
Abstract
Corporate bankruptcy predictions are crucial to companies, investors, and authorities. However, most bankruptcy prediction studies have been based on stationary models, and they tend to ignore important challenges of financial distress like data non-stationarity, concept drift and data imbalance. This study proposes methods for dealing with these challenges and uses data collected from financial statements quarterly provided by companies to the Securities and Exchange Commission of Brazil (CVM). It is composed of information from 10 years (2011 to 2020), with 905 different corporations and 23,834 records with 82 indicators each. The sample majority have no financial difficulties, and only 651 companies have financial distress. The empirical experiment uses a sliding window, a history and a forgetting mechanism to avoid the degradation of the predictive model due to concept drift. The characteristics of the problem, especially the data imbalance, the performance of the models is measured through AUC, Gmean, and F1-Score and achieved 0.95, 0.68, and 0.58, respectively.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Nowadays, markets and companies are tightly intertwined, with a huge amount of capital flowing among market players. About 23% of the capital assets and 48% of the liability of a financial institution come from other financial institutions [9] and allow better risk and capital allocation sharing among enterprises. On the other hand, it opens the way to systemic risk, as noticed during the subprime financial crisis in 2008, which had spread globally [11]. Consequently, bankruptcy or financial distress prediction (FDP) could avoid or deal with systemic risk and diminish its consequences [33]. Moreover, it is relevant because stakeholders and the corporate owner could take action before the occurrence of bankruptcy. For instance, it could empower owners to address the financial state of the enterprise in order to avert a bankruptcy scenario [26].
The FDP using economic-financial indicators has been extensively researched since the late 1960s [22]. Altman (1968) [4] was the first relevant work about it and used a statistical tool called Multiple Discriminant Analysis (MDA) for bankruptcy prediction, which became very popular among finance professionals. Around the 1990s, scholars started to use Artificial Intelligence (AI) and Machine Learning (ML) methods for bankruptcy prediction or FDP [10, 37]. In some reviews, Alaka et al. (2018) [2] and Shi & Li (2019) [32] have already verified that, on average, ML models have more accuracy than statistical models.
There is a gap in the studies about FDP since most of them deal with stationary data [4, 5], whereas the indicators come through a data flow and are non-stationary [31, 35]. They have temporal order and timestamp associated with it. Agrahari and Singh (2021) [1] state that any data sequence with a timestamp is known as a Data Stream (DS), so FDP should be treated as a data stream problem. Additionally, in real-world applications, FDP has to deal with imbalanced classes and concept drift over time.
This study integrates two fields that are typically developed separately, the FDP and the time dimension of the data, treating it in a data stream environment. The contributions of this study are (i) a benchmark of ML classifiers for FDP in a DS environment; (ii) a benchmark of methods for data imbalance from DS; (iii) an experiment using a real-world database from the CVM; (iv) a realist scenario evaluation; (v) an impact analysis about the prediction horizon increasing.
This paper is structured as follows: Sect. 2 presents concepts to understand FDP and ML in a DS environment. Section 3 brings the reviews, surveys, and relevant studies that were the starting point of this paper. Section 4 explains the strategies used to preprocess the data, deal with concept drift, train the classifiers, and metrics to measure the performance. Section 5 brings some data and charts to illustrate the selection of the best classifier. Finally, Sect. 6 presents the conclusion and future work possibilities.
2 Background
Financial distress refers to a situation in which an enterprise is unable to meet its financial obligations and debt repayments. In other words, it could be defined as an inability to pay debts or preferred dividends having consequences like overdrafts, liquidation for the interests of creditors, and it may lead to a statutory bankruptcy proceeding. [4]. Some symptoms include late or missed debt payments, declining credit scores, high levels of debt, and difficulty obtaining new credit [34].
J. Sun et al. (2014) [34] present financial distress from two different perspectives. From a theoretical perspective, it has degrees such as mild financial distress when an enterprise faces a temporary cash-flow difficulty, and it is severe when the business fails and starts statutory bankruptcy proceedings. Additionally, it is a dynamic changing process resulting from a continuous abnormality of business operation taking months, years, or even longer to happen [1]. The second is the empirical perspective when the enterprise faces difficulty paying debts on time and renegotiating debts with creditors.
