
Abstract
Hidden Markov Model (HMM)-based synthesis (HTS) has recently been confirmed to be the most effective method in generating natural speech. However, it lacks adequate context generalization when the training data is limited. As a solution, current study provides a new context-dependent speech modeling framework based on the Gaussian Conditional Random Field (GCRF) theory. By applying this model, an innovative speech synthesis system has been developed which can be viewed as an extension of Context-Dependent Hidden Semi Markov Model (CD-HSMM). A novel Viterbi decoder along with a stochastic gradient ascent algorithm was applied to train model parameters. Also, a fast and efficient parameter generation algorithm was derived for the synthesis part. Experimental results using objective and subjective criteria have shown that the proposed system outperforms HSMM substantially in limited speech databases. Moreover, Mel-cepstral distance of the spectral parameters has been reduced considerably for any size of training database.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Statistical Parametric Speech Synthesis (SPSS) has reportedly been a dominant research area due to its peculiarities since the last decade [1, 2]. Modeling in the domain of SPSS is of prime importance and it is naïve to assume unnecessary simplifying assumptions in modeling as it may reduce the quality of synthetic speech. This work extends Hidden Semi Markov Model (HSMM) synthesis [3] by eliminating some of its simplifying assumptions. In the next subsection we will briefly discuss related works.
1.1 Related Work
Many research activities have already been performed to improve the quality of basic HTS. The progresses such as Hidden Semi Markov Model (HSMM) [3], Trajectory HMM [4] and Multi-Space Distribution HMM [5] have made HTS the most powerful statistical approach. However, these systems do not lead to an acceptable quality with limited databases (less than 30 min). This deficiency is a direct result of applying decision-tree-based context clustering which cannot exploit contextual information efficiently, because each training sample is associated in modeling only one context cluster. This study is an attempt to improve SPSS quality even for limited training data.
The rest of the paper is organized as follows. In Sect. 2, GCRF is introduced. Sections 3 and 4 propose a context-dependent model for speech using GCRF and its application in speech synthesis. Experimental results are presented in Sect. 5 and final remarks are given in Sect. 6.
2 Gaussian Conditional Random Field
To define GCRF, first a brief description of Markov Random Field (MRF) and Conditional Random Field (CRF) is given.
Definition 1.
Let \( {\text{G}} = ({\text{V}},{\text{E}}) \) be an undirected graph, \( {\text{X}} = \left( {{\text{X}}_{\text{v}} } \right)_{{{\text{v}}{ \in }{\text{V}}}} \) be a set of random variables indexed by nodes of G, \( {\text{X}} \) is modeled by MRF iff \( {\forall }{\text{A}},{\text{B}} \subseteq {\text{V}}, {\text{P}}\left( {{\text{X}}_{\text{A}} | {\text{X}}_{\text{B}} } \right) = {\text{P}}\left( {{\text{X}}_{\text{A}} | {\text{X}}_{\text{S}} } \right) \), where \( {\text{S}} \) is a border subset of \( {\text{A}} \) such that every path from a node in \( {\text{A}} \) to a node in \( {\text{B}} \) passes through \( {\text{S}} \) [6].
Definition 2.
\( \left( {{\text{X}},{\text{C}}} \right) \) is a CRF iff for any given set of random variables \( {\text{C}} \), \( {\text{X}} \) forms an MRF [6].
In the speech synthesis framework, given an utterance contextual information \( {\text{C}} \), sufficient statistics of speech (acoustic features) can be considered as an MRF.
Hammersley-Cliffort’s Theorem. Suppose \( \left( {{\text{x}},{\text{c}}} \right) \) is an arbitrary realization of a CRF \( \left( {{\text{X}},{\text{C}}} \right) \) defined based on a graph \( {\text{G}} \) with positive probability, then \( {\text{P}}\left( {\text{x|c}} \right) \) can be factorized by the following Gibbs distribution [7].
where \( {\mathcal{A}} \) denotes a set of all maximal cliques of \( {\text{G}} \). \( {\text{Z}}\left( {\text{c}} \right) \) is called partition function which ensures that the distribution sums to one. In other words,
The theorem also states that for any choice of positive local functions \( \left\{ {\Psi _{a} \left( {\text{x}} \right)} \right\} \) (potential functions) a valid CRF is generated. One of the simplest choices of a potential function is Gaussian function. CRF with Gaussian potential function is named GCRF which is introduced in the next section.
3 Context-Dependent Speech Modeling Using GCRF
For modeling speech, the proposed system primarily splits each segment into a fixed number of states. Then, acoustic and binary contextual features (sufficient statistics) are extracted for each state. The goal is to model and generate acoustic features provided that contextual features are present. The following notations are taken into account henceforth.
