
Abstract
Temporal knowledge graph completion (TKGC) is an important research task due to the incompleteness of temporal knowledge graphs. However, existing TKGC models face the following two issues: 1) these models cannot be directly applied to few-shot scenario where most relations have only few quadruples and new relations will be added; 2) these models cannot fully exploit the dynamic time and relation properties to generate discriminative embeddings of entities. In this paper, we propose a temporal-relational matching network, namely TR-Match, for few-shot temporal knowledge graph completion. Specifically, we design a multi-scale time-relation attention encoder to adaptively capture local and global information based on time and relation to tackle the dynamic properties problem. Then, we build a new matching processor to tackle the few-shot problem by mapping the query to few support quadruples in a relation-agnostic manner. Finally, we construct three new datasets for few-shot TKGC task based on benchmark datasets. Extensive experimental results demonstrate the superiority of our model over the state-of-the-art baselines.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Knowledge graphs (KGs) have proved their powerful strength in various downstream tasks, such as recommender system [18], information retrieval [12], concept discovery [6], and question answering [25], etc. KGs represent every fact with a triplet (s, r, o), where s, o are the subject entity and the object entity, and r is the relation between s and o. For example, \((Biden,\ President,\ USA)\) represents that Biden is the president of the USA. However, many facts are not static but highly ephemeral. For instance, \((Biden,\ President,\ USA)\) is true only after \((Trump,\ President,\ USA)\). Thus, by incorporating temporal information into KGs, temporal knowledge graphs (TKGs) represent each fact with a quadruple (s, r, o, t), where t represents a temporal constraint specifying the temporal validity of the fact. Due to the incompleteness of TKGs, temporal knowledge graph completion (TKGC) becomes an increasingly important research task. The task is to infer missing facts at specific timestamps based on the existing ones by answering queries such as \((Biden,\ President,\ ?,\ 2022)\).
Most current TKGC models perform the completion task by proposing a distance-based scoring function that incorporates the time representations. For example, TTransE [11] modifies the distance formula of TransE [2] by adding the temporal information, ATiSE [22] projects the representations of TKGs into the space of multi-dimensional Gaussian distributions, TeRo [21] represents time as a rotation in complex vector space, etc. However, these methods still do not perform well because they all face the few-shot relations problem and dynamic entity properties problem:
(1) Few-shot relations. Few-shot relations problem widely exists in real-world TKGs, bringing difficulties to complete temporal knowledge graph due to the following twofold. On the one hand, most relations in TKGs only have a small number of quadruples. This brings difficulties for conventional TKGC models to learn discriminative embeddings of entities, relations and timestamps from few quadruples, because these models usually require a lot of quadruples for training. As a result, they cannot accurately compute the distance between embeddings for completion task. On the other hand, some new relations will be added into TKGs consistently, so that conventional TKGC methods should finetune to update the learned embeddings to fit new relations. Recently, some studies, such as GMatching [19], MetaR [4], FSRL [24] and FAAN [15], have been proposed to tackle the few-shot problem, but these methods elaborated for static KGs cannot be applied to temporal KGs.

Two examples to illustrate the influence of neighbors on the target entity varying dynamically with the (a) relation and (b) time when completing the knowledge graph.
(2) Dynamic entity properties. Dynamic entity properties mean that the influence of neighbors on entity varies with the time and relation of different completion tasks. Figure 1 illustrates two examples of dynamic entity properties problem. Specifically, when we perform the completion task \((Biden,\ Make\ a\ visit,\ ?,\) 2022), the influence of entity USA on Biden is greater than the influence of entity Jill on Biden, as shown in Fig. 1(a). This is because the relation President shares the same work property as the relation \(Make\ a\ visit\), while the relation Wife reflects a different family property than the relation \(Make\ a\ visit\). Meanwhile, as shown in Fig. 3(b), the timespan affects the weights of different neighbors too. Despite that the entities Markel and Putin share the same relation Call, entity Biden weights more on its neighbor Putin than Markel due to the smaller timespan between Biden and Putin. Existing few-shot KGC methods [4, 15, 19, 24] ignore the dynamic properties of entities, resulting in inaccurate encoding of entities. Thus, how to jointly exploit the relation and time for TKGC remains a challenging problem.
