
Abstract
Text semantic matching is a fundamental task in natural language understanding, and has a wide range of applications in information retrieval, question and answer systems, reading comprehension, and machine translation. Currently, a better way to do text semantic matching tasks is to extract word vectors or sentence vectors with BERT and then fine-tuning them, but the commonly used fine-tuning methods suffer from the overfitting problem. We propose a bi-directional long short-term memory-parallel dropout model (BiLSTM-PD), which combines word vectors and sentence vectors to improve feature vectors quality and uses parallel dropout to reduce overfitting. First, word vectors and sentence vectors are generated using the pre-trained model, BiLSTM converts the word vectors into sentence vectors, and the sentence vectors generated by BiLSTM are combined with the sentence vectors generated by the pre-trained model to form the final sentence vectors representation; then, four dropout functions are used to randomly discard a portion of the neurons of the sentence vectors to obtain four subsets, and then a linear layer is used to transform the four subsets of dimensionality and calculate the average value, and then use the Softmax and Argmax functions to calculate the predicted value of each batch to know whether the two sentences are similar. Experiments on two text semantic matching datasets and detailed analyses demonstrate the effectiveness of our model.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Text semantic matching refers to comparing the semantic similarity between two pieces of text to determine whether they have the same meaning or express similar meanings. In recent years, significant progress has been made in the application of pre-trained models for the semantic matching of text pre-trained models can learn linguistic representations by training on large-scale data to provide higher-quality semantic features for downstream tasks. Among them, feature-based matching [21] and interaction-based matching [18] are the two main applications of pre-trained models for text semantic matching.
The feature-based matching method refers to encoding two sentences separately to obtain their sentence vectors representations and then processing these sentence vectors by simple fusion to obtain the final matching result. The feature-based matching approach can effectively avoid the problem of information overload and has good computational efficiency at the same time. However, the independent encoding of two sentences in a sentence pair may lead to the neglect of the interaction information between sentences, which affects the matching accuracy. We usually use interactive matching methods to better use the interaction information between sentences. The interactive matching method refers to splicing two texts together as a single text for classification. This method can obtain richer semantic information and thus improve the matching accuracy. For example, in question-answer systems, the correlation between the question and the text can be better captured by stitching the question and the text together.
In this study, we propose the BiLSTM-PD model. The model combines word vectors and sentence vectors to improve the quality of feature vectors, uses parallel dropout to reduce overfitting, and uses interactive matching methods to obtain richer semantic information. Experiments on two semantic matching datasets show that the present model achieves excellent performance. The contribution of this paper includes three parts:
-
1.
Combining word vectors and sentence vectors to ensure a higher quality representation of feature vectors.
-
2.
Parallel dropout is proposed to reduce overfitting by parallel operations.
-
3.
The results show that the BiLSTM-PD model can improve the performance of semantic matching and can also be easily integrated into other interaction-based text semantic matching models to improve accuracy.
2 Related Work
2.1 Text Semantic Matching
Text semantic matching aims to determine the semantic relationship between two text sequences. In earlier work, researchers mainly used keyword-based matching methods such as TF-IDF [12] and BM25 [11]. These methods rely on manually defined features and often fail to assess the semantic relevance of the text. With the development of deep learning techniques, researchers have started to propose various neural models to solve the text semantic matching problem. These models use deep learning techniques such as recurrent neural networks (RNN) [9] and convolutional neural networks (CNN) [10] to encode text sequences and then compare the encoded text sequences to determine the similarity between them. Their recurrent neural networks are mainly used for sequence modeling and can handle variable-length input sequences adaptively. They are widely used in the field of text semantic matching. There are also some improved models based on RNNs, such as Siamese [17], which classifies two text sequences by encoding them separately through the same RNN and then stitching them together for the task of text semantic matching. With the emergence of pre-trained models, the field of text semantic matching has also started to apply this technique. Pre-trained models can automatically learn rich semantic information by performing unsupervised learning on a large-scale text corpus to improve the performance of text semantic matching. BERT [5] is a representative model among them, which achieves extremely high performance by learning bidirectional contextual representations through a joint training task. Subsequent researchers have also proposed various improved models based on BERT, such as RoBERTa [15] and ALBERT [13].
