
Abstract
Energy management has become the main focus of researchers to propose efficient strategies to use available resources and reduce CO2 emissions, thus preserving the environment and creating smarter cities. One of the most efficient energy management tools in this sector is non-intrusive load monitoring (NILM). NILM aims to extract the power consumption of each appliance from the given total consumption through purely analytical methods. This information about the appliances can be sent as feedback to the consumers, which increases their knowledge about their consumption behavior and helps them make the right decisions to reduce their consumption and cost while maintaining their comfort. In this chapter, we present the basic concepts about NILM, various algorithms that have been explored to develop more practical and accurate NILM techniques and their challenges. Finally, we illustrate the application of NILM in determining the energy flexibility potential of each consumer.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others



Keywords
- Demand-side management
- Energy management
- Energy flexibility
- Residential sector
- Load monitoring
- Intrusive load monitoring
- Semi-intrusive load monitoring
- Non-intrusive load monitoring
- Optimization
- Supervised methods
- Unsupervised methods
- Classification
- Clustering
- Sample-based methods
- Event-based methods
- AMPds dataset
13.1 Introduction
The ever-increasing energy consumption in the residential sector as shown in Fig. 13.1 is of great importance in terms of carbon emissions, global warming, and sustainability issues. Due to the fact that residential demand accounts for 30% of the total demand (Li & Dick, 2018), increasing the role of residential buildings in the power grid from passive consumers to active ones (Clarke, 2021) plays a crucial role in addressing the aforementioned issues. Numerous studies in the area of building energy confirm that reducing energy consumption in buildings requires effective and efficient residential energy management (REM) (Faustine et al., 2020). Therefore, the concepts of residential demand-side management (RDSM) and home energy management (HEM) appear and take an important place in the research and development efforts of science and industry.

Total primary energy consumption for building in the USA (Hafemeister, 2009)
RDMS aims to shape customers’ consumption patterns to enable more efficient use of energy system resources, improve grid reliability, and reduce emissions by peak-shaving and valley-filling, which results in increasing the second-by-second balance between demand and generation. In this regard, one of the main goals of the active buildings is proposing a cost-efficient way of minimizing energy demand of buildings (Wang et al., 2017). The implementation and success of such programs depend on advanced knowledge of characteristics of loads and the usage pattern of consumers. Therefore, modelling and predicting these factors could be an important support for RDSM and HEM (Zoha et al., 2012).
In this trend, researchers and industry have worked over the last decades to obtain information on household consumption. This information is beneficial for both the supplier and the consumer (Devlin & Hayes, 2019). The utility company can use this information to propose different energy management strategies or for control purposes. Consumers can use this information to identify appliances with high electricity consumption and faulty or inefficient appliances. They can also control their consumption to reduce their costs while ensuring their comfort based on this information. Overall, this information can reduce consumption by more than 9% (Aydin et al., 2018; Darby et al., 2006).
Monitoring the consumption of each appliance which is entitled as load monitoring (LM) is one of the useful methods to extract this information (Zhou et al., 2020). Figure 13.2 illustrates the benefits of LM algorithms for consumers and the utility. As it is mentioned in Fig. 13.2, LM provides an opportunity to the utility to extract and characterize the energy flexibility potential of each consumer. Furthermore, studies show that the active building concept is associated more with energy flexibility than self-generation of electricity (Bulut et al., 2016). Therefore, extracting the flexibility via LM plays a crucial role in the efficiency of active buildings.

LM benefits to consumers and grid
In the first phase of this chapter, fundamental concepts of load monitoring will be discussed. Then, its application in flexibility extraction of residential buildings will be shown. The schematic of this technique is illustrated in Fig. 13.3.

The framework of this study
13.2 Different Types of Load Monitoring
Load monitoring algorithms based on the number of meters and appliances can be categorized into three main groups which will be discussed below.
13.2.1 Intrusive Load Monitoring
The simplest and most accurate approach to obtain the consumption pattern of appliances is to install a meter on each of them to measure, record, and report their consumption which is called intrusive load monitoring (ILM) (Azizi et al., 2020). Figure 13.4c shows the schematic of ILM. However, this approach causes the following concerns:
-
1.
Installing a meter on each appliance is time-consuming (Liu et al., 2019).
-
2.
It incurs high costs to the consumer and the utility due to the need for additional meters, cables, etc. (Liu et al., 2019).
-
3.
This approach causes privacy concerns and most consumers are unwilling to take the risk of this approach (Erkin et al., 2013).

