
Abstract
Answering questions, finding the most appropriate answer to the question given by the user as input are among the important tasks of natural language processing. Many studies have been done on question answering and datasets, methods have been published. The aim of this article is to reveal the studies done in question answering and to identify the missing research topics. In this literature review, it is tried to determine the datasets, methods and frameworks used for question answering between 2000 and 2022. From the articles published between these years, 91 papers are selected based on inclusion and exclusion criteria. This systematic literature review consists of research analyzes such as research questions, search strategy, inclusion and exclusion criteria, data extraction. We see that the selected final study focuses on four topics. These are Natural Language Processing, Information Retrieval, Knowledge Base, Hybrid Based.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Question answering
- Information retrieval
- Knowledge based question answering
- NLP based question answering
- Systematic literature review
1 Introduction
In the growing technology world, the importance of data is increasing. Question and answer systems have been developed for the growth of the data, the extraction of the desired information from the data and the processing of this information. Question answering (QA) is the system that takes a certain query input from the user and brings the closest answer to this query over the desired data.
QA consists of various systems such as search engine, chatbot. These systems vary according to needs. At first, search engines would only return documents containing information related to queries created by users in natural language, but over time, it is desired to return a direct answer to the user’s question along with the documents and the needs are increasing. Question answering systems consist of research areas such as Information Retrieval (IR), Answer Extraction (AE), and Natural Language Processing (NLP). Different studies, methods and datasets have been published in the field of QA. To this end, a comprehensive picture of the current state of QA is requested.
In this study, our purpose is to analyze the studies conducted between 2000 and 2022 in the field of QA. These analyzes are prepared on the methods used, the most used techniques, and datasets. The sections of this article are determined as follows. In Sect. 2, research methods are described. The criteria and results determined for the research questions are given in Sect. 3. In the last section, the summary of this study is given.
2 Methodology
2.1 Review Method
A systematic approach is chosen when conducting a literature search on question answering systems. Systematic literature reviews are well established method of review in question answering. In a systematic literature review, it can be defined as examining all the necessary research in a subject area and drawing conclusions [1]. This systematic literature review was prepared according to the criteria suggested by Kitchenham and Charters (2007). Some of the works and figures in this section have also been adapted by (Radjenović, Heričko, Torkar,Živkovič, 2013) [2], (Unterkalmsteiner et al. 2012) [3] and Wahono [4].

Systematic literature review steps
As shown in Fig. 1, Srl work consists of certain stages. These stages are planning, executing and reporting. In the planning stage, the needs are determined.
In the introduction part, realization targets are mentioned. Then, existing slr studies on question answering are collected and reviewed. The purpose of this review is designed to reduce researcher bias when conducting the slr study (Step 2). Research questions, search strategy, inclusion and exclusion criteria, study process, data extraction are described in Sects. 2.2, 2.3, 2.4 and 2.5.
2.2 Research Questions
The research questions studied in this review are indicated in Table 1.
The methods and datasets used in the question answering area shown in Table 1 from RQ1 to RQ7 were analyzed. Important methods, datasets are analyzed between RQ4 and RQ7. It gives a summary of the work done in the field of question answering from RQ1 to RQ3.
2.3 Search Strategy
The search process (Step 4) consists of several stages. Determination of digital libraries, determination of search keywords, development of search queries and final studies that match the search query from digital libraries are extracted. In order to select the most relevant articles, first of all, appropriate database sets are determined. The most popular literature database sets are researched and selected in order to keep our field of study wide. Digital databases used: ACM Digital Library, IEEE eXplore, ScienceDirect, Springer, Scopus
The search query is determined according to certain criteria. These criteria are;
-
1.
Search terms were determined from the research questions
-
2.
Searching the generated query in related titles, abstracts and keywords
-
3.
Identifying different spellings, synonyms and opposite meaning of query
-
4.
A comprehensive search string was created using the specified search terms
Boolean AND and OR. The generated search string is as follows.
(“question answering” AND “natural language processing”) AND (“information retrieval”) AND (“Document Retrieval” OR “Passage Retrieval” OR “Answer Extraction”)
Digital databases were scanned based on keywords, titles and abstracts. The search limited publications between 2000 and 2022. Within the scope of the research, only journal articles and conference papers published in English were included in the search.
