(C_{f}(i)\), is defined as the number of commuters affected per hour when node i is down. We classify the affected commuters into three categories:
-
Commuters traveling from node i to other nodes;
-
Commuters traveling from other nodes to node i; and
-
Commuters traveling through node i.
Hence, we define the commuter flow centrality of a node i to be:
where \(h_{ij}\) denotes the number of commuters from node i to node j per hour, and \(h_{jk}(i)\) denotes the number of commuters from node j to node k through node i per hour. In Sect. 4, we will describe how the two sets of commuter flow data can be derived from trip transactions.
Time Delay Centrality Time delay is incurred for commuters to find alternative means to reach destinations when a node is down. To determine the extent of delay caused to the people affected, we consider the following:
-
\(t_{exp}(i,j)\): The expected time taken to travel from node i to node j;
-
\(t_{alt}(i,j)\): The time taken to travel from node i to node j using an alternative means of transportation (e.g. bus) which varies by the hour.
Assuming that commuters do not receive advance notice about node failures in the transportation, they have to find alternative routes from the failed node to their final destinations, or from the origins to the failed nodes. Let n be the number of nodes in the network. The time delay centrality for a node i \(C_{del}(i)\) is thus defined as:
where
In the above definition, we assume that \(t_{exp}\) is static and \(t_{alt}\) varies throughout the day. The time delay factor \(l_{ij}\) is asymmetric as both \(t_{exp}(i,j)\) and \(t_{alt}(i,j)\) are asymmetric. When the time delay factor \(l_{ij}\) equals to 1, it signifies no delay. When \(l_{ij}\) is greater than 1, commuters will take a longer than expected time to reach their desired destinations. The larger the \(l_{ij}\) value (\(>\)1), the greater the time delay. \(l_{ij}<1\) means an improvement of the alternative means of transportation, which is an unlikely scenario when disruptions occur to the network.
Notice that time delay centrality \(C_{del}(i)\) does not take commuter flow into consideration in determining time delay. For example, a commuter may incur a long travel time from node i to node j when using an alternative means of transport over the network (i.e., \(l_{ij}\) is large), but only a small number of commuters are actually affected by it. Thus, there is a need to combine time delay factor with the underlying commuter flow volume. We therefore propose the DelayFlow centrality by summing the product of commuter flow and average time delay factor of all paths traveling to, from and through a node.
DelayFlow Centrality The DelayFlow centrality of node i, \(C_{\textit{dflow}}(i)\), is defined as:
where \(\sum _{j \in V} in(j)\) is the total commuter flow of the transportation network . \(l_{ij}\) and \(l_{ji}\) have been earlier defined and
4 Datasets
The Singapore’s mass rapid train (MRT) network consists of 89 stations in four train lines. Figure 2 depicts these train lines (in different colors) and stations. The node color represents the different train lines: red for North-South line (NSL), green for East-West line (EWL), purple for North-East line (NEL), orange for Circle line (CL), and blue for the interchange stations. We use two datasets about MRT network. The first dataset MRTDB consists of nearly 2 millions commuter trip transactions per day. In our experiment, we used three days worth of trip transaction data from November 26 (Saturday) to November 28, 2011 (Monday) to derive the commuter flow information. The second dataset GoThereDB provides data about the travel time information.

