
Abstract
In this paper, we propose an embarrassingly simple yet highly effective adversarial domain adaptation (ADA) method. We view ADA problem primarily from an optimization perspective and point out a fundamental dilemma, in that the real-world data often exhibits an imbalanced distribution where the large data clusters typically dominate and bias the adaptation process. Unlike prior works that either attempt loss re-weighting or data re-sampling for alleviating this defect, we introduce a new concept of go-getting domain labels (Go-labels) to replace the original immutable domain labels on the fly. The reason why call it as “Go-labels” is because “go-getting” means able to deal with new or difficult situations easily, like here Go-labels adaptively transfer the model attention from over-studied aligned data to those overlooked samples, which allows each sample to be well studied (i.e., alleviating data imbalance influence) and fully unleashes the potential of adaption model. Albeit simple, this dynamic adversarial domain adaptation framework with Go-labels effectively addresses data imbalance issue and promotes adaptation. We demonstrate through theoretical insights, empirical results on real data as well as toy games that our method leads to efficient training without bells and whistles, while being robust to different backbones.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

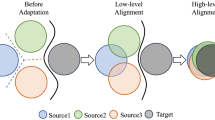

1 Introduction
Most deep models rely on huge amounts of labeled data and their learned features have proven brittle to data distribution shifts [58, 68]. To mitigate the data discrepancy issue and reduce dataset bias, unsupervised domain adaptation (UDA) is extensively explored, which has access to labeled samples from a source domain and unlabeled data from a target domain. Its objective is to train a model that generalizes well to the target domain [8, 10, 14, 15, 19, 24, 25, 28].
As a mainstream branch of UDA, adversarial domain adaptation (ADA) approaches leverage a domain discriminator paired with a feature generator to adversarially learn a domain-invariant feature [9, 11, 15, 35, 50]. For the domain discriminator training, all source data are equally taken as one domain (e.g., positive ‘1’) while target data as another one (e.g., negative ‘0’) [11, 15, 35]. However, this fixed positive-negative separation neglects a fact that most real-world data exhibit imbalanced distributions [12, 13]: the clusters with abundant examples (i.e., large clusters) may swamp the clusters with few examples (i.e., small clusters). Such imbalanceness contains two aspects, intra-class long-tailed distribution [34, 44] and inter-class long-tailed distribution [55, 64], and is widely existed in many UDA benchmarks. For example, in DomainNet [42], the “dog” class in the “clipart” domain has 70 image samples while has 782 image samples in the “real” domain. The majority “bike” samples (90%) in “Amazon” domain in Office31 [46] have no background scene (empty) while minority “bike” samples have real-world background instead.
On the other hand, deep neural networks (DNNs) typically learn simple patterns first before memorizing. In other words, DNN optimization is content-aware, taking advantage of patterns shared by multiple training examples [2]. Therefore, in the process of domain adaptation, the large domain clusters would dominate the optimization of domain discriminator, so that bias its decision boundary and hinder the effective adaptation. As shown in Fig. 1(a), only the large clusters of two domains (i.e., two large circles) have been pulled close as the adaptation goes on, but those minority clusters (four small circles) are still under-aligned. This bias the optimization of domain discriminator so that misleads the feature extractor to learn unexpected domain-specific knowledge from large clusters. As a result, the adapted model still can not correctly classify these under-explored samples (marked by “misclassify”).

Motivation illustration. (\(\times \), \(\triangle \)) denote two different classes, and (blue, orange) color mean different domains. (a) Previous DA methods tend to be dominated by those large clusters and neglects small clusters, which will bias the domain discriminator optimization, leading to a sub-optimal adaptation accuracy. (b) Our method attempts to fully leverage both large and small data clusters for alignment, to enhance the domain-invariant representation learning, and thus achieving a better adaptation performance on the target set. (Color figure online)
In this paper, we attempt to design an optimization strategy to progressively take full advantage of both large and small data clusters across different domains, like shown in Fig. 1(b). In this way, the domain-invariant representation learning could be gradually promoted, and the potential of adaptation model will be unleashed, leading a satisfied classification performance. Our study is different from existing methods that purely designed for long-tailed classification [22, 69, 71] in application scenarios and exhibits advantages in domain-agnostic representation learning. This problem is challenging, but valuable and meaningful for DA task.
There also exists few works have noticed the distribution imbalance issues in the domain adaptation task, and try to tackle it by re-weighting (IWAN [61, 70]), data re-sampling (RADA [24]), or data augmentation (Domain Mixup [65]). Differently, our paper focuses on a more general imbalance setting, which contains two aspects of long-tailed intra-class and inter-class distribution. Besides, we try to achieve a high-powered optimization strategy to empower DA model study each sample well to promote distribution alignment without any cost increase.
To this end, we propose to replace the original immutable domain labels with an adjustable and importance-aware alternative, dubbed Go-getting Domain Labels (Go-labels). Its core idea is to adaptively reduce the importance of these dominated training data that have been aligned, and timely encourage the domain discriminator to pay more attention to those easy-to-miss minority clusters, which ensures each sample can be well studied. In the implementation, we assign a go-getting domain label (Go-label) to each sample according to its own optimization situation: If one sample has ambiguous domain predictions (e.g., \(\sim \)0.5) when passing through domain discriminator, it means such sample has been well studied, or said, the learned feature w.r.t this sample has been domain-invariant. Then, we enforce a relaxation constraint on it through changing its groundtruth (i.e., directly taking 0.5 as its new domain label), so as to reduce its optimization importance. Our contributions are summarized as follows,
-
We revisit domain adaptation problem from an optimization perspective, and pinpoint the training defect caused by imbalanced data distributions issue.
