
Abstract
We present a novel unsupervised domain adaptation method for semantic segmentation that generalizes a model trained with source images and corresponding ground-truth labels to a target domain. A key to domain adaptive semantic segmentation is to learn domain-invariant and discriminative features without target ground-truth labels. To this end, we propose a bi-directional pixel-prototype contrastive learning framework that minimizes intra-class variations of features for the same object class, while maximizing inter-class variations for different ones, regardless of domains. Specifically, our framework aligns pixel-level features and a prototype of the same object class in target and source images (i.e., positive pairs), respectively, sets them apart for different classes (i.e., negative pairs), and performs the alignment and separation processes toward the other direction with pixel-level features in the source image and a prototype in the target image. The cross-domain matching encourages domain-invariant feature representations, while the bidirectional pixel-prototype correspondences aggregate features for the same object class, providing discriminative features. To establish training pairs for contrastive learning, we propose to generate dynamic pseudo labels of target images using a non-parametric label transfer, that is, pixel-prototype correspondences across different domains. We also present a calibration method compensating class-wise domain biases of prototypes gradually during training. Experimental results on standard benchmarks including GTA5 \(\rightarrow \) Cityscapes and SYNTHIA \(\rightarrow \) Cityscapes demonstrate the effectiveness of our framework.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction

An illustration of our framework for UDASS. We generate pseudo labels of target images using a nonparametric label transfer. We then perform bi-directional pixel-prototype contrastive learning. This encourages pixel-level features in a target image and a prototype of the same object class in a source domain to pull each other, while setting them apart for different ones. We also perform the alignment and separation in a reverse direction, with pixel-level features of source images and prototypes of a target domain.
Semantic segmentation is to assign a semantic label to each pixel in an image. In the past decade, supervised methods based on convolutional neural networks (CNNs) [1, 17, 26, 33, 41, 56] have achieved remarkable improvements in semantic segmentation. Training networks for the dense prediction task generally requires lots of pixel-level labels. Annotating pixel-level labels of high-resolution images is, however, significantly labor-intensive and time-consuming. For example, annotating the labels for an image of size \(2048 \times 1024\) in Cityscapes [6] takes about 90 min. One alternative is to leverage synthetic datasets, e.g., GTA5 [32] and SYNTHIA [34], that contain realistic images and corresponding pixel-level labels. The annotation cost is much cheaper than the manual labeling, but CNNs trained with synthetic datasets do not work well on real images, due to the domain discrepancy between synthetic and real images.
To reduce the domain discrepancy, several methods [4, 15, 16, 23, 43, 44] have exploited an unsupervised domain adaptation approach. It transfers knowledge learned from a source domain (e.g., a synthetic dataset) to a target one (e.g., a real dataset), with labels for the source domain alone. Many unsupervised domain adaptation methods leverage an adversarial training scheme [12] that aligns distributions of source and target domains by fooling a domain classifier [3,4,5, 10, 15, 16, 23, 27, 28, 30, 36, 42, 44, 48, 49, 55]. However, they typically focus on reducing the domain discrepancy globally, and fail to keep pixel-level semantics [50]. For example, regions corresponding to a car class in a source image might align with those for a bus class in a target image. Self-training methods [22, 50, 51, 58, 59] enable a class-aware alignment. They generate pseudo labels for target images iteratively in a parametric approach, typically using CNNs trained with a source dataset, and then retrain a segmentation model on both source and target samples with the pseudo labels. This aligns cross-domain features in a class-level, improving performance of the model on target images progressively. The pseudo labels obtained using a parametric approach have the following drawbacks: First, they are very sparse, since low confident predictions are discarded to obtain reliable labels. Second, estimating pseudo labels is also computationally demanding, making them not to be updated frequently during training. These problems cause the segmentation model to overfit to pseudo labels, resulting in a large bias and a variance of predictions. In the following, we will call the labels estimated using a parametric approach as static pseudo labels.
We present a novel contrastive learning framework using cross-domain pixel-prototype correspondences for unsupervised domain adaptive semantic segmentation (UDASS). It aligns pixel-level features of each object class in target images, obtained by pseudo labels, with prototypes of corresponding class in a source domain, computed by ground truth, while setting them apart for different classes (Fig. 1). The alignment and separation process is also performed in a reverse direction, with pixel-level features of source images and prototypes of a target domain. The cross-domain matching encourages domain-invariant feature representations, and the bidirectional pixel-prototype correspondences provide compact and discriminative representations. We also present a nonparametric approach to generating dynamic pseudo labels using pixel-prototype correspondences. Specifically, we calibrate prototypes of individual object classes in a source domain, while considering the domain discrepancy in target images, and establish correspondences for each prototype with individual pixel-level features in target images. We then transfer ground-truth labels of prototypes to corresponding pixels in target images. In contrast to the parametric approach in current self-training methods, our nonparametric approach provides denser pseudo labels, and generates the labels dynamically, whenever source images are changed during training. This helps to obtain more accurate pseudo labels, and prevents the overfitting problem. Experimental results on standard benchmarks including GTA5-to-Cityscapes [6, 32] and SYNTHIA-to-Cityscapes [6, 34] demonstrate that our contrastive learning framework provides domain-invariant and discriminative features for UDASS. The main contributions can be summarized as follows:
-
We introduce a novel contrastive learning framework using bi-directional pixel-prototype correspondences to learn domain-invariant and discriminative feature representations for UDASS.