Different types of load monitoring, (a) NILM, (b) SILM, (c) ILM
Therefore, non-intrusive load monitoring attracts a lot of attention in recent years.
13.2.2 Non-intrusive Load Monitoring
Rather than installing a meter on each appliance individually and measuring its consumption intrusively, Hart proposed non-intrusive load monitoring (NILM) in 1992 (Hart, 1992). The NILM technique aims to obtain the consumption pattern of each appliance by analysing and disaggregating a given aggregate signal measured by existing meters using purely analytical approaches. The schematic of this technique is illustrated in Fig. 13.4a. However, its accuracy is lower than ILM methods. The concept of semi-intrusive load monitoring (SILM) emerged in this field which is the trade-off between cost and accuracy.
13.2.3 Semi-intrusive Load Monitoring
In the semi-intrusive load monitoring (SILM) technique, the set of appliances are divided into some subgroups, and a meter is installed in each subgroup to measure and record the aggregated consumption signal of appliances. Then, the disaggregation approach is applied to each subgroup, separately (Dash et al., 2019). The schematic of this approach is illustrated in Fig. 13.4b. In comparison with ILM methods, SILM reduces the cost and in comparison with NILM increases the accuracy of load disaggregation. The main challenge of these approaches is obtaining a proper number of subgroups based on the consumer’s willingness to pay the cost of meters, the infrastructure of the building, and number of appliances.
Due to the fact that NILM does not interfere with the existing building infrastructure, omits the requirement of costly sub-metering, and saves time and protects consumer’s privacy, it is more practical and is preferred from different viewpoints (Zhang et al., 2019). Therefore, in this chapter, the basic concepts of this technique will be discussed.
13.3 NILM Problem Statement
Non-intrusive load monitoring is a well-known problem that involves disaggregating the total electrical energy consumption of a building into its individual electrical load components without the need for extensive metering equipment at each appliance. This problem can be classified as a blind identification problem, Abed-Meraim et al. (1997) where given the observed output of the entire system (i.e. the household total power consumption), the unobserved sub-states (i.e. the electricity consumption of individual appliances) are to be estimated. The schematic of NILM is shown in Fig. 13.5. Mathematically, NILM can be formulated as an optimization problem and a learning-based problem, which are described below.

