
Abstract
The Affective Computing community commonly uses dimensional models of emotions to rate conscious emotional perceptions in emotion elicitation tasks. Although several structures of affect have been introduced in the literature, the valence and arousal dimensions have had the most impact. In this study, we compared Watson and Tellegen’s Positive-Negative Affect model to Russell’s Valence-Arousal plane. We used the publicly available Continuously Annotated Signals of Emotions (CASE) dataset, which provides ratings along the valence and arousal dimensions continuously annotated while watching video clips eliciting four emotions: scariness, amusement, relaxation, and boredom. We derived the Positive and Negative Affect time series from the valence and arousal time series through a 45° rotation of Russell’s plane. We calculated the median values and Fuzzy Entropy for each time series and video clip to investigate their linear and nonlinear dynamics. Our analysis showed that Watson and Tellegen’s model had fewer statistically significant differences between emotions than Russell’s model when considering the median values. However, when investigating the dynamic evolution of perceptions, the Positive Affect dimension showed the highest discriminative power, identifying the time series traced during the boring stimuli as the most regular and statistically different from all others. Our findings suggest that further acquisitions of continuously annotated ratings in several experimental settings, and the investigation of the nonlinear coupling between more dimensions, could significantly improve real-time emotion recognition.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Affective computing
- Continuously annotated ratings
- Emotion discrimination
- Valence-arousal plane
- Positive-negative affect model
- Fuzzy entropy
- Nonlinear time series analysis
1 Introduction
In the Affective Computing field, emotion elicitation and recognition are topics strictly influenced by the complexity of the definition of consciously experienced affective states [24]. According to the previous literature, models of emotions were broadly organised into two categories [12, 13, 23, 24]: discrete and dimensional models. The former essentially aimed at determining a set of primary and innate emotions, leading to prototypical responses when elicited [9, 12]. On the other hand, dimensional models emerged from exploring core dimensions [24, 31] that described more than a single discrete emotional state at once. Furthermore, more recent and sophisticated models were proposed, e.g. the “appraisal-based models”, but they are still unsuited for the experimental assessment of emotions [13].
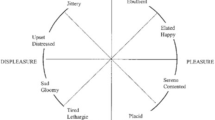
Currently, the most widespread dimensional model is the Circumplex model of Affects proposed by Russell [23]. It consists of a plane with two orthogonal and bipolar dimensions: valence and arousal. The former denotes the hedonic dimension, i.e. the degree of the pleasantness of the perceived emotion, ranging from unpleasant to pleasant. The latter describes the intensity of the emotion felt that is represented by the arousal degree, ranging from low to high arousal. Alternative interpretations of the structure of affects were proposed [5], such as the Positive-Negative Affect model defined by Watson and Tellegen [31]. They proposed two novel dimensions, namely Positive Affect (thereinafter PA) and Negative Affect (thereafter NA), which they considered to be the subjective expression of the two fundamental behavioural systems of approach and with drawal, respectively [31]. Therefore, paralleling Russell’s work, they portrayed a novel Affect Circumplex entailing four bipolar dimensions spaced 45° apart [31]: pleasantness, PA, engagement, and NA. Being largely independent and negatively correlated, the authors emphasised the PA and NA as essential dimensions for the structure of affects, which they measured throughout the PANAS scale, one of the most widely used psychometric scales by the Affective Computing community [30]. Throughout this work, we will refer to the circumplex model defined by PA and NA as the PA-NA plane.
Lately, innovative annotation tools deployed in experimental protocols have allowed participants to rate perceived emotions in more than a single dimension at once. In particular, the experimental setup of the Continuously Annotated Signal of Emotion (CASE) dataset [26] was specifically devised to continuously record self-assessed ratings of arousal and valence dimensions in real-time, during video elicitation sessions. In a previous study [11], we investigated the dynamics of the arousal annotation data considering two video stimuli only, the relaxing and the scary. An experimental comparison between the time-continuous emotion ratings in the valence-arousal plane and the rearranged values in the PA-NA plane has not yet been presented in the literature.
