
Abstract
A Hidden Markov Model (HMM) is a temporal statistical model which is widely utilized for various applications such as gene prediction, speech recognition and localization prediction. HMM represents the state of the process in a discrete variable, where the values are the possible observations of the world. For the purpose of process mining for resource allocation, HMM can be applied to discover a probabilistic workflow model from activities and identify the observations based on the resources utilized by each activity. In this paper, we introduce a process discovery method that combines an organizational perspective with a probabilistic approach to address the resource allocation and improve the productivity of resource management, maximizing the likelihood of the model using the Expectation-Maximization procedure.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
The basic idea of business process modeling is how enterprises can represent actual processes in the way that those processes can be analyzed and improved. Through this model, organizations can obtain a graphical representation of the process activities defining a workflow in order to reach and accomplish intended objectives of business processes [1].
Currently, existing process models do not consider a probabilistic analysis of resources. Consequently, this paper examines a probabilistic approach to resource allocation to represent the relationship between resources and their activities as well as analyze their transitions to indicate the importance of each resource in the related activity. Hence, based on the context of process mining and their perspectives [2], this study will emphasize a control-flow perspective combined with an organizational perspective to support resource allocation by constructing a stochastic model from an event log and reveal how the resources interact directly with the activities.
Meanwhile, machine learning and process mining techniques are closely related [3]. Some machine learning algorithms operate as a “black box” but are helpful for creating systems that can learn from data through poor control-flow discovery. Some machine learning techniques [4] are statistically based on the way that they have learned from data and are concerned with the collection, analysis, and interpretation of data, making these techniques the heart of quantitative reasoning which is necessary for making decisions and recommendations in systems. Hence, HMM is a technique that can deal precisely with noise, incompleteness and not over-fitting the model unlike other techniques e.g. decision trees, support vector machines, ANOVA, etc.
In general, HMM can be helpful in a specific form of the transition process and the process can be considered as a series of time slices. Basically, HMM is modeled after the process in different states for each activity, and the observations in HMM become the resources that interact with the activities. As a result, this research evaluates the possibility of discovering an extended probabilistic process model from a control-flow process with an organizational perspective by applying HMM for resource allocation, analyzing the resource attribute of each event and the activities flow, and estimating the parameters for each activity (state) and resource (observation).
Therefore, this paper investigates the contribution of the applicability of HMM for process mining based on previous premises by defining a probabilistic model that is likely to explain the observed behavior that considers the control-flow patterns, resources, and organization structure.
The remainder of the paper is organized as follows. First, the related work is discussed in more detail in Sect. 2. Section 3 introduces the event logs and HMM notations for the proposed model and explains HMM workflow discovery. Section 4 presents the estimation of the probabilities, resource allocation notations and applicability of the HMM Miner. Finally, Sect. 5 provides the conclusions and future work of the paper.
2 Related Work
There are a few research approaches of HMM in process mining. Rozinat et al. [5] propose a method that begins with a petri-net in order to construct a HMM for a quality evaluation of the model, taking into account different metrics like fitness and precision. Da Silva and Ferreira [6] apply HMM in sequence clustering, where all the elements of the sequence are related with each state in the model as well as propose five different topologies for the model. In [7, 8], the intension mining approach is proposed to identify the reasoning of processes that are behind of the activities.
A number of previous studies have focused on resource and actions or reactions in the business process execution. Rozinat and van der Aalst [3] propose a decision mining technique based on case perspective analysis. Song and van der Aalst [10] present social mining that has an organizational perspective which monitors the originators and relationships and focuses on how the originators interact between them, though not directly with the activities. Recently, Kim et al. [11] introduced a performer recommendation using a decision tree which focuses on time and organizational perspective, resulting in the length of the decision tree becoming too large and too difficult to analyze.
The proposed approach based on the probabilistic method differs from the existing studies from two perspectives: the control-flow perspective proposing a model based on the order of activities, and organizational perspective analyzing and proposing the best interaction between the activities and resources.
