
Abstract
Cardiac magnetic resonance imaging (CMR) is a valuable non-invasive tool for identifying cardiovascular diseases. For instance, Cine MRI is the benchmark modality for assessing the cardiac function and anatomy. On the other hand, multi-contrast (T1 and T2) mapping has the potential to assess pathologies and abnormalities in the myocardium and interstitium. However, voluntary breath-holding and often arrhythmia, in combination with MRI’s slow imaging speed, can lead to motion artifacts, hindering real-time acquisition image quality. Although performing accelerated acquisitions can facilitate dynamic imaging, it induces aliasing, causing low reconstructed image quality in Cine MRI and inaccurate T1 and T2 mapping estimation. In this work, inspired by related work in accelerated MRI reconstruction, we present a deep learning-based method for accelerated cine and multi-contrast reconstruction in the context of dynamic cardiac imaging. We formulate the reconstruction problem as a least squares regularized optimization task, and employ vSHARP, a state-of-the-art Deep Learning-based inverse problem solver, which incorporates half-quadratic variable splitting and the alternating direction method of multipliers (ADMM) with neural networks. We treat the problem in two setups; a 2D reconstruction and a 2D dynamic reconstruction task, and employ 2D and 3D deep learning networks, respectively. Our method optimizes in both the image and k-space domains, allowing for high reconstruction fidelity. Although the target data is undersampled with a Cartesian equispaced scheme, we train our deep neural network using both Cartesian and simulated non-Cartesian undersampling schemes to enhance generalization of the model to unseen data, a key ingredient of our method. Furthermore, our model adopts a deep neural network to learn and refine the sensitivity maps of multi-coil k-space data. Lastly, our method is jointly trained on both, undersampled cine and multi-contrast data.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Accelerated Cardiac MRI
- Deep MRI Reconstruction
- Dynamic Cardiac MRI Reconstruction
- Cine Reconstruction
- T1-T2 Reconstruction
1 Introduction
Cardiac magnetic resonance (CMR) stands as a vital clinical tool for assessing cardiovascular diseases due to its non-invasive and radiation-free nature, enabling a comprehensive evaluation of cardiovascular aspects, such as structure, function, flow, perfusion, viability, tissue characterization, as well as the assessment of myocardial fibrosis and other pathologies [1,2,3]. Key CMR applications include cine MR imaging and T1/T2 mapping.
However, CMR faces inherent physical challenges, primarily the time consuming MRI acquisition process. The requirement for increased spatiotemporal resolution in cardiac imaging further amplifies this challenge. To mitigate prolonged scan times, accelerated MRI acquisitions are utilized by obtaining undersampled k-space data, though this approach violates the Nyquist-Shannon sampling criterion [4].
In the broader MRI domain, conventional techniques such as Parallel Imaging (PI) [5, 6] and Compressed Sensing (CS) [7, 8] have been employed to accelerate MRI data acquisition. These approaches leverage spatial sensitivity information from multiple receiver coil arrays and exploit the sparsity or compressibility of MRI data. However, these methods have limitations, such as noise amplification in PI, and assumptions of sparsity that may not hold for all MRI data in CS, whilst finding optimal parameters for CS methods might be computationally and time consuming.
In the last decade, Deep Learning (DL) has revolutionized MRI image reconstruction, exhibiting superior performance compared to traditional methods, especially in accelerated MRI reconstruction tasks [9]. DL-based algorithms can learn complex image representations directly from available datasets, enabling enhanced image reconstruction from undersampled k-space measurements, often in supervised learning [10,11,12,13], or self-supervised settings [14]. This advancement holds significant potential to impact CMR by elevating the image quality of reconstructed highly undersampled data while concurrently reducing breath-hold duration.
In this work, motivated by the need for reducing acquisition times and breath-hold durations further during CMR, we employ vSHARP [15] (variable Splitting Half-quadratic ADMM algorithm for Reconstruction of inverse-Problems), a DL-based inverse problem solver, previously applied on brain and prostate MR imaging exhibiting state-of-the-art performance. We particularize vSHARP for accelerated Cardiac MRI Reconstruction and introduce in Sect. 3.1 two variants by treating the problem at hand as a 2D reconstruction task (2D model) or as a 2D dynamic reconstruction task (3D model). Additionally, in Sect. 3.2 we propose various training techniques to boost model training and generalizability across unseen cardiac (cine and T1/T2) MRI data. In Sect. 5, we experimentally compare our two approaches, highlighting that our 2D dynamic implementation outperforms traditional 2D reconstruction and we further compare our models with current state-of-the-art approaches.
