
Abstract
Haze poses challenges in many vision-related applications. Thus, dehazing an image becomes popular among vision researchers. Available methods use various priors, deep learning models, or a combination of both to get plausible dehazing solutions. This paper reviews some recent advancements and their results on both homogeneous and non-homogeneous haze datasets. Intending to achieve haze removal for both types of haze, we propose a new architecture, developed on a convolutional neural network (CNN). The network is developed based on reformulating the atmospheric scattering phenomenon and estimating haze density to extract features for both types of haze. The haze-density estimation is supplemented by channel attention and pixel attention modules. The model is trained on perceptual loss. The quantitative and qualitative results demonstrate the efficacy of our approach on homogeneous as well as non-homogeneous haze as compared to the existing methods, developed for a particular type.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Haze is a natural phenomenon that occurs due to the atmospheric particles that cause scattering and deflection of light. These particles may consist of different molecules, aerosol, water droplet etc. [29]. Thus, when a scene is captured by a camera, a portion of the information gets lost due to the scattering and absorption of lights caused by the particles. Further, a portion of atmospheric light gets added in the capturing process due to the scattering effect [29]. As a result, captured image is obscured by haze effect, which becomes even more for long-range scenery. The contrast and the variance of the image get reduced and the colors of the scene contents also get dull. This results in a lack of visual vividness, appeal, and poor visibility of the objects along with a reduced range of effective surveillance. This degradation has proportionality with the depth of the object. As a result, haze appears to be denser at the farthest objects than the closer ones. This behavior makes the haze homogeneous in nature. This can be modelled mathematically using [24, 28, 29]
where C(x) is the clear scene without the haze involvement, H(x) is the degraded scene due to haze, \(\tau (x)\) is the medium transmission that contains information about depth at each pixel, \(\lambda \) is the global illumination or atmospheric light and x is the pixel location in the image. The transmission coefficient \(\tau (x)\) represents how much of the light reaches the camera without scattering. In term of depth, \(\tau (x)\) is defined as \(\tau (x)=e^{-\sigma \delta (x)}\). Here \(\delta (x)\) is the depth or distance of the object at that pixel from the camera, and \(\sigma \) is the scattering coefficient of the atmosphere. This suggests that when \(\delta (x)\) goes to infinity, \(\tau (x)\) approaches to zero. Hence, the captured image will be \(H(x) = \lambda \). This suggests that to reduce the haze effect, accurate estimation the medium transmission map is the key.
In some cases, the degradation phenomenon is not depth varying. For example, smog generally appears to be dense near factories. This kind of haze is non-homogeneous in nature. In this case, finding out haze density can play a significant role. Most of the existing works either deal with spatially varying homogeneous haze or address non-homogeneous haze. In this paper, we try to address both type of haze in a single framework based on convolutional neural network (CNN). Our proposed model try to estimate the significant parameters of both types of haze using atmospheric model and density map estimator, and combine them for dehazing any type of haze without any prior information. The channel attention and pixel attention modules in the haze density estimator improves the estimation accuracy as well as the results. Main contributions can be summarized as:
-
1.
We propose a deep learning based dehazing model that can work for homogeneous as well as non-homogeneous haze without any prior information.
-
2.
The combination of atmospheric model based parameter and haze density estimator plays the main role in our network.
-
3.
The model can produce competitive results on any type of haze with out re-training the model.

Haze Types: Homogeneous Haze (Left) & Non-Homogeneous Haze (Right)
2 Related Works
The word haze is generally used to denote visibility reducing aerosols. Depending on its characteristics, we can divide it into two types: Homogeneous and Non-Homogeneous haze (see Fig. 1). Homogeneous haze has a uniform density across the region. Mostly, hazes of natural origin are of this type. Long-range scenery photographs are highly affected by this type of haze. Non-Homogeneous Haze has non-uniform haze density across the region and generally they consist in a small area. Photography consisting of this type of haze contains patches with varying density. Existing methods can be divided into two types: i) Traditional and ii) Deep learning based techniques.
2.1 Traditional Techniques
Image Dehazing is an ill-posed problem. Methods proposed in early 20’s rely on multiple images or inputs from the user to remove haze. For example, a few works suggest polarization-based methods [26, 34, 35], where they use polarization property of the light to get the depth map information. This requires multiple images to be captured through a polarizer while changing its angles. A few other works [27, 28] require one or more restrictions to achieve dehazing. For example, reference constraints are required to capture several scene images under different weathers. Some methods [20] gets depth mapping from a user or a 3D model.
