
Abstract
With the development of multi-source detectors, the fusion of infrared and visible light images has received close attention from researchers. Infrared images have the advantages of all-day time, and can clearly image temperature-sensitive targets under low or no light conditions. Visible light images have strong imaging capabilities for target details under good lighting conditions. After the two are fused, the advantages of the two imaging methods can be integrated. In this paper, to obtain more valuable scene information in the fused image, an infrared and visible image fusion method based on multi-scale Gaussian rolling guidance filter (MLRGF) decomposition is proposed. First of all, the MLRGF is utilized to decompose infrared images and visible light images into three different scale layers, which are called detail preservation layer, edge preservation layer and energy base layer, respectively. Then, the three different scale layers are respectively fused based on the properties of different scale layers through spatial frequency-based, gradient-based and energy-based fusion strategies. Finally, the final fusion result is obtained by adding the fusion results of the three different scale layers. Experimental results show that the proposed method has achieved excellent results in both subjective evaluation and objective evaluation.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Image fusion is an enhancement technology whose purpose is to combine images obtained by different types of sensors to generate an image with rich information for subsequent processing. Infrared image and visible light image fusion is an important branch of image fusion. The fusion of infrared and visible light images is very meaningful, and the research has broad application prospects in the fields of video surveillance, military, aerospace, and low-quality surveys.
Traditional image fusion methods can be roughly divided into the following three types: transform domain based fusion methods, spatial domain based fusion methods and deep learning based fusion methods.
The methods of transform domain are mostly based on the idea of multi-scale decomposition, including Laplacian pyramid (LP) transform [1], dual-tree complex wavelet transform (DTCWT) [2], non-subsampled contourlet transform (NSCT) [3, 4] and other methods. The advantage of these methods is that the detailed information of different scales can be merged, and the information is relatively rich. However, the fusion process is more complicated, the amount of calculation is too large, and the fusion result may have a reduced contrast.
The spatial based domain fusion method directly operates on the pixels without cross-domain transformation. The necessary information of the multi-modal image is directly extracted in the spatial domain. The spatial domain based fusion method has strong binding force on the fusion. The detailed information of the obtained image is also more comprehensive. However, there is a risk of undesirable phenomena such as blocking effect. Traditional spatial domain image fusion methods include segmentation methods based on regional blocks, saliency-based methods, and other spatial domain methods [5, 6].
The fusion method of deep learning is a new way that has emerged in recent years. Deep learning is a research sub-field of machine learning. Artificial Neural Network (ANN) is used as the main architecture of the model. The model fits the end-to-end data mapping well. The deep learning fusion method can not only mine the deep features of the image, but also has good model learning capabilities. But its storage occupancy rate and computational complexity are expensive, which needs high configured hardware equipment. Existing deep learning fusion methods can be roughly divided into three categories: methods based on convolutional sparse representation (CSR), methods based on pre-trained deep networks, and methods based on end-to-end learning deep networks. The method based on convolutional sparse representation replaces the matrix product with convolutional operation in the objective function based on traditional sparse representation. The consistency between different image patches is considered in this method. And the sparse coding coefficients can be obtained in an efficient way. Liu et al. apply Convolutional Sparse Representation (CSR) [7] to image fusion, and perform image decomposition through sparse coding coefficients obtained by CSR. Compared with other traditional methods based on sparse representation, this method retains more detailed information and has better robustness when multi-source image registration is not good. The method based on pre-trained deep network uses convolutional neural network as an intermediate tool to apply part of the steps of image fusion. [8, 9] has done many work on this area. The method based on the end-to-end learning deep network takes multi-modal images as input and fused images as output to generate end-to-end images. Ma et al. proposed the first image fusion method based on generative adversarial network, FusionGAN [11], which transforms the fusion task into an adversarial learning process of infrared and visible image information retention.
