
Abstract
The need for audio compression is still a vital issue, because of its significance in reducing the data size of one of the most common digital media that is exchanged between distant parties. In this paper, the efficiencies of two audio compression modules were investigated; the first module is based on discrete cosine transform and the second module is based on discrete wavelet transform. The proposed audio compression system consists of the following steps: (1) load digital audio data, (2) transformation (i.e., using bi-orthogonal wavelet or discrete cosine transform) to decompose the audio signal, (3) quantization (depend on the used transform), (4) quantization of the quantized data that separated into two sequence vectors; runs and non-zeroes decomposition to apply the run length to reduce the long-run sequence. Each resulted vector is passed into the entropy encoder technique to implement a compression process. In this paper, two entropy encoders are used; the first one is the lossless compression method LZW and the second one is an advanced version for the traditional shift coding method called the double shift coding method. The proposed system performance is analyzed using distinct audio samples of different sizes and characteristics with various audio signal parameters. The performance of the compression system is evaluated using Peak Signal to Noise Ratio and Compression Ratio. The outcomes of audio samples show that the system is simple, fast and it causes better compression gain. The results show that the DSC encoding time is less than the LZW encoding time.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Modern operating systems support a native format for audio files because digital audio has become as significant as digital images and videos [1]. The speech compression process converts input speech data stream into a smaller size data stream, by removing inherent redundancy related to speech signals. The compression mechanism reduces the overall program execution time and storage area of the processor [2]. The principle objective within the audio coding process is to demonstrate the audio signal with a minimum range of bits by implementing transparent signal reproduction and producing output audio that can't be recognized from the initial signal [3]. DCT and DWT techniques are usually utilized on the speech signal. The DCT is used for data compression because in this technique the rebuilding of the audio signal can be done very accurately [4], while DWT is very appropriate for speech compression because of the localization feature of wavelet along with the time-frequency resolution property [5]. There are many mechanisms with different amounts of performance that have been applied in the last few years. Drweesh and George [6] employed the biorthogonal tab 9/7 to design a perfect and low complexity audio compression scheme. The suggested system is composed of the audio data normalization, wavelet transform, quantization, adjusted run-length encoding, and high order shift encoder. In decoding processes, the last operation is to decrease the impact of quantization noise through the post-processing filtering process. Usually, this noise is distinguished at the low energetic parts of the audio signal. The outcomes showed that the promising compression system and the CR are expanded with the increment in the number of passes (Npass) in the wavelet. The post-processing step has encouraging results by improving the quality of the recreated audio file signal and enhancement of the fidelity level of the recreated audio signal when PSNR is under 38 Db. Romano et al. [7] used biorthogonal wavelet filters to design a new method for analyzing and compressing speech signals. The thresholding methods are applied to remove some unnecessary details of the signal, then acquiring a lossy compression that makes notably reduces the audio bit-stream length, without the distortion of the quality of the resulting sound. A comparison was made between this innovative compression method with a typical VoIP encoding of the human voice, confirming how using wavelet filters may be suitable, especially in CR without making a significant weakness in audio signal quality for listeners. Salau [8] used DCT with temporal auditory masking (TAM) to perform an algorithm for the compression of audio signals. The outcomes illustrated that the suggested algorithm gives a CR of 4:1 of the original signal. This was assisted by the recording device's negligence of background noise. Ahmed et al. [9] suggested an audio compression system that depends on a combined transform coding system; the bi-orthogonal transform to analyze the input audio signal file into low sub-band and many high sub-bands, the DCT applied to these sub-bands, the progressive hierarchical quantization performed to result of the combined transform stage, then traditional run-length encoding, and lastly, LZW algorithm applied to produce the results. The results show the good performance of this system and the output compression results appear a wonderful reduction in audio file size with good PSNR.