2.2 Dropout
Dropout is a regularization technique commonly used in deep learning to reduce the complexity of the network by dropping some random neurons during training, thus reducing the risk of overfitting. Dropout was first proposed by Hinton et al. [8], one of the reasons for model overfitting is that the relationship between neurons is too complex, and dropout can prevent the relationship between neurons from being too complex by randomly dropping some neurons. Dropout is implemented in a simple way, i.e., some neurons are randomly dropped with a certain probability p in each training so that they are not involved in forward and backward propagation. This allows the network to be more robust during training and improves generalization. In addition to the original dropout technique, there are some improved methods. For example, DropConnect [19], which replaces random dropout with random disconnections, can increase the capacity of the network while reducing overfitting, and DropBlock [6], which replaces random dropout with random block dropout, can further reduce the risk of overfitting. However, these methods generally use only one dropout, while the parallel dropout we use works better by using multiple dropouts to randomly discard a portion of the neurons in the sentence vectors.
3 Method
Text semantic matching can be viewed as a classification task to find labels \(y\in Y= \left\{ similar, dissimilar \right\} \) for a given sentence pair \(\left( S_{a},S_{b} \right) \). Figure 1 shows our model BiLSTM-PD for this task, and the model structure includes an input layer, a feature extraction layer, a dropout layer, and an output layer. In the following, we describe the components of the model.

General framework of the model
3.1 Input Layer
Given two text sequences \(S_{a}=\left\{ w_{1}^{a},...,w_{l}^{a}\right\} \) and \(S_{b}=\left\{ w_{1}^{b},...,w_{l}^{b}\right\} \), we need to add an \(\left[ cls \right] \) at the beginning of the sentence and \(\left[ sep \right] \) in the middle and at the end of the two sentences, \(S_{a,b}= \left[ \left[ cls \right] S_{a}\left[ sep \right] S_{b}\left[ sep \right] \right] \). Here, \(w_{i}^{a}\) and \(w_{j}^{b}\) represent the i-th and j-th word in the sequences; \(\left[ cls \right] \) denotes the beginning of the sequence and is used for the classification task; \(\left[ sep \right] \) is used to separate two sentences or paragraphs in the input sequence so that BERT can distinguish them. We use \(S_{a,b}\) as the input of BERT.
3.2 Feature Extraction Layer
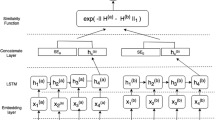
The feature extraction layer consists of two parts, BERT and BiLSTM. The main work of this layer is that BERT generates word vectors and sentence vectors, BiLSTM converts the word vectors into sentence vectors, and the sentence vectors generated by BiLSTM are combined with the sentence vectors generated by the pre-trained model to form the final sentence vectors representation the structure of BiLSTM is shown in Fig. 2.

BiLSTM structure
BERT: BERT is a pre-trained natural language processing model with a Transformer-based neural network at its core, whose goal is to map text data into vector representations by learning large amounts of unlabeled text data. We input \(S_{a,b}\) to the BERT layer to obtain a vector representation S of the entire sentence pair and a vector representation \(x_{t}\) of each word, \(x_{t}= \left[ T_{1},..., T_{N}; T_{1},..., T_{M} \right] \), and we use \(x_{t}\) as input to the BiLSTM.
BiLSTM: The BiLSTM [7] consists of a combination of a forward LSTM [23] and a backward LSTM, using the forward LSTM and the backward LSTM to traverse the end and the beginning of the sequence, respectively, with the aim of efficiently capturing the global information of the input sequence. In this paper, we use BiLSTM to transform word vectors into sentence vectors. The BILSTM is calculated as follows:
where \(x_{t}\) is the input data at moment t, \(\overrightarrow{h_{t} }\) and \(\overleftarrow{h_{t} }\) is the output of the forward LSTM hidden layer and the output of the reverse LSTM hidden layer, respectively, and H is the output after the two are connected. The sentence vectors H is obtained by BILSTM processing, and the sentence vectors H is combined with the sentence vectors S generated by BERT to obtain the sentence vectors C, \(C=\left[ S,H \right] \).