- L,I::
-
Total number of acoustic and linguistic features.
- \( {\mathcal{J}}: \) :
-
Total number of states for the current utterance.
- V::
-
All acoustic parameters. (Extracted from frame samples)
- \( {\text{x}}_{{l{\text{j}}}}: \) :
-
l-th acoustic feature of state \( {\text{j}} \). (Extracted from V)
- \( {\text{x}}_{l}: \) :
-
l-th acoustic feature vector, \( {\text{x}}_{l}\,\mathop{=}\limits^{{\rm def}}\, \left[ {{\text{x}}_{l1} , \ldots ,{\text{x}}_{{l{\mathcal{J}}}} } \right]^{T} . \)
- X::
-
All acoustic features, \( {\text{X}}\,\mathop{=}\limits^{{\rm def}}\,\left[ {{\text{x}}_{1} , \ldots ,{\text{x}}_{\text{L}} } \right] . \)
- \( {\text{c}}_{\text{ji}}: \) :
-
i-th binary linguistic feature of state j.
- \( {\text{c}}_{\text{j}}: \) :
-
Linguistic feature vector of state j, \( {\text{c}}_{\text{j}}\,\mathop{=}\limits^{{\rm def}}\,\left[ {{\text{c}}_{{{\text{j}}1}} , \ldots ,{\text{c}}_{\text{jI}} } \right]^{T} . \)
- C::
-
All linguistic features, \( {\text{C}}\,\mathop{=}\limits^{{\rm def}}\,\left[ {{\text{c}}_{1} , \ldots ,{\text{c}}_{{\mathcal{J}}} } \right] . \)
3.1 GCRF Graphical Structure
Factor graph [8] of the proposed GCRF (with order one) is depicted in Fig. 1. As it is obvious in the figure, GCRF is a set of L linear chain CRF [8] (with order one) which are independent when C is given. Each rectangular node \( \Psi _{\text{lj}} \) represents a potential function describing the effect of a maximal clique \( ( {\text{x}}_{\text{lj}} ,\,{\text{x}}_{{{\text{l}}({\text{j}} - 1)}} ,{\text{c}}_{\text{j}} ) \) in the random field distribution. This figure can be extended to higher order linear chain CRFs. As a result, if GCRF extends with order o, \( \Psi _{\text{lj}} \). becomes a function of \( ( {\text{x}}_{\text{lj}} , \ldots ,{\text{x}}_{{{\text{l}}({\text{j}} - {\text{o}})}} ,{\text{c}}_{\text{j}} ) \).

Factor graph of the first order GCRF.
3.2 GCRF Distribution
Having described the graphical model, this subsection investigates the probability distribution provided by GCRF. Markov property of MRFs implies the following equality.
where \( \uptheta \) is the set of all model parameters. This paper assumes that the partition function, \( \Psi _{\text{lj}} \), is formulated by Eq. 4 which is a Gaussian function with parameters \( {\text{H}}_{\text{lji}} \) and \( {\text{u}}_{\text{lji}} \).
In this equation, \( {\text{H}}_{\text{lji}} \) has to be a symmetric and positive definite matrix. If \( {\text{H}}_{\text{lji}} \) is not restricted to a positive definite matrix, the distribution may be realized by a number greater than one. Thus, considering positive definite condition seems to be necessary. Moreover, in GCRF with order o, \( {\text{H}}_{\text{lij}} \) and \( {\text{u}}_{\text{lij}} \) contain only \( \left( {{\text{o}} + 1} \right) \times \left( {{\text{o}} + 1} \right) \) and \( \left( {{\text{o}} + 1} \right) \) nonzero elements respectively. The overall form of model parameters is shown as follows.
By considering defined potential function and according to the fundamental theorem of Hammersley and Cliffort the final expression for \( {\text{P}}\left( {{\text{x}}_{\text{l}} | {\text{C}};\uptheta_{\text{l}} } \right) \) is given by
where \( {\text{H}}_{\text{l}} = \sum_{{{\text{j}} = 1}}^{{\mathcal{J}}} \sum_{{{\text{i}} = 1}}^{\text{I}} {\text{c}}_{\text{ji}} {\text{H}}_{\text{lji}} \) and \( {\text{u}}_{\text{l}} = \sum_{{{\text{j}} = 1}}^{{\mathcal{J}}} \sum_{{{\text{i}} = 1}}^{\text{I}} {\text{c}}_{\text{ji}} {\text{u}}_{\text{lji}} \).