-
We propose a nonparametric approach to generating dynamic pseudo labels. We also present a calibration method to reduce domain biases for pixel-prototype correspondences between target and source domains.
-
We set a new state of the art on standard benchmarks for UDASS, and demonstrate the effectiveness of our contrast learning framework.
2 Related Work
UDASS. UDASS leverages knowledge learned from a label-rich source domain to predict semantic labels of a scene in a target domain, where ground-truth annotations are not available. Synthetic images (e.g., GTA5 [32] and SYNTHIA [34]) are widely used as source samples, as pixel-level labels can be generated automatically using computer graphics engines. The key factor for UDASS is hence to learn domain-invariant features to reduce the discrepancy between source and target domains. To this end, many UDASS methods adopt an adversarial learning framework [12] to fool a domain discriminator. They can generally be categorized into image-level and feature-level alignment methods. Motivated by image translation techniques [18, 57], image-level alignment methods [5, 15, 23, 30, 49] transfer the styles (e.g., texture and illumination) of target images to the source, so that segmentation models can accommodate both domains. Feature-level alignment methods [3, 4, 10, 16, 27, 28, 36, 42, 44, 48, 55] align the feature distributions of source and target images explicitly. These adversarial approaches, however, align source and target distributions globally. Namely, they perform a class-agnostic alignment, and ignore positional information of a scene. This suggests that the adversarial approaches fail to transfer pixel-level semantics, related to the structural information of a scene, from source to target domains.
UDASS methods based on self-training [22, 58, 59] have recently been introduced. The self-training approach first segments target images using a model trained on a source dataset, and obtains pseudo labels if the confidence of semantic labels predicted by the model exceeds a pre-defined threshold. It then retrains the model iteratively with both ground-truth and pseudo labels of source and target datasets, respectively. The representative work of [58] proposes to use different thresholds for individual object categories to consider a class imbalance problem. In [59], soft pseudo labels have been introduced, together with a confidence regularization technique that helps transfer discriminative feature representations from source to target domains. The self-training approaches [22, 52, 58, 59] are, however, likely to overfit to pseudo labels. The reasons are as follows: (1) Pseudo labels are fixed for a few epochs during training, due to computational overheads, which accumulates error from incorrect pseudo labels; (2) Pseudo labels are very sparse, as high confident predictions are chosen only as the labels. Our method alleviates these limitations by generating denser pseudo labels dynamically in a nonparametric way using pixel-prototype correspondences. Most similar to ours is PLCA [20] using pixel-wise matches. It adopts a contrastive learning scheme to reduce the distances between source and target features directly at a pixel-level. The pixel-level domain alignment, however, does not consider contextual information, and fails to obtain compact representations between corresponding object categories in source and target domains. Our method instead uses bidirectional pixel-prototype correspondences for contrastive learning, which encourages intra-class compactness and inter-class separability across domains.
Prototypical Learning. The seminal work of [40] introduces prototypical networks that extract prototype representations for individual object categories. The prototypical features have proven useful in the limited-data regime for the task of, e.g., few-/zero-shot classification. PL [9] extends the idea of prototypical learning for few-shot semantic segmentation in such a way that class prototypes obtained from a support set are matched to pixel-level features in a query image. PANet [46] presents a bidirectional framework exploiting correspondences between prototypical features for a support set and pixel-level ones for query images, and vice versa, for few-shot semantic segmentation. Similar to these methods, we exploit prototypical features for semantic segmentation. Differently, we leverage them within a framework of contrastive learning for UDASS. We use pixel-prototype correspondences to obtain domain-invariant and discriminative feature representations. We also leverage the correspondences to obtain dynamic pseudo labels, which alleviates the limitations of current self-training methods using static pseudo labels.