An audio compression problem is to detect an effective, fast and functional method to remove various redundancies between data of the audio file. So, the research work aims to develop a system for compression audio using both Wavelet and DCT transform. The target “better compression with good fidelity” has been taken into consideration during the design phase. The main contributions of this system are: (1) Two entropy encoder is given: LZW and develop version of shift coding called DSC, (2) Applies run-length encoding depend on zeros and runs in audio sequences, (3) Comparison between wavelet and DCT with two entropy encoder, and (4) Comparison in encoding and decoding time between two entropy encoder.
2 The Proposed Methodology
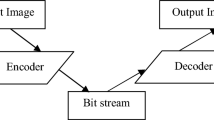
The proposed audio compression system contains many stages; detail of these stages is described in the following subsections (as shown in Fig. 1).
2.1 Audio Data Loading
The audio file is loaded for obtaining the basic file information description signal detailing through viewing the header data. The header data has the sample numbers, channel numbers, and the resolution of sampling. Thereafter in an array, these audio sample data are stored, then the equation [1] is used to normalize to the range [–1, 1]:

The layout of the proposed system
2.2 Transform Technique
Transform coding is the process that transforms the signal from its spatial domain to various representations often to the frequency domain [10]. It is used to provide a result with a new set of smaller values data. In this audio compression system, it was implemented one of two ways of transform coding; the bi-orthogonal (tap-9/7) wavelet transform, and the DCT.
Bi-orthogonal Wavelet Transform (Tap 9/7).
The bi-orthogonal wavelet transform is performing by applying a lifting scheme after applying the scaling scheme. The lifting step is consisting of a sequence of phases and is characterized into three phases: Split phase, Predict phase, and Update phase [11].
DCT (Discrete Cosine Transform).
The signal is partitioned into non-overlapping blocks in DCT, and then each block is handled separately and transformed into AC and DC coefficients in the frequency domain [12]. The following equations applied this process [13]:
Where u = 0.., Num–1 and C (u) appointed to the uth coefficient of the DCT, and A () appointed to a set of Num audio input data values.
2.3 Quantization
It is the process that rounding floating-point numbers to integers and thus in the coding process, fewer bits are necessary to store the transformed coding coefficients [14]. The main goal of this process is to make high-frequency coefficients to zero by reducing most of the less important of these coefficients [15]. Every element in the DCT array is quantized, this process is done by dividing the coefficients of each block by its quantization step (QS). The equation [4, 5] is to implement the quantization process:
Where the Qs are used to quantize the coefficients and calculated by the following equations:
The produced wavelet detailed and approximate coefficients in each subband are quantized using progressive scalar quantization where this quantization acts by performing quantization in a hierarchal shape. In the wavelet transform, every pass is quantized with various scales beginning with large quantization scales, and when the number of passes increases then quantization scales decrease drastically. The used equation for uniform quantization is [6]:
Where, Q = Qlow; Qhigh(n) when the quantization is applied on approximation subband and nth high subband, Wave(i) is the input coefficient of the wavelet transform, Waveletq(i) is the corresponding quantization wavelet. For detail subbands, the quantization step is:
Where β is the rate of increase of the applied quantization step.
2.4 Run-Length
It is a simple form of lossless compression [16]. It is composed of outputting the lengths of the sequences with successive repetitions of a character in the input and is usually applied to compress binary sequences [17]. The steps for applying the run-length are:
-
1.
Take the non-zero values and put them in a new vector in the sequence called a non-zero sequence.
-
2.
Replace the original location of non-zero values in the input sequence with ones and make the zeros values and ones values in the array and then set it in a new different vector called Binary Sequence.
-
3.
For the series of zeros and ones, run-length encoding is utilized
-
4.
Just the non-zero sequences and their length are encoded and stored.
The following example illustrates the process:
-
Input Sequence = {3, 7, –3, 0, 1, 2, 0, 0, 0, 0, –1, 2, 4, 1, 0, 0, 0, 0, 0, 0, 1, –2, 0, 0, 0, 0, 0, 0}.
-
Non-Zero Sequence = {3, 7, –3, 1, 2, –1, 2, 4, 1, 1, –2}.
-
Binary Sequence = {1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0}.
-
Run Length = {1, 3, 1, 2, 4, 4, 6, 2, 6}.