\( {\text{Z}}_{\text{l}} \) is the partition function and is computed by Eq. 2. Fortunately, for Gaussian distribution of Eq. 4 there is a closed formula for the partition function as:
A marvelous point is that conventional CD-HSMM can be considered as a type of GCRF with order zero and mutually exclusive contextual features.
4 Speech Synthesis Based on GCRF
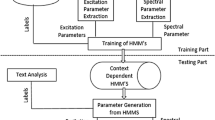
Figure 2 shows an overview of the proposed GCRF-based speech synthesis system. All blocks in the figure are identical to classical SPSS [1], except the three further blocks added with a different color. In the training part, acoustic sufficient statistics or features (X) are extracted according to both speech parameters (V) and state boundaries \( ({\mathcal{T}} ) \). State boundaries are latent and the added Viterbi block is employed to train them in an unsupervised manner. It should be noted that only sufficient statistics are modeled in the training phase; therefore synthesis phase has to generate them first. After generating features, speech parameters and speech signal are successively synthesized.

An overview of the proposed architecture.
4.1 Estimation of Model Parameters
In this section, we discuss how to train model parameters \( \uptheta \). We are given a set of T iid training data\( \left\{ {{\text{X}}^{\text{t}} ,{\text{C}}^{\text{t}} } \right\}_{{{\text{t}} = 1}}^{\text{T}} \), the goal is to find the best set of parameters, \( \widehat{\uptheta} \), which maximizes the conditional log likelihood:
The problem is that, acoustic feature Matrix \( {\text{X}}^{\text{t}} , \) wholly depends on the state boundaries which are latent. Hence, it is impossible to compute \( {\text{L(}}\uptheta ) \). A correct solution for this problem that converges to the Maximum Likelihood (ML)-estimate is given by the Expectation Maximization (EM) algorithm; however, EM is computationally expensive. Another commonly used method which is computationally efficient and works well in practice is to compute first \( {\text{X}}^{\text{t}} \) and then \( {\text{L(}}\uptheta ) \) on the Viterbi path. Appling this approach and substituting \( {\text{P}}\left( {{\text{X}}^{\text{t}} | {\text{C}}^{\text{t}} ;\uptheta} \right) \) with Eq. 6 gives
In general, this function cannot be maximized in closed form, therefore numerical optimization is used. The partial derivatives of \( {\text{L(}}\uptheta ) \) are calculated as follows.

where o denotes the order of model, \( { \star } \) denotes element-by-element product operator and  is a \( { \mathcal{J}} \) -by-\( {\mathcal{J}} \) (\( {\mathcal{J}} \)) Boolean matrix (vector) defined by an indicator function I as:
is a \( { \mathcal{J}} \) -by-\( {\mathcal{J}} \) (\( {\mathcal{J}} \)) Boolean matrix (vector) defined by an indicator function I as:


A common solution of this optimization problem is to take entire training samples into account and update model parameters using an optimization algorithm such as BFGS. Unfortunately, this in turn leads to large computational complexity. This paper proposes the application of stochastic gradient ascent [9] method which is faster than above-mentioned algorithm by orders of magnitude. This method has proven to be effective [9]. Following equations express its updating rule:
A variable step size algorithm described by [10] is utilized in our experiments.
4.2 Viterbi Algorithm for GCRF
Given a sequence of acoustic parameters (V), sentence contextual features (C) and a trained GCRF parameters (θ), this section presents an algorithm to find the most likely state boundaries \( ({\hat{\mathcal{T}}} ) \). Thus the aim is to estimate \( {\hat{\mathcal{T}}} \) such that
From Eq. 6 we have
where \( \phi_{\text{j}} \left( {{\mathcal{T}},{\text{V}},{\text{C}},\uptheta} \right)\,\mathop{=}\limits^{{\rm def}}\,\mathop \sum \nolimits_{{{\text{l}} = 1}}^{\text{L}} \mathop \sum \nolimits_{{{\text{i}} = 1}}^{\text{I}} \left( {{\text{x}}_{\text{lj}}^{\text{T}} {\text{H}}_{\text{lij}} {\text{x}}_{\text{lj}} + {\text{b}}_{\text{lij}}^{\text{T}} {\text{x}}_{\text{lj}} } \right){\text{c}}_{\text{ji}} . \)
Let  be the j-th state boundary (j-th element of \( { \mathcal{T}} \)), then for a GCRF with order o, \( \phi_{\text{j}} \) becomes a function of
be the j-th state boundary (j-th element of \( { \mathcal{T}} \)), then for a GCRF with order o, \( \phi_{\text{j}} \) becomes a function of  instead of entire elements of \( { \mathcal{T}} \). This fact gives us an ability to exploit dynamic programming for performing a complete search on \( { \mathcal{T}} \). Inspired by the other Viterbi algorithms, we need to define an auxiliary variable \( \updelta_{\text{j}} \).
instead of entire elements of \( { \mathcal{T}} \). This fact gives us an ability to exploit dynamic programming for performing a complete search on \( { \mathcal{T}} \). Inspired by the other Viterbi algorithms, we need to define an auxiliary variable \( \updelta_{\text{j}} \).