2.4 Study Selection
Inclusion and exclusion criteria specified in Table 2 are shown in order to determine the final studies.
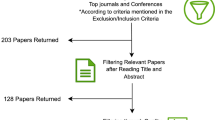
Figure 2 shows each step of the review process and the number determined. The study selection process was carried out in 2 steps. Title, abstract and full-text studies have been removed. Literature studies and studies that did not include experimental results were also excluded. Other studies were included according to the degree of similarity with question answering from the remaining studies.

Search and selection of final studies
In the first stage, the final list was selected. The final list includes 91 final studies. Considering the inclusion and exclusion criteria of 91 final studies, research questions and study similarities were examined.
2.5 Data Extraction
In the final study, our goal is to identify studies that contribute to the research questions. A data extraction form was created for each of the 91 final studies. This form was designed to collect information on studies and to answer research questions. In Table 3, five features were used to analyze the research questions.
2.6 Threats to Validity of Research
Some conference papers and journal articles were omitted because it is difficult to manually review all article titles during the literature review.
3 Analysis Results
3.1 Important Journal Publications
In this literature study, there are 91 final studies in the field of question answering. Depending on the final studies, we showed the numerical change of the studies in the field of question answering over the years. Our aim here is to see how the interest has changed over the years. Observation by years is shown in Fig. 3. It is observed that the interest in the field of question answering has increased more since 2005 and it shows that the studies carried out are more contemporary.

Distribution of selected studies over the years
The most important journals included in this literature study are shown in Fig. 4.

Journal publications
The Scimago Journal Rank (SJR) values of the most important journals with final studies are given in Table 4.

Influential researchers and number of studies
3.2 Most Active Researchers
The researchers who are most active in the field of question answering are shown in Fig. 5 according to the number of studies. Boris Katz, Yuan-ping Nie, Mourad Sarrouti, SaidOuatik El Alaoui, Prodromos Malakasiotis, Ion Androutsopoulos, Paolo Rosso, Stefanie Tellex, Aaron Fernandes, Gregory Marton, Dragomir Radev, Weiguo Fan, Davide Buscaldi, Emilio Sanchis, Dietrich Klakow, Matthew W. Bilottiare are the most active researchers.
3.3 Research Topics in the Question Answering Field
To answer this question, we considered Yao’s classification paper. When the final studies were examined, it was seen that the studies were carried out on four topics [5].
-
1.
Natural Language Processing based (NLP): Machine learning, NLP techniques are used to extract the answers.
-
2.
Information Retrieval based (IR): It deals with the retrieval or sorting of answers, documents and passages in search engine usage.
-
3.
Knowledge Base based (KB): Finding answers is done through structured data. Standard database queries are used in replacement of word-based searches [6].
-
4.
Hybrid Based: A hybrid approach is the combination of IR, NLP and KB.
Figure 6 shows the total distribution of research topics on question answering from 2000 until 2022. From the 91 studies, 6.72% of the papers implemented a knowledge base, 31.94% implemented a natural language processing, 59.24% implemented an information retrieval and 2.1% implemented a Hybrid. When the final studies are examined, it is seen that there are more studies in the field of NLP. As the reasons why researchers focus on this issue, studies on obtaining information through the search engine are increasing. A lot of text nlp and machine learning techniques have been tried to be applied in order to extract the most correct answer from the unstructured data.

Ratio of subjects
3.4 Datasets Used for Question Answering
Dataset is a data collection on which machine learning is applied [6]. The training set is the data on which the model is trained by giving it to the learning system. The test set or evaluation set is a dataset used to evaluate the model developed on a training set.
The distribution of datasets by years is presented. 35.95% of the studies are private datasets. Since these datasets are not public, the results of the studies cannot be compared with the results of the proposed models. The distribution of final studies by years is shown in Fig. 7. Looking at the distribution, there is an increasing awareness of the use of public data.