-
1 = because the start element is not zero.
2.5 Entropy Encoder
The lossless compression is applied as the last step of the proposed audio compression to save the quantized coefficients as the compressed audio. In this paper, one of the two coding schemes has been utilized to compress the audio data; the first one is LZW coding, and the second one is Double Shift Coding (DSC).
Lempel-Ziv-Welch (LZW).
LZW is a popular data compression method. The basic steps for this coding method are; firstly the file is read and the code is given to all characters. It will not allocate the new code when the same character is located in the file and utilize the existing code from a dictionary. This operation is continued until the end of the file [18]. In this coding technique, a table of strings is made for the data that is compressed. During compression and decompression, the table is created at the same time as the data is encoded and decoded [19].
Double Shift Coding (DSC).
The double shift is an enhanced version for the traditional shift coding (that based on using two code words, the smallest code word is for encoding the most redundant set of small numbers (symbols), and the second codeword, which is usually longer, is for encoding other less redundant symbols). The double shift encoding is used to overcome the performance shortage due to encoding the set of symbols that have histograms with very long tails. The involved steps of shift encoding are dividing the symbols into three sets; the first one consists of a small set of the most redundant symbols, and the other two longs less redundant sets are encoded firstly by long code then they categorized into two sets by one leading shift bit {0,1}. The applied steps for implementing the enhanced double shift coding consist of the following steps (the first two steps are pre-processing steps to adjust the stream of symbols and making it more suitable for double shift coding):
Delta Modulation.
The primary task of delta modulation is to remove the local redundancy existent between the inter-samples correlation. The existence of local redundancy leads to the range in the sample values being large and the range will be smaller when it is removed. The difference between every two neighboring pixels is calculating using the following equation:
Where x = 1… Size of the data array.
Mapping to Positive and Calculate the Histogram.
The mapping process is necessary to remove the negative sign from values and to reduce difficulties in the coding process when storing these numbers. This is a simple process performed by the negative numbers are represented to be positive odd numbers while the positive numbers are represented to be even numbers. The mapping process is implemented by performing the following equation [20]:
Finally, the histogram of the output sequence and maximum value in the sequence are calculated.
Coding Optimizer.
This step is used to define the length of the optimal three code words used to encode the input stream of symbols. The optimizer uses the histogram of symbols, the search for the optimal bits required to get fewer numbers of bits for encoding the whole stream of symbols. The equation of determining the total numbers of bits are:
Where, (n1, n2, n3) are integer values bounded the maximum symbol value (Max); such that:
According to the objective function of total bits (equation *), a fast search for the optimal values of (n1, n2) is conducted to get the least possible values for total bits.
Shift Encoder.
Finally, the double shift encoder is applied as an entropy encoder due to the following reasons:
-
This technique is characterized by simplicity and efficiency in both the encoding and decoding stages.
-
In the decoding process, the size of its corresponding overhead information that is needed is small.
-
It is one of the simple types that belong to Variable Length Coding (VLC) schemes. In the VLC methods, short codewords are assigned to symbols that have a higher probability.
-
In this coding technique, the statistical redundancies are exploiting to improve attained compression efficiency.
The compression audio file can be rebuilt to make the original audio signal. This process is done by loading the overhead information and the audio component values which are stored in a binary file and, then, performing in reverse order the same stages that are applied in the encoding stage. Figure 1b explained the main steps of the decoding process.
3 Results and Discussion
A set of eight audio files have been conducted to test, determine and evaluate the suggested system performance. The features of these files are shown in Table 1. The waveform patterns of these audio samples show in Fig. 2. The performance of the suggested audio compression system was studied using several parameters. All audio samples are evaluated by two schemes; the first scheme illustrates the results of compression when the LZW method is applied and the second scheme illustrates the results of compression when the DSC method is applied. The test results are assessed and compared depend on PSNR and CR. Also, the real-time encoding and decoding process was assessed. The CR, MSE (Mean Square Error), and PSNR are defined as follows [21]:
Where, i (k) is the value of the input audio data, j(k) is the value of the reconstructed audio file, S represents the number of the audio samples, and the dynamic range of the audio file is 255 when 8-bits sample resolution, and equal to 65535 for 16-bits sample resolution.
