
Abstract
Magnetic field fingerprinting has been an interesting topic in indoor localization researches because of its advantages of being ubiquitous, energy-efficient and infrastructure-free. Most existing indoor magnetic field-based positioning methods use the raw three-dimensional magnetic field strength obtained by the magnetic sensor built in smartphones. However, they have to overcome the problem of ambiguity that originates from the nature of geomagnetic data, especially in the large-scale environment. In this paper, we first expand the dimension of magnetic data elements, and a sliding window mechanism is designed to construct magnetic sequence fingerprints to increase the distinguishability of magnetic field fingerprints. Moreover, an accurate indoor positioning model combining the advantages of one-dimensional convolutional neural network and long short-term memory network is designed to automatically learn the mapping between ground-truth positions and magnetic sequence fingerprints. To demonstrate the effectiveness of our proposed method, we perform a comprehensive experimental evaluation on three real-world datasets, and the results show that the proposed approach can remarkably improve positioning performance compared with other methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
With the rapid development of mobile technology, accurate and pervasive location-based service significantly facilitates and enriches daily life. The proliferation of modern smartphones and their wide usage in daily life motivate the rapid development of LBS (Location-Based Services) that could provide precise location information for the user, both outdoor and indoor. The outdoor location can be obtained by GPS (Global Positioning System) with high accuracy. However, its signals cannot cover many indoor scenarios, such as shopping malls, libraries, and museums. Therefore, indoor localization has become a hot research area.
In order to achieve robust meter-level accuracy of indoor location-based services, many types of indoor positioning methods have been proposed, including Bluetooth [12], Wi-Fi [15] and CSI (Channel State Information) [11]. Unfortunately, these positioning signals have inherent limitations: Bluetooth-based positioning requires extra infrastructure; Wi-Fi-based positioning can only provide rough location estimation due to its signal fluctuation; CSI can provide high precision positioning only in a small-range environment because it needs to sample a large number of dense training points.
Magnetic field-based indoor localization has been actively studied in recent years since its signal is ubiquitous, and it incurs almost no additional energy consumption and requires no extra infrastructure. In addition, researchers find that the magnetic field strength (MFS), determined by the geomagnetic field and building’s iron structures such as steel frames and electrical appliances, is sufficiently stable in indoor environments [4]. So far, various indoor localization approaches (see Sect. 2 for a review) have been presented that take advantage of magnetic field data to locate a person in the indoor environment. However, existing magnetic field-based positioning methods using smartphone are limited by two factors. First, the magnetic field dataset collected from smartphones is a collection of three-dimensional vectors with great ambiguity, especially in a large-scale indoor environment with a similar structure. Second, the existing magnetic field-based positioning models cannot effectively extract enough features from raw magnetic sequence data.
In this paper, we propose an accurate magnetic field-based indoor localization system with a hybrid neural network that combines a one-dimensional convolutional neural network (1D-CNN) and a long short-term memory (LSTM) network. In order to reduce the ambiguity and improve the uniqueness of magnetic field fingerprints, we expand the raw three-dimensional magnetic data elements to five-dimensional. In addition, we observed in the experiment that although the magnetic field strength may fluctuate at a point, the magnetic sequence of the same path has the same trend. Therefore, a sliding window mechanism is designed to construct the magnetic sequence fingerprints (MSFs) based on the transformed magnetic data elements. In order to obtain the optimal positioning model, we divide the model training into two steps: the Adam optimizer first to converge the model quickly and then the stochastic gradient descent (SGD) optimizer to make the model better.
The contributions of this research can be summarized as follows.
-
1.
An indoor localization model called CNN-LSTM is proposed that combines the advantages of 1D-CNN and LSTM and uses magnetic field fingerprints alone to realize localization in the indoor environment.
-
2.
A novel fingerprint construction method is devised, which first expands the dimension of magnetic data elements and then uses a sliding window mechanism to construct magnetic sequence fingerprints.
-
3.
The proposed approach is tested on three real-world datasets, and experimental results show that the proposed positioning method significantly surpasses the existing approaches in terms of mean positioning error and cumulative error distribution.
The remainder of the paper is arranged as follows. Section 2 surveys related work on indoor positioning with the magnetic field or deep learning. Section 3 provides our proposed system architecture, data collection and preprocessing, MSFs construction. The detailed process of the proposed positioning model is described in Sect. 4. And Sect. 5 describes how the experimental campaign was set and conducted, and results analysis. Section 6 concludes the paper. Some related acronyms are listed in Table 1.
2 Related Work
The request for pervasive indoor LBS (Location-Based Services) has spurred the development of efficient indoor positioning techniques. In this section, we mainly review two types of indoor localization systems, i.e., magnetic field-based and deep learning-based systems.
Earth magnetic field has been proven to be useful in indoor positioning because it is natural and ubiquitous. After Suksakulchai [14] realized that the magnetic field disturbances could be used for indoor localization, Chung et al. [5] and Grand et al. [8] used the magnetic field signal as fingerprint for indoor localization. In order to make better use of the information of the magnetic field, different magnetic field features (e.g., kurtosis, mean and slope) were tested to achieve room-level accuracy [7]. The work [6] studied the magnetic field intensity and direction distribution features for constructing magnetic maps. The improved work [13] proposed a feature distinguishability measurement technique to evaluate the performance of different feature extraction methods for magnetic fingerprints. Unfortunately, the study [3] found that the magnetometers in smartphones are vulnerable to a few factors such as user’s postures and walking speed, which causes the magnetic field strength corresponding to a location often shift in time or exhibit local distortions, thus greatly limits the positioning performance of existing methods rely on raw magnetic field strength.
Recently, many researchers use deep learning technology for indoor positioning to improve positioning accuracy. There are three types of deep networks used for indoor localization, including deep autoencoder networks, deep convolution neuron networks (CNN), and LSTM networks [18]. DeepFi was the first work based on autoencoder to use CSI amplitudes for indoor positioning [16]. Moreover, deep autoencoder networks-based indoor localization systems with Bluetooth Low Energy (BLE) [20] and Wi-Fi [1] have also been proposed. CiFi was the first system that incorporated a deep CNN for indoor localization [17]. Immediately afterwards, AMID [10] utilized a convolution neural network (CNN) for analyzing magnetic field features and a multi-layer perceptron (MLP) for magnetic landmark classification. In addition, MINLOC [2] designed multiple CNN models combining with a voting mechanism to improve positioning performance. The proposed DeepML [19] system was the first to employ deep LSTM with magnetic and light bimodal data for indoor localization. In order to save the workforce, in reference [4], Chiang et al. built a robotic platform for magnetic field data collection, and they studied some data augmentation mechanisms to facilitate the RNN-LSTM model for improving the positioning accuracy. However, many of the above-mentioned works require a large amount of data for training to predict user position. Additionally, heterogeneous smartphones and the different walking speeds of users reduce the scalability of these methods.