Appliances’ consumption extraction based on NILM (Esa et al., 2016)
13.3.1 Optimization-Based Formulation
NILM algorithms aim to extract the consumption signal of each appliance from the aggregated consumption signal of each consumer, herein denoted by P(t). Considering {1, 2, …, N} as the dataset of appliances, and N the total number of appliances, P(t) is sum of the consumption signal of each appliance, P i(t) as (13.1).
However, each appliance i, 1 ≤ i ≤ N, has m i operating modes. Due to the presence of noise, fluctuations, overshoots, and spikes, the power value in these operating modes is not fixed in practice. However, by ignoring them and considering fixed values for mode j of appliance i, denoted as x ij, the estimated piecewise constant consumption power of appliance i, \(\tilde {P}_i(t)\) is obtained as (Piga et al., 2016)
where element j of the vector X i shows the fixed consumption of mode j of appliance i. \(\varTheta _i=\begin {bmatrix}\theta _{i1} & \dots & \theta _{im_i}\end {bmatrix}^T\)is a binary-valued vector indicating the operating mode of appliance i at time t, defined as
In other words, Θ i(t) is a binary-valued vector indicating the mode of appliance i at time t that satisfies
We note that the condition (13.4) guarantees that an appliance cannot operate in two modes simultaneously.
NILM method aims to obtain the consumption signal of each appliance, \(\tilde {P}_i(t)\), by determining Θ i(t) via minimizing the following error
13.3.2 Learning-Based Problem Statement
In learning-based NILM problem definition, a training dataset of appliances’ consumption exists. The training dataset consists of the consumption or the ON/OFF status of all appliances for a specific period of time. Based on this training dataset, the operation mode of each appliance in each event of the aggregated signal exists. Mathematically, let A = {1, …, i, …, N} be the set of appliances, in which N stands for the total number of appliances. TD the training dataset consist of labelled events
where e i shows the value of the ith event and l i denotes its respective label (or appliance). N e stands for the total number of events in the aggregated signal.
Learning-based algorithms extract a model based on the events and their assigned labels. Then, based on the extracted model (learned model), a proper label (or appliance) is assigned to each event of the aggregated test signal.
13.4 Review on NILM Algorithms
The existing optimization-based and learning-based approaches to NILM will be reviewed in this section.
13.4.1 Optimization-Based NILM Algorithms Review
The NILM problem is formulated as a convex quadratic programming in Lin et al. (2016). In this paper, the whole training dataset is used to train the model which increases the computation complexity and time. Furthermore, the proposed method is highly dependent to the training dataset. Therefore, it is not scalable and has low accuracy in disaggregating the consumption of other consumers. Authors in Singh and Majumdar (2017) proposed sparse optimization NILM problem which is solved by dictionary learning-based algorithm. Six different metaheuristic optimization techniques were evaluated in Egarter and Elmenreich (2015) by considering different datasets. NILM is formulated as a stochastic-based optimization problem in Shahroz et al. (2020), and the probability of usage of appliances is defined as the regularization term.
Authors in Suzuki et al. (2008) defined NILM problem as an integer programming (IP) to detect the simultaneously ON appliances and increase the disaggregation accuracy in disaggregating the high number of appliances with multi-operation modes. NILM problem is formulated as a mixed-integer programming (MIP) in Piga et al. (2016), and the results are compared with a learning-based one. Authors in Bhotto et al. (2017) modified the formulation of IP by defining novel boundaries for the appliances. To reduce the computation burden in MIP-based NILM, a window-based algorithm is utilized in Wittmann et al. (2018). To increase the disaggregation accuracy, ILP and clustering algorithm are merged in Ayub et al. (2018). Authors in Azizi et al. (2020) defined constraints based on the transitions between different modes multi-mode appliances to decrease the computation time of the MIP-based NILM method.
All the aforementioned optimization-based NILM algorithms require pre-information about appliances, such as the total number of appliances, the consumption of each operation mode of appliances, their consumption pattern, etc. This information is obtained via involving and asking consumers, the manual datasheet of appliances, or collecting a training dataset which causes new challenges in this field.
13.4.2 Learning-Based NILM Review
Based on the presence of the training dataset, learning-based NILM can be divided into two main groups, supervised NILM algorithms and unsupervised NILM algorithms (Zhao et al., 2020). A brief review of these methods is discussed below.
(1) Supervised NILM Methods
Supervised NILM algorithms aim to extract a proper model from the training dataset which maps each sample or event of the aggregated signal to a specific appliance. Then, based on the extracted model, the test aggregated signal is disaggregated. One of the well-known supervised NILM algorithms is the classification technique which attracts a lot of attention in recent years. NILM is formulated as KNN problem in Schirmer and Mporas (2019) which reduces the burden of computation. Authors in Tabatabaei et al. (2017) and Massidda et al. (2020) proposed multi-label classification-based NILM which results in high accuracy in disaggregating the multi-mode appliances. Deep-learning-based approach is utilized in Singhal et al. (2019) which requires a high volume of a training dataset. To disaggregate the consumption of multi-mode appliances, authors in Shahroz et al. (2020) utilized a novel deep convolutional neural networks-based algorithm.
All supervised NILM methods proved to be accurate in disaggregating high number of appliances and appliances with overlapping power values (Singhal et al., 2019). However, the main challenge in this field is the requirement for a high volume of training dataset that is not in general feasible to collect (Yang et al., 2019). In the last few years, researchers focused on extracting more features and signatures of appliances from small training datasets to address this challenge (Dash et al., 2020).
(2) Unsupervised NILM Methods
In contrast with supervised methods, unsupervised NILM algorithms do not require a training dataset and prior information about appliances. One of the common methods of unsupervised methods is clustering which is used in this field frequently. Authors in Henao et al. (2015) utilized the subtractive clustering method to the events of the aggregated signal to extract a proper number of appliances as shown in Fig. 13.6. In Kong et al. (2016), k-means method is applied on the events of the aggregated signal. The principal component analysis method as an unsupervised method is utilized in Moradzadeh et al. (2020) to reduce the dimension of data and extract the profile of each appliance.

Grouping events based on substractive clustering (Henao et al., 2015)
Despite some success in the case where all appliances are type I, these algorithms have been ineffective in dealing with multi-mode appliances (Kong et al., 2016; Dinesh et al., 2019). Moreover, these methods, extract different groups of appliances without assigning any appliances to them.
13.5 Types of Appliances
The accuracy of disaggregation of the consumption of an appliance is highly dependent on its category. Generally speaking, appliances are divided into four main groups based on their number of operation modes and their consumption pattern as discussed below (Zoha et al., 2012):
-
1.
Type I: This type of appliances has two operation modes (ON/OFF modes). Examples of these appliances are table lamp, toaster, etc.
-
2.
Type II: Appliances such as washing machine, dishwasher, stove burner, etc., which have multi-operation modes are included in the type II category. This type of appliances is entitled as a finite state machines (FSM). The switching pattern of these appliances makes them more distinguishable and increases the disaggregation accuracy.
-
3.
Type III: Appliances such as the power drill and dimmer lights are included in type III category that have not fixed number of operation modes which are entitled as continuously variable appliances. Disaggregating the consumption of these appliances is one of the main challenges in this field.
-
4.
Type IV: This type of appliances consumes power 24 h of a day. Examples of type IV appliances are hard-wired smoke alarm and external power supplies.
Figure 13.7 illustrates the power pattern of the first three types of appliances. Among different types of appliances, Type III ones are rarely used by consumers and type IV appliances consume low power. Therefore, disaggregating the consumption of type I and II appliances gains a great deal of attention among researchers.

