
Abstract
In this paper, we propose a novel approach to extract local descriptors of a video, based on two ideas, one using motion boundary between objects, and, second, the resulting motion boundary trajectories extracted from videos, together with other local descriptors in the neighbourhood of the extracted motion boundary trajectories, histogram of oriented gradients, histogram of optical flow, motion boundary histogram, can be used as local descriptors for video representations. The motion boundary approach captures more information between moving objects which might be caused by camera movements. We compare the performance of the proposed motion boundary trajectory approach with other state-of-the-art approaches, e.g., trajectory based approach, on a number of human action benchmark datasets (YouTube, UCF sports, Olympic Sports, HMDB51, Hollywood2 and UCF50), and found that the proposed approach gives improved recognition results.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Recognizing human action in a video is a commonly studied topic in computer vision and machine learning [1–4]. Broadly speaking, a popular approach is to first extract a set of local descriptors, and then use a bag-of-features model for matching those local descriptors obtained in the set of labeled training video clips, to those as yet unlabelled in the testing dataset [5–7].
Laptev [8] introduced space-time interest points (STIPs) using an extension of the Harris corner detection method [9] from image to video. Other detectors are also used to detect interest points in videos, e.g., Willems et al. [10] proposed using the determinant of the spatiotemporal Hessian matrix for interest point detection, Dollar et al. [11] proposed a 1D Gabor filter in the time dimension with a 2D Gaussian in the spatial dimensions to detect the underlying periodic frequency components for interest point detection.
Based on the detected interest points in a video, a descriptor is proposed to describe the information of sub-regions of the video as local features. Several descriptors have been proposed for describing these spatiotemporal local features, e.g., higher order derivatives (local jets) [8], histogram of oriented gradient (HOG) [12] for capturing object shape, these are called the appearance descriptors; histogram of optical flow (HOF) [12] for capturing object motion information, a spatiotemporal version of HOG, called HOG3D [13] which extends the idea of HOG to the 3D case, histogram of oriented flows (HOF), a way of representing movements across time [12], and motion boundary histograms (MBH) [14] to cope with the camera motion. This detector/descriptor approach can be considered as a kind of bag-of-features video representation.
In contrast from detecting interest points in a 3D volume data, another approach to obtaining local features from a video is the trajectory approach, so called dense trajectory approach, as the patch is represented by a large number of interest points, [4, 15]. In this approach, a set of local interest points is first detected using the 2D Harris condition [9] from video frames and an optical flow field is then used to track these interest points temporally to form the patch trajectories in the video [4]. The trajectory descriptor, together with the local descriptors, can be used to represent the video under a bag-of-features framework.
However, it is difficult to detect the actual moving objects in a complex background scene with severe camera motion using the 2D Harris corner condition [9] as the local patch detector. In this paper, we wish to show that the motion patterns of objects are important and will help detect informative patch trajectories for action recognition. In [16], the authors also introduced a motion boundary based sampling for action recognition, though it is different from the one which we proposed in this paper. The fact that motion provides important cue for grouping objects is well known [17]. On the other hand, to cope with camera motion, Dalal et al. introduced the motion boundary histogram (MBH) [14] as an effective local descriptor. MBH encodes the gradients of optical flow, which are helpful for canceling constant camera motion. Despite the importance of MBH as clearly shown in Dalal et al. [14], it appears that no one has yet explored the idea of a motion boundary in the dense trajectory approach [4]. It is expected that if we can embed the motion boundary concept in the dense trajectory approach [4], then it can handle issues related to camera motion, and thus would result in improved recognition rate, for datasets which may have taken while the camera might be moving. In this paper, we propose to use the motion boundary between objects for detecting local patches within the dense trajectory approach [4]. The motion boundary can capture more informative information between moving objects which might be caused because the camera was moving. With the motion boundary defined, the motion boundary trajectory can be extracted and can be used for the video representation. We compare the performances of various approaches on a number of standard benchmark datasets [18–22] and achieve better results using the proposed approach.