3.3 Dropout Layer
The dropout layer consists of four dropout functions and four linear layers. Since the four dropout functions randomly discard a part of the neurons of the sentence vectors, the sentence vectors produce four subsets after the dropout layer. The dropout layer is computed as follows:
C represents the sentence vectors, \(d_{i}\) represents the four dropout functions; \(v_{i}\) represents the four subsets of the sentence vectors; \(l_{i}\) represents the four linear layers; \(u_{i}\) represents the four probability vectors mapped to the predicted label space. \(u_{i}\) is averaged to obtain z, and the probability vectors z goes to the output layer for the next processing step.
3.4 Output Layer
The output layer consists of a Softmax function and an Argmax function.
Softmax is the function that generates the vectors of probability distribution and Argmax is the function that determines the location of the maximum value. Z obtains the probability distribution vectors by Softmax function, and then obtains the predicted label vectors f for each Batch by Argmax function, with the value of f being 0 or 1. The accuracy of this Batch is obtained by comparing the predicted labels with the true labels.
4 Experimental Setup
4.1 Datasets
The model was evaluated on two semantic matching datasets, including BQ [1], and LCQMC [14]. BQ is a question matching dataset for the banking and finance domain with data from question pairs in the customer service logs of online banking, while LCQMC is a large-scale open-domain Chinese question matching dataset constructed from Baidu Know. All datasets are divided into training, validation, and test data. Datasets statistics of BQ and LCQMC are shown in Table 1.
4.2 Parameter Setting
The parameters are set as shown in Table 2. The batch size of the dataset is fixed at 32. The initial learning rate is 2e-05, which decreases at a rate of 0.01 during the training period. Also, we adjust the output dimension of the BiLSTM hidden layer to 384. Finally, we use the ADAMW optimizer to modify all trainable parameters.
4.3 Evaluation Metrics
To evaluate the effectiveness of the model, the evaluation metrics for text semantic matching include accuracy (ACC) rate and F1 score (F1).
4.4 Contrast Model
We compare our model with recent work, including state-of-the-art neural network models and BERT-based approaches. DIIN [16] extracts relevant information from input sequences by a self-attention mechanism in the absence of RNNs or CNNs. ESIM [2] extracts information from text sequences using a bidirectional LSTM and models the relationship between sequences by a self-focusing mechanism. BiMPM [20] uses multi-angle matching and fusion. RE2 [22] employs richer features for the alignment process to improve performance. For the pre-trained approach, we consider BERT, RoBERTa, PERT [4], and MacBERT [3].
5 Experimental Results
5.1 Comparison Results and Discussion
Table 3 shows the results of the BQ dataset. All baselines are divided into two groups, the first group is four neural network-based methods and the second group is four pre-trained model-based methods. The pre-trained model-based methods show superior performance compared to the traditional neural matching models. For example, BERT outperformed ESIM by 1.95\(\%\) and 0.95\(\%\) in terms of accuracy and F1, respectively. MacBERT outperformed RE2 by 4.47\(\%\) and 3.53\(\%\) in terms of accuracy and F1, respectively. And the BiLSTM-PD model using MacBERT as the base model outperformed all eight models. For example, BiLSTM-PD is 1.82\(\%\) and 2.30\(\%\) higher than RoBERTa in terms of accuracy and F1, respectively. The possible reasons are that our model uses BiLSTM, which can better integrate the contextual information of the input sequences, combining word vectors and sentence vectors can extract richer semantic features.