To address the above problems, we propose a Temporal-Relational Matching network for few-shot temporal knowledge graph completion (TR-Match). Specifically, we firstly follow the few-shot settings [14, 17] to split and generate each task with support and query quadruples based on relation. Secondly, we propose a multi-scale time-relation attention encoder to learn the representations of support quadruples with dynamic properties. The encoder adaptively aggregates local neighbor information based on time and relation to obtain quadruple representations, and interacts the representations with global relational information among all support quadruples via a multi-head attention mechanism. Thirdly, we introduce a matching processor to deal with the few quadruples and unseen relations existing in few-shot scenario. The processor utilizes an attention-based LSTM to generate the informative representation of each query quadruple, and maps the query to few support quadruples in a relation-agnostic manner to deal with new relation by ranking the similarity between quadruples. Main contributions of this paper are summarized as follow:
-
We propose a novel few-shot TKGC model, namely TR-Match, to deal with the dynamic few-shot problem.
-
In TR-Match, the multi-scale time-relation attention encoder can dynamically encode quadruples based on the time and relation. Furthermore, the matching processor can map the query quadruples to support quadruples in a relation-agnostic manner to achieve few-shot TKCG task.
-
We create three few-shot TKG datasets and conduct extensive experiments to demonstrate the superiority of our model over state-of-the-art baselines.
2 Related Work
2.1 Temporal Knowledge Graph Completion Methods
Recently, many temporal knowledge graph embedding models have been proposed, which encode time information in their embeddings. TTransE [11] modifies the distance formula of TransE [2] to complete the temporal knowledge graph by adding the projection of temporal information and carrying out vector calculation. ATiSE [22] considers the temporal uncertainty during the evolution of entity/relation representations over time and projects the representations of TKGs into the space of multi-dimensional Gaussian distributions. TeRo [21] proposes scoring functions which incorporate time representations into a distance-based score function. DE-SimplE [5] uses diachronic entity embeddings to represent entities at different time steps and exploit the same score function as SimplE [8] to score the plausibility of a quadruple. Based on ComplEx [16], TComplEx [10] and TNTComplEx [10] analogously factorize the input TKG, which both models represent as a 4th-order tensor. TeLM [20] performs 4th-order tensor factorization of a TKG, using the asymmetric geometric product instead of complex Hermitian operator. These conventional TKGC methods do not consider the few-shot relations problem. Although FTMF [1] takes into account the few-shot relations problem, it focuses on temporal knowledge graph reasoning.
2.2 Few-shot Knowledge Graph Completion Methods
Recently, few-shot knowledge graph completion has attracted more and more research attention. GMatching [19] is the first one-shot knowledge graph completion model which consists an entity encoder to average ground aggregation of heterogeneous neighbors and a matching processor to measure the similarity between the support triple and the query triple. Based on GMatching, FSRL [24] uses an attention mechanism to aggregate neighbor information and a LSTM-based encoder to represent few-shot relations by support entity pairs. FAAN [15] is the first to propose a dynamic attention mechanism for one-hop neighbors adapting to the different relations which connect them. MetaR [4] focuses on transferring relation-specific meta to represent and fast update few-shot relations. MetaP [7] extracts the patterns effectively through a convolutional pattern learner and measures the validity of triples accurately by matching query patterns with reference patterns. GANA [13] puts more emphasis on neighbor information and accordingly proposes a gated and attentive neighbor aggregator. However, these models developed for static knowledge graphs cannot be applied to temporal knowledge graphs.
3 Preliminaries
In this section, we first present the notations of the temporal knowledge graph, then introduce the few-shot learning settings of our model, and finally define the few-shot temporal knowledge graph completion task in this work.
3.1 Temporal Knowledge Graph
Let \(\mathcal {E}\), \(\mathcal {R}\) and \(\mathcal {T}\) represent a finite set of entities, relations and timestamps, respectively. A TKG is a collection of facts represented as a set of quadruples \(G=\{(s, r, o, t)\} \subseteq \mathcal {E} \times \mathcal {R} \times \mathcal {E} \times \mathcal {T}\) in which \(s \in \mathcal {E}\) and \(o \in \mathcal {E}\) are subject entity and object entity respectively, \(r \in \mathcal {R}\) is the relation and \(t \in \mathcal {T}\) denotes the happened time of these facts.