Number of datasets
3.5 Methods Used in Question Answering
As can be seen in Fig. 8, fourteen methods used and recommended in the field of question answering since 2000 have been determined. These determined methods are shown in Fig. 8.

Methods used in question answering
3.6 Best Method Used for Question Answering
Many studies have been carried out in the field of question answering. When the literature is examined, there is a pipeline process consisting of Natural Language Processing (NLP), Information Retrieval (IR), and Answer Extraction (IE). A question given in natural language first goes through the analysis phase. In other words, search queries are created to facilitate document retrieval, which is the next step. When the literature is examined, it is seen that the first studies used mostly classical methods such as tf-idf, bm25 [8,9,10] in the retrieval phase. Here, retrieval is provided by searching for words similar to the query received by the user as input.
When we look at other studies, one of the most used methods is the name entity recognition(ner) and post tagging methods. It has been observed that success in the retrieval phase increases thanks to semantic role labeling with these methods [11,12,13]. It is seen that support vector machine (SVM) is used as the other classical method classifier. Here, the category to which the query belongs is the classifier that performs document retrieval over that category. Semantic capture was improved with SVM [9, 14].
The disadvantage of classical methods is that the query is misspelled or fails to find semantically similar words. When we examine the literature, we observe that deep learning studies have increased in recent years. When we examine the studies using deep learning, we see that more successful results are obtained than the classical methods (Chen, Y.,) (Pappas, D.) (X. Zhang,) (Lin, H.) (Nie P.) [15,16,17,18]. The advantage of deeplearning is that words are captured in semantic and misspelled words. In this way, most of the studies in the field of question answering in recent years are on deep learning.
4 Conclusion and Future Works
In this systematic literature study, our goal is to analyze and summarize the trends, datasets and methods used in the studies in the field of question answering between 2000–2022. According to the inclusion and exclusion criteria, 91 final studies were determined.
When the studies in the literature are examined, problems such as noisy data, performance and success rates have been dealt with and these problems are still among the subjects that are open to research. In the analysis of selected final studies, it was determined that the current question answering research focused on four topics: KB, IR, NLP, Hybrid Base. When the studies in the field of question answering are examined, 6.72% of the topics are KB topics, 31.94% are IR topics, 59.24% are NLP topics and 2.10% are Hybrid base. In addition, 65.05% of the studies were used as public datasets and 34.95% as private datasets. Fourteen different methods were used for question answering. Among the fourteen methods, seven most applied methods were determined in the field of question answering. These are relation finding(similarity distance), parsing, ner, Tokenize, deep learning, post tagging, graph. Using some of these techniques, the researchers proposed some techniques to improve accuracy in the QA field.
References
Kitchenham, B., Charters, S.: Guidelines for performing systematic literature reviews in software engineering. EBSE Technical Report Version 2.3, EBSE (2007)
Radjenović, D., Heričko, M., Torkar, R., Živkovič, A.: Software fault prediction metrics: a systematic literature review. Inf. Softw. Technol. 55(8), 1397–1418 (2013). https://doi.org/10.1016/j.infsof.2013.02.009
Unterkalmsteiner, M., Gorschek, T., Islam, A., Cheng, C.K., Permadi, R.B., Feldt, R.: Evaluation and measurement of software process improvement-a systematic literature review. IEEE Trans. Softw. Eng. 38(2), 398–424 (2012). https://doi.org/10.1109/TSE.2011.26