Contrastive Learning. Contrastive learning [2, 13] is a de facto approach to learning generic feature representations in a self-supervised way. The basic idea is to encourage positive pairs with the same label to be close, while negative ones with different labels to be distant. In order to set positive and negative pairs without ground-truth labels, contrastive learning augments a single input image, e.g., using random cropping and color jittering. It then considers the original image and the augmented one as a positive pair, while setting the pairs composed of the original and other images as negative ones. Similar to ours, CANet [19] adopts contrastive learning for unsupervised domain adaptive classification. It computes the domain discrepancies using image-level features, and then performs a class-wise alignment using target labels obtained by a clustering method. Differently, our method leverages contrastive learning using correspondences between pixels and prototypes across domains. Optimizing bidirectional correspondences jointly in our method also enables aggregating features for the same object category, regardless of domains.
Nonparametric Label Transfer. Label transfer has been widely used in object localization [29], scene segmentation [25, 31, 35, 39], automatic image annotation [45], and image translation [38]. Label transfer methods first search visually similar images or patches in large datasets for given queries, and then transfer labels of retrieved samples to the queries. Similar to our approach, the work of [8] adopts a nonparametric label transfer method for scene parsing under different domains (e.g., weather or illumination). Specifically, it extracts features from query images with pre-trained networks, finds the best matching images using SIFT flow [24], and transfers labels of the images to the queries via a probabilistic MRF model, suggesting that this approach requires source images and ground-truth labels at both training and test time. Our method, on the other hand, uses source images and corresponding ground-truth labels only at training time. Namely, we leverage non-parametric label transfer to train a parametric segmentation model.

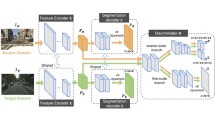
An overview of our framework. (Left) Bi-directional contrastive learning: We first extract feature maps, \(f_\text {S}\) and \(f_\text {T}\), from source and target images, \(x_\text {S}\) and \(x_\text {T}\), respectively. We then obtain prototypes in a source domain, \(\rho _\text {S}\) using ground-truth labels of source images \(y_{\text {S}}\). Prototypes in a target domain \(\rho _\text {T}\) are similarly computed but with dynamic pseudo labels of target images \(y_{\text {T}}\). Bidirectional contrastive terms, FCL and BCL, exploit pixel-prototype correspondences across domains to learn domain-invariant and discriminative features for UDASS. (Right) Hybrid pseudo labels: We generate dynamic pseudo labels \(y_{\text {D}}\) using pixel-prototype correspondences across domains, while calibrating the prototypes to reduce domain discrepancies. We then combine them with static ones \(y_{\text {F}}\) using a parametric approach to obtain hybrid pseudo labels \(y_{\text {T}}\).
3 Approach
3.1 Overview
We introduce a cross-domain contrastive learning framework for UDASS using pixel-prototype correspondences (Fig. 2). It first extracts feature maps from source and target images, respectively, using a siamese network. We obtain prototypes of source and target domains using ground-truth labels of source images and pseudo labels of target ones, respectively. Our method then establishes correspondences between the prototypes and pixel-level features across domains, and leverages them to learn domain-invariant and discriminative representations via contrastive learning. To this end, we introduce a bi-directional contrastive loss that consists of a forward contrastive term (FCL) and a backward contrastive term (BCL). FCL matches individual pixel-level features of a target image with prototypes of a source domain, and enforces pixel-prototype pairs with the same class labels to be aligned closely than other ones. BCL performs the alignment process in a reverse direction, with pixel-level features of a source image and prototypes of a target domain, encouraging our model to provide discriminative and compact features. In order to establish training pairs for computing the bi-directional contrastive loss, we require pseudo labels of target images. To this end, we use dynamic pseudo labels obtained by a nonparametric label transfer, addressing the drawbacks of static pseudo labels. Specifically, given a pair of source-target images, we establish correspondences between prototypes of a source domain and pixel-level features of a target image, while calibrating the prototypes progressively during training to compensate domain discrepancies. We then set the pseudo labels of pixel-level features to the class labels of the corresponding prototypes in a source domain. Unlike static pseudo labels estimated by a parametric approach [22, 58], our approach can generate novel pseudo labels of target images dynamically, whenever a pair of source-target images are changed, during training. We estimate hybrid pseudo labels by combining dynamic and static labels, and use them for the bi-directional contrastive learning.