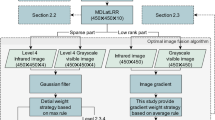
There are many kinds of methods mentioned above, and each has advantages and disadvantages. In view of the fact that existing image fusion methods, especially non-deep learning methods, have a weak ability to retain details. In this paper, an infrared and visible light image fusion method based on multi-scale Gaussian rolling guidance filter (MLRGF) decomposition is proposed to get better fusion results. Just as shown in Fig. 1.
The main contributions of this article are as follows:
-
(1)
An effective image decomposition framework called MLRGF is proposed for multi-scale decomposition of infrared and visible images.
-
(2)
Different fusion strategies are adopted for the feature layers of different scales according to the characteristics of the feature layers.
-
(3)
Through the comparison of subjective and objective evaluations of several sets of fusion results, it is proved that the proposed fusion framework has more superior performance in most evaluations.

Framework of the proposed method.
2 Proposed Method
Motivated by the good edge preserving properties in [12], an infrared and visible image fusion method based on MLRGF decomposition is proposed. It uses filters of different performance to get the details with different attributes. Therefore, we can design the fusion strategies according to attributes, which means that the details with different attributes in two images can be better fused.
2.1 Image Decomposition
Infrared and visible light images are respectively decomposed into three different scale layers by MLRGF. The structure of the decomposition model is shown in Fig. 3. In MLRGF, Gaussian filtering and rolling guidance filter are used for multi-scale decomposition. Gaussian filtering is very classic, it won’t be described here.
Rolling Guidance Filter. Rolling guidance filter [12] is an effective edge-preserving filtering method. It can ensure the accuracy of object boundaries in large areas when removing and smoothing small and complex areas in the image. Rolling guidance filter can be divided into two steps: the removal of microstructures and the restoration of edges. in the first step, Gaussian filtering is used to filter out small structures. The Expression of the filter is shown as
where I represents the input image, G represents the output image, σs represents the standard deviation of Gaussian filtering, N(i) is the neighborhood centered on pixel i, and Ki is the normalization coefficient of the weight. The calculation expression of Ki is as follows
The second step of edge recovery is an iterative process. We use Jt+1 to represent the output result of the t-th iteration, and J1 is set as the Gaussian filtering result G after filtering out the small structure. Given the input image I and the image Jt in the previous iteration, the value of Jt+1 in the t-th iteration is obtained in the form of joint bilateral filtering. It can be calculated by
where ki is the normalization coefficient. The calculation formula of ki is as follows
where σs and σr control the spatial weight and the range weight respectively.
Through Eqs. (1) and (3), we use a sliding window to calculate the result from left to right on the entire image. In this paper, the rolling guidance filter process image I iterated n times is expressed as RGF(I, n).
Image Decomposition Based on MLRGF. The ability of a single multi-scale filtering method to extract features is limited, and the extraction of detailed features is not sufficient. Like the classic Gaussian filter, it can well retain the average energy information of the image and filter out edges and tiny structural information. However, due to the different pixel distribution characteristics of the edge and the tiny structure in the image, the same fusion method is used for fusion, and the effect often leads to the neglect of the tiny structure. This will lead to insufficient fusion information. Based on this, in this article, our method is to use filters with different performance to construct an information variance. It can separate the structural features with different attributes to achieve the full fusion of information. An image decomposition method based on MLRGF is proposed, as shown in Fig. 3. In MLRGF, we use two kinds of filters with different performance: Gaussian filter and rolling guidance filter. Gaussian filter can well retain the low-frequency information of the image. Edges and tiny structural information can be filtered out. Rolling guidance filter can filter out small structures while retaining large-scale edge information in the image. By combining the two structures, we can separate the small structure from the large-scale edges through the differential operations. Afterwards, the image fusion is adopted to ensure that the information is fully utilized.
Here we just using Gaussian filter to illustrate the detail preservation. It is shown in Fig. 2

Structure of MLRGF
In Fig. 3, I is the input image, Ign (n = 1,2,3) is the result image of the n-th Gaussian filtering, Idn (n = 1,2,3) is the result of the n-th rolling guidance filter, DPn (n = 1,2,3) is the n-th level of detail preservation layer, EPn (n = 1,2,3) is the n-th level of edge preservation layer, and B is the energy base layer.