-
To alleviate this issue, we propose a novel concept of go-getting domain labels (Go-labels) to achieve a dynamic adaptation, which allows each sample to be well studied and reduces long-tailed influence, so as to promote domain alignment for DA without any increase in computational cost.
-
As a byproduct, our work also provides a new perspective to understand the task of adaptation, and gives theoretical insights about the effectiveness of dynamic training strategy with Go-labels.
We thoroughly study the proposed Go-labels with several toy cases, and conduct experiments on multiple domain adaptation benchmarks, including Digit-Five, Office-31, Office-Home, VisDA-2017, and large-scale DomainNet, upon various baselines, to show it is effective and reasonable.
2 Related Work
Unsupervised Domain Adaptation. Recent UDA works focus on two mainstream branches, (1) moment matching and (2) adversarial training. The former works typically align features across domains by minimizing some distribution similarity metrics, such as Maximum Mean Discrepancy (MMD) [7, 36, 62] and second-/higher-order statistics [28, 42, 54]. Adversarial domain adaptation (ADA) methods have achieved superior performance and this paper also focuses on it. The pioneering works of DANN [15] and ADDA [59] both employ a domain discriminator to compete with a feature extractor in a two-player mini-max game. CDAN [35] improves this idea by conditioning domain discriminator on the information conveyed by the category classifier. MADA [41] uses multiple domain discriminators to capture multi-modal structures for fine-grained domain alignment. Recent GVB [11] gradually reduces the domain-specific characteristics in domain-invariant representations via a bridge layer between the generator and discriminator. MCD [49], STAR [37] and Symnet [72] all build an adversarial adaptation framework by leveraging the collision of multiple object classifiers. Unfortunately, all these methods ignore the imbalanced distribution issue in DA.
Imbalanced Domain Adaptation. Several prior works have noticed the distribution imbalance issues in domain-adversarial field, and provided rigorous analysis and explanations [23, 26, 55, 64, 74]. In particular, IWAN [70] leverages the idea of re-weighting for adaptation, and RADA [24] enhances the ability of domain discriminator in DA via sample re-sampling and augmentation. Besides, the works of [30, 55, 64] focus on the subpopulation shift issue (partial DA), where the source and target domains have imbalanced label distribution. Differently, our paper focuses on the more general covariate shift setting in DA, which contains two aspects of long-tailed intra-class and inter-class distribution. Such imbalanced problems are widely existed in the existing UDA benchmarks.
Adversarial Training. Our work is also related to the researches which aim to leverage or modify the discriminator output to further augment the standard GAN training [1, 3, 17, 18, 39, 52, 63]. Their core idea is to distill useful information from the discriminator to further regularize generator to obtain a better generation performance. Although our work shares a similar idea of enhancing adversarial training, the main contributions and target task are different.
3 Adversarial Domain Adaptation with Go-labels
3.1 Prior Knowledge Recap and Problem Definition
To be self-contained, we first simply review the problem formulation of adversarial domain adaptation (ADA). Taking classification task as example, we denote the source domain as \(\mathcal {D}_S=\{({x}_i^s,y_i^s,d_i^s) \}_{i=1}^{N_s}\) with \(N_s\) labeled samples covering C classes, \(y_i^s \in [0, C - 1]\). \(d_i^s\) is the domain label of each source sample and it always equals to ‘1’ during the training [15, 35]. The target domain is similarly denoted as \(\mathcal {D}_T=\{{x}_j^t, d_i^t \}_{j=1}^{N_t}\) with \(N_t\) unlabeled samples that belong to the same C classes, \(d_i^t\) denotes the domain label of each target sample and it always equals to ‘0’ so as to construct a ‘0–1’ pair with source samples for adversarial optimization. Most ADA algorithms tend to learn domain-invariant representations, by adversarially training the feature extractor and domain discriminator in a minmax two-player game [11, 15, 21, 35]. They typically use classification loss \(\mathcal {L}_{cls}\) (i.e., cross-entropy loss \(\mathcal {L}_{ce}\)) and domain adversarial loss \(\mathcal {L}_{adv}\) (i.e., binary cross-entropy loss \(\mathcal {L}_{bce}\)) for training,
where F, C, D represents the feature extractor, the category classifier, and the domain discriminator, respectively. They are shared across domains. The total optimization objective is described as (\(\min \limits _{D} \mathcal {L}_{adv} + \min \limits _{F, C} \mathcal {L}_{cls} - \mathcal {L}_{adv}\)). Note that, a gradient reversal layer (GRL) [15] is often used to connect feature extractor F and domain discriminator D to achieve the adversarial function by multiplying the gradient from D by a certain negative constant during the back-propagation to the feature extractor F.