In this study, we used nonlinear time series analysis techniques to investigate the dynamics of the CASE dataset time-varying ratings in the valence-arousal plane and their transformation in the PA-NA plane. Previous works in the domain of physiological time series analysis highlighted the importance of taking advantage of nonlinear analysis approaches to account for the dynamics of these signals and characterise the autonomic [17,18,19] and the central nervous system activities for emotion recognition tasks [10]. We investigated the dynamics of all four dimensions of emotions (i.e., valence, arousal, PA, and NA) using Fuzzy Entropy (hereinafter FuzzyEn), which was developed to measure physiological time series regularity [7]. Moreover, we calculated the median of each time series as a reference averaged time-domain metric. Then, we focused on the statistical differences between the four emotions (scariness, amusement, relaxation, and boredom) elicited by the CASE video stimuli.
2 Materials and Methods
2.1 The Continuously Annotated Signal of Emotion (CASE) Dataset
The publicly-available CASE dataset [25, 26] provides continuously annotated ratings of emotions, recorded from 30 young adults (15 females, aged 25.71 ± 3.1 years, and 15 males, aged 28.6 ± 4.8 years). The arousal and valence ratings were collected by asking each participant to view eight emotional video clips with duration in the range [119, 197] s and continuously rate his/her emotional state in real-time [25, 26]. The videos were singled out to induce four distinct emotional states (relaxation, scariness, amusement, and boredom, with two clips for each emotion) and presented in pseudo-randomized order.
The CASE dataset is distinct from other datasets furnishing continuous ratings of emotions [1, 21, 22] since each subject evaluated its emotional state along the valence and arousal dimensions in real-time while viewing the emotion eliciting video clips. A custom joystick-based interface [3, 27] allowed a simultaneous annotation along both affective dimensions. Specifically, the joystick interface was connected to a graphic interface that appeared on the upper right corner of the screen where the video clip was played [3]. The graphic interface was based on Russell’s plane [23] and was enhanced by placing the icons of the Self-Assessment Manikin [6] on each axis to simplify the annotation task. Before the elicitation, a practice session of five short videos endowed participants with familiarising themselves with the task and the annotation interface. The annotation data were acquired with a sampling frequency of 20 Hz [26].
2.2 The Positive and Negative Affect (PA-NA) Plane
From the original valence and arousal data, we generated a novel dataset made by the PA and NA annotation data, to compare the four annotated data types (arousal, valence, PA, and NA) and investigate their emotion discrimination capability. Specifically, in [31] a novel structure of affect was proposed based on two dimensions: PA and NA. A unique affect circumplex, containing four bipolar axes (i.e., pleasantness, engagement, PA, and NA), was depicted with dimensions spaced 45° apart [31].
From a geometric perspective, since the PA-NA plane concerns a 45° rotation of the valence-arousal plane, our idea was to apply a rotation to the original data collected in the valence and arousal plane to make them fit the PA-NA plane. Valence and arousal data were rated in the [0.5, 9.5] range. Therefore, to obtain the PA and NA data, we first removed the origin (i.e., [6, 6]) of the valence-arousal plane. To rotate the data, we applied a rigid transformation to each data vector of valence and arousal time series through a standard rotation matrix, with rotation angle θ equal to 45°, according to:
with pa(t) and na(t) being the time series along the PA and NA dimensions, v(t) and a(t) represent the original valence and arousal time series, and v0 and a0 are the values of the origin for the valence and arousal time series, respectively. We applied this operation for all eight video types by coupling the annotated valence and arousal time series. Therefore, for each video type, through this transformation, we gained two additional annotation types along the PA and NA dimensions.
2.3 Phase Space Reconstruction and Fuzzy Entropy Analysis
The first step for computing nonlinear indexes of the annotated ratings was the phase space reconstruction for each of the four dimensions. We used the Takens embedding theorem [28] to reconstruct the so-called embedded vectors, which describe each time series’s trajectory in the phase space. We computed two parameters for each time series to construct the relative embedded vectors: the time delay τ and the embedding dimensions m. The first parameter is the time lag to plot the time series against itself; the second one represents the dimension of the phase space, i.e., the dimension of the embedded vectors. According to [2], we calculated τ as the first minimum of the auto-mutual information function, estimated through the kernel density estimation approach described in [29]. Additionally, we computed the value of m applying the False Nearest Neighbors (FNN) algorithm, proposed in [14].
