
Abstract
In this paper, we combine the advantages of convolution local correlation and translation invariance in CNN with Transformer’s ability to effectively capture long-term dependencies between pixels to produce high-quality pseudo labels. In order to segment images efficiently and quickly, we select nnU-Net [2] as the final segmentation network and use pseudo labels, unlabeled data and labeled data together to train the network, and then we use Generic U-Net [2], the backbone network of nnU-Net, as final prediction network. The mean DSC of the prediction results of our method on validation set of FLARE2022 Challenge [3] is 0.7580.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Accurate segmentation of organs or lesions from medical images plays an important role in many clinical applications, such as diagnosis, treatment and postoperative planning. With the increase of annotation data, deep learning has achieved great success in image segmentation. However, for medical images, the acquisition of annotation data is often expensive because of the expertise and time required to generate accurate annotations, especially in 3D images.
In order to reduce labeling cost, many methods have been proposed in recent years to develop high-performance medical image segmentation models to reduce labeling data. A small amount of labelled data and a large amount of unlabeled data are more consistent with the actual clinical scenarios. The semi-supervised learning framework obtains high-quality segmentation results by learning directly from limited labeled data and a large amount of unlabeled data.
In this paper, a semi-supervised method for abdominal multi-organ image segmentation is proposed, which combines CNN and Transformer [1] to generate a large amount of pseudo labels, and uses pseudo labels, unlabeled data and labeled data to train the network, which is equivalent to dataset augmentation and improving the performance of the network.
2 Method
This chapter focuses on two network frameworks used to generate high-quality pseudo labels, and the entire process of using the pseudo label to improve the performance of the backbone network.
2.1 nnU-Net
Preprocessing. We first crop the non-zero regions of the image and resample the cropped data, and then we use Z-Score standardization to normalize the data. The Z-Score standardized formula is as follows:
\(\mu \) is the average value of the CT value of the image label, \(\sigma \) is the variance of the CT value of the image label.
Network. We use 3D U-Net [8] at full resolution for training. As shown in Fig. 1, this 3D U-Net is Generic U-Net, the backbone network of nnU-Net, which is also used as the final prediction network.

Generic U-Net, the backbone network of nnU-Net.
Training. We use the sum of dice loss and cross entropy loss as our total loss function:

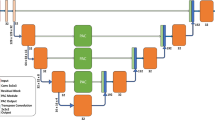
The overall structure of nnFormer. A shows the architecture of nnFormer. B, C, D and E are the specific details of embedding layer, down-sampling layer, up-sampling layer and expanding layer, respectively. K represents the convolutional kernel size. S represents the stride. DK represents the deconvolutional kernel size. Norm is the normalization strategy.
The dice loss function is formulated as follows:
where u is softmax output and v is one hot encoding ground and truth. K is the number of categories. The formula of cross entropy loss function is as follows:
The probability distribution p is the expected output, and the probability distribution q is the actual output.
Testing. The whole testing process is based on the patch size and we use TTA for data augmentation.
2.2 nnFormer [9]
Network. As shown in Fig. 2, the backbone structure of nnFormer is mainly composed of encoder, bottleneck layer and decoder.
The encoder includes an embedding layer, two local self-attention layer blocks and two down-sampling layers. The input image is transformed into features that can be processed by the network through the convolution structure.
The decoding part symmetrically includes two local self-attention layer blocks, two up-sampling layers and the last patch expanding layer for mask prediction. nnFormer uses a local 3D image block-based self-attention calculation called V-MSA [9]. Compared with the traditional voxel self-attention calculation method, V-MSA can greatly reduce the computational complexity.
The bottleneck layer consists of a down-sampling layer, an up-sampling layer, and three global self-attention layer blocks to provide a large receive domain to support the decoder. At the same time, adding skip attention [9] connections in a symmetrical manner between the corresponding feature pyramids of the encoder and decoder helps to recover fine-grained details in the prediction.
Training and Testing. In nnFormer, we use the same training and testing strategy as nnU-Net.