Problem Definition of Imbalanced Data Distributions in DA. This paper focuses on the general covariate shift setting following [51, 53] in the DA field, and assumes each domain presents an “imbalanced” data distributions. Suppose a source/target domain \(\{(x_i,y_i)\}_{i=1}^n\) drawn i.i.d. from an imbalanced distribution P(x, y). Such imbalanceness comprises two aspects: 1). the marginal distribution P(y) of classes are likely long-tailed, i.e., inter-class long-tailed. 2). the data distribution within each class is also long-tailed, i.e., intra-class long-tailed distribution. We expect to learn a well adapted model \(F(\cdot ;\theta )\) with adversarial DA technique equipped with a domain discriminator \(D(\cdot ;\omega )\), to learn domain-invariant representations.

Red and green points denote source and target domain data, respectively. The darker the color, the better the alignment, the more possible to be mis-classified by domain discriminator. (Color figure online)
Motivation Re-clarification. Here we look into whether the imbalanced data distribution issue actually hinders the effective ADA training, through a t-SNE [48] visualization results. This experiment is conducted on Office31 [46] (W\(\rightarrow \)A setting) with the baseline of DANN [15]. We count the number of times each sample was misclassified by the domain discriminator during the DA training, and use this number as the color parameter. The darker the color, the better the alignment, the more possible to be mis-classified by domain discriminator. From Fig. 2, we see that, there obviously exists an imbalance situation with training going on, where some samples (surrounded by a blue circle) have been well aligned/studied by the domain discriminator (the darker the color, the better the alignment), but some samples are still under-studied or not aligned well. Therefore, treating those aligned and not aligned training data in different ways to promise each sample being well explored to alleviate imbalance influence is urgently required.
3.2 Proposed Go-getting Domain Labels
To alleviate the optimization difficulty caused by imbalanced data distributions and thus enhance the domain-invariant representation learning, we introduce a dynamic adversarial domain adaptation framework with the proposed go-labels: when calculating the domain adversarial loss on a mini-batch that contains both source and target domain samples, we replace the original immutable domain labels of samples (source as ‘1’, target as ‘0’) with an adjustable domain labels (i.e., Go-labels) on the fly. In formula, we modify the domain adversarial loss \(\mathcal {L}_{adv}\) of Eq. 1 to
where \({g_i^s}\) and \({g_i^t}\) are the updated go-getting domain labels for i-th source sample and i-th target sample in the mini-batch, they are no longer a fixed ‘1’ or ‘0’, but become adjustable and adaptive. Intuitively, a reliable metric to distinguish the well-aligned large cluster data and not aligned small cluster data is needed for the new updated domain labels assignment/decision.
Measurement of Alignment. The critic, domain discriminator D, can be seen as an online scoring function for data: one sample will receive a higher score (\(\sim \)1) if its extracted feature is close to the source distribution, and a lower score (\(\sim \)0) if its extracted feature is close to the target distribution. Thus, we directly take the predicted domain results of domain discriminator, denoted as \(\widetilde{d^s}\)/\(\widetilde{d^t}\), as the alignment measurement metric for each source/target sample. For example, if the domain discriminator prefers to classify a source sample (\(d_i^s=1\)) as target data, i.e., \(\widetilde{d_i^s} \rightarrow 0\), we believe the learned feature w.r.t this sample has been well aligned and is fake enough to fool domain discriminator. In this way, we could online distinguish the well-aligned and not aligned data during training.
Go-getting Domain Labels Update. In the implementation, we merge the alignment measurement (i.e., well-aligned samples selection) and domain label update into a single step. Formally, we leverage a non-parametric mathematical rounding \(Round(\cdot )\) to modify the original domain labels \({d_i^s}=1\), \({d_i^t}=0\) of i-th source, target sample according to their predicted domain results \(\widetilde{d_i^s}\), \(\widetilde{d_i^t}\):
where go-getting domain labels of \({g_i^s}\), \({g_i^t}\) are dynamic and adjustable, depending on the different domain prediction results \(\widetilde{d_i^s}\), \(\widetilde{d_i^t}\). The original domain label \({d_i^s}=1\), \({d_i^t}=0\) can be taken as groundtruth, and their intermediate decision boundary \(({d_i^s} + {d_i^t}) / 2\) = 0.5 can be regarded as a threshold to automatically update go-getting domain labels through \(Round(\cdot )\). That means that if the domain prediction result of a source sample is lower than the threshold of 0.5, i.e., \(\widetilde{d_i^s} < 0.5\), we believe the learned feature w.r.t this sample has been well aligned and is fake enough to fool domain discriminator.
It can be see that the \(Round(\cdot )\) function could keep the raw domain labels unchanged for those correctly classified samples by D. They have not been well aligned (i.e., \(\widetilde{d_i^s}> 0.5\) and \(\widetilde{d_i^t}< 0.5\)). We only update the domain labels for these mis-classified well-aligned samples (i.e., \(\widetilde{d_i^s}\le 0.5\) and \(\widetilde{d_i^t}\ge 0.5\)), which reduces the optimization importance of these aligned training data and encourage the domain discriminator to pay more attention to those not aligned data.
Implementation in PyTorch. A simple PyTorch-like [40] pseudo-code snippet is shown below. The dynamic adversarial DA with go-getting domain labels (Go-labels) modification amounts simply to the addition of lines 9, 10 of the example code, which indicates its ease of implementation and generality.

