
Abstract
Health data geo-coded with residential coordinates are being used to investigate the relationship between ambient air quality and pediatric emergency department visits in the State of Georgia over the time period 2000–2010. Two types of ambient air quality data – observed concentrations from ambient monitors and predicted concentrations from a chemical transport model (CMAQ) – are being fused to provide spatially resolved daily metrics of five air pollutant gases (CO, NO2, NOx, SO2 and O3) and seven airborne particulate matter measures (PM10, PM2.5, and PM2.5 constituents SO4 2−, NO3 −, NH4 +, EC, OC). The observational data provide reliable temporal trends at and near monitors, but limited spatial information due to the sparse monitoring network; CMAQ data, on the other hand, provide rich spatial information but less reliable temporal information. Four data fusion techniques were applied to provide daily spatial fields of ambient air pollutant concentrations, with data withholding used to evaluate model performance. Two of the data fusion methods were combined to provide results that minimized bias and maximized correlation over time and space with withheld data. Results vary widely across pollutants. These results provide health researchers with complete temporal and spatial air pollutant fields, as well as with temporal and spatial error estimate fields that can be incorporated into health risk models. Future work will apply these methods to five cities for use in ongoing air pollution health studies and to examine strategies for incorporating land use regression variables for spatial downscaling of data fusion results.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others
Keywords
- Data Fusion
- Chemical Transport Model
- Evaluate Model Performance
- Data Fusion Method
- Data Fusion Technique
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
49.1 Introduction
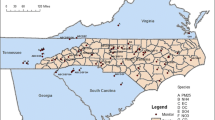
Large population studies of human health effects associated with air pollution can take advantage of both temporal and spatial variation in ambient air quality levels when such estimates are available. As a part of the Southeastern Center for Air Pollution and Epidemiology (SCAPE), we are examining relationships of health outcomes with ambient air pollution resolved temporally to a daily level and resolved spatially to a 4 km and smaller scale. Presented here is an approach for estimating daily spatial fields of air pollution in the State of Georgia for use in an investigation of the relationship with pediatric emergency department visits, geo-coded with residential coordinates, that builds on previous work [2].
49.2 Methods
Observed concentrations of five air pollutant gases (CO, NO2, NOx, SO2 and O3) and seven airborne particulate matter measures (PM10, PM2.5, and PM2.5 constituents SO4 2−, NO3 −, NH4 +, EC, OC) were obtained from EPA’s Air Quality System (AQS), the Southeastern Aerosol Research Characterization (SEARCH) [3], and the Assessment of the Spatial Aerosol Composition in Atlanta (ASACA) [1] networks for Georgia for the 2000–2010 time period. The number of monitors and daily metrics calculated are listed in Table 49.1. Locations of monitors are shown in Fig. 49.1. The observational data provide reliable temporal trends at and near monitors [6], but limited spatial information due to the sparse monitoring network. Predicted hourly concentrations from CMAQ were obtained for the Georgia domain at the 12 km scale for 2002–2008 [5] and at the 4 km scale for 2009–2010 [4]; daily metrics were computed from these datasets. The CMAQ data provide rich spatial information but less reliable temporal information. Four data fusion techniques are applied and evaluated for 2010. Two methods use regression models of observational and CMAQ annual mean data for scaling (Eq. 49.1). One of these methods involves daily kriging of the ratio of the observation (OBS) to its annual mean and then rescaling by the predicted annual mean (C* 1, Eq. 49.2). The second of these methods involves rescaling the CMAQ data (C* 2, Eq. 49.3). The other two methods involve kriging error on a multiplicative (C* 3, Eq. 49.4) and additive (C* 4, Eq. 49.5) basis. Data withholding was used to evaluate model performance. Two of the methods were then selected and combined to provide results that minimized bias and maximized correlation over time and space with withheld data.

Map of Georgia showing regions and major cities, major roadways, and locations of speciated PM2.5 and ozone monitors
49.3 Results
The four data fusion methods yield similar spatial fields (e.g. Fig. 49.2). However, the methods that involved daily kriging of error (Eqs. 49.4 and 49.5) were less stable, performing less well in terms of both bias and correlation for most pollutants. Therefore, the methods that involved using the annual mean model (Eq. 49.1) were selected. The first approach involving kriging daily observation ratios (OBS method) yields results with a spatial structure of CMAQ and perfectly correlated temporally with observations at monitor locations. As the distance from monitors increases, the Pearson correlation coefficient decreases (exponential correlogram model: R1 = eγD where D is a weighted distance to monitors). The second approach that involves rescaling CMAQ predictions (CMAQ method) yields results that have similar correlations with observations across monitors (average Pearson correlation coefficient of R2). Thus, the OBS method performs best near monitors and the CMAQ method performs best far from monitors.