Based on the parameters τ and m, we defined the states of the valence, arousal, PA, and NA dynamical systems in their own phase spaces throughout the coordinates of their embedded vectors. Specifically, from the original N dimensional time series x = [x(1), x(2),…, x(N)], we computed the N − (m − 1)τ embedded vectors in Rm. The i-th embedded vector ui was calculated as ui = [x(i), x(i + τ),…, x(i + (m − 1)τ)], with i ∈ [1, N − (m − 1)τ].
Following the reconstruction of the phase spaces of the four affective dimensions, we characterised their information content by employing information theoretic approaches. We used the FuzzyEn as a measure of regularity of the reconstructed dynamics [7]. In contrast to other entropy indexes, such as Sample Entropy and Approximate Entropy [20], FuzzyEn is not based on a binary comparison with a fixed threshold to estimate the similarity between points in the phase space. It is rather established on the broader concept of fuzzy sets to measure the closeness between points. Consequently, each distance between two vectors contributes to the estimate of trajectory similarity.
Practically, the first step for the computation of the FuzzyEn relies on the computation of the Chebyshev distance between each pair of embedded vectors ui and uj in the phase space, with \(i \ne j\) to exclude self-matches, as follows:
An exponential function is employed as a membership degree function, which assigns a value in the continuous range [0, 1] for each distance value d(ui, uj). Specifically, this distance value is used to compute the similarity degree Dmij (n, r) between embedded vector ui to uj, according to the following equation:
with m being the embedding dimension; n and r are parameters linked to the width and the gradient of the boundary of the exponential function, respectively. According to previous
work in physiological time series analysis [7], for our preliminary analysis we set r equal to 20% of the standard deviation of each time series and n equal to 2. Based on the FuzzyEn algorithm, the sample correlation measure Am(n, r) is defined as the similarity degree value accounting for all vectors in the phase space, normalized by the total number of vectors N − mτ, as in the following equation:
Afterwards, the value of the embedding dimension is increased from m to m + 1 and the values of \(D_{ij}^{m + 1} \left( {n, \, r} \right)\) are computed for each new pair of (m + 1)-dimensional vectors in the phase space, according to Eq. (3). Then, as shown in Eq. (4), we computed the new value of the sample correlation measure Am+1(n, r). Finally, we computed the value of FuzzyEn according to the following formula:
As a reference measure in the time domain, to compare the emotion discrimination capability along each dimension, we computed the median of the time series as an average measure.
2.4 Statistical Analysis
In this work, for each of the four annotation data types (i.e., arousal, valence, PA, NA), we averaged across the same subject the FuzzyEn and median values computed for the two videos with the same emotional content. Therefore, we obtained a single subject-dependent measurement of FuzzyEn and median for each emotion type. For all four annotation data types, we tested independently the FuzzyEn and the median through a within-subject statistical comparison between the four emotions. We performed a non-parametric Friedman test to check any difference between the medians of the four different emotion types for each measure and each annotation data type. If we found a significant difference, we applied the Wilcoxon signed-rank test for paired samples as the multiple comparison test. We set the statistical significance level at α = .05 and applied the Bonferroni correction when testing for multiple comparisons. We used non-parametric statistical tests due to the non-gaussianity of the sample distributions, demonstrated by testing each sample with the Shapiro-Wilk test. According to the signal quality, all the statistical tests were performed on 26 subjects. We executed all the analyses with the software Matlab (Release 2021b, Mathworks Inc., Natick, MA).
3 Results
The FuzzyEn presented the lowest median (± median absolute deviation, i.e., MAD) value for the boring stimulation compared to all the other emotion stimulation types, as highlighted by the violin plots in Fig. 1a. In particular, for the arousal annotation data, the FuzzyEn of the boring stimulation (0.181 ±0 .085) resulted significantly lower than the amusing (0.302 ± 0.090, p = 0.0050) and the scary (0.263 ± 0.041, p = 0.0476) ones. Similarly, for the valence annotation data, the FuzzyEn for the boring (0.193 ±0 .062) stimulation was significantly lower than the amusing (0.328 ±0 .065, p =0 .0096) and the scary (0.254 ±0 .007, p = 0.0045) clips. Regarding the PA data, the FuzzyEn for the boring (0.138 ±0 .052) stimulation was significantly lower than all the other induced emotions: fear (0.243 ± 0.053, p = 0.0007), amusement (0.259 ± 0.053, p = 0.0002), and relaxation (0.229 ± 0.078, p = 0.0176). However, for the annotations along the NA dimension, the FuzzyEn for the boring (0.160 ± 0.058) stimulation came about to be significantly lower than the amusing (0.233 ±0 .029, p = 0.0131) only.