Singapore MRT Network
MRTDB Dataset Each trip transaction consists of the origin station, destination station and the timestamps at the two stations. We use the trip transactions to derive commuter flow \(h_{ij}\)’s. We compute the overall \(h_{ij}\) by dividing the total number of trips between stations i and j (not necessarily the origin and destination stations) by the number of MRT operating hours, i.e., 19 h (from 0500 to 0000 h). In a similar way, we compute \(h_{jk}(i)\) from trips between j and k through i.
To study commuter flow centrality and DelayFlow centrality at different time of the day, we divide the trip transactions into 19, one-hour long disjoint segments from 0500 to 0000 h. A trip is assigned to a time segment if its origin station’s timestamp falls within the time segment. We can then compute the time specific commuter flow numbers \(h_{ij}\)’s and \(h_{jk}(i)\)’s for each time segment.
To determine the path a commuter takes to travel from one station to another for determining \(h_{ij}\)’s and \(h_{jk}(i)\)’s, we first assume that all commuters with the same origin and destination stations take the same path and the path should be the shortest among all other path options. We use Dijkstra’s algorithm to compute these shortest paths [6]. To represent delays at interchange stations, create k separate proxy stations for an interchange station for k train lines and \(\left( {\begin{array}{c}k\\ 2\end{array}}\right) \) edges to connect these pairs of proxy stations. Each edge is assigned a 2 min transfer time at the interchange station.
Figures 3 and 4 show the number of commuters at different 1 h time segments on a weekday and weekend day respectively. They show that the number of commuters peaks on both the morning and evening rush hours on weekdays, but peaks only in the evening on a weekend. The weekday trend indicates that many commuters use MRT trains to get to their work places in the morning, and return home from work in the evening. At the peaks, we have more than two millions commuters using the train network, representing about \(\frac{2}{3}\) of the Singapore’s population. On weekends, commuters clearly show a late start of their travel which peaks at around 5pm. For the rest of this paper, we shall just focus on the weekday data.
GoThereDB Dataset To determine the expected travel time and travel time using alternative routes, we made use of a third-party route suggestion service known as “gothere.sg”.Footnote 1 The gothere.sg API’s allow us to determine the travel time by MRT train (expected) or bus (alternative) for each origin and destination station pair. Bus is chosen as it is the next most commonly used mode of public transportation. Given that we have altogether 89 stations in the MRT network, we use the APIs to derive \(t_{exp}(i,j)\) and \(t_{alt}(i,j)\) time for all \(89 \cdot 88=7832\) station pairs. To keep things simple, we assume that \(t_{exp}(i,j)\)’s and \(t_{alt}(i,j)\)’s are independent of the time of the day.

Commuter flow (weekday)

Commuter flow (weekend)
5 Comparison of Centrality Measures
Distribution of Degree , Closeness and Betweenness Centralities Figures 5, 6 and 7 show the distribution of the degree, closeness and betweenness centrality values of the stations in MRT network. As shown in Fig. 5, most nodes have degree = 2 or 1 as they are non-interchange stations. There are only 10 interchange stations with degrees ranging from 3 to 5. The closeness centrality values, as shown in Fig. 6, concentrate within the small range between 0.06 and 0.14. This suggests that the shortest paths between stations have relatively short length. Figure 7 shows the betweenness centrality is well spreaded between 0 to 1300. Only very few stations have betweenness greater than 1000 serving in the middle of many shortest paths between other stations.

Degree centrality \(C_{deg}\) distribution

Closeness centrality \(C_{cls}\) distribution

Betweenness centrality \(C_{btw}\) distribution
Distribution of Commuter Flow Centrality Figure 8 shows the commuter flow centrality distribution on a weekday. The centrality values can be as large as 29,362. Most stations (90 %) have relatively small commuter flow centrality values with values in [0,20000). Only 9 stations (10 %) have larger commuter flow centrality values with values in [20000,30000). Not surprisingly, these are mainly the interchange stations with high volume of commuters. The only exceptions are two stations which are located in densely populated township and highly popular shopping area.
Figure 9 shows the commuter flow centrality distribution at different time durations of a weekday as the centrality. The figure shows that there are more stations having higher commuter flow centrality values in the [0800,0900) and [1800,1900) time segments due to larger concentration of commuters using these stations during that time. Otherwise, most stations have commuter flow centrality values in the [0,20000) range, consistent with what we observed in Fig. 8.

Commuter flow centrality \(C_{f}\) distribution (weekday)

Commuter flow centrality distribution at selected time segments (weekday)
Distribution of Time Delay Centrality Figure 10 depicts the time delay centrality distribution at different time durations of a weekday as the centrality. The centrality ranges between 1.5 and 3.4 showing that the alternative means of transportation can take between 50 to 240 % more than the expected time required. This result shows that the alternative means of transportation for the stations with high time delay centrality can be further improved. The average time delay centrality is 2.395.