Discussion: Why use Rounding? Rounding-based dynamic domain labels only reduce the importance for these well-aligned (i.e., mis-classified by discriminator) majority samples progressively, while keep unchanged for those not aligned minority data. This design makes the “dynamically change” of go-getting domain labels more “targeted”. If no rounding, the real-valued soft Go-labels will be always affected by the probability scores of domain discriminator, even the discriminator has not yet been well-trained at early stage. In short, the physical meanings behind Go-labels is to softly reduce the importance for these dominated majority samples on the fly while progressively transferring optimization focus to those minority data.
3.3 Theoretical Insights of Go-labels
Many classic domain adaptation approaches typically bound/model the adapted target error by the sum of the (1) source error and (2) a notion of distance between the source and the target distributions. The classic generalization bound theory of the \(\mathcal {H}\)-divergence that based on the earlier work of [29] and used by [4, 5, 15] is obtained following theorem-1 in [6]:
where C is a constant when such bound is achieved by hypothesis in \(\mathcal {H}\). And \(\hat{\mathcal {D}}_{S}^{N}\), \(\hat{\mathcal {D}}_{T}^{N}\) denote the empirical distribution induced by sample of size N drawn from \(\mathcal {D}_{S}\), \(\mathcal {D}_{T}\) respectively. \(\mathcal {R}_{t}\) denote the true risk on target domain, and \(\hat{\mathcal {R}}_{s}\) denote the empirical risk on source domain.
Let \(\{ \textbf{x}^{s}_{i} \}_{i=1}^{N}\), \(\{ \textbf{x}^{t}_{i} \}_{i=1}^{N}\) be the samples in the empirical distributions \(\hat{\mathcal {D}}_\text {S}\) and \(\hat{\mathcal {D}}_\text {T}\) respectively. The empirical source risk can be written as \(\hat{\mathcal {R}}_{s}(h) = \frac{1}{N} \sum \limits _{i}^{N}\hat{\mathcal {R}}_{\textbf{x}^{s}_{i}}(h)\). Now, considering a dynamic updated source-target domain distributions \(\hat{\mathcal {D}}_{dS}\) and \(\hat{\mathcal {D}}_{dT}\) achieved by the proposed adjustable go-getting domain labels, which corresponds to relabeling the well-aligned samples (assuming that the number of selected well-aligned target samples is M), the new generalization bound for this updated data distribution can be modified as
the first term on right becomes an updated source risk that could re-energize the object classifier optimization, and the second term becomes an updated domain discrepancy/divergency that could re-energize the domain discriminator optimization. They together unleash the potential of adaptation model. Besides, the risk of the target domain can be re-bounded by the risk of the updated source domain and the updated domain discrepancy, providing theoretical guarantees for the proposed approach. When \(M=0\), we get the original bound of Eq. (4). Hence, the original bound is in the feasible set of our optimization with Go-labels.
4 Experiments
4.1 Validation on Toy Problems
2D Random Point Classification. First, we observe the behavior of our method on toy problem of 2D random point classification. We compared the class decision boundary of our method with Baseline obtained from the domain discriminator trained with immutable domain labels. To better evaluate adaptation performance of the trained model, we visualize source and target data separately. Experimental details are provided in Supplementary. We observe that the Baseline scheme is prone to miss the small tail cluster, especially when it is very closed to a large cluster belonged to the different class. In contrast, our method could better leverage both large/head and small/tail data clusters in the different domains to reduce discrepancy.
Inter-twinning Moons. Furthermore, we observe the behavior of Go-labels on toy problem of inter-twinning moons [15, 49]. We compare our method with the model trained with source data only and DANN [15] in the Fig. 3. We observe that both baselines of Source only and DANN neglect the outlier samples. In contrast, our method not only gets a satisfactory classification boundary between two classes in the source domain, but also covers these minority tail data well and classifies them to the correct class. More details are presented in Supplementary.

The second toy game of inter-twinning moons. Red “ ”, green “
”, green “ ”, and black “\(\cdot \)” markers indicate the source positive samples (label 1), source negative samples (label 0), and target samples, respectively.
”, and black “\(\cdot \)” markers indicate the source positive samples (label 1), source negative samples (label 0), and target samples, respectively.
4.2 Experiments on the General UDA Benchmarks
Datasets. Except for toy tasks, we also conduct experiments on the commonly-used domain adaptation (DA) datasets, including Digit-Five [14], Office31 [46], Office-Home [60], VisDA-2017 [43], and DomainNet [42]. These datasets cover various kinds of domain gaps, such as handwritten digit style discrepancy, office supplies imaging discrepancy, and synthetic\(\leftrightarrow \)real-world environment discrepancy. The data distribution imbalanced issue is also widely existed, and especially serious for the large-scale set, like DomainNet. The detailed introductions for each dataset can be found in Supplementary.
Implementation Details. As a plug-and-play optimization strategy, we apply our Go-labels on top of four representative ADA baselines, DANN [15], CDAN [35], GVB [11], and ASAN [45] for validation. DANN has been described in Sect. 3, and CDAN additionally conditions the domain discriminator on the information conveyed by the category classifier predictions (class likelihood). Recently-proposed GVB equips the adversarial adaptation framework with a gradually vanishing bridge, which reduces the transfer difficulty by reducing the domain-specific characteristics in representations. ASAN [45] integrates relevance spectral alignment and spectral normalization into CDAN. All reported results are obtained from the average of multiple runs (Supplementary).
