
Abstract
Most modern theoretical studies on the cerebellum stem from the Marr-Albus-Ito model. In this article, we illustrate the “evolutionary tree” of that theoretical model, and review how the original Marr-Albus-Ito model was conceived and how it has evolved. Over the past 50 years, this work has been applied to studies of behavior, granular layer encoding, memory capacity of Purkinje cells, distributed and synergistic synaptic plasticity, internal models, and general computational principles of the cerebellar circuit. We also discuss future directions of theoretical studies on the cerebellum.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Marr-Albus-Ito model
- Behavioral study
- Granular layer encoding
- Memory capacity
- Distributed plasticity
- Olivocerebellar system
- Internal models
- General computational principles
- Reinforcement learning
1 Introduction
A theory is a way of thinking about what a given system is and how it behaves. It is grounded on available experimental data, but a good theory will also be consistent with data obtained in the future. Furthermore, a good theory provides experimentally testable predictions to further enhance our understandings of the system.
Around 1970, Marr (1969), Ito (1970), and Albus (1971) conceptualized the computational principle of the cerebellum based on a blueprint of the cerebellar circuit (Eccles et al., 1967). About 10 years later, Ito and his colleagues found the missing piece of the concept experimentally, which was plasticity at parallel fiber-Purkinje cell synapses (Ito et al., 1982; Ito, 1989). Following the discovery of the plasticity that we now know as long-term depression (LTD), the Marr-Albus-Ito model was established. Since then, the model has been analyzed, challenged, and extended to obtain better and deeper understandings of cerebellar computational principles (Ito, 1984, 2012).
The Marr-Albus-Ito model has provided a compass with which to navigate the ocean of cerebellar research for 50 years (Yamazaki & Lennon, 2019). Without the compass, researchers would be easily drawn in front of a huge amount of experimental data. Meanwhile, the model has been gradually evolving to account for new findings and concepts up to date.
The original Marr-Albus-Ito model postulated various important concepts: applications to behavioral studies, granular layer encoding, memory capacity of Purkinje cells, distributed and synergistic synaptic plasticity, internal models, and general computational principles of the cerebellar circuit. For these concepts, a number of theoretical models have been proposed. We have summarized the “evolution” of the original model as an evolutionary tree (Fig. 11.1). In this article, we review how the original MAI model has been adapted to account for those concepts.

An evolutionary tree of the Marr-Albus-Ito model. Gray boxes represent models, whereas lines represent inheritance relationships. Blue boxes represent conceptual works published outside of the cerebellar research. Green boxes are representative review papers. The pink box indicates the Marr-Albus-Ito model. Please note that the tree is not exhaustive. Only the models necessary to draw the diagram are shown. Abbreviations as in the text
Meanwhile, computational studies using supercomputers are another important direction for cerebellar research. While theoretical studies aim to extract the principle or “essence” of a given system by eliminating a number of biological details, computational studies aim to replicate the system itself to reproduce the dynamics by incorporating as many details as possible. Both are called models, but their approaches are completely different. For computational studies, another review article will be available (Yamazaki et al., Submitted).
2 Evolutionary Tree of the Marr-Albus-Ito Model
To illustrate how the Marr-Albus-Ito model has influenced its successors, we compiled a number of theoretical models that stemmed from the Marr-Albus-Ito model, and created an “evolutionary tree” (Fig. 11.1).
2.1 The Marr-Albus-Ito Model
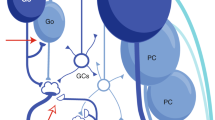
The ancestor is of course the Marr-Albus-Ito model. Although there are fewer than ten types of neurons in the cerebellum (more specifically, in a corticonuclear microcomplex) that constitute a network with recurrent connections, these pioneers focused on a feedforward network composed of Pons (input layer), granule cells (middle layer), and Purkinje cells (output layer) with climbing fiber inputs, while leaving aside the other neurons and connections (Fig. 11.2). The resulting network was assumed to be a cerebellar counterpart of the perceptron (Rosenblatt, 1958), which is the simplest form of supervised learning machine. The Marr-Albus-Ito model, which was also called the perceptron hypothesis, postulated two important observations:
-
Granule cells in the middle layer encode afferent inputs from Pons via mossy fibers sparsely in a distributed manner.
-
Connection strengths from granule cells to Purkinje cells are adjusted by climbing fibers.