2 Theory and Problem Formulation
2.1 Accelerated MRI Reconstruction
Recovering a two-dimensional image \(\textbf{x}^{*}\in \mathbb {C}^{N}\) from undersampled multi-coil (assume \(N_c\) coils) k-space measurements \(\tilde{\textbf{y}}\in \mathbb {C}^{N\times N_{c}}\) can be formulated as a minimisation problem as follows:
where \(\mathcal {A}^{k}\) represents the forward or corruption operator per coil. It involves mapping the image to an individual coil image using a known sensitivity map \(\textbf{S}^{k}\), transforming it to the k-space domain via the Fast Fourier Transform (FFT) \(\mathcal {F}\), and undersampling with \(\textbf{U}\). The function \(\mathcal {R}: \mathbb {C}^{N} \rightarrow \mathbb R\) denotes a regularization functional, which is assumed to impose prior knowledge about the image.
In the context of cardiac magnetic resonance, acquisitions are typically dynamic and synchronized with electrocardiography (ECG)-derived cardiac cine. In dynamic acquisitions, multiple undersampled k-space data \(\tilde{\textbf{y}}\in \mathbb {C}^{N\times N_{c} \times N_{f}}\) are obtained at \(N_{f}\) time frames. Consequently, Eq. 1 is adapted as follows:
In dynamic acquisitions, it is often assumed that knowledge can be shared across time frames or that the motion pattern is known, thereby requiring the selection of an appropriate prior \(\mathcal {R}: \mathbb {C}^{N \times N_{f} } \rightarrow \mathbb R\) that incorporates this information [16].
3 Methods
3.1 Deep Learning Framework
Sensitivity Map Prediction. In conventional settings, sensitivity maps are estimated from the autocalibration signal (ACS) data, often incorporating a portion of the center of the k-space. Advanced techniques for refining these estimated sensitivities include ESPIRiT or GRAPPA [5, 17]. However, these approaches can impose computational constraints. To overcome the need for such computationally expensive algorithms, we employ a two-dimensional deep learning module, specifically a 2D U-Net [18]. This model takes ACS-estimated sensitivity maps as input and produces refined versions of them as output. The predicted sensitivity maps \(\left\{ \textbf{S}^{k} \right\} _{k=1}^{N_c}\) are used for downstream reconstruction tasks, and the sensitivity module is trained in an end-to-end manner along with the reconstruction model.
Reconstruction via ADMM Unrolled Optimization. Our approach utilizes vSHARP [15], a DL-based inverse problem solver, to address Eq. 1. vSHARP employs the half-quadratic variable splitting method [19] to transform the optimization problem in Eq. 1 by introducing an intermediate variable \(\textbf{w}\). It then unrolls the optimization process over T iterations using the alternating direction method of multipliers algorithm (ADMM) [20], as follows:
Our method incorporates U-Nets to replace the need for manually selecting a prior functional \(\mathcal {R}\) in Eq. 3a and learn the solution from data directly, namely the denoising step. Next, data consistency is enforced by solving Eq. 3b via an unrolled (differentiable) gradient descent scheme. Our approach initializes \(\textbf{w}^{(0)}\) and \(\textbf{x}^{(0)}\) using a zero-filled reconstruction with \(\tilde{\textbf{y}}\) and the predicted coil sensitivity maps: \(\textbf{w}^{(0)} = \textbf{x}^{(0)} := \sum _{k=1}^{N_c}{\textbf{S}^{k}}^{*} \mathcal {F}^{-1} (\tilde{\textbf{y}}^{k}) \). Additionally, a learned initializer, adapted from [13], is used to determine an initialization for the Lagrange Multipliers \(\textbf{m}^{(0)}\). For dynamic reconstruction as in Eq. 2, Eq. 3 is replaced by:
3.2 Model Training Techniques
In this section, we outline the various additional techniques employed in our paper to enhance the performance of our models.