The rest of this paper is organized as follows. Section 2 discusses related work; Sect. 3.3 briefly introduces the concept of local descriptor extractions from videos, which include motion boundary trajectories (in Sect. 3.2), appearance based descriptors and motion descriptors; Sect. 4 provides approaches to classification; experimental results are shown in Sect. 5. Finally, some conclusions are drawn in Sect. 6.
Contribution: This paper establishes the deployment of motion boundary detemination in the dense-trajectory approach for action recognition. The motion boundary between objects is determined and then those points in this motion boundary are tracked to form the motion boundary trajectories for video representation. Experimental results show that this idea can improve the performance of recognition significantly.
2 Relative Works
The most popular approach for action recognition is the well known bag-of-feature model [19, 23, 24]. In this model, the selection of local features of a video is important for the video representation. There are two broad approaches within this tradition: the detector/descriptor approach [18] and the trajectory approach [4]. In the detector/descriptor approach [18], the detector is used to detect interesting sub-regions of a video, contained within such sub-regions are typically the intensity values that have significant local variations in both space and time. For these sub-regions, the descriptors are applied to describe the spatial-temporal local features of the video [18]. The dense trajectory approach [4] tracks the detected local patches in the video frames through time. Then patch trajectories can be extracted from these sub-regions of the video. In the dense trajectory approach, the extracted spatial-temporal local features are significant [4]. It can be explained that the detected/extracted features are specifically based on object appearances and, to some extent, on motions (as the motion boundary histogram is used to represent the motion).
Some related work can be found in motion segmentation and video co-segmentation [25]. Motion segmentation is the problem of decomposing a video and to detect moving objects and background based on the idea of coherent regions with respect to motion and appearance properties [25]. Motion information provides an important cue for identifying the surfaces in a scene and for differentiating image texture from physical structures. In [17], long term point trajectories based on dense optical flow are used to spatial–temporal cluster the feature points into temporally consistent segmentations of moving objects. The quality of motion segmentation depends significantly on the pair of frames with a clear motion difference between the objects [26]. The advantage of motion segmentation derives from the fact that it combines motion estimation with segmentation. For segmenting multiple objects in the scene, the layered model for motion segmentation is proposed [27]. Typically, the scene consists of a number of moving objects and representing each moving object by a layer that allows the motion of each layer to be described [27]. Such a representation can model the occlusion relationships among layers making the detection of occlusion boundaries possible [28, 29]. Typically, the background/foreground segmentation is a special case of binary object segmentation in this layered model [30].
In [25], multiple objects and multi-class video co-segmentation task is proposed to segment objects in videos. Object co-segmentation [25] is to segment a prominent object based on an image pair in which it appears in both images. With this idea, video co-segmentation segments the objects that are shared between videos, therefore co-segmentation can be encouraged. With this approach, object boundaries can be detected [28, 29].
Based on the idea of motion segmentation, objects may be segmented from the background in the action recognition. Inspired by the idea of motion boundary histogram descriptor in the bag-of-feature framework, in this paper, we propose to use the boundary between objects as a descriptor in the dense-trajectory approach. The motion boundary can then be tracked frame by frame and then deployed as a descriptor, very much in the same manner as the patch trajectories in the dense trajectory approach [4] and then used for action recognition. This has the advantage of not requiring to perform the segmentation or co-segmentation task which are very time consuming tasks, where there is no significant occlusion of the objects involved.
3 Motion Boundary Trajectories
In this section, we will describe the proposed motion boundary dense trajectory approach. We will first describe the dense trajectory approach [4] briefly, and then we will show how motion boundary trajectories can be extracted from the video.
3.1 Dense Trajectories
The idea of a trajectory is based on interest points tracking [4]; the interest points are tracked frame by frame and then the corresponding trajectory can be extracted based on the tracked points [4]. For the motion boundary trajectories, we first detect the motion boundary on video frames and then track the detected motion boundary through time to form the motion boundary trajectories of a video.