Different types of appliances
13.6 Features/Signatures of Appliances
To disaggregate the aggregated signal, various specific features or signatures of appliances are used. These features or signatures are unique to the appliances and make them more distinguishable from each other. The different types of these features are described below.
13.6.1 Steady-State Features
Steady-state features of appliances refer to longer-lasting changes in power signal when at least one appliance switches its operating mode. The most well-known steady-state features include active and reactive power, current, and current and voltage waveforms (Azizi et al., 2021).
13.6.2 Transient Features
Transient features are short-term fluctuations in power signal before settling to a steady-state condition which include shape, size, duration, and harmonics of the transient. The transient signature of the majority of appliances is pronounced, which makes it suitable for load identification and increases the disaggregation accuracy. However, these features require a high-frequency sampling dataset and specific hardware to collect these data.
13.6.3 Non-traditional Features
In addition to the aforementioned signatures of appliances, in recent years non-traditional signatures such as temperature, light, consumers’ special usage behaviour, time of day, etc. are increasingly used in disaggregation methods to improve the disaggregation accuracy.
Figure 13.8 shows different kinds of smart meters. Since smart meters of active power have the lowest price, the majority of studies focused on steady-state active power-based NILM algorithms.

Different types of smart meters vs their cost (Xu et al., 2018)
13.7 Classification of NILM Methods
Active power-based NILM studies can be broadly divided into two main classes, sample-based algorithms and event-based algorithms which are described below.
13.7.1 Sample-Based Approaches
In sample-based NILM algorithms, by assuming a finite-state machine for each appliance, the total consumption signal is disaggregated based on the pre-learned model of state transitions of appliances (Zhao et al., 2018).
13.7.2 Event-Based Approaches
Event-based methods focused on detecting significant variations in the power signal called events and classifying them based on the specific transitions of appliances (Lu & Li, 2019).
Compared to the sample-based methods, event-based methods are more direct and comprehensive and have low computational complexity and time. Therefore, they have gained a lot of attention in the last years (Azizi et al., 2020). One of the main challenges in these methods is detecting real events. Due to the presence of various noises as shown in Fig. 13.9, event detection plays a crucial role in the disaggregation accuracy of event-based NILM methods (Zhao et al., 2018). Therefore, not detecting any real event or mistakenly considering a fluctuation as an event decreases the accuracy of disaggregation in these methods.

Different types of noises in the measured power signal (Zhao et al., 2018)
13.8 Evaluation Metrics
Two main groups of evaluation metrics exist in the NILM problem: (1) event-detection evaluation metric and (2) load disaggregation accuracy.
13.8.1 Event-Detection Accuracy Metric
Three famous metrics for measuring the accuracy of event detection can be listed as:
-
1.
False-positive rate (FPR): Ratio of FP to the actual negatives
$$\displaystyle \begin{aligned} FPR = \frac{FP}{FP+TN}, \end{aligned} $$(13.7)where FP and TN show the false-positive events (detected non-event as event) and true-negative events (detected non-event as non-event), respectively.
-
2.
F β: Trade-off between precision and recall
$$\displaystyle \begin{aligned} F_{\beta} = \frac{(1+\beta^2)\times TRP \times RC}{(\beta^2\times TRP)+RC}, \end{aligned} $$(13.8)$$\displaystyle \begin{aligned} TPR = \frac{TP}{TP+FN},~RC = \frac{FP}{FP+TN}, \end{aligned} $$(13.9)where TRP and RC show the precision and recall; TP is true positive, FP is false positive, TN is true negative, and FN is false negative. The weighting factors is shown with β. F 1 score is specific type of F β in which β = 1.
-
3.
Overall accuracy:
$$\displaystyle \begin{aligned} OA=\frac{N_{dis}}{N_{true}} \end{aligned} $$(13.10)where N dis shows number of events and N true stands for the non-events that are detected correctly.
13.8.2 Energy Disaggregation Accuracy
The common energy disaggregation accuracy metrics based on the difference between the estimated consumption of each appliance \(\hat {E}_i\) and its actual consumption E i, for N appliances can be listed as:
-
1.
Relative error (RE): The ratio of the error of disaggregation to the actual power consumption which is formulated as
$$\displaystyle \begin{aligned} RE=\frac{\sum_{i=1}^NE_i-\sum_{i=1}^{N}\hat{E}_i}{\sum_{i=1}^NE_i} \end{aligned} $$(13.11) -
2.
Root mean square error (RMSE): This parameter measures the standard deviation of the disaggregation error based on
$$\displaystyle \begin{aligned} RMSE=1-\sqrt{\frac{1}{N}\sum_{i=1}^N(E_i-\hat{E}_i)} \end{aligned} $$(13.12) -
3.
Mean absolute error (MAE): MAE measures the average estimated error based on
$$\displaystyle \begin{aligned} MAE=\frac{1}{N}\sum_{i=1}^N |E_i-\hat{E}_i| \end{aligned} $$(13.13) -
4.
Mean absolute percentage error (MAPE): MAPE defines the accuracy as the following ratio
 (13.14)
(13.14) -
5.
R 2: This accuracy metric is defined based on the variance of the data and the residual sum of squares as follows
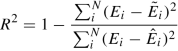 (13.15)
(13.15)where \(\tilde {E}_i\) is the average of E i.

