
Abstract
Unmanned aerial vehicles (UAVs) have diverse applications in various fields, including the deployment of drones in 5G mobile networks and upcoming 6G and beyond. In UAV wireless networks, where the UAV is equipped with an eNB or gNB, it is critical to position it optimally to serve the maximum number of users located in high-capacity areas. Furthermore, the high mobility of users leads to greater network dynamics, making it challenging to predict channel link states. This study examines the use of Proximal Policy Optimization (PPO) to optimize the joint UAV position and radio spectrum resource allocation to meet the users’ quality-of-service (QoS) requirements.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- 5G
- 6G
- Unmanned aerial vehicle (UAV)
- resource allocation optimization
- deep reinforcement learning (DRL)
- Proximal Policy Optimization (PPO)
- Deep Reinforcement Learning (DQN)
1 Introduction
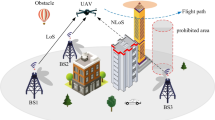
The beauty of Unmanned Aerial Vehicles (UAVs), which includes drones, have recently attracted lots of researcher’s attention in the industrial fields due to their ability to operate and monitor activities from remote locations; moreover, UAVs are well known for their portability, lightweight, low cost and flying without a pilot. UAV features make it suitable to be integrated into the fifth-generation (5G) and the networks beyond 6G wireless networks, where UAV can be deployed as aerial base stations into what is called the UAV-assisted [1, 2]. Such situations include quick service recovery after a natural disaster and offloading base stations or the Next Generation Node B (gNBs) at hotspots in case of failure or malfunction of the ground base station or the gNB. In addition, UAV can be used to enhance network coverage and performance, where the location of the UAV can be controlled and dynamically changed to optimize the network performance according to the users’ needs and their mobility model. Such scenarios are represented in Fig. 1.

UAV emergency model.
A UAV-assisted application was investigated in terms of performance analysis, resource allocation, UAV placement and position optimization, channel modeling, and information security as in [3, 4] and [5]. UAV-assisted wireless communications have three main types; the first type is called UAV-carried Evolved Node B (eNB) or gNB, where the UAV acts as an aerial base station and is used to extend the network coverage [6, 7] and [8]. The second type is called UAV relaying, where the UAVs are used as aerial relays to provide a wireless connection for users that cannot communicate with each other directly [9, 10]. Finally, the third type is identified as a UAV-assisted Internet-of-Things (IoT) network, where UAVs assist the IoT network in collecting/disseminating data from/to its nodes or charging its nodes [11] and [12].
However, due to the UAV’s limitations, only some applications use UAVs in the existing systems. The fundamental limitation is the battery life of the UAV, which is affected by the high power consumption dissipated in the hovering, horizontal, and vertical movements of the drone. Besides the battery life, the position of the UAV is also a significant concern in implementing real systems.
One of the significant applications of using the UAV in the communication system is during emergencies (such as floods or earthquakes, ... etc.) while the infrastructure is partially or totally unavailable, and the need to provide mobile service to the users is highly required. In these situations, the UAV can perform this task and provide mobile services to the user equipment (UE’s) while granting the required quality-of-service (QoS). The main challenge for using the UAV-assisted network is to find the optimal position of the UAV in the cell area before getting a dead battery. Which is very complicated and challenging to determine, and the traditional optimization methods of artificial intelligence (AI) cannot solve those complicated optimization problems.
In order to address those two concerns, Reinforcement learning (RL) algorithms are applied, especially deep reinforcement learning, which has been proven to outperform the existing traditional algorithm. In this work, we introduced a different deep RL algorithm to solve the UAV-assisted joint position and radio resource allocation optimization problem. The main target is to find the optimal position of the UAV that is dynamically changed concerning the UE’s required QoS and consider the UAV battery energy level in each time step, in addition to the required energy to get back to the start point.
Our main contribution in this study is presented as follows. We developed a method that collaboratively optimizes communication resource allocation and position for the UAV based on reinforcement learning, where the position and radio resource allocation joint optimization problem is formulated to obtain the maximum cumulative discounted reward. For the non-convexity nature of the optimization problem, we designed and applied different deep reinforcement learning algorithms for the UAV to solve the joint optimization issue, then we compared these algorithms’ performance to solve the proposed problem; these algorithms are Proximal Policy Optimization (PPO) and Deep Reinforcement Learning (DQN).
