
Abstract
Vision Transformers (ViTs) is emerging as an alternative to convolutional neural networks (CNNs) for visual recognition. They achieve competitive results with CNNs but the lack of the typical convolutional inductive bias makes them more data-hungry than common CNNs. They are often pretrained on JFT-300M or at least ImageNet and few works study training ViTs with limited data. In this paper, we investigate how to train ViTs with limited data (e.g., 2040 images). We give theoretical analyses that our method (based on parametric instance discrimination) is superior to other methods in that it can capture both feature alignment and instance similarities. We achieve state-of-the-art results when training from scratch on 7 small datasets under various ViT backbones. We also investigate the transferring ability of small datasets and find that representations learned from small datasets can even improve large-scale ImageNet training.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Transformers [32] have recently emerged as an alternative to convolutional neural networks (CNNs) for visual recognition [13, 31, 41]. The vision transformer (ViT) introduced by [13] is an architecture directly inherited from natural language processing [12], but applied to image classification with raw image patches as input. ViT and variants achieve competitive results with CNNs but require significantly more training data. For instance, ViT performs worse than ResNets [16] with similar capacity when trained on ImageNet [29] (1.28 million images). One possible reason may be that ViT lacks certain desirable properties inherently built into the CNN architecture that make CNNs uniquely suited to solve vision tasks, e.g., locality, translation invariance and hierarchical structure [38]. As a result, ViTs need a lot of data for training, usually more data-hungry than CNNs.
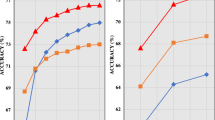
In order to alleviate this problem, a lot of works try to introduce convolutions to ViTs [22, 36, 38, 41]. These architectures enjoy the advantages of both paradigms, with attention layers modeling long-range dependencies while convolutions emphasizing the local properties of images. Empirical results show that these ViTs trained on ImageNet outperform ResNets of similar sizes. However, ImageNet is still a large-scale dataset and it is still not clear what is the behavior of these networks when trained on small datasets (e.g., 2040 images). As shown in Fig. 1, we cannot always rely on such large-scale datasets from the perspective of data, computing and flexibility, which will be further analyzed.

Comparison of transfer learning (left) and training from scratch (right).
In this paper, we investigate how to train ViTs from scratch with limited data. We first perform self-supervised pretraining and then supervised fine-tuning on the same target dataset, as done in [3]. We focus on the self-supervised pretraining stage and our method is based on parametric instance discrimination [14]. We theoretically analyze that parametric instance discrimination can not only capture feature alignment between positive pairs but also find potential similarities between instances thanks to the final learnable fully connected layer W. Experimental results further verify our analyses and our method achieves better performance than other non-parametric contrastive methods [7,8,9,10]. It is known that instance discrimination suffers from high GPU computation, high memory overload and slow convergence for high-dimensional W on large-scale datasets. Since in this paper we focus on small datasets, we do not need complicated strategies for large-scale datasets as in [2, 21]. Instead, we adopt small resolution [3], multi-crop [6] and CutMix [42] for the small data setup and we also analyze them from both the theoretical and empirical perspectives.
We call our method Instance Discrimination with Multi-crop and CutMix (IDMM) and achieve state-of-the-art results on 7 small datasets when training from scratch under various ViT backbones. For instance, we achieve 96.7% accuracy when training from scratch on flowers [25] (2040 images), which shows that training ViTs with small data is surprisingly viable. Moreover, we are the first to analyze the transferring ability of small datasets. We find that ViTs also have good transferring ability even when pretrained on small datasets and can even facilitate training on large-scale datasets, e.g., ImageNet. [20] also investigates training ViTs with small-size datasets but they focus on the fine-tuning stage while we focus on the pretraining stage. More importantly, we achieve much better results than [20], where the best reported accuracy on flowers was 56.3%.
In summary, our contributions are:
-
We propose IDMM for self-supervised ViT training and achieve state-of-the-art results when training from scratch for various ViTs on 7 small datasets.
-
We give theoretical analyses on why we should prefer parametric instance discrimination when dealing with small data from the loss perspective. Moreover, we show how strategies like CutMix alleviate the infrequent updating problem from the gradient perspective.
-
We empirically show the projection MLP head is essential for non-parametric contrastive methods (e.g., SimCLR [8]) but not for parametric instance discrimination, thanks to the final learnable W in instance discrimination.
