
Abstract
In open-set recognition (OSR), classifiers should be able to reject unknown-class samples while maintaining high closed-set classification accuracy. To effectively solve the OSR problem, previous studies attempted to limit latent feature space and reject data located outside the limited space via offline analyses, e.g., distance-based feature analyses, or complicated network architectures. To conduct OSR via a simple inference process (without offline analyses) in standard classifier architectures, we use distance-based classifiers instead of conventional Softmax classifiers. Afterwards, we design a background-class regularization strategy, which uses background-class data as surrogates of unknown-class ones during training phase. Specifically, we formulate a novel regularization loss suitable for distance-based classifiers, which reserves sufficiently large class-wise latent feature spaces for known classes and forces background-class samples to be located far away from the limited spaces. Through our extensive experiments, we show that the proposed method provides robust OSR results, while maintaining high closed-set classification accuracy.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Generalized open-set recognition
- Distance-based classifiers
- Background-class regularization
- Probability of inclusion
1 Introduction
In machine learning (ML), classification algorithms have achieved great success. Through recent advances in convolutional neural networks, their classification performance already surpassed the human-level performance in image classification [8]. However, such algorithms have usually been developed under a closed-set assumption, i.e., the class of each test sample is assumed to always belong to one of the pre-defined set of classes. Although this conventional assumption can be easily violated in real-world applications (classifiers can face unknown-class data), traditional classification algorithms are highly likely to force unknown-class samples to be classified into one of the known classes. To tackle this problem, the open-set recognition (OSR) problem [34] aims to properly classify unknown-class samples as “unknown” and known-class samples as one of the known classes.
According to the definition of OSR [34], it is required to properly limit the latent feature space of known-class data. To satisfy the requirement, various OSR methods were developed based on traditional ML models. Previously, Scheirer et al. [33] calibrated the decision scores of support vector machines (SVMs). Based on the intuition that a large set of data samples of unknown classes can be rejected if those of known classes are accurately modeled, Jain et al. [13] proposed \(P_I\)-SVM, which utilized the statistical modeling of known-class samples located near the decision boundary of SVMs. Afterwards, it was attempted to solve the OSR problem based on the principle of the nearest neighbors [14]. Taking distribution information of data into account, Rudd et al. [29] proposed the extreme value machine which utilizes the concept of margin distributions.
Since deep neural networks (DNNs) have robust classification performance by learning high-level representations of data, OSR methods for DNNs have received great attention. Based on the theoretical foundations studied in traditional ML-based OSR methods, Bendale and Boult [1] proposed the first OSR strategy for DNNs called Openmax, which calibrates the output logits of pre-trained Softmax classifiers. To improve Openmax, Yoshihashi et al. [41] proposed the classification-reconstruction learning to make robust latent feature vectors. Afterwards, Oza and Patel [27] proposed to exploit a class-conditioned autoencoder and use its reconstruction error to assess each input sample. Sun et al. [37] employed several class-conditioned variational auto-encoders for generative modeling.
Although previous methods applied offline analyses to pre-trained Softmax classifiers or employed complicated DNN architectures, they have limited performance since the classifiers were trained solely based on known-class data. To mitigate the problem, this paper designs an simple and effective open-set classifier in the generalized OSR setting, which uses background-class regularization (BCR) at training time. Despite its effectiveness, BCR has received a little attention in OSR and previous BCR methods [5, 11, 21] are insufficient to properly solve the OSR problem. In this paper, we denote the infinite label space of all classes as \(\mathcal {Y}\) and use the following class categories, whose definition is also provided in [5, 7].
-
Known known classes (KKCs; \(\mathcal {K}= \{1,\cdots ,C\} \subset \mathcal {Y}\)) include distinctly labeled positive classes, where \(\mathcal {U}=\mathcal {Y}\setminus \mathcal {K}\) is the entire unknown classes.
-
Known unknown classes (KUCs; \(\mathcal {B}\subset \mathcal {U}\)) include background classes, e.g., labeled classes which are not necessarily grouped into a set of KKCs \(\mathcal {K}\).
-
Unknown unknown classes (UUCs; \(\mathcal {A}=\mathcal {U}\setminus \mathcal {B}\)) represent the rest of \(\mathcal {U}\), where UUCs are not available at training time, but occur at inference time.
Also, we denote \(\mathcal {D}_{t}\) as a training set consisting of multiple pairs of a KKC data sample and the corresponding class label \(y \in \{1,\cdots ,C\}\). \(\mathcal {D}_{test}^{k}\) and \(\mathcal {D}_{test}^{u}\) are test sets of KKCs and UUCs, respectively. \(\mathcal {D}_{b}\) is a background dataset of KUCs.
2 Preliminary Studies
2.1 The Open-Set Recognition Problem
The OSR problem addresses a classification setting that can face test samples from classes unseen during training (UUCs). In this setting, open-set classifiers aim to properly classify KKC samples while rejecting UUC ones simultaneously. A similar problem to OSR is out-of-distribution (OoD) detection [10], which typically aims to reject data items drawn far away from the training data distribution. Conventionally, previous studies such as [10, 17, 18, 20] assumed that OoD samples are drawn from other datasets or can be even noise data. In this paper, we aim to reject test data whose classes are unknown but related to the training data, which narrows down the scope of conventional OoD detection tasks.

