
Abstract
In the multi-criteria decision analysis (MCDA) domain, one of the most important challenges of today is Rank Reversal. In short, it is a paradox that the order of alternatives belonging to a certain set is changed when a new alternative is added to that set or one of the current ones is removed. It may undermine the credibility of ratings and rankings, which are returned by methods exposed to the Rank Reversal phenomenon.
In this paper, we propose to use the Characteristic Objects method (COMET), which is resistant to the Rank Reversal phenomenon and combining it with the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) and Preference Ranking Organization Method for Enrichment Evaluations II (PROMETHEE II) methods. The COMET method requires a very large number of pair comparisons, which depends exponentially on the number of criteria used. Therefore, the task of pair comparisons will be performed using the PROMETHEE II and TOPSIS methods. In order to compare the quality of both proposed approaches, simple comparative experiments will be presented. Both proposed methods have high accuracy and are resistant to the Rank Reveral phenomenon.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Multi-Criteria Decision Analysis (MCDA) is an important branch of operational research, where the most crucial challenge is to correctly identify the values of preferences and rankings for a defined set of alternatives with commonly contradictory criteria. Many interesting studies were devoted to the selection of appropriate MCDA methods to the specified problem class [7, 21, 24]. However, a significant challenge for the MCDA methods is still the Rank Reversal (RR) paradox. There are also many studies conducted on the problem of ranking reversal for MCDA methods, e.g. TOPSIS [9, 26], AHP [2], ELECTRE [11] or PROMETHEE [23]. The RR phenomenon can define as a change in the ranking of alternatives when the alternative is added or removed in a given set. In this case, the order of priority of decision-makers between the two alternatives changes, which is incompatible with the principle of independence of irrelevant alternatives [1].
Recently, research directions aimed at creating reliable methods fully resistant to the RR phenomenon have become increasingly visible. The most important methods of recent years include Ranking of Alternatives through Functional mapping of criterion sub-intervals into a Single Interval (RAFSI) [27], Stable Preference Ordering Towards Ideal Solution (SPOTIS) [8], and the Characteristic Objects Method (COMET) [17]. Apart from resistance to the RR phenomenon, the COMET method’s main advantages are high accuracy and not requiring arbitrary weights. However, the number of required pair comparisons is exponentially dependent on the number of analyzed criteria and the number of characteristic values. Thus, despite its advantages, it is very laborious. That is why the idea was put forward to create a hybrid approach, which would have most of the COMET method’s positive features but would not require the expert to make pair comparisons.
In order to create a hybrid approach, we want to test two popular methods such as the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) and Preference Ranking Organization Method for Enrichment Evaluations II (PROMETHEE II) methods. These methods have been successfully applied in many scientific works despite the burden of the RR paradox for them [3, 4]. They represent two different approaches to decision making [25].
In this paper, we propose a new hybrid approach to combine the advantages of COMET and two other MCDA methods. In both cases, MCDA methods replace the expert when comparing pairs of characteristic objects. As a result, we have obtained two similar approaches, which will be compared with each other, where one is based on TOPSIS method and the second on the PROMETHE II method. At the same time, the use of these classical MCDA methods, together with the COMET method, will also be immune to the rank reversal phenomenon.
The rest of the paper is organized as follows: In Sect. 2, some basic preliminary concepts on MCDA are presented. The PROMETHEE II, TOPSIS and COMET algorithms are presented in Sects. 2.1, 2.2, and 2.3, respectively. The ranking similarity coefficients used in this paper are described in Sect. 2.4. The method for determining criterion weights based on entropy is discussed in Sect. 2.5. In Sect. 3, the proposed approach is presented with numerical examples. In Sect. 4, we present the summary and conclusions.
2 Methods
In this section, the methods used in our work are presented in order to make the newly proposed approach easier to understand.