3.2 Bi-directional Contrastive Learning
Given a pair of source and target images, our goal is to aggregate pixel-level features for the same object class, regardless of domains, to learn domain-invariant and discriminative feature representations. To this end, we formulate UDASS as bi-directional pixel-prototype contrastive learning. Let us denote by \(\mathcal {C}\) the set of object classes. We obtain prototypes of source and target domains for the class \(c \in \mathcal {C}\), \(\rho _\text {S}(c)\) and \(\rho _\text {T}(c)\), using masked average pooling (MAP) as follows:
where we denote by \(f_\text {S}(p)\) and \(f_\text {T}(p)\) pixel-level features of source and target images, respectively, at position p. \(y_{\text {S}}(p,c)\) and \(y_{\text {T}}(p,c)\) are one-hot labels, i.e., 1 if the class label at position p correspond to c and 0 otherwise. Note that we use ground-truth labels of source images \(y_{\text {S}}\) and hybrid pseudo labels of target ones \(y_{\text {T}}\) to set the labels, \(y_{\text {S}}\) and \(y_{\text {T}}\), respectively. Using the prototypes of source and target domains, we perform cross-domain contrastive learning in a bi-directional way. We leverage a bi-directional constative loss that consists of FCL and BCL. FCL exploits prototypes of a source domain and pixel-level features of a target image. To be specific, given pixel-level features of a target image, we select the prototypes of a source domain having the same class labels as the features, and set them as positive pairs, while other prototypes are used to set negative ones. FCL maximizes the similarities between positive pairs as follows:
where \(\tau \) is a temperature parameter, and \(s(\cdot , \cdot )\) computes cosine similarity. Similarly, BCL exploits prototypes of a target domain and pixel-level features of a source image. It encourages positive pairs sharing the same labels to pull each other, while making others set apart as follows:
In summary, using the bidirectional contrastive loss, pixel-level features for the same object class are embedded closely, regardless of domains, while those for different classes are distinguished from each other. That is, by jointly optimizing FCL and BCL, we can minimize intra-class variations and maximize inter-class variations of pixel-level features progressively during training. In contrast to current UDASS methods [22, 50, 51, 54, 58, 59] that do not consider such variations for domain adaptation, our approach provides more discriminative and compact features. This in turn allows to perform more accurate class-wise alignments across domains, and enables our model to generalize better on a target domain.
3.3 Dynamic Pseudo Labels
Current self-training methods [22, 50, 51, 54, 58, 59] employ a parametric model trained with ground-truth labels of source images to obtain static pseudo labels of target images. Specifically, using the parametric segmentation model, confidence scores for individual object classes are computed for each pixel-level feature from entire target images. The pixel-level features with high confidence scores are chosen, and corresponding object classes are used as pseudo labels. Although exploiting static pseudo labels of target images enables performing class-aware UDASS, they have the following drawbacks: First, computing the pixel-level confidence scores for all target images to obtain the pseudo labels is computationally demanding. Current self-training methods perform this process for a few iterations (e.g., 10000) during training, and update the pseudo labels of target images very occasionally. The error from incorrect pseudo labels might hence be accumulated. Second, current self-training methods choose highly confident pixel-level features only for static pseudo labels, and thus they are very sparse. These problems cause a model to overfit to the static pseudo labels, and induce suboptimal class-wise alignments between domains. To overcome the limitations, we introduce a novel approach to generating dynamic pseudo labels. It leverages a nonparametric label transfer technique using pixel-prototype correspondences between source and target images. That is, we estimate pseudo labels using pairs of source and target images. This suggests that our approach generates pseudo labels of target images dynamically, whenever source images are changed during training. In other words, the pseudo labels for the same target image could be different, depending on which source images are used to establish pixel-prototype correspondences w.r.t the target one (Fig. 3).

Visual comparison of static, dynamic, and hybrid pseudo labels for a target image. In contrast to the static label (the first column), estimated using a parametric segmentation model, dynamic labels are obtained by a nonparametric label transfer between source and target images. This suggests that they are denser and cheap to update. We can also obtain different dynamic labels (the second column), according to source images (the fourth column). We combine both labels to get hybrid pseudo labels (the third column), and use them to augment the number of positive and negative pairs for contrastive learning.
Concretely, given a pair of source and target images, we establish correspondences between prototypes of a source image and pixel-level features of a target one. To obtain reliable correspondences, we alleviate domain biases between source and target domains. We could estimate the degree of domain biases by calculating average class-wise features for each domain using all source and target images, followed by computing differences between the average features, which however requires lots of computational overheads. We instead leverage prototypes of source and target images. We first update prototypes of source and target domains progressively during training using an exponential moving average with a momentum parameter of \(\lambda \) as follows:
where we denote by \(\mu _\text {S}(c)\) and \(\mu _\text {T}(c)\) updated prototypes of source and target domains, respectively, for the class c. We then estimate class-wise domain biases:
and obtain calibrated prototypes for each object class in a source domain as follows:
Using the calibrated prototypes, we can establish more correct correspondences across domains. We consider the correspondences are correct, if similarity scores between the pixel-prototype matches are larger than a pre-defined threshold, and set dynamic pseudo labels of target images to corresponding object categories of the prototypes, as follows:
where \(y_{\text {D}}(p,c)\) is a dynamic pseudo label for the class c at position p, \(\mathcal {T}\) is a pre-defined threshold, and
Hybrid Pseudo Labels. We can obtain diverse pseudo labels even for the same target image every iteration, and the dynamic labels are much denser than static ones. Static pseudo labels, on the other hand, are sparse but reliable. In order to take advantage of both, we combine them and obtain hybrid pseudo labels \(y_{\text {T}}\) as follows:
where \(y_{\text {F}}(p,c)\) is a static pseudo label for the class c at position p.
