
Abstract
With the advancement of modern technologies, the human-machine interaction conveyed towards a more natural means of communication. The frequent example used in the devices is speech, where an Automatic Speech Recognition (ASR) system is prominent to convert the uttered word to text. In this paper, we focus on the acoustic model which translate the relationship between the acoustic features and the phonemes to a probability distribution. To directly output the spoken phonemes from the input features, we introduce an End-to-End acoustic model. The proposed model is built with the combination of the one-dimensional Convolutional Neural Networks (1D CNNs) and Bidirectional Long Short-Term Memory (BLSTM) while using Focal Connectionist Temporal Classification (CTC) loss in the training phase. Experimental results show that the proposed acoustic model reaches up to 20.3% in terms of Phone Error Rate (PER).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

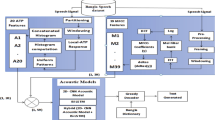
References
Ghahramani, Z.: An introduction to hidden Markov models and Bayesian networks. IJPRAI 15, 9–42 (2001)
Deng, L., et al.: Phonemic hidden Markov models with continuous mixture output densities for large vocabulary word recognition. IEEE Trans. Signal Process. 39, 1677–1681 (1991)
Hinton, G.E., Osindero, S., Teh, Y.W.: A fast learning algorithm for deep belief nets. Neural Comput. 18, 1527–1554 (2006)
Palaz, D., Magimai-Doss, M., Collobert, R.: Analysis of CNN-based speech recognition system using raw speech as input. In: INTERSPEECH 2015, 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015, (ISCA 2015), pp. 11–15 (2015)
Maas, A.L., et al.: Recurrent neural networks for noise reduction in robust ASR. In: INTERSPEECH 2012, 13th Annual Conference of the International Speech Communication Association, Portland, Oregon, USA, 9–13 September 2012, (ISCA 2012), pp. 22–25 (2012)
Sak, H., Senior, A.W., Beaufays, F.: Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In: Li, H., Meng, H.M., Ma, B., Chng, E., Xie, L. (eds.) INTERSPEECH 2014, 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014, (ISCA 2014), pp. 338–342 (2014)
Graves, A., Fernández, S., Gomez, F., Schmidhuber, J.: Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In: Proceedings of the 23rd International Conference on Machine Learning, pp. 369–376 (2006)
Huang, D., Fei-Fei, L., Niebles, J.C.: Connectionist temporal modeling for weakly supervised action labeling. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 137–153. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_9
Feng, X., Yao, H., Zhang, S.: Focal CTC loss for Chinese optical character recognition on unbalanced datasets. Complexity 2019, 9345861:1–9345861:11 (2019)
Nair, V., Hinton, G.E.: Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning (ICML 2010), pp. 807–814 (2010)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Bach, F.R., Blei, D.M. (eds.) Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015, vol. 37, pp. 448– 456. JMLR.org (2015)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014)
Ranzato, M., Huang, F.J., Boureau, Y.-L., LeCun, Y.: Unsupervised learning of invariant feature hierarchies with applications to object recognition. In: 2007 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8 (2007)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9, 1735–1780 (1997)
Fernández, S., Graves, A., Schmidhuber, J.: Phoneme recognition in TIMIT with BLSTM-CTC. CoRR abs/0804.3269 (2008)
Garofolo, J.S., Lamel, L.F., Fisher, W.M., Fiscus, J.G., Pallett, D.S.: DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon technical report n 93 (1993)
Lee, K.-F., Hon, H.-W.: Speaker-independent phone recognition using hidden Markov models. IEEE Trans. Acoust. Speech Signal Process. 37, 1641–1648 (1989)
Luo, Y., Chiu, C., Jaitly, N., Sutskever, I.: Learning online alignments with continuous rewards policy gradient. In: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 March 2017, pp. 2801–2805. IEEE (2017)
Raffel, C., Luong, M.-T., Liu, P.J., Weiss, R.J., Eck, D.: Online and linear-time attention by enforcing monotonic alignments. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 2837–2846 (2017)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
El Fatehy, F.Z., Khalil, M., Adib, A. (2022). End-to-End Acoustic Model Using 1D CNN and BLSTM Networks with Focal CTC Loss. In: Kacprzyk, J., Balas, V.E., Ezziyyani, M. (eds) Advanced Intelligent Systems for Sustainable Development (AI2SD’2020). AI2SD 2020. Advances in Intelligent Systems and Computing, vol 1417. Springer, Cham. https://doi.org/10.1007/978-3-030-90633-7_49
Download citation
DOI: https://doi.org/10.1007/978-3-030-90633-7_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-90632-0
Online ISBN: 978-3-030-90633-7
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)