However, in practice, depth information is not easily available neither are multiple images or other constraints. These solutions have limitations in online dehazing applications. This motivates researchers to propose dehazing methods that use a single image. These methods heavily rely on traits of haze-free or hazy images. For example, Tan [38] has proposed a method that uses contrast characteristics of a haze-free image. Haze reduces contrast, so by directly maximizing the local contrast in a patch, one can enhance the visibility. However, this very basic approach introduces blocky artifacts around the regions where the depth varies sharply. Fattal [14] has proposed a solution that generates the transmission map using the reflectance of a surface. This solution assumes that the scene depth and the albedo are independent of each other at the local patch level. However, in the case of dense haze where a vast diffused solar reflection is present at the scene, this hypothesis does not hold. He et al. [17] proposed a new prior by observing the property of clear outdoor images. This prior is known as Dark Channel Prior or DCP. This uses the fact that one of the color channels of RGB in the outdoor image has considerably low intensity. DCP fails in the sky regions, where the intensity of pixels are close to that of atmospheric light. Recently, patch similarity has also been studied to estimate transmission map like parameter for dehazing of atmospheric and underwater images [23]. Apart from these, some haze relevant features like maximum contrast, hue disparity, color attenuation [39] have also been explored for dehazing.
2.2 Deep Learning Models
Following the recent advancements in deep learning and bio-inspired neural networks, and their success in other high-level computer vision tasks of image detection and segmentation, a few deep learning based methods are also proposed for low-level vision tasks such as image dehazing and reconstructions. Here we discuss a few closely related deep learning architectures.
Dehaze-Net. Cai et al. [8] have proposed Dehazenet that produces results with good performance indices compared to statistical approaches. DehazeNet learns the function to map hazy image to the transmission map in an end-to-end manner [8]. After estimating transmission map \(\tau (x)\), atmospheric light \(\lambda \) is estimated. Then, the haze-free image is achieved by
AOD-Net. Li et al. [21] have proposed AOD-Net that gives better results as compared to existing networks. Most of the existing works estimate \(\tau (x)\) and \(\lambda \) independently, which often amplifies the reconstruction error. AOD-Net estimates both key parameters together by combining them into one variable K
where K is
The combined estimation of these two parameters not only reduces reconstruction error but also mutually refines each other and creates more realistic lightning conditions and structural details as compared to overexposure caused in other models [7]. More deep learning based dehazing methods have been proposed, and can be found in the following references [11, 31].
Trident Dehazing Network. The atmospheric scattering model fails when haze is non-homogeneous. At NTIRE 2020 Non-Homogeneous Dehazing challenge [5], a novel Trident Dehazing Network (TDN) has been proposed to address this issue. TDN [22] learns the mapping function from a non-homogeneous hazy image to its haze-free counterpart. The architecture consists of three sub-networks: one reconstrcuts coarse-level features, another one adds up the details of haze-free image features and the third one generates the haze density of different regions of the hazy image. Finally the feature maps of these sub-nets are concatenated and fed to deformabale convolution block to produce the final result.
Apart from these methods, a few notable works are mentioned as follows. DenseNet based encoder and decoder have been used to jointly estimate transmission map and atmospheric light for dense haze scenario [16]. Haze color corrections and visibility improvement modules have been employed to address the issues of chromatic cast in bad weather condition [13]. A physical-model based disentanglement and reconstruction method has been introduced in dehazing an image with the help of multi-scale adversarial training [1]. Multi-scale features have also been utilized for image dehazing [10, 40]. GAN-based architecture using residual inception has been utilized in image dehazing [12]. To reduce haze effect for autonomous driving, a fast and resource constraint network has been proposed [25].
3 Proposed Model
Both models AOD-net and TDN give good performance on homogeneous and non-homogeneous haze, respectively. However, both models fail to perform better on other haze type. We propose a novel architecture that can handle both types of haze quite well.