3.4 Training Loss
Following the previous works [22, 50, 51, 58, 59], we exploit segmentation and entropy terms using ground-truth and pseudo labels of source and target images, respectively. The former encourages our model to provide accurate pixel-wise predictions, and the latter minimizes the entropy of the predictions. We define a loss for training a baseline model as follows:
where \(\mathcal {L}_{seg}^{\text {S}}\) and \(\mathcal {L}_{seg}^{\text {T}}\) are segmentation losses for source and target domains, respectively. \(\mathcal {L}_{ent}^{\text {S}}\) and \(\mathcal {L}_{ent}^{\text {T}}\) are entropy terms for source and target domains, respectively. \(\lambda _{seg}^{\text {S}}\), \(\lambda _{seg}^{\text {T}}\), \(\lambda _{ent}^{\text {S}}\), and \(\lambda _{ent}^{\text {T}}\) are balance parameters for each term. For the baseline, we obtain static pseudo labels using the method of [58]. As our final model, we additionally use a bi-directional contrastive loss to learn domain-invariant and discriminative representations as follows:
where \(\lambda _{FC}\) and \(\lambda _{BC}\) are weighting factors for forward and backward contrastive terms, respectively.
4 Experiments
4.1 Implementation Details
Dataset and Evaluation Metric. We evaluate our framework on two standard benchmarks (GTA5 [32] \(\rightarrow \) Cityscapes [6], and SYNTHIA [34] \(\rightarrow \) Cityscapes [6]). GTA5 and SYNTHIA provide 24,996 and 9400 images, respectively. Cityscapes consists of 2975, 500, and 1525 images for training, validation, and testing, respectively. Following the standard protocol in [15, 43, 58, 59], we report the mean intersection over Union (mIoU) on 19 classes for GTA5 \(\rightarrow \) Cityscapes and 13 (or 16) classes for Synthia \(\rightarrow \) Cityscapes.
Training. We adopt the DeepLab-V2 [1] architecture with ResNet-101 [14] as a backbone network pretrained for ImageNet classification [7]. We first train DeepLab-V2 with a source dataset, and use it as an initial segmentation model for UDASS. We train the model for 100k iterations with a batch size of 4, using stochastic gradient descent (SGD) [21] of a momentum of 0.9 and weight decay of \(5 \times 10^{-4}\). We use a poly learning rate scheduling with an initial learning rate of \(7.5 \times 10^{-5}\). We update static pseudo labels \(y_{\text {F}}\) every 10k iterations. We resize a shorter side of images to 850, and crop them into a patch of size 730 \(\times \) 730. For data augmentation, we use horizontal flipping and random scaling with the factor of [0.8, 1.2]. We use a weighted sampling strategy to select source images containing objects that rarely appear in a source domain, mitigating low co-occurrence rates for the rare object categories. Following [11, 52], we additionally apply a self-distillation technique to our final model. Detailed descriptions for the weighted sampling and hyperparameter settings are available in the supplement.

Qualitative comparisons on GTA5 \(\rightarrow \) Cityscapes. Our model gives better results than the baseline. (Best viewed in color).

t-SNE visualization of a baseline (a) and our model (b). (Best viewed in color).