Concerning the analysis of the median, by looking at Fig. 1b we can appreciate that for the arousal data, all pairwise comparisons were significantly different, whereas, for the valence data, the only non-significant comparison was between amusing (6.308 ± .539) and relaxing (5.879 ± 0.733) stimulations. However, a different picture was unveiled when dealing with the median of the derived annotation data PA and NA. More in detail, for the median of the PA annotation data, the amusing stimulation is significantly higher than all the others, as well as the boring has the lowest median (−0.673 ±0 .695) compared to the others: relaxing (0.056 ± 0.431, p = 0.0022), scary (0.391 ± 0.407, p = 0.0002), and amusing (1.140 ± 0.546, p ≪ .0001). Regarding the NA data, the fear-inducing stimulation presents a higher median (2.248 ± .870) than the others: the amusing (−0.719 ± 0.373, p ≪ 0.0001), the relaxing (−0.876 ±0 .513, p ≪ 0.0001), and the boring (−0.823 ±0 .401, p ≪ 0.0001), but there is no difference among the last three.

Violin plots depicting the dispersion of Fuzzy Entropy (FuzzyEn) a and median b values for the arousal (top left), valence (top right), positive arousal (PA, bottom left), and negative arousal (NA, bottom right) annotation data. Values reported were obtained by averaging for the same subject two entropy indexes a and median values b, calculated by starting from the annotated time series (i.e., arousal, valence, PA, and NA) of each of the two videos inducing the same emotion category. Statistically significant p-values, corrected by the number of multiple comparisons, are reported in accordance with the following legend: ∗ p ≤ .050; ∗∗ p ≤ .010; ∗∗∗ p ≤ .001.
4 Discussion and Conclusions
In this computational study, we conducted a preliminary investigation into the dynamics of four conscious emotions that were collected through continuous recordings of self-assessed ratings during an emotion-eliciting task. We utilized the arousal and valence annotated signals provided by the CASE dataset to derive the Positive Affect (PA) and Negative Affect (NA) dimensions due to their mutual connections [30, 31]. In our previous work, we explored the possibility of distinguishing between relaxation and scariness using entropy indexes [11]. However, no previous study has compared emotions based on a nonlinear analysis of their dynamics according to two different emotion models: Russell’s valence arousal plane [23] and Watson and Tellegen’s PA-NA plane [31].
To assess the dynamics’ regularity, we utilized FuzzyEn, given its robustness against short time series. Pairwise comparisons of the PA and NA time series highlighted the possibility of successfully distinguishing boredom from the other three emotions (scariness, amusement, and relaxation) using the PA data. When comparing the statistical findings obtained by applying nonlinear analysis techniques to the four emotion dimensions, PA emerged as the unique scale capable of completely discriminating one emotion (boredom). In contrast, the FuzzyEn for the valence and arousal dimensions did not differentiate between relaxation and boredom. We also analyzed the median of the annotated time series. Although almost all four emotions were differentiated by the valence and arousal annotation median, the same did not hold for the PA and NA annotations. Specifically, the median of PA annotations demonstrated superior discrimination power compared to NA, with the latter being useful only for differentiating scariness. Therefore, combining the average and the nonlinear entropy index would increase the emotion discrimination capability in the PA-NA plane.
One limitation of this study is the data transformation from the valence arousal plane to the PA-NA plane. Specifically, users were trained to rate their emotional state in the valence-arousal plane only. Since the CASE dataset did not contain annotations along the PA and NA dimensions, we derived these data. Additionally, the original annotated data were collected in a rectangular valence-arousal plane, constraining the boundaries of the rotated space.
