
Abstract
A CNN (Convolutional Neural Network) is an artificial neural network used to evaluate visual pictures. It is used for visual image processing and is categorised as a deep neural network in deep learning. So, using real-time image processing, an AI autonomous driving model was built using a road crossing picture as an impediment. Based on the CNN model, we created a low-cost approach that can realistically perform autonomous driving. An end-to-end model is applied to the most widely used deep neural network technology for autonomous driving. It was shown that viable lane identification and maintaining techniques may be used to train and self-drive on a virtual road.
S. Bhujade—Independent Researcher.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Images have recognized, and natural language processing has been improved with its usage in recent times. Because CNN (Convolutional Neural Network) performs better than conventional techniques, there is a lot of work being done in image recognition. The development of self-driving automobiles is a prominent area of investigation. Several instruments and cameras are necessary to detect the nearby atmosphere and instantaneously identify acceleration, deceleration. They halt to acquiring and analyzing information both within and outside the autonomous vehicle. Another benefit of using continuous video or data feeds for autonomous driving is tackling this problem much more rapidly. An autonomous driving system for automobiles is being developed and tested in this study using a deep learning algorithm. This approach, which has a significant influence on picture recognition, can easily handle the development of autonomous driving systems.
2 Deep Learning Method for Self-driving Car

Structure of reinforcement learning
As a result of this, convolutional artificial neural networks (CNNs) have been developed. Neural networks are the basic building blocks of CNNs. 1) Neurons between layers remain “local” and disconnected in each layer. Neuron input from a lower-layer neuron located in a rectangular space next to the neuron’s upper layer. The neural receptive field may be found here. Neural cells in the same layer share the weights of “local” connections. The number of CNN model parameters is reduced because of the immutability of visual input. CNN is regarded as “implicit previous knowledge” in computer vision; CNN has proved to be a viable paradigm for resolving cv difficulties. AlexNet [3] surpassed ImageNet [4] in 2012, which prompted CNN and its newest algorithms to be adopted immediately. As a result, CNN has become a symbol of self-driving vehicles. An RNN is a deep learning method that works well with large datasets. Being able to deal with time. Natural language processing, as well as video, are two of its strong points. Streaming. An accurate depiction of self-driving vehicles is essential. Unpredictable and ever-changing environmental conditions Thus, driving data from the past may be used to create more accurate representations of the environment. Reinforcement learning may be modelled using the Markov Decision Process. In the same way as in a When the robot correctly determines the present state of the environment, it gets rewarded. Reinforcement, The optimum technique is learned via this process of trial and error. To maximise the cumulative Reward, the policy recommends an approach that maximises the sum of all rewards. Laws like this. Figure 1 depicts a conceptual framework for reinforcement learning. Learners should be rewarded for their efforts. In self-driving cars, technology is used in a variety of ways.
Tries to identify a continuous action strategy that maximizes the agent’s advantage environment. Action, Reward, State, Agent, and Environment are the five components. a subject that learns and acts in the environment. When Agent Acts, Agent recognizes its own condition as Reward. The agent so interacts with reinforcement learning continues [6,7,8,9].
3 Deep Learning-Based Acknowledgement of Autonomous Driving
Figure 2 displays two self-driving car channels based on deep learning. However, (b) is an all-encompassing system that recognises, plans, and executes all at once. A non-learning method or a deep learning technique may both be used in a sequential pipeline. Deep learning is used widely in end-to-end learning systems.
Using deep neural networks to operate sensors directly speeds the process. Deep neural networks This is based on recent studies [12]. End-to-end control of autonomous vehicles using layer three neural networks was first demonstrated in the late 1980s [13]. This experiment employed a six-layer CNN in the initial 2000s [14] for DARPA’s autonomous vehicle (DAVE) research. From the visual pixels, the neural network model generates steering control instructions. All intermediary steps are skipped in the sequential pipeline approach.
Cameras in automobiles take 30 frames per second of roadside images, according to NVIDIA research. This information was also obtained, which is how many degrees to the right or left. A cause and a result must be linked in supervised learning. Lane-maintaining AI uses the road image as a cause value (X) and the handle value. As a result, value (Y) (Y). The lane-maintenance function cannot be implemented using a modest linear equivalence. Because of this, an artificial neural network is needed. In additional arguments, as predictive models, artificial neural networks have taken the role of straight lines. The predicted handle value is returned as before when the highway copy is input into the artificial neural network. To minimise the overall number of mistakes, an artificial neural network is trained to provide the smallest possible difference between the predicted and actual values of the steering wheel.