Since the 90s, ML has been used to deal with bankruptcy prediction or financial distress identification [2, 32]. In a supervised learning problem, the goal is to learn a mapping between the input vector X and the output vector Y, given that there is a training set D of input-output pairs (\(x_i, y_i\)). Indeed there is an unknown function \(y = f(x)\) generating each \(y_i\). Therefore, the model training has to find a hypothesis h that approximates the function f. When the output \(y_i\) is one of a finite set, the learning problem is called classification, and if it has only two classes, it is a binary classification [29]. For example, a dataset for FDP contains healthy (negative class) and non-healthy (positive class) enterprises. Thus, it is a binary classification problem.
Nowadays, data is becoming increasingly ubiquitous [15]. Researchers have responded to this trend by developing ML algorithms for DS commonly known as incremental learning, real-time data mining, online learning, or DS learning [15]. Each item has an associated timestamp, and predictive models must consider items temporal order in real-time [1, 19]. When the timestamp t is considered to the supervised learning set of input-output pairs \((x_i, y_i)\) in D, the problem is described as a set of tuples with timestamp mark \(D^t = \{(x_1^t, y_1^t), (x_2^t, y_2^t), ..., (x_n^t, y_n^t)\}\). Where i is a natural number bounded by \(1 \le i \le n\), and identifies a element of the data chunk at the moment t.
H. M. Gomes et al. (2019) [15] define concept drift as a change in the statistical properties of a DS over time, and highlight that it occurs when the distribution of target concepts in a DS changes, leading to a degradation in the models’ results. In the Eq. 1, \(P^t(x_i, y_i)\) is the probability of an element \(x_i\) receiving the label \(y_i\) at time t. However, over time, this probability may change. It is a common problem in DS environments, where data is constantly generated and updated, making it challenging to maintain the accuracy.
In some datasets, the classes are not equally distributed, which means that at least one of them is in the minority concerning the others [13]. It biases the learning process towards the majority class and impairs the model generalization. There are two types of imbalance: intrinsic, when imbalance is something natural to the problem, for example, the financial situation of companies that are usually healthy, with a minority facing financial troubles; and extrinsic, which occurs when the imbalance results from a failure in the data collection [15].
Besides that, F. Shen et al. (2020) [31] have already noticed that some metrics used to evaluate ML models, such as accuracy, are not suitable for imbalanced data. It occurs when the metric uses more elements from the majority class distorting the result. Thus, it is necessary to use other set of metrics. For example, true positive rate (TPR), also known as sensitivity or recall [25], harmonic mean of precision and sensitivity when beta is equal 1 (F1) [25], geometric mean of specificity and sensitivity (Gmean) [25], Area Under the Curve of Receiver Operating Characteristic (AUC-ROC) [25], and Area Under the Curve of Precision and Sensitivity (AUC-PS) [30].
3 Related Work
The recent interest in FDP can be justified by the evolution of ML methods which has opened new possibilities and has achieved better results [5, 32]. On the other hand, the academy’s interest in DS learning is more recent and dates from the 2000s. The data nature is changing, the technology is collecting data all the time, and the computational power is not increasing at the same rate [14]. Given the current industry needs, there are challenges to address before the application of DS learning in real-world problems [15]. For instance, the concept drift challenge pervades different domains where the predictions are ordered by time, like bankruptcy prediction, FDP, and others [1].
The initial studies about FDP identification date from 1968 [4]. Even though it is not a new research field, in recent years, there has been a growing interest in financial and business [24, 32]. T. M. Alam et al. (2020) [3] highlight that predicting financial distress poses two significant challenges. Firstly, the combination of economic and financial indicators, which remains a difficult task despite the efforts of specialists. Secondly, it is necessary to address the problem of data imbalance since in real-world scenarios, the amount of healthy enterprises is much larger than those facing financial distress.