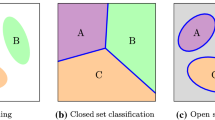
Given (a) a latent feature space, we demonstrate (b) closed-set and (c) open-set problems, where KKCs and UUCs are known and unknown classes, respectively.
Previously, Scheirer et al. [34] introduced a formal definition of OSR based on the notion of open-space risk \(R_{\mathcal {O}}\), which is a relative measure of a positively labeled union of balls \(\mathcal {S}_V\) and open space \(\mathcal {O}\) located far from \(\mathcal {S}_V\). Since labeling any data item in \(\mathcal {O}\) incurs open-space risk, it is straightforward that a classifier cannot be a solution for the OSR problem if the classifier accepts data in infinitely wide regions, i.e., its open-space risk is unbounded (\(R_{\mathcal {O}} = \infty \)). The definition implies that essential requirements to solve the OSR problem are 1) bounding open-space risk and 2) ideally balancing it with empirical risk.
Unlike traditional classifier models, open-set classifiers are required to limit the latent feature space of KKC data to bound their open-space risk. To ensure open-space risk to be bounded, Scheirer et al. [33] introduced compact abating probability (CAP) models. The principle of CAP models is that if the support region of a classifier decays in all directions from the training data, thresholding the region will bound the classifier’s open-space risk [2]. As depicted in Fig. 1, which compares traditional closed-set and open-set classification problems [7], building proper class-wise CAP models is an effective strategy for OSR.
2.2 Post-Classification Analysis for Pre-Trained Softmax Classifier
This paper aims to solve the OSR problem solely based on a standard DNN-based classifier architecture f as a latent feature extractor. Applying a fully-connected layer to f, a conventional Softmax classifier computes the posterior probability of an input \(\textbf{x}\) belonging to the c-th known class by
where \(c \in \{1,\cdots ,C\}\), \(f(\textbf{x}) \in \mathbb {R}^n\) is the latent feature vector of \(\textbf{x}\), and \(\textbf{w}_c\) and \(b_c\) are the weight and bias for the c-th class, respectively. For pre-trained Softmax classifiers, Hendrycks and Gimpel [10] proposed a baseline technique to detect anomalous samples, which imposes a threshold on the predictive confidence of Eq. (1). When using the baseline approach to solve the OSR problem, one can estimate the class of each KKC sample and recognize UUC data by
However, Eq. (2) cannot formally bound open-space risk and formulate class-wise CAP models since it only rejects test data near the decision boundary of classifiers, thus having infinitely wide regions of acceptance [2]. Therefore, post-classification analysis methods using an auxiliary measure other than the Softmax probability are necessary to build auxiliary CAP models in the latent feature space of f, where distance measures have been widely employed in previous studies [1, 18].
To build class-wise CAP models, Openmax [1] defined radial-basis decaying functions \(\{s(\textbf{x},i)\}_{i=1}^C\), each of which measures the class-belongingness of \(\textbf{x}\) for the c-th class, in the latent feature space of f. For each \(s(\textbf{x},c)\), the authors employed distance measures between \(f(\textbf{x})\) and an empirical class mean vector \(\boldsymbol{\mu }_c\), e.g., \(s(\textbf{x},c) = D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c) = (f(\textbf{x})-\boldsymbol{\mu }_c)^T(f(\textbf{x})-\boldsymbol{\mu }_c)\). To formulate more effective CAP models, they statistically analyzed the distribution of \(s(\textbf{x},c)\) based on the extreme value theory (EVT) [32], which provides a theoretical foundation that the Weibull distribution is suitable for modeling KKC samples located far from the class mean vectors (extreme samples). To be specific, Openmax fits a Weibull distribution on extreme samples of the c-th class having the highest \(D_E(f(\textbf{x}), \boldsymbol{\mu }_c)\) values, where its cumulative distribution function (CDF) formulates the probability of inclusion \(P_I(\textbf{x},c)\) [13, 29], i.e., \(P_I(\textbf{x},c) = 1 - \texttt {WeibullCDF}\), which rapidly decays near the extreme samples. Based on \(P_I(\textbf{x},c)\), the decision rule of Eq. (2) can be calibrated to conduct OSR with Softmax classifiers.
2.3 Background-Class Regularization
Although they need additional inference procedures (e.g., EVT modeling), previous offline analyses may have limited OSR performance since the classifiers were trained solely based on known-class data. To obtain robust empirical results without complicated analyses, one can use the strategy of BCR at the training phase, which exploits background-class (KUC) samples as surrogates of UUC data. Geng et al. [7] argued that the generalized OSR setting that utilizes KUC samples is still less-explored and an important research direction for robust OSR.
Conventionally, a loss function for training classifiers with BCR can be
where \(\mathcal {L}_{cf}\) and \(\mathcal {L}_{bg}\) are the loss terms for closed-set classification and BCR, respectively, and \(\lambda \) is a hyperparameter. For \(\mathcal {L}_{bg}\), previous studies designed their own \(f_{reg}\), where [5] proposed the objectosphere loss for OSR, and [11] and [21] employed the uniformity and the energy losses for OoD detection, respectively.
In this paper, we tackle the following limitations of the previous BCR methods.
-
In the previous BCR methods, \(\mathcal {L}_{bg}\) were designed to make normal data and anomalies more distinguishable in terms of the corresponding anomaly scores. Since they categorized normal data into a single group (did not consider the classes) in \(\mathcal {L}_{bg}\), the previous methods may have limited performance in rejecting UUC data and maintaining robust closed-set classification results.