Joint Modality Training. During the training of our DL-based approach, we jointly trained it using all available data at our disposal (see Sect. 4.3). This approach served a dual purpose; Firstly, instead of training separate models for each modality, our joint modality training aimed to utilize a larger dataset promoting more effective learning and generalization. Moreover, by integrating cine and T1/T2-weighted MRI data, we aimed to harness the complementarity between these modalities. This approach enabled the model to exploit the shared features and correlations, potentially improving the reconstruction quality for both modalities.
Random k -space Cropping. To optimize computational efficiency during training, we utilized random cropping on the fully-sampled multi-coil k-space data. Since direct cropping of the k-space would be inappropriate, we first applied the inverse Fast Fourier Transform (FFT) to reconstruct it into fully-sampled multi-coil images. Subsequently, random cropping was performed on this reconstructed image, and the resulting cropped image was transformed back to the k-space domain (via FFT). The k-space data was then undersampled and used as input to our model. This approach not only offered computational benefits but also allowed our model to gain exposure to different parts of the reconstructed data, including background noise and the regions of interest, without compromising overall reconstruction quality as compared to using non-cropped data. Figure 1 illustrates examples of cropped images before the transformation back to the k-space domain. It’s important to note that for dynamic data, the same cropping process was applied to all time frames.

Randomly cropped (in the image domain) examples of cine and T1/T2-weighted MRI images from the dataset. These images are then transformed to the k-space domain, followed by retrospective undersampling, and are subsequently utilized for training.
Multi-scheme Undersampling. Undersampling for the target (validation) data comprised Cartesian rectilinear equispaced undersampling masks, with 24 fully-sampled ACS (central) lines, and with acceleration factors of \(R=\) 4, 8 and 10. Inspired by previous work [21], which demonstrated enhanced model generalizability in reconstructing Cartesian rectilinear data, we employed a multi-scheme undersampling setup during training. Alongside the provided undersampling pattern, we used the following undersampling schemes: Equispaced and Random Cartesian rectilinear, Gaussian 2D Cartesian, and pseudo-Radial and pseudo-Spiral schemes. These undersampling schemes are visualized in Fig. 2. Note that for dynamic data, the same undersampling scheme was applied on all time frames.

Undersampling Schemes during training.
Dual Domain Loss. To train our models we designed a dual-domain loss:
where \(\mathcal {L}_{\boldsymbol{\phi }}^{img}\) and \( \mathcal {L}_{\boldsymbol{\phi }}^{freq}\) represent losses computed in the image and frequency domain, respectively.
Image Domain Loss. The image domain loss, \(\mathcal {L}_{\boldsymbol{\phi }}^{img}\), is computed between the ground truth RSS image \(\textbf{x}\) and the magnitude of the model-predicted image \(\hat{\textbf{x}}_{\boldsymbol{\phi }}\). This loss comprises several components:
which are defined as follows:
In Eq. 7, SSIM denotes the Structural Similarity Index Measure, computed over W windows, each of size \(7\times 7\) pixels extracted from images \(\textbf{u}\) and \(\textbf{v}\). It is defined as:
Here, \(\mu _{\textbf{u}_i}\), \(\mu _{\textbf{v}_i}\), \(\sigma _{\textbf{u}_i}\) and \(\sigma _{\textbf{v}_i}\) represent the means and standard deviations of each window, while \(\sigma _{\textbf{u}_i\textbf{v}_i}\) signified the covariance between \(\textbf{u}_i\) and \(\textbf{v}_i\). HFEN\(_1\) represents the High-Frequency Error Norm, and is defined as follows:
where \(\text {G}\) denotes a \(15\times 15\) Laplacian of Gaussian filter with a standard deviation of 2.5.
SSIM and HFEN are computed per single 2D slice/time frame. For dynamic reconstruction experiments, we also incorporated \(\lambda _{\text {SSIM3D}} \mathcal {L}_{\text {SSIM3D}}\), which computes the SSIM metric for volumes using windows of voxel-size \(7\times 7 \times 7\).
Frequency Domain Loss. The frequency domain loss, \(\mathcal {L}_{\boldsymbol{\phi }}^{freq}\), was computed between the ground truth multi-coil k-space \(\textbf{y}\) and the k-space transformation of the model predicted image \(\hat{\textbf{y}}_{\boldsymbol{\phi }}\):
The choice of the weighting factors \(\lambda _{\text {SSIM}}\), \(\lambda _{\text {SSIM3D}}\), \(\lambda _{1}\), \(\lambda _{\text {HFEN}_{1}}\), \(\lambda _{\text {NMAE}} \ge 0\) are hyperparameters that determine the influence of each loss component in the overall optimization process.