2.1 The PROMETHEE II Method
The Preference Ranking Organization Method for Enrichment Evaluations II (PROMETHEE II) is a method whose main logic is to compare alternative solutions in pairs. Decision options in this method evaluated according to different types of criteria, which, depending on the type, must be minimized or maximized. This method comes from the PROMETHEE family of methods developed by Brans [6]. It is used in many decision-making problems [14, 15, 21].
Step 1. The first step is to define a decision-making space at the aid of a decision matrix with n alternatives and criteria in m. The type of criteria (benefit or cost) and the weighting of the criteria must be defined. The sum of criteria weights should be equal to 1.
Step 2. The next stage in the PROMETHEE II method is the normalization of the decision matrix. In this case, linear normalization was used, which is represented by Eqs. (1) (for the benefit type criterion) and (2) (for the cost type criterion).
For beneficial type criteria:
For cost type criteria:
where:
-
\(x_{ij}\) - value of the decision matrix for column j and row i
-
\(r_{ij}\) standardized value of column j and row i
Step 3. Calculating the differences \(d_{j}\) of alternatives \(i^{th}\) with respect to the other alternatives for each criterion. The pairwise comparison for all alternatives is calculated, where \(g_{j}(a)\) is the value of alternative a in criterion j (3).
Step 4. In the PROMETHEE II method, we use usual preference function to calculate preference values [16]:
The most common choice for calculating preferences in PROMETHEE II is the preference function (4) because it has no additional parameters.
Step 5. The aggregated preference values are then determined based on the formula (5) if the sum of weights is equal to 1 (6).
Step 6. Leaving and entering outranking flows. Based on the aggregated preference values, the positive values of (7) and negative values of (8) preference flow \(\phi ^{-}\) and \(\phi ^{+}\) are calculated.
Step 7. Net outranking flows. The last step in the PROMETHEE II method is to calculate the net preference flow using Eq. (9). The highest calculated value gets the first position in the ranking.
2.2 The TOPSIS Method
The concept of the TOPSIS method is to specify the distance of the considered objects from the ideal and anti-ideal solution [21]. The final effect of the study is a synthetic coefficient which forms a ranking of the studied objects. The best object is defined as the one with the shortest distance from the ideal solution and, at the same time, the most considerable distance from the anti-ideal solution [13, 21]. The formal description of the TOPSIS method should be shortly mentioned [4]:
Step 1. Create a decision matrix consisting of n alternatives with the values of criteria k. Then normalize the decision matrix according to the formula (10).
where \(x_{ij}\) and \(r_{ij}\) are the initial and normalized value of the decision matrix.
Step 2. Then create a weighted decision matrix that has previously been normalized according to the Eq. (11).
where \(v_{ij}\) is the value of the weighted normalized decision matrix and \(w_{j}\) is the weight for j criterion.
Step 3. Determine the best and worst alternative according to the following formula (12):
where:
Step 4. Calculate the separation measure from the best and worst alternative for each decision variant according to the Eq. (13).
Step 5. Calculate the similarity to the worst condition by equation:
Step 6. Rank the alternatives by their similarity to the worst state.
2.3 The COMET Method
The COMET algorithm the formal notation of the COMET method should be briefly recalled [10, 19]:
Step 1. Definition of the space of the problem - the expert determines the dimensionality of the problem by selecting r criteria, \(C_{1}, C_{2}, \ldots , C_{r}\). Then, a set of fuzzy numbers is selected for each criterion \(C_{i}\), e.g. \(\{\tilde{C}_{i1}, \tilde{C}_{i2}, \ldots , \tilde{C}_{ic_{i}}\}\) (15):
where \(c_{1}, c_{2}, \ldots , c_{r}\) are the ordinals of the fuzzy numbers for all criteria.