Effectiveness of Go-getting Domain Labels. Our proposed Go-labels is generic and can be applied into most existing ADA frameworks, to alleviate the optimization difficulty caused by imbalanced domain data distributions, and thus enhance the domain-invariant representation learning. To prove that, we adopt three baselines, DANN [15], CDAN [35], GVB [11], and evaluate adaptation performance on Digit-Five and Office31, respectively. Table 1(a)(b) shows the comparison results, we observe that, regardless of the difference in framework design, our Go-labels (all +Go-labels schemes) consistently improves the accuracy of all three baselines on two datasets, i.e., 2.8%/4.0%, 2.2%/1.1%, 2.3%/1.1% gains on average for DANN, CDAN, GVB, respectively on Digit-Five/Office31. With the help of Go-labels, each sample can be well explored in a dynamic way, resulting in better adaptation performance.
What Happens to Domain Discriminator When Training with Go-labels? For this experiment, we made statistics on the mis-classified cases of the domain discriminator during the training, and then visualize the changing trend in Fig. 4. There are two symmetrical mis-classified cases that need to be counted: mis-classify the raw source sample into the target domain or mis-classify the raw target sample into the source domain. Experiments are conducted on the Office31 and VisDA-2017 datasets, the compared baseline scheme is DANN [15]. As shown in Fig. 4, we observe that, the number of mis-classified cases by domain discriminator in our method is more than that in the baseline. We know that, ‘mis-classified by domain discriminator’ can be approximately equivalent to ‘well-aligned’. Therefore, more ‘mis-classified’ samples by domain discriminator indicates that our method with Go-labels has a capability to align more samples, or said, could better cover those easy-to-miss minority clusters for alignment.
Loss Curve Comparison. Here we also show and compare the loss curves of domain discriminator for baseline DANN and our method. From Fig. 5, we can observe that the loss curve of baseline first drops quickly and gradually rises to near a constant as training progresses. In comparison, the domain discriminator loss curve of our method drops slowly, because more samples (including large and small cluster data) need to be studied/aligned during the training, which could in turn further drive better domain-invariant representations learning.

Trend analysis of the mis-classified cases statistics for the domain discriminator in the training. Here, baseline is DANN [15] with ResNet-50 as backbone.

Domain discriminator loss curves of baseline (DANN) and our method (DANN + Go-labels). Experiments are on the setting of W\(\rightarrow \)A of Office31.
Why Not Directly Ignore Well-Aligned Data? The core idea of our dynamic adversarial domain adaptation with Go-labels is to transfer the model attention from over-studied aligned data to those overlooked samples progressively, so as to allow each sample to be well studied. Therefore, an intuitive alternative solution is to directly discard these over-aligned data, e.g., simply zero out their gradients. We conduct this experiment on the Office31 based on DANN [15]. In Table 2, we see the scheme of DANN + Zero Out that directly discards these well-aligned samples is even inferior to Baseline (DANN) by 2.1% on average. This indicates that such ‘hard and rude’ data filtering trick is sub-optimal because it may lose some important knowledge by mistake. Differently, our Go-labels training strategy could softly and progressively transfer the focus of optimization from the over-aligned samples to the under-explored data.
Comparison with Re-weighting Based Methods. As pointed in previous researches [27, 33], the re-weighting schemes have the risks of over-fitting the tail data (by over-sampling) and also have the risk of under-fitting the global data distribution (by under-sampling), when data imbalance is extreme [76]. Besides, most sample re-weighting techniques [67] start re-weighting operation from the beginning of the entire training process. However, the non-converged feature extractor may affect the re-weighting decision, and cause unstable training. To prove that, we further compare our Go-labels with some sample (re)weighting based methods, including entropy-based re-weighting (+ E) [35], IWAN [70]. Entropy-based re-weighting (+ E) aims to prioritize the easy-to-transfer samples according to predictions of the category classifier to ease the entire adaptation optimization. IWAN [70] re-weights the source samples to exclude the outlier classes in the source domain. Table 2 shows the comparison results. We can observe that even all the sample re-weighting strategies bring performance gains, 3.0% for + E and 2.4% for + IWAN, but our Go-labels strategy still outperforms all competitors. In addition, our Go-labels is also complementary to these re-weighting techniques, the scheme of DANN + E + Go-labels still could achieve 1.6% gain in comparison with DANN + E.
Go-labels is Well-Suited to DA Settings with Intra-class and Inter-class Imbalance. The results on DomainNet [42] can be taken as experimental evidence to prove this point. Because DomainNet has multiple domains, when testing the model adaptation ability on the certain target domain, the rest domains are mixuped as a large source domain. Such large source domain is seriously imbalanced, with both of intra-class and inter-class situations [55]. From the Table 3, we can observe that our Go-labels consistently achieves gains on the different sub-settings, which demonstrates it is always effective to DA settings with the different imbalances to some extents. We analyze that the go-getting labeling encourages the domain discriminator to learn well each sample to get a better source and target domain alignment. This in turn drives a better feature extractor to learn discriminative and domain-invariant features for all samples (they promote each other). Thus, a better feature extractor further improves the classifier and classification accuracy even the classes are still imbalanced.