4 Experimental Setup
We conducted two sets of experiments, addressing the reconstruction task from two perspectives: a 2D reconstruction problem and a 2D dynamic reconstruction problem involving spatial dimensions and time.
4.1 2D Reconstruction
In this setup, our goal was to solve Eq. 3. We utilized 2D U-Nets with four scales as denoisers, each featuring 32 filters in the initial scale. The optimization process involved 16 steps (T = 16). Data consistency in Eq. 3b was ensured through 14 gradient descent iterations. For the sensitivity model, we employed a 2D U-Net with four scales and 32 filters for the first scale. This configuration focused on reconstructing 2D images. The input consisted of undersampled multi-coil k-space data from single slices or frames, and the output comprised 2D images.
4.2 2D Dynamic Reconstruction
In this configuration, we approached the reconstruction challenge dynamically, utilizing the formulation presented in Eq. 4. Our model took as input a sequential series of time frames featuring 2D undersampled multi-coil k-space data. Our objective was to generate a corresponding sequential series of time-frame images as the output. In contrast to the previous setup, we employed 3D U-Nets, incorporating four scales and 32 filters in the initial scale. However, to accommodate GPU memory constraints, we limited the optimization steps to T = 10 and conducted 8 gradient descent iterations for data consistency. Similarly to the 2D reconstruction setup, for the sensitivity model we utilized a 2D U-Net with four scales and 32 filters in the initial scale.
4.3 Dataset
We conducted our experiments using the CMRxRecon dataset [22], containing 4D multi-coil Cine and multi-contrast k-space data acquired on a 3T MRI scanner with protocols outlined in [23]. The Cine MRI data included short-axis (SAX) and long-axis (LAX) views, while the multi-contrast data encompassed T1 and T2-weighted MRI data. For training, we had access to a total of 203 cine and 240 multi-contrast 4D volumes of fully-sampled k-spaces. The validation dataset comprised 111 cine and 118 multi-contrast 4D volumes of undersampled k-spaces at acceleration factors of 4, 8, and 10.
4.4 Training and Optimization Details
Our models were implemented and optimized using PyTorch [24]. The Deep Image Reconstruction Toolkit (DIRECT) [25] facilitated our pipeline tools. We employed Adam as the model parameter optimizer, with \( \epsilon =10^{-8}\) and \(\left( \beta _1,\beta _2\right) = \left( 0.9, 0.999 \right) \). Training was conducted on four NVIDIA A100 80GB GPUs with a batch size of 1 and 2 on each GPU, for dynamic and non-dynamic tasks, respectively.
For both experimental setups, the loss computation used these weighting parameters: \(\lambda _{\text {SSIM}} \, = \, \lambda _{1} \, = \, \lambda _{\text {HFEN}_{1}} \, = \, 1.0\), and \(\lambda _{\text {NMAE}} \, = \, 3.0\). For 2D dynamic reconstruction (Sect. 4.2), we employed both versions of the SSIM loss, computed per 2D slice and across the entire sequence, and we set \(\lambda _{\text {SSIM3D}} \, = \, 1.0\).
4.5 Comparisons
To evaluate our proposed methods, we compared them against two state-of-the-art 2D MRI reconstruction approaches, the Recurrent Variational Network (RecurrentVarNet) [13], wining method in the MultiCoil MRI Reconstruction Challenge [10] and the End-to-end Variational Network (E2EVarNet), one of the top-performing solutions in the fastMRI challenge [12]. Both approaches were trained using the same settings and techniques as used for our proposed methods.
4.6 Evaluation Metrics
Metrics used for evaluation were the structural similarity index measure (SSIM), the normalized mean-squared-error (NMSE), and the peak signal-to-noise ratio (PSNR).