\( \updelta_{\text{j}} \) can be calculated from \( \updelta_{{{\text{j}} - 1}} \) by following recursion.

Using this recursion, it is straightforward to obtain Viterbi algorithm.
4.3 Parameter Generation Algorithm
This section, for a given GCRF, derives an algorithm to estimate the best synthesized speech parameters \( ({\hat{V}} ) \) by maximizing the likelihood criteria, i.e.
The synthesis part needs to respond quickly, however, solving this problem directly is challenging. Hence, the algorithm derived from Eq. 24 is not practical.
A two-step algorithm is proposed here which approximates \( {\hat{\text{V}}} \) fast.
-
Step 1. For a given \( \uptheta \), compute the ML-estimate of X:
$$ {\hat{\text{X}}}\,\mathop{=}\limits^{{\rm def}}\,{\text{argmax}}_{{ {\text{X}}}} {\text{P}}\left( {{\text{X|}}\uptheta} \right). $$(25) -
Step 2. For a given \( {\text{X}} \), compute the ML-estimate of V:
$$ {\hat{\text{V}}}\,\mathop{=}\limits^{{\rm def}} \,{\text{argmax}}_{{ {\text{V}}}} {\text{P}}\left( {\text{V|X}} \right). $$(26)
The first step is simply obtained by considering the distribution discussed in Sect. 3. Since different acoustic features are statistically independent (given in Eq. 3), the algorithm can generate features independently, i.e.
Optimizing the Gaussian distribution \( {\text{P}}\left( {{\text{x}}_{\text{l}} | {\text{C}};\uptheta_{\text{l}} } \right) \), expressed by Eq. 6, results in the set of linear equations below:
\( {\text{H}}^{\text{l}} \) is symmetric and positive definite, so Eq. 28 can be efficiently solved using the Cholesky decomposition.
Second step depends heavily on the selected acoustic features. For the set of acoustic features extracted in our system, Tokoda et al. [11] algorithm was used in this step.
5 Experiments
5.1 Experimental Conditions
To evaluate the proposed system, a Persian speech database [12] consisting of 1000 utterances with an average length of 8 s was employed. Experiments were conducted on a fixed test set of 200 utterances and 5 different training sets with remaining 50, 100, 200, 400 and 800 utterances. It should be noted that the average length of each utterance is about 8 s. Speech parameters including mel-cepstral coefficients, bandpass aperiodicity and fundamental frequency were extracted by STRAIGHT [13]. Sample mean and variance of each static and dynamic parameter, in addition to the voicing probability and duration are computed as the acoustic state features. For contextual state features a set of 150 well designed binary questions are employed. Following subsections evaluate the proposed method in contrast to the HSMM-based technique.
5.2 Objective Evaluation
As Fig. 3 shows, three objective measures were calculated to evaluate the proposed and HSMM-based systems, namely the average mel-cepstral distortion (expressed in dB) [14], the Root-Mean-Square (RMS) error of fundamental frequency logarithm (expressed in cent) and the RMS error of phoneme durations (expressed in terms of number of frames). Computing the first and second measures needs an assumption about state boundaries that was estimated here using the Viterbi algorithm. Since F0 value is not observed in unvoiced regions, only voiced frames of speech were taken into account for the second measure.

Objective evaluation of HSMM-based and proposed speech synthesis systems. (Left) Mel-cepstral distance [dB]; (Middle) RMSE of log F0 [cent]; (Right) RMSE of phoneme duration [frame].
From Fig. 3, it is noticeable that GCRF always outperforms HSMM in generating mel-cepstral and duration parameters, but HSMM is superior in synthesizing fundamental frequency when the number of training data is larger than 200 utterances. This drawback is a result of weak estimation of F0 parameters during the training process. Table 1 compares the accuracy of voiced/unvoiced detection in proposed system with its counterpart in HSMM-based synthesis.