Table 4 shows the results of the LCQMC dataset. The method based on pre-trained models showed superior performance compared to the traditional neural matching models. For example, RoBERTa outperforms DIIN in terms of accuracy and F1 by 1.83\(\%\) and 0.60\(\%\), respectively. PERT outperforms BiMPM in terms of accuracy and F1 by 2.71\(\%\) and 1.35\(\%\), respectively. And the BiLSTM-PD model using MacBERT as the base model outperformed all eight models. For example, BiLSTM-PD outperforms MacBERT in terms of accuracy and F1 by 0.63\(\%\) and 0.68\(\%\), respectively. Overall, our models achieved the best results on the LCQMC dataset.
To explore the effectiveness of our models, we combined BiLSTM-PD with the four pre-trained models to compare the results with the original pre-trained models and calculated the improvement in accuracy and F1, with bolded numbers indicating significant changes. As can be seen in Table 5 and Table 6, the accuracy and F1 of all pretrained models steadily improved on both datasets, and the improvement was particularly significant on the two pretrained models, RoBERTa and MacBERT. The results show that converting word vectors into sentence vectors by BiLSTM and combining the sentence vectors generated by BiLSTM with those generated by BERT and using four dropout functions to randomly discard a portion of the neurons of the sentence vectors can effectively improve the model and can be well integrated with the pre-trained model.
5.2 Ablation Experiments
The main modules of the BiLSTM-PD model are the BiLSTM and the dropout layer, and the dropout layer has two important parameters, so we designed two ablation experiments.
Number of Dropout Samples: We choose 6 quantities of 0, 1, 2, 4, 8, and 16 respectively. We can see from Fig. 3 that the error rate tends to decrease and then increase as the number of dropout samples increases, which indicates that too many or too few dropout samples will make the model less effective. When the number of dropout samples is 4, the error rate of both data sets is the lowest, so it is better to choose 4 as the number of dropout samples in the experiment.

Error rate of different dropout sample numbers

Error rate of different dropout ratio
Dropout Ratio: We choose five probabilities, 10%, 30%, 50%, 70%, and 90%. Here we show how the multiple samples loss of BQ and LCQMC datasets works with different loss rates:{10%, 10%, 10%, 10%}, {10%, 10%, 30%, 30% }, {30%, 30%, 30%, 30%}, {10%, 30%, 50%, 70%}, {10%, 30%, 70%, 90% }, {30%, 50%, 70%, 90% }, {70%, 70%, 70%, 70% }, {70%, 70%, 90%, 90% }, {90%, 90%, 90%, 90% }, with mean values of 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, and 90%, respectively. Figure 4 shows the test set error rates for different dropout ratios. Regardless of the dropout ratio setting, parallel dropout outperforms no dropout. Dropout ratio from 10\(\%\) to 90\(\%\), the Test error rate shows a wave-like growth followed by a decline, and the test set error rate reached its lowest at an average dropout ratio of 30\(\%\). The overall change in the test error rate is not significant, which indicates that the parameter of dropout ratio has little effect on the model.
6 Conclusion
In this study, we propose a text semantic matching model that combine word vectors and sentence vectors to improve feature vectors quality and uses parallel dropout to reduce overfitting. The method is simple and effective, and easy to combines with pre-trained models. Experiments on two semantic matching datasets show that the proposed method outperforms the previously proposed model. However, the pre-trained models and datasets used in our work are all in Chinese, and since different languages have different characteristics and processing methods, future work may focus on modifying the models appropriately according to language characteristics to apply to other language datasets.