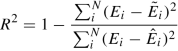
13.9 Sampling Frequency
Depending on the sampling frequency of the power signals, NILM approaches are divided into two main groups:
-
1.
High-frequency sampling data: To obtain higher-resolution data and monitor small changes (<50 W), the consumption is sampled with high frequency (>1 Hz). This sampling rate requires specific hardware and contains a high volume of dataset. However, different signatures (steady and transient signatures) of appliances can be easily extracted from this dataset.
-
2.
Low-frequency sampling data: In this case, the data is sampled with low frequency (<1 Hz) with existing meters. Therefore, this type of sampling omits the cost of additional hardware. Steady signatures must be extracted from these datasets.
Due to the low cost and volume of low-frequency sampling data, in recent years researchers have been focused on these dataset in NILM problem.
13.10 NILM Datasets
With the importance of NILM came the need for standardized datasets to benchmark the wide variety of published algorithms. The most popular datasets in this field and their characteristics are listed in Table 13.1.
13.11 Companies of NILM Products
Over the last decade, different companies have developed different NILM products that analyse the total building electricity consumption and extract the consumption of individual appliances based on complex learning or optimization approaches. Based on these results, some of them suggest different energy management and cost-saving strategies to consumers. Table 13.2 shows the list of known companies in this field.
13.12 Application of NILM in Energy Flexibility Potential Extraction
Shiftable appliances, electrical vehicles, and energy storage devices in the residential sector provide flexibility in the power grid. Generally speaking, the energy flexibility potential of each consumer is computed based on the earliest start time and latest finished time for shiftable/flexible appliance (D’hulst et al., 2015). Mathematically, assuming N app shiftable/flexible appliances, the total energy consumption is obtained based on:
where,

in which P i shows the power of each flexible appliance i.
To extract the energy flexibility potential two parameters are defined as


where P max and P min show the power signal when appliance i starts at earliest time and finished at the latest time, respectively.
The energy patterns considering earliest start and latest finished time for appliances is computed based on
It should be noted that E max and E min show the boundaries of the energy flexibility of the considered appliances’ set as shown in Fig. 13.10.

E max and E min vs typical energy pattern
To compute the energy flexibility of consumers the power signal of shiftable/flexible appliances are required. To obtain them, installing a meter on each appliance (ILM technique) is time-consuming and expensive. Therefore, NILM method must be applied to the aggregated signal of each consumer.
13.12.1 Numerical Results on AMPds
To evaluate the efficiency of the NILM method in the energy flexibility potential extraction the AMPds which consists of minutely measured data is considered (Makonin et al., 2013). Four appliances were considered in this case which include a heat pump, a clothes dryer, a dishwasher, as flexible appliances, and a refrigerator as the most frequent ON/OFF appliance. Figure 13.11 shows the power signal of these appliances and their aggregated one in a typical day.

Total power consumption of appliances
The event-based optimization NILM method of Azizi et al. (2020) is applied to this dataset which consists of three main steps:
-
1.
Pre-processing: In this step, three-point method is applied to the consumption signal of each appliance and the aggregated signal to omit the outliers such as spikes and overshoots, filter the signal and extract events. Then, k-means clustering is applied to events of each appliance to extract the number of their operation modes and their consumption in each mode.
-
2.
Optimization-based NILM: Based on the results of the previous step, MINLP is utilized to solve NILM problem in this stage.
-
3.
Post-processing: Finally, considering non-fixed consumption values for each operation mode of appliances, the consumption signal of appliances are reconstructed.
Table 13.3 shows the accuracy of the estimated power signals based on (13.11). Based on the extracted power signals of shiftable/flexible appliances (HP, DW, and CW), the boundaries of the energy flexibility are computed which is illustrated in Fig. 13.12. The error between the estimated boundaries and the real ones is less than 5% which shows the effectiveness of NILM methods in energy flexibility extraction of consumers.