The control parameters impacts have been explored to analyze the results of the proposed system:
-
NPass is the pass number in wavelet transform.
-
Blk is the block size in DCT.
-
Q0, Q1, and α are the quantization control parameters.
-
The sampling rate is how many times per second a sound is sampled.
-
Sampling resolution is the number of bits per sample.
The range of the control parameters appears in Table 2, while the supposed default values of these control parameters appear in Table 3. The default values are specified by making a complete set of tests then selecting the best setup of parameters. Each parameter is tested by changing its value while setting other parameters constant at their default values. Figure 3a displays the effect of Npass on CR and PSNR. The choice Npass equal to 2 is recommended because it leads to the best results. Figures 3b and 4) display the effects of Blk, Q0, Q1, and α on PSNR and CR on the system performance for audio test samples, the increase of these parameters leads to an increase in the attained CR while decreasing the fidelity level. Figure 5 displays the effect of sampling rate on PSNR and CR, the outcomes specified that the 44100 sampling rate obtains higher CR while the lower sampling rate cases obtain lower CR. Figure 6 displays the effect of sampling resolution on the performance of the system. The outcomes specified that the sampling resolution has a significant impact and the 16-bit sampling resolution displays the best results. Figure 7 displays the effect of run-length on the coding system; it gives the best result in compression and fidelity. For comparison purposes, Fig. 8 displays the attained relationship (i.e., PSNR versus CR) for the DCT method and the wavelet method. The DCT method outperforms the performance of the wavelet method. Table 4 displays the comparison between LZW and DSC on encoding and decoding time. So, the time of the DSC method is the same or less than the time of the LZW method in the case of encoding or decoding.

The waveform of the tested wave files

The effect of Npass in (Wavelet) and Blk (in DCT) on the relation between PSNR and CR

The effect of (Q0), (Q1) and (α), on the relation between PSNR and CR

The effect of sampling rate on the relation between PSNR and CR

The effect of sampling resolution on the relation between PSNR and CR

The effect of run-length on the compression results

A comparison between the results of DCT and Wavelet audio compression methods
4 Comparisons with Previous Studies
It is difficult to make a comparison between the results of sound pressure, due to the lack of the same samples used in those researches, since they are not standardized and each research used samples different from others in other research. Because of that, a comparison was made between the results of the same audio file (test 5) used in a previous search [9], and the results showed in Table 5 a very good CR and PSNR.
5 Conclusion
From the conducted test results on the proposed audio compression system, the compression method achieved good results in terms of CR and PSNR. The increase in the quantization step (i.e.; Q0, Q1, and α) and block size (Blk) lead to an increment in the attend CR while a decrease in the PSNR fidelity value. DCT compression is better than bi-orthogonal wavelet transform in terms of CR and PSNR. The use of run-length displays a significant improvement in CR. DSC compression method showed excellent results for CR and very close to the LZW compression method at the same PSNR. When the proposed DSC technique is applied, the encoding and decoding time has been reduced compared to the LZW technique.
As a future suggestion additional enhancements can be made to the proposed entropy encoder system to increase the CR. Also, another coding technique such as Arithmetic Coding can be performed to determine the performance of the proposed encoder system.