The calculation process of MLRGF is as follows
In Eqs. (5) and (6), GF(·) is Gaussian filtering, μg and σg are the mean and variance of Gaussian filtering, RGF(·) is rolling guidance filter, and m is the number of RGF iterations. In this paper, through a large number of experiments, it is determined that μg = 0, σg = 20, and m = 5.
After obtaining multiple filtered images, three feature maps of different scales can be calculated as
After the above calculation steps, the multi-scale decomposition process in Fig. 3 is completed. The relationship between the different scale images obtained by this decomposition and the original image is
Through the relationship of Eq. (10), the calculation method of reconstruction can be obtained. Experiments have proved that when n = 3, the processing time and the fusion effect can reach a better result.

Structure of MLRGF
2.2 Image Fusion
After the image is decomposed, we adopt different fusion strategies for different scale layers according to the characteristics of the decomposed image. The detail-preserving layer has the tiny structure and detail characteristics of the image, so we adopt the fusion strategy of spatial frequency-local variance (SF-LV) [13] integration. The edge-preserving layer has large-scale edge information and a small amount of small structure information of the image, so it adopts the fusion strategy of multi-scale morphological gradient domain pulse coupled neural network (MSMG-PCNN) [14]. The energy base layer contains a large amount of low-frequency information, so a weighted fusion strategy based on energy weights is adopted.
Fusion Strategy of Detail Preservation Layer
The detail preservation layer after image decomposition contains more small structures and edges. We believe that the more small structures and edges contained in a local area, the more information should be preserved. Therefore, we adopt the fusion strategy of SF-LV. The spatial frequency can be calculated by [15]. Here just using SF(x, y) represents the spatial frequency result at point (x, y).
The calculation formula of local variance is as follows
where P and Q respectively represent the size of the region centered on (x, y). μ is the average value of pixels in the P × Q area.
The calculation formula of the SF-LV strategy is as follows
where FuDi is the fusion result of the detail preservation layer, \(DP_i^{IR}\) and \(DP_i^{VIS}\) are the detail preservation layers decomposed from visible light image and infrared image respectively, \(SF_i^{FIR}\) and \(SF_i^{FVIS}\) are the results of the spatial frequency of \(DP_i^{IR}\) and \(DP_i^{VIS}\), respectively, \(LV_i^{FIR}\) and \(LV_i^{FVIS}\) is the calculation result of the local variance of \(DP_i^{IR}\) and \(DP_i^{VIS}\). In this paper, the value of i above is 1, 2, 3. Through Eqs. (11) to (12), the fusion of the detail preservation layer is completed.
Fusion Strategy of Edge Preservation Layer. The edge preservation layer has more large-scale edges and a small amount of micro-structure edges, which requires effective extraction of edge structures. Multi-scale Morphological Gradient Domain Pulse Coupled Neural Network (MSMG-PCNN) is an effective edge extraction and fusion strategy. It can comprehensively consider the edge strength and distribution of the corresponding positions in different images. This method has been successfully applied to image fusion [14]. In this article, the fusion strategy is applied.
MSMG
Multi-scale morphological gradient is a very effective edge extractor. The specific calculation steps are as follows. First define the multi-scale morphological gradient operator
where SE1 represents the basic structural unit, and t represents the number of scales. In this article, the value of t is 3.
After that, the structural elements of Eq. (13) can be used to calculate the special features.
where \(\oplus\) and \(\rm{ \ominus }\) are morphological expansion and morphological corrosion respectively. f(x, y) represents the pixel at position (x, y) in original image.