S. Wanget et al. (2018) [36] consider two problems inherent to DS: data imbalance and concept drift. Both are very present, usually together. The authors point out that although this combination of problems frequently exists in real situations, few studies address these issues, and propose: (i) a framework to handle these cases; (ii) some algorithms to minimize these problems jointly. In addition, the authors highlight the lack of studies to assess the effects of data imbalance on misconceptions.
J. Sun et al. (2019) [35] and F. Shen et al. (2020) [31] noticed that previous studies on FDP seldom consider the problem of concept drift and neglect how to predict the industry financial distress in a DS environment. Both used data from Chinese companies, the sliding window method and realized that the data imbalance problem is an obvious issue related to FDP. To address it they used SMOTEBoost and Adaptive Neighbor SMOTE-Recursive Ensemble Approach (ANS-REA), respectively. J. Sun et al. (2019) [35] verified the existence of concept drift in FDP and associated the use of the sliding window method as the reason for outperforming stationary models. To overcome the concept drift, F. Shen et al. (2020) [31] used a sliding window and a forgetting mechanism. Additionally, they suggested parameter optimization and different forgetting mechanism to improve accuracy. Despite 70 attributes usage, the authors proposed the addition of new financial and non-financial indicators in the model.
This study proposes a benchmark evaluation of some ML classifiers already used for FDP in a DS environment, like Logistic Regression (LR), Support Vector Machine (SVM), Random Forest (RF), Decision Tree (DT) [31, 35], and adds XGBoost and CatBoost commonly used in stationary environments [20, 22]. Another benchmark is about methods for data imbalance like SMOTE (Synthetic Minority Over-Sampling Technique) [8], and its variants like BorderlineSMOTE [16], ADASYN [18], SVMSMOTE [27], SMOTEENN [6] e SMOTETomek [28] because its popularity [12]. The idea is to evaluate them through an experiment using a real-world database from the CVM and also evaluate the impact on the model’s results after increasing the prediction horizon.
4 Methodology
This study has gathered data from the companies listed in the CVMFootnote 1. The most important documents were: the asset balance sheet, balance sheet of liabilities, income statement, and cash flow statement. They were used to produce a dataset with 23,834 entries and 82 economic-financial indicators, organized into 40 quarters over ten years (2011 to 2020). The data is strongly imbalanced: 2.73% are data of companies in financial distress situation, while 97.27% are not.
The sequence of quarters \({X^{t-h},..., X^{t-2}, X^{t-1}, X^{t}, X^{t+1}, X^{t+2},..., X^{t+k}}\) is the DS where t is the present, \(t-h\) is a past moment and \(t+k\) are quarters not presented to the model yet. Each quarter X is a set of distinct data companies x with 82 attributes each. Companies in a past quarter (\(X^{t-h}\)) have a label (\(Y^{t-h}\)), which can be “financial distress” or “normal”; companies in the present quarter (\(X^{t}\)) or ahead (\(X^{t+i}\), \(i \in {1,...,k}\)) have no label and are the ones to be predicted by the model.
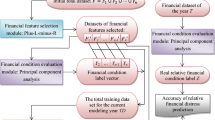
In this proposal, the model is trained with data from a sliding window and a subset of the historical data, as shown in Fig. 1. The sliding window is used to deal with concept drift and minimize its impact on the model performance. It comprises the eight most recent quarters of labeled data and its size is fixed a priori. The history data comprises data quarters older than those in the sliding window set and includes only instances of the minority class. These data are used to reduce the imbalanced problem, but passes through a forgetting mechanism to reduce the importance of old instances. It is an adaptation of exponential weighting scheme [23]: \(f(h) = 1 - exp^{-\alpha h}\), where h is the distance to the oldest quarter of the sliding window set and \(\alpha \) is a forgetting coefficient. The function f(h) returns the proportion of elements to forget for a specific historical quarter h. The prediction target, also known as the test set, is the data quarter which will be predicted by the model using the financial indicators, which are already known at time t. The prediction horizon (k) specifies how many quarters in advance the prediction will be performed. In this work, we assume the values 2, 4, 8, 12, 16, 20, and 24 quarters.