References
Raut, R., Sawant, R., Madbushi, S.: Cognitive Radio Basic Concepts Mathematical Modeling and Applications, 1st edn. CRC Press, Boca Raton (2020)
Gunjal, S.D., Raut, R.D.: Advance source coding techniques for audio/speech signal: a survey. Int. J. Comput. Technol. App. 3(4), 1335–1342 (2012)
Spanias, A., Painter, T., Atti, V.: Audio Signal Processing and Coding. Wiley, USA (2007)
Rao, P.S., Krishnaveni, G., Kumar, G.P., Satyanandam, G., Parimala, C., Ramteja, K.: Speech compression using wavelets. Int. J. Mod. Eng. Res. 4(4), 32–39 (2014)
James, J., Thomas, V.J.: Audio compression using DCT and DWT techniques. J. Inf. Eng. App. 4(4), 119–124 (2014)
Drweesh, Z.T., George, L.E.: Audio compression using biorthogonal wavelet, modified run length, high shift encoding. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 4(8), 63–73 (2014)
Romano, N., Scivoletto, A., Połap, D.: A real-time audio compression technique based on fast wavelet filtering and encoding. In: Proceedings of the Federated Conference on Computer Science and Information Systems, IEEE, vol. 8, pp. 497–502, Poland (2016)
Salau, A.O., Oluwafemi, I., Faleye, K.F., Jain, S.: Audio compression using a modified discrete cosine transform with temporal auditory masking. In: International Conference on Signal Processing and Communication (ICSC), IEEE, pp. 135–142, India (March 2019)
Ahmed, Z.J., George, L.E., Hadi, R.A.: Audio compression using transforms and high order entropy encoding. Int. J. Elect. Comput. Eng. (IJECE) 11(4), 3459–3469 (2021)
Varma, V.Y., Prasad, T.N., Kumar, N.V.P.S.: Image compression methods based on transform coding and fractal coding. Int. J. Eng. Sci. Res. Technol. 6(10), 481–487 (2017)
Kadim, A.K., Babiker, A.: Enhanced data reduction for still images by using hybrid compression technique. Int. J. Sci. Res. 7(12), 599–606 (2018)
Tsai1, S.E., Yang, S.M.: A fast DCT algorithm for watermarking in digital signal processor. Hindawi. Math. Probl. Eng. 2017, 1–7 (2019)
Ahmed, N., Natarajan, T., Rao, K.R.: Discrete cosine transform. IEEE Trans. Comput. C–23(1), 90–93 (1974)
Tiwari, P.K., Devi, B., Kumar, Y.: Compression of MRT Images Using Daubechies 9/7 and Thresholding Technique. In: International Conference on Computing, Communication and Automation, IEEE, pp. 1060–1066, India (2015)
Raid, A.M., Khedr, W.M., El-dosuky, M.A., Ahmed, W.: JPEG image compression using discrete cosine transform - a survey. Int. J. Comput. Sci. Eng. Surv. 5(2), 39–47 (2014)
Hardi, S.M., Angga, B., Lydia, M.S., Jaya, I., Tarigan, J.T.: Comparative analysis run-length encoding algorithm and fibonacci code algorithm on image compression. Journal of Physics: Conference Series. In: 3rd International Conference on Computing and Applied Informatics, 1235, pp.1–6, Indonesia, September 2018
Agulhar, C.M., Bonatti, I.S., Peres, P.L.D.: An adaptive run length encoding method for the compression of electrocardiograms. Med. Eng. Phys. 35(2013), 145–153 (2010)
Kavitha, P.: A survey on lossless and Lossy data compression methods. Int. J. Comput. Sci. Eng. Technol. 7(3), 110–114 (2016)
Btoush, M.H., Dawahdeh, Z.E.: A complexity analysis and entropy for different data compression algorithms on text files. J. Comput. Commun. 6(1), 301–315 (2018)
Ahmed, S.D., George, L.E., Dhannoon, B.N.: The use of cubic Bezier interpolation, biorthogonal wavelet and quadtree coding to compress colour images. Br. J. Appl. Sci. Technol. 11(4), 1–11 (2015)
Salomon, D., Motta, G.: Handbook of Data Compression, 5th edn. Springer, London (2010)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Ahmed, Z.J., George, L.E. (2021). Audio Compression Using Transform Coding with LZW and Double Shift Coding. In: Al-Bakry, A.M., et al. New Trends in Information and Communications Technology Applications. NTICT 2021. Communications in Computer and Information Science, vol 1511. Springer, Cham. https://doi.org/10.1007/978-3-030-93417-0_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-93417-0_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-93416-3
Online ISBN: 978-3-030-93417-0
eBook Packages: Computer ScienceComputer Science (R0)