4.2 Results
Quantitative Results. We compare our method with the state-of-the-art methods on GTA5 \(\rightarrow \) Cityscapes and SYNTHIA \(\rightarrow \) Cityscapes in Tables 1 and 2, respectively. Note that all methods in the tables are based on the DeepLab-V2 [1] architecture with ResNet-101, except for CAG-UDA [53]. For a fair comparison, we report the results of ProDA [52] using the same network architecture as other methods, reproduced using an official source code. CBST [58] uses a self-training-based method to perform a class-aware alignment. This method is similar to our baseline, but it uses a limited number of pseudo labels, being outperformed by our approach on both benchmarks. PLCA [20] uses a pixel-wise association method to align source and target domains in a pixel-level. This method, however, fails to obtain compact feature representations, and it is hence outperformed by our approach on both benchmarks. CorDA [47] uses depth maps of source and target domains to transfer the knowledge of a source domain to a target one. Our method outperforms CorDA [47] on both benchmarks even without using the depth information, indicating that our contrastive learning framework effectively transfers the knowledge across domains using pseudo labels. ProDA [52] focuses on removing false-positives of pseudo labels [58] and uses sparse labels. Different from ProDA [52], we are interested in generating additional labels based upon the ones obtained by the approach of [58]. That is, our method focuses on obtaining more true-positives and generating denser labels using pixel-prototype correspondences. Other than ProDA [52], we additionally use the bi-directional contrastive loss to minimize intra-class variations and maximize inter-class variations of pixel-level features. We achieve mIoU gains of 0.6% and 1.6% for GTA5 \(\rightarrow \) Cityscapes and SYNTHIA \(\rightarrow \) Cityscapes, respectively, compared to ProDA [52]. The results imply that our method effectively learns domain-invariant and discriminative representations with denser pseudo labels, improving the mIoU performance of semantic segmentation. Additional comparisons with ProDA [52] are available in the supplement. We also report mIoU scores for the test split of Cityscapes, obtained from an official evaluation server, which has been ignored by most previous works. We use official source codes provided by the authors to obtain the results of state-of-the-art methods. We achieve non-trivial mIoU gains over CorDA [47] and ProDA [52] for the test split of Cityscapes, demonstrating that ours can generalize better than them. Considering the performance gains of recent UDASS methods, the results are significant. For example, FDA [51] achieves a mIoU gain of 0.3% over CAG_UDA [53], and TPLD [37] gets the gain of 0.7% over FDA [51]. CorDA [47] and ProDA [52] provide large mIoU gains compared to other methods, but the improvements mainly come from exploiting additional depth maps and applying post-processing method, respectively.
Qualitative Results. We show in Fig. 4 segmentation results on the GTA5 \(\rightarrow \) Cityscapes task. Compared to the baseline model, our model provides more accurate segmentation results (e.g., the bus in the first row, and the road and the rider in the second row). We show in Fig. 5 the t-SNE plot of feature representations of our model and the baseline. We visualize features of source and target images for each method by red and blue circles, respectively. The results show that our method successfully aligns the features for the same object category and separates them for different ones. That is, it minimizes intra-class variations, and maximizes inter-class variations, regardless of domains.
Ablation Study. We present in Table 3 an ablation analysis for each component of our framework on GTA5 \(\rightarrow \) Cityscapes and SYNTHIA \(\rightarrow \) Cityscapes. We show mIoU scores for variants of our model on the validation split of Cityscapes. As a baseline in the first row, we use static pseudo labels, obtained by the method of [58], to perform a class-aware alignment between source and target domains. We can see from the second row that FCL gives better mIoU scores, demonstrating the effectiveness of our approach to aligning prototypes and pixel-level features across domains. From the first and third rows, we can clearly see that jointly optimizing two contrastive terms is effective to UDASS. The fourth row demonstrates that leveraging additional dynamic pseudo labels provides better results than exploiting the static ones alone in terms of the mIoU score, even without the calibration (w/o cal.). We can observe from the fifth row that the calibration (w/ cal.) reduces domain discrepancies, and further improves the performance significantly.

Visualization of dynamic pseudo labels. (a–b) Pseudo labels obtained without and with calibrating prototypes of a source domain; (c) Target labels.

Pseudo labels at 30k and 60k iterations using \(\rho _\text {S}\) (a) and \(\mu _\text {S}\) (b), respectively.
Comparison of Pseudo Labels. We measure the densities of various pseudo labels and corresponding label accuracies, and report the results in Table 4. We can see that the densities of dynamic pseudo labels are slightly higher than that of a static one, even without calibrating domain biases, while maintaining the label accuracies. Using pixel-prototype correspondences between target and source domains leads to obtaining denser labels than [58]. The calibration process largely densifies dynamic pseudo labels. We can establish more correct correspondences between source and target domains by using the calibration process. The approach of [58] neglects the biases between source and target domains. Different from [58], ours compensate for the class-wise domain biases and generate more accurate and denser labels than [58]. Hybrid pseudo labels that combine static and dynamic ones provide the best result in terms of the label density and accuracy. When obtaining hybrid pseudo labels, we can reduce the number of incorrect static labels [58] by comparing them with dynamic ones. We show in Fig. 6 examples of dynamic pseudo labels obtained with and without the class-wise calibration. The results show that calibrating class-wise domain biases for source prototypes leads to establishing more correct pixel-prototype correspondences, providing denser and more accurate pseudo labels.
In Fig. 7, we compare generated pseudo labels using instance-wise prototypes \(\rho _\text {S}\) and momentum-based ones \(\mu _\text {S}\). We can see that using instance-wise prototypes \(\rho _\text {S}\) provides more diverse pseudo labels. They are more various than the other ones \(\mu _\text {S}\) slowly moving with momentum, and lead our model to establish diverse pixel-prototype correspondences.