Consider a video which consists of \(I^{(t)},t=1,2,\dots ,T\) and \(I^{(t)}\) is a 2D pixel intensity array with dimensions \(W\times H\). The optical flow field is computed over a two-frame sequence \(I^{(t)}\) and \(I^{(t+1)}\), \(\omega ^{(t)}=(u^{(t)},v^{(t)})\), where, \(u^{(t)}\), \(v^{(t)}\) are respectively the optical flow in the horizontal and vertical directions. We apply a median filtering on the optical flow field \(\omega ^{(t)}=(u^{(t)},v^{(t)})\) within a \(3\times 3\) patch. The resulting optical flow field is denoted by \(\bar{\omega }^{(t)}=(\bar{u}^{(t)},\bar{v}^{(t)})=\omega ^{(t)}\star M_{3\times 3}\), where \(M_{3\times 3}\) is the median filter kernel and \(\bar{\omega }^{(t)}\) is the filtered result of the optical flow field and \(\star \) is the convolution operator.
In the dense trajectory approach [4], the Harris corner condition [9]. With this selection, a set of interest points, determined using a 2D Harris corner condition [9] on the object appearance, is then tracked frame by frame to form the dense trajectories.
In other to cope with the camera motion, a matching of feature points using SURF descriptors and dense optical flow is applied to estimate a homography between two subsequent frames by RANSAC algorithm as in [31]. Based on the reason of human action is in general different from camera motion. A human detector is employed to remove matches from human regions to improve the camera motion estimation. Finally, the trajectories consistent with the camera motion are then removed which are no longer useful for the tracking process [31].
3.2 Motion Boundary Trajectories
Different from using object appearances, motion boundary trajectory approach is based on the motion boundary between objects. To detect the motion boundary, we extract its location using the optical flow. Assume each object will have different flow directions and velocities, we detect their boundaries using the derivative of the optical flow field which captures the discontinuity, e.g., edges, of the optical flow field. For the point \(P_{i}^{(t)}\in I^{(t)}\), the measurement of its boundary is given by
where, \((\bar{u}_{P_{i}^{(t)}},\bar{v}_{P_{i}^{(t)}})\) is the flow vector of point \(P_{i}^{(t)}\).
The determination of the motion boundary trajectories is very similar to that proposed in [4] in the dense trajectory approach. Given a dense grid of frame \(I^{(t)}\), we can densely sample points on a grid spaced by \(w\) pixels. In our case, the dense grid is set to \(5\times 5\). Sampling is carried out on each spatial scale separately. Different scales can be obtained by simply re-sizing the video to different resolutions, with a scaling factor of \(\frac{1}{\sqrt{2}}\). In our setting, there are at most 8 spatial scales in total [4]. To obtain the motion boundary trajectories, we first select the points based on Harris corner condition
where, \((\lambda _{P_{i}^{(t)}}^{1},\lambda _{P_{i}^{(t)}}^{2})\) are the eigenvalues of the auto-correlation matrix of point \(P_{i}^{(t)}\) in frame \(I^{(t)}\). We then threshold the motion boundary based on the threshold \(T_{corner}^{(t)}\) as
We then use another threshold condition for which a point is of interest (i.e., significant enough for further consideration):
The point \(P_{i}^{(t)}\) will be selected, if its magnitude is greater than the threshold, i.e., \(\tilde{H}_{P_{i}^{(t)}}>T_{motion}^{(t)}\), while those points which do not satisfy this condition will not be considered further. In our setting, we set \(C_{1}=0.0001\), \(C_{2}=0.01\) and \(C_{3}=0.002\). From the above process, we will know which sub-sampled point \(P_{i}^{(t)}\) will need to be considered for the trajectory tracking. We then track the selected points using optical flow field \(\bar{\omega }^{(t)}=(\bar{u}^{(t)},\bar{v}^{(t)})\). Consider a point \(P_{i}^{(t)}=(x_{i}^{(t)},y_{i}^{(t)})\) in frame \(I^{(t)}\), the tracked point \(P_{i}^{(t+1)}=(x_{i}^{(t+1)},y_{i}^{(t+1)})\) of \(P_{i}^{(t)}\) in the next frame \(I^{(t+1)}\) is computed by:
The tracked points of subsequent frames are then concatenated temporally to form a trajectory, \(\text {Traj}_{i}=(P_{i}^{(t)},P_{i}^{(t+1)},P_{i}^{(t+2)},\ldots )\). For each frame, if no tracked point is found in the neighborhood, a new point \(P_{i^{*}}^{(t)}\) is sampled and added to the tracking process. If the length of a trajectory has reached a maximum length \(L=15\), a post-processing stage is then performed to remove the static trajectories [4].