-
We analyze the transferring ability of small datasets and find that ViTs also have good transferring ability even when pretrained on small datasets.
2 Related Works
Self-supervised Learning. Self-supervised learning (SSL) has emerged as a powerful method to learn visual representations without labels. Many recent works follow the contrastive learning paradigm [26], which is also known as non-parametric instance discrimination [39]. For instance, SimCLR [8] and MoCo [15] trained networks to identify a pair of views originating from the same image when contrasted with many views from other images. Unlike the two-branch structure in contrastive methods, some approaches [2, 14, 21] employed a parametric, one-branch structure for instance discrimination. Exemplar-CNN [14] learned to discriminate between a set of surrogate classes, where each class represents different transformed patches of a single image. [2] and [21] proposed different methods to alleviate the infrequent instance visiting problem or reduce the GPU memory consumption for large-scale datasets, but rely on complicated engineering techniques for CNNs and lack theoretical analyses. In this paper, we not only apply parametric instance discrimination to ViTs, but also focus on small datasets. In addition, we give theoretical analyses of why we should prefer parametric method, at least for small datasets.
Recently, there have also been self-supervised methods designed for ViTs. [10] found that instability is a major issue that impacts self-supervised ViT training and proposed a simple contrastive baseline MoCov3. DINO [7] designed a simple self-supervised approach that can be interpreted as a form of knowledge distillation with no labels. However, they focused on large-scale datasets while we focus on small data. Our method is more stable for various networks and more effective for small data.
Vision Transformers. The Vision Transformer (ViT) [13] treated an image as patches/tokens and employed a pure transformer structure. With sufficient training data, ViT outperforms CNNs on various image classification benchmarks, and many ViT variants have been proposed since then. [31] introduced a teacher-student distillation token strategy into ViT, namely DeiT. Beyond classification, Transformer has been adopted in diverse vision tasks, including detection [4], segmentation [37], etc. Many ViT variants were proposed in recent months. Swin Transformer [22] applied the shifted window approach to compute self-attention matrix. Wang et al. proposed PVT-based model [35, 36], which built a progressive shrinking pyramid and a spatial-reduction attention layer to generate multi-resolution feature maps. T2T-ViT [41] introduced a tokens-to-token (T2T) module to aggregate neighboring tokens into one recursively. However, ViTs are known to be data-hungry [20] and how to train ViTs with limited data is an important but not fully investigated question. [20] proposed a self-supervised task for ViTs, which can extract additional information from images and make training much more robust when training data are scarce. In contrast, we focus on the self-supervised pretraining stage while [20] focuses on the supervised fine-tuning stage. Moreover, we achieve much higher accuracy when training from scratch and we investigate the transferring ability when training on small datasets.
3 Method
We first explain why we use parametric instance discrimination (Sect. 3.1), then analyze how our strategies help weight updating (Sect. 3.2), and describe the complete method.
3.1 Analyses on Instance Discrimination

Illustration of parametric instance discrimination on a dataset containing N images.

Pipeline of our methods when training from scratch on a dataset containing N images from C classes
As shown in Fig. 2, an input image \(\boldsymbol{x}_i\) (\(i=1,\cdots ,N\)) is sent to a network \(f(\cdot )\) and get output representation \(\textbf{z}_i=f(\boldsymbol{x}_i)\in {\mathbb {R}^d}\), where N denotes the total number of instances. Then, a fully connected (fc) layer W is used for classification and the number of classes equals the total number of training images N for parametric instance discrimination. We denote \(\textbf{w}_j\in {\mathbb {R}^{d}}\) as the weights for the j-th class and \(W=[\textbf{w}_1 | \dots | \textbf{w}_N]\in {\mathbb {R}^{d\times {N}}}\) contains the weights for all N classes. Hence we have \(O^{(i)}=W^T\textbf{z}_i\), where the output for the j-th class \(O^{(i)}_j=\textbf{w}^T_j{\textbf{z}_i}\). Finally, \(O^{(i)}\) is sent to a softmax layer to get a valid probability distribution \(P^{(i)}\).
For instance discrimination, the loss function is:
where the superscript i sums over instances while the subscript c sums over classes. For instance discrimination, the class label corresponds to the instance ID: \(y_c^{(i)}=1 \text { iff } c=i\).