3.1 Base Model
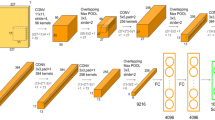
Transmission map of the atmospheric model plays an important role in homogeneous dehazing and haze denisty map is quite significant in non-homogeneous dehazing. Proposed model estimates these both parameters in two different subnets: K-estimation subnet and Density-estimation subnet. We learn transmission map \(\tau (x)\) and global atmospheric light \(\lambda \) jointly using K-estimation subnet. This targets homogeneous haze features of an image. The second subnet generates haze density map using an encoder-decoder architecture with skip connections, which is similar to U-Net [18] (see Fig. 2). We have six down-sampling and six up-sampling blocks with the connection between shallow and deeper layers. We also append an additional 3 \(\times \) 3 convolution layer for output refinement. The combined output of both the subnets is fed into a convolution block, batch normalization and relu activation in a sequence. This is the base architecture of our proposed model and an example result is shown in Fig. 3. The image is taken from O-Haze dataset [4]. The base model can reduce the haze effect from the image up to some extent. However, the results have some distortion. To achieve visual vividness and sharpness we carried out some novel modifications, as discussed next.

UNet architecture used in Haze Density Map generation subnet [22]
3.2 Adapting Base Model for Visual Enhancement
For improvement, we use channel attention and pixel attention blocks.

Base model output (Left-to-right): Hazy; Result of base model; Ground truth
Channel and Pixel Attention Blocks. To overcome loss in visual vividness, we use Channel Attention block from FFA-Net [30]. Our aim is to target color attenuation and hue disparity properties by exploiting the relationship of features between color channels and generating a channel attention map. Pixel Attention block [30] is known to generate sharper results [41]. We connect both attention blocks (Fig. 4) to the Haze density map generation subnet. Two channel attention blocks followed by a pixel attention block are added between the last two decoder layers of the density map generation subnet. One more pair of blocks is added after the final convolution layer of the density map generation subnet. These attention modules not only reduce the color loss but also help generate better density maps.

Channel attention & Pixel atttention block
Perceptual Loss. To further increase the sharpness, we use perceptual loss[19], which performs quite well in image restoration tasks [15, 32]. The output of both the subnet is concatenated and fed into a convolution block after batch normalization and activation layers. The output with 3 color channels is then fed into the loss model which is generated by selecting few bottom layers of pre-trained vgg16 [37]. Only selecting the output from VGG16 model does not do a good perceptual loss since the final output is made more of concepts than of features. We select the outputs from layers 1, 2, 9, 10, 17 and 18 as loss-model outputs. These layers’ weights are frozen during training. The aim is to sharpen the result by calculating the high-level difference. Lastly, we follow another \(3\times 3\) convolution layer which gives a clearer haze-free image. The layout of these final model architecture is shown in Fig. 5. The model is trained on a batch size of 8 for 20 epochs with a learning rate of \(1e-4\). The weight decay is \(1e-2\).

Proposed model
4 Experimental Results
4.1 Datasets and Model Details
A major issue in learning based image dehazing is the requirement of hazy and clear ground truth images under identical conditions such as weather, light, and wind. Hence, most of the available training datasets are augmentations on ground truth images such as NYU-2-Hazy [36]. Recently NTIRE challenge has employed new realistic image dehazing datasets: I-Haze [6], O-Haze [4], and Dense-Haze [2]. However, most of these augmented datasets assume that haze is homogeneously distributed over the scene, which may not be the case in many real scenes where haze may be non-homogeneous in nature. To this end, a new dataset NH-Haze [3] has been introduced by manually generating the haze in some areas of haze-free image. For training the model we use the mixture of synthetic NYU-Haze and Dense-Haze datasets and 10 out of 55 images from the NH-Haze dataset. The evaluation is done on three separate datasets. I-Haze is a synthetic haze dataset generated using depth information of indoor images. O-Haze is also a synthetic haze dataset but for outdoor images. NH-Haze consists of outdoor images with non-homogeneous haze. Images used in training from the NH-Haze dataset are excluded from the evaluation. Our model has 55M parameters and it requires 338 MB of disk space.
4.2 Quantitative Evaluation
We evaluate our results in terms of PSNR and SSIM values in Table 1. The results of our method are compared with NLD [7], MSC [33] TensorFlow implementation of TDN [22], AOD-Net [21] and GCA [9]. Comparison shows that the proposed model has better PSNR and SSIM values for I-Haze and O-Haze datasets. However, for NH-Haze, TDN method still performs better than ours. The reason being that the TDN method is specifically tailored to reduce the NH-Haze, but it fails to reduce homogeneous haze, effectively. On the other hand, our method can reduce both types of haze quite well without retraining the network. The results can be further improved by appropriate weighting the two sub-nets (K-estimation and haze density estimation) in our network.