Sliding window after eleven quarter with three historic quarters and eight quarters for the window
In addition to using historical data containing only cases from the minority class, this study also applies oversampling techniques to increase the number of instances of companies in financial distress to mitigate the problem of data imbalance. The idea is to create synthetic samples to increase the minority class to 50% and 100% of the majority class to identify the best balancing rate (Rt) for each model using methods to balance the data (i.e. SMOTE, BorderlineSMOTE, ADASYN, SVMSMOTE, SMOTEENN, and SMOTETomek).
In the preprocessing phase, a set of instances of the minority class is oversampled before model training. Figure 2 illustrates the training set generation. In step 1, it selects all instances of the minority class from the sliding window mc and merge with instances from the history after the forgetting mechanism \(hmc'\). Hence, it merges the selected set \(hmc'+mc\) with the sliding window majority class Mc. Then, in step 2.1, it applies the oversampling technique. Step 2.2 minimizes the creation of synthetic instances by the under-sampling technique \((hmc'+mc)'+Mc'\).

Data preprocessing to generate the training set
After the sliding window has accumulated enough data, with eight quarters, the training process is conducted in rounds using the prepared training set. Because of the time dependence of the data, the nested cross-validation on time series [21] is more appropriate to train and validate the classification model (i.e. LR, SVM, RF, DT, XGBoost and CatBoost).
Mainly because of the imbalance condition of the dataset and the importance of correct classification of the minority samples, the metrics used to evaluate models performance were F1-Score and Gmean. Other important metrics were the AUC-ROC to measure the overall accuracy [7, 17] and the AUC-PS to complement the analysis [30].
5 Results
Firstly the classifiers’ performances were evaluated after preprocessing approach using different balancing strategies rate (\(Rt=\{0, 0.5, 1\}\)) and different prediction horizon (2, 4, 8, 12, 16, 20, and 24 quarters), the average and the standard deviation of metrics (F1-Score, Gmean, AUC-ROC and AUC-PS) were computed. In Table 1, the average best results of F1-Score, Gmean, AUC-ROC and AUC-PS for the combination of classifier, preprocessing approach, and balancing strategies were presented. The italic values are the best results of a classifier among balancing techniques (in a column), and the bold number is the best result for a specific metric among all classifiers.
In Table 1 it is possible to observe that the best predictive performance (bold values) is related to the CatBoost for most of the metrics analysed. Additionally, the best balancing technique is the SMOTEENN with a balancing rate \(Rt=1\) because it presents the higher value for F1 and AUC-ROC, while the values for Gmean and AUC-PS are very close. Hence, the CatBoost classifier and SMOTEENN with a balancing strategy of 100% are better.
Next analyses are about the impact of prediction horizon variation (2, 4, 8, 12, 16, 20 and 24) on the metrics F1-Score, Gmean, AUC-ROC and AUC-PS, using the CatBoost classifier and SMOTEENN (100%) as balancing technique. In Fig. 3, the x-axis is the prediction horizon quarters and the y-axis is the average result of the metrics over time.

The evaluation metrics F1-Score, Gmean, AUC-ROC and AUC-PS after changing the precision horizon from 2 quarters to 24 quarters

Classifier AUC-ROC and AUC-PS evolution during training using prediction horizon of 2 quarters
Figure 3 shows that the prediction horizon and classifier performance measured by F1-Score, Gmean, AUC-ROC, and AUC-PS are inversely proportional. It means that when the prediction horizon increases, the classifier performance decreases. Hence, the best classifier result is when the prediction horizon is smaller (i.e. 2 quarters). The AUC-ROC behavior differs from others because the strong data imbalance rate impacts it, and it should be analyzed together with AUC-PS [30].