Step 2. Generation of the characteristic objects - the characteristic objects (CO) are obtained with the usage of the Cartesian product of the fuzzy numbers’ cores of all the criteria (16):
As a result, an ordered set of all CO is obtained (17):
where t is the count of COs and is equal to (18):
Step 3. Evaluation of the characteristic objects - the expert determines the Matrix of Expert Judgment (MEJ) by comparing the COs pairwise. The matrix is presented below (19):
where \(\alpha _{ij}\) is the result of comparing \(CO_{i}\) and \(CO_{j}\) by the expert. The function \(C_{exp}\) denotes the mental judgement function of the expert. It depends solely on the knowledge of the expert. The expert’s preferences can be presented as (20):
After the MEJ matrix is prepared, a vertical vector of the Summed Judgments (SJ) is obtained as follows (21):
The number of query is equal \(p = \frac{t(t-1)}{2}\) because for each element \(\alpha _{ij}\) we can observe that \(\alpha _{ji}=1-\alpha _{ij}\). The last step assigns to each characteristic object an approximate value of preference \(P_i\) by using the following Matlab pseudo-code:

In the result, the vector P is obtained, where i-th row contains the approximate value of preference for \(CO_i\).
Step 4. The rule base – each characteristic object and its value of preference is converted to a fuzzy rule as (22):
In this way, a complete fuzzy rule base is obtained.
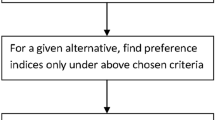
Step 5. Inference and the final ranking - each alternative is presented as a set of crisp numbers, e.g. \(A_{i} = \{a_{i1},a_{i2},a_{ri}\}\). This set corresponds to the criteria \(C_{1}, C_{2}, \ldots , C_{r}\). Mamdani’s fuzzy inference method is used to compute the preference of the \(i - th\) alternative. The rule base guarantees that the obtained results are unequivocal. The whole process of the COMET method is presented on the Fig. 1.

The flow chart of the COMET procedure [18]
2.4 Similarity Coefficients
Similarity coefficients are measures by which one can compare to what extent the results obtained are similar. In this study, we compared rankings of multi-criteria decision-making methods using the Spearman correlation coefficient (23), Spearman weight correlation coefficient (24), Kendall correlation coefficient (26) and the WS rank similarity coefficient (25) [20].
2.5 Entropy Weighting Method
Shannon’s Entropy is a measure used in many areas of informational research [22]. It is a measure of uncertainty and the degree of disorderly elements and states in a specific set. In the case of multi-criteria decision-making methods, it is used to calculate the weighting of criteria [5].
Step 1. Assuming that there is a decision matrix A with dimensions of \(n \times m\), where n is the number of criteria and m is the number of alternatives, it should be normalized for the benefit type criterion and the profit type according to formulas 27 and 28 respectively.
Step 2. The entropy for each criterion is calculated for a normalized matrix, where Ec is the entropy of criterion C. The entropy of a criterion is defined by the 29 equation.
Step 3. The degree of unreliability of dc for entropy criterion Ec can be calculated using the formula 30.
Step 4. After calculating the degree of divergence for each criterion, the weights should be calculated according to the formula:
3 The Proposed Approaches
The proposed approach is based on the COMET method algorithm. The narrow throat of this method is the necessary number of pair comparisons, which exponentially depends on the number of criteria and characteristic values. Therefore, in step 3 of the algorithm, we propose to use TOPSIS or PROMETHEE II instead of expert comparisons. Both approaches will be compared with each other in order to determine effectiveness. Critical weighting is determined by the entropy method.
This means that this method will not require the expert to create the MEJ matrix. The mentioned MCDA methods would be generated instead of the expert function \(f_{exp}\). It is worth mentioning that thanks to this hybrid approach the rank reversal phenomenon is not possible, because all characteristic objects are evaluated together, and not the set of alternatives as in the original versions of these methods. The TOPSIS or PROMETHEE II method is used only for the automatic configuration of the COMET method.