Wahono, R.S.: A systematic literature review of software defect prediction: research trends, datasets, methods and frameworks. J. Softw. Eng. 1(1), 1–16 (2015)
Yao, X.: Feature-Driven Question Answering with Natural Language Alignment. John Hopkins University (2014)
Sammut, C., Webb, G.I.: Encyclopedia of Machine Learning. Springer, New York (2011). https://doi.org/10.1007/978-0-387-30164-8
Yang, M.-C., Lee, D.-G., Park, S.-Y., Rim, H.-C.: Knowledge-based question answering using the semantic embedding space. Expert Syst. Appl. 42(23), 9086–9104 (2015). https://doi.org/10.1016/j.eswa.2015.07.009
Brokos, G.-I., Malakasiotis, P., Androutsopoulos, I.: Using centroids of word embeddings and word mover’s distance for biomedical document retrieval in question answering. In: BioNLP 2016 - Proceedings of the 15th Workshop on Biomedical Natural Language, pp. 114–118 (2016). https://doi.org/10.18653/v1/W16-2915
Cao, Y., Liu, F., Simpson, P., Ely, J., Yu, H.: AskHERMES, an online question answering system for complex clinical questions. J. Biomed. Inform. 44(2), 277–288 (2011)
Tellex, S., Katz, B., Fernandes, A., Marton, G.: Quantitative evaluation of passage retrieval algorithms for question answering. In: SIGIR 2003, Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 41–47 (2003)
Bilotti, M.W., Elsas, J., Carbonell, J., Nyberg, E.: Rank learning for factoid question answering with linguistic and semantic constraints. In: International Conference on Information and Knowledge Management, Proceedings, pp. 459–468 (2010)
Pardiño, M., Gómez, J.M., Llorens, H., Moreda, P., Palomar, M.: Adapting IBQAS to work with text transcriptions in QAst task. In: IBQAst: CEUR Workshop Proceedings (2008)
Roth, B., Conforti, C., Poerner, N., Karn, S.K., Schütze, H.: Neural architectures for open-type relation argument extraction. Nat. Lang. Eng. 25(2), 219–238 (2019)
Niu, Y., Hirst, G.: Identifying cores of semantic classes in unstructured text with a semi-supervised learning approach. In: International Conference Recent Advances in Natural Language Processing, RANLP (2007)
Chen, Y., Zhang, X., Chen, A., Zhao, X., Dong, Y.: QA system for food safety events based on information extraction. Nongye Jixie Xuebao/Trans. Chin. Soc. Agric. Mach. 51, 442–448 (2020)
Pappas, D., Androutsopoulos, I.: A neural model for joint document and snippet ranking in question answering for large document collections. In: ACL-IJCNLP 2021–59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Conference, pp. 3896–3907 (2021)
Lin, H.-Y., Lo, T.-H., Chen, B.: Enhanced Bert-based ranking models for spoken document retrieval. In: IEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2019 - Proceedings, vol. 9003890, pp. 601–606 (2019)
Zhang, Y., Nie, P., Ramamurthy, A., Song, L.: Answering any-hop open-domain questions with iterative document reranking. In: SIGIR 2021 - Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, vol. 3462853, pp. 481–490 (2021)
Kratzwald, B., Feuerriegel, S.: Adaptive document retrieval for deep question answering. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP, pp. 576–581 (2018)
Cong, Y., Wu, Y., Liang, X., Pei, J., Qin, Z.: PH-model: enhancing multi-passage machine reading comprehension with passage reranking and hierarchical information. Appl. Intell. 51(8), 5440–5452 (2021). https://doi.org/10.1007/s10489-020-02168-3
Nguyen, T.M., Tran, V.-L., Can, D.-C., Vu, L.T., Chng, E.S.: QASA advanced document retriever for open-domain question answering by learning to rank question-aware self-attentive document representations. In: ACM International Conference Proceeding Series, pp. 221–225 (2019)
Guo, Q.-L., Zhang, M.: Semantic information integration and question answering based on pervasive agent ontology. Expert Syst. Appl. 36(6), 10068–10077 (2009)