A self-driving automobile powered by deep learning.
4 Low-Cost Autonomous Vehicle Architecture Design
4.1 Preparation of the Data for Analysis
Before gathering data for self-driving vehicles, the route must be prepared. Small or large, the road was created and used in an unsuitable manner. 1.5 to 2 times the width of an automobile is ideal. On a small path, it’s problematic to ambition and get enough drill information. If the road is also varied, the camera may not be able to detention both left and right sides at the same time. Moderate curves and straight lines would be included in the roads. A discrepancy in rotational speed between the left and suitable motors in prototype studies makes it difficult to handle curving roads. Accomplished A incorrect turn might be difficult to navigate, even on a straight route. If an artificial intelligence system is operating in a safe mode, direct driving enables the driver to act like a human. The prototype road model is seen in Fig. 3.

Prototypes of self-driving vehicles.
It is essential that the data proportions be equalised. As an example, for a left turn, the ratio is 14%; for a straight-ahead, it is 76%; and for a right turn, it is 20%. There is a 76% to 18% shift in the correct turn ratio after running decalcompy.py. Learning to turn left and right is improved by reducing the left/right balance. Scaling data may be done in two ways when it is not equal. Down Left/right turn counts are equalised by selecting the number of left/right angles from the total data of straight forward, which has an 18%, 76%, 18% ratio. Reduces the number of categories to a few from many with many classes, in other words. An artificial intelligence system may not function as well as it might if the missing knowledge is critical. When the ratio of left, straight, and right turns reaches 18%, it begins to replicate the data. It develops the data volume of a wide variety with a high data rate by continually copying and using the data of a category with a low data rate. Overfitting on repeated data might be a drawback of this approach, which benefits from increasing the number of data and altering the data rate. The data rate may be adjusted by using sampling in this study.
4.2 Prototype Training for the Self-driving Car
Figure 4 depicts the System hardware structure. Using Tensorflow to classify images is covered in more depth later. In this case, the picture and the arrow keys associated with it are preserved in the Orange Pie light internal folder. After gathering the training data, the system regulates the speed of the DC motor and runs using image classification.
This study employed a categorization model. Classification is the process of categorizing a result and predicting it. The system flow is as follows. First, using VNC Viewer to connect to Orange-pi remotely, the user collects learning data and saves it as an image. After gathering training data, a classification model is developed. Figure 5 depicts the model’s classification process. The road picture is sent to the input layer of the artificial neural network, which predicts and expresses a value in the output layer of four neurons (stop, go straight, turn right, turn left). It also stops at a crosswalk on the road. Predicted values for four categories are shown as likelihood based on the current road picture. Among these, the most likely value is chosen as the AI’s output value.

Overall system structure

Images of road signs are used to classify them.
4.3 Network Architecture
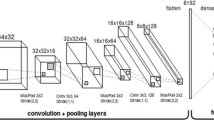
As illustrated in Fig. 6, the learning technique employed in this study has four convolutional layers and three fully linked layers. Figure 7 also shows the internal structure of the convolutional and fully linked layers. The convolution layer uses a 3 × 3, and a 5 × 5 kernel in the sequence of convolution and activation functions indicated in Fig. 7. More steps in the convolutional layer improve feature detection but takes a long time to learn. However, if it gets above a particular point, the picture becomes distorted, and the performance suffers. Conversely, a low amount of convolutional layer limits feature extraction, resulting in poor accuracy.