We plan to validate our results in future studies with other validated entropy metrics (e.g., Distribution Entropy [16]). This will allow us to thoroughly characterize the dynamics of these novel annotation signals and unleash their potential for real-time emotion classification tasks. An essential step in that direction would be to investigate the emotion discrimination capabilities by coupling annotated signals along different dimensions in a multivariate analysis. Specifically, several psychological models of emotion suggest that bidimensional models might fail to capture subtle differences between emotions. Therefore, as in [8], we could couple more than two dimensions. Furthermore, according to [31], we applied a rotation to the valence-arousal plane of 45 degrees. However, our future research will investigate how different rotation angles impact the emotion discrimination capabilities of these annotated data.
Given the considerable amount of studies showing the discriminative power of nonlinear analysis of physiological signals [7, 10, 15,16,17,18,19], we believe that combining this information with the study of annotated signals could remarkably disclose still unnoticed connections between consciously experienced emotions and unconscious physiological processes.
References
Abadi, M.K., Ramanathan, S., Kia, S.M., Avesani, P., Patras, I., Sebe, N.: De caf: Meg-based multimodal database for decoding affective physiological responses. IEEE Trans. Affect. Comput. 6, 209–222 (2015)
Abarbanel, H.D., Brown, R., Sidorowich, J.J., Tsimring, L.S.: The analysis of observed chaotic data in physical systems. Rev. Mod. Phys. 65(4), 1331 (1993)
Antony, J., Sharma, K., Castellini, C., van den Broek, E.L., Borst, C.W.: Continuous affect state annotation using a joystick-based user interface. In: Proceedings of Measuring Behavior 2014: 9th International Conference on Methods and Techniques in Behavioral Research, pp. 500–505 (2014)
Barrett, L.F., Russell, J.A.: The structure of current affect: controversies and emerging consensus. Curr. Dir. Psychol. Sci. 8(1), 10–14 (1999)
Bradley, M.M., Lang, P.J.: Measuring emotion: the self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 25(1), 49–59 (1994)
Chen, W., Wang, Z., Xie, H., Yu, W.: Characterization of surface emg signal based on fuzzy entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 15(2), 266–272 (2007)
Eerola, T., Vuoskoski, J.K.: A comparison of the discrete and dimensional models of emotion in music. Psychol. Music 39(1), 18–49 (2011)
Ekman, P.: An argument for basic emotions. Cogn. Emot. 6(3–4), 169–200 (1992)
García-Martínez, B., Martinez-Rodrigo, A., Alcaraz, R., Fernández-Caballero, A.: A review on nonlinear methods using electroencephalographic recordings for emotion recognition. IEEE Trans. Affect. Comput. 12(3), 801–820 (2019)
Gargano, A., Scilingo, E.P., Nardelli, M.: The dynamics of emotions: a preliminary study on continuously annotated arousal signals. In: 2022 IEEE International Symposium on Medical Measurements and Applications (MeMeA), pp. 1–6. IEEE (2022)
Grandjean, D., Sander, D., Scherer, K.R.: Conscious emotional experience emerges as a function of multilevel, appraisal-driven response synchronization. Conscious. Cogn. 17(2), 484–495 (2008)
Gunes, H., Schuller, B., Pantic, M., Cowie, R.: Emotion representation, analysis and synthesis in continuous space: a survey. In: 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), pp. 827–834. IEEE (2011)
Kennel, M.B., Brown, R., Abarbanel, H.D.: Determining embedding dimension for phase-space reconstruction using a geometrical construction. Phys. Rev. A, Atom. Mol. Opt. Phys. 45(6), 3403–3411 (1992)
Lake, D.E., Richman, J.S., Griffin, M.P., Moorman, J.R.: Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol.-Regul. Integr. Comp. Physiol. 283(3), R789–R797 (2002)
Li, P., Liu, C., Li, K., Zheng, D., Liu, C., Hou, Y.: Assessing the complexity of short-term heartbeat interval series by distribution entropy. Med. Biol. Eng. Compu. 53(1), 77–87 (2015)