3.1 Rank Reversal - Exemplary Study Case
In the purpose of presenting the significance of the rank reversal phenomenon, a simple theoretical example consisting of only two criteria will be presented. It will analyze a set consisting of 10 alternatives, and then another alternative will be added to present the reversal ranking paradox. The range of both criteria is set from zero to one. The weights in both cases were determined using the entropy method (w1 = 0.4874, w2 = 0.5126).

The decision grid with decision alternatives for the ranking reversal paradox study.
After obtaining the rankings using the classical TOPSIS and PROMETHEE II methods, an investigation for the proposed approach was conducted. For this purpose, the same sets of alternatives were used in the study for PROMETHEE II and TOPSIS itself. In the first step, a decision grid was defined for criteria \(C_{1}\) and \(C_{2}\) with values of [0, 0.5, 1]. The characteristic objects from the grid were then evaluated using the PROMETHEE II (and in second approach TOPSIS) method, where the weights were selected by entropy. The evaluated characteristic objects were used in creating the COMET rule base. The COMET model then evaluated two sets of alternatives, a reference set and a set with an additional alternative. As in the case of the PROMETHEE II and TOPSIS methods itself, they were ordered, but in the second set of alternatives, the additional alternative’s evaluation was not taken into account. In this way, rankings were obtained for the proposed approach of combining the PROMETHEE II and COMET methods.
Figure 2 shows a defined decision grid for studying the proposed approach combining the PROMETHEE II (or TOPSIS) and COMET methods. Black dots on the grid indicate characteristic objects. A reference set of 10 decision alternatives is shown as a green diamond on the grid, while the additional alternative is shown as a red diamond. The Table 1 shows alternatives with values for each criterion and their rankings. In the case of the assessments of both sets of alternatives, the rankings for the PROMETHEE II method and the COMET method combined approach are different. In case of ranking for the PROMETHEE II method itself, rankings differ significantly, and both are presented in the table. The values of similarity coefficients between PROMETHEE II in both cases (for ten and eleven alternatives) are significant lower, i.e. \(r_{w} = 0.8236\), \(r_{s} = 0.8787\), \(WS = 0.8599\) and \(\tau _{b}. = 0.8222\). It is caused by the paradox of reversal rankings, where when adding another alternative to the reference set of alternatives, their rating changes dramatically [12, 23]. However, the proposed approach eliminates the ranking reversal paradox using the COMET method, which is resistant to the paradox.
It is worth noting that this example clearly shows that both the PROMETHEE II and TOPSIS methods themselves have shown their lack of resistance to the rank reversal phenomenon. In the two-hybrid methods, there is no rank reversal because PROMETHEE II and TOPSIS do not serve to evaluate alternatives directly but only indirectly by evaluating the characteristic objects. Thus, the proposed approach is systematically free of the rank reversal phenomenon, which has been illustrated in the presented example and directly results from the COMET method’s properties.
3.2 Effectiveness
In the purpose of presenting the effectiveness of the approaches considered, the following study was performed. The first step was to evaluate the set generated in each iteration consisting of 3 to 10 alternatives to the three criteria. The first criterion was the patient’s heart rate, which was in the range [60, 100], the second criterion was the patient’s age, which was in the range [40, 60], and the third criterion was systolic blood pressure, which was in the range [90, 180]. This set was evaluated by an expert function defined as TRI, and this evaluation was a reference preference. The expert function TRI can be defined as follows:
where, HR is heart rate (bits per minute bpm), A is baseline age (years), and SBP is systolic blood pressure (mmHg).

In the next step, the same set of alternatives was evaluated using the PROMETHEE II method (and analogical TOPSIS) itself and a combination of the PROMETHEE II and COMET methods. All alternatives were then ranked according to the preferences obtained from the respective approaches. Correlation coefficients were calculated for the obtained rankings with reference rankings, specified in Sect. 2.4. Ten thousand iterations repeated these actions. Algorithm 1 provides details of the next steps of the study.