3.2 Few-Shot Learning Settings
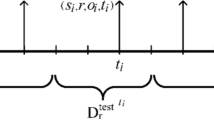
In this work, we classify the relations in TKG into two categories, frequent relations \(\mathcal {R}_{freq}\) and sparse relations \(\mathcal {R}_{sp}\), based on the frequency of their occurrence. Following GMamtching [19], the quadruples with the relations in \(\mathcal {R}_{freq}\) construct background knowledge graph \(G^{'}\) to get neighbor information. Each sparse relation corresponds to a few-shot relation. Following the standard few-shot learning settings [14, 17], we consider the completion problem of quadruples with sparse relation \(r \in \mathcal {R}_{sp}\) as a task, so as to access a set of tasks. In our problem, each task \(T_{r}\) corresponds to a sparse relation \(r \in \mathcal {R}_{sp}\), and has its own support/query set: \(T_{r} =\{\mathcal {S}_{r}, \mathcal {Q}_{r}\}\). Each support set \(\mathcal {S}_{r}\) only contains few support quadruples \(\{(s_{1}, r, o_{1}, t_{1}),(s_{2}, r, o_{2}, t_{2}),...,(s_{k}, r, o_{k}, t_{k})\}\), and \(|\mathcal {S}_{r}|=k\) denotes the few-shot size. Besides, query set \(\mathcal {Q}_{r}\) contains all query quadruples of relation r, including positive query quadruples \(\mathcal {Q}^{+}_{r} = \{(s_{i}, r, o^{+}_{i}, t_{i})|(s_{i}, r, o^{+}_{i}, t_{i}) \in G, o^{+}_{i} \in \mathcal {C}\}\) and corresponding negative query quadruples \(\mathcal {Q}^{-}_{r} = \{(s_{i}, r, o^{-}_{i}, t_{i})|(s_{i}, r, o^{-}_{i}, t_{i}) \notin G, o^{-}_{i} \in \mathcal {C}\}\). \(\mathcal {C}\) is the candidate entity set, and the candidate entity set in this work is composed of all entities, i.e. \(\mathcal {C} = \mathcal {E}\).

A few-shot learning settings example, where few-shot size is 3.

A few-shot TKGC task \(T_{consult}\) example.
Moreover, we divide all the tasks into two sets, meta-train set \(\mathbb {T}_{mtr}\) and meta-test set \(\mathbb {T}_{mte}\). Notably, the relations in \(\mathbb {T}_{mte}\) does not appear in \(\mathbb {T}_{mtr}\). And we leave out a subset of relations in \(\mathbb {T}_{mtr}\) as the meta-validation set \(\mathbb {T}_{mtv}\). Figure 2 illustrates a few-shot learning settings example.
3.3 Few-Shot Temporal Knowledge Graph Completion
In this work, our purpose is to predict the object entity o given the subject entity, relation and timestamp: (s, r, ?, t). In contrast to previous conventional TKGC methods that usually assume enough quadruples are available for training, this work studies the case where only few training quadruples are available. To be more specific, the goal is to rank the true object entity higher than other candidate entities in candidate entity set \(\mathcal {C}\) to complete the quadruples in query set, given only few support quadruples. Figure 3 is an example of task \(T_{consult}\).
Define \(\ell _{\varTheta }(\mathcal {Q}_{r}|\mathcal {S}_{r})\) as the ranking loss of task \(T_{r}\), \(\varTheta \) is the set of model parameters, the probabilistic optimization objective for this problem is given as:
4 Proposed Model
In this section, we give an introduction to our model in detail. This work aims to compute a similarity score \(\mathcal {P}_{\varTheta }((s_{q}, r, o_{q}, t_{q}),\mathcal {S}_{r})\) for each query \((s_{q}, r, o_{q}, t_{q})\) given the support set. To achieve this purpose, we propose a completion network including an encoding and matching step, as shown in Fig. 4. Specifically, the encoding step utilizes multi-scale time-relation attention encoder to dynamically encode entity and time to obtain the representations of support and query quadruples, then the matching step uses matching processor to calculate the similarity between support and query quadruples for TKGC.
4.1 Multi-scale Time-Relation Attention Encoder
As shown in Fig. 4, multi-scale time-relation attention encoder is designed to obtain the temporal-relational representations of support and query quadruples. In this module, we design an adaptive neighbor aggregator and utilize a multi-head attention to capture the local and global information in TKGs, respectively.

The framework of TR-Match: it first obtains representations of the support and query quadruples by multi-scale time-relation attention encoder, then captures the similarity score between support and query quadruples by matching processor.
4.1.1 Adaptive Neighbor Aggregator.
The influence of neighbors on one entity keeps changing based on the relevance of relation and the length of timespan. The neighbor with similar relation and smaller timespan put a higher weight on certain entity. However, existing few-shot KGC methods [15, 19, 24] cannot simultaneously consider the relation and timespan to obtain discriminative entity representations.