-
The previous methods using the decision rule of Eq. (2) (e.g., objectosphere [5] and uniformity [11]) cannot bound open-space risk. Although one can use post-classification analyses to bound open-space risk, trained latent feature space can be inappropriate for using another metric such as distance measures.
-
To increase the gap between KKC and KUC data in terms of latent feature magnitude and energy in the objectosphere [5] and the energy [21] losses, respectively, it is necessary to find proper margin parameters for each dataset.
3 Proposed Method
3.1 Overview
Using a standard classifier f, this paper aims to design open-set classifiers having simple yet effective inference steps. In the following, we summarize our method.
-
Instead of applying fully-connected layers to feature extractors f, we use the principle of linear discriminant analysis (LDA) [24] to classify images based on a distance measure. By simply imposing a threshold on the distance as in Eq. (2), our classifiers can easily build class-wise CAP models. (Sect. 3.2)
-
Afterwards, we propose a novel BCR strategy suitable for the distance-based classifiers. Following the convention of Eq. (3), we design our own \(\mathcal {L}_{bg}\) called class-inclusion loss, where our total loss is function defined by
$$\begin{aligned} \mathcal {L} = \mathcal {L}_{cf} + \lambda \mathcal {L}_{bg} = \mathcal {L}_{cf} + \lambda ( \mathcal {L}_{bg,k}+\mathcal {L}_{bg,u}) \end{aligned}$$(4)The class-inclusion loss first limits the feature space of KKC data by formulating explicit class-wise boundaries, and then forces KUC data to be located outside the boundaries at each training iteration. Our loss is designed to increase the distance gaps between KKC and KUC samples while maintaining robust closed-set classification performance. (Sects. 3.3 and 3.4)
For a better understanding of the training and inference processes of our method, we provide their detailed algorithm in our supplementary materials.
3.2 Distance-Based Classification Models
Distance-based Classifiers. To train a robust open-set classifier, we formulate a distance-based classifier as an alternative of Eq. (1):
where Eq. (5) uses the principle of LDA and \(\mathcal {L}_{cf} = \mathbb {E}_{(\textbf{x}^k, y)\sim \mathcal {D}_{t}} [- \log P_d(y|\textbf{x}^k)]\). In Eq. (5), we exploit an identity covariance matrix \(\textbf{I}\) and \(P_c = P(y=c)=C^{-1}\) for all c for KKCs. The classifier estimates the class of each \(\textbf{x}\) via \(D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c) = (f(\textbf{x})-\boldsymbol{\mu }_c)^T(f(\textbf{x})-\boldsymbol{\mu }_c)\), the Euclidean distance between \(f(\textbf{x}) \in \mathbb {R}^n\) and \(\boldsymbol{\mu }_c \in \mathbb {R}^n\), where we call \(\boldsymbol{\mu }_c\) a class-wise anchor. To ensure sufficiently large distance gaps between the pairs of initial class-wise anchors, we randomly sample each \(\boldsymbol{\mu }_c\) from the standard Gaussian distribution and then set each \(\boldsymbol{\mu }_c\) as a trainable vector. For distance analysis results of such randomly sampled vectors, see [12].
Decision Rule. At inference time, each KKC sample \(\textbf{x}\) can be classified via \(\widehat{y} = {\mathop {\hbox {arg min}}\nolimits _{c \in \{1,\cdots ,C\}}} D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c)\). Furthermore, applying a threshold to \(D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c)\) can bound open-space risk by formulating class-wise CAP models as follows:
As Eq. (6) employs the same metric \(D_E\) for classification and UUC rejection, our method may support more accurate latent feature space analysis for OSR than the previous OSR methods using post-classification analyses.
The concept of distance-based classification was also employed in prototypical networks [36], nearest class mean classifiers [23], and the previous studies of the center loss function [38] and convolutional prototype classifiers [40]. In addition, polyhedral conic classifiers [3] used the idea of returning compact class regions for KKC samples based on distance-based feature analyses. It is noteworthy that our main contribution is a novel BCR method that can effectively utilize KUC samples in a distance-based classification scheme (described in Sect. 3.3 and 3.4), not the distance-based classifier method itself. To the best of our knowledge, we are the first to discuss the necessity of distance-based BCR methods for OSR and propose a reasonable regularization method for distance-based classifiers.
3.3 Background Class Regularization for Distance-based Classifiers
Intuition and Hypersphere Classifiers. To obtain robust OSR performance via Eq. (6), we aim to design a BCR method suitable for distance-based classifiers, which uses \(\mathcal {D}_{t}\) and \(\mathcal {D}_b\) as surrogates of \(\mathcal {D}_{test}^k\) and \(\mathcal {D}_{test}^u\) at training time, respectively. Although it cannot provide any information of \(\mathcal {D}_{test}^{u}\), \(\mathcal {D}_b\) can be effective to limit the latent feature space of KKCs, while reserving space for UUCs. With \(\mathcal {D}_b\), it is intuitive that the primary objective of BCR for Eq. (6) is to make KUC samples located far away from \(\boldsymbol{\mu }_i\) for all classes \(i \in \{1,\cdots ,C\}\).