The Fig. 3 shows a box graph for the value of the rs correlation coefficient to the number of alternatives in the set for the two approaches considered. It shows that proposed approaches have higher level of rankings similarity to reference ranking than for classical TOPSIS and PROMETHEE II methods. Moreover, the rs correlation coefficient values for the two considered cases are not significantly different.

Experimental results comparing the similarity of the rankings.
Similar results were also obtained for the other coefficients. This clearly shows that the use of the hybrid approach produces better results than classical methods. Additionally, it should be remembered that the proposed approaches are free from the rank reversal phenomenon.
4 Conclusions
The following paper proposes the use of a new approach to decision-making to avoid rank reversal. The proposed hybrid approach combines the COMET method and TOPSIS or PROMETHEE II methods. Thanks to this combination, it is possible to avoid the curse of dimensionality. The COMET method’s main disadvantage is that the number of queries to the expert increases exponentially as the number of criteria and characteristic values increases. Therefore, the expert evaluation’s mental function is proposed to be replaced by calculations obtained with the TOPSIS or PROMETHEE method. Such an action still guarantees the non-appearance of the rank reversal phenomenon. As shown in the simulation example, the results obtained are better than when using PROMETHEE II and TOPSIS methods alone.
This study poses many further research challenges, where as the main direction for further research may be enumerate:
-
testing the influence of the number of characteristic values on the accuracy of the hybrid approach;
-
investigating the impact of selecting an optimal grid of characteristic object points on accuracy;
-
investigating other methods of preference for PROMETHEE II;
-
investigation of other MCDA methods and their possible combination with the COMET method;
-
further work on accuracy assessment of the proposed solution.
References
de Farias Aires, R.F., Ferreira, L.: The rank reversal problem in multi-criteria decision making: aliterature review. Pesquisa Operacional 38(2), 331–362 (2018)
Barzilai, J., Golany, B.: Ahp rank reversal, normalization and aggregation rules. INFOR: Inf. Syst. Oper. Res. 32(2), 57–64 (1994)
Behzadian, M., Kazemzadeh, R.B., Albadvi, A., Aghdasi, M.: Promethee: a comprehensive literature review on methodologies and applications. Eur. J. Oper. Res. 200(1), 198–215 (2010)
Behzadian, M., Otaghsara, S.K., Yazdani, M., Ignatius, J.: A state-of the-art survey of topsis applications. Expert Syst. Appl. 39(17), 13051–13069 (2012)
Bhowmik, C., Bhowmik, S., Ray, A.: The effect of normalization tools on green energy sources selection using multi-criteria decision-making approach: a case study in India. J. Renew. Sustain. Energy 10(6), 065901 (2018)
Brans, J.P., Vincke, P., Mareschal, B.: How to select and how to rank projects: the promethee method. Eur. J. Oper. Res. 24(2), 228–238 (1986)
Cinelli, M., Kadziński, M., Gonzalez, M., Słowiński, R.: How to support the application of multiple criteria decision analysis? let us start with a comprehensive taxonomy. Omega, p. 102261 (2020)
Dezert, J., Tchamova, A., Han, D., Tacnet, J.M.: The spotis rank reversal free method for multi-criteria decision-making support. In: 2020 IEEE 23rd International Conference on Information Fusion (FUSION), pp. 1–8. IEEE (2020)
García-Cascales, M.S., Lamata, M.T.: On rank reversal and topsis method. Math. Comput. Model. 56(5–6), 123–132 (2012)
Jankowski, J., Sałabun, W., Wątróbski, J.: Identification of a multi-criteria assessment model of relation between editorial and commercial content in web systems. In: Zgrzywa, A., Choroś, K., Siemiński, A. (eds.) Multimedia and Network Information Systems. AISC, vol. 506, pp. 295–305. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-43982-2_26