The overall architecture. Images(L) represents the labeled image. Images(U) represents the unlabeled image. Images(L+U) represents the labeled and unlabeled image mixed together.
2.3 Proposed Method
The overall architecture of the approach is shown in Fig. 3, which consists of the generation of pseudo label and the prediction network. In pseudo label generation stage, nnU-Net and nnFormer network models are mainly used. In the final prediction part, we adopte Generic U-Net, the basic network model of nnU-Net.
Pseudo Label Generation. Specifically, in the generation stage of pseudo label, we mainly adopte two network models, nnU-Net and nnFormer. We first train the two models with only 50 cases of labeled data, and then predicted the unlabeled data respectively, and generated the final prediction result by means of prediction probability fusion. This method combine the advantages of local correlation of convolution to spatial information encoding in CNN and long-term dependency capturing in Transformer [4].
After the prediction results are obtained, we use the connected domain analysis for data selection, only the largest part of the connected domain results of each label were saved. Finally, the pseudo label containing each organ is obtained, as shown in Fig. 4. We use ITK-SNAP [7] for visualization.

Three planes of an unlabeled CT image and corresponding generated pseudo label.
Predictive Network. To improve the segmentation efficiency, we use simple network structure for final prediction. We adopt the backbone network Generic U-Net in nnU-Net method as our predictive network. After obtaining pseudo label, the original label and generated pseudo label are trained through nnU-Net, and finally Generic U-Net, the basic network of nnU-Net, is used as the final prediction network.
Post-processing. In some computer vision tasks, it is necessary to do some post-processing on the output of the model to optimize the visual effect, and connected domain is a common post-processing method. Especially for segmentation tasks, sometimes there are some false positives in the output mask. Finding independent contours with small area through 3D connected domain and removing them can effectively improve the visual effect. We use connected domain principal component analysis to remove 3D small connected domains and retain the largest part of each label connected domain.
3 Experiments
Dataset. The FLARE 2022 is an extension of the FLARE 2021 [5] with more segmentation targets and more diverse abdomen CT scans. The FLARE2022 Challenge [3] provides a small amount of labeled cases and a large amount of unlabeled cases regarding abdominal organs. The training set includes 50 labeled CT images and organ of patients with pancreatic disease and 2000 unlabeled CT images of patients with pancreatic disease. The organs to be segmented include 13 organs, including liver, spleen, pancreas, right kidney, left kidney, stomach, gallbladder, esophagus, aorta, inferior vena cava, right adrenal gland, left adrenal gland and duodenum. The validation set includes 50 CT images from patients with liver, kidney, spleen, or pancreas disease. The test set includes 100 CT images of patients with liver, kidney, spleen, and pancreas diseases and 100 CT images of patients with endometrial, bladder, stomach, sarcoma, and ovarian diseases [6].
Evaluation Measures. The evaluation indexes of this competition include dice similarity coefficient, normalized surface dice, running time, area under GPU memory time curve and area under CPU utilization time curve.
The dice similarity coefficient is a statistic used to evaluate the similarity of two samples, essentially measuring the overlap of two samples. The formula is as follows:
|X| and |Y| represent the number of elements in each set, respectively. It is used to measure how similar the prediction result is to the original label. Normalized surface dice is a boundary-based evaluation method used to describe the boundary error between the prediction result and the original label. In addition, the GPU memory and GPU utilization are recorded every 0.1s, and the area under the GPU memory-time curve and the area under the CPU utilization-time curve are cumulative values of running time.
Implementation Details. The development environments and requirements are presented in Table 1.
We use the same training strategy for nnU-Net and nnFormer. The training protocol is presented in Table 2.
Before training, we resample all images to the same spacing. In the process of training, we use data augmentation methods such as rotation, scaling, Gaussian noise, Gaussian blur, gamma enhancement and mirror image.
4 Results
4.1 Quantitative Results on Validation Set
This method combines the advantages of CNN and Transformer to produce a high-quality pseudo label. We use 50 labeled data for training and test on the validation set. This produces a higher quality result than using either model alone, and their respective dice score metrics on the validation set are shown in Table 3.
We compare the prediction results of this method with those of directly transferring to Generic U-Net after training without using pseudo label. The dice score of the predicted results on the validation set without and with pseudo label training are shown in Table 4. The results show that using pseudo label can greatly improve network segmentation performance.
This shows the value of large amounts of unlabeled data. A large amount of unlabeled image data is used to generate pseudo labels, which can get high-quality data after selection, which can make up for the shortage of labels to some extent and improve the prediction ability of the model. For prediction on the validation set, some results and their corresponding labels are shown in Fig. 5. The structure of prediction network is simple and it is difficult to learn deeper features, so the prediction results of some unseen CT images are bad.
4.2 Segmentation Efficiency Results on Validation Set
In this paper, we adopt Generic U-Net, the backbone network of nnU-Net, as the final prediction network. Because the size of some images is too large, nnU-Net or nnFomer consumes too much RAM, which exceeds the required maximum limit. nnU-Net or nnFomer can not be used as the final predictive framework. Compared with nnU-Net or nnFormer, this method can greatly reduce RAM, GPU memory consumption and running time because of the simple predictive framework. The efficiency indicators in the validation set are shown in Table 5. Beyond that, we do not optimize the segmentation efficiency.
4.3 Results on Final Testing Set
The DSC index of the results on final testing set is shown in Table 6, and the NSD index of the results on final testing set is shown in Table 7.