Before we illustrate our BCR method, we first introduce hypersphere classifiers (HSCs) [30]. An HSC conducts anomaly detection by using a feature extractor g, where its anomaly score for an input \(\textbf{x}\) is the Euclidean distance between a single center vector \(\boldsymbol{\mu }\) and \(g(\textbf{x})\). When training the HSC model, the authors used normal and background data, \(\mathcal {D}_{t}\) and \(\mathcal {D}_{b}\), respectively, and a loss function
The loss function is designed to decrease the Euclidean distances between normal samples \(\textbf{x}^k\) and \(\boldsymbol{\mu }\) while increasing the distances for background samples \(\textbf{x}^b\). In Eq. (7), \(h(x) = \sqrt{x + 1} - 1\), which implies that the Euclidean distance \(D_E^2(g(\textbf{x}), \boldsymbol{\mu })\) is scaled into the range of (0, 1] via \(\exp (-h(D_E^2(g(\textbf{x}), \boldsymbol{\mu })))\).
Background-class Regularization Strategy. It is straightforward that the decision rule of Eq. (6) employs the principle of HSCs in a class-wise manner. In other words, the class-wise HSC for the c-th class determines whether a test sample belongs to the c-th class by computing \(D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c)\), where the input is determined as UUC if the entire class-wise HSCs reject the data item. Thus, a proper BCR strategy for distance-based classifiers should force each KUC sample \(\textbf{x}^b\) to be rejected by the entire class-wise HSCs (increase \(D_E^2(f(\textbf{x}^b), \boldsymbol{\mu }_i)\) for all i). Since it is inefficient to consider the entire KKCs to regularize f with \(\textbf{x}^b\) at each iteration, we approximate the process by only taking the closest class-wise HSC into account (increase \(\min _{i\in \{1,\cdots ,C\}} D_E^2(f(\textbf{x}^b), \boldsymbol{\mu }_i)\)).
Although one can adopt Eq. (7) to formulate \(\mathcal {L}_{bg}\) for distance-based classifiers, scaling \(D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c)\) into (0, 1] via \(\exp (-h(D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c)))\), which rapidly decays near \(\boldsymbol{\mu }_c\), can be insufficient to move KUC data far away from class-wise anchors. Therefore, we design \(\mathcal {L}_{bg}\) that can guarantee sufficient spaces for KKC data and simultaneously force KUC samples located outside the limited class-wise spaces.
3.4 Probability of Inclusion and Class-Inclusion Loss
As we described in Sect. 2.2, the probability of inclusion builds effective CAP models, since it is designed to rapidly decay near extreme data, i.e., \(P_I(\textbf{x},c) \approx 1\) in the region that a majority of class-c KKC samples are located. In the following, we introduce a novel regularization method for distance-based classifiers based on the principle of the probability of inclusion, and then design a loss function.
Probability of Inclusion for Distance-Based Classifiers. For pre-trained Softmax classifiers, Openmax [1] formulated the probability of inclusion via EVT modeling at inference time, where the strategy is to find implicit class-wise boundaries that distinguish KKCs from UUCs. However, such EVT-based analysis can be intractable at each training iteration, since it requires computationally-expensive and parameter-sensitive processes. In addition, it is inappropriate to make boundaries by analyzing features which are not properly trained yet.
Thus, we build explicit class-wise boundaries by formulating \(P_I(\textbf{x},c)\) based on the underlying assumption of LDA, and then use the boundaries for regularization without additional analysis of latent feature distribution. Under the assumption of LDA that each class-c latent feature vector is drawn from a unimodal Gaussian distribution \(\mathcal {N}(f(\textbf{x})|\boldsymbol{\mu }_c, \textbf{I})\), the Euclidean distance \(D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c)\), a simplified version of the Mahalanobis distance, can be assumed to follow the Chi-square distribution having the degree of freedom n. Then, we have
where \(t \ge 0\), \(\varGamma (\cdot )\) is the Gamma function, and n is the dimension of \(f(\textbf{x})\).
As previous studies [1, 13, 29] formulated the probability of inclusion by computing the CDF of the Weibull distribution, i.e., \(P_I(\textbf{x},c) = 1 - \texttt {WeibullCDF}\), we define our \(P_I(\textbf{x},c)\) by using the CDF of Eq. (8) as follows:
where \(\varGamma (\cdot , \cdot )\) is the upper incomplete Gamma function. It is noteworthy that Eq. (9) can be easily computable via \(\texttt {igammac}\) function in PyTorch [28].

\(P_H\) and \(P_I\) (Ours).
Class-inclusion Loss Function. Based on \(\mathcal {D}_{t}\), \(\mathcal {D}_{b}\), and our \(P_I(\textbf{x},c)\) of Eq. (9), the primary objective of the proposed BCR strategy, which aims to force each KUC data sample to be located far away from the closest class-wise HSC, can be achieved by employing a loss function \(\mathcal {L}_{bg,u} = \mathbb {E}_{\textbf{x}^b \sim \mathcal {D}_{b}}[-\log (1 - \max _{i\in \{1,\cdots ,C\}} P_I(\textbf{x}^b,i)) ]\). To compare \(P_I(\textbf{x},c)\) and \(P_H(\textbf{x},c) = \exp (-h(D_E^2(f(\textbf{x}), \boldsymbol{\mu }_c)))\), which was used in Eq. (7), we plot \(P_I(\textbf{x},c)\) and \(P_H(\textbf{x},c)\) in Fig. 2 with respect to \(||f(\textbf{x}) - \boldsymbol{\mu }_c||\) by assuming \(n=128\). The figure implies that unlike \(P_H(\textbf{x},c)\), our \(P_I(\textbf{x},c)\) can assign sufficiently large space for KKC data and force KUC samples to be located outside the space. Also, it is noteworthy that our regularization method based on \(P_I(\textbf{x},c)\) does not require any margin parameters dependent on datasets or the dimension of latent features.
