
Abstract
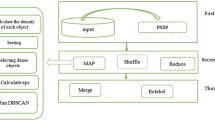
The volume of data generated, processed, and consumed in the digital world is exponentially increasing. The clustering of such a huge volume of data, known as big data, necessitates the development of highly scalable clustering methods. Density-based algorithms have attracted researchers’ interest because they help to better understand complex patterns in spatial datasets. As a result, they are capable of discovering clusters with varying shapes. However, most of the density-based algorithms are challenged by the discovery of clusters with varying density and the ability to cluster big datasets. The VDENCLUE algorithm was proposed to discover clusters with varying densities. However, VDENCLUE incurs high computation overhead, which is impractical for large datasets. In this paper, a parallel approximated variant of VDENCLUE is proposed, called MR-VDENCLUE. Besides discovering clusters with arbitrary shapes, MR-VDENCLUE can discover clusters with varying densities and scale up to handle big datasets.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
Log scale is used for the number of influence calculations.
References
Alkurdi, M.Z.; Malware detection for android applications using simhash algorithm. malware detection for android applications using simhash algorithm (2014)
Jon Louis Bentley: Multidimensional binary search trees used for associative searching. Commun. ACM 18(9), 509–517 (1975)
Chang, H., Yeung, D.-Y.: Robust path-based spectral clustering. Pattern Recogn. 41(1), 191–203 (2008)
Charikar, M.S.: Similarity estimation techniques from rounding algorithms. In Proceedings of the Thiry-Fourth Annual ACM Symposium on Theory of Computing, STOC 2002, pp. 380–388. Association for Computing Machinery, New York (2002)
Charikar, M.S.: Similarity estimation techniques from rounding algorithms. In: Proceedings of the Thiry-Fourth Annual ACM Symposium on Theory of Computing, pp. 380–388 (2002)
Dash, M., Ng, W.: Efficient reservoir sampling for transactional data streams. In: Sixth IEEE International Conference on Data Mining-Workshops (ICDMW 2006), pp. 662–666. IEEE (2006)
Gong, C., Huang, Y., Cheng, X., Bai, S.: Detecting near-duplicates in large-scale short text databases. In: Washio, T., Suzuki, E., Ting, K.M., Inokuchi, A. (eds.) PAKDD 2008. LNCS (LNAI), vol. 5012, pp. 877–883. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-68125-0_87
Henzinger, M.: Finding near-duplicate web pages: a large-scale evaluation of algorithms. In: Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 284–291 (2006)
Hinneburg, A., Keim, D.A.: An efficient approach to clustering in large multimedia databases with noise. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, KDD’98, pp. 58–65. AAAI Press (1998)
Ho, P.-T., Kim, H.-S., Kim, S.-R.: Application of sim-hash algorithm and big data analysis in spam email detection system. In: Proceedings of the 2014 Conference on Research in Adaptive and Convergent Systems, pp. 242–246 (2014)
joensuu (2019)
Khader, M., Al-Naymat, G.: Density-based algorithms for big data clustering using mapreduce framework: a comprehensive study. ACM Comput. Surv. 53(5), September 2020
Khader, M., Al-Naymat, Vdenclue, G.: An enhanced variant of denclue algorithm. In: Intelligent Systems and Applications, pp. 1–12. Springer Nature Switzerland AG (2021, 2020)
Manku, G.S., Jain, A., Das Sarma, A.: Detecting near-duplicates for web crawling. In: Proceedings of the 16th International Conference on World Wide Web, pp. 141–150 (2007)
Pi, B., Fu, S., Wang, W., Han, S.: Simhash-based effective and efficient detecting of near-duplicate short messages. In: Proceedings of the 2009 International Symposium on Computer Science and Computational Technology (ISCSCI 2009), p. 20. Citeseer (2009)
Uddin, S., Roy, C.K., Schneider, K.A., Hindle, A.: On the effectiveness of simhash for detecting near-miss clones in large scale software systems. In: 2011 18th Working Conference on Reverse Engineering, pp. 13–22. IEEE (2011)
Vitter, J.S.: Random sampling with a reservoir. ACM Trans. Math. Softw. (TOMS) 11(1), 37–57 (1985)
Zhang, Y., Chen, S., Yu, G.: Efficient distributed density peaks for clustering large data sets in mapreduce. IEEE Trans. Knowl. Data Eng. 28(12), 3218–3230 (2016)
Acknowledgment
This paper was supported by Ajman University Internal Research Grant No. 2021-IRG-ENIT-4. The research findings presented in this paper are solely the authors’ responsibility.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Al-Naymat, G., Khader, M., Al-Betar, M.A., Hriez, R., Hadi, A. (2023). MR-VDENCLUE: Varying Density Clustering Using MapReduce. In: Arai, K. (eds) Intelligent Systems and Applications. IntelliSys 2022. Lecture Notes in Networks and Systems, vol 542. Springer, Cham. https://doi.org/10.1007/978-3-031-16072-1_55
Download citation
DOI: https://doi.org/10.1007/978-3-031-16072-1_55
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-16071-4
Online ISBN: 978-3-031-16072-1
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)