Analysis About Rounding Operation in Go-labels. To validate the rounding design in Go-labels, we experimented with real-valued soft go-getting domain labels (based on the probability scores without rounding) for comparison. Actually, this is the initial version of our Go-labels. This scheme of using real-valued soft go-getting domain labels (built upon DANN) is inferior to our rounding version by 9.4% in average accuracy on Office31 (77.5% vs. 86.9%, baseline of DANN is 82.9%). We analyze such large drop is because that the real-valued soft go-getting domain labels of training samples are always affected by the probability scores of domain discriminator, even the discriminator has not yet been well-trained at early stage. On the contrary, our rounding-based Go-labels makes no influence for the entire optimization at the stage where the domain discriminator could clearly/correctly classify source-target sample. And, it only reduce the importance for these well-aligned (mis-classified by discriminator) majority samples progressively while keep unchanged for those not aligned minority data. In short, the rounding design makes Go-labels more robust.
4.3 Comparison with State-of-the-Arts
As a general technique, we insert our Go-labels into multiple DA algorithms to validate: CDAN with entropy regularization [35] (CDAN+E), GVB [11], ASAN [45], and RADA [24]. Table 1, Table 5 and Table 6 show the comparisons with the state-of-the-art approaches on Office31, Office-Home and VisDA-2017, respectively. For fair comparison, we report the results from their original papers if available, and we also report the results of the baseline schemes GVB and CDAN+E reproduced by our implementation. We find GVB+Go-labels, CDAN+E+Go-labels, and ASAN+Go-labels all outperform their corresponding baselines and also achieves the state-of-the-art performance on three datasets, and Go-labels is also more simple and efficient per without extra computation.
5 Conclusion
We propose a simple plug-and-play technique dubbed go-getting domain labels (Go-labels) to achieve a dynamic adversarial domain adaptation framework, which effectively alleviates the imbalanced data distribution issue and significantly enhances the domain-invariant representation learning. Go-labels requires changing only two lines of code that yields non-trivial improvements across a wide variety of adversarial based UDA architectures. In fact, improvements of Go-labels come without bells and whistles on all domain adaptation benchmarks we evaluated, despite embarrassingly simple.
References
Arjovsky, M., Chintala, S., Bottou, L.: Wasserstein generative adversarial networks. In: ICML, pp. 214–223. PMLR (2017)
Arpit, D., et al.: A closer look at memorization in deep networks. In: ICML, pp. 233–242. PMLR (2017)
Azadi, S., Olsson, C., Darrell, T., Goodfellow, I., Odena, A.: Discriminator rejection sampling. arXiv preprint arXiv:1810.06758 (2018)
Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., Vaughan, J.W.: A theory of learning from different domains. Mach. Learn. 79(1–2), 151–175 (2010)
Ben-David, S., Blitzer, J., Crammer, K., Pereira, F.: Analysis of representations for domain adaptation. In: NeurIPS, pp. 137–144 (2007)
Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., Wortman, J.: Learning bounds for domain adaptation. In: NeurIPS, pp. 129–136 (2008)
Borgwardt, K.M., Gretton, A., Rasch, M.J., Kriegel, H.P., Schölkopf, B., Smola, A.J.: Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 22(14), e49–e57 (2006)
Chen, L., et al.: Reusing the task-specific classifier as a discriminator: discriminator-free adversarial domain adaptation. In: CVPR, pp. 7181–7190 (2022)
Chen, Q., Liu, Y., Wang, Z., Wassell, I., Chetty, K.: Re-weighted adversarial adaptation network for unsupervised domain adaptation. In: CVPR, pp. 7976–7985 (2018)
Cui, S., Wang, S., Zhuo, J., Li, L., Huang, Q., Tian, Q.: Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations. In: CVPR, pp. 3941–3950 (2020)
Cui, S., Wang, S., Zhuo, J., Su, C., Huang, Q., Tian, Q.: Gradually vanishing bridge for adversarial domain adaptation. In: CVPR, pp. 12455–12464 (2020)
Feldman, V.: Does learning require memorization? a short tale about a long tail. In: Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, pp. 954–959 (2020)
Feldman, V., Zhang, C.: What neural networks memorize and why: discovering the long tail via influence estimation. arXiv preprint arXiv:2008.03703 (2020)
Ganin, Y., Lempitsky, V.: Unsupervised domain adaptation by backpropagation. In: ICML, pp. 1180–1189. PMLR (2015)
Ganin, Y., et al.: Domain-adversarial training of neural networks. J. Mach. Learn. Res. 17(1), 2030–2096 (2016)