3 HMM-Based Process Mining
3.1 Resource-Oriented Event Log
An event log is used as input of process mining to construct models that explain and interpret some aspect of the behavior stored. The event log contains traces referring to the number of cases, activities and resources, as shown in Table 1. It should be noted that this study has not taken into account time stamps or other types of data. Instead, the formal models presented by van der Aalst [12] are extended for HMM miner which adds a limitation based on an event log and a footprint matrix, and it is defined as a resource-oriented event log which follows:
Definition 1.
(Resource-Oriented Event Log) Let L be an event log. L is a tuple < C, S, V > , where C is the set of all possible cases, S of length \( N \) is the finite set of event labels \( \{ s_{1} , \ldots , s_{N} \} \) that has been performed over L, and \( V \in L^{*} \) of length M is a set of originators \( \{ v_{1} , \ldots ,v_{M} \} \) that specify the resource associated with the task.
The construction of HMM workflow is explained in Sects. 3.2 and 3.3. To calculate the initial parameters, the event log is needed to mine the frequency of the occurrence of the activities and resources. This is explained more in Sect. 4. Section 5 discusses how to find the maximum-likelihood estimation (MLE).
3.2 HMM Miner Algorithm
To accommodate the event log, process mining, and HMM in terms of resource allocation, the concepts of HMM workflow is introduced. The formal notation for the HMM workflow is as follows:
Definition 2.
(HMM Workflow) Let L be a resource-oriented event log. A HMM workflow \( \theta \left( L \right) = (s, V, Fs, Fv) \) is represented by:
-
\( s = \{ s_{1} , \ldots , s_{N} , \varepsilon_{N + 1} \} \, \in \,L \) where \( \{ s_{1} , \ldots , s_{N} \} \) are the states or activities of L and \( \{ \varepsilon_{N + 1} \} \) a dummy end state.
-
\( V = \{ v_{1} , \ldots ,v_{M} , \varepsilon_{M + 1} \} \, \in \,L \) where \( \{ v_{1} \ldots v_{M} \} \) are the observations of resources and \( \{ \varepsilon_{M + 1} \} \) a dummy observation of the dummy end state \( \{ \varepsilon_{N + 1} \} \).
-
Fs is an NxN matrix with footprint sequence and frequency of occurrence for transitions \( s_{i} \) to \( s_{j} \).
-
Fv is an NxM matrix with the frequency of occurrence for resources V in state \( s_{i} \).
The procedure for constructing the HMM workflow is presented in Fig. 1. The HMM miner algorithm first investigates the control-flow perspective of a process model from an event log, and considers the order of the events within a case. The attributes such as case id, activity, and resource are utilized in the mining process.

HMM miner algorithm.
3.3 Mining Markovian States
HMM workflow learns from the event log which is fully observed data where the states of the HMM can be represented based on the activities. It takes the notation of event logs to describe the example log in Table 1 where it observes the event sequences L = < abcd, abcd, abcd, acbd, acbd, aed > .
In order to discover a process model, the event log has to be analyzed while it is mining the causal dependencies by using the footprint notation for HMM Miner, and, when analyzed, different patterns of the states evaluate the precedence of each activity, and the frequency of the observed sequences. In order to satisfy these requirements the footprint matrix is introduced in Definition 3.
In process mining, α-algorithm [9] is considered one of the baseline techniques for analysis of patterns in event logs. In our approach, a footprint matrix is required to construct the state transitions of a HMM model analyzing the relations of a pair of activities. The footprint matrix is focused on a process perspective especially in analysis and differentiation of activities sequences. It can measure the frequency of activities and the sequences, helping to real situations where the data is not complete or has noise.
Definition 3.