5.3 Subjective Evaluation
We conducted preference score measure to compare the proposed and HSMM-based systems subjectively. 20 subjects were presented with 10 randomly chosen pairs of synthesized speech from the two models and then asked for their preference.
Figure 4 shows the average preference score. The result confirms that the synthetic speech generated by proposed system has been favorable when training data are limited.

Subjective evaluation of HSMM and proposed systems using preference score.
6 Conclusion
This paper improves HSMM-based synthesis in the following ways:
-
1.
The independence assumption of states distribution in HTS is removed.
-
2.
In contrast to HMM, the proposed model does not limit its potential functions to be a probability distribution.
-
3.
CD-HMM uses decision-tree-based context clustering that does not provide efficient generalization in limited training data, because each speech parameter vector is associated in modeling of only one context cluster. In contrast, our method contributes each training vector in many clusters to offer an efficient generalization.
Despite the advantages, which made our system to outperform in small training data, a drawback such as difficult training procedure is noticed in large databases.
References
Black, A.W., Zen, H., Tokuda, K.: Statistical Parametric Speech Synthesis. In: ICASSP’2007, Honolulu, Hawai’i, USA, pp. IV-1229–IV-1232 (2007)
Zen, H., Tokuda, K., Black, A.W.: Statistical parametric speech synthesis. Speech Commun. Elsevier 51(11), 1039–1064 (2009)
Zen, H., Tokuda, K., Masuko, T., Kobayashi, T., Kitamura, T.: Hidden semi-markov model based speech synthesis. In: Interspeech’2004, Jeju Island, Korea, pp. 1393–1396, October 4–8 2004
Zen, H., Tokuda, K., Kitamura, T.: An introduction of trajectory model into hmm-based speech synthesis. In: SSW5, pp. 191–196. Carnegie Mellon University, June 2004
Tokuda, K., Masuko, T., Miyazaki, N., Kobayashi, T.: Multi-space probability distribution HMM. IEICE Trans. Inf. Syst. E85-D(3), 455–464 (2002)
Lafferty, J., McCallum, A., Pereira, F.: Conditional random fields: probabilistic models for segmenting and labeling sequence data. In: Proceedings of the Eighteenth International Conference on Machine Learning, pp. 282–289 (2001)
Grimmett, G.R.: A theorem about random fields. Bull. Lond. Math. Soc. 5, 81–84 (1973)
Sutton, C., McCallum, A.: An introduction to conditional random fields for relational learning. In: Getoor, L., Taskar, B. (eds.) Introduction to statistical Relational Learning. MIT Press, Cambridge (2006)
Gardner, W.A.: Learning characteristics of stochastic-gradient-descent algorithms: a general study, analysis and critique. Sig. Process. 6(2), 113–133 (1984)
Vrahatis, M.N., Androulakis, G.S., Lambrinos, J.N., Magoulas, G.D.: A class of gradient unconstrained minimization algorithms with adaptive stepsize. J. Comput. Appl. Math. 114(2), 367–386 (2000)
Tokuda, K., Yoshimura, T., Masuko, T., Kobayashi, T., Kitamura, T.: Speech parameter generation algorithms for HMM-based speech synthesis. In: ICASSP’2000, vol. 3, Istanbul, pp. 1315–1318, June 2000
Bijankhan, M., Sheikhzadegan, J., Roohani, M.R., Samareh, Y., Lucas, C., Tebiani, M.: The speech database of farsi spoken language. In: Proceedings of 5th Australian International Conference on Speech Science and Technology (SST’94), pp. 826–831 (1994)
Kawahara, H., Masuda-Katsuse, I., de Cheveigné, A.: Restructuring speech representations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequency-based F0 extraction: possible role of a repetitive structure in sounds. Speech Commun. 27(3–4), 187–207 (1999)
Kubichek, R.F.: Mel-cepstral distance measure for objective speech quality assessment. In: Proceedings of the IEEE Pacific Rim Conference on Communications, Computers, and Signal Processing, pp. 125–128 (1993)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this paper
Cite this paper
Khorram, S., Bahmaninezhad, F., Sameti, H. (2014). Speech Synthesis Based on Gaussian Conditional Random Fields. In: Movaghar, A., Jamzad, M., Asadi, H. (eds) Artificial Intelligence and Signal Processing. AISP 2013. Communications in Computer and Information Science, vol 427. Springer, Cham. https://doi.org/10.1007/978-3-319-10849-0_19
Download citation
DOI: https://doi.org/10.1007/978-3-319-10849-0_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-10848-3
Online ISBN: 978-3-319-10849-0
eBook Packages: Computer ScienceComputer Science (R0)