Now we move on to the contrastive learning (CL) loss. There are typically 2 views (i.e., positive pairs) for each input \(\boldsymbol{x}_i\) and we call them \(\boldsymbol{x}_{iA}\), \(\boldsymbol{x}_{iB}\) (corresponding representations are \(\textbf{z}_{iA}\), \(\textbf{z}_{iB}\)). The contrastive loss can be represented as follows (we omit hyper-parameter \(\tau \) for simplicity):
where \(\textbf{z}_i^-\) enumerates all negative pairs for \(\textbf{z}_i\), i.e., \(\textbf{z}_{jA}\) and \(\textbf{z}_{jB}\) for all \(j\ne {i}\). Consider the loss term for the i-th instance:
If we set \(\textbf{w}_i=\textbf{z}_i\) in instance discrimination, then from Eq. (2) we have (also consider the i-th term):
Now it is clear that (5) and (4) are almost identical, except that there are two views in Eq. (4) (\(\textbf{z}_{iA}\) and \(\textbf{z}_{iB}\) vs. \(\textbf{z}_i\)). Both have two terms: the alignment term encouraging more aligned positive features and the uniformity term encouraging the features to be roughly uniformly distributed on the unit hypersphere, as noted in [34]. Hence, we conclude that instance discrimination is approximately equivalent to the contrastive loss when we set \(\textbf{w}_j=\textbf{z}_{j}, \forall \,{j}\). Our analyses also give a theoretical interpretation of the contrastive prior used in [21], which initializes W in a contrastive way to accelerate convergence for high-dimensional W.
In other words, the contrastive loss is a special case of instance discrimination, with each \(\textbf{w}_i\) set to the representation of \(\textbf{x}_i\) in the current batch (i.e., non-parametric instance discrimination). In contrast, the learnable fc W in instance discrimination has at least two advantages:
(i) Separate representation learning from learning specific properties of the loss. As known in many contrastive learning methods (e.g., SimCLR [8]), using an extra projection head (MLPs) after representation is essential to learn good representations. However, we find that this projection head is not necessary for instance discrimination, thanks to the learnable weights W of this fc, as will be shown in Sect. 4.4.
(ii) Find potential similarities between instances (classes). Now we consider DeepClustering [5], whose clustering loss can be reformulated as follows using our notation:
where K denotes the number of clusters, \(y^{(i)}_k\) indicates whether the i-th instance belongs to the k-th cluster, and \(P^{(i)}_k\) denotes the probability that the i-th instance belongs to the k-th cluster. Let \(C_k\) denotes the index of instances in cluster k, then if we set all \(\{\textbf{w}_j|j\in {C_k}\}\) to the same, i.e., \(\textbf{w}_j=\tilde{\textbf{w}}_k\) for all \(j\in C_k\), we have:
where \(\sigma (\cdot )\) is the softmax function. Similarly, Eq. (6) becomes
Hence, when the weights W are appropriately set, instance discrimination is equivalent to the deep clustering loss, which can observe potential instance similarities. As can be seen from Fig. 4, instance discrimination learns more distributed representations and captures better intra-class similarities.
Since in this paper we focus on ViTs, there is another important reason why we choose parametric instance discrimination: the simplicity and stability. As noted in [10], instability is a major issue that impacts self-supervised ViT training. Hence, the form of instance discrimination (cross entropy) is more stable and easier to optimize. It will be further demonstrated in Sect. 4.3 and Sect. 4.4 that our method can better adapt to various emerging ViT networks and does not rely on specific designs (e.g., projection MLP head).

t-SNE [23] visualization of 10 classes selected from flowers using DeiT-Tiny. The first row shows the results before fine-tuning (i.e., without using any class labels) and the second row shows the results after fine-tuning (‘FT’). This figure is best viewed in color. (Color figure online)
3.2 Gradient Analysis
Consider the loss term for the i-th instance in Eq. (2):
Then, the gradient w.r.t. \(\textbf{w}_k\) can be calculated as follows:
where \(\delta \) is an indicator function, equals 1 iff \(k=i\).