At training time, \(P_I(\textbf{x},c) = 0.5\) constructs an auxiliary decision boundary between the c-th class KKC data and the other data items, where \(\mathcal {L}_{bg,u}\) makes a majority of KUC data to be located outside the entire class-wise boundaries. However, \(\mathcal {L}_{bg,u}\) can be insufficient to achieve robust UUC rejection and closed-set classification results, since it does not control correctly classified KKC samples to be located inside the corresponding class-wise boundaries. Therefore, in addition to \(\mathcal {L}_{cf} = \mathbb {E}_{(\textbf{x}^k, y)\sim \mathcal {D}_{t}} [- \log P_d(y|\textbf{x}^k)]\), we apply another loss \(\mathcal {L}_{bg,k}\) to KKC data to maintain high closed-set classification accuracy and enhance the gap between KKC and KUC samples in terms of the Euclidean distance. By formulating \(\mathcal {L}_{bg,k} = \mathbb {E}_{(\textbf{x}^k,y) \sim \mathcal {D}_{t}}[-\mathbbm {1}(y = \hat{c})\log (P_I(\textbf{x}^k,\hat{c}))]\), where \(\hat{c} = {\mathop {\hbox {arg max}}\nolimits _{i\in \{1,\cdots ,C\}}} P_I(\textbf{x}^k,i)\), we define our \(\mathcal {L}_{bg}\) as \(\mathcal {L}_{bg,k} + \mathcal {L}_{bg,u}\) and call \(\mathcal {L}_{bg}\) the class-inclusion loss.
In our total loss (Eq. (4)), \(\mathcal {L}_{cf}\) makes KKC samples be correctly classified, \(\mathcal {L}_{bg,u}\) makes KUC samples located outside the explicit class-wise boundaries, and \(\mathcal {L}_{bg,k}\) additionally regularizes correctly classified KKC samples. It is noteworthy that we use an additional loss for KKC samples after they are correctly classified, to prevent obstructions in training closed-set classifiers at early iterations.
4 Experiments
Through extensive experiments, we compared our class-inclusion loss for distance-based classifiers to the objectosphere [5], the uniformity (also widely known as OE) [11], and the energy [21] losses for conventional Softmax classifiers. This section aims to show that whether our approach provides competitive UUC rejection results, while keeping high closed-set classification accuracy. Furthermore, we conducted additional experiments and provided the corresponding discussions.
4.1 Experimental Settings
For evaluation, we first measured the closed-set classification accuracy. To quantify the accuracy of UUC data rejection, we also measured the area under the receiver operating characteristic curve (AUROC). Also, we used the open-set classification rate (OSCR) as additional OSR accuracy measure by quantifying the correct closed-set classification rate when the false positive rate for UUC rejection is \(10^{-1}\). For in-depth details of OSCR, see [5]. As \(\mathcal {D}_b\), we used ImageNet [31], which was also employed in [19]. To ensure that the classes of \(\mathcal {D}_b\) and our test sets are disjoint, we used only the remaining classes of ImageNet, which are not included in the test sets. In our experiments, we considered the following two settings.
Setting 1.
In Setting 1, a single dataset was split into KKCs and UUCs, where we used the KKCs in the training set as \(\mathcal {D}_{t}\), and the KKCs and UUCs in the test set as \(\mathcal {D}_{test}^k\) and \(\mathcal {D}_{test}^u\), respectively. Following the protocol in [25], which were also employed in [27, 37], we conducted experiments by using the following standard datasets: SVHN [26], CIFAR10 & CIFAR100 [15], and TinyImageNet [16].
SVHN, CIFAR10 For SVHN and CIFAR10, each of which consists of images of 10 classes, each dataset was randomly partitioned into 6 KKCs and 4 UUCs.
CIFAR+10, CIFAR+50 For CIFAR+M, we employed randomly selected 4 classes of CIFAR10 as KKCs and M classes of CIFAR100 as UUCs.
TinyImageNet For a larger number of classes, we randomly selected 20 classes of TinyImageNet as KKCs and then used the remaining 180 classes as UUCs.
Setting 2. By using the training and the test sets of a single dataset as \(\mathcal {D}_{t}\) and \(\mathcal {D}_{test}^k\), respectively, we employed the test set of another dataset relatively close to \(\mathcal {D}_{t}\) as \(\mathcal {D}_{test}^u\) in Setting 2. Adopting the experiment settings in [41] and [20], we used the entire classes of a dataset as KKCs for CIFAR10 & CIFAR100. For UUC dataset, TinyImageNet, LSUN [42], and iSUN [39] were selected. TinyImageNet and LSUN consists of 10,000 test samples each, where the samples in each dataset were resized (R) or cropped (C) into the size \(32 \times 32\). The iSUN dataset has 8,925 test samples and they were also resized into the size of \(32 \times 32\). The modified datasets can be obtained in the Github repository of [20].
4.2 Training Details
Network Selection. For f, we employed the Wide-ResNet (WRN) [43] and then used its penultimate layer \(f(\textbf{x}) \in \mathbb {R}^n\) for the latent feature vector of each input sample \(\textbf{x}\). For CIFAR10 and TinyImageNet, we used WRN 40-2 with a dropout rate of 0.3, where WRN 28-10 was employed for CIFAR100 with the same dropout rate. For SVHN, we used WRN 16-4 with a dropout rate of 0.4. Such network selection was determined by referring the experiments in [11, 43].