5 Results
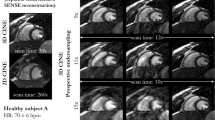
In Fig. 3 we present sample reconstructions and in Table 1 are presented the reconstruction evaluation results on the validation dataset, from both of our experimental setups. Additionally, we include results from the two methods employed for comparison: the RecurrentVarNet and the E2EVarNet. We can observe that both, 2D reconstruction and 2D dynamic reconstruction with vSHARP, yielded superior results in terms of quantitative metrics, surpassing both the RecurrentVarNet and the E2EVarNet. However, the 2D dynamic reconstruction setup outperforms the 2D reconstruction for both Cine and Multi-Contrast tasks.
Additionally, in Table 2, we present the time required for volume reconstruction in seconds across the two experimental setups detailed in this work. From Table 2 is evident that in overall, the 2D dynamic reconstruction surpasses the 2D reconstruction in both Cine and Multi-Contrast scenarios.

Sample reconstructions from the 10\(\times \) undersampled validation set.
6 Conclusion and Discussion
In this work we employed the variable Splitting Half-quadratic ADMM algorithm for Reconstruction of inverse-Problems (vSHARP) network, a state-of-the-art DL-based method, to the task of reconstructing undersampled Cardiac MRI data. We adapted vSHARP under two settings, one that considers the reconstruction problem as a 2D reconstruction task, i.e., each image at a specific time frame is treated individually, and one that it considers it as a dynamic task by operating on all time frame data within a given sequence.
Upon reviewing the Table 1, it becomes evident that both of our proposed methods have demonstrated superior performance compared to the alternatives. In addition, as anticipated and demonstrated in other works [26], our empirical findings confirm that 2D dynamic reconstruction outperforms the traditional 2D reconstruction. This improved performance of the 2D dynamic model can be attributed to its ability to leverage shared information across data points within the same time sequence.
Another aspect worth considering is that, in our dynamic setup, we employed all time frames per slice as input. This introduced GPU memory limitations, thereby constraining the parameter count in the reconstruction model (3D vSHARP). However, by utilizing only a subset of the time sequence data (e.g., 2–3 adjacent time frames), it would be feasible to construct a larger model.
Furthermore, Table 2 shows that the 2D dynamic reconstruction setup requires less inference time. This can be attributed to the fact that the 2D reconstruction process involves loading individual slices or time frames into memory and subsequently performing a forward pass through the model. This leads to relatively longer reconstruction times, as evidenced by the higher values for both the Cine and Multi-Contrast datasets. Conversely, in the 2D dynamic reconstruction setup, sequences of data are loaded collectively and processed in a single forward pass through the 2D dynamic model, resulting in significantly reduced reconstruction times. This observation could indeed play a pivotal role in selecting an appropriate reconstruction model for real-time clinical scenarios.
References
Arai, A.E.: The cardiac magnetic resonance (CMR) approach to assessing myocardial viability. J. Nucl. Cardiol. 18(6), 1095–1102 (2011). https://doi.org/10.1007/s12350-011-9441-5
Kim, P.K., et al.: Myocardial T1 and T2 mapping: techniques and clinical applications. Korean J. Radiol. 18(1), 113 (2017). https://doi.org/10.3348/kjr.2017.18.1.113
Larose, E., Rodés-Cabau, J., Delarochelliere, R., Barbeau, G., Noel, B., Bertrand, O.: Cardiovascular magnetic resonance for the clinical cardiologist. Can. J. Cardiol. 23, 84B–88B (2007). https://doi.org/10.1016/s0828-282x(07)71017-6
Shannon, C.: Communication in the presence of noise. Proc. IRE 37(1), 10–21 (1949)
Griswold, M.A., et al.: Generalized auto calibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. 47(6), 1202–1210 (2002). https://doi.org/10.1002/mrm.10171
Niendorf, T., Sodickson, D.K.: Parallel imaging in cardiovascular MRI: methods and applications. NMR in Biomed. 19(3), 325–341 (2006). https://doi.org/10.1002/nbm.1051
Geethanath, S., et al.: Compressed sensing MRI: A review. Crit. Rev. Biomed. Eng. 41(3), 183–204 (2013). https://doi.org/10.1615/critrevbiomedeng.2014008058