Notice that for instance discrimination the number of classes N can easily go very large and there exists extremely infrequent visiting of instance samples [2, 21]. Hence for infrequent instances \(k\ne {i}\), we can expect \(P^{(i)}_k\approx 0\) and hence \(\frac{\partial {L}}{\partial {\textbf{w}_k}} \approx \textbf{0}\), which means extremely infrequent update of \(\textbf{w}_k\). [2] and [21] introduced different strategies to alleviate the problems for large datasets, such as the high GPU computation and memory overhead. Since in this paper we focus on small datasets, such strategies are not necessary. Instead, we use CutMix [42] and label smoothing [30] to update the weight matrix more frequently by directly modifying the one-hot label, which are also commonly used in supervised training of ViTs. If we use label smoothing, then
where \(\epsilon \) is the smoothing factor and we set it to 0.1 throughout this paper. Then the loss becomes:
If we continue to use CutMix, Eq. (13) becomes:
where \(\lambda \) is the mixed coefficient, \(i'\) is the index of the other instance in CutMix, \(\tilde{\textbf{z}}_{ii'}\) is the output of the mixed input and
And the gradient w.r.t. \(\textbf{w}_k\) becomes:
If we set \(\lambda =0.5\) and \(N=2040\), then \(C_i=C_{i'}\approx 0.45\) and \(C\approx 2.5e-5\). Hence, we are able to update \(\textbf{w}_k\) even for instances \(k\ne {i}\) (with relative large gradients for \(\textbf{w}_i\) and \(\textbf{w}_{i'}\) and small gradients for others), which alleviates the infrequent updating problem. Moreover, we can alleviate the overfitting problem by using CutMix as our regularization with limited data, as revealed in [42, 43].
In conclusion, we use the following strategies to enhance instance discrimination (InsDis) on small datasets:
-
(1)
Small resolution. It has been shown in [3] that small resolution during pretraining is useful for small datasets.
-
(2)
Multi-crop. As analyzed before, InsDis generalizes the contrastive loss to capture both feature alignment and uniformity when using multiple crops.
-
(3)
CutMix and label smoothing. As analyzed above, it helps us alleviate the overfitting and infrequent accessing problem when applying InsDis.
We call our method instance discrimination with multi-crop and CutMix (IDMM) and we conduct ablation studies on these strategies in Sect. 4.4.
4 Experiments
We used 7 small datasets for our experiments, as shown in Table 1. First, we explain the reasons why we need training from scratch in Sect. 4.1 and training from scratch results in Sect. 4.2. Then, we study the transferring ability of ViTs pretrained on small datasets (even facilitate large-scale datasets training) in Sect. 4.3. Finally, we conduct ablation studies on different components in Sect. 4.4. All our experiments were conducted using PyTorch and Titan Xp GPUs.
4.1 Why Training from Scratch?
We explain the reasons why do we need training from scratch directly on target datasets from 3 aspects:
-
Data. Current ViT models are often pretrained on a large-scale dataset (such as ImageNet or even larger ones), and then fine-tuned in various downstream tasks. Moreover, the lack of the typical convolutional inductive bias makes these models more data-hungry than common CNNs. Hence, it is critical to investigate whether we can train ViTs from scratch for a task where the total amount of available images is limited (e.g., 100 categories with roughly 20 images per category).
-
Computing. The combination of a large-scale dataset, a large number of epochs and a complex backbone network means that ViT training is extremely computationally expensive. This phenomenon makes ViT a privilege for researchers at few institutions.
-
Flexibility. The pretraining followed by downstream fine-tuning paradigm will sometimes become cumbersome. For instance, we may need to train 10 different models for the same task, and deploy them to different hardware platforms [1], but it is impractical to pretrain 10 models on a large-scale dataset.

Parameter-Accuracy tradeoff on flowers. The blue circles represent IN pretrained models while the red stars represent models of different sizes training from scratch using our method.

Comparison of different SSL methods on flowers dataset. All pretrained for 800 epochs and then fine-tuned for 200 epochs on flowers.
As shown in Fig. 5, it is obvious that ImageNet pretrained models need much more data and computational cost when compared to training from scratch. Moreover, when we need to deploy models of different sizes on terminal devices, training from scratch provides better parameter-accuracy tradeoffs. For instance, the smallest ImageNet pretrained model of PVTv2 (i.e., B0) has 3.4M parameters, which may still be too big for some devices. In contrast, we can train a much smaller model (0.8M) from scratch to adapt to the devices, which reaches 93.8% accuracy using our IDMM.