Gao, Z., Zhang, S., Huang, K., Wang, Q., Zhong, C.: Gradient distribution alignment certificates better adversarial domain adaptation. In: ICCV, pp. 8937–8946 (2021)
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., Courville, A.: Improved training of wasserstein gans. arXiv preprint arXiv:1704.00028 (2017)
Guo, T., et al.: On positive-unlabeled classification in gan. In: CVPR, pp. 8385–8393 (2020)
Haeusser, P., Frerix, T., Mordvintsev, A., Cremers, D.: Associative domain adaptation. In: ICCV, pp. 2765–2773 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR, pp. 770–778 (2016)
Hoffman, J., et al.: Cycada: cycle-consistent adversarial domain adaptation. In: ICML, pp. 1989–1998. PMLR (2018)
Huang, C., Li, Y., Loy, C.C., Tang, X.: Learning deep representation for imbalanced classification. In: CVPR, pp. 5375–5384 (2016)
Jiang, X., Lao, Q., Matwin, S., Havaei, M.: Implicit class-conditioned domain alignment for unsupervised domain adaptation. In: ICML, pp. 4816–4827. PMLR (2020)
Jin, X., Lan, C., Zeng, W., Chen, Z.: Re-energizing domain discriminator with sample relabeling for adversarial domain adaptation. In: ICCV (2021)
Jin, X., Lan, C., Zeng, W., Chen, Z.: Style normalization and restitution for domain generalization and adaptation. IEEE Trans. Multimedia 24, 3636–3651 (2021)
Johansson, F.D., Sontag, D., Ranganath, R.: Support and invertibility in domain-invariant representations. In: AISTATS, pp. 527–536. PMLR (2019)
Kang, B., et al.: Decoupling representation and classifier for long-tailed recognition. In: ICLR (2019)
Kang, G., Jiang, L., Yang, Y., Hauptmann, A.G.: Contrastive adaptation network for unsupervised domain adaptation. In: CVPR, pp. 4893–4902 (2019)
Kifer, D., Ben-David, S., Gehrke, J.: Detecting change in data streams. In: VLDB, vol. 4, pp. 180–191. Toronto, Canada (2004)
Li, B., et al.: Rethinking distributional matching based domain adaptation. arXiv preprint arXiv:2006.13352 (2020)
Li, S., Xie, M., Gong, K., Liu, C.H., Wang, Y., Li, W.: Transferable semantic augmentation for domain adaptation. In: CVPR, pp. 11516–11525 (2021)
Li, S., et al.: Semantic concentration for domain adaptation. In: ICCV, pp. 9102–9111 (2021)
Li, Y., et al.: Overcoming classifier imbalance for long-tail object detection with balanced group softmax. In: CVPR, pp. 10991–11000 (2020)
Liu, J., Sun, Y., Han, C., Dou, Z., Li, W.: Deep representation learning on long-tailed data: a learnable embedding augmentation perspective. In: CVPR, pp. 2970–2979 (2020)
Long, M., Cao, Z., Wang, J., Jordan, M.I.: Conditional adversarial domain adaptation. In: NeurIPS, pp. 1640–1650 (2018)
Long, M., Zhu, H., Wang, J., Jordan, M.I.: Deep transfer learning with joint adaptation networks. In: ICML, pp. 2208–2217 (2017)
Lu, Z., Yang, Y., Zhu, X., Liu, C., Song, Y.Z., Xiang, T.: Stochastic classifiers for unsupervised domain adaptation. In: CVPR, pp. 9111–9120 (2020)
Luo, Y.W., Ren, C.X.: Conditional bures metric for domain adaptation. In: CVPR, pp. 13989–13998 (2021)
Nowozin, S., Cseke, B., Tomioka, R.: f-gan: training generative neural samplers using variational divergence minimization. In: NeurIPS (2016)
Paszke, A., et al.: Pytorch: an imperative style, high-performance deep learning library. arXiv preprint arXiv:1912.01703 (2019)
Pei, Z., Cao, Z., Long, M., Wang, J.: Multi-adversarial domain adaptation. In: AAAI, vol. 32 (2018)
Peng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., Wang, B.: Moment matching for multi-source domain adaptation. In: ICCV, pp. 1406–1415 (2019)
Peng, X., Usman, B., Kaushik, N., Hoffman, J., Wang, D., Saenko, K.: Visda: the visual domain adaptation challenge. arXiv preprint arXiv:1710.06924 (2017)
Peng, Z., Huang, W., Guo, Z., Zhang, X., Jiao, J., Ye, Q.: Long-tailed distribution adaptation. In: ACMMM, pp. 3275–3282 (2021)
Raab, C., Vath, P., Meier, P., Schleif, F.M.: Bridging adversarial and statistical domain transfer via spectral adaptation networks. In: ACCV (2020)
Saenko, K., Kulis, B., Fritz, M., Darrell, T.: Adapting visual category models to new domains. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010. LNCS, vol. 6314, pp. 213–226. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15561-1_16
Saito, K., Kim, D., Sclaroff, S., Saenko, K.: Universal domain adaptation through self supervision. In: NeurIPS (2020)
Saito, K., Ushiku, Y., Harada, T., Saenko, K.: Strong-weak distribution alignment for adaptive object detection. In: CVPR, pp. 6956–6965 (2019)
Saito, K., Watanabe, K., Ushiku, Y., Harada, T.: Maximum classifier discrepancy for unsupervised domain adaptation. In: CVPR, pp. 3723–3732 (2018)
Sankaranarayanan, S., Balaji, Y., Castillo, C.D., Chellappa, R.: Generate to adapt: aligning domains using generative adversarial networks. In: CVPR, pp. 8503–8512 (2018)