Grau, B.: Finding an answer to a question. In: Proceedings of the International Workshop on Research Issues in Digital Libraries, IWRIDL-2006. In: Association with ACM SIGIR, vol. 1364751 (2007)
Radev, D., Fan, W., Qi, H., Wu, H., Grewal, A.: Probabilistic question answering on the web. In: Proceedings of the 11th International Conference on World Wide Web, WWW 2002, pp. 408–419 (2002)
Lin, J., et al.: The role of context in question answering systems. In: CHI EA 2003: CHI 2003 Extended Abstracts on Human Factors in Computing Systems (2003)
Pérez-Coutiño, M., Solorio, T., Montes-y-Gómez, M., López-López, A., Villaseñor-Pineda, L.: Question answering for Spanish based on lexical and context annotation. In: Lemaître, C., Reyes, C.A., González, J.A. (eds.) IBERAMIA 2004. LNCS (LNAI), vol. 3315, pp. 325–333. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-30498-2_33
Zhang, X., Zhan, K., Hu, E., Fu, C., Luo, L., Jiang, H.: Answer complex questions: path ranker is all you need. Artif. Intell. Rev. 55(1), 207–253 (2021)
Fan, Y., , J., Ma, X., Zhang, R., Lan, Y., Cheng, X.: A linguistic study on relevance modeling in information retrieval. In: The Web Conference 2021 - Proceedings of the World Wide Web Conference, WWW 2021, pp. 1053–1064 (2021)
Kaiser, M. : Incorporating user feedback in conversational question answering over heterogeneous web sources. In: SIGIR 2020 - Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 28–42 (2020)
Lamurias, A., Sousa, D., Couto, F.M.: Generating biomedical question answering corpora from QA forums. IEEE Access 8(9184044), 161042–161051 (2020). https://doi.org/10.1109/ACCESS.2020.3020868
Sarrouti, M., Ouatik El Alaoui, S.: SemBioNLQA a semantic biomedical question answering system for retrieving exact and ideal answers to natural language questions. Artif. Intell. Med. 102(101767) (2020)
Shah, A.A., Ravana, S.D., Hamid, S., Ismail, M.A.: Accuracy evaluation of methods and techniques in Web-based question answering systems. Knowl. Inf. Syst. 58(3), 611–650 (2019). https://doi.org/10.1016/j.artmed.2019.101767
Roth, B., Conforti, C., Poerner, N., Karn, S.K., Schütze, H.: Neural architectures for open-type relation argument extraction. Nat. Lang. Eng. 25(2), 219–238 (2019)
Samarinas, C., Tsoumakas, G.: WamBY: an information retrieval approach to web-based question answering. In: ACM International Conference Proceeding Series (2018)
Novotn, V., Sojka, P.: Weighting of passages in question answering. In: Recent Advances in Slavonic Natural Language Processing, December 2018, pp. 31–40 (2018)
Sarrouti, M., Ouatik El Alaoui, S.: A passage retrieval method based on probabilistic information retrieval and UMLS concepts in biomedical question answering. J. Biomed. Inform. 68, 96–103 (2017). https://doi.org/10.1016/j.jbi.2017.03.001
Jin, Z.-X., Zhang, B.-W., Fang, F., Zhang, L.-L., Yin, X.-C.: A multi-strategy query processing approach for biomedical question answering. In: BioNLP 2017 - SIGBioMed Workshop on Biomedical Natural Language Processing, Proceedings of the 16th BioNLP Workshop, pp. 373–380 (2017)
Aroussi, S.A., Habib, N.E., Beqqali, O.E.: Improving question answering systems by using the explicit semantic analysis method. In: SITA 2016–11th International Conference on Intelligent Systems: Theories and Applications 7772300 (2016)
Omari, A., Carmel, D., Rokhlenko, O., Szpektor, I.: Novelty based ranking of human answers for community questions. In: SIGIR 2016 - Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 215–224 (2016)
Hoque, M.M., Quaresma, P.: An effective approach for relevant paragraph retrieval in Question Answering systems. In: 2015 18th International Conference on Computer and Information Technology, ICCIT 2015 7488040, pp. 44–49 (2016)
Brokos, G.-I., Malakasiotis, P., Androutsopoulos, I.: Using centroids of word embeddings and word mover’s distance for biomedical document retrieval in question answering. In: BioNLP 2016-Proceedings of the 15th Workshop on Biomedical Natural Language Processing, pp. 114–118 (2016)