Finally, the calculation formula of MSMG is
where wt represents the gradient weight of the t-th scale, which is calculated by
MSMG-PCNN
Pulse Coupled Neural Network (PCNN) [15] is a simple neural network. It is created by imitating the working mechanism of the human eye's retina. For the application of PCNN in the field of image fusion, its structure can be simplified to a two-channel PCNN model, and the calculation formulas are as follows.
where \(S_{ij}^1\) and \(S_{ij}^2\) represent the pixel values of the two input images in the neural network at point i; Lij represents the link parameter; \(\beta_{ij}^1\) and \(\beta_{ij}^2\) represent the link strength; \(F_{ij}^1\) and \(F_{ij}^2\) represent the input feedback. Uij is a dual-channel output. θij is the threshold of the step function, De is the degree of the threshold decline, Vθ determines the threshold of active neurons, Tij is a parameter that determines the number of iterations, and Yij(k) is the output of the k-th PCNN.

Model of MSMG-PCNN
MSMG-PCNN replaces the link weights \(\beta_{ij}^1\) and \(\beta_{ij}^2\) of the dual-channel PCNN with the output result of MSMG. Which is
where M1 and M2 respectively represent the MSMG calculation results of the two images to be fused. They can be calculated by Eq. (15). Based on this, the fusion model is given by the following formula.
where MSMG-PCNN(·) represents the MSMG-PCNN operation function. \(EP_i^{IR}\) and \(EP_i^{VIS}\) represent the i-th edge preservation layer of infrared and visible light images, respectively. t is the multi-scale decomposition parameter of MSMG. In this article, t = 3.
The MSMG-PCNN fusion model is shown in Fig. 4.
Fusion Strategy of the Energy Base Layer
The information in the energy base layer is mainly low-frequency information, and the information intensity is relatively strong. Therefore, the fusion of the base layer plays a decisive role in the overall quality of the fused image. Since the base layer contains most of the information of the source image, the energy attribute fusion strategy based on the natural index is used. The fusion strategy is mainly divided into three steps.
Calculate the energy characteristic attributes of the base layer.
where μIR and MIR represent the mean and median of infrared base layer image. μVIS and MVIS represent the mean and median of visible light base layer image, respectively.
Calculate the energy characteristic function of the base layer, which is represented by EIR and EVIS respectively.
where exp(·) represents natural exponential operation. τ represents the gain factor. In this article, τ = 0.25.
Calculate the fused base layer through the weighted fusion method.
Reconstruction of Fusion Image
The fusion image can be reconstructed by the fusion results of three different scales. According to Eq. (10), the reconstruction process can be calculated by the following equation.
3 Experimental Results and Analysis
The method proposed will be compared with the comparison algorithms from both subjective and objective aspects. In this paper, GFF [6], ASR [16], and LatLRR [17] are used as comparison algorithms. Ten groups of comparative experiments will be demonstrated to prove the effectiveness of the proposed method.
3.1 Subjective Evaluation
For the fusion of infrared and visible light images, the more detailed information and clearer targets the fused image contains, the better the fusion effect. Based on this criterion, ten comparative experiments in Figs. 5, 6 and 7 were completed.

“Camp” images and fused results obtained by different algorithms

“Marne1” images and fused results obtained by different algorithms


Other images and fused results obtained by different algorithms
In Figs. 5, 6 and 7, we can find that the proposed method has obvious advantages in the detail preservation of visible and infrared images and the overall contrast of the fused image.
At the subjective evaluation point of view, we believe our proposed method has better performance than the comparison algorithms.
3.2 Objective Evaluation
In this paper, four metrics in the field of image fusion are used, including Spatial Frequency (SF) [15], Structural Similarity Index Measure (SSIM) [18], Mutual Information (MI) [19] and Total fusion metrics (QAB/F) [20].
Table 1 shows the objective evaluation of the ten groups of experiments. The best results have been bolded. It can be seen that the proposed method is superior to other state-of-the-art algorithms in most metrics and scene. For the other cases, even if it is not the best fusion performance, the proposed algorithm achieves the second-best performance.
4 Conclusion
In this paper, an infrared and visible image fusion method based on MLRGF decomposition is proposed. In this method, the input source images are first decomposed into three different scale layers: the detail preservation layer, the edge preservation layer and the energy base layer. According to the respective characteristics of the three scale layers, three different fusion strategies are used for fusion. Finally, the fusion image is obtained by adding the fusion results of three different scales. Experimental results show that the method proposed performs better than other fusion methods in both subjective and objective evaluation. However, the complexity of the method is relatively high, which leads to poor real-time. So in the future work, we will try to simplify the method framework and improve the method performance.