Shimodaira, H.: Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Inference 90(2), 227–244 (2000)
Sinha, S., Zhao, Z., Alias Parth Goyal, A.G., Raffel, C.A., Odena, A.: Top-k training of gans: improving gan performance by throwing away bad samples. In: NeurIPS, vol. 33, pp. 14638–14649 (2020)
Sugiyama, M., Krauledat, M., Müller, K.R.: Covariate shift adaptation by importance weighted cross validation. J. Mach. Learn. Res. 8(5), 1–21 (2007)
Sun, B., Feng, J., Saenko, K.: Return of frustratingly easy domain adaptation. In: AAAI, vol. 30 (2016)
Tan, S., Peng, X., Saenko, K.: Class-imbalanced domain adaptation: an empirical odyssey. In: Bartoli, A., Fusiello, A. (eds.) ECCV 2020. LNCS, vol. 12535, pp. 585–602. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-66415-2_38
Tang, H., Chen, K., Jia, K.: Unsupervised domain adaptation via structurally regularized deep clustering. In: CVPR, pp. 8725–8735 (2020)
Tang, H., Jia, K.: Discriminative adversarial domain adaptation. In: AAAI, vol. 34, pp. 5940–5947 (2020)
Torralba, A., Efros, A.A.: Unbiased look at dataset bias. In: CVPR 2011. pp. 1521–1528
Tzeng, E., Hoffman, J., Saenko, K., Darrell, T.: Adversarial discriminative domain adaptation. In: CVPR, pp. 7167–7176 (2017)
Venkateswara, H., Eusebio, J., Chakraborty, S., Panchanathan, S.: Deep hashing network for unsupervised domain adaptation. In: CVPR (2017)
Wang, S., Zhang, L.: Self-adaptive re-weighted adversarial domain adaptation. IJCAI (2020)
Wei, G., Lan, C., Zeng, W., Chen, Z.: Metaalign: coordinating domain alignment and classification for unsupervised domain adaptation. In: CVPR (2021)
Wu, Y., Donahue, J., Balduzzi, D., Simonyan, K., Lillicrap, T.: Logan: latent optimisation for generative adversarial networks. arXiv preprint arXiv:1912.00953 (2019)
Wu, Y., Winston, E., Kaushik, D., Lipton, Z.: Domain adaptation with asymmetrically-relaxed distribution alignment. In: ICML, pp. 6872–6881. PMLR (2019)
Xu, M., et al.: Adversarial domain adaptation with domain mixup. In: AAAI (2020)
Xu, R., Li, G., Yang, J., Lin, L.: Larger norm more transferable: an adaptive feature norm approach for unsupervised domain adaptation. In: ICCV, pp. 1426–1435 (2019)
Yang, L., Balaji, Y., Lim, S.-N., Shrivastava, A.: Curriculum manager for source selection in multi-source domain adaptation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12359, pp. 608–624. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58568-6_36
Yosinski, J., Clune, J., Bengio, Y., Lipson, H.: How transferable are features in deep neural networks? In: NeurIPS (2014)
You, C., Li, C., Robinson, D.P., Vidal, R.: Scalable exemplar-based subspace clustering on class-imbalanced data. In: ECCV, pp. 67–83 (2018)
Zhang, J., Ding, Z., Li, W., Ogunbona, P.: Importance weighted adversarial nets for partial domain adaptation. In: CVPR, pp. 8156–8164 (2018)
Zhang, X., Fang, Z., Wen, Y., Li, Z., Qiao, Y.: Range loss for deep face recognition with long-tailed training data. In: ICCV, pp. 5409–5418 (2017)
Zhang, Y., Tang, H., Jia, K., Tan, M.: Domain-symmetric networks for adversarial domain adaptation. In: CVPR, pp. 5031–5040 (2019)
Zhang, Y., Liu, T., Long, M., Jordan, M.I.: Bridging theory and algorithm for domain adaptation. In: ICML (2019)
Zhao, H., Des Combes, R.T., Zhang, K., Gordon, G.: On learning invariant representations for domain adaptation. In: ICML, pp. 7523–7532. PMLR (2019)
Zhao, H., Zhang, S., Wu, G., Moura, J.M., Costeira, J.P., Gordon, G.J.: Adversarial multiple source domain adaptation. In: NeurIPS, pp. 8559–8570 (2018)
Zhou, B., Cui, Q., Wei, X.S., Chen, Z.M.: Bbn: bilateral-branch network with cumulative learning for long-tailed visual recognition. In: CVPR, pp. 9719–9728 (2020)
Acknowledgments
This work was supported in part by NSFC under Grant U1908209, 62021001 and the National Key Research and Development Program of China 2018AAA0101400. This work was also supported in part by the Advanced Research and Technology Innovation Centre (ARTIC), the National University of Singapore under Grant (project number: A-0005947-21-00).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Jin, X. et al. (2023). Unleashing the Potential of Adaptation Models via Go-getting Domain Labels. In: Karlinsky, L., Michaeli, T., Nishino, K. (eds) Computer Vision – ECCV 2022 Workshops. ECCV 2022. Lecture Notes in Computer Science, vol 13808. Springer, Cham. https://doi.org/10.1007/978-3-031-25085-9_18
Download citation
DOI: https://doi.org/10.1007/978-3-031-25085-9_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-25084-2
Online ISBN: 978-3-031-25085-9
eBook Packages: Computer ScienceComputer Science (R0)