To tackle the above issue, we design a time-relation attention mechanism to dynamically assign neighbor weights. For every entity e, our model constructs the neighbors of e, i.e., \(\mathcal {N}_{e}=\{(e_{i}^{'}, r_{i}^{'}, t_{i}^{'})|,(e, r_{i}^{'}, e_{i}^{'}, t_{i}^{'}) \in G^{'}\}\), by searching for the quadruples in background knowledge graph \(G^{'}\) whose subject entity is e. \(e_{i}^{'}\) is the object entity which is regarded as a neighbor of e, \(r_{i}^{'}\) is the relation between e and \(e_{i}^{'}\), and \(t_{i}^{'}\) is the time of fact \((e, r_{i}^{'}, e_{i}^{'})\). Then, the weight \(\alpha _{i}\) of the neighbor \(e_{i}^{'}\) on entity e can be calculated as follows:
It can be seen from Eq. (2) that we assign the weight \(\alpha _i\) by jointly considering the relevance of different relations and the length of timespan. Specifically, the relevance of different relations can be calculated through \(\textbf{v}_r^T \textbf{W}_1 \textbf{v}_{r_{i}^{'}}\). \(\textbf{v}_{r}\) denotes the embedding of current task relation r, which can be randomly initialized as a d-dimension vector, i.e. \(\textbf{v}_{r} \in \mathbb {R}^{d}\). \(\textbf{W}_{1} \in \mathbb {R}^{d \times d}\) is a learnable parameter which is the similarity matrix to calculate the relevance between relations. The length of timespan can be measured via the inner product of paired time encoding, i.e., \(\langle \varPhi (t),\varPhi (t_{i}^{'})\rangle \). To ensure that the neighbors with smaller timespan have relatively higher weights, we refer to [23] to encode the time t as follows,
where \(\{\omega _{1},\omega _{2},...,\omega _{d}\}\) is a set of learnable parameters. With this encoding function, the neighbors with smaller timespan can receive higher weights on time factor, i.e., if \(|t-t^{'}_{i}|<|t-t^{'}_{j}|\), then \(\langle \varPhi (t),\varPhi (t_{i}^{'})\rangle > \langle \varPhi (t),\varPhi (t_{j}^{'})\rangle \).
Having obtained the weights of neighbors, we can learn entity e’s representation by adaptively aggregating neighbor information and its own information.
where \(\textbf{h}_{e}\) denotes e’s entity representation obtained from the adaptive neighbor aggregator. \(\textbf{v}_{e}\) is the embedding of entity e, which can be randomly initialized as a d-dimension vector, i.e. \(\textbf{v}_{e} \in \mathbb {R}^{d}\). \(\sigma (\cdot )\) denotes activation function of Relu. \(\mathbf {W_{2}}, \mathbf {W_{3}} \in \mathbb {R}^{d \times d}\) are trade-off parameters learned by MLP, which balance the importance between neighbor information and entity itself information.
4.1.2 Multi-head Attention for Support Set.
The entity representations obtained above consider only local neighbor information, but ignore global relational information in support set. Due to this, we use a multi-head attention module to generate informative representations of support set by refining the relational information of support set. We use the combination of the entity pair representations and time embedding as the input \(\textbf{U}_{r}\) of multi-head attention to better capture the temporal dependence between support quadruples:
where \(\textbf{u}^{r}_{i}\) is the initial representation of support quadruple \((s_{i}, r, o_{i}, t_{i})\). \(\textbf{h}_{s_{i}}\) and \(\textbf{h}_{o_{i}}\) are the representations of entities \(s_{i}\) and \(o_{i}\), respectively, obtained by the adaptive neighbor aggregator. \(\Vert \) denotes concatenation operation to gather paired representations \(\textbf{h}_{s_{i}}\) and \(\textbf{h}_{o_{i}}\). Moreover, we take the time embedding \(\varPhi (t_{i})\) as positional encoding to capture the temporal dependence of support quadruples. After that, we can obtain the support quadruple representations via the following multi-head attention layer,
where \(\textbf{Z}_{r} = [\textbf{z}^{r}_{1}, \textbf{z}^{r}_{2},...,\textbf{z}^{r}_{k}] \in \mathbb {R}^{k \times 2d}\) is the support quadruple representations. \(\textbf{W}^{O} \in \mathbb {R}^{2Nd\times 2d}\) is parameter matrix and N is the number of heads. \(\textbf{Q}_{i} = \textbf{U}_{r}\textbf{W}_{i}^{Q},\ \textbf{K}_{i} = \textbf{U}_{r}\textbf{W}_{i}^{K},\ \textbf{V}_{i} = \textbf{U}_{r}\textbf{W}_{i}^{V}\) are the ‘queries’, ‘keys’ and ‘values’ of the ith head attention. \(\textbf{W}_{i}^{Q},\textbf{W}_{i}^{K},\textbf{W}_{i}^{V} \in \mathbb {R}^{2d\times 2d}\) are the projection matrices of the ith head attention. The multi-head attention mechanism fully interacts with the global relational information of the support set.