The final analysis is about the CatBoost behavior over cross-validation on time series using the SMOTEENN with a balancing strategy of 100% and a prediction horizon of 2 quarters. Figure 4 shows a chart where the x-axis is the classifier result, and the y-axis is the quarter, a variation curve of AUC-ROC, a variation curve of AUC-PS. As time goes, the AUC-ROC remains always above 0.95 while AUC-PS get its worst value (0.7164) in the 19th quarter and increases until it reaches its best value (0.9760) in the 39th quarter. Thus, there is an increasing trend for the AUC-PS curve because of the accumulation of financial distress instances in history, which reduces the number of synthetic samples necessary to balance the data chunk. The valleys in the AUC-ROC and AUC-PS curves (quarters 12, 19, 28, and 31) may be interpreted as concept drifts.
On this study the best overall results were obtained using CatBoot and the balancing method of SMOTEENN. The results may be compared with F. Shen et al. [31] because they used a very similar methodology and forgetting coefficient set to “1”, its best classifier is RF and the balancing method is the ANS-REA. The performance of AUC-ROC was better in this study (0.9519 vs. 0.9138), however, the F1-Score (0,5811 vs. 0.8003) and the Gmean (0,6865 vs. 0.8783) was not. In this study the minority class represents 2.73% of samples while in the Shen’s study the minority class represents 33%, this reasonable difference explains the difference in the F1-Score and the Gmean between the studies.
6 Conclusion
This study investigates the FDP with strongly imbalanced data in a DS environment combining different classifiers, preprocessing data balancing techniques, and data selection to deal with concept drift. This approach is more suitable than those that deal with stationary data because enterprises’ economic-financial indicators are susceptible to concept drift [35], and it can be the basis for building an autonomous FDP solution.
The empirical experiment uses data from 2011 to 2020, consisting of 651 financially distressed companies and 23,183 matching normal enterprises, all of which are listed on the Brazilian stock exchange from CVM. The results demonstrate that FDP in a DS environment is possible even when the data is strongly imbalanced. The use of balancing techniques improved the metrics’ results in all cases. Hence, they are import tools to deal with imbalanced data and should be added to machine learning pipelines to deal with FDP in DS. When the CatBoost is used with SMOTEENN, balancing the minority class at 100% of majority, it outperforms the best results of the classifiers LR, DT, SVC, RF, and XGBoost. In F1-Score it is superior by 117.35%, 63.17%, 723.23%, 29.91%, and 9.62%, in AUC-ROC it is superior by 14.51%, 44.55%, 46.01%, 2.39% and 1.02%, in AUC-PS it is superior by 360.75%, 62.66%, 734.77%, 8.75%, and 9.69%. The exception is in Gmean because it is superior to DT, SVC, and RF by 23.44%, 194.86%, and 24.13%, although it is slightly inferior to LR and XGBoost by 0.65% and 1.13%.
Differently, from other studies about FDP in dynamic environments [31, 35] that did not use AUC-PS, in this study it complemented the information from AUC-ROC and helped to identify the moments of concept drift and the way the model recovered from a drift. It also showed that the sliding window, the history, and the forgetting mechanism are important to deal with the concept drift. Thus, it should be used more often when dealing with imbalanced data and data streams. Additionally, the prediction horizon should be increased with caution because it severe impacts the classifiers performance.
The experiment performed during this study may be improved with the use of a period larger than ten years because this could enlarge the history and fewer synthetic instances of the minority class will be necessary. The forgetting coefficient should also be adjusted to more accurate parameter optimization to improve the accuracy because, with the current value, the mechanism forgets most historic instances til the second quarter of the history. Different sliding window lengths could be tried or even an adaptive sliding window [23] could be used. Moreover, further research could be conducted on concept drift to identify different types of drift and adapt the models after detecting a drift [1]. For this purpose, the dataset used in this study is available on GitHubFootnote 2.