Nardelli, M., Lanata, A., Bertschy, G., Scilingo, E.P., Valenza, G.: Heartbeat complexity modulation in bipolar disorder during daytime and nighttime. Sci. Rep. 7(1), 1–11 (2017)
Nardelli, M., Valenza, G., Greco, A., Lanata, A., Scilingo, E.P.: Recognizing emotions induced by affective sounds through heart rate variability. IEEE Trans. Affect. Comput. 6(4), 385–394 (2015)
Nardelli, M., Valenza, G., Greco, A., Lanata, A., Scilingo, E.P., Bailón, R.: Quantifying the lagged poincaré plot geometry of ultrashort heart rate variability series: automatic recognition of odor hedonic tone. Med. Biol. Eng. & Comput. 58(5), 1099–1112 (2020)
Richman, J.S., Moorman, J.R.: Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol.-Hear. Circ. Physiol. 278(6), H2039–H2049 (2000)
Ringeval, F., Schuller, B., Valstar, M.F., Gratch, J., Cowie, R., Scherer, S., Mozgai, S., Cummins, N., Schmitt, M., Pantic, M.: Avec 2017: real-life depression, and affect recognition workshop and challenge. In: Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, pp. 3–9 (2017)
Ringeval, F., Sonderegger, A., Sauer, J.S., Lalanne, D.: Introducing the recola multimodal corpus of remote collaborative and affective interactions. In: 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), pp. 1–8 (2013)
Russell, J.A.: A circumplex model of affect. J. Pers. Soc. Psychol. 39(6), 1161–1178 (1980)
Russell, J.A.: Core affect and the psychological construction of emotion. Psychol. Rev. 110(1), 145 (2003)
Sharma, K., Castellini, C., Stulp, F., Van den Broek, E.L.: Continuous, real-time emotion annotation: a novel joystick-based analysis framework. IEEE Trans. Affect. Comput. 11(1), 78–84 (2017)
Sharma, K., Castellini, C., van den Broek, E.L., Albu-Schaeffer, A.O., Schwenker, F.: A dataset of continuous affect annotations and physiological signals for emotion analysis. Sci. Data 6 (2019)
Sharma, K., Wagner, M., Castellini, C., van den Broek, E.L., Stulp, F., Schwenker, F.: A functional data analysis approach for continuous 2-d emotion annotations. Web Intell. 17, 41–52 (2019)
Takens, F.: Detecting strange attractors in turbulence. In: Rand, D., Young, L.S. (eds.) Dynamical Systems and Turbulence, Warwick 1980, pp. 366–381. Springer, Berlin, Heidelberg (1981). https://doi.org/10.1007/BFb0091924
Thomas, R.D., Moses, N.C., Semple, E.A., Strang, A.J.: An efficient algorithm for the computation of average mutual information: validation and implementation in matlab. J. Math. Psychol. 61, 45–59 (2014)
Watson, D., Clark, L.A., Tellegen, A.: Development and validation of brief measures of positive and negative affect: the panas scales. J. Pers. Soc. Psychol. 54(6), 1063 (1988)
Watson, D., Tellegen, A.: Toward a consensual structure of mood. Psychol. Bull. 98(2), 219 (1985)
Watson, D., Wiese, D., Vaidya, J., Tellegen, A.: The two general activation systems of affect: Structural findings, evolutionary considerations, and psychobiological evidence. J. Pers. Soc. Psychol. 76(5), 820 (1999)
Acknowledgement
The research leading to these results has received partial funding from European Union Horizon 2020 Programme under grant agreement n° 824153 of the project “POTION-Promoting Social Interaction through Emotional Body Odours” and by the Italian Ministry of Education and Research (MIUR) in the framework of the FoReLab project and CrossLab project (Departments of Excellence).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Gargano, A., Scilingo, E.P., Nardelli, M. (2024). Comparing Valence-Arousal and Positive-Negative Affect Models of Affect: A Nonlinear Analysis of Continuously Annotated Emotion Ratings. In: Badnjević, A., Gurbeta Pokvić, L. (eds) MEDICON’23 and CMBEBIH’23. MEDICON CMBEBIH 2023 2023. IFMBE Proceedings, vol 93. Springer, Cham. https://doi.org/10.1007/978-3-031-49062-0_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-49062-0_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-49061-3
Online ISBN: 978-3-031-49062-0
eBook Packages: EngineeringEngineering (R0)