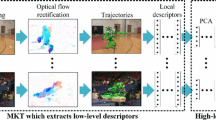
In order to obtain a better motion boundary, we follow [31] and estimate the homography of two subsequent frames, and then warp the second frame with the estimated homography. Based on the warped frame, the Harris cornerness is computed by the warped second frame and the optical flow is computed between, the first and the warped second frame. To obtain more interest points surrounding the moving objects, we apply a Gaussian filter and then a median filter on the motion boundary map, i.e., \(\tilde{H}\). We then select and track the points for extracting the motion boundary trajectories. For the optical flow, we use the Farneback optical flow algorithm [32], which employs a polynomial expansion to approximate the pixel intensities in the neighborhood to obtain a good quality flow field as well as capturing some fine details [4]. Figure 1 shows the results of the motion boundary as well as the motion boundary trajectory obtained from some selected videos.

The first row shows the original images; the second row shows the detected motion boundaries; and the third row shows the corresponding motion boundary trajectories
It is observed that the motion boundary trajectories can capture the motion quite well.
3.3 Motion Boundary Descriptors
Local descriptors are features which describe the spatial temporal behaviours of humans in the video. There are a number of such descriptors proposed by various researchers: [4]. The essential idea is to find good descriptors which will describe the spatial temporal behaviours of pixel values in a small neighborhood of a volume consisting of two dimensional space and time [4]. Some of these methods were extended from image processing techniques, while others were constructed explicitly for spatial temporal behaviours [4].
Several descriptors can be obtained to encode either the shape of a trajectory or the local motion [4] and appearance within a space-time volume [14] around the trajectory. The trajectory shape descriptor encodes local motion patterns by using the displacement vectors of a trajectory [4]. HOG (Histogram of oriented gradient) along a trajectory focuses on the static part of the appearance of a local patch of the video. For encoding the motion information, HOF (Histograms of optical flow) captures the local motion information based on the optical flow field; MBH (Motion boundary histogram) uses the gradient of the optical flow to cancel out most of the effects of camera motion [14]. These descriptors give a state-of-the-art performance for representing local information.
In this paper, we will add the motion boundary trajectories as the descriptors for the motion in the time axis. The motion trajectory descriptor can be formed by considering the shape of the trajectories, in a manner very similar to that proposed in [4]. Given a trajectory of length \(L\), a sequence \((\triangle P_{i}^{(t)},\ldots ,\triangle P_{i}^{(t+L-1)})\) of the displacement vectors \(\triangle P_{i}^{(t)}=P_{i}^{(t+1)}-P_{i}^{(t)}=(x_{i}^{(t+1)}-x_{i}^{(t)},y_{i}^{(t+1)}-y_{i}^{(t)})\) is used for describing the trajectory shape. The normalized concatenation of the displacement vectors will become the feature vector of the trajectory shape:
With the motion boundary trajectory, \(\text {Traj}_{i}=(P_{i}^{(t)},P_{i}^{(t+1)},P_{i}^{(t+2)},\ldots )\), the corresponding HOG, HOF and MBH descriptors can also be extracted based on the motion boundary trajectory as the trajectory based HOG, HOF and MBH descriptors (please see Fig. 2 for an illustration of these concepts). We follow [31], motion descriptors (HOF and MBH) are computed on the warped optical flow. The trajectory shape descriptor and HOG descriptor remain unchanged.

Illustration of motion boundary trajectory descriptor. The motion boundary trajectory is represented by relative point coordinates, \(\text {Traj}_{i}=(P_{i}^{(t)},P_{i}^{(t+1)},P_{i}^{(t+2)},\ldots )\); based on the motion boundary trajectories, the HOG, HOF and MBH descriptors are computed along the trajectories.