13.13 Status Quo, Challenges, and Outlook
In recent years, large amounts of datasets on power profiles have become available, leading to various methods being proposed for the NILM problem. However, there are still some challenges (such as (1) the need for a training dataset for supervised methods, (2) achieving high accuracy in disaggregating the multi-mode appliances, (3) proposing scalable approaches, (4) limiting human contribution during configuration, (5) minimizing hardware complexity and cost, etc.) that have not been addressed yet. Therefore, a practical NILM algorithm should have the following guidelines:
-
1.
The proposed methods should be applicable on low-frequency sampled data (1 Hz or less) which are reported with existing smart meters. The proposed NILM approaches on the high-frequency sample data require specific meters which increases the cost.
-
2.
The accuracy of disaggregation should be more than 80% for each appliance. However, the presence of multi-mode appliances increases the complexity of algorithms and decreases accuracy. Developing a NILM algorithm that could work well in disaggregating all types of appliances regardless of their number of modes is still an unsolved challenge in this field.
-
3.
The majority of proposed NILM algorithms require pre-information about appliances or training dataset. However, to address the privacy concerns of consumers, no training dataset should be required which is still one of the main challenges in this field.
-
4.
The proposed NILM techniques may have high accuracy for specific consumers, while they may have low accuracy in disaggregating the aggregated signal of other consumers. However, the algorithm must be scalable to apply to different residential buildings and consumers.
13.14 Conclusion
Using energy resources responsibly, protecting the environment, and reducing CO2 emissions are key objectives in the development of smart sustainable cities. In this regard, energy management strategies are integral parts of smart sustainable cities. The major goals of energy management programs are extracting information about the consumption behaviour of consumers, proposing proper strategies based on consumer’s behaviour in order to peak shaving and valley filling, and finally, increasing the balance between demand and generation. Since more than 30% of total energy consumption belongs to the residential sector, energy management in this sector plays a crucial role to attain the aforementioned goals.
One of the effective tools in residential energy management is non-intrusive load monitoring (NILM). NILM algorithms extract the consumption pattern of each appliance and provide feedback to the consumer about appliances such as their operation condition (normal/faulty), the cost of consumption of each appliance, etc. Furthermore, based on this feedback the energy flexibility potential of each consumer can also be characterized.
In this chapter, we discussed the basic concepts of NILM. To illustrate its application in energy flexibility characterization, four appliances of AMPds are considered, and an optimization-based NILM algorithm is utilized to disaggregate their consumption signal. Then, considering the earliest start time and latest finished time, the energy flexibility of this dataset is extracted.
In this chapter, the energy flexibility of shiftable appliances is computed. Extracting the electrical vehicle consumption pattern using NILM methods and characterizing its energy flexibility potential are one of the main future directions for the researchers who consider reading this chapter. Furthermore, proposing a NILM algorithm that does not require any training dataset and results in high accuracy in disaggregation high number of appliances with multi-mode operation modes can be considered as another future direction for researchers.
References
Abed-Meraim, K., Qiu, W., & Hua, Y. (1997). Blind system identification. Proceedings of the IEEE, 85(8), 1310–1322.
Aydin, E., Brounen, D., & Kok, N. (2018). Information provision and energy consumption: Evidence from a field experiment. Energy Economics, 71, 403–410.
Ayub, M. A., Hassan, N. U., & Yuen, C. (2018). Hybrid iterative algorithm for non-intrusive load disaggregation. In 2018 IEEE International Conference on Communications (ICC) (pp. 1–6).
Azizi, E., Shotorbani, A. M., Hamidi-Beheshti, M.-T., Mohammadi-Ivatloo, B., & Bolouki, S. (2020). Residential household non-intrusive load monitoring via smart event-based optimization. IEEE Transactions on Consumer Electronics, 66(3), 233–241.