References
Agrahari, S., Singh, A.K.: Concept drift detection in data stream mining: a literature review. J. King Saud Univ. Comput. Inf. Sci. (2021). https://doi.org/10.1016/j.jksuci.2021.11.006
Alaka, H.A., et al.: Systematic review of bankruptcy prediction models: towards a framework for tool selection. Expert Syst. Appl. 94, 164–184 (2018). https://doi.org/10.1016/j.eswa.2017.10.040
Alam, T.M., et al.: Corporate bankruptcy prediction: an approach towards better corporate world. Comput. J. 64(11), 1731–1746 (2020). https://doi.org/10.1093/comjnl/bxaa056
Altman, E.I.: Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 23(4), 589–609 (1968). https://doi.org/10.1111/j.1540-6261.1968.tb00843.x
Barboza, F., Kimura, H., Altman, E.: Machine learning models and bankruptcy prediction. Expert Syst. Appl. 83, 405–417 (2017). https://doi.org/10.1016/j.eswa.2017.04.006
Batista, G.E.A.P.A., Prati, R.C., Monard, M.C.: A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor. Newsl. 6(1), 20–29 (2004). https://doi.org/10.1145/1007730.1007735
Bradley, A.P.: The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recogn. 30(7), 1145–1159 (1997). https://doi.org/10.1016/S0031-3203(96)00142-2
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: SMOTE: synthetic minority over-sampling technique. J. Artif. Intell. Res. 16(1), 321–357 (2002). https://doi.org/10.5555/1622407.1622416
Duarte, F., Jones, C.: Empirical network contagion for U.S. financial institutions. FRB of NY Staff Report 1(826) (2017)
Efrim Boritz, J., Kennedy, D.B.: Effectiveness of neural network types for prediction of business failure. Expert Syst. Appl. 9(4), 503–512 (1995). https://doi.org/10.1016/0957-4174(95)00020-8. https://www.sciencedirect.com/science/article/pii/0957417495000208. Expert systems in accounting, auditing, and finance
Eichengreen, B., Mody, A., Nedeljkovic, M., Sarno, L.: How the subprime crisis went global: evidence from bank credit default swap spreads. J. Int. Money Financ. 31(5), 1299–1318 (2012). https://doi.org/10.1016/j.jimonfin.2012.02.002
Fernández, A., García, S., Herrera, F., Chawla, N.V.: Smote for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 61(1), 863–905 (2018)
Fernández, A., García, S., Galar, M., Prati, R.C., Krawczyk, B., Herrera, F.: Learning from Imbalanced Data Sets. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-98074-4
Gama, J.: A survey on learning from data streams: current and future trends. Progress Artif. Intell. 1(1), 45–55 (2012). https://doi.org/10.1007/s13748-011-0002-6
Gomes, H.M., Read, J., Bifet, A., Barddal, J.P., Gama, J.: Machine learning for streaming data: state of the art, challenges, and opportunities. ACM SIGKDD Explor. Newsl. 21(2), 6–22 (2019). https://doi.org/10.1145/3373464.3373470
Han, H., Wang, W.-Y., Mao, B.-H.: Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: Huang, D.-S., Zhang, X.-P., Huang, G.-B. (eds.) ICIC 2005. LNCS, vol. 3644, pp. 878–887. Springer, Heidelberg (2005). https://doi.org/10.1007/11538059_91
Hanley, J., Mcneil, B.: The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 143, 29–36 (1982). https://doi.org/10.1148/radiology.143.1.7063747
He, H., Bai, Y., Garcia, E.A., Li, S.: ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), pp. 1322–1328 (2008). https://doi.org/10.1109/IJCNN.2008.4633969
He, H., Chen, S., Li, K., Xu, X.: Incremental learning from stream data. IEEE Trans. Neural Netw. 22(12), 1901–1914 (2011). https://doi.org/10.1109/TNN.2011.2171713
Huang, Y.P., Yen, M.F.: A new perspective of performance comparison among machine learning algorithms for financial distress prediction. Appl. Soft Comput. 83, 105663 (2019). https://doi.org/10.1016/j.asoc.2019.105663
Hyndman, R.J., Athanasopoulos, G.: Forecasting: Principles and Practice. OTexts (2021)