Section 2 reviews the related literature on optimizing the position and resource allocation in UAV-assisted networks. Also, we review the reinforcement learning application in such optimization problems for UAV-assisted wireless networks. System model and problem formulation are illustrated in Sect. 3, and simulation and results are presented in Sect. 4. The conclusion is discussed in Sect. 5.
2 Related Work
The design of UAV position for improving various communication performance metrics has gained significant attention, as shown in various studies such as in [13], which focused on optimizing the spectrum efficiency and energy efficiency of a UAV-enabled mobile relaying system by adjusting the UAV’s flying speed, position, and time allocation. [14] aimed to optimize the global minimum average throughput through optimized UAV trajectories and OFDMA (orthogonal frequency-division multiple access) resource allocation. [15] explored the UAV-enabled wireless communication system with multiple UAVs and aimed to increase the minimum user throughput by optimizing communication scheduling, power allocation, and UAV trajectories. In [16], UAVs served as flying Base Stations (BSs) for vehicular networks, delivering data from vehicular sources to destination nodes. The authors determined the optimal UAV position and radio resource allocation by combining Linear Programming and successive convex approximation methods.
Despite the deployment optimization of UAVs, machine learning (ML) algorithms have been introduced to optimize different QoS network requirements. The reinforcement RL and deep learning (DL) received the foremost researchers’ focus in this field. Such researches as in [17], where the authors proposed UAV autonomous indoor navigation and target detection approach based on a Q-learning algorithm. While in [18], the authors proposed multi-agent reinforcement learning to optimize the resource allocation of the multi-UAV networks, and the algorithm is designed to maximize the systems’ long-term reward. The authors of [19] have considered RL algorithms to optimize UAV’s position to maximize sensor network data collection under QoS constraints. Moreover, in [20], the researchers adopted deep learning RL based to dynamically allocate radio resources in heterogeneous networks.
Based on the related literature review, a limited number of researchers are solving the UAV position’s joint optimization problem and the UE’s resource allocation. Motivated by that, we applied the deep RL algorithms to solve this optimization problem.
3 An RL-Based Approach
We considered a multi-rotor UAV with total energy \(E_{max}\) that flying at a fixed altitude of \(h_{max}\) from a base point denoted by \(s_{0} = (x_0,y_0)\). The UAV has an onboard gNB that will serve K subscribers within a specific area. At the beginning (\(\tau _i\)) of time slot i, the gNB decides the assignment of Resource Blocks (RB) for each customer according to specific criteria; in our study, we adopt the customer’s QoS requirements, and the channel quality, where the gNB can measure the channel quality of each user’s device and allocate the RB’s based on a minimum requirement to maintain the network performance. We assume that the gNB receives the CQI values. (\(CQI(i)= [ CQI_{1,i}, CQI_{2,i},\ldots , CQI_{k,i} ]\)) of \(k=\{1, ..., K\}\) user equipment (UEs) at time instance \(\tau _i\) where \(i=0,\ldots \), which is in accordance with the time-slot operation of the gNB, so \(\tau _{i+1}-\tau _i=\varDelta \). At each time step \(\tau _i= a\times i \times \varDelta \), the UAV decides to continue flying or get back to the base point while monitoring the battery level. For this problem, we apply Reinforcement learning (RL) for flight control as follows:
-
At each time step \(\tau _i\), the state \(s_{i} = [(x_{i}, y_{i}, h_{max}, E_{i}), [CQI_{k,i} ] ] \, \) \( \forall \, \, k\in [0,K]\) consists of UAV position, which can be denoted by the coordinates \((x_i,y_i, h_{max})\) and the UAV battery energy level, in addition to the received CQI values, form the UE’s \(CQI_{k,i}\forall k \in [1,K]\), and the UAV battery level \(E_{i}\).
-
We assume that the altitude of the UAV is fixed in this study, which can lead to the possible actions: backward, forward, left, right, and hovering in the same location and returning to the base point. The action space is \(\mathcal {A}== \{L,R, FW, BW, HO, RE\}\).
-
The reward function \(r_i = \sum _{k=1}^{K} U_{k,i}\) is defined as the total number of served UE’s in each time step, where the binary variable \(U_{k} \in {\{0,1\}}, \forall k\), which is asserted if the UAV succeeded in serving the \(k^{th}\) UE, and allocated the required resources to guarantee the minimum throughput required to provide coverage for the cell in emergencies. Otherwise, \(U_{k}\) is set to 0. In this study, we adopt the max CQI scheduling allocation of the UE’s, where the UE’s with the highest values of CQI are allocated while there are available resource blocks in the radio frame.