The indoor positioning system architecture
We, therefore, seek to minimize those drawbacks by using magnetic data combined with deep learning to better perform indoor localization. First, a novel fingerprint construction method is proposed to construct MSFs with high distinguishability, and then these MSFs are used to train the CNN-LSTM model to predict the user location accurately. Furthermore, our system has good scalability, because it has achieved considerable positioning performance in three different typical experimental environments, using different smartphones, and with different walking speeds of users.
3 System Architecture
3.1 General Overview
The architecture of the proposed indoor positioning system is presented in Fig. 1. The main processes of the system contains magnetic data collection and preprocessing phase, model training phase and online localization phase. The details of these phases are described in the Sect. 3.2, Sect. 3.3 and Sect. 4.
3.2 Magnetic Data Collection and Preprocessing
The magnetic data collection and preprocessing process consists of data collection, magnetic data elements expansion, magnetic sequence data scaling, noise reduction, and data normalization.
Magnetic Data Collection. There is a large error in the point-based positioning due to the following two factors: 1) the MFS at a given indoor location is a 3-D vector in space that varying similarly with near location; 2) different orientation or postures of mobile phone lead to different MFS readings at the same location. Moreover, we collected three magnetic sequences for the same space trajectory at different times, which are shown in Fig. 2. We could observe that there may be some shifts in the magnetic sequence at different times, but the changing trend is basically the same. Therefore, this study adopts a fast continuous collection method to collect magnetic sequence data on multiple paths in the indoor environment, which can well reflect the distribution of the indoor magnetic field and has good uniqueness. Figure 3 shows the procedure of the collection of magnetic data on an indoor path. The distance between every two reference points on the experimental path is 0.5 m. Since the sampling frequency 50 Hz and the walking speed is 1 m/s, the magnetic sequence between the two reference points includes 25 magnetic data.