Tsatsaronis, G., et al.: An overview of the BioASQ large-scale biomedical semantic indexing and question answering competition. BMC Bioinform. 16(1), 138 (2015)
Neves, M.: HPI question answering system in the BioASQ 2015 challenge. In: CEUR Workshop Proceedings, vol. 1391 (2015)
Liu, Z.J., Wang, X.L., Chen, Q.C., Zhang, Y.Y., Xiang, Y.: A Chinese question answering system based on web search. In: Proceedings-International Conference on Machine Learning and Cybernetics, vol. 2,7009714, pp. 816–820 (2014)
Ageev, M., Lagun, D., Agichtein, E.: The answer is at your fingertips: improving passage retrieval for web question answering with search behavior data. In: EMNLP 2013–2013 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, pp. 1011–1021 (2013)
Sun, W., Fu, C., Xiao, Q.: A text inference based answer extraction for Chinese question answering. In: Proceedings-2012 9th International Conference on Fuzzy Systems and Knowledge Discovery, FSKD 2012, vol. 6234145, pp. 2870–2874 (2012)
Lu, W., Cheng, J., Yang, Q.: Question answering system based on web. In: Proceedings-2012 5th International Conference on Intelligent Computation Technology and Automation, ICICTA 2012, vol. 6150169, pp. 573–576 (2012)
Saias, J., Quaresma, P.: Question answering approach to the multiple choice QA4MRE challenge. In: CEUR Workshop Proceedings, vol. 1178 (2012)
Foucault, N., Adda, G., Rosset, S.: Language modeling for document selection in question answering. In: International Conference Recent Advances in Natural Language Processing, RANLP, pp. 716–720 (2011)
Monz, C.: Machine learning for query formulation in question answering. Nat. Lang. Eng. 17(4), 425–454 (2011)
Zhang, W., Duan, L., Chen, J.: Reasoning and realization based on ontology model and Jena. In: Proceedings 2010 IEEE 5th International Conference on Bio-Inspired Computing: Theories and Applications, BIC-TA 2010, vol. 5645115, pp. 1057–1060 (2010)
Li, F., Kang, H., Zhang, Y., Su, W.: Question intention analysis and entropy-based paragraph extraction for medical question answering. In: ICCASM 2010–2010 International Conference on Computer Application and System Modeling, Proceedings, vol. 3,5620229, pp. V3354–V3357 (2010)
Li, X., Chen, E.: Graph-based answer passage ranking for question answering. In: Proceedings-2010 International Conference on Computational Intelligence and Security, vol. 5696360, pp. 634–638 (2010)
Lu, W.-H., Tung, C.-M., Lin, C.-W.: Question intention analysis and entropy-based paragraph extraction for medical question answering. In: IFMBE Proceedings 31 IFMBE, pp. 1582–1586 (2010)
Nguyen, D.T., Pham, T.N., Phan, Q.T.: A semantic model for building the Vietnamese language query processing framework in e-library searching application. In: ICMLC 2010 - The 2nd International Conference on Machine Learning and Computing, vol. 5460746, pp. 179–183 (2010)
Nguyen, D.T., Nguyen, H.V., Phan, Q.T.: Using the Vietnamese language query processing framework to build a courseware searching system. In: 2010 2nd International Conference on Computer Engineering and Applications, ICCEA 2010, vol. 2,5445613, pp. 117–121 (2010)
Buscaldi, D., Rosso, P., Gómez-Soriano, J.M., Sanchis, E.: Answering questions with an n-gram based passage retrieval engine. J. Intell. Inf. Syst. 34(2), 113–134 (2010)
Momtazi, S., Klakow, D.: A word clustering approach for language model-based sentence retrieval in question answering systems. In: International Conference on Information and Knowledge Management, Proceedings, pp. 1911–1914 (2009)
Dang, N.T., Thi, D., Tuyen, T.: Document retrieval based on question answering system. In: 2009 2nd International Conference on Information and Computing Science, ICIC 2009, vol. 1,5169570, pp. 183–186 (2009)
Guo, Q.-L., Zhang, M.: Semantic information integration and question answering based on pervasive agent ontology. Expert Syst. Appl. 36(6), 10068–10077 (2009)