4.2 Matching Processor
Conventional TKGC models are mainly encountered with two issues: (1)They require a large number of quadruples to train usually learn poor embeddings under few-shot scenario that most relations only have a few quadruples. (2)They should be finetuned to adapt newly added relations since the learned embeddings are unavailable to update after training. To this end, we propose a matching processor that includes an embedding step and a matching step to address the poor embeddings and new relation problems, respectively.
In the embedding step, we choose LSTM to improve the quality of query embedding because LSTM can selectively capture the feature impact of support set on query [17]. Moreover, we argue that different support quadruples have different weights for a query because of the semantic divergence existing in support quadruples. Therefore, we design an Att module based on attention mechanism to dynamically aggregate support quadruples. Finally, we combine LSTM and Att module to generate informative representation \({h}_{i}\) of query quadruple as follows:
where \({\text {LSTM}}(\cdot )\) is a standard \({\text {LSTM}}\) cell with input \(\textbf{q}_{r}\), hidden state \(p_{i-1}\) and cell state \(c_{i-1}\), and \(\textbf{q}_{r}=(\textbf{h}_{s_{q}}\Vert \textbf{h}_{o_{q}})+\varPhi (t_{q})\) is the initial representation of query \((s_{q}, r, o_{q}, t_{q})\). The hidden state \(p_{i-1}\) regarded as a hidden representation of query \((s_{q}, r, o_{q}, t_{q})\) can be calculated via the Att module as follows:
where \(\beta _{j}\) is the weight of support quadruple \((s_{j},r,o_{j},t_{j})\) and \(\textbf{z}^{r}_{j}\) is the representation of support quadruple \((s_{j},r,o_{j},t_{j})\) obtained by Eq. (7). After l layer \({\text {LSTM}}\), we can obtain the representation \(h_{l}\) of query \((s_{q}, r, o_{q}, t_{q})\).
In the matching step, our goal is to rank the query quadruples to find the best candidate object entity with respect to a certain relation, so as to complete the missing quadruples. Considering that the new relation will be added to TKGs, it is not suitable to complete quadruples by calculating the distance between subject entity, relation and object entity. This is because new relation unseen in the training process cannot be presented in testing process without finetuning. To address this, we aim to directly achieve the completion task in an end-to-end network via a relation-agnostic matching. Specifically, we rank the query quadruples via the similarity score between query and support set which can be defined as the sum of inner product between quadruple representations:
where \(h_{l}\) and \(\textbf{z}^{r}_j{}\) are query and support quadruple representations, respectively. It is worth noting that, the representations of query quadruples learned from Eq. (8) do not embed relation directly, meaning that each query representation is relation-agnostic. Thus, we match the quadruples only based on the similarity of entities and timespans between query and support quadruples. As a result, given a new relation, our matching process can find the best candidate object entity by selecting a query quadruple similar to support quadruples with new relation.
4.3 Loss Function and Training
We train the model on meta-training task set \(\mathbb {T}_{mtr}\). We encourage high similarity scores for positive pairs and low similarity scores for negative pairs. The objective function is a hinge loss defined as follow:
where \([x]_{+} = max(0, x)\) is standard hinge loss, and \(\lambda \) is a hyperparameter represents safety margin distance. The detail of the training process is shown in Algorithm 1.

5 Experiments
In this section, we begin with an introduction about how to construct datasets for few-shot settings. Then, we provide an overview of baselines and implement details. Finally, we conduct a series of experiments and provide an analysis of the experimental results.