Three magnetic sequences of the same space trajectory at different times

Collection of magnetic data
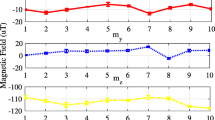
Magnetic Data Elements Expansion. As shown in Fig. 4(a), the magnetic field information collected by the smartphone is represented by three-axis data (\(M_x\), \(M_y\), \(M_z\)). When we synthesize them, we can represent the rich magnetic field information, e.g., total magnetic field strength \(M_{xyz}\) and horizontal component \(M_{xy}\). The magnetic data obtained by the built-in magnetic sensor of the smartphone is based on the device coordinate system of the mobile phone, and the direction of the mobile phone held on the user is arbitrary in the walking, so the device coordinate system is changing. This study converts the measured magnetic data from the device coordinate system to the world coordinate system which is fixed (Their definitions are shown in Fig. 4(b) and Fig. 4(c), respectively.). The triaxial component (\(M_x^{'}\), \(M_y^{'}\), \(M_z^{'}\)) of the magnetic field in the world coordinate system is obtained. These elements can be calculated by the Eq. (1):
where (\(M_x\), \(M_y\), \(M_z\)) represents the three-dimensional magnetic field strength obtained by the smartphone’s magnetic sensor, (\(M_x^{'}\), \(M_y^{'}\), \(M_z^{'}\)) represents the three-dimensional magnetic field strength under the world coordinate system. R represents the rotation matrix from the device coordinate system to the world coordinate system, which can be obtained by the function “getRotationMatrix”Footnote 1 in the application programming interface (API) for Android application development.
However, the selection of magnetic data elements greatly influences the resolution of the MSFs, which determines the positioning performance. Moreover, we have learned that the original three-dimensional magnetic data elements \((M_x, M_y, M_z)\) are orientation-dependent of the smartphone, but the total magnetic field magnitude \(M_{xyz}\) is stable and orientation-independent of the smartphone. Therefore, this study uses five-dimensional magnetic data elements (\(M_{xy}\), \(M_z\), \(M_y^{'}\), \(M_z^{'}\), \(M_{xyz}\)) (Because the value of the \(M_x^{'}\) component is always close to 0, it is discarded.) that are not affected by the orientation changing of the smartphone and are highly distinguishable.

Information of the magnetic field and the definition of coordinate systems
Magnetic Sequence Data Scaling. The magnetic signal is sampled sequentially while walking of the user, but different walking speeds produce different number of magnetic field data on the same experimental path. This feature may bring a lot of magnetic sequences with different lengths. However, all magnetic sequences fed into the positioning model are required to have the same length. Therefore, user speed is one of the main issues when using a sequence fingerprint for indoor localization.
In this study, we use interpolation and deletion for getting the same number of magnetic field data at different walking speeds. For magnetic sequences obtained in fast walking, we propose an interpolation algorithm named Neighbor Average Interpolation, as shown in Algorithm 1. For magnetic sequences obtained in slow walking, we delete redundant data in the magnetic sequences at an equal interval d. This interval d is calculated by Eq. (2).
where \(l_S\) and \(l_N\) are the length of magnetic sequence collected at slow speed and normal speed, respectively.

Noise Reduction. Low-quality magnetometers built in smartphones produce a lot of noise. To reduce the noise, we use a smoothing filter (Median Average Filtering) with a particular window size, and the window size is 25 (Because the magnetic sequence between the two reference points includes 25 magnetic data.). Median average filtering is a combination of arithmetic average filtering and median filtering, whose principle is to remove a maximum value and a minimum value from the data in the window and then average the remaining data.
Data Normalization. In this paper, we adopt Min-Max normalization, which is formulated by Eq. (3), to convert the input data to the range of 0 to 1.
where \(z_{nor}\), z, \(z_{max}\) and \(z_{min}\) represent normalized data, data, maximum and minimum, respectively.
3.3 Magnetic Sequence Fingerprints Creation
The essential quality of a fingerprint is its distinguishability or uniqueness. Increasing the length of the magnetic sequence to represent a location will increase the uniqueness, but it will boost the localization time which affects the real-time performance of the positioning system. On the other hand, smaller length reduces the time but affects the fingerprint uniqueness and ultimately degrades the localization accuracy. Hence, a proper fingerprint size is very critical. We analyzed the magnetic sequences with different lengths to ensure that MSFs can reach sufficiently distinguishable and found that MSFs are distinguishable with the length of 75 (Each MSF includes 3 reference points, and each reference point contains 25 magnetic data.).
Figure 5 shows that comparison of MSFs with different lengths of 25, 50, 75, and 100 in four adjacent positions (\({P_1}, {P_2}, {P_3}, {P_4}\)). It can be observed that MSFs with the length of 25 are almost similar and make the distinction very difficult. It is clear that the MSFs of \(P_1\) and \(P_2\) become dissimilar, but the MSFs of \(P_3\) and \(P_4\) look almost identical when the length is 50. They become distinguishable with the length of 75. Therefore, we use MSFs with the length of 75 to train the CNN-LSTM model used in our study.