(Footprint Matrix for HMM Miner) Let L be an event log. Let x1, x2 \( \in \) L:
-
x1 > L x2 if and only if there is a trace σ = < t1, t2, t3,…, tn > and i \( \in \) {1,…, n-1} such that σ \( \in \) L and ti = x1 and ti+1 = x2 (Contains all pairs of activities in a “directly follows”). If is a directly follow, fs = \( \mathop \sum \limits_{\sigma \in L} L(\sigma ) \)
-
x1 → L x2 if and only if x1 > L x2 and x2 > L x1 (Contains all pairs of activities in a “causality” relation
-
x1 #L x2 if and only if x1 > L x2 and x2 > L x1
-
x1 ||L x2 of and only if x1 > L x2 and x2 > L x1
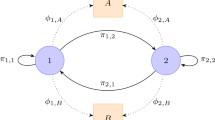
For our implementation activities x1, x2 … xn, are the states for the HMM, e.g. a, b, …, e. After constructing the footprint matrix, the next step is to start with the construction of a Markov chain that simulates a dependency graph based on the states of HMM. The HMM diagram has states expressed by “oval shape and activity name,” and transitions are represented by two different “arcs,” one for transition activities and other for the resource relationships. The first one represents the successor states and in terms of resource mining, the relationship between the activities, and the second, the observations (resources) that correspond to that activity, e.g. activity a has a causality relation with activities b, c and e; so, it is creates a transition denoted by an “arc” from a to these activities. The initial states of the HMM workflow are denoted graphically by a double oval, and the probabilities of each initial state are assigned in the initial state distribution π. Figure 2 shows that all observations were represented with a “square shape and resource name” and assigned directly to each state, and, in turn, the resources are mined from the event log and related to specific activity.

HMM workflow constructed from the footprint matrix without probabilities of Table 2.
To model the end of the process dummy state ε is added, which receives its input from the last activity in each sequence and from which no other state is reachable. Consequently, the transition probability from this state to itself should equal 1. Figure 2 describes a constructed HMM workflow and the interaction of the activities with the different resources show how after the state d is fired and reaches the state ε.
The next section describes how to estimate the probabilities in the mode which first, calculates the initial values for the state transition probability distribution A and for the observation symbol probability distribution B. After several steps, it is determined that the expectation maximization for these probabilities obtains the estimated A* and B*.
4 Resource Allocation with HMM Miner
4.1 Relating Resources to HMM
After obtaining the mined structure of HMM, including the number of states (activities) N, name of the different states s, count of observations (resources) M, label of each observation V and the initial states defined in π, the next step is to determine the initial state transition probability distribution A and the observation symbol probability distribution B. To begin analyzing both probability distributions, the frequency f of each activity and resource, is needed and with them, the weight of the arcs can be calculated, and it is possible to decide which elements should be kept for analysis, and which elements can be discarded to reduce the noise of the mined event log. Starting with the transition probabilities, the footprint matrix is needed to obtain the frequencies.
In order to start the analysis to get the probabilities for the HMM workflow the assumption is made that the data is from an event log L = < C, S, V > ; and each event in L is given by a tuple (s, v) and the total events in L is K. Then (s k , v k ) = (\( s_{1} ,v_{1} \)),…,(\( s_{N} ,v_{M} \)) the probabilities can be computed and collected :
Note in this equation, it is taken in account the frequency where f(i) is the number of times i is the initial state in (s,v). In f(i,j) the number of times j follows i in (s,v) this frequency is in the footprint matrix Fs and f(v k ) the number of times i is paired with observation v is in matrix Fv.
According to these HMM parameters, the log probability can be easily calculated:
In order to find λ that give us a maximum value for L(λ) The following formula is needed: \( {\text{d L}}(\lambda )/{\text{d}}\lambda = 0 \)
Basically, a supervised learning from all mined activities and resources is taken, allowing for the calculation of the probability of each element independently.
4.2 Maximum Likelihood Estimation
Knowing the initial values λ = (N, M, A, B, π); it would be possible to estimate the maximum likelihood in selecting the best values for the model parameters that make the observed data the most probable and obtain λ* = (N, M, A*, B*, π*). As described in Fig. 3, EM procedure essentially calculates their values in 2 steps E and M can be calculated using forward and backward algorithms [4] for HMM.