5.1 Datasets
Since conventional temporal knowledge graph datasets, such as ICEWS14, ICEW S05-15 and ICEWS18 [3], are not suitable for few-shot settings, we construct three new datasets ICEWS14-few, ICEWS05-15-few and ICEWS18-few based on conventional datasets for few-shot TKGC. The details of each dataset are illustrated in Table 1. Following GMatching [19], we construct each dataset by selecting appropriate number of sparse relations based on the size of corresponding conventional dataset as follows:
ICEWS14-few. To construct ICEWS14-few dataset, we select the relations with number less than 200 but greater than 10 quadruples as sparse relations \(\mathcal {R}_{sp}\), and the relations with number more than 200 are considered as frequent relations \(\mathcal {R}_{freq}\) from ICEWS14 dataset. Then, we use 92/11/11 task relations for \(\mathbb {T}_{mtr}\)/\(\mathbb {T}_{mtv}\)/ \(\mathbb {T}_{mte}\).
ICEWS05-15-few. To construct ICEWS05-15-few dataset, we select the relations with less than 500 but more than 50 quadruples as the sparse relations \(\mathcal {R}_{sp}\) from ICEWS05-15 dataset, and the relations in greater than 500 as frequent relations \(\mathcal {R}_{freq}\) from ICEWS05-15 dataset. Then, we use 81/9/9 task relations for \(\mathbb {T}_{mtr}\)/\(\mathbb {T}_{mtv}\)/ \(\mathbb {T}_{mte}\).
ICEWS18-few. ICEWS18-few dataset is constructed in the same way as ICEWS05-15-few. The frequency interval of \(\mathcal {R}_{sp}\) and \(\mathcal {R}_{freq}\) in ICEWS18-few is the same as ICEWS05-15-few. We use 81/9/9 task relations for \(\mathbb {T}_{mtr}\)/\(\mathbb {T}_{mtv}\)/ \(\mathbb {T}_{mte}\).
5.2 Baselines
Since there is no few-shot TKGC model focusing on the completion task for comparison, we select two kinds of baseline models for comparison in this experiment: few-shot KGC models and conventional TKGC models. (1) As for few-shot KGC models, we adopt the following state-of-the-art models as baselines: GMatching [19], MetaR [4], FSRL [24] and FAAN [15]. Since all few-shot KGC models are static and cannot be generalized into dynamic scenario, we provide these models with all the quadruples in the original datasets and neglect time information, i.e., neglecting t in (s, r, o, t). (2) As for conventional TKGC models, we adopt the following state-of-the-art models for comparison: DE-SimpIE [5], TNTComplEx [10], ATISE [22], TeRo [21] and TeLM [20]. Following GMatching, when evaluating these conventional TKGC models, we use the quadruples in background knowledge graph \(G^{'}\), the quadruples in \(\mathbb {T}_{mtr}\) and the quadruples in support set of \(\mathbb {T}_{mtv}\) and \(\mathbb {T}_{mte}\) as the train set.
5.3 Implementation
In our model, all entities and relations embeddings are initialized randomly with dimension of 100. The few-shot size k is set to 3 for the following experiments. We select the best hyperparameters that can achieve the highest MRR in validation set. The maximum number of local neighbors in adaptive neighbor aggregator is set to 50 for all datasets. In addition, we use LSTM in matching processor, the dimension of hidden state is 200 in our experiments. The number of layers of LSTM is set to 4 for ICEWS14-few and ICEWS05-15-few, and 5 for ICEWS18-few. The margin distance \(\lambda \) is set to 10. We implement all experiments with PyTorch and use Adam optimizer [9] to optimize model parameters with a learning rate of 0.001.
For models Gmatching, MateR, FSRL and FAAN, the few-shot size k is the same as our model, and the other parameters use the optimal parameters from the original papers. For models DE-SimpIE, TNTComplEx, ATiSE, TeRo, TeLM, we refer to the best hyperparameter settings of baseline methods reported in their original papers. We report two standard evaluation metrics: MRR and Hit@N. MRR is the mean reciprocal rank and Hits@N is the proportion of correct entities ranked in the top N, with N = 1,5,10.
5.4 Performance Comparison
5.4.1 Experimental Comparison with Baselines.
We compare TR-Match with nine baselines on ICEWS14-few, ICEWS05-15-few and ICEWS18-few datasets, respectively, to evaluate the effectiveness of TR-Match. The performances of all models are reported in Table 2, where the best results are highlighted in bold, and the best performance of the two kinds of baselines on different datasets is underlined. It can be seen that our model outperforms all the baselines by achieving a higher MRR and Hits@1/5/10.