Comparison of MSFs with different lengths in four adjacent positions

The magnetic sequence fingerprints creation process
In this paper, we design a sliding window to cut the magnetic sequences in the same length for every position label. Figure 6 shows an example of how the MSFs creation process. In detail, the magnetic data elements value of the reference points in each sliding window are concatenated sequentially to construct a magnetic sequence, which is labelled by the location coordinates of the endpoint (see the Example in the Fig. 6). Moreover, the size of the sliding window is 75, and the sliding step is 25.
4 Positioning Model
This section clarifies our proposed positioning model. The details of model architecture, model training and model testing processes are explained.
4.1 Model Architecture
LSTM is an improved recurrent neural network (RNN), which is suited to handle time-series data and capture the long-term dependencies in the data series. LSTM not only inherits the most characteristics of RNN models but also solves the problems of exploding or vanishing gradients found in RNN [9]. However, magnetic sequence data are easily affected by the surrounding environment, resulting in noise, making it difficult for a single LSTM network to locate users accurately using the raw MSFs. Fortunately, one-dimensional convolutional neural network (1D-CNN) can be well applied to the time series analysis of sensor data (e.g., magnetometer or accelerometer data). Therefore, in our study, we propose a CNN-LSTM model, which combines the advantages of 1D-CNN and LSTM. The architecture of our proposed positioning model is shown in Fig. 7. And it is composed of three parts, the CNN part, the Deep LSTM part and the Prediction part.

The architecture of our proposed positioning model

The process of the CNN part
-
1)
CNN Part
As shown on the left side of Fig. 7, the CNN part uses a one-dimensional convolution layer with 128 filters to extract complex patterns from the inputted MSFs, followed by a ReLU activation function to add nonlinearity, and then a MaxPooling1D layer for reducing data size. Finally, the flatten layer unfolds the acquired multiple dimensional features into one dimension to be used as the input of the deep LSTM. The theory of the CNN part is formulated by Eq. (4) and the process is shown in Fig. 8.
$$\begin{aligned} \mathbf{z} _t = Maxpooling1D(ReLU(\mathbf{W} {} \mathbf{s} _t+\mathbf{b} )) \end{aligned}$$(4)where \(\mathbf{s} _t\) and \(\mathbf{z} _t\) are the input and output of the CNN part, respectively, W and b are the weight and bias vectors of the convolution layer, ReLU(\(\tiny \bullet \)) is the rectified linear unit, which is the activation function defined as
$$\begin{aligned} ReLU(x)=\left\{ \begin{array}{rcl} x &{} &{} {x > 0}\\ 0 &{} &{} {x \le 0} \end{array} \right. \end{aligned}$$(5)The ReLU(\(\tiny \bullet \)) function has the advantages of sparse representation, high gradient propagation efficiency and low computational complexity. And Maxpooling1D is the pooling operation, which leverages a max filter to filter the sub-regions of the initial feature map and takes the most obvious feature of that region, creating a new output feature map.
-
2)
Deep LSTM Part
As shown in the middle of Fig. 7, the deep LSTM part including three LSTM layers and each LSTM layer is followed by a ReLU activation function to add nonlinearity. And what needs to be explained is that each LSTM layer has 128 neurons. The key idea of LSTM is to use the forget gate to decide what information to be removed and use the input gate to determine what information to be added to the cell state. As shown in Fig. 9, the LSTM model comprises the time-series input \(x_t\), cell state \(C_t\), temporary cell state \(\widetilde{C}_t\), hidden layer state \(h_t\), forget gate \(f_t\), input gate \(i_t\), and output gate \(o_t\). The first step in LSTM is to decide what information to be thrown away from the previous cell state \(C_{t-1}\). This action is achieved by the forget gate which is formulated by
$$\begin{aligned} f_t = \sigma (\mathbf{W} _f \cdot [h_{t-1}, x_t]+\mathbf{b} _f) \end{aligned}$$(6)where \(\sigma (x) = 1 / (1+e^{-x})\) is the sigmoid function with outputs in [0,1]. Therefore, the value of \(f_t\) close to 0 means to throw away all information, while close to 1 means to retain all information. Then, we want to determine what information we would store in the cell state \(C_t\). This procedure can be done by the input gate, which is defined as
$$\begin{aligned} \begin{aligned}&i_t = \sigma (\mathbf{W} _i \cdot [h_{t-1}, x_t]+\mathbf{b} _i)\\&\widetilde{C}_t = tanh(\mathbf{W} _c \cdot [h_{t-1}, x_t]+\mathbf{b} _c) \end{aligned} \end{aligned}$$(7)where \(tanh(x)=(e^x -e^{-x})/(e^x+e^{-x})\) is the hyperbolic tangent function with outputs in [–1,1]. After that, we could calculate a new cell state \(C_t\) by
$$\begin{aligned} C_t = f_t*C_{t-1}+i_t*\widetilde{C}_t \end{aligned}$$(8)Finally, we could update the hidden layer state \(h_t\) through the output gate, which can be calculated by
$$\begin{aligned} \begin{aligned}&o_t = \sigma (\mathbf{W} _o \cdot [h_{t-1}, x_t]+\mathbf{b} _o)\\&h_t = o_t * tanh(C_t) \end{aligned} \end{aligned}$$(9)where \(\mathbf{W} \) terms denote the matrices of weights, \(\mathbf{b} \) terms denote the bias vectors.
-
3)
Prediction Part
As shown on the right side of Fig. 7, the prediction part includes one dense layer with 256 neurons, a ReLU activation function and one output layer. As shown in Fig. 10, each layer in the prediction part has a large number of neuron nodes, and each neuron node is fully connected to all nodes in the next layer. The purpose of the dense layer is to gain the relationship between the previously extracted features through nonlinear changes in the dense layer and finally map them to the output space. Therefore, the function of the prediction part is to convert the output of deep LSTM into the location coordinates of the user.