Predicted 1-h max NO2 fields by four data fusion methods, 9/21/10
The OBS and CMAQ methods were combined to provide the best overall prediction. A correction was added to the CMAQ method prediction to correct for seasonal bias. The daily spatial fields generated by the OBS and CMAQ methods were averaged by weighting based on their temporal correlation coefficients (R1 and R2). Thus, at monitor locations the OBS data fusion method prediction was used and far from monitors the CMAQ data fusion method was used. Combined data fusion method results minimize bias and maximize temporal correlation over space. Results shown in Fig. 49.3 show the percent biases and temporal correlations in the CMAQ method predictions for the 2002–2008 time period using 12 km CMAQ data. When combined with OBS method predictions, temporal correlations increase near monitors.

Percent bias (left) and Pearson correlation coefficient (right) for CMAQ method predictions, 2002–2008. Bars represent averages and error bars represent standard deviations across all monitors. The number of monitors for each pollutant is given in parentheses
Results vary widely across pollutants. Estimates of primary pollutants largely from mobile sources (i.e. CO, NO2, NOx, and EC) rely largely on CMAQ data because they are spatially heterogeneous and have low spatial autocorrelation, whereas estimates of largely secondary pollutants (i.e. O3, SO4 2−, NO3 −, NH4 +) and pollutants of mixed origin (PM10, PM2.5 and OC) rely to a greater extent on observations because they are spatially more homogeneous and have high spatial autocorrelation. SO2, largely from coal combustion, is the most difficult pollutant to estimate due to the inability of monitors to capture and CMAQ to predict accurately point source plume dispersion.
These results provide health researchers with complete temporal and spatial air pollutant fields, as well as with temporal and spatial error estimate fields that can be incorporated into health risk models. Future work will apply these methods to five cities for use in ongoing air pollution health studies and to examine strategies for incorporating land use regression variables for spatial downscaling of data fusion results.
References
Butler AJ, Andrew MS, Russell AG (2003) Daily sampling of PM2.5 in Atlanta: results of the first year of the assessment of spatial aerosol composition in Atlanta study. J Geophys Res 108(D7):8415
Darrow LA, Klein M, Flanders WD, Waller LA, Correa A, Marcus M, Mulholland JA, Russell AG, Tolbert PE (2009) Ambient air pollution and preterm birth: a time-series analysis. Epidemiology 20(5):689–698
Hansen DA, Edgerton ES, Hartsell BE, Jansen JJ, Kandasamy N, Hidy GM, Blanchard CL (2003) The southeastern aerosol research and characterization study: Part 1 – overview. J Air Waste Manage Assoc 53(12):1460–1471
Hu Y, Chang M, Russell A, Odman M (2010) Using synoptic classification to evaluate an operational air quality forecasting system in Atlanta. Atmos Pollut Res 1:280–287
PHASE (2013) Air quality data for the CDC national environmental public health tracking network. URL http://www.epa.gov/heasd/research/cdc.html. Accessed 2013
Wade KS, Mulholland JA, Marmur A, Russell AG, Hartsell B, Edgerton E, Klein M, Waller L, Peel JL, Tolbert PE (2006) Effects of instrument precision and spatial variability on the assessment of the temporal variation of ambient air pollution in Atlanta, Georgia. J Air Waste Manage Assoc 56(6):876–888
Acknowledgments
This publication was made possible by USEPA grant R834799. Its contents are solely the responsibility of the grantee and do not necessarily represent the official views of the USEPA. Further, USEPA does not endorse the purchase of any commercial products or services mentioned in the publication.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this paper
Cite this paper
Sororian, S.A. et al. (2014). Temporally and Spatially Resolved Air Pollution in Georgia Using Fused Ambient Monitor Data and Chemical Transport Model Results. In: Steyn, D., Mathur, R. (eds) Air Pollution Modeling and its Application XXIII. Springer Proceedings in Complexity. Springer, Cham. https://doi.org/10.1007/978-3-319-04379-1_49
Download citation
DOI: https://doi.org/10.1007/978-3-319-04379-1_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-04378-4
Online ISBN: 978-3-319-04379-1
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)