The energy consumption of the UAV consists of mainly two parts: one that is required to provide the onboard gNB with its energy to operate, and the other is the propulsion energy of the UAV so that it can fly around. The UAV will decide to get back to the base point by monitoring its battery energy level \((E_i)\) at each time step \(\tau _i\), and compare it with the energy required to fly back to the start point \( s_{0} = (x_0,y_0) \) from its position point \((E_{i+1,r})\). The UAV battery energy constraints is assumed to be:
4 Simulation and Analysis
4.1 Models Used in Simulation
User Mobility. User mobility modeled in this research is based on the Gauss-Markov Mobility Model [21]. Where the Mobile nodes (UE’s) are located in random locations within the cell area, these nodes will set their speed as for the \(k^{th}\) UE the speed is denoted as \((V_{i,k})\) and its direction denoted as \((D_{i,k})\) for each specific step (i). At every step i, the current position of the \(k^{th}\) UE coordinates \((x_{k,i},y_{k,i})\) depends on the previous location \((x_{k,i-1},y_{k,i-1})\), previous speed \(V_{k,i-1}\) and previous direction \(D_{k,i-1}\), assuming the directions values can be set to \(\in [0,90,180,270]\), to follow the proposed grid world model of the network cell. The \(k^{th}\) UE position at the \(i^{th}\) step, is expressed as
Parameters \(V_{k,i-1}\) and \(D_{k,i-1}\) are chosen from a random Gaussian distribution with a mean equal to 0 and a standard deviation equal to 1.
RB Scheduling Algorithm. In our study, we adopt the best-CQI scheduling algorithm to allocate RB to the UE, where the gNB Scheduler allocates the RBs to the UE’s that reported the highest CQI during Transmission Time Interval (TTI), where the higher CQI value means a better channel condition.
Energy Consumption Model for Multi-rotor UAV. In this study, we considered rotary-wing UAV, the UAV has four brushless motors which are powered by the carried battery, and they rotate at the same constant speed \(\omega _{rotor}\). The UAV will fly to a specific position and hover or continue flying to the next position. We follow the forces model in [22] to derive the energy consumption for both UAV motion phases. The propulsion power of the UAV is essential to support the UAV’s hovering and moving activities either the vertical movement, where in our study, we assumed the UAV height is constant; thus, we will not consider this movement phase, the other movement type is the horizontal movement from one position to another in the cell grid.

UAV hovering state forces.

UAV forward state forces.
Hovering is one of the motion activities of the drone, where the thrust of the rotor is used to equilibrate the gravity effect completely; Fig. 2 represents the hovering phase forces. Thrust is denoted by:
where \(\rho \) is the air density and equals to \((1.225\,\mathrm{kg/m}^2)\), the rotor propeller area is \(A_{uav}\) and is equal to \( A_{uav} = \pi r_{uav}^2\) where \(r_{uav}\) is the propeller radius. Finally, the number of UAV rotors is represented by the variable \(N_{rotor}\). The \(V_{UAV}\) is the resultant velocity of the drone, and the hovering phase is equal to the motor speed, which is denoted by \(\omega _{rotor}\) and can also be defined as the induced velocity of the rotor blades.
In the hovering phase, the thrust of the drone motors must equal the gravitational force \((m_{tot} \times g)\), where the value of \(V_{uav} = \sqrt{2 m_{tot} \times g / (\rho A_{uav} N_{rotor})}\). Accordingly, in time step duration \(\varDelta \) where the power is equal to \(P_{hov} = F_{T} V_{uav}\), with \(V=0\), the energy that the battery must supply is only that to defy the weight force, and considering the UAV motor efficiency \(\eta _{mot}\) and the propeller efficiency \(\eta _{pro}\) is defined as
where \(m_{tot}\) is the total mass in Kg and equals to the sum of UAV mass \((m_{uav})\), the payload (the carried gNB) \((m_{pld})\) and the battery \((m_b)\), i.e. \(m_{tot} = m_{uav} + m_b + m_{pld}\). The earth gravitational force g and equals to \((9.81\approx 10\,\mathrm{m/s}^s )\). Finally, \(\eta _{mot}\) is the efficiency of the UAV motor.