Compared to the few-shot KGC baselines, TR-Match consistently outperforms the best few-shot KGC baseline, i.e., FSRL, by achieving 3.0/13.4/18.1% improvement of MRR metric on ICEWS14-few/ICEWS05-15-few/ICEWS18-few datasets, respectively. This is because, compared to few-shot KGC models ignoring the temporal information, TR-Match can jointly and adaptively take the relation and time into consideration to aggregate local information, resulting in more accurate entity representations. Moreover, few-shot KGC models assume that different support quadruples are of equivalent importance to each query, while TR-Match can adaptively assign weights to support quadruples via matching process to capture the discriminative information.
Compared to the conventional TKGC baselines, TR-Match achieves significant improvements over the best results of conventional TKGC baselines by obtaining 16.7/34.13/15.8% gains of MRR metric on ICEWS14-few/ICEWS05-15-few/ICEWS18-few datasets, respectively. This is because conventional TKGC models requiring large-scale training data fail to achieve satisfying performance on such three datasets with few-shot relations. By contrast, our model is powerful to handle few-shot data by calculating the similarity between quadruples in matching processor.

The MMR of TR-Math and FSRL for each relation on ICEWS14-few and ICEWS05-15-few.
5.4.2 Comparison over Different Relations.
To demonstrate the superiority of our model in more detail, we set up comparative experiments on ICEWS14-few and ICEWS05-15-few with different relations. In this experiment, we compare our proposed TR-Match with the best few-shot static KGC baseline FSRL. The experimental results are shown in Fig. 5, where Relation ID represents a class of relation. On ICEWS14-few, our TR-Match outperforms FSRL in MRR metric with 8 out of 11 relations. On ICEWS05-15-few, our TR-Match outperforms FSRL in MRR metric with 8 out of 9 relations. Experimental results indicate that TR-Match is more powerful to learn discriminative quadruple representations by taking the advantage of time encoding in both encoding step and matching step.
5.5 Ablation Study
We perform experiments on all the datasets with several variants of our proposed model to provide a better understanding of the contribution of each module to our proposed model. The ablative results are shown in Table 3. In TR-Match(v1), we use the neighbor encoder proposed by GMatching [19] instead of our proposed adaptive neighbor aggregator to encode entities. Experiments demonstrate that dynamically aggregating neighbors based on relation and time can improve the model performance compared to aggregating neighbors with fixed weights. In TR-Match(v2), we remove multi-head attention from our model. The experimental results demonstrate that multi-head attention can stably boost the performance of our model by capturing the global relational information for support set. In TR-Match(v3), we replace Att in matching processor with mean-pooling. Experimental results show that Att can improve our model performance by adaptively aggregating support features compared to fixed support weights.

Impact of few-shot size on ICEWS14-few and ICEWS05-15-few.
5.6 Impact of Few-shot Size
In this subsection, we study the impact of few-shot size k. We perform experiments on TR-Match, FSRL [24], and FAAN [15] models on ICEWS14-few and ICEWS05-15-few datasets, and set different k values from a subset \(\{2,3,4,5,6,7\}\). Experimental results in Fig. 6 demonstrate that: (1) The performance of TR-Match is always better than the comparative models, indicating the capability of our proposed method in few-shot TKGC. (2) TR-Match obtains relatively stable boosts compared to FSRL and FAAN, which shows the robustness of TR-Match to few-shot size.
6 Conclusion
In this paper, we propose a new few-shot temporal knowledge graph completion model, i.e., TR-Match, which consists of an encoding step and a matching step. In the encoding step, we can dynamically aggregate the local and global information to generate temporal-relational representations, so as to capture the dynamic properties in completion task. In the matching step, we can map the query to few support quadruples in a relation-agnostic manner to overcome the few-shot problem. Additionally, we construct three datasets suitable for few-shot learning based on public datasets. The experimental results show the superiority of our model and the effectiveness of each component in our model.