5 Conclusion
We have introduced a novel contrastive learning framework for UDASS. Our key idea is to use cross-domain pixel-prototype correspondences to learn domain-invariant and discriminative representations. We have introduced a bi-directional contrastive loss to align the features for the same object category and seperate them for different ones. We have also introduced an approach to generating pseudo labels dynamically in a nonparametric way using pixel-prototype correspondences, while compensating class-wise domain biases between source and target domains. Experimental results show the effectiveness of our framework, setting a new state of the art on standard benchmarks.
References
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected CRFs. ICLR (2015)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: ICML (2020)
Chen, Y.H., Chen, W.Y., Chen, Y.T., Tsai, B.C., Frank Wang, Y.C., Sun, M.: No more discrimination: cross city adaptation of road scene segmenters. In: ICCV (2017)
Chen, Y., Li, W., Van Gool, L.: ROAD: reality oriented adaptation for semantic segmentation of urban scenes. In: CVPR (2018)
Chen, Y.C., Lin, Y.Y., Yang, M.H., Huang, J.B.: CrDoCo: pixel-level domain transfer with cross-domain consistency. In: CVPR (2019)
Cordts, M., et al.: The cityscapes dataset. In: CVPR Workshop (2015)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: CVPR (2009)
Di, S., Zhang, H., Li, C.G., Mei, X., Prokhorov, D., Ling, H.: Cross-domain traffic scene understanding: a dense correspondence-based transfer learning approach. IEEE Trans. ITS 19(3), 745–757 (2017)
Dong, N., Xing, E.P.: Few-shot semantic segmentation with prototype learning. In: BMVC (2018)
Du, L., et al.: SSF-DAN: separated semantic feature based domain adaptation network for semantic segmentation. In: ICCV (2019)
Fang, Z., Wang, J., Wang, L., Zhang, L., Yang, Y., Liu, Z.: SEED: self-supervised distillation for visual representation. ICLR (2021)
Ganin, Y., et al.: Domain-adversarial training of neural networks. JMLR 17(1), 1–35 (2016)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: CVPR (2020)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Hoffman, J., et al.: CyCADA: cycle-consistent adversarial domain adaptation. In: ICML (2018)
Hoffman, J., Wang, D., Yu, F., Darrell, T.: FCNs in the wild: pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649
Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., Liu, W.: CCNet: criss-cross attention for semantic segmentation. In: ICCV (2019)
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with conditional adversarial networks. In: CVPR (2017)
Kang, G., Jiang, L., Yang, Y., Hauptmann, A.G.: Contrastive adaptation network for unsupervised domain adaptation. In: CVPR (2019)
Kang, G., Wei, Y., Yang, Y., Zhuang, Y., Hauptmann, A.: Pixel-level cycle association: a new perspective for domain adaptive semantic segmentation. In: NeurIPS (2020)
Kiefer, J., Wolfowitz, J.: Stochastic estimation of the maximum of a regression function. Ann. Math. Stat. 23, 462–466 (1952)
Li, G., Kang, G., Liu, W., Wei, Y., Yang, Y.: Content-consistent matching for domain adaptive semantic segmentation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12359, pp. 440–456. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58568-6_26
Li, Y., Yuan, L., Vasconcelos, N.: Bidirectional learning for domain adaptation of semantic segmentation. In: CVPR (2019)
Liu, C., Yuen, J., Torralba, A.: SIFT flow: dense correspondence across scenes and its applications. IEEE Trans. PAMI 33(5), 978–994 (2010)
Liu, C., Yuen, J., Torralba, A.: Nonparametric scene parsing via label transfer. IEEE Trans. PAMI 33(12), 2368–2382 (2011)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR (2015)
Luo, Y., Liu, P., Guan, T., Yu, J., Yang, Y.: Significance-aware information bottleneck for domain adaptive semantic segmentation. In: ICCV (2019)
Luo, Y., Zheng, L., Guan, T., Yu, J., Yang, Y.: Taking a closer look at domain shift: category-level adversaries for semantics consistent domain adaptation. In: CVPR (2019)
Malisiewicz, T., Gupta, A., Efros, A.A.: Ensemble of Exemplar-SVMs for object detection and beyond. In: ICCV (2011)
Murez, Z., Kolouri, S., Kriegman, D., Ramamoorthi, R., Kim, K.: Image to image translation for domain adaptation. In: CVPR (2018)
Najafi, M., Namin, S.T., Salzmann, M., Petersson, L.: Sample and filter: nonparametric scene parsing via efficient filtering. In: CVPR (2016)
Richter, S.R., Vineet, V., Roth, S., Koltun, V.: Playing for data: ground truth from computer games. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 102–118. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_7