The structure of LSTM

The structure of the prediction part
4.2 Model Training
In this paper, the training on the proposed positioning model is carried out using the MSFs. In order to improve the generalization ability of the model, we divide the collected data (We collect 230 samples (Each sample includes 25 magnetic data.) for every reference point on each experimental path.) into a training dataset and a validation dataset, train the model on the training dataset and validate the model on the validation dataset, where the training dataset accounts for 90% and the validation dataset accounts for 10%. Furthermore, the model training process is divided into two steps to find the best hyperparameters of the model. First of all, the Adam optimizer is used to train the model to reduce the training loss fast so that the model converges quickly. Next, the fine-tuned SGD optimizer is used to train the model for making the model better.
4.3 Model Testing
In the online testing phase, newly collected magnetic field data (We collect 26 samples (Each sample includes 25 magnetic data.) for every reference point on each experimental path.) from a smartphone are first processed in the data preprocessing module. Then the newly MSFs are constructed and fed into the trained positioning model for testing the performance.
5 Experiments and Results
In this section, the evaluation of the proposed system is demonstrated. The experiment setup is first described. Then, we explore and evaluate the performance of the proposed indoor localization technique. Finally, we compare our presented solution with other positioning methods.
5.1 Experiment Setup
We developed an android application with Android Studio 4.0.1 on the smartphone (Mi 10 Youth, Beijing, China) for data collection. The Mi 10 Youth is equipped with an AK0991X 3-axis magnetic field sensor, and its sampling frequency are set 50 Hz throughout all the experiments.
Experiments have been conducted in three buildings of a university campus which are shown in Fig. 11(a), Fig. 11(b) and Fig. 11(c) separately. The first building is the student laboratory, whose dimensions are 8\(\times \)5 m\(^2\). The second building is the science building, 60 m long and 20 m wide, with a 2.4-m-wide corridor. And the third building is the student dormitory, whose dimensions are 75\(\times \)50 m\(^2\), and it contains an ambulatory that is approximately 1.8 m wide. What needs to be explained is that the green line represents the experimental path, and the red dot represents the reference point. And the total number of reference points in the three environments is 70, 480, and 474, respectively.