4 Classification
We apply the standard bag-of-features approach to convert the local descriptors from a video into a fixed-dimensional vector. We first construct a codebook for the trajectory descriptor (Sect. 3.3) using the \(k\)-mean clustering algorithm, and then the clusters will serve as visual words. We fix the number of visual words to \(V=4,000\). To limit the complexity of the problem, we cluster a subset of 100,000 randomly selected from the training features in the \(k\)-mean clustering algorithm. Descriptors are then assigned to their closest vocabulary word using an Euclidean norm. The resulting histograms of visual word occurrences are used as video representations.
We apply the linear and non-linear SVM for action recognition. For the linear SVM [33], we first scale the value of each visual word feature to \([0,1]\), and then the feature vector of a video is normailzied by a norm-2 normalization. For the nonlinear SVM [12], we normalize the histogram using the RootSIFT approach [34], i.e., square root each dimension after L1 normalization, and then apply the standard RBF (radial basis function)-\(\chi ^{2}\) kernel [4] as the baseline algorithm in our experiments.
where \(H_{i}=\{h_{ik}\}_{k=1}^{V}\) and \(H_{j}=\{h_{jk}\}_{k=1}^{V}\) are the frequency histograms of word occurrences and \(V\) is the vocabulary size. \(A\) is the mean value of distances between all training samples [18]. In the case of multi-class classification, the one-against-all approach is applied, we select the class with the highest score. Typically, the approach for integrating the contribution of different descriptors is the multiple channel SVM [7, 12], which is a special case of multiple kernel learning [35]. We simply average the kernels computed from different representations to combine different channels using the idea of multiple channel SVM.
We also apply the Fisher vector [36] encoding for video representation. Fisher vector encodes both first and second order statistics between the video descriptors and a Gaussian Mixture Model (GMM). We follow [31], first reduce the descriptor dimensionality by Principal Component Analysis (PCA), as in [31]. We set the number of Gaussians to \(K=256\) and randomly sample a subset of 256,000 features from the training set to estimate the GMM [31]. As a result, for each type of descriptor, each video is represented by a \(2DK\) dimensional Fisher vector, where \(D\) is the dimension of the descriptor after performing PCA. Finally, we apply power and the RootSIFT approach normalization to the Fisher vector. For integrating different descriptor types, we concatenate their normalized Fisher vectors, and a linear SVM is used for classification.
5 Experiments
This section evaluates the proposed motion boundary trajectories as a descriptor. We run the experiments at least 3 times for descriptor-classifier pairs. We will report the average accuracy of those experiments.
5.1 Datasets
We evaluate our proposed motion boundary descriptor on six standard benchmark datasets, viz., UCF-Sports [20], YouTube dataset [19], Olympic Sports dataset [21], the HMDB51 dataset [22], the Hollywood2 datasets, and the UCF50 datasets.
The UCF-Sports dataset contains 150 videos from ten action classes, diving, golf swinging, kicking, lifting, horse riding, walking, running, skating, swinging (on the pommel horse and on the floor), and swinging (at the high bar). These videos are taken from real sports broadcasts and the bounding boxes around the subjects are provided for each frame. We follow the protocol proposed in [37, 38] using the same training/testing samples for our experiments; by taking one third of the videos from each action category to form the test set, and the rest of the videos are used for training. Average accuracy over all classes is reported as the performance measure.
The YouTube dataset contains 11 action categories: basketball shooting, biking/cycling, diving, golf swinging, horse back riding, soccer juggling, swinging, tennis swinging, trampoline jumping, volleyball spiking, and walking with a dog. For each category, the videos are grouped into 25 groups with more than 4 action clips in it. The dataset contains a total of 1,168 sequences. We follow the original setup [19], using leave-one-out cross-validation for a pre-defined set of 25 groups. Average accuracy over all classes is reported as the performance measure.