4.2 Training from Scratch Results
In this section, we investigate training ViTs from scratch. Following [3], the full learning process contains two stages: pretraining and fine-tuning. We use the pretrained weights obtained by SSL for initialization and then fine-tune networks for classification using the cross entropy loss. As shown in Fig. 3, SSL pretraining and fine-tuning are both performed only on the target dataset. We focus on the first stage and the fine-tuning stage follows common practices.
For the fine-tuning stage, we follow the setup in DeiT [31] and fine-tune all methods for 200 epochs (except for Table 3). Specifically, we use AdamW with a batch size of 256 and a weight decay of 1e–3. The learning rate (lr) is initialized to 5e–4 and follows the cosine learning rate decay. For the SSL pretraining stage, all methods are pretrained for 800 epochs and our IDMM follows the same training settings as in the fine-tuning stage. We set \(\alpha =0.5\) for CutMix in our IDMM. We follow the settings in the original papers for other methods and more details are included in the appendix. We use 112\(\,\times \,\)112 resolution during pretraining and 224\(\,\times \,\)224 during fine-tuning for all methods, as suggested in [3].
First, we compare our method with popular SSL methods for both CNNs and ViTs in Table 2. For fair comparisons, all methods are pretrained for 800 epochs and then fine-tuned for 200 epochs. As can be seen in Table 2 and Fig. 6, SSL pretraining is useful even when training from scratch and all SSL methods perform better than random initialization. Our method achieves the highest accuracy on all these datasets, except for aircraft. When the number of images is small (e.g., flowers and pets), the advantage of our method is more obvious, which is consistent with our analyses before.
Then, following [3], we fine-tune the models for longer epochs to get better results. Specifically, with the IDMM initialized weights, we first fine-tune for 800 epochs under 224\(\,\times \,\)224 resolution and then continue fine-tuning for 100 epochs under 448\(\,\times \,\)448 resolution. As shown in Table 3, we achieve the state-of-the-art results when training from scratch on these 7 datasets for all these ViT models, to the best of our knowledge. Moreover, the gap between training from scratch and using ImageNet pretrained models (colored in gray) has been greatly reduced using our method, which indicates that training from scratch is promising even for ViT models. Notice that PVTv2 models achieve better performance than DeiT and T2T by introducing convolutions to ViTs. The introduction of the typical convolutional inductive bias makes it less data-hungry than common ViTs and hence achieving better performance on these small datasets. We also experimented on the popular CIFAR-10 and CIFAR-100 [19] in Table 4 and the results still demonstrate the effectiveness of our method.
Further, we also study the randomness during both the pretraining and fine-tuning stage because the number of training images is small. For the pretraining stage, we pretrain 3 different models (using our method) and fine-tune them separately. For the fine-tuning stage, we run 3 times with one pre-trained model. As shown in Table 5, the standard deviation is small in both stages on the two smallest datasets and hence we only report single run results in Tables 2, 3 and 4.
4.3 Transfer Ability of Small Datasets
Having investigated training from scratch on small datasets for various ViT models, we now study the transfer ability of the representations learned on these small datasets. The transfer ability of representations pretrained on large-scale datasets has been well studied, but few works studied the transfer ability of small datasets.
In Table 6 we evaluate the transferring accuracy of models pretrained on different datasets. As in Sect. 4.2, we train 800 epochs for pretraining and fine-tuning 200 epochs. The on-diagonal cells perform pretraining and fine-tuning on the same dataset. The off-diagonal cells evaluate transfer performance across these small datasets. From Table 6 we can conclude:
-
ViTs have good transferring ability even when pretrained on small datasets. This means that we can use pretrained models from small datasets to transfer to other datasets in different domains to improve performance.
-
Our method also has higher transferring accuracy on all these datasets when compared to SimCLR and SupCon. As analyzed before, we think that it is due to the learnable fully connected layer W, which can capture both feature alignment and instance similarity. Also, the learnable fc better protects features from learning specific properties of the loss, as will be shown in Sect. 4.4.
-
We can obtain surprisingly good results even if the pretrained dataset and the target dataset are not in the same domain. For instance, models pretrained on Indoor67 achieve the highest accuracy when transfer to Aircraft. It is obvious that the number of images in the pretrained dataset matters, because Cars performs best in all. However, we want to argue that it is not the only reason because we can see that Indoor67 and CUB perform better than Cars in some cases despite having fewer training images. We leave it to future work to study what properties matter for pretraining datasets when transferring.