Azizi, E., Beheshti, M. T., & Bolouki, S. (2021). Event matching classification method for non-intrusive load monitoring. Sustainability, 13(2), 693.
Bhotto, M. Z. A., Makonin, S., & Bajić, I. V. (2017). Load disaggregation based on aided linear integer programming. IEEE Transactions on Circuits and Systems II: Express Briefs, 64(7), 792–796.
Bulut, M. B., Odlare, M., Stigson, P., Wallin, F., & Vassileva, I. (2016). Active buildings in smart grids—exploring the views of the Swedish energy and buildings sectors. Energy and Buildings, 117, 185–198.
Clarke, J. (2021). Designing active buildings. In Emerging Research in Sustainable Energy and Buildings for a Low-Carbon Future (pp. 11–24). Springer.
D’hulst, R., Labeeuw, W., Beusen, B., Claessens, S., Deconinck, G., & Vanthournout, K. (2015). Demand response flexibility and flexibility potential of residential smart appliances: Experiences from large pilot test in Belgium. Applied Energy, 155, 79–90.
Darby, S., et al. (2006). The effectiveness of feedback on energy consumption. In A Review for DEFRA of the Literature on Metering, Billing and direct Displays (Vol. 486, p. 26).
Dash, S., Sodhi, R., & Sodhi, B. (2019). A semi-intrusive load monitoring approach for demand response applications. In 2019 8th International Conference on Power Systems (ICPS) (pp. 1–6). IEEE.
Dash, S., Sodhi, R., & Sodhi, B. (2020). An appliance load disaggregation scheme using automatic state detection enabled enhanced integer-programming. IEEE Transactions on Industrial Informatics, 17(2), 1176–1185.
Devlin, M. A., & Hayes, B. P. (2019). Non-intrusive load monitoring and classification of activities of daily living using residential smart meter data. IEEE Transactions on Consumer Electronics, 65(3), 339–348.
Dinesh, C., Makonin, S., & Bajić, I. V. (2019). Residential power forecasting using load identification and graph spectral clustering. IEEE Transactions on Circuits and Systems II: Express Briefs, 66(11), 1900–1904.
Egarter, D., & Elmenreich, W. (2015). Load disaggregation with metaheuristic optimization. In Energieinformatik (pp. 1–12).
Erkin, Z., Troncoso-Pastoriza, J. R., Lagendijk, R. L., & Pérez-González, F. (2013). Privacy-preserving data aggregation in smart metering systems: An overview. IEEE Signal Processing Magazine, 30(2), 75–86.
Esa, N. F., Abdullah, M. P., & Hassan, M. Y. (2016). A review disaggregation method in non-intrusive appliance load monitoring. Renewable and Sustainable Energy Reviews, 66, 163–173.
Faustine, A., Pereira, L., & Klemenjak, C. (2020). Adaptive weighted recurrence graphs for appliance recognition in non-intrusive load monitoring. IEEE Transactions on Smart Grid, 12(1), 398–406.
Hafemeister, D. W. (2009). Review of the 2008 APS energy study, energy future: Think efficiency. Physics and Society, 38(2), 16.
Hart, G. W. (1992). Nonintrusive appliance load monitoring. Proceedings of the IEEE, 80(12), 1870–1891.
Henao, N., Agbossou, K., Kelouwani, S., Dubé, Y., & Fournier, M. (2015). Approach in nonintrusive type I load monitoring using subtractive clustering. IEEE Transactions on Smart Grid, 8(2), 812–821.
Kelly, J., & Knottenbelt, W. (2015). The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Scientific Data, 2(1), 1–14.
Kleiminger, W., Beckel, C., & Santini, S. (2015). Household occupancy monitoring using electricity meters. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp 2015), Osaka, Japan.
Kolter, J. Z., & Johnson, M. J. (2011). REDD: A public data set for energy disaggregation research. In Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA (Vol. 25, pp. 59–62).
Kong, W., Dong, Z. Y., Ma, J., Hill, D. J., Zhao, J., & Luo, F. (2016). An extensible approach for non-intrusive load disaggregation with smart meter data. IEEE Transactions on Smart Grid, 9(4), 3362–3372.
Li, D., & Dick, S. (2018). Residential household non-intrusive load monitoring via graph-based multi-label semi-supervised learning. IEEE Transactions on Smart Grid, 10(4), 4615–4627.
Lin, S., Zhao, L., Li, F., Liu, Q., Li, D., & Fu, Y. (2016). A nonintrusive load identification method for residential applications based on quadratic programming. Electric Power Systems Research, 133, 241–248.
Liu, Q., Kamoto, K. M., Liu, X., Sun, M., & Linge, N. (2019). Low-complexity non-intrusive load monitoring using unsupervised learning and generalized appliance models. IEEE Transactions on Consumer Electronics, 65(1), 28–37.