The UAV horizontal movement is considered the most challenging drone motion to estimate; where according to Newton’s \(1^{st}\) low where the drone required to generate motors thrust force \((F_{T})\) that is equal and opposite to the total sum of forces consists of drag force \((F_{D})\) due to the drone speed and the weight force \((F_{W} = m_{tot} \times g)\) due to the total weight of the drone and it is cargo (battery and carried gNB). All horizontal movement forces are shown in Fig. 3. The vertical forces under the equilibrium condition are mathematically represented by
Applying Newton’s \(1^{st}\) law to find the UAV velocity required to maintain the required conditions, the forces are denoted by
where \(C_{D}\) represents the drag coefficient, and \(A_{uav}^{eff}\) represents the vertical projected area of the UAV and can be evaluated as \(A_{uav}^{eff} = A_{uav}^{side} \sin {(90-\phi _{tilt})} + A_{uav}^{top} \sin {\phi _{tilt}}\), where \(A_{uav}^{side}\) and \(A_{uav}^{top}\) represents the side and top surface of the UAV, which can be approximated as \(A_{uav}^{eff} = A_{uav}^{top} \sin {\phi _{tilt}}\). To evaluate the UAV energy consumed in the horizontal movement of the drone with constant speed, and using Eqs. 5 and 6, the power formula denoted by \(P_{hor} = F_{T} V_{uav}\) is presented as
where \(\eta _{mot}\) and \(\eta _{pro}\) are the efficiency of the motor and the propeller, respectively. The UAV properties and parameters values used in the simulation are represented in Table 1, in addition to the UAV battery specifications, which represent the battery model installed with DJI Matrice 600 Pro drone models [23]. At a given trajectory \((x_{i}, y_{i}, h_{max})\), the remaining energy of the UAV can be expressed as
Energy Model of gNB. Path loss is modeled as the probability model that consists mainly of two components, i.e., LoS and NLoS. LoS connection probability between the receiver and transmitter is an essential factor and can be formulated as [24]
where \(a_{LOS}\) and \(b_{LOS}\) are environmental constants, and \(\phi _{k}(i)\) is the elevation angle in degree, and it depends on the UAV height as well as the distance between the UAV and user k, the elevation angle can be evaluated from \(\phi _{k} = - \frac{180}{\pi } \sin ^{-1}(\frac{h(i)}{d_k(i)})\). Furthermore, h(i) is the UAV height, and \(d_k(i)\) is the distance between the UAV and the \(k^{th}\) UE and defined as
The probability of having NLoS communication between the UAV and \(k^{th}\) UE is denoted by:
Hence, the mean path loss model (in dB) we adopt the following equation from [24]
where, \(L_{\text {LoS},k}(i)\) and \(L_{\text {NLoS},k}(i)\) are the path loss for LoS and NLoS communication links and denoted by
where \(\alpha _{pl}\) is the path loss exponent and its environment-dependent variable, both of the \(\delta _{\text {LoS}}\) and \(\delta _{\text {NLoS}}\) are the mean losses due to LoS and NLoS communication links, \(c = 3 \times 10^8\) the speed of light and \(f_c\) is the network operating frequency.
With \(\gamma _{k}(i)\) represents the Signal-to-Noise Ratio (SNR) of the \(k^{th}\) UE at the \(i^{th}\) step, while assuming \({P_{r,k}(i)}\) is the received signal power at the \(k^{th}\) UE, the SNR is defined as
The SNR can be rewritten in terms of the path loss and transmitted UAV power as
where \(P_{k}(i)\) is the transmitted power from the UAV to the \(k^{th}\) UE at the \(i^{th}\) step.
The 5G NR maximum data rate of the \(k^{th}\) UE can be evaluated in Mbps using the formula defined in [25], and expressed as:
where J represents the number of aggregated component carriers, \((\varOmega _{j,k})\) is the maximum number of layers, and \((M_{j,k})\) is the modulation order. In contrast, \((\zeta _{j,k})\) is a scaling factor that has values of (1, 0.8, 0.75, and 0.4). The code rate is denoted by \((C_{R,\max })\), and is can have the values in Tables 5.1.3.1-1, 5.1.3.1-2 and 5.1.3.1-3 in 3gpp.38.214 with a maximum value of (948/1024). The numerology \(\mu \) can have the values of [0, 1, 2, 3, 4] which responds to the subcarrier spacing (SCS) of 15 kHz, 30 kHz, 60 kHz, 120 kHz and 240 kHz. The variable \(T^\mu _{s}\) represents the average OFDM symbol duration for certain \(\mu \) and can be evaluated as \((T^\mu _{s}=\frac{10^3}{14\times 2^\mu }) \). The \(N_{j,k}^{RB}(i)\) is the number of allocated RBs to the \(k^{th}\) UE at the \(i^{th}\) step. Finally, \(O H_{j,k}\) denotes the overhead and can have the values of (0.14, 0.18, 0.08, and 0.10).