After observing that models pretrained on small datasets have surprisingly good transferring ability, we can further explore the potential of small datasets. We sample the original ImageNet to smaller subsets with 10,000 images (SIN-10k), motivated by [3]. By pretraining models on SIN-10k, we evaluate the performance when transferring to small datasets in Table 7 as well as the large-scale dataset ImageNet in Table 8. In Table 7 we compare our method with various SSL methods as well as the supervised baseline under different backbones. It can be seen that our method has a large edge over these comparison methods and representations learned on SIN-10k can serve as a good initialization when transferring to other datasets. It is worth noting that MoCov3 and DINO fail to converge under T2T-ViT-7 after trying various hyper-parameters so we don’t report the results for them in Table 7. It indicates our method can be easily applied to emerging ViTs without the need of special design or tuning.
Furthermore, we investigate whether we can benefit from pretraining on 10,000 images when training on ImageNet. As seen in Table 8, using the representation learned from 10,000 images as initialization can greatly accelerate the training process and finally achieve higher accuracy (about 1 point) on ImageNet. Notice that we sampled a balanced subset before (10 images per class) and we also compare with the setting where we randomly sample 10,000 images without using label information (SIN-total 10k). As seen, whether to use labels when sampling (balanced or not) has no effect on the result, as noted in [40].
4.4 Ablation Studies
In this section, we first investigate the effect of different components in our method in Table 9. ‘LS’, ‘SR’, ‘MC’, and ‘CM’ denote label smoothing, small resolution, multi-crop and CutMix, respectively. Then, we investigate the effect of the projection MLP head in Table 10.
As can be seen in Table 9, all the 4 strategies are useful and combining all these strategies achieves the best results. The experimental results further confirm the analyses in Sect. 3.1 that using multiple views and CutMix is helpful.
In Table 10, all methods are pretrained for 800 epochs on SIN-10k and then fine-tuned for 200 epochs when transferring to target datasets. The projection MLP head is essential for contrastive methods like SimCLR while it is not the case for instance discrimination. It further confirms the analyses in Sect. 3.1 that the learnable fc W protects features from learning specific properties of the loss and hence achieving better transferring ability. In contrast, the W in contrastive loss is not learnable and they need extra projection head.
5 Conclusions
In this paper, we proposed a method called IDMM for (pre)training ViTs with small data and the effectiveness of the proposed approach is well validated by both theoretical analyses and experimental studies. We achieved state-of-the-art results on 7 small datasets under various ViT backbones when training from scratch. Moreover, we studied the transferring ability of small datasets and found that ViTs also have good transferring ability even when pre-trained on small datasets. However, there is still room for improvement when training from scratch on these small datasets for architectures like DeiT. Furthermore, it is still unknown what properties matter for pretraining on small datasets when transferring and we leave them to future work.
References
Cai, H., Gan, C., Wang, T., Zhang, Z., Han, S.: Once-for-all: train one network and specialize it for efficient deployment. In: The International Conference on Learning Representations, pp. 1–14 (2020)
Cao, Y., Xie, Z., Liu, B., Lin, Y., Zhang, Z., Hu, H.: Parametric instance classification for unsupervised visual feature learning. arXiv preprint arXiv:2006.14618 (2020)
Cao, Y.H., Wu, J.: Rethinking self-supervised learning: Small is beautiful. arXiv preprint arXiv:2103.13559 (2021)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12346, pp. 213–229. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58452-8_13
Caron, M., Bojanowski, P., Joulin, A., Douze, M.: Deep Clustering for unsupervised learning of visual features. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision – ECCV 2018. LNCS, vol. 11218, pp. 139–156. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01264-9_9
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., Joulin, A.: Unsupervised learning of visual features by contrasting cluster assignments. In: Advances in Neural Information Processing Systems, pp. 9912–9924 (2020)
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: The IEEE International Conference on Computer Vision, pp. 9650–9660 (2021)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: The International Conference on Machine Learning, pp. 1597–1607 (2020)
Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297 (2020)
Chen, X., Xie, S., He, K.: An empirical study of training self-supervised vision transformers. In: The IEEE International Conference on Computer Vision, pp. 9640–9649 (2021)