References
Burt P.J., Adelson E.H.: The Laplacian pyramid as a compact image code. Readings in Computer Vision. Morgan Kaufmann, pp. 671–679 (1987)
Lewis, J.J., O’Callaghan, R.J., Nikolov, S.G., et al.: Pixel-and region-based image fusion with complex wavelets. Inf. Fusion 8(2), 119–130 (2007)
Da Cunha, A.L., Zhou, J., Do, M.N.: The nonsubsampled contourlet transform: Theory, design, and applications. IEEE Trans. Image Process. 15(10), 3089–3101 (2006)
Zhao, C., Guo, Y., Wang, Y.: A fast fusion scheme for infrared and visible light images in NSCT domain. Infrared Phys. Technol. 72, 266–275 (2015)
He, K., Sun, J., Tang, X.: Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 35(6), 1397–1409 (2012)
Li, S., Kang, X., Hu, J.: Image fusion with guided filtering. IEEE Trans. Image Process. 22(7), 2864–2875 (2013)
Liu, Y., Chen, X., Ward, R.K., et al.: Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 23(12), 1882–1886 (2016)
Liu, Y., Chen, X., Cheng, J., et al.: Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolut. Inf. Process. 16(03), 1850018 (2018)
Li, H., Wu, X.J., Durrani, T.S.: Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 102, 103039 (2019)
He, K., et al.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778 (2016)
Ma, J., Yu, W., Liang, P., et al.: FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 48, 11–26 (2019)
Zhang, Q., Shen, X., Xu, L., et al.: Rolling Guidance Filter. In: European conference on computer vision. Springer, Cham, pp. 815–830 (2014)
Tan, W., Zhou, H., Song, J., et al.: Infrared and visible image perceptive fusion through multi-level Gaussian curvature filtering image decomposition. Appl. Opt. 58(12), 3064–3073 (2019)
Tan, W., Xiang, P., Zhang, J., et al.: Remote sensing image fusion via boundary measured dual-channel PCNN in multi-scale morphological gradient domain. IEEE Access 8, 42540–42549 (2020)
Xiao-Bo, Q., Jing-Wen, Y., Hong-Zhi, X., et al.: Image fusion algorithm based on spatial frequency-motivated pulse coupled neural networks in nonsubsampled contourlet transform domain. Acta Automatica Sinica 34(12), 1508–1514 (2008)
Liu, Y., Wang, Z.: Simultaneous image fusion and denoising with adaptive sparse representation. IET Image Proc. 9(5), 347–357 (2015)
Li, H., Wu, X.J.: Infrared and visible image fusion using latent low-rank representation. arXiv preprint arXiv:1804.08992 (2018)
Wang, Z., Bovik, A.C., Sheikh, H.R., et al.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Qu, G., Zhang, D., Yan, P.: Information measure for performance of image fusion. Electron. Lett. 38(7), 313–315 (2002)
Petrovic, V., Xydeas, C.: Objective image fusion performance characterization. In: Tenth IEEE International Conference on Computer Vision (ICCV'05), vol. 1., IEEE 2, pp. 1866–1871 (2005)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, J., Xiang, P., Teng, X., Zhang, X., Zhou, H. (2022). Infrared and Visible Image Fusion Based on Multi-scale Gaussian Rolling Guidance Filter Decomposition. In: Berretti, S., Su, GM. (eds) Smart Multimedia. ICSM 2022. Lecture Notes in Computer Science, vol 13497. Springer, Cham. https://doi.org/10.1007/978-3-031-22061-6_6
Download citation
DOI: https://doi.org/10.1007/978-3-031-22061-6_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-22060-9
Online ISBN: 978-3-031-22061-6
eBook Packages: Computer ScienceComputer Science (R0)