The layout of three environments
5.2 Localization Performance Exploration
The key to fingerprint-based indoor location is the identifiability of fingerprints. In this paper, we explore the influence of magnetic data elements and sequence length on the identifiability of MSFs.
Optimal Component of Magnetic Sequence Fingerprint. In this paper, we divided the magnetic data elements into three types of combinations and carried out experiments.
-
Class1: \((M_x, M_y, M_z)\)
-
Class2: \((M_y^{'}, M_z^{'}, M_{xyz})\)
-
Class3: \((M_{xy}, M_z, M_y^{'}, M_z^{'}, M_{xyz})\)
Figure 12 shows the cumulative distribution function (CDF) and mean distance error of localization errors under different types of MSF in the three experimental environments. Observing the results, we can find that the positioning performance can reach the best when the MSF is composed of five-dimensional magnetic data elements \((M_{xy}, M_z, M_y^{'}, M_z^{'}, M_{xyz})\).
There is no surprising that the MSFs composed of original three-dimensional magnetic data elements \((M_x, M_y, M_z)\) have poor positioning accuracy, because raw magnetic readings are highly orientation-dependent. Although, the MSFs composed of the transformed magnetic data elements \((M_y^{'}, M_z^{'}, M_{xyz})\) have a good feature is that independent on the orientation of the mobile phone. Unfortunately, this kind of MSF contains few features leading to low distinguishability, reducing positioning accuracy. To sum up, the MSFs composed of five-dimensional magnetic data elements \((M_{xy}, M_z, M_y^{'}, M_z^{'}, M_{xyz})\) are optimal, which are orientation-independent of the mobile phone and have high distinguishability.

Positioning performance of different types of magnetic sequence fingerprints in three experimental environments(Lab, Corridor and Ambulatory)
Optimal Length of Magnetic Sequence Fingerprint. In this section, we evaluated the influence of MSF with different lengths on positioning accuracies. We carried out experiments on MSFs with lengths of 25, 50, 75, and 100. And the mean distance errors in the three experimental environments are shown in Fig. 13. From this figure, we observe that the positioning performance increases gradually when the MSF length increases from 25 to 75 and then drops when the MSF length is greater than 75. Therefore, the best results are 0.26 m for lab, 0.64 m for corridor and 0.94 m for ambulatory when the MSF length equals to 75. Another observation is the mean positioning error degrades significantly when the MSF length is shorter. This is no surprising that since there are few magnetic field data about each MSF, leading the advantage of sequence fingerprint-based indoor positioning can be ignored. However, the mean positioning error also degrades significantly when the MSF length is relatively large. The reason may be that too much magnetic field data in each MSF, which leads to overfitting.

Positioning performance of magnetic sequence fingerprints with different lengths in three experimental environments(Lab, Corridor and Ambulatory)
5.3 Localization Performance Evaluation
In this paper, various experiments are performed to evaluate the performance of the proposed indoor localization technique with two perspectives: how different walking speeds of the user can influence the positioning performance; and the effect of device diversity on positioning performance.
Impact of User Speed. In this section, we conduct experiments on the magnetic sequences obtained at three different speeds (Normal, Slow, Fast). Figure 14 shows the results obtained by the positioning model under different walking speeds of the user in the corridor. In general, the proposed method has obtained good results in terms of the mean localization error, i.e., 0.68 m for normal speed, 0.77 m for slow speed, and 0.84 m for fast speed. And the results also reveal that the positioning performance under slow speed is slightly better than that under fast speed. The reason may be that more original magnetic field information can be read at a slow speed.