Dang, N.T., Tuyen, D.T.T.: Natural language question-answering model applied to document retrieval system: world academy of science. Eng. Technol. 39, 36–39 (2009)
Dang, N.T., Tuyen, D.T.T.: E-document retrieval by question answering system: world academy of science. Eng. Technol. 38, 395–398 (2009)
Abouenour, L., Bouzoubaa, K., Rosso, P.: Structure-based evaluation of an Arabic semantic query expansion using the JIRS passage retrieval system. In: Proceedings of the EACL 2009 Workshop on Computational Approaches to Semitic Languages, SEMITIC@EACL 2009, pp. 62–68 (2009)
Ortiz-Arroyo, D.: Flexible question answering system for mobile devices: 3rd International Conference on Digital Information Management, ICDIM 2008, vol. 4746794, pp. 266–271 (2008)
Lita, L.V., Carbonell, J.: Cluster-based query expansion for statistical question answering. In: JCNLP 2008–3rd International Joint Conference on Natural Language Processing, Proceedings of the Conference (2008)
Kürsten, J., Kundisch, H., Eibl, M.: QA extension for Xtrieval: contribution to the QAst track. In: CEUR Workshop Proceedings, vol. 1174 (2008)
Comas, P.R., Turmo, J.: Robust question answering for speech transcripts: UPC experience in QAst. In: CEUR Workshop Proceedings, vol. 1174 (2008)
Hu, B.-S., Wang, D.-L., Yu, G., Ma, T.: Answer extraction algorithm based on syntax structure feature parsing and classification. Jisuanji Xuebao/Chin. J. Comput. 31(4), 662–676 (2008)
Yang, Z., Lin, H., Cui, B., Li, Y., Zhang, X.: DUTIR at TREC 2007 genomics track. NIST Special Publication (2007)
Schlaefer, N., Ko, J., Betteridge, J., Pathak, M., Nyberg, E.: Semantic extensions of the ephyra QA system for TREC 2007. NIST Special Publication (2007)
Hickl, A., Roberts, K., Rink, B., Shi, Y., Williams, J.: Question answering with LCC’s CHAUCER-2 at TREC 2007. NIST Special Publication (2007)
Pasca, M.: Lightweight web-based fact repositories for textual question answering. In: International Conference on Information and Knowledge Management, Proceedings, pp. 87–96 (2007)
Peters, C.: Multilingual information access: the contribution of evaluation. In: Proceedings of the International Workshop on Research Issues in Digital Libraries, IWRIDL-2006, vol. 1364761. Association with ACM SIGIR (2007)
Yang, Y., Liu, S., Kuroiwa, S., Ren, F.: Question answering system of confusian analects based on pragmatics information and categories. In: IEEE NLP-KE 2007 - Proceedings of International Conference on Natural Language Processing and Knowledge Engineering, vol. 4368056, pp. 361–366 (2007)
Tiedemann, J.: Comparing document segmentation strategies for passage retrieval in question answering. In: International Conference Recent Advances in Natural Language Processing, RANL (2007)
Yarmohammadi, M.A., Shamsfard, M., Yarmohammadi, M.A., Rouhizadeh, M.: Using WordNet in extracting the final answer from retrieved documents in a question answering system. In: GWC 2008: 4th Global WordNet Conference, Proceedings, pp. 520–530 (2007)
Niu, Y., Hirst, G.: Comparing document segmentation strategies for passage retrieval in question answering. In: International Conference Recent Advances in Natural Language Processing, RANLP 2007-January, pp. 418–424 (2007)
Hussain, M., Merkel, A., Klakow, D.: Dedicated backing-off distributions for language model based passage retrieval. Lernen, Wissensentdeckung und Adaptivitat, LWA 2006, 138–143 (2006)
Jinguji, D., Lewis, W., Efthimiadis, E.N., Yu, P., Zhou, Z.: The university of Washington’s UWCLMAQA system. NIST Special Publication (2006)
Balantrapu, S., Khan, M., Nagubandi, A.: TREC 2006 Q &A factoid TI experience. NIST Special Publication (2006)
Ofoghi, B., Yearwood, J., Ghosh, R.: TREC 2006 Q &A factoid: TI experience. In: Conferences in Research and Practice in Information Technology Series, vol. 48, pp. 95–101 (2006)
Ferrés, D., Rodríguez, H.: Experiments using JIRS and Lucene with the ADL feature type Thesaurus. In: CEUR Workshop Proceedings, vol. 1172 (2006)