Results on I-Haze dataset [6]

Results on O-Haze dataset [4]

Results on NH-Haze dataset [3]
4.3 Qualitative Results
Figures 6, 7 and 8 show final dehazed output images of Proposed Model and other state-of-the-art dehazing models for I-Haze, O-Haze, and NH-Haze datasets, respectively. From left to right are Hazy images, outputs of AOD-Net [21], outputs of TDN [22], outputs of Proposed Model, and Haze-free(ground truth) images. One can observe that the proposed model is able to produce better results as compared to the existing approaches for homogeneous hazy images from the I-Haze and O-Haze datasets. For non-homogeneous haze, the proposed model is slightly lagging behind the TDN, which is developed for non-homogeneous haze only. However, the proposed model is able to reduce the haze effect better than the methods, developed for homogeneous haze. This is due to the combination of blocks that are responsible for estimating homogeneous and non-homogeneous haze properties.
5 Conclusion
In this paper, we have addressed the ill-posed problem of image dehazing in the presence of homogeneous and/or non-homogeneous haze. For homogeneous case, estimating transmission map is the key, whereas density map plays an important role for non-homogeneous haze. Our deep architecture aims to estimate these key parameters in a single framework to deal with both types of haze. We have experimented with homogeneous as well as non-homogeneous hazy images to demonstrate the efficacy of our model. The produced results are superior than the existing methods for homogeneous haze. This suggests that the K-estimation module works as intended in generating features for homogeneous haze. For non-homogeneous haze, the proposed model has produced competitive results, which can be further improved by assigning appropriate weights between the K-estimation and density map estimation. Our model performs quite well when the haze type is unknown or both types of haze are present.
References
Towards perceptual image dehazing by physics-based disentanglement and adversarial training 32. https://ojs.aaai.org/index.php/AAAI/article/view/12317
Ancuti, C.O., Ancuti, C., Sbert, M., Timofte, R.: Dense-haze: a benchmark for image dehazing with dense-haze and haze-free images. In: 2019 IEEE International Conference on Image Processing (ICIP), pp. 1014–1018. IEEE (2019)
Ancuti, C.O., Ancuti, C., Timofte, R.: NH-HAZE: an image dehazing benchmark with non-homogeneous hazy and haze-free images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 444–445 (2020)
Ancuti, C.O., Ancuti, C., Timofte, R., De Vleeschouwer, C.: O-HAZE: a dehazing benchmark with real hazy and haze-free outdoor images. In: Proceedings of the IEEE Conference on computer Vision and Pattern Recognition Workshops, pp. 754–762 (2018)
Ancuti, C.O., Ancuti, C., Vasluianu, F.A., Timofte, R.: Ntire 2020 challenge on nonhomogeneous dehazing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 490–491 (2020)
Ancuti, C., Ancuti, C.O., Timofte, R., De Vleeschouwer, C.: I-HAZE: a dehazing benchmark with real hazy and haze-free indoor images. In: Blanc-Talon, J., Helbert, D., Philips, W., Popescu, D., Scheunders, P. (eds.) ACIVS 2018. LNCS, vol. 11182, pp. 620–631. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01449-0_52
Berman, D., Avidan, S., et al.: Non-local image dehazing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1674–1682 (2016)
Cai, B., Xu, X., Jia, K., Qing, C., Tao, D.: DehazeNet: an end-to-end system for single image haze removal. IEEE Trans. Image Process. 25(11), 5187–5198 (2016)
Chen, D., et al.: Gated context aggregation network for image dehazing and deraining. In: 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 1375–1383. IEEE (2019)
Chen, S., Chen, Y., Qu, Y., Huang, J., Hong, M.: Multi-scale adaptive dehazing network. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 2051–2059 (2019). https://doi.org/10.1109/CVPRW.2019.00257
Dong, H., et al.: Multi-scale boosted dehazing network with dense feature fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2157–2167 (2020)
Dudhane, A., Aulakh, H.S., Murala, S.: RI-GAN: an end-to-end network for single image haze removal. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 2014–2023 (2019). https://doi.org/10.1109/CVPRW.2019.00253
Dudhane, A., Biradar, K.M., Patil, P.W., Hambarde, P., Murala, S.: Varicolored image de-hazing. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4563–4572 (2020). https://doi.org/10.1109/CVPR42600.2020.00462
Fattal, R.: Single image dehazing. ACM Trans. Graph. (TOG) 27(3), 1–9 (2008)
Gholizadeh-Ansari, M., Alirezaie, J., Babyn, P.: Deep learning for low-dose CT denoising using perceptual loss and edge detection layer. J. Digit. Imaging 33(2), 504–515 (2020)