The Olympic Sports dataset [21] consists of athletes practising different sports, which are collected from YouTube and annotated using the Amazon Mechanical Turk technique. There are 16 sports actions: high jump, long jump, triple jump, pole vault, discuss throw, hammer throw, javelin throw, shot put, basketball layup, bowling, tennis serve, platform (diving), springboard (diving), snatch (weight lifting), clean and jerk (weight lifting) and vault (gymnastics), represented by a total of 783 video sequences. We adopt the train/test split from [21]. The mean average precision (mAP) over all classes [12, 39] is reported as the performance measure.
The HMDB51 contains 51 distinct action categories, each containing at least 101 clips for a total of 6,766 video clips extracted from a wide range of sources. We follow the original evaluation protocol using three train-test splits [22]. For every class and split, there are 70 videos for training and 30 videos for testing. We report the average accuracy over three-splits as performance measure.
The Hollywood2 dataset [40] has been collected from 69 different Hollywood movies and includes 12 action classes. It contains 1,707 videos split into a training set (823 videos) and a test set (884 videos). Training and test videos come from different movies. The performance is measured by mean average precision (mAP) over all classes, as in [40].
The UCF50 dataset [41] has 50 action categories, consisting of real-world videos taken from YouTube. There are 50 categories in UCF50 dataset, the videos are split into 25 groups. For each group, there are at least 4 action clips. In total, there are 6,618 video clips. We apply the leave-one-group-out cross-validation as recommended by the authors and report average accuracy over all classes.
5.2 Experimental Results
The experimental results using bag-of-feature histogram are shown in Table 1. We also list the results of improved dense trajectory approach [4] in our experiments, under the name Dense Trajectory in Table 1. For the dense trajectory approach, the 2D interest points are detected based on corner condition [4], and then track the detected points frame by frame to form the dense trajectories. From the results listed in Table 1, we note that the best performance is achieved using our motion boundary trajectory descriptor.
We found that on the UCF Sports dataset, the motion boundary trajectory descriptor together with HOF as well as MBH obtain very good results. The UCF Sports dataset contains videos which are typically featured on broadcast television channels, e.g., BBC and ESPN; these videos are recorded by professional cameramen and camera movement is relatively smooth. As a result, the detected motion boundary is much more meaningful, which is shown in Fig. 3. This observation is also true with the Olympic Sports dataset, in which the motion boundary trajectory with MBH descriptor obtain good results.
The videos of YouTube dataset are collected from YouTube and are personal videos. This dataset is very challenging due to large variations in camera motion. In this case, the motion boundary trajectories are not very accurate. As a result, the performance of motion boundary trajectory only improve slightly that compare with dense trajectory.

Comparison between the dense trajectories and motion boundary trajectories (the first row shows dense trajectory; the second shows motion boundary trajectory)
We also evaluated the performance of combining representations named Combined as listed in Table 1. We evaluated two different classifiers, viz., the linear SVM and the \(\chi ^{2}\) SVM. We simply average the kernel matrices computed from different representations to obtain the aggregated results. The motion boundary trajectory also improves the performance at least 1 % on the UCF Sports and HMDB51 datasets and slightly improves on YouTube and Olympic Sports datasets.
Figure 3 show the motion boundary trajectories and the dense trajectories. In Fig. 3, we note that the motion boundary detected in some videos is significant, the motion boundary can capture the trajectories around the moving objects when compare with those obtained from the dense trajectory approach.
Comparison to the state of the art. In [31], Wang introducted improved dense trajectory feature for action recognition. Together with the Fisher vector encoding for video representation, Wang obtained state-of-the-art results. We use the same setting as in [31] but instead of extracting dense trajectory, we extract the motion boundary trajectory. We also use the human boundary boxes provided by authors [31] for better eastimation of homography between two subsequent frames. The experimental result in Table 2, we also listed the result from [31], named as IDT (improved dense trajectory). In Table 2, we noted that the Olympic Sports dataset, the motion boundary trajectory (MBT) approach obtains at least 2 % improvement. We obtain 93.5 % mAP. For the HMDB51 dataset, we obtain at least 5 % improvement and obtain 63.8 accuracy. For the Hollywood2 dataset, the improvement is not too much, only 0.1 % improvement. For the UCF50 dataset, we get 1 % improvement and obtain 92.2 % accuracy. Those results show that the motion boundary is useful for describing the motion information and significantly improve the recognition accuracy in action recognition.