CNN network structure

Fully linked layer structure with a convolutional layer.
The kernel derives the image’s features and checks if the detected feature exists in the area based on the learnt part. This work employed three layers for the ultimately linked layer. After flattening using 1D data, dropout is used to the first completely connected layer to avoid over-fitting. The second layer is dropped out again after employing the Relu activation algorithm. The final layer uses Relu and Dropout. The last layer connects the photographs to the same four layers as the experiment’s image kinds.
Implementation:
The system utilises Python, Tensorflow, and Otangepi. Apple’s H3 quad-core Cortex-A7 H.265/HEVC 4K CPU and Mali 400MP2 GPU @600 MHz support OpenGL ES 2.0 on Orangepi. Figure 8: Autonomous car prototype.

Autonomous car prototype

Each experiment’s self-driving prediction accuracy (loss value)
During the learning process, prediction rates are shown graphically in Fig. 9. The final learning model has a prediction rate of 87%, which is the most significant. Tertiary learning models’ loss values decrease as learning progresses in Fig. 9. Afterwards, the model is ready for self-driving operations. More iterations are mentioned training accuracy, training loss and Validation accuracy and loss is mentioned in Fig. 9. Figure 8 shows the camera on the toy car prototype’s camera taking a photo of the vehicle as it moves forward, left, and right. Because of this, the left and right turns are 100% correct so that you won’t get lost. Off-roading is less probable if you make more accurate left/right turns. Despite its zigzag function, it is safe to drive since it can only be steered by turning left or right. If the straight line’s precision is at or over 50%, it is blended correctly.
5 Conclusion
A CNN-based deep learning algorithm was used to construct an active vehicle autonomous driving system to examine low-cost autonomous driving based on picture categorisation. This article’s discussion of self-driving cars relies on a technique known as convolutional neural networks (CNN). This might be done in the future with the creation of a low-cost testbed. By explaining the responsibilities of other subsystems in autonomous driving, it is feasible to investigate object identification and navigation.
References
Kurnia, R.I., Girsang, A.S.: Classification of user comment using word2vec and deep learning. Int. J. Emerg. Technol. Adv. Eng. 11(5), 1–8 (2021). https://doi.org/10.46338/IJETAE0521_01
Adytia, N.R., Kusuma, G.P.: Indonesian license plate detection and identification using deep learning. Int. J. Emerg. Technol. Adv. Eng. 11(7), 1–7 (2021). https://doi.org/10.46338/ijetae0721_01
Rahman, R.A., Masrom, S., Zakaria, N.B., Halid, S.: Auditor choice prediction model using corporate governance and ownership attributes: machine learning approach. Int. J. Emerg. Technol. Adv. Eng. 1(7), 87–94 (2021). https://doi.org/10.46338/ijetae0721_11
Dela Cruz, L.A., Tolentino, L.K.S.: Telemedicine implementation challenges in underserved areas of the Philippines. Int. J. Emerg. Technol. Adv. Eng. 11(7), 60–70 (2021). https://doi.org/10.46338/ijetae0721_08
Hermanto, Kusuma, G.P.: Density estimation-based crowd counting using CSRNet and Bayesian+ loss function. Int. J. Emerg. Technol. Adv. Eng. 11(7), 19–27 (2021). https://doi.org/10.46338/ijetae0721_04
Mustapa, R.F., Rifin, R., Mahadan, M.E., Zainuddin, A.: Interactive water level control system simulator based on OMRON CX-programmer and CX-designer. Int. J. Emerg. Technol. Adv. Eng. 11(9), 91–99 (2021). https://doi.org/10.46338/IJETAE0921_11