Some visualized results on the validation set and corresponding labels. Row (a) and row (b) are good predicted results and corresponding labels. Row (c) and row (d) are bad predicted results and corresponding labels. Column (f) are predicted results of axial slices and column (g) are corresponding labels of axial slices. Column (i) are 3D results of predicted results and column (j) are 3D results of corresponding labels.
4.4 Limitation and Future Work
The method proposed in this paper only adopts CNN in the final prediction network, and the limited receptive field leads to the failure to capture global information. In the future, it is hoped to design a lightweight network combining the characteristics of CNN and Transformer for efficient inference of images.
5 Conclusion
In this paper, we combine the advantages of CNN and Transformer to establish a long-term dependency relationship, and produce high-quality pseudo labels to enhance the performance of network segmentation. Moreover, we adopt Generic U-Net, the backbone network of nnU-Net, as the final prediction network. The results show that the combination of the two methods produce a high-quality pseudo label compared to using CNN or Transformer alone, and the method achieves effective semi-supervised segmentation performance in the FLARE2022 Challenge.
References
Dosovitskiy, A., et al.: An image is worth 16x16 words: transformers for image recognition at scale (2020). https://doi.org/10.48550/ARXIV.2010.11929. https://arxiv.org/abs/2010.11929
Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18(2), 203–211 (2021)
Ma, J., Wang, B., Bharadwaj, S.: FLARE2022 challenge (2022). https://flare22.grand-challenge.org/
Liu, Z., et al.: Swin transformer: hierarchical vision transformer using shifted windows (2021). https://doi.org/10.48550/ARXIV.2103.14030. https://arxiv.org/abs/2103.14030
Ma, J., et al.: Fast and low-GPU-memory abdomen CT organ segmentation: the flare challenge. Med. Image Anal. 82, 102616 (2022). https://doi.org/10.1016/j.media.2022.102616
Ma, J., et al.: AbdomenCT-1K: is abdominal organ segmentation a solved problem? IEEE Trans. Pattern Anal. Mach. Intell. 44(10), 6695–6714 (2022)
Yushkevich, P., Gerig, G., Bharadwaj, S.: ITK-SNAP (2022). http://www.itksnap.org/
Ronneberger, O., Fischer, P., Brox, T.: U-net: convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 234–241 (2015)
Zhou, H.Y., Guo, J., Zhang, Y., Yu, L., Wang, L., Yu, Y.: nnFormer: interleaved transformer for volumetric segmentation (2021). https://doi.org/10.48550/ARXIV.2109.03201. https://arxiv.org/abs/2109.03201
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Xin, R., Wang, L. (2022). Abdominal Multi-organ Segmentation Using CNN and Transformer. In: Ma, J., Wang, B. (eds) Fast and Low-Resource Semi-supervised Abdominal Organ Segmentation. FLARE 2022. Lecture Notes in Computer Science, vol 13816. Springer, Cham. https://doi.org/10.1007/978-3-031-23911-3_24
Download citation
DOI: https://doi.org/10.1007/978-3-031-23911-3_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-23910-6
Online ISBN: 978-3-031-23911-3
eBook Packages: Computer ScienceComputer Science (R0)