Parameters. For the entire BCR methods, we set the mini-batch sizes of KKC training samples and KUC samples to 128. We kept \(\lambda \) as a constant during training, i.e., each f was trained with the BCR method from scratch. To select hyperparameters and margin parameters of the previous regularization methods, we followed the official implementationsFootnote 1\(^{,}\)Footnote 2\(^{,}\)Footnote 3. For SVHN, CIFAR10, CIFAR100, and TinyImageNet, we trained the corresponding classifiers for 80, 100, 200, and 200 epochs, respectively, where we used the stochastic gradient descent for optimization. For SVHN and the other datasets, we used initial learning rates of 0.01 and 0.1, respectively, and a cosine learning rate decay [22]. We also used the learning rate warm-up strategy for the first 5 epochs of each training process.
4.3 Results
The OSR results of our proposed approach and the previous methods are reported in Tables 1 and 2. All the reported values were averaged over five randomized trials, by randomly sampling seeds, data splits of KKCs and UUCs, and class-wise anchors. In the tables, \(\uparrow \) and \(\downarrow \) indicate higher-better and lower-better measures, respectively, where underlined values present the best scores.
Setting 1. For the first setting, Table 1 compares our proposed BCR methods for distance-based classifiers with the previous approachs designed for Softmax classifiers. The results demonstrate that our proposed method obtained robust UUC rejection results, which were superior to the results of the previous approaches. It is noteworthy that our method achieved higher classification accuracy values, which were critical in acquiring better OSR results in terms of the OSCR measure, than the previous methods. Such results imply that the proposed framework effectively satisfies the two essential requirements described in Sect. 2.1, bounding open-space risk and ideally balancing it with empirical risk.
Setting 2. In Table 2, we present our experiment results of the second setting. When using the CIFAR10 and CIFAR100 datasets as KKC data, our approach achieved the highest closed-set classification accuracy, which is consistent with the experiment results of Setting 1. Furthermore, by averaging the AUROC and the OSCR values over the various UUC datasets, the table shows that our model outperformed the previous methods in the second setting.
Average Runtime. We conducted all the experiments with PyTorch and two GeForce RTX 3090 GPUs. At each trial in the CIFAR10 experiment of Setting 1, the running time of each training epoch took 28 s for our method, where its OSR evaluation required approximately 6.5 s. We observed that the other methods take similar running time at their training and inference phases.
4.4 Additional Experiments and Discussions
We further analyzed our BCR method by using various \(\lambda \) in our loss function. Furthermore, we compared our method by formulating another baseline using the triplet loss [35]. Using the CIFAR10 and TinyImageNet experiments in Setting 1, we present the corresponding OSR results. We also conducted various additional experiments that can show the effectiveness of our proposed method.
Selecting \(\lambda \). Conducting additional OSR experiments with \(\lambda \in \{0.1, 0.5, 1, 5, 10\}\) in our loss function \(\mathcal {L} = \mathcal {L}_{cf} + \lambda \mathcal {L}_{bg}\), Table 3 presents that our method provides robust OSR accuracy across a wide range of \(\lambda \), e.g., \(\lambda \in [1,5]\), which implies that users can flexibly select \(\lambda \) in our method. Although such range may depend on datasets, users are not required to carefully adjust the \(\lambda \) parameter. In additional experiments, \(\lambda = 5\) yielded the best OSR results in the SVHN and CIFAR + M experiments of Setting 1 and the CIFAR10 experiments of Setting 2, where \(\lambda =0.5\) showed the best results in the CIFAR100 experiments. Such empirical results implies that a lower \(\lambda \) value can be better when handling more KKCs.
Triplet Loss. We propose a distance-based BCR method suitable for the OSR problem, where the proposed method defines explicit class-wise boundaries and then increases the distance gap between KKC and KUC samples based on the boundaries. Another loss function that can separate KKC and KUC data in terms of such distance measure is the triplet loss, where the loss function has been widely employed to control the distances between latent feature vectors effectively. Therefore, we formulated a baseline distance-based BCR method by following the conventional definition of the triplet loss \(\mathcal {L}_{tri}\), where we set class-wise anchors, KKC training data, and KUC data as anchors, positive samples, and negative samples, respectively. Since we observed that training classifiers solely based on the triplet loss \(\mathcal {L} = \mathcal {L}_{tri}\) yields significantly worse OSR results in comparison with the regularization method \(\mathcal {L} = \mathcal {L}_{cf} + \lambda \mathcal {L}_{tri}\), we employed \(\mathcal {L}_{tri}\) as a regularization loss function for BCR. In Table 3, we reported experiment results by using the triplet loss as \(\mathcal {L}_{bg}\). The results show that our proposed method (class-inclusion loss) outperforms the regularization method based on the triplet loss.
Vanilla Distance-Based Classifiers. To show the effectiveness of our method, we assessed the OSR performance of vanilla distance-based classifiers (trained solely based on \(\mathcal {L}_{cf}\)), where we present the results in the form of (Accuracy/AUROC/OSCR). In the CIFAR10 and TinyImageNet experiments of Setting 1, we obtained (0.962/0.757/0.470) and (0.785/0.629/0.315), respectively. In the CIFAR10 and CIFAR100 experiments of Setting 2, the OSR results averaged over the five UUC datasets in vanilla distance-based classifiers were (0.936/0.838/0.709) and (0.766/0.807/0.549), respectively. Comparing these results to the results in Tables 1 and 2, we show that our regularization strategy can significantly improve the OSR performance of distance-based classifiers.