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 3606–3613 (2014)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics, pp. 4171–4186 (2019)
Dosovitskiy, A., et al.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In: International Conference on Learning Representations, pp. 1–12 (2021)
Dosovitskiy, A., Springenberg, J.T., Riedmiller, M., Brox, T.: Discriminative unsupervised feature learning with convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 766–774 (2014)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 9729–9738 (2020)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Khosla, P., et al.: Supervised contrastive learning. In: Advances in Neural Information Processing Systems, pp. 18661–18673 (2020)
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3D object representations for fine-grained categorization, In: ICCV Workshop on 3D Representation and Recognition (2013)
Krizhevsky, A., Hinton, G.E.: Learning multiple layers of features from tiny images. University of Toronto, Tech. rep. (2009)
Liu, Y., Sangineto, E., Bi, W., Sebe, N., Lepri, B., Nadai, M.D.: Efficient training of visual transformers with small-size datasets. In: Advances in Neural Information Processing Systems, pp. 23818–23830 (2021)
Liu, Y., Huang, L., Pan, P., Wang, B., Xu, Y., Jin, R.: Train a one-million-way instance classifier for unsupervised visual representation learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35,pp. 8706–8714 (2021)
Liu, Z., et al.: Swin transformer: hierarchical vision transformer using shifted windows. In: The IEEE International Conference on Computer Vision, pp. 10012–10022 (2021)
van der Maaten, L., Hinton, G.: Visualizing data using t-SNE. J. Mach. Learn. Res. 9(86), 2579–2605 (2008)
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013)
Nilsback, M.E., Zisserman, A.: A visual vocabulary for flower classification. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 1447–1454 (2006)
van den Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
Parkhi, O.M., Vedaldi, A., Zisserman, A., Jawahar, C.V.: Cats and dogs. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 3498–3505 (2012)
Quattoni, A., Torralba, A.: Recognizing indoor scenes. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 413–420 (2009)
Russakovsky, Q., et al.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vision 115(3), 211–252 (2015)
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818–2826 (2016)
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: The International Conference on Machine Learning, pp. 10347–10357 (2021)
Vaswani, A., et al.: Attention is All you Need. In: Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The Caltech-UCSD Birds-200-2011 Dataset. Tech. Rep. CNS-TR-2011-001, California Institute of Technology (2011)
Wang, T., Isola, P.: Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In: The International Conference on Machine Learning, pp. 9929–9939 (2020)
Wang, W., et al.: PVTv 2: improved baselines with pyramid vision transformer. arXiv preprint arXiv:2106.13797 (2021)
Wang, W., et al.: Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. In: The IEEE International Conference on Computer Vision, pp. 568–578 (2021)
Wang, Y., et al.: End-to-end video instance segmentation with transformers. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 8741–8750 (2021)
Wu, H., et al.: CvT: introducing convolutions to vision transformers. In: The IEEE International Conference on Computer Vision, pp. 22–31 (2021)
Wu, Z., Xiong, Y., Yu, S.X., Lin, D.: Unsupervised feature learning via non-parametric instance discrimination. In: The IEEE Conference on Computer Vision and Pattern Recognition, pp. 3733–3742 (2018)
Yang, Y., Xu, Z.: Rethinking the value of labels for improving class-imbalanced learning. In: Advances in Neural Information Processing Systems, pp. 19290–19301 (2020)
Yuan, L., et al.: Tokens-to-token ViT: training vision transformers from scratch on imagenet. arXiv preprint arXiv:2101.11986 (2021)
Yun, S., Han, D., Oh, S.J., Chun, S., Choe, J., Yoo, Y.: CutMix: regularization strategy to train strong classifiers with localizable features. In: The IEEE International Conference on Computer Vision, pp. 6023–6032 (2019)
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: Mixup: beyond empirical risk minimization. In: The International Conference on Learning Representations, pp. 1–13 (2018)
Acknowledgments
This research was partly supported by the National Natural Science Foundation of China under Grant 61921006 and Grant 61772256.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Cao, YH., Yu, H., Wu, J. (2022). Training Vision Transformers with only 2040 Images. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13685. Springer, Cham. https://doi.org/10.1007/978-3-031-19806-9_13
Download citation
DOI: https://doi.org/10.1007/978-3-031-19806-9_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19805-2
Online ISBN: 978-3-031-19806-9
eBook Packages: Computer ScienceComputer Science (R0)