Time delay centrality \(C_{del}\) distributions at selected time segments (weekday)
Distribution of DelayFlow Centrality Figure 11 depicts the distribution of DelayFlow centrality on a weekday. There are a cluster of stations with small DelayFlow centrality values between 0.0 and 0.1. Another major cluster of stations have DelayFlow centrality values between 0.2 and 0.4. There are very few stations with high centrality values. Figure 12 shows the distribution of DelayFlow centrality at different selected time segments of a weekday. We observe that the two peaks of the overall centrality distribution are contributed largely by more busy stations during the busy morning and evening hours (i.e., [0600,0700), [0900,1000), [1800,1900), and [2100,2200) h). During the non-peak hours, there are more stations with smaller DelayFlow centrality values making the two peaks less obvious.

DelayFlow centrality \(C_{\textit{dflow}}\) distribution (weekday)

DelayFlow centrality distributions at selected time segments (weekday)
Correlation Between Centrality Measures Table 1 shows the Pearson Correlation scores between the different centrality measures. The table shows that among the traditional centrality measures based on network topology, degree centrality and betweenness centrality are more similar than with closeness centrality. The nodes with high closeness are more likely be near the center of the network while high degree and betweenness nodes may be located away from the center.
Among the new centrality measures based on travel time and commuter flow, the commuter flow and DelayFlow centrality are more similar with degree centrality and betweenness centrality with correlation scores above 0.5. The time delay centrality is quite different from the rest except closeness centrality. This suggests that those station that have large time delay to other stations are likely to be those near the center of the network. This is later verified by the top 10 stations of each centrality measure in Table 2. We also observe that DelayFlow centrality is highly similar to commuter flow centrality measure with a correlation score of 0.97. Again, we can also see this in Table 2.
In Table 2, the top stations ranked by most centrality measures are usually the interchange stations. The non-interchange stations are annotated with “*”. Only the time delay centrality gives highest score to a non-interchange station, S110. It also ranks several other non-interchange stations highly. These stations are expected to have large delay factor values compared with other stations.
6 Visual Analytics of Centrality Measures
In this research, we also develop a visual analytics tool to feature the stations with different centrality measures, and to explore the changes to centrality value over time. Figure 13 shows the main web interface of the visual analytics tool. The figure shows the layout of station nodes of the Singapore’s MRT network. We show the nodes with size proportional to the selected centrality values of the nodes—the bigger the node, the higher the centrality. User can select one of the six centrality measures to be analyzed, namely, Degree Centrality, Closeness Centrality, Betweeness Centrality, Commuter Flow Centrality, Time Delay Centrality and DelayFlow Centrality. For the three new centrality measures, we can also visualize them for a selected day of the week and for specific hour of the day.

Visualization of centralities
The visual analytics tool can also show a parallel plot to depicts different centrality values of every station represented by a polyline as shown in Fig. 14. One can explore and compare the DelayFlow centrality against the other centrality measures. In addition, information pertaining to the respective train stations will also be displayed on the top right-hand corner when the end-user performs a mouse-over action on the corresponding line in the parallel plot. Lastly, the table on the bottom right-hand corner shows the top 20 train stations with the highest DelayFlow centrality values.

Parallel plots of centrality
To visualize the dynamic changes of commuter flow and DelayFlow centrality, the tool provides a continuous rendering of the centrality values for the network from 0500 to 0000 h. In this way, a quick overview of the importance of stations over time can be obtained. As shown in Fig. 15, in a selected weekday, stations in the west have higher DelayFlow values (or more importance) as commuters begin to travel to the central and east areas for work around 0600 h. Failures at these stations can also cause major delays. At around 0900 h, stations in the central area gain higher DelayFlow values due to increased activities in the area, while stations in the west see their DelayFlow values reduced. At around 1200 h, all stations appear to have smaller DelayFlow values. At around 1800 h, commuters begin to travel to the west causing some increase to the DelayFlow of relevant stations. These stations see their DelayFlow values return to normal at around 2100 h. The above dynamic changes of centrality are very useful when developing response plan for network failures as the stations give different impact to the transportation system at different time of the day.