Ablation Study on Loss Terms. Recall our loss function \(\mathcal {L}_{cf} + \lambda (\mathcal {L}_{bg,k} + \mathcal {L}_{bg,u})\). As \(\mathcal {L}_{bg,u}\) is essential for BCR by making KUC samples located outside explicit class-wise boundaries, we conducted an ablation study to investigate the necessity of \(\mathcal {L}_{bg,k}\). In the absence of \(\mathcal {L}_{bg,k}\), which additionally regularizes correctly classified KKC data, we obtained the result of (0.963/0.821/0.509) for the (Accuracy/AUROC/OSCR) measures in the CIFAR10 experiment of Setting 1, which is worse than our original result (0.973/0.948/0.870). This result implies that \(\mathcal {L}_{bg,k}\) is necessary to increase the distance gap between KKC and KUC data.
Also, by designing \(\mathcal {L}_{bg}\) based on the original HSC loss function (Eq. (7)), we obtained the result of (0.950/0.634/0.338) for (Accuracy/AUROC/OSCR) in the CIFAR10 experiment of Setting 1, which supports our hypothesis.
Previous OSR Approaches. We additionally compared our proposed approach to previous OSR methods, whose OSR results are already reported in [6, 41]. For fair comparison, the entire methods presented in Table 4 (including ours) were implemented by using a VGG backbone and tested based on the codebase of (https://github.com/Anjin-Liu/Openset_Learning_AOSR). The table, which presents OSR results based on the macro-averaged F1 score measure, shows that our distance-based BCR approach can achieve robust OSR results via a simple inference process in standard classifier architectures.
ResNet-18 Architecture. In our main experiments, we used the WRN architectures as feature extractors. To further investigate the effectiveness of our method, we used another standard classifier architecture, ResNet-18 [9]. In the first setting, we obtained the quantitative results of (0.963/0.945/0.844), (0.966/0.950/0.845), (0.967/0.945/0.848), and (0.971/0.947/ 0.850) for the regularization methods using the objectosphere [5], the uniformity [11], the energy [21], and our class-inclusion losses, respectively. In addition to the results, Table 5 shows quantitative results in the second setting, where the results imply that our method can outperform the previous BCR methods with ResNet-18, as we observed in the experiments using the WRN architectures.
Text Classification. To show that our proposed BCR method can be applicable in another domain, we compared our class-inclusion loss to the uniformity loss in text classification applications. For text classification, we used 20 Newsgroups and WikiText103 for KKCs and KUCs, respectively, and trained a simple GRU model [4] for f as in [11]. As UUC sets, we used Multi30K, WMT16, and IMDB. Since the margin parameters of the objectosphere and the energy losses selected for image classification cannot be suitable for the text classification tasks, we only tested the uniformity loss for comparison. In Table 6, we present the results, where we additionally reported the area under the precision-recall curve (AUPR) and the false-positive rate at \(95\%\) true-positive rate (FPR95) measures. As it outperformed the uniformity loss in image classification tasks, our method also showed significantly better OSR accuracy in text classification. We provide more training details of our text classification models in our supplementary materials.
5 Concluding Remarks
In this paper, we propose a novel BCR method to train open-set classifiers that can provide robust OSR results with a simple inference process. By employing distance-based classifiers with the principle of LDA, we designed a novel class-inclusion loss based on the principle of probability of inclusion, which effectively limits the feature space of KKC data in a class-wise manner and then regularizes KUC samples to be located far away from the limited class-wise spaces. Through our extensive experiments, we present that our method can achieve robust UUC rejection performance, while maintaining high closed-set classification accuracy. As this paper aims to improve the reliability of modern DNN-based classifiers, we hope our work to enhance reliability and robustness in various classification applications by providing a novel methodology of handling UUC samples.