Rahman, A.S.A., Masrom, S., Rahman, R.A., Ibrahim, R.: Rapid software framework for the implementation of machine learning classification models. Int. J. Emerg. Technol. Adv. Eng. 11(8), 8–18 (2021). https://doi.org/10.46338/IJETAE0821_02
Khotimah, N., Wibowo, A.P., Andreas, B., Girsang, A.S.: A review paper on automatic text summarization in Indonesia language. Int. J. Emerg. Technol. Adv. Eng. 11(8), 89–96 (2021). https://doi.org/10.46338/IJETAE0821_11
Ehsani, M., Gao, Y., Emadi, A.: Modern Electric, Hybrid Electric, and Fuel Cell Vehicles, 2nd edn. CRC Press, Boca Raton (2009)
Gao, Y., Ehsani, M.: Design and control methodology of plug-in hybrid electric vehicles. IEEE Trans. Industr. Electron. 57(2), 633–640 (2010)
Sciarretta, A., Guzzella, L.: Control of hybrid electric vehicles. IEEE Control. Syst. 27(2), 60–70 (2007)
Martinez, C.M., Hu, X., Cao, D., Velenis, E., Gao, B., Wellers, M.: Energy management in plug-in hybrid electric vehicles: recent progress and a connected vehicles perspective. IEEE Trans. Veh. Technol. 66(6), 4534–4549 (2017)
Mahrishi, M., et al.: Video index point detection and extraction framework using custom YoloV4 Darknet object detection model. IEEE Access 9, 143378–143391 (2021)
Feng, T., Yang, L., Gu, Q., Hu, Y., Yan, T., Yan, B.: A supervisory control strategy for plug-in hybrid electric vehicles based on energy demand prediction and route preview. IEEE Trans. Veh. Technol. 64(5), 1691–1700 (2013)
Li, L., Yang, C., Zhang, Y., Zhang, L., Song, J.: Correctional DP-based energy management strategy of plug-in hybrid electric bus for citybus-route. IEEE Trans. Veh. Technol. 64(7), 2792–2803 (2015)
Manikyam, S., Kumar, S.S., Pavan, K.V.S., Kumar, T.R.: Laser heat treatment was performed to improve the bending property of laser welded joints o low-alloy ultrahigh-strength steel with minimized strength loss. 83, 2659–2673 (2019)
Siddam, S., Somasekhar, T., Reddy, P., Kumar, T.: Duplex stainless steel welding microstructures have been engineered for thermal welding cycles & nitrogen (N) gas protection. Mater. Today Proc. (2021). https://doi.org/10.1016/j.matpr.2020.11.091
Kumar, T., Mahrishi, M., Meena, G.: A comprehensive review of recent automatic speech summarization and keyword identification techniques. In: Fernandes, S.L., Sharma, T.K. (eds.) Artificial Intelligence in Industrial Applications. LAIS, vol. 25, pp. 111–126. Springer, Cham (2022). https://doi.org/10.1007/978-3-030-85383-9_8
Dhotre, V.A., Mohammad, H., Pathak, P.K., Shrivastava, A., Kumar, T.R.: Big data analytics using MapReduce for education system. Linguist. Antverpiensia 3130–3138 (2021)
Gurugubelli, S., Chekuri, R.B.R.: The method combining laser welding and induction heating at high temperatures was performed. Design Eng. 592–602 (2021)
Pavan, K.V.S., Deepthi, K., Saravanan, G., Kumar, T.R., Vinay, A.V.: Improvement of delamination spread model to gauge a dynamic disappointment of interlaminar in covered composite materials & to forecast of material debasement. PalArch’s J. Archaeol. Egypt/Egyptol. 17(9), 6551–6562 (2020)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Bhujade, S., Kamaleshwar, T., Jaiswal, S., Babu, D.V. (2022). Deep Learning Application of Image Recognition Based on Self-driving Vehicle. In: Balas, V.E., Sinha, G.R., Agarwal, B., Sharma, T.K., Dadheech, P., Mahrishi, M. (eds) Emerging Technologies in Computer Engineering: Cognitive Computing and Intelligent IoT. ICETCE 2022. Communications in Computer and Information Science, vol 1591. Springer, Cham. https://doi.org/10.1007/978-3-031-07012-9_29
Download citation
DOI: https://doi.org/10.1007/978-3-031-07012-9_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-07011-2
Online ISBN: 978-3-031-07012-9
eBook Packages: Computer ScienceComputer Science (R0)