Dynamic change of DelayFlow centrality
7 Conclusion
In our paper, we have demonstrated the importance of considering transportation factors such as commuter flow and time delay in measuring network centrality of transportation network. When incorporating trip data and time information, we derive three new centrality measures which can dynamically vary with time. These dynamic centrality measures allow us to generate unique insights giving better guidance to the design and improvement of the transportation network. They can also be extremely useful for optimizing travel schedules for commuters and increasing the standard of transportation services. Compared with the network topology based centrality measures, our new centrality measures are more relevant to the transportation domain in identifying critical nodes. A visual analytics tool has also been developed to illustrate the efficacy of the new centrality measures.
With this foundation research, we plan to apply the measures on other transportation networks to explore some common properties among the network centralities. We have so far assumed that the expected and alternative travel times are independent of the time of the day in our centrality definitions. This assumption will be relaxed in the future by computing the travel times at different time of the day. Relationship between the new centralities and the underlying population distribution, as well as extensions to consider other modes of transportation are also among the interesting topics for future research.
Notes
References
Berche B, von Ferber C, Holovatch T, Holovatch Y (2009) Resilience of public transport networks against attacks. Eur Phys J B 71(1):125–137
Boccaletti S, Latora V, Moreno Y, Chavez M, Hwang D (2006) Complex networks: structure and dynamics. Phys Rep 424(4–5):175–308
Brin S, Page L (1998) The anatomy of a large-scale hypertextual web search engine. In: The seven international conference on world wide web, pp 107–117
De Montis A, Barthelemy M, Chessa A, Vespignani A (2005) The structure of inter-urban traffic: a weighted network analysis
Derrible S (2012) Network centrality of metro systems. PLoS One 7(7): e40575
Dijkstra E (1959) Dijkstra’s algorithm. A note on two problems in connexion with graphs. Numerische Mathematik 1:269–271
Freeman L (1977) A set of measures of centrality based on betweenness. Sociometry 40:35–41
Freeman L (1978/79) Centrality in social networks: conceptual clarification. Soc Netw 1:215–239
Gao M, Lim E-P, Lo D (213) R-energy for evaluating robustness of dynamic networks. In: ACM conference on web science
Goh K-I, Oh E, Jeong H, Kahng B, Kim D (2002) Classification of scale-free networks. PNAS 99(20):12583–12588
Guimer R, Mossa S, Turtschi A, Amaral LAN (2005) The worldwide air transportation network: anomalous centrality, community structure, and cities’ global roles. Proc Natl Acad Sci USA 102(22):7794–7799
Newman M (2008) The mathematics of networks. In: Blume L, Durlauf S (eds) The new Palgrave encyclopedia of economics, 2nd edn. Palgrave Macmillan, Canada
Opsahl T, Agneessens F, Skvoretz J (2010) Node centrality in weighted networks: generalizing degree and shortest paths. Soc Netw 32(3):245–251
Scheurer J, Curtis C, Porta S (2008) Spatial network analysis of multimodal transport systems: developing a strategic planning tool to assess the congruence of movement and urban structure. In: Technical report GAMUT2008/JUN/02, GAMUT Australasian centre for the governance and management of urban transport, The University of Melbourne
Sevtsuk A, Mekonnen M (2012) Urban network analysis toolbox. Int J Geomat Spat Anal 22(2):287–305
Acknowledgments
We would like to thank the Land Transport Authority (LTA) of Singapore for sharing with us the MRT dataset. This work is supported by the National Research Foundation under its International Research Centre@Singapore Funding Initiative and administered by the IDM Programme Office, and National Research Foundation (NRF).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Cheng, YY., Lee, R.KW., Lim, EP., Zhu, F. (2015). Measuring Centralities for Transportation Networks Beyond Structures. In: Kazienko, P., Chawla, N. (eds) Applications of Social Media and Social Network Analysis. Lecture Notes in Social Networks. Springer, Cham. https://doi.org/10.1007/978-3-319-19003-7_2
Download citation
DOI: https://doi.org/10.1007/978-3-319-19003-7_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-19002-0
Online ISBN: 978-3-319-19003-7
eBook Packages: Computer ScienceComputer Science (R0)