6 Conclusion
In this paper, we propose a novel approach based on two ideas, one using motion boundary between objects, and, second, the resulting motion boundary trajectories extracted from videos as the local descriptors. These resulted in a new descriptor, the motion boundary descriptor. We compare the performance of the proposed approach with other state-of-the-art approaches, e.g., trajectory based approach, on six human action recognition benchmark datasets, and found that the proposed approach gives better recognition results.
References
Brendel, W., Todorovic, S.: Learning spatiotemporal graphs of human activities. In: ICCV, pp. 778–785 (2011)
Niebles, J.C., Wang, H., Fei-Fei, L.: Unsupervised learning of human action categories using spatial-temporal words. IJCV 79, 299–318 (2008)
Guo, K., Ishwar, P., Konrad, J.: Action recognition in video by covariance matching of silhouette tunnels. In: Brazilian Symposium on Computer Graphics and Image Processing, pp. 299–306 (2009)
Wang, H., Kläser, A., Schmid, C., Liu, C.L.: Dense trajectories and motion boundary descriptors for action recognition. IJCV 103, 60–79 (2013)
Wallraven, C., Caputo, B., Graf, A.: Recognition with local features: the kernel recipe. In: ICCV, pp. 257–264 (2003)
Willamowski, J., Arregui, D., Csurka, G., Dance, C.R., Fan, L.: Categorizing nine visual classes using local appearance descriptors. In: ICPR Workshop on Learning for Adaptable Visual Systems (2004)
Zhang, J., Lazebnik, S., Schmid, C.: Local features and kernels for classification of texture and object categories: a comprehensive study. IJCV 73, 213–238 (2007)
Laptev, I.: On space-time interest points. IJCV 64, 107–123 (2005)
Harris, C., Stephens, M.: A combined corner and edge detector. In: Proceedings of the Alvey Vision Conference, pp. 147–151 (1988)
Willems, G., Tuytelaars, T., Van Gool, L.: An efficient dense and scale-invariant spatio-temporal interest point detector. In: Forsyth, D., Torr, P., Zisserman, A. (eds.) ECCV 2008, Part II. LNCS, vol. 5303, pp. 650–663. Springer, Heidelberg (2008)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: CVPR, pp. 886–893 (2005)
Laptev, I., Marszałek, M., Schmid, C., Rozenfeld, B.: Learning realistic human actions from movies. In: CVPR, pp. 1–8 (2008)
Kläser, A., Marszałek, M., Schmid, C.: A spatio-temporal descriptor based on 3d-gradients. In: BMVC, pp. 995–1004 (2008)
Dalal, N., Triggs, B., Schmid, C.: Human detection using oriented histograms of flow and appearance. In: Leonardis, A., Bischof, H., Pinz, A. (eds.) ECCV 2006. LNCS, vol. 3952, pp. 428–441. Springer, Heidelberg (2006)
Matikainen, P., Hebert, M., Sukthankar, R.: Trajectons: action recognition through the motion analysis of tracked features. In: ICCV Workshop on Video-oriented Object and Event Classification (2009)
Peng, X., Qiao, Y., Peng, Q., Qi, X.: Exploring motion boundary based sampling and spatial-temporal context descriptors for action recognition. In: BMVC (2013)
Brox, T., Malik, J.: Object segmentation by long term analysis of point trajectories. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010, Part V. LNCS, vol. 6315, pp. 282–295. Springer, Heidelberg (2010)
Schuldt, C., Laptev, I., Caputo, B.: Recognizing human actions: a local SVM approach. In: ICPR, vol. 3, pp. 32–36 (2004)
Liu, J., Luo, J., Shah, M.: Recognizing realistic actions from videos in the wild. In: CVPR (2009)
Rodriguez, M., Ahmed, J., Shah, M.: Action mach a spatio-temporal maximum average correlation height filter for action recognition. In: CVPR, pp. 1–8 (2008)
Niebles, J.C., Chen, C.-W., Fei-Fei, L.: Modeling temporal structure of decomposable motion segments for activity classification. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010, Part II. LNCS, vol. 6312, pp. 392–405. Springer, Heidelberg (2010)