Liu, X., Ma, Y.: A method to analyze the rank reversal problem in the electre ii method. Omega, p. 102317 (2020)
Mareschal, B., De Smet, Y., Nemery, P.: Rank reversal in the promethee ii method: some new results. In: 2008 IEEE International Conference on Industrial Engineering and Engineering Management, pp. 959–963. IEEE (2008)
Menouer, T.: KCSS: Kubernetes container scheduling strategy. J. Supercomput. 77, 4267–4293 (2020)
Menouer, T., Cérin, C., Darmon, P.: Accelerated promethee algorithm based on dimensionality reduction. In: Hsu, C.-H., Kallel, S., Lan, K.-C., Zheng, Z. (eds.) IOV 2019. LNCS, vol. 11894, pp. 190–203. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-38651-1_17
Palczewski, K., Sałabun, W.: Influence of various normalization methods in promethee ii: an empirical study on the selection of the airport location. Procedia Comput. Sci. 159, 2051–2060 (2019)
Podvezko, V., Podviezko, A.: Dependence of multi-criteria evaluation result on choice of preference functions and their parameters. Technol. Econ. Dev. Econ. 16(1), 143–158 (2010)
Sałabun, W.: The characteristic objects method: a new distance-based approach to multicriteria decision-making problems. J. Multi-Criteria Decis. Anal. 22(1–2), 37–50 (2015)
Sałabun, W., Palczewski, K., Wątróbski, J.: Multicriteria approach to sustainable transport evaluation under incomplete knowledge: electric bikes case study. Sustainability 11(12), 3314 (2019)
Sałabun, W., Piegat, A.: Comparative analysis of MCDM methods for the assessment of mortality in patients with acute coronary syndrome. Artif. Intell. Rev. 48(4), 557–571 (2017)
Sałabun, W., Urbaniak, K.: A new coefficient of rankings similarity in decision-making problems. In: Krzhizhanovskaya, V., et al. (eds.) ICCS 2020. LNCS, vol. 12138, pp. 632–645. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-50417-5_47
Sałabun, W., Wątróbski, J., Shekhovtsov, A.: Are mcda methods benchmarkable? a comparative study of topsis, vikor, copras, and promethee ii methods. Symmetry 12(9), 1549 (2020)
Shannon, C.E.: A mathematical theory of communication. Bell Syst. Tech. J. 27(3), 379–423 (1948)
Verly, C., De Smet, Y.: Some results about rank reversal instances in the promethee methods. Int. J. Multicriteria Decision Making 71 3(4), 325–345 (2013)
Wątróbski, J., Jankowski, J., Ziemba, P., Karczmarczyk, A., Zioło, M.: Generalised framework for multi-criteria method selection. Omega 86, 107–124 (2019)
Wątróbski, J., Jankowski, J., Ziemba, P., Karczmarczyk, A., Zioło, M.: Generalised framework for multi-criteria method selection: rule set database and exemplary decision support system implementation blueprints. Data Brief 22, 639 (2019)
Yang, W.: Ingenious solution for the rank reversal problem of topsis method. Math. Problems Eng. 2020, 1–12 (2020)
Žižović, M., Pamučar, D., Albijanić, M., Chatterjee, P., Pribićević, I.: Eliminating rank reversal problem using a new multi-attribute model—the rafsi method. Mathematics 8(6), 1015 (2020)
Acknowledgments
The work was supported by the National Science Centre, Decision number UMO-2018/29/B/HS4/02725.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Kizielewicz, B., Shekhovtsov, A., Sałabun, W. (2021). A New Approach to Eliminate Rank Reversal in the MCDA Problems. In: Paszynski, M., Kranzlmüller, D., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M.A. (eds) Computational Science – ICCS 2021. ICCS 2021. Lecture Notes in Computer Science(), vol 12742. Springer, Cham. https://doi.org/10.1007/978-3-030-77961-0_29
Download citation
DOI: https://doi.org/10.1007/978-3-030-77961-0_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-77960-3
Online ISBN: 978-3-030-77961-0
eBook Packages: Computer ScienceComputer Science (R0)