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Ros, G., Sellart, L., Materzynska, J., Vazquez, D., Lopez, A.M.: The SYNTHIA dataset: a large collection of synthetic images for semantic segmentation of urban scenes. In: CVPR (2016)
Russell, B.C., Efros, A., Sivic, J., Freeman, W.T., Zisserman, A.: Segmenting scenes by matching image composites (2009)
Sankaranarayanan, S., Balaji, Y., Jain, A., Lim, S.N., Chellappa, R.: Unsupervised domain adaptation for semantic segmentation with GANs. arXiv preprint arXiv:1711.06969
Shin, I., Woo, S., Pan, F., Kweon, I.S.: Two-phase pseudo label densification for self-training based domain adaptation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12358, pp. 532–548. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58601-0_32
Shrivastava, A., Malisiewicz, T., Gupta, A., Efros, A.A.: Data-driven visual similarity for cross-domain image matching. In: SIGGRAPH Asia (2011)
Singh, G., Kosecka, J.: Nonparametric scene parsing with adaptive feature relevance and semantic context. In: CVPR (2013)
Snell, J., Swersky, K., Zemel, R.S.: Prototypical networks for few-shot learning. In: NeurIPS (2017)
Song, L., et al.: Learnable tree filter for structure-preserving feature transform. In: NeurIPS (2019)
Sun, R., Zhu, X., Wu, C., Huang, C., Shi, J., Ma, L.: Not all areas are equal: transfer learning for semantic segmentation via hierarchical region selection. In: CVPR (2019)
Tsai, Y.H., Hung, W.C., Schulter, S., Sohn, K., Yang, M.H., Chandraker, M.: Learning to adapt structured output space for semantic segmentation. In: CVPR (2018)
Tsai, Y.H., Sohn, K., Schulter, S., Chandraker, M.: Domain adaptation for structured output via discriminative patch representations. In: ICCV (2019)
Uricchio, T., Ballan, L., Seidenari, L., Del Bimbo, A.: Automatic image annotation via label transfer in the semantic space. PR 71, 144–157 (2017)
Wang, K., Liew, J.H., Zou, Y., Zhou, D., Feng, J.: PANet: few-shot image semantic segmentation with prototype alignment. In: ICCV (2019)
Wang, Q., Dai, D., Hoyer, L., Van Gool, L., Fink, O.: Domain adaptive semantic segmentation with self-supervised depth estimation. In: ICCV (2021)
Wang, Z., et al.: Differential treatment for stuff and things: a simple unsupervised domain adaptation method for semantic segmentation. In: CVPR (2020)
Yang, J., An, W., Wang, S., Zhu, X., Yan, C., Huang, J.: Label-driven reconstruction for domain adaptation in semantic segmentation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12372, pp. 480–498. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58583-9_29
Yang, Y., Lao, D., Sundaramoorthi, G., Soatto, S.: Phase consistent ecological domain adaptation. In: CVPR (2020)
Yang, Y., Soatto, S.: FDA: Fourier domain adaptation for semantic segmentation. In: CVPR (2020)
Zhang, P., Zhang, B., Zhang, T., Chen, D., Wang, Y., Wen, F.: Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In: CVPR (2021)
Zhang, Q., Zhang, J., Liu, W., Tao, D.: Category anchor-guided unsupervised domain adaptation for semantic segmentation. In: NeurIPS (2019)
Zhang, Y., David, P., Gong, B.: Curriculum domain adaptation for semantic segmentation of urban scenes. In: ICCV (2017)
Zhang, Y., Qiu, Z., Yao, T., Liu, D., Mei, T.: Fully convolutional adaptation networks for semantic segmentation. In: CVPR (2018)
Zheng, S., et al.: Conditional random fields as recurrent neural networks. In: ICCV (2015)
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: ICCV (2017)
Zou, Y., Yu, Z., Vijaya Kumar, B.V.K., Wang, J.: Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11207, pp. 297–313. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01219-9_18
Zou, Y., Yu, Z., Liu, X., Kumar, B., Wang, J.: Confidence regularized self-training. In: ICCV (2019)
Acknowledgements
This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No. RS-2022-00143524, Development of Fundamental Technology and Integrated Solution for Next-Generation Automatic Artificial Intelligence System, and No. 2022-0-00124, Development of Artificial Intelligence Technology for Self-Improving Competency-Aware Learning Capabilities), and the Yonsei Signature Research Cluster Program of 2022 (2022-22-0002).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Lee, G., Eom, C., Lee, W., Park, H., Ham, B. (2022). Bi-directional Contrastive Learning for Domain Adaptive Semantic Segmentation. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13690. Springer, Cham. https://doi.org/10.1007/978-3-031-20056-4_3
Download citation
DOI: https://doi.org/10.1007/978-3-031-20056-4_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-20055-7
Online ISBN: 978-3-031-20056-4
eBook Packages: Computer ScienceComputer Science (R0)