References
Bai, L., Zhang, M., Zhang, H., Zhang, H.: FTMF: Few-shot temporal knowledge graph completion based on meta-optimization and fault-tolerant mechanism. In: World Wide Web, pp. 1–28 (2022)
Bordes, A., Usunier, N., García-Durán, A., Weston, J., Yakhnenko, O.: Translating embeddings for modeling multi-relational data. In: NeurIPS, pp. 2787–2795 (2013)
Boschee, E., Lautenschlager, J., O’Brien, S., Shellman, S., Starz, J., Ward, M.: ICEWS Coded Event Data (2015). https://doi.org/10.7910/DVN/28075
Chen, M., Zhang, W., Zhang, W., Chen, Q., Chen, H.: Meta relational learning for few-shot link prediction in knowledge graphs. In: EMNLP-IJCNLP, pp. 4217–4226 (2019)
Goel, R., Kazemi, S.M., Brubaker, M.A., Poupart, P.: Diachronic embedding for temporal knowledge graph completion. In: AAAI, pp. 3988–3995 (2020)
Jeon, I., Papalexakis, E.E., Faloutsos, C., Sael, L., Kang, U.: Mining billion-scale tensors: Algorithms and discoveries. VLDB J. 25(4), 519–544 (2016). https://doi.org/10.1007/s00778-016-0427-4
Jiang, Z., Gao, J., Lv, X.: Metap: Meta pattern learning for one-shot knowledge graph completion. In: SIGIR, pp. 2232–2236 (2021)
Kazemi, S.M., Poole, D.: Simple embedding for link prediction in knowledge graphs. NeurIPS, pp. 4289–4300 (2018)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. CoRR (2015)
Lacroix, T., Obozinski, G., Usunier, N.: Tensor decompositions for temporal knowledge base completion. In: ICLR (2019)
Leblay, J., Chekol, M.W.: Deriving validity time in knowledge graph. WWW, pp. 1771–1776 (2018)
Liu, Z., Xiong, C., Sun, M., Liu, Z.: Entity-duet neural ranking: Understanding the role of knowledge graph semantics in neural information retrieval. In: ACL, pp. 2395–2405 (2018)
Niu, G., et al.: Relational learning with gated and attentive neighbor aggregator for few-shot knowledge graph completion. In: SIGIR, pp. 213–222 (2021)
Ravi, S., Larochelle, H.: Optimization as a model for few-shot learning. In: ICLR (2017)
Sheng, J., et al.: Adaptive attentional network for few-shot knowledge graph completion. In: EMNLP, pp. 1681–1691 (2020)
Trouillon, T., Welbl, J., Riedel, S., Gaussier, É., Bouchard, G.: Complex embeddings for simple link prediction. In: ICML, pp. 2071–2080 (2016)
Vinyals, O., Blundell, C., Lillicrap, T., Wierstra, D., et al.: Matching networks for one shot learning. NeurIPS, pp. 3637–3645 (2016)
Wang, X., Wang, D., Xu, C., He, X., Cao, Y., Chua, T.S.: Explainable reasoning over knowledge graphs for recommendation. In: AAAI, pp. 5329–5336 (2019)
Xiong, W., Yu, M., Chang, S., Guo, X., Wang, W.Y.: One-shot relational learning for knowledge graphs. In: EMNLP, pp. 1980–1990 (2018)
Xu, C., Chen, Y.Y., Nayyeri, M., Lehmann, J.: Temporal knowledge graph completion using a linear temporal regularizer and multivector embeddings. In: NAACL, pp. 2569–2578 (2021)
Xu, C., Nayyeri, M., Alkhoury, F., Yazdi, H.S., Lehmann, J.: Tero: A time-aware knowledge graph embedding via temporal rotation. In: COLING, pp. 1583–1593 (2020)
Xu, C., Nayyeri, M., Alkhoury, F., Yazdi, H., Lehmann, J.: Temporal knowledge graph completion based on time series gaussian embedding. In: ISWC, pp. 654–671 (2020)
Xu, D., Ruan, C., Körpeoglu, E., Kumar, S., Achan, K.: Inductive representation learning on temporal graphs. ArXiv (2020)
Zhang, C., Yao, H., Huang, C., Jiang, M., Li, Z.J., Chawla, N.: Few-shot knowledge graph completion. In: AAAI, pp. 3041–3048 (2020)
Zhang, Y., Dai, H., Kozareva, Z., Smola, A.J., Song, L.: Variational reasoning for question answering with knowledge graph. In: AAAI, pp. 1–8 (2018)
Acknowledgements
This work was partially supported by the National Natural Science Foundation of China: 61976051, U19A2067, and the Major Key Project of PCL: PCL2022A03
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Gong, X., Qin, J., Chai, H., Ding, Y., Jia, Y., Liao, Q. (2023). Temporal-Relational Matching Network for Few-Shot Temporal Knowledge Graph Completion. In: Wang, X., et al. Database Systems for Advanced Applications. DASFAA 2023. Lecture Notes in Computer Science, vol 13944. Springer, Cham. https://doi.org/10.1007/978-3-031-30672-3_52
Download citation
DOI: https://doi.org/10.1007/978-3-031-30672-3_52
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-30671-6
Online ISBN: 978-3-031-30672-3
eBook Packages: Computer ScienceComputer Science (R0)