Guo, T., Li, X., Cherukuri, V., Monga, V.: Dense scene information estimation network for dehazing. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 2122–2130 (2019). https://doi.org/10.1109/CVPRW.2019.00265
He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 33(12), 2341–2353 (2010)
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1125–1134 (2017)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 694–711. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_43
Kopf, J., et al.: Deep photo: Model-based photograph enhancement and viewing. ACM Trans. Graph. (TOG) 27(5), 1–10 (2008)
Li, B., Peng, X., Wang, Z., Xu, J., Feng, D.: AOD-Net: all-in-one dehazing network. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4770–4778 (2017)
Liu, J., Wu, H., Xie, Y., Qu, Y., Ma, L.: Trident dehazing network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 430–431 (2020)
Mandal, S., Rajagopalan, A.: Local proximity for enhanced visibility in haze. IEEE Trans. Image Process. 29, 2478–2491 (2019)
McCartney, E.J.: Optics of the atmosphere: scattering by molecules and particles. New York (1976)
Mehra, A., Mandal, M., Narang, P., Chamola, V.: ReviewNet: a fast and resource optimized network for enabling safe autonomous driving in hazy weather conditions. IEEE Trans. Intell. Transp. Syst. 22(7), 4256–4266 (2021). https://doi.org/10.1109/TITS.2020.3013099
Namer, E., Schechner, Y.Y.: Advanced visibility improvement based on polarization filtered images. In: Polarization Science and Remote Sensing II, vol. 5888, p. 588805. International Society for Optics and Photonics (2005)
Narasimhan, S.G., Nayar, S.K.: Removing weather effects from monochrome images. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, vol. 2, p. II. IEEE (2001)
Narasimhan, S.G., Nayar, S.K.: Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 25(6), 713–724 (2003)
Nayar, S.K., Narasimhan, S.G.: Vision in bad weather. In: Proceedings of the Seventh IEEE International Conference on Computer Vision, vol. 2, pp. 820–827. IEEE (1999)
Qin, X., Wang, Z., Bai, Y., Xie, X., Jia, H.: FFA-Net: feature fusion attention network for single image dehazing. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 11908–11915 (2020)
Qu, Y., Chen, Y., Huang, J., Xie, Y.: Enhanced pix2pix dehazing network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8160–8168 (2019)
Rad, M.S., Bozorgtabar, B., Marti, U.V., Basler, M., Ekenel, H.K., Thiran, J.P.: Srobb: targeted perceptual loss for single image super-resolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2710–2719 (2019)
Ren, W., Liu, S., Zhang, H., Pan, J., Cao, X., Yang, M.-H.: Single image dehazing via multi-scale convolutional neural networks. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 154–169. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_10
Schechner, Y.Y., Narasimhan, S.G., Nayar, S.K.: Instant dehazing of images using polarization. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, vol. 1, p. I. IEEE (2001)
Schechner, Y.Y., Narasimhan, S.G., Nayar, S.K.: Polarization-based vision through haze. Appl. Opt. 42(3), 511–525 (2003)
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from RGBD images. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7576, pp. 746–760. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33715-4_54
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Tan, R.T.: Visibility in bad weather from a single image. In: 2008 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE (2008)
Tang, K., Yang, J., Wang, J.: Investigating haze-relevant features in a learning framework for image dehazing, pp. 2995–3002, June 2014. https://doi.org/10.1109/CVPR.2014.383
Zhang, J., Tao, D.: FAMED-Net: a fast and accurate multi-scale end-to-end dehazing network. IEEE Trans. Image Process. 29, 72–84 (2020). https://doi.org/10.1109/TIP.2019.2922837
Zhao, H., Kong, X., He, J., Qiao, Yu., Dong, C.: Efficient image super-resolution using pixel attention. In: Bartoli, A., Fusiello, A. (eds.) ECCV 2020. LNCS, vol. 12537, pp. 56–72. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-67070-2_3
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Gajjar, M., Mandal, S. (2022). Homogeneous and Non-homogeneous Image Dehazing Using Deep Neural Network. In: Raman, B., Murala, S., Chowdhury, A., Dhall, A., Goyal, P. (eds) Computer Vision and Image Processing. CVIP 2021. Communications in Computer and Information Science, vol 1567. Springer, Cham. https://doi.org/10.1007/978-3-031-11346-8_33
Download citation
DOI: https://doi.org/10.1007/978-3-031-11346-8_33
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-11345-1
Online ISBN: 978-3-031-11346-8
eBook Packages: Computer ScienceComputer Science (R0)