References
Bendale, A., Boult, T.E.: Towards open set deep networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1563–1572 (2016)
Boult, T.E., Cruz, S., Dhamija, A.R., Gunther, M., Henrydoss, J., Scheirer, W.J.: Learning and the unknown: surveying steps toward open world recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 33, pp. 9801–9807 (2019)
Cevikalp, H., Uzun, B., Köpüklü, O., Ozturk, G.: Deep compact polyhedral conic classifier for open and closed set recognition. Pattern Recogn. 119, 108080 (2021)
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: The 2014 Conference on Empirical Methods in Natural Language Processing (2014)
Dhamija, A.R., Günther, M., Boult, T.: Reducing network agnostophobia. Adv. Neural Inf. Process. Syst. 31, 9157–9168 (2018)
Fang, Z., Lu, J., Liu, A., Liu, F., Zhang, G.: Learning bounds for open-set learning. In: International Conference on Machine Learning, pp. 3122–3132. PMLR (2021)
Geng, C., Huang, S.J., Chen, S.: Recent advances in open set recognition: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 43(10), 3614–3631 (2020)
He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: surpassing human-level performance on imagenet classification. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1026–1034 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hendrycks, D., Gimpel, K.: A baseline for detecting misclassified and out-of-distribution examples in neural networks. In: International Conference on Learning Representations (2017)
Hendrycks, D., Mazeika, M., Dietterich, T.: Deep anomaly detection with outlier exposure. In: International Conference on Learning Representations (2019)
Izmailov, P., Kirichenko, P., Finzi, M., Wilson, A.G.: Semi-supervised learning with normalizing flows. In: International Conference on Machine Learning, pp. 4615–4630 (2020)
Jain, L.P., Scheirer, W.J., Boult, T.E.: Multi-class open set recognition using probability of inclusion. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8691, pp. 393–409. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10578-9_26
Júnior, P.R.M., Boult, T.E., Wainer, J., Rocha, A.: Specialized support vector machines for open-set recognition. arXiv preprint arXiv:1606.03802 (2016)
Krizhevsky, A.: Learning multiple layers of features from tiny images (2009)
Le, Y., Yang, X.: Tiny imagenet visual recognition challenge. CS 231N, 7(7), 3 (2015)
Lee, K., Lee, H., Lee, K., Shin, J.: Training confidence-calibrated classifiers for detecting out-of-distribution samples. In: International Conference on Learning Representations (2018)
Lee, K., Lee, K., Lee, H., Shin, J.: A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Adv. Neural Inf. Process. Syst. 31, 7167–7177 (2018)
Li, Y., Vasconcelos, N.: Background data resampling for outlier-aware classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13218–13227 (2020)
Liang, S., Li, Y., Srikant, R.: Enhancing the reliability of out-of-distribution image detection in neural networks. In: International Conference on Learning Representations (2018)
Liu, W., Wang, X., Owens, J., Li, Y.: Energy-based out-of-distribution detection. Adv. Neural Inf. Process. Syst. 33 (2020)
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983 (2016)
Mensink, T., Verbeek, J., Perronnin, F., Csurka, G.: Metric learning for large scale image classification: generalizing to new classes at near-zero cost. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7573, pp. 488–501. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33709-3_35
Murphy, K.P.: Machine Larning: a Probabilistic Perspective. MIT Press (2012)
Neal, L., Olson, M., Fern, X., Wong, W.K., Li, F.: Open set learning with counterfactual images. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 613–628 (2018)
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., Ng, A.Y.: Reading digits in natural images with unsupervised feature learning (2011)
Oza, P., Patel, V.M.: C2ae: Class conditioned auto-encoder for open-set recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2307–2316 (2019)
Paszke, A., et al.: Pytorch: An imperative style, high-performance deep learning library. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 32, pp. 8024–8035. Curran Associates, Inc. (2019)
Rudd, E.M., Jain, L.P., Scheirer, W.J., Boult, T.E.: The extreme value machine. IEEE Trans. Pattern Anal. Mach. Intell. 40(3), 762–768 (2018)
Ruff, L., Vandermeulen, R.A., Franks, B.J., Müller, K.R., Kloft, M.: Rethinking assumptions in deep anomaly detection. arXiv preprint arXiv:2006.00339 (2020)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. (IJCV) 115(3), 211–252 (2015). https://doi.org/10.1007/s11263-015-0816-y
Scheirer, W.J.: Extreme value theory-based methods for visual recognition. Synth. Lect. Comput. Vis. 7(1), 1–131 (2017)
Scheirer, W.J., Jain, L.P., Boult, T.E.: Probability models for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 36(11), 2317–2324 (2014)
Scheirer, W.J., de Rezende Rocha, A., Sapkota, A., Boult, T.E.: Toward open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 35(7), 1757–1772 (2013)
Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815–823 (2015)
Snell, J., Swersky, K., Zemel, R.: Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 30, 4080–4090 (2017)
Sun, X., Yang, Z., Zhang, C., Ling, K.V., Peng, G.: Conditional gaussian distribution learning for open set recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13480–13489 (2020)
Wen, Y., Zhang, K., Li, Z., Qiao, Y.: A comprehensive study on center loss for deep face recognition. Int. J. Comput. Vis. 127(6), 668–683 (2019)
Xu, P., Ehinger, K.A., Zhang, Y., Finkelstein, A., Kulkarni, S.R., Xiao, J.: Turkergaze: crowdsourcing saliency with webcam based eye tracking. arXiv preprint arXiv:1504.06755 (2015)
Yang, H.M., Zhang, X.Y., Yin, F., Yang, Q., Liu, C.L.: Convolutional prototype network for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. (2020)
Yoshihashi, R., Shao, W., Kawakami, R., You, S., Iida, M., Naemura, T.: Classification-reconstruction learning for open-set recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4016–4025 (2019)
Yu, F., Seff, A., Zhang, Y., Song, S., Funkhouser, T., Xiao, J.: LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365 (2015)
Zagoruyko, S., Komodakis, N.: Wide residual networks. arXiv preprint arXiv:1605.07146 (2016)
Acknowledgements
This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No. 2019-0-00075, Artificial Intelligence Graduate School Program (KAIST)) and the National Research Foundation of Korea (NRF) grants funded by the Korea government (MSIT) (No. NRF-2018M3E3A1057305 and No. NRF-2022R1A2B5B02001913).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Cho, W., Choo, J. (2022). Towards Accurate Open-Set Recognition via Background-Class Regularization. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13685. Springer, Cham. https://doi.org/10.1007/978-3-031-19806-9_38
Download citation
DOI: https://doi.org/10.1007/978-3-031-19806-9_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19805-2
Online ISBN: 978-3-031-19806-9
eBook Packages: Computer ScienceComputer Science (R0)