Jabeur, S.B., Gharib, C., Mefteh-Wali, S., Arfi, W.B.: CatBoost model and artificial intelligence techniques for corporate failure prediction. Technol. Forecast. Soc. Change 166, 120658 (2021). https://doi.org/10.1016/j.techfore.2021.120658
Klinkenberg, R.: Learning drifting concepts: example selection vs. example weighting. Intell. Data Anal. 8(3), 281–300 (2004). https://doi.org/10.5555/1293831.1293836
Kumbure, M.M., Lohrmann, C., Luukka, P., Porras, J.: Machine learning techniques and data for stock market forecasting: a literature review. Expert Syst. Appl. 197, 116659 (2022). https://doi.org/10.1016/j.eswa.2022.116659
Li, Z., Huang, W., Xiong, Y., Ren, S., Zhu, T.: Incremental learning imbalanced data streams with concept drift: the dynamic updated ensemble algorithm. Knowl.-Based Syst. 195, 105694 (2020). https://doi.org/10.1016/j.knosys.2020.105694
Lin, X., Zhang, Y., Wang, S., Ji, G.: A rule-based model for bankruptcy prediction based on an improved genetic ant colony algorithm. Math. Probl. Eng. 753251 (2013). https://doi.org/10.1155/2013/753251
Nguyen, H.M., Cooper, E.W., Kamei, K.: Borderline over-sampling for imbalanced data classification. Int. J. Knowl. Eng. Soft Data Paradigm 3(1), 4–21 (2011). https://doi.org/10.1504/IJKESDP.2011.039875
Rana, C., Chitre, N., Poyekar, B., Bide, P.: Stroke prediction using Smote-Tomek and neural network. In: 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), pp. 1–5 (2021). https://doi.org/10.1109/ICCCNT51525.2021.9579763
Russell, S., Norvig, P.: Artificial Intelligence: A Modern Approach, 3rd edn. Prentice Hall, Hoboken (2010)
Saito, T., Rehmsmeier, M.: The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 10, 1–21 (2015). https://doi.org/10.1371/journal.pone.0118432
Shen, F., Liu, Y., Wang, R., Zhou, W.: A dynamic financial distress forecast model with multiple forecast results under unbalanced data environment. Knowl.-Based Syst. 192, 105365 (2020). https://doi.org/10.1016/j.knosys.2019.105365
Shi, Y., Li, X.: A bibliometric study on intelligent techniques of bankruptcy prediction for corporate firms. Heliyon 5(12), 12 (2019). https://doi.org/10.1016/j.heliyon.2019.e02997
Silva, T.C., da Silva Alexandre, M., Tabak, B.M.: Bank lending and systemic risk: a financial-real sector network approach with feedback. J. Financ. Stab. 38, 98–118 (2017). https://doi.org/10.1016/j.jfs.2017.08.006
Sun, J., Li, H., Huang, Q.H., He, K.Y.: Predicting financial distress and corporate failure: a review from the state-of-the-art definitions, modeling, sampling, and featuring approaches. Knowl.-Based Syst. 57, 41–56 (2014). https://doi.org/10.1016/j.knosys.2013.12.006
Sun, J., Zhou, M., Ai, W., Li, H.: Dynamic prediction of relative financial distress based on imbalanced data stream: from the view of one industry. Risk Manag. 21(4), 215–242 (2019). https://doi.org/10.1057/s41283-018-0047-y
Wang, S., Minku, L.L., Yao, X.: A systematic study of online class imbalance learning with concept drift. IEEE Trans. Neural Netw. Learn. Syst. 29(10), 4802–4821 (2018). https://doi.org/10.1109/TNNLS.2017.2771290
Wilson, R.L., Sharda, R.: Bankruptcy prediction using neural networks. Decis. Support Syst. 11(5), 545–557 (1994). https://doi.org/10.1016/0167-9236(94)90024-8
Acknowledgment
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001.
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Chaves, R.M., Rossi, A.L.D., Garcia, L.P.F. (2023). Financial Distress Prediction in an Imbalanced Data Stream Environment. In: García Bringas, P., et al. Hybrid Artificial Intelligent Systems. HAIS 2023. Lecture Notes in Computer Science(), vol 14001. Springer, Cham. https://doi.org/10.1007/978-3-031-40725-3_15
Download citation
DOI: https://doi.org/10.1007/978-3-031-40725-3_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-40724-6
Online ISBN: 978-3-031-40725-3
eBook Packages: Computer ScienceComputer Science (R0)