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: HMDB: a large video database for human motion recognition. In: ICCV (2011)
Sivic, J., Zisserman, A.: Video Google: a text retrieval approach to object matching in videos. In: ICCV, vol. 2, pp. 1470–1477 (2003)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In: Proceedings of CVPR 2006, pp. 2169–2178 (2006)
Chiu, W.C., Fritz, M.: Multi-class video co-segmentation with a generative multi-video model. In: CVPR (2013)
Wang, J.Y., Adelson, E.H.: Representing moving images with layers (1994)
Sun, D., Sudderth, E.B., Black, M.J.: Layered segmentation and optical flow estimation over time. In: CVPR, pp. 1768–1775 (2012)
Black, M.J., Fleet, D.J.: Probabilistic detection and tracking of motion boundaries. IJCV 38, 231–245 (2000)
Feghali, R., Mitiche, A.: Spatiotemporal motion boundary detection and motion boundary velocity estimation for tracking moving objects with a moving camera: a level sets pdes approach with concurrent camera motion compensation. IEEE Trans. Image Process. 13, 1473–1490 (2004)
Sun, D., Wulff, J., Sudderth, E., Pfister, H., Black, M.: A fully-connected layered model of foreground and background flow. In: CVPR (2013)
Wang, H., Schmid, C.: Action recognition with improved trajectories. In: ICCV (2013)
Farnebäck, G.: Two-frame motion estimation based on polynomial expansion. In: Bigun, J., Gustavsson, T. (eds.) SCIA 2003. LNCS, vol. 2749, pp. 363–370. Springer, Heidelberg (2003)
Chang, C.C., Lin, C.J.: Libsvm: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2, 1–27 (2011)
Arandjelović, R., Zisserman, A.: Three things everyone should know to improve object retrieval. In: CVPR (2012)
Gönen, M., Alpaydin, E.: Multiple kernel learning algorithms. JMLR 12, 2211–2268 (2011)
Perronnin, F., Sánchez, J., Mensink, T.: Improving the fisher kernel for large-scale image classification. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010, Part IV. LNCS, vol. 6314, pp. 143–156. Springer, Heidelberg (2010)
Shapovalova, N., Vahdat, A., Cannons, K., Lan, T., Mori, G.: Similarity constrained latent support vector machine: an application to weakly supervised action classification. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012, Part VII. LNCS, vol. 7578, pp. 55–68. Springer, Heidelberg (2012)
Lan, T., Wang, Y., Yang, W., Robinovitch, S., Mori, G.: Discriminative latent models for recognizing contextual group activities. PAMI 34(8), 1549–1562 (2012)
Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL Visual Object Classes Challenge 2007 (VOC 2007) Results
Marszałek, M., Laptev, I., Schmid, C.: Actions in context. In: CVPR (2009)
Reddy, K.K., Shah, M.: Recognizing 50 human action categories of web videos. Mach. Vis. Appl. 24, 971–981 (2013)
Acknowledgment
This work was financially supported by Fundo para o Desenvolvimento das Ciencia das e da Tecnologia, Macau SAR Grant Number 034/2011/A2. The authors would like to thank Associate Prof. Markus Hagenbuchner, University of Wollongong and Prof. Franco Scarselli, University of Siena, for many helpful comments on the proposed approach.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Lo, SL., Tsoi, AC. (2015). Motion Boundary Trajectory for Human Action Recognition. In: Jawahar, C., Shan, S. (eds) Computer Vision - ACCV 2014 Workshops. ACCV 2014. Lecture Notes in Computer Science(), vol 9008. Springer, Cham. https://doi.org/10.1007/978-3-319-16628-5_7
Download citation
DOI: https://doi.org/10.1007/978-3-319-16628-5_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-16627-8
Online ISBN: 978-3-319-16628-5
eBook Packages: Computer ScienceComputer Science (R0)