García-Cumbreras, M.A., Ureña-Lòpez, L.A., Santiago, F.M., Perea-Ortega, J.M.: BRUJA system. The University of Jaén at the Spanish task of CLEFQA 2006. In: CEUR Workshop Proceedings, vol. 1172 (2006)
Blake, C.: A comparison of document, sentence, and term event spaces. In: COLING/ACL 2006–21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, vol. 1, pp. 601–608 (2006)
Yu, Z.T., Zheng, Z.Y., Tang, S.P., Guo, J.Y.I.: Query expansion for answer document retrieval in Chinese question answering system. In: 2005 International Conference on Machine Learning and Cybernetics, ICMLC 2005, pp. 72–77 (2005)
Jousse, F., Tellier, I., Tommasi, M., Marty, P.: Learning to extract answers in question answering. In: CORIA 2005–2EME Conference en Recherche Informations et Applications (2005)
Ferrés, D., Kanaan, S., Dominguez-Sal, D, Surdeanu, M., Turmo, J.: Experiments using a voting scheme among three heterogeneous QA systems. NIST Special Publication (2005)
Yang, G.C., Oh, H.U.: ANEX an answer extraction system based on conceptual graphs. In: Proceedings of the 2005 International Conference on Information and Knowledge Engineering, IKE 2005, pp. 17–24 (2005)
Tiedemann, J.: Integrating linguistic knowledge in passage retrieval for question answering. In: HLT/EMNLP 2005-Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, pp. 939–946 (2005)
Isozaki, H.: An analysis of a high-performance Japanese question answering system. ACM Trans. Asian Lang. Inf. Process. 4(3), 263–279 (2005)
Tiedemann, J. : Integrating linguistic knowledge in passage retrieval for question answering. In: International Conference Recent Advances in Natural Language Processing, RANLP 2005-January, pp. 540–546 (2005)
Amaral, C., Figueira, H., Martins, A., Mendes, P., Pinto, C.: Priberam’s question answering system for Portuguese. In: CEUR Workshop Proceedings, vol. 1171 (2005). (Subseries of Lecture Notes in Computer Science), vol. 3315, pp. 325–333 (2004)
Banerjee P, Han H.: Incorporation of corpus-specific semantic information into question answering context. In: ONISW 2008 Proceedings of the 2nd International Workshop on Ontologies and Information Systems for the Semantic (2008)
Khushhal, S., Majid, A., Abbas, S.A., Nadeem, M.S.A., Shah, S.A.: Question retrieval using combined queries in community question answering. J. Intell. Inf. Syst. 55(2), 307–327 (2020). https://doi.org/10.1007/s10844-020-00612-x
Nie, Y., Han, Y., Huang, J., Jiao, B., Li, A.: Attention-based encoder-decoder model for answer selection in question answering. Front. Inf. Technol. Electron. Eng. 18, 535–544 (2017)
Cao, Y., Wen, Y., Chin, Y., Yong, Y.: A structural support vector method for extracting contexts and answers of questions from online forums. Inf. Process. Manag. 47(6), 886–898 (2011)
Monroy, A., Calvo, H., Gelbukh, A.: Using graphs for shallow question answering on legal documents. In: Gelbukh, A., Morales, E.F. (eds.) MICAI 2008. LNCS (LNAI), vol. 5317, pp. 165–173. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-88636-5_15
Ofoghi, B., Yearwood, J., Ghosh, R.: A semantic approach to boost passage retrieval effectiveness for question answering. In: ACSC 2006: Proceedings of the 29th Australasian Computer Science Conference, vol. 48, pp. 95–101 (2006)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Bakır, D., Aktas, M.S. (2022). A Systematic Literature Review of Question Answering: Research Trends, Datasets, Methods. In: Gervasi, O., Murgante, B., Misra, S., Rocha, A.M.A.C., Garau, C. (eds) Computational Science and Its Applications – ICCSA 2022 Workshops. ICCSA 2022. Lecture Notes in Computer Science, vol 13377. Springer, Cham. https://doi.org/10.1007/978-3-031-10536-4_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-10536-4_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-10535-7
Online ISBN: 978-3-031-10536-4
eBook Packages: Computer ScienceComputer Science (R0)