Expectation-Maximization procedure.
In order to improve λ, the EM procedure uses \( \alpha_{i} \) from the forward algorithm and \( \beta_{i} \) from the backward algorithm, which utilizes the variables \( \gamma \) and ξ as temporal variables [4] in order to estimate the values of A*, B*, and π*.
Given an observation sequence, \( \gamma_{i} (t) \) is the probability of being in state i at time t and \( \xi_{ij} (t) \) is the probability of being in state i at time t and being in state j at time t + 1. These temporal variables are useful in order to determine the maximum likelihood of the parameters, \( \gamma_{i} (t) \) can be interpreted like the possibility to be in a specific activity on a determined time of the process and \( \xi_{ij} (t) \) the probability of the following activities in a specified time.
where \( \pi_{i}^{*} \) is the expected initial state distribution at time 1 in state i. In other words, the expected probability is to begin the process in a specific activity.
where \( a_{ij}^{*} \) is the expected state transition probability distribution, and is the number of times that the transition i occurs in sequence from t = 1 to T − 1. Then, \( a_{ij}^{*} \) is the expected probability from being in activity i to j.
\( b_{j}^{*} \left( {v_{k} } \right) \) is the expected observation symbol probability distribution, where is the expected number of times in state j and observing symbol \( v_{k} \), divided by the expected number of times in j. In terms of this study, it is the predicted parameters of the resources assigned to a specified activity.
4.3 Example
The example is based on the event log from Table 1. It is used for the mining algorithm in Fig. 1 in order to construct the HMM workflow. In Table 2, a footprint matrix is created and Fig. 2 shows the mined HMM workflow without the frequencies. From this point, the next step is calculate the frequency matrix Fv for the analysis of resources, and calculates the initial parameters explained in Sect. 4.1, and the values for the maximum likelihood explained in Sect. 4.2.
First, the mined event log produces three different activity sequences and the algorithm estimate a percentage for < abcdε > with 0.5 %, < acbdε > with 0.33 % and < aedε > with 0.16 %, the number of states that identifies each activity are N = 6 with s = {a, b, c, d, e, ε} and the number of resources that will be the observations M = 6 with V = {Pete, Mike, Ellen, Sue, Sean, ε}.
Table 3 shows the frequency of resources \( s_{i} \) based on activities \( v_{j} \) and is used to create the observation symbol probability distribution \( B = \{ b_{i} (v_{k} )\} \). The initial state distribution is \( \pi_{i} = [1,0,0,0,0,0]^{T} \), where activity {a} is the only one that starts all the process sequence.
Table 4 shows the probabilities for HMM workflow from Eq. 6 where it analyzes the transition from the state i corresponding to the current transition to all states j. For example to assign value probability from activity {a} to {b}, after {a} is fired {b, c, e} can be the next state, the total frequency of sequences {ab}, {ac} and {ae} are 6, and evaluating just {ab} the frequency is 3 showed in Table 2, the probability is 3/6. In the case of resources probabilities, Table 5 shows the observation probability distribution where it is analyzes the resources that interact with a specific activity. For example, in activity {a} the resources used are {Pete, Mike, Ellen} the total frequency is 6 and frequency observed for {Mike} is 1 showed in Table 3, then applying Eq. 7 the probability is 1/6.
With the initial values for the HMM workflow, the EM procedure is utilized to estimate the expected values for transition A* and observation B* distribution. Tables 6 and 7 are shown in graphical form in Fig. 3.
It should be noted that this study has been primarily concerned with the estimation of control flow probabilities and the analysis of work distributions between resources and activities. Our approach is helpful to answer related questions in resource allocation, such as: “How to determine the experience of resources in a specific activity?,” “How to promote a resource effectively based on their experience?” and “What activity has to be scheduled and the resources required?.”
We plan to conduct related experiments in the near future in order to compare and evaluate the proposed method using real-life event logs and implement it in a ProM framework (Fig. 4).