Moreover, the data rate can have another formula to be evaluated according to [25], as
where \(TBS_{j,k}\) is the total maximum number of DL-SCH transport block bits received within a 1ms TTI for the \(k^{th}\) UE and \(j^{th}\) carrier.
4.2 Simulation Results
In our case study, we considered one UAV that flies at a maximum altitude of \(h_{max} = 200\) m over grid area size \((1500 \times 1500)\), The simulation parameters listed in Table 1 and the network setting listed in Table 2. In each episode, there are two scenarios for the UE’s mobility. One scenario is considering 20 number of UE which are generated and distributed randomly in the cell area while assuming random walk mobility model to be the mobility model for the UE within the cell, moreover, the second scenario considered placing four UE’s and fix their positions at the corners of the cell.
The deep RL algorithms PPO and DQN models were constructed and trained on a random proposed environment where the UAV carries the eNB and flies around the cell to provide mobile services to the maximum number of UE’s. The battery capacity of the UAV was initialized with a value \(E_{max}\). The first scenario where the mobility of the UE’s is considered, we illustrate the comparison results for applying PPO and DQN RL algorithms then tuned them with different learning rates (lr) values: [0.01, 0.001, 0.0001].
The accumulative rewards for each iteration of the training is illustrated in Fig. 4, in this training results the PPO which was tuned wit learning rate 0.001 has the better performance than the other to solve the optimization problem. The other scenario in which we placed four UE’s corners of the cell, Fig. 5 illustrates the accumulative rewards achieved in each training iteration using both model (PPO and DQN) which are in addition tuned with different learning rates (lr) [0.01, 0.001, 0.0001]. Comparing the performance of the RL algorithms showed that the PPO agent which tuned with \(lr=0.01\) or \(lr=0.001\) proves a superior performance than the others.

Max reward per episode - 20 UE with random walk mobility model.

Max reward per episode - 4 UE places at cell corners.
5 Conclusion
In this paper, we developed a framework for UAV autonomous navigation in urban environments that takes into account trajectory and resource allocation and the battery limitation of the UAV while taking into account the UE mobility within the environment. We deploy the RL PPO-based algorithm, which allows the UAV to navigate in continuous 2D environments using discrete actions, where the model was trained to navigate in a random environment. Then evaluated, the PPO and DQN algorithms while tuning the agents with different learning rate values, and then compared the results accordingly.
References
Zeng, Y., Zhang, R., Lim, T.J.: Wireless communications with unmanned aerial vehicles: opportunities and challenges. IEEE Commun. Mag. 54(5), 36–42 (2016)
Mozaffari, M., Saad, W., Bennis, M., Nam, Y., Debbah, M.: A tutorial on UAVs for wireless networks: applications, challenges, and open problems. IEEE Commun. Surv. Tutor. 21(3), 2334–2360 (2019)
Wu, Q., Liu, L., Zhang, R.: Fundamental trade-offs in communication and trajectory design for UAV-enabled wireless network. IEEE Wirel. Commun. 26(1), 36–44 (2019)
Wu, Q., Mei, W., Zhang, R.: Safeguarding wireless network with UAVs: a physical layer security perspective. IEEE Wirel. Commun. 26, 12–18 (2019)
Lin, X., et al.: The sky is not the limit: LTE for unmanned aerial vehicles. IEEE Commun. Mag. 56(4), 204–210 (2018)
Zhao, H., Wang, H., Wu, W., Wei, J.: Deployment algorithms for UAV airborne networks toward on-demand coverage. IEEE J. Sel. Areas Commun. 36(9), 2015–2031 (2018)