Positioning performance under different walking speeds

Positioning performance of using different smartphones
Impact of Device Diversity. In order to verify the influence of device diversity on the proposed positioning model, we exerted three different smartphones (Mi 10 Youth, Galaxy S8 and Honor V10) to obtain magnetic information on the same path in the corridor. The built-in magnetic sensors of these smartphones are shown in Table 2. And the result of Fig. 15 reveals that the effect of device diversity on positioning performance is acceptable.
5.4 Localization Performance Comparison
Based on the prediction accuracy results, we choose the best prediction model for each test environment. To obtain the positioning error, we calculate the Euclidean distance between reference points and predicted points. In order to demonstrate the utility of our proposed model, we conduct the performance comparison between our method and the existed works, such as RNN-LSTM [4] and DeepML [19].
-
(1)
The cumulative distribution function (CDF) of localization error
Fig. 16 plots the CDFs of the localization errors in the lab, corridor and ambulatory, respectively. In the lab, as shown in Fig. 16(a), in 90% case, the positioning errors of CNN-LSTM (our method) are less than 0.53 m, while RNN-LSTM and DeepML are less than 1.13 m and 2.01 m, respectively. In the corridor, as shown in Fig. 16(b), for over 80% of the test spots, the errors of our method are less than 0.8 m. However, RNN-LSTM and DeepML have errors of 1.77 m and 1.14 m under the same experimental conditions. In the ambulatory, as shown in Fig. 16(c), our scheme has a distance error of 0.88 m for 70% of the test spots in this more complex indoor environment. Meanwhile, the distance error of RNN-LSTM and DeepML is 1.02 m and 1.2 m, respectively.
-
(2)
Mean distance error
Fig. 17 gives the mean distance error obtained by the proposed algorithm CNN-LSTM (our method), RNN-LSTM [4] and DeepML [19]. As shown in the figure, in the lab, CNN-LSTM achieves the mean error of 0.26 m, which outperforms RNN-LSTM and DeepML by more than 0.35 m and 0.57 m, and the gain is about 57%, 68%, respectively. Moreover, in the corridor, the mean error of our approach is 0.64 m, which is about 47% and 59% gain than RNN-LSTM and DeepML, respectively. What’s more, in the ambulatory scenario, which is a large-scale indoor environment with a similar structure, the mean accuracy of our approach is 0.93 m, which is about 34% and 50% gain than RNN-LSTM and DeepML, respectively.