Kido, T., et al.: Compressed sensing real-time cine cardiovascular magnetic resonance: accurate assessment of left ventricular function in a single-breath-hold. J. Cardiovasc. Magn. Reson. 18(1), 50 (2016). https://doi.org/10.1186/s12968-016-0271-0
Pal, A., Rathi, Y.: A review and experimental evaluation of deep learning methods for MRI reconstruction (2022)
Beauferris, Y., et al.: Multi-coil MRI reconstruction challenge-assessing brain MRI reconstruction models and their generalizability to varying coil configurations. Front. Neurosci. 16, 919186 (2022). https://www.frontiersin.org/articles/10.3389/fnins.2022.919186
Küstner, T., et al.: CINENet: deep learning-based 3D cardiac CINE MRI reconstruction with multi-coil complex-valued 4D spatio-temporal convolutions. In: Scientific Reports, vol. 10, no. 1 (2020). https://doi.org/10.1038/s41598-020-70551-8
Sriram, A., et al.: End-to-end variational networks for accelerated MRI reconstruction. In: Martel, A.L., et al. (eds.) MICCAI 2020. LNCS, vol. 12262, pp. 64–73. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-59713-9_7
Yiasemis, G., Sonke, J.-J., Sánchez, C., Teuwen, J.: Recurrent variational network: a deep learning inverse problem solver applied to the task of accelerated MRI reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 732–741 (2022)
Hamilton, J.I.: A self-supervised deep learning reconstruction for shortening the breathhold and acquisition window in cardiac magnetic resonance fingerprinting. Front. Cardiovasc. Med. 9, 928546 (2022). https://doi.org/10.3389/fcvm.2022.928546
Yiasemis, G., Moriakov, N., Sonke, J.-J., Teuwen, J.: vSHARP: variable splitting half-quadratic admm algorithm for reconstruction of inverse-problems. arXiv.org (2023). arXiv:2309.09954 [eess.IV], https://doi.org/10.48550/arXiv.2309.09954
Ye, J.C.: Compressed sensing MRI: a review from signal processing perspective. BMC Biomed. Eng. 1(1), 8 (2019). https://doi.org/10.1186/s42490-019-0006-z
Uecker, M., et al.: ESPIRiT-an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magn. Reson. Med. 71(3), 990–1001, (2013). https://doi.org/10.1002/mrm.24751
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Li, R., Luo, L., Zhang, Y.: Convolutional neural network combined with half-quadratic splitting method for image restoration. J. Sens. 2020, 1–12 (2020). https://doi.org/10.1155/2020/8813413
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J., et al.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 3(1), 1–122 (2011)
Yiasemis, G., Sánchez, C.I., Sonke, J.-J., Teuwen, J.: On retrospective k-space subsampling schemes for deep MRI reconstruction. Mag. Reson. Imaging S0730725X23002199 (2024). https://doi.org/10.1016/j.mri.2023.12.012
Wang, C., et al.: CMR x Recon: An open cardiac MRI dataset for the competition of accelerated image reconstruction (2023)
Wang, C., et al.: Recommendation for cardiac magnetic resonance imaging-based phenotypic study: imaging part. Phenomics 1(4), 151–170 (2021). https://doi.org/10.1007/s43657-021-00018-x
Paszke, A., et al.: Automatic differentiation in pytorch (2017)
Yiasemis, G., Moriakov, N., Karkalousos, D., Caan, M., Teuwen, J.: Direct: deep image reconstruction toolkit. J. Open Source Softw. 7(73), 4278 (2022). https://doi.org/10.21105/joss.04278
Zhang, C., Caan, M.W., Navest, R., Teuwen, J., Sonke, J.-J.: Radial-rim: accelerated radial 4D MRI using the recurrent inference machine. In: Proceedings of International Society for Magnetic Resonance in Medicine, vol. 31 (2023)
Acknowledgements
This work was funded by an institutional grant from the Dutch Cancer Society and the Dutch Ministry of Health, Welfare and Sport.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Yiasemis, G., Moriakov, N., Sonke, JJ., Teuwen, J. (2024). Deep Cardiac MRI Reconstruction with ADMM. In: Camara, O., et al. Statistical Atlases and Computational Models of the Heart. Regular and CMRxRecon Challenge Papers. STACOM 2023. Lecture Notes in Computer Science, vol 14507. Springer, Cham. https://doi.org/10.1007/978-3-031-52448-6_45
Download citation
DOI: https://doi.org/10.1007/978-3-031-52448-6_45
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-52447-9
Online ISBN: 978-3-031-52448-6
eBook Packages: Computer ScienceComputer Science (R0)