References
Chen, J., Chen, Q., Liu, X., Yang, H., Lu, D., Tang, B.: The BQ corpus: a large-scale domain-specific Chinese corpus for sentence semantic equivalence identification. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 4946–4951 (2018)
Chen, Q., Zhu, X., Ling, Z.H., Wei, S., Jiang, H., Inkpen, D.: Enhanced LSTM for natural language inference. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1657–1668 (2017)
Cui, Y., Che, W., Liu, T., Qin, B., Wang, S., Hu, G.: Revisiting pre-trained models for Chinese natural language processing. In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 657–668 (2020)
Cui, Y., Yang, Z., Liu, T.: PERT: pre-training BERT with permuted language model, arXiv preprint arXiv:2203.06906 (2022)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding, arXiv preprint arXiv:1810.04805 (2018)
Ghiasi, G., Lin, T.Y., Le, Q.V.: Dropblock: a regularization method for convolutional networks. In: Advances in Neural Information Processing Systems, vol. 31 (2018)
Graves, A., Schmidhuber, J.: Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 18(5–6), 602–610 (2005)
Hinton, G.E., Srivastava, N., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.R.: Improving neural networks by preventing co-adaptation of feature detectors, arXiv preprint arXiv:1207.0580 (2012)
Hou, B.J., Zhou, Z.H.: Learning with interpretable structure from gated RNN. IEEE Trans. Neural Netw. Learn. Syst. 31(7), 2267–2279 (2020)
Huang, P.S., He, X., Gao, J., Deng, L., Acero, A., Heck, L.: Learning deep structured semantic models for web search using clickthrough data. In: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, pp. 2333–2338 (2013)
Kadhim, A.I.: Term weighting for feature extraction on Twitter: a comparison between BM25 and TF-IDF. In: 2019 International Conference on Advanced Science and Engineering (ICOASE), pp. 124–128. IEEE (2019)
Kim, D., Seo, D., Cho, S., Kang, P.: Multi-co-training for document classification using various document representations: TF-IDF, LDA, and Doc2Vec. Inf. Sci. 477, 15–29 (2019)
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., Soricut, R.: Albert: a lite BERT for self-supervised learning of language representations. In: International Conference on Learning Representations (2019)
Liu, X., et al.: LCQMC: a large-scale Chinese question matching corpus. In: Proceedings of the 27th International Conference on Computational Linguistics, pp. 1952–1962 (2018)
Liu, Y., et al.: RoBERTa: a robustly optimized BERT pretraining approach, arXiv preprint arXiv:1907.11692 (2019)
Mirakyan, M., Hambardzumyan, K., Khachatrian, H.: Natural language inference over interaction space: ICLR 2018 reproducibility report. arXiv preprint arXiv:1802.03198 (2018)
Mueller, J., Thyagarajan, A.: Siamese recurrent architectures for learning sentence similarity. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30 (2016)
Rao, J., Liu, L., Tay, Y., Yang, W., Shi, P., Lin, J.: Bridging the gap between relevance matching and semantic matching for short text similarity modeling. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5370–5381 (2019)
Wan, L., Zeiler, M., Zhang, S., Le Cun, Y., Fergus, R.: Regularization of neural networks using DropConnect. In: International Conference on Machine Learning, pp. 1058–1066. PMLR (2013)
Wang, Z., Hamza, W., Florian, R.: Bilateral multi-perspective matching for natural language sentences. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence, pp. 4144–4150 (2017)
Wu, Z., et al.: An efficient Wikipedia semantic matching approach to text document classification. Inf. Sci. 393, 15–28 (2017)
Yang, R., Zhang, J., Gao, X., Ji, F., Chen, H.: Simple and effective text matching with richer alignment features. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4699–4709 (2019)
Yu, Y., Si, X., Hu, C., Zhang, J.: A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 31(7), 1235–1270 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Li, Z., Shao, Z., Xiao, J., Yu, Z., Zhang, X. (2023). Text Semantic Matching Research Based on Parallel Dropout. In: Iliadis, L., Papaleonidas, A., Angelov, P., Jayne, C. (eds) Artificial Neural Networks and Machine Learning – ICANN 2023. ICANN 2023. Lecture Notes in Computer Science, vol 14258. Springer, Cham. https://doi.org/10.1007/978-3-031-44192-9_44
Download citation
DOI: https://doi.org/10.1007/978-3-031-44192-9_44
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-44191-2
Online ISBN: 978-3-031-44192-9
eBook Packages: Computer ScienceComputer Science (R0)