The CDFs in the different indoor environments

The comparison of mean distance error
6 Conclusion
This paper proposes an accurate indoor positioning system utilizing deep learning. It introduces a novel fingerprint representation scheme that firstly converts raw three-dimensional magnetic field signals into five-dimensional and designs a sliding window mechanism to construct MSFs. Compared with the existing positioning methods, our system designs a CNN-LSTM model, which combines the advantages of 1D-CNN and LSTM. It can also automatically learn the mapping between ground-truth positions and MSFs, which assures the achieving of high positioning accuracies. The objective of the proposed method is to improve the performance and robustness of magnetic field-based localization system. Extensive experiments are performed to evaluate the performance of the proposed approach. Results demonstrate that CNN-LSTM can localize a user within 0.9 m with an accuracy of 70% under three experimental environments, different smartphones and different user speeds. For future work, we plan to further enhance indoor positioning performance by the proposed magnetic sequence fingerprints, and enable real-time indoor magnetic-based positioning by implementing our method using cloud-edge-end cooperation architecture.
Notes
- 1.
See the help document of Android developer.http://developer.android.com/reference/packages.html..
References
Abbas, M., Elhamshary, M., Rizk, H., Torki, M., Youssef, M.: Wideep: Wifi-based accurate and robust indoor localization system using deep learning. In: 2019 IEEE International Conference on Pervasive Computing and Communications, PerCom, Kyoto, Japan, 11–15 March 2019, pp. 1–10. IEEE (2019). https://doi.org/10.1109/PERCOM.2019.8767421
Ashraf, I., Kang, M., Hur, S., Park, Y.: MINLOC: magnetic field patterns-based indoor localization using convolutional neural networks. IEEE Access 8, 66213–66227 (2020). https://doi.org/10.1109/ACCESS.2020.2985384
Chen, Y., Zhou, M., Zheng, Z.: Learning sequence-based fingerprint for magnetic indoor positioning system. IEEE Access 7, 163231–163244 (2019). https://doi.org/10.1109/ACCESS.2019.2952564
Chiang, T.H., Sun, Z.H., Shiu, H.R., Lin, K.C.J., Tseng, Y.C.: Magnetic field-based localization in factories using neural network with robotic sampling. IEEE Sensors J. 20(21), 13110–13118 (2020). https://doi.org/10.1109/JSEN.2020.3003404
Chung, J., Donahoe, M., Schmandt, C., Kim, I., Razavai, P., Wiseman, M.: Indoor location sensing using geo-magnetism. In: Agrawala, A.K., Corner, M.D., Wetherall, D. (eds.) Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services (MobiSys 2011), Bethesda, MD, USA, 28 June–01 July 2011, pp. 141–154. ACM (2011). https://doi.org/10.1145/1999995.2000010
Frassl, M., Angermann, M., Lichtenstern, M., Robertson, P., Julian, B.J., Doniec, M.: Magnetic maps of indoor environments for precise localization of legged and non-legged locomotion. In: 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013, pp. 913–920. IEEE (2013). https://doi.org/10.1109/IROS.2013.6696459
Galván-Tejada, C.E., García-Vázquez, J., Brena, R.F.: Magnetic field feature extraction and selection for indoor location estimation. Sensors 14(6), 11001–11015 (2014). https://doi.org/10.3390/s140611001
Grand, E.L., Thrun, S.: 3-axis magnetic field mapping and fusion for indoor localization. In: IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, MFI 2012, Hamburg, Germany, 13–15 September 2012, pp. 358–364. IEEE (2012). https://doi.org/10.1109/MFI.2012.6343024
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997). https://doi.org/10.1162/neco.1997.9.8.1735
Lee, N., Ahn, S., Han, D.: AMID: accurate magnetic indoor localization using deep learning. Sensors 18(5), 1598 (2018). https://doi.org/10.3390/s18051598
Li, T., Wang, H., Shao, Y., Niu, Q.: Channel state information-based multi-level fingerprinting for indoor localization with deep learning. Int. J. Distrib. Sens. Netw. 14(10) (2018). https://doi.org/10.1177/1550147718806719
Pusnik, M., Galun, M., Sumak, B.: Improved bluetooth low energy sensor detection for indoor localization services. Sensors 20(8), 2336 (2020). https://doi.org/10.3390/s20082336
Shao, W., et al.: Location fingerprint extraction for magnetic field magnitude based indoor positioning. J. Sensors 2016, 1945695:1–1945695:16 (2016). https://doi.org/10.1155/2016/1945695
Suksakulchai, S., Thongchai, S., Wilkes, D.M., Kawamura, K.: Mobile robot localization using an electronic compass for corridor environment. In: Proceedings of the IEEE International Conference on Systems, Man & Cybernetics: “Cybernetics Evolving to Systems, Humans, Organizations, and their Complex Interactions”, Sheraton Music City Hotel, Nashville, Tennessee, USA, 8–11 October 2000, pp. 3354–3359. IEEE (2000). https://doi.org/10.1109/ICSMC.2000.886523
Wang, R., Li, Z., Luo, H., Zhao, F., Shao, W., Wang, Q.: A robust wi-fi fingerprint positioning algorithm using stacked denoising autoencoder and multi-layer perceptron. Remote Sens. 11(11), 1293 (2019). https://doi.org/10.3390/rs11111293
Wang, X., Gao, L., Mao, S., Pandey, S.: Deepfi: deep learning for indoor fingerprinting using channel state information. In: 2015 IEEE Wireless Communications and Networking Conference, WCNC 2015, New Orleans, LA, USA, 9–12 March 2015, pp. 1666–1671. IEEE (2015). https://doi.org/10.1109/WCNC.2015.7127718
Wang, X., Wang, X., Mao, S.: Cifi: deep convolutional neural networks for indoor localization with 5 ghz wi-fi. In: 2017 IEEE International Conference on Communications (ICC), pp. 1–6 (2017). https://doi.org/10.1109/ICC.2017.7997235
Wang, X., Wang, X., Mao, S.: RF sensing in the internet of things: a general deep learning framework. IEEE Commun. Mag. 56(9), 62–67 (2018). https://doi.org/10.1109/MCOM.2018.1701277
Wang, X., Yu, Z., Mao, S.: Indoor localization using smartphone magnetic and light sensors: a deep LSTM approach. Mob. Netw. Appl. 25(2), 819–832 (2020). https://doi.org/10.1007/s11036-019-01302-x
Xiao, C., Yang, D., Chen, Z., Tan, G.: 3-D BLE indoor localization based on denoising autoencoder. IEEE Access 5, 12751–12760 (2017). https://doi.org/10.1109/ACCESS.2017.2720164
Acknowledgement
This work is supported by the National Key Research and Development Program of China (2020YFB2104202).
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Springer Nature Switzerland AG
About this paper

Cite this paper
Ding, X., Zhu, M., Xiao, B. (2022). Accurate Indoor Localization Using Magnetic Sequence Fingerprints with Deep Learning. In: Lai, Y., Wang, T., Jiang, M., Xu, G., Liang, W., Castiglione, A. (eds) Algorithms and Architectures for Parallel Processing. ICA3PP 2021. Lecture Notes in Computer Science(), vol 13155. Springer, Cham. https://doi.org/10.1007/978-3-030-95384-3_5
Download citation
DOI: https://doi.org/10.1007/978-3-030-95384-3_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-95383-6
Online ISBN: 978-3-030-95384-3
eBook Packages: Computer ScienceComputer Science (R0)