Sharma, N., Magarini, M., Jayakody, D.N.K., Sharma, V., Li, J.: On-demand ultra-dense cloud drone networks: opportunities, challenges and benefits. IEEE Commun. Mag. 56(8), 85–91 (2018)
Zhang, Q., Mozaffari, M., Saad, W., Bennis, M., Debbah, M.: Machine learning for predictive on-demand deployment of UAVs for wireless communications. In: 2018 IEEE Global Communications Conference (GLOBECOM), pp. 1–6 (2018)
Chen, X., Hu, X., Zhu, Q., Zhong, W., Chen, B.: Channel modeling and performance analysis for UAV relay systems. China Commun. 15(12), 89–97 (2018)
Zhang, G., Yan, H., Zeng, Y., Cui, M., Liu, Y.: Trajectory optimization and power allocation for multi-hop UAV relaying communications. IEEE Access 6, 48566–48576 (2018)
Zhan, C., Zeng, Y., Zhang, R.: Energy-efficient data collection in UAV enabled wireless sensor network. IEEE Wirel. Commun. Lett. 7(3), 328–331 (2018)
Xu, J., Zeng, Y., Zhang, R.: UAV-enabled wireless power transfer: trajectory design and energy optimization. IEEE Trans. Wireless Commun. 17(8), 5092–5106 (2018)
Zhang, J., Zeng, Y., Zhang, R.: Spectrum and energy efficiency maximization in UAV-enabled mobile relaying. In: 2017 IEEE International Conference on Communications (ICC), pp. 1–6 (2017)
Qingqing, W., Zhang, R.: Common throughput maximization in UAV-enabled OFDMA systems with delay consideration. IEEE Trans. Commun. 66(12), 6614–6627 (2018)
Yu, X., Xiao, L., Yang, D., Qingqing, W., Cuthbert, L.: Throughput maximization in multi-UAV enabled communication systems with difference consideration. IEEE Access 6, 55291–55301 (2018)
Samir, M., Chraiti, M., Assi, C., Ghrayeb, A.: Joint optimization of UAV trajectory and radio resource allocation for drive-thru vehicular networks. In: 2019 IEEE Wireless Communications and Networking Conference (WCNC), pp. 1–6 (2019)
Guerra, A., Guidi, F., Dardari, D., Djurić, P.M.: Reinforcement learning for UAV autonomous navigation, mapping and target detection. In: 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), pp. 1004–1013 (2020)
Cui, J., Liu, Y., Nallanathan, A.: Multi-agent reinforcement learning-based resource allocation for UAV networks. IEEE Trans. Wireless Commun. 19(2), 729–743 (2020)
Cui, J., Ding, Z., Deng, Y., Nallanathan, A., Hanzo, L.: Adaptive UAV-trajectory optimization under quality of service constraints: a model-free solution. IEEE Access 8, 112253–112265 (2020)
Tang, F., Zhou, Y., Kato, N.: Deep reinforcement learning for dynamic uplink/downlink resource allocation in high mobility 5G HetNet. IEEE J. Sel. Areas Commun. 38(12), 2773–2782 (2020)
Camp, T., Boleng, J., Davies, V.: A survey of mobility models for ad hoc network research. Wirel. Commun. Mob. Comput. 2(5), 483–502 (2002)
Valavanis, K.P., Vachtsevanos, G.J.: Handbook of Unmanned Aerial Vehicles. Springer, Dordrecht (2014). https://doi.org/10.1007/978-90-481-9707-1
DJI matrice 600 prospecs. https://www.dji.com/hr/matrice600-pro/info#specs. Accessed 20 Mar 2023
Al-Hourani, A., Kandeepan, S., Lardner, S.: Optimal lap altitude for maximum coverage. IEEE Wirel. Commun. Lett. 3(6), 569–572 (2014)
3GPP. 5G, NR, User Equipment (UE) radio access capabilities. 3GPP TS, 15.3.0 edition (2018)
IWAVE airborne 4G LTE base station. https://www.iwavecomms.com/. Accessed 20 Mar 2023
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Jwaifel, A.M., Van Do, T. (2023). Deep Reinforcement Learning for Jointly Resource Allocation and Trajectory Planning in UAV-Assisted Networks. In: Nguyen, N.T., et al. Computational Collective Intelligence. ICCCI 2023. Lecture Notes in Computer Science(), vol 14162. Springer, Cham. https://doi.org/10.1007/978-3-031-41456-5_6
Download citation
DOI: https://doi.org/10.1007/978-3-031-41456-5_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-41455-8
Online ISBN: 978-3-031-41456-5
eBook Packages: Computer ScienceComputer Science (R0)