Estimated HMM workflow constructed from the footprint matrix of Table 1.
5 Conclusions
This study presented designs a probabilistic discovery process from event log using HMM to support resource allocation. Specifically, the expectation maximization approach was adopted for estimating the model parameters. The proposed method is useful in real-world scenarios for managing standard errors and noise in real case event logs. Since determining the number of hidden states is very difficult, the following model was based on activities and resources in such a way that the comprehension of the model is enhanced. Also, the proposed technique is helpful to compare the performance of resources for activity executions. Future work includes the consideration of the time perspective to analyze if a resource is busy and the extension of the technique to other scenarios.
References
Aguilar-Saven, R.S.: Business process modelling: Review and framework. Int. J. Prod. Econ. 90(2), 129–149 (2004)
van der Aalst, W., Adriansyah, A., de Medeiros, A.K.A., Arcieri, F., Baier, T., Blickle, T., Pontieri, L., et al.: Process mining manifesto. In: Florian, D., Kamel, B., Schahram, D. (eds.) BPM 2006. LNBIP, vol. 99, pp. 169–194. Springer, Heidelberg (2006)
Rozinat, A., van der Aalst, W.M.: Decision mining in ProM. In: Dustdar, S., Fiadeiro, J.L., Sheth, A.P. (eds.) BPM 2006. LNCS, vol. 4102, pp. 420–425. Springer, Heidelberg (2006)
Bishop, C.M.: Pattern Recognition and Machine Learning. Springer, New York (2006)
Rozinat, A., Veloso, M., van der Aalst, W.M.P.: Using hidden markov models to evaluate the quality of discovered process models. Extended Version. BPM Center Report BPM-08-10. BPMcenter.org (2008)
da Silva, G.A., Ferreira, D.R.: Applying hidden Markov models to process mining. In Sistemas e Tecnologias de Informação. AISTI/FEUP/UPF (2009)
Khodabandelou, G.: Supervised intentional process models discovery using hidden markov models. In: RCIS 2013, pp. 1–11. IEEE Press (2013)
Khodabandelou, G., Hug, C., Deneckère, R., Salinesi, C.: Process mining versus intention mining. In: Nurcan, S., Proper, H.A., Soffer, P., Krogstie, J., Schmidt, R., Halpin, T., Bider, I. (eds.) BPMDS 2013 and EMMSAD 2013. LNBIP, vol. 147, pp. 466–480. Springer, Heidelberg (2013)
van der Aalst, W.M.P., Weijters, T., Maruster, L.: Workflow mining: discovering process models from event logs. IEEE T. Knowl. Data En. 16(9), 1128–1142 (2004)
Song, M., van der Aalst, W.M.P.: Towards comprehensive support for organizational mining. Decis. Support Syst. 46(1), 300–317 (2008)
Kim, A., Obregon, J., Jung, J.-Y.: Constructing decision trees from process logs for performer recommendation. In: Lohmann, N., Song, M., Wohed, P. (eds.) BPM 2013 Workshops. LNBIP, vol. 171, pp. 224–236. Springer, Heidelberg (2014)
van der Aalst, W.M.P.: Process Mining: Discovery, Conformance and Enhancement of Business Processes. Springer, Heidelberg (2011)
Acknowledgments
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT & Future Planning (No. 2012R1A1B4003505).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Carrera, B., Jung, JY. (2015). Constructing Probabilistic Process Models Based on Hidden Markov Models for Resource Allocation. In: Fournier, F., Mendling, J. (eds) Business Process Management Workshops. BPM 2014. Lecture Notes in Business Information Processing, vol 202. Springer, Cham. https://doi.org/10.1007/978-3-319-15895-2_41
Download citation
DOI: https://doi.org/10.1007/978-3-319-15895-2_41
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-15894-5
Online ISBN: 978-3-319-15895-2
eBook Packages: Computer ScienceComputer Science (R0)