Lu, M., & Li, Z. (2019). A hybrid event detection approach for non-intrusive load monitoring. IEEE Transactions on Smart Grid, 11(1), 528–540.
Makonin, S., Popowich, F., Bartram, L., Gill, B., & Bajić, I. V. (2013). AMPds: A public dataset for load disaggregation and eco-feedback research. In 2013 IEEE Electrical Power & Energy Conference (pp. 1–6). IEEE.
Massidda, L., Marrocu, M., & Manca, S. (2020). Non-intrusive load disaggregation by convolutional neural network and multilabel classification. Applied Sciences, 10(4), 1454.
Moradzadeh, A., Sadeghian, O., Pourhossein, K., Mohammadi-Ivatloo, B., & Anvari-Moghaddam, A. (2020). Improving residential load disaggregation for sustainable development of energy via principal component analysis. Sustainability, 12(8), 3158.
Piga, D., Cominola, A., Giuliani, M., Castelletti, A., & Rizzoli, A. E. (2016). Sparse optimization for automated energy end use disaggregation. IEEE Transactions on Control Systems Technology, 24(3), 1044–1051.
Schirmer, P. A., & Mporas, I. (2019). Statistical and electrical features evaluation for electrical appliances energy disaggregation. Sustainability, 11(11), 3222.
Shahroz, M., Younis, M. S., & Nasir, H. A. (2020). A scenario-based stochastic optimization approach for non-intrusive appliance load monitoring. IEEE Access, 8, 142205–142217.
Singh, S., & Majumdar, A. (2017). Analysis co-sparse coding for energy disaggregation. IEEE Transactions on Smart Grid, 10(1), 462–470.
Singhal, V., Maggu, J., & Majumdar, A. (2019). Simultaneous detection of multiple appliances from smart-meter measurements via multi-label consistent deep dictionary learning and deep transform learning. IEEE Transactions on Smart Grid, 10(3), 2969–2978.
Suzuki, K., Inagaki, S., Suzuki, T., Nakamura, H., & Ito, K. (2008). Nonintrusive appliance load monitoring based on integer programming. In IEEE, SICE Annual Conference, Tokyo, Japan (pp. 20–22)
Tabatabaei, S. M., Dick, S., & Xu, W. (2017). Toward non-intrusive load monitoring via multi-label classification. IEEE Transactions on Smart Grid, 8(1), 26–40.
Wang, Y., Shukla, A., & Liu, S. (2017). A state of art review on methodologies for heat transfer and energy flow characteristics of the active building envelopes. Renewable and Sustainable Energy Reviews, 78, 1102–1116.
Wittmann, F. M., López, J. C., & Rider, M. J. (2018). Nonintrusive load monitoring algorithm using mixed-integer linear programming. IEEE Transactions on Consumer Electronics, 64(2), 180–187.
Xu, F., Huang, B., Cun, X., Wang, F., Yuan, H., Lai, L. L., & Vaccaro, A. (2018). Classifier economics of semi-intrusive load monitoring. International Journal of Electrical Power & Energy Systems, 103, 224–232.
Yang, C. C., Soh, C. S., & Yap, V. V. (2019). A systematic approach in load disaggregation utilizing a multi-stage classification algorithm for consumer electrical appliances classification. Frontiers in Energy, 13(2), 386–398.
Zhang, J., Chen, X., Ng, W. W., Lai, C. S., & Lai, L. L. (2019). New appliance detection for nonintrusive load monitoring. IEEE Transactions on Industrial Informatics, 15(8), 4819–4829.
Zhao, B., He, K., Stankovic, L., & Stankovic, V. (2018). Improving event-based non-intrusive load monitoring using graph signal processing. IEEE Access, 6, 53944–53959.
Zhao, B., Ye, M., Stankovic, L., & Stankovic, V. (2020). Non-intrusive load disaggregation solutions for very low-rate smart meter data. Applied Energy, 268, 114949.
Zhou, Z., Xiang, Y., Xu, H., Yi, Z., Shi, D., & Wang, Z. (2020). A novel transfer learning based intelligent non-intrusive load monitoring with limited measurements. IEEE Transactions on Instrumentation and Measurement, 70, 1–8.
Zoha, A., Gluhak, A., Imran, M. A., & Rajasegarar, S. (2012). Non-intrusive load monitoring approaches for disaggregated energy sensing: A survey. Sensors, 12(12), 16838–16866.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Azizi, E., Beheshti, M.T.H., Bolouki, S. (2022). Non-intrusive Load Monitoring and Its Application in Energy Flexibility Potential Extraction of Active Buildings. In: Vahidinasab, V., Mohammadi-Ivatloo, B. (eds) Active Building Energy Systems. Green Energy and Technology. Springer, Cham. https://doi.org/10.1007/978-3-030-79742-3_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-79742-3_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-79741-6
Online ISBN: 978-3-030-79742-3
eBook Packages: EnergyEnergy (R0)