
Abstract
Automatic classification of software errors is an important tool for ensuring the quality of software being tested. By automating this process, testers can save time and effort, improve accuracy, gain a better understanding of errors, and improve communication between stakeholders. Software error clustering is an important concept in software testing that involves identifying and analyzing patterns in software errors or defects. The goal of error clustering is to understand the relationships between defects and identify the root causes of software errors, so that they can be prevented or corrected. The article provides a comprehensive survey of various techniques for software error clustering, including clustering algorithms. The author note that many of these techniques require significant expertise in software engineering and data analysis, and that there is a need for more user-friendly tools for software error clustering. This article presents an empirical research of software defect clustering, in which the author analyzes a large dataset of defects from a software development projects to identify several patterns in the defects, including clusters of related defects and common root causes.
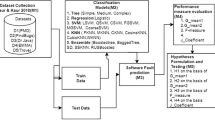
The proposed software method uses stack traces to cluster data about software testing errors. The method uses a kNN algorithm to analyze test results, allowing the user to assign the text of the software test result to specified categories. The kNN algorithm has a high accuracy rate of 0.98, which is better than other clustering methods like Support Vector and Naive Bayes. The proposed method has several advantages, including a single repository for test results, automatic analysis of software testing results, and the ability to create custom error types and subtypes for error clustering. The developed new software method allows multiple launches to be combined. If there are a large number of test suites, they are divided into smaller groups as they cannot be included in a single run. The test suites can then be combined into a single run to present the data on dashboards and generate reports. The method is integrated into software using a Docker container, which reduces the time and human resources required for error analysis. Overall, the method provides real-time monitoring of project status for managers and customers.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Kaur, H., Malhotra, R., Singh, H.: Software error clustering: a systematic review. IEEE Access 8, 98244–98261 (2020). https://doi.org/10.1109/ACCESS.2020.2996594
Ramalingam, S., Arumugam, S., Kannan, S.: An empirical study on error clustering in commercial software applications. Int. J. Comp. Sci. Netw. Secu. 14(7), 27–38 (2014)
Aggarwal, A., Williams, L., Nagappan, N.: An analysis of software error clustering in open-source software. Empir. Softw. Eng. 23(1), 582–625 (2018). https://doi.org/10.1007/s10664-017-9526-y
Xu, P., Fu, J., Su, Z.: Identifying error clustering in large-scale software systems: a study of 23 million lines of code. IEEE Trans. Software Eng. 42(4), 349–367 (2016). https://doi.org/10.1109/TSE.2015.2482201
Jalali, R., Wohlin, C.: A systematic review of software error clustering: trends, challenges, and opportunities. J. Syst. Softw. 85(6), 1213–1227 (2012). https://doi.org/10.1016/j.jss.2012.01.060
Sedighi, S., Rezaei, M.: Software error clustering: A systematic literature review. J. Syst. Softw. 165, 110591 (2020). https://doi.org/10.1016/j.jss.2020.110591
Truong, A., Hellström, D.: Clustering and Classification of Test Failures Using Machine Learning. Master’s thesis work. Department of Computer Science Faculty of Engineering LTH (2018)
Dang, Y., Wu, R., Zhang, H., Zhang, D., Nobel, P.: ReBucket: a method for clustering duplicate crash reports based on call stack similarity. In: 2012 34th International Conference on Software Engineering (ICSE), pp. 1084–1093. IEEE. Conference on Software Engineering (ICSE). IEEE (2012, June)
Moran, K., Linares-Vásquez, M., Bernal-Cárdenas, C., Vendome, C., Poshyvanyk, D.: Automatically discovering, reporting and reproducing android application crashes. In: 2016 IEEE international conference on software testing, verification and validation, pp. 33–44. IEEE (2016)
Abbineni, J., Thalluri, O.: Software defect detection using machine learning techniques. In: 2nd International Conference on Trends in Electronics and Informatics, IEEE. pp. 471–475 (2018)
Buchgeher, B.R.R., Klammer, G., Pfeiffer, M., Salomon, C., Thaller, H., Linsbauer, L.: Improving defect localization by classifying the affected asset using machine learning. In: International Conference on Software Quality, pp. 125–148 (2019)
Durelli, V.H.S., et al.: Machine Learning Applied to Software Testing: A Systematic Mapping Study. IEEE Transactions on Reliability, 1–24 (2019)
Karim, S., Leslie, H., Spits, H., Abdurachman, E., Soewito, B.: Software metrics for fault prediction using machine learning approaches. In: IEEE International Conference on Cybernetics and Computational Intelligence, pp. 19–23 (2017)
Alsmadi, I., Alda, S.: Test cases reduction and selection optimization in testing web services. I.J. Information Engineering and Electronic Business 5, 1–8 (2012)
Nasar, M.d., Johri, P., Chanda, U.: Software testing resource allocation and release time problem: a review. I.J. Modern Education and Computer Science 2, 48–55 (2014)
Mohapatra, S.K., Prasad, S.: Finding Representative Test Case for Test Case Reduction in Regression Testing. Int. J. Intell. Sys. Appli. (IJISA) 7(11), 60–65 (2015)
Ansari, G.A.: Detection of infeasible paths in software testing using UML application to gold vending machine.Int. J. Edu. Manage. Eng. (IJEME) 7(4), 21–28 (2017)
Mahmood, H., Sirshar, M.: A case study of web based application by analyzing performance of a testing tool. Int. J. Edu. Manage. Eng. (IJEME) 7(4), 51–58 (2017)
Nawaz, Z.: Proposal of Enhanced FDD Process Model. Int. J. Edu. Manage. Eng. (IJEME) 11(4), 43–50 (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Oleshchenko, L. (2023). Machine Learning Algorithms Comparison for Software Testing Errors Classification Automation. In: Hu, Z., Dychka, I., He, M. (eds) Advances in Computer Science for Engineering and Education VI. ICCSEEA 2023. Lecture Notes on Data Engineering and Communications Technologies, vol 181. Springer, Cham. https://doi.org/10.1007/978-3-031-36118-0_55
Download citation
DOI: https://doi.org/10.1007/978-3-031-36118-0_55
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-36117-3
Online ISBN: 978-3-031-36118-0
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)