Reduction of the cerebellar circuit to a perceptron. (a) Schematic of a corticonuclear microcomplex. Abbreviations: MF mossy fibers, GR granule cells, Go Golgi cells, MLI molecular layer interneurons, PC Purkinje cells, PF parallel fibers, CN cerebellar nuclei, CF climbing fibers, IO inferior olive. (b) The Marr-Albus-Ito model known as a perceptron. Only Pons, GR, PC, and IO are considered
The first idea was called “codon theory” (Marr, 1969) or “expansion recoding” (Albus, 1971), whereas the second one was confirmed about 10 years later by Ito and his colleagues, which we now known as long-term depression (LTD) (Ito et al., 1982). During those 10 years, the parallel fiber-Purkinje cell LTD was a missing piece to establish the Marr-Albus-Ito model. Contrary to the most common synaptic plasticity mechanism called Hebbian learning (Hebb, 1949), in which a synaptic connection between a pair of neurons is updated based on the correlated activity of the pre- and postsynaptic neurons, a synaptic weight is updated based on the correlated activities of the presynaptic parallel fiber and the climbing fiber innervating the same Purkinje cell in LTD.
Moreover, these authors did not forget to discuss the potential roles of other components such as Golgi cells and molecular layer interneurons. The authors first dissected the essential components from other peripheral components, continued to investigate the roles of the other components separately, and finally integrated their roles once again into the main model.
2.2 Applications to Behavioral Studies
2.2.1 Eye Movement Control
The Marr-Albus-Ito model was readily applied to behavioral studies. The first attempt was an application to eye movement control such as the vestibulo-ocular reflex (VOR) and optokinetic response (OKR). VOR is an eye movement reflex in which the eyes rotate in the opposite direction compared with the head rotation, whereas OKR is a reflex in which the eyes rotate to the same direction in response to slow movement of the entire visual world. Information on the head and visual world movements are fed by mossy fibers to the cerebellum. When the eye rotation is insufficient against the head or visual world movements, the visual image on the retina slips. This retinal slip provides an “error” signal to Purkinje cells via climbing fibers, which induces learning to adjust the eye movement gain (gain adaptation). In VOR, artificial stimuli could decouple the phases of head rotation and eye rotation while keeping the eye movement gain, which is called phase adaptation.
In the original Marr-Albus-Ito model, granule cells were considered an encoder of spatial input patterns conveyed by mossy fibers. Fujita (1982a) introduced sinusoidal temporal dynamics of mossy fibers representing the head and eye rotations and that of a climbing fiber that represents retinal slip errors. The model also included an implementation of the granular layer network composed of granule cells and a Golgi cell. Due to distributed synaptic weights of mossy fibers and inhibition exerted by the Golgi cell, granule cells exhibited various sinusoidal activity patterns with different amplitudes and phases. In the end, the model successfully reproduced both gain and phase adaptations in VOR and OKR (Fujita, 1982b). The model adopted the notion of adaptive filtering in the field of engineering (Widrow et al., 1975) and therefore was called an adaptive filter model.
The adaptive filter model was a pioneering theoretical model that first put the Marr-Albus-Ito model into action. The model became a stepstone for eyeblink conditioning (section “Eyeblink Conditioning”) and general computational principles (Sect. 2.7). In fact, Fujita’s original adaptive filter model was later generalized in the context of general computational principles with the same name (Dean et al., 2010). This might produce unnecessary confusion.
After Ito (1975) on the flocculus hypothesis for VOR, another hypothesis on VOR was proposed from outside the Marr-Albus-Ito model (Miles & Lisberger, 1981). Those authors hypothesized that plasticity at mossy fiber synapses on the vestibular nuclei played the prominent role in VOR. In those days, the LTD at parallel fiber synapses on Purkinje cells was a matter of debate. A research group strongly argued that the inferior olive was a timing device that controls motor timing precisely (Llinás & Sugimori, 1980) (Sect. 2.8), but not a subsystem that provided teacher or error signals. Based on the Miles and Lisberger (1981) hypothesis, a series of theoretical models were reported later (Lisberger, 1988; Lisberger & Sejnowski, 1992; Lisberger, 1994), which proposed that Purkinje cells “guide” learning in the downstream neurons of the vestibular nuclei while incorporating recurrent connections from vestibular nuclei to Purkinje cells. Ito immediately responded to the hypothesis (Ito, 1982), and a long-lasting debate over 30 years started (Kandel et al., 2000). Through this debate, the concept of distributed synaptic plasticity within the cerebellum has been gradually developed (Sect. 2.5). In addition, there was an attempt to include the effect of recurrent connections into the Marr-Albus-Ito model (Tabata et al., 2002).
2.2.2 Eyeblink Conditioning
Eyeblink conditioning is a type of classical conditioning, in which an animal receives repeated presentations of a neutral stimulus such as a tone (conditioned stimulus; CS) paired with an aversive stimulus such as an airpuff to the eye (unconditioned stimulus (US)). The animal becomes conditioned to close its eyes in response to the tone (conditioned response (CR)). Moreover, in delay eyeblink conditioning paradigms, the CR is elicited with a delay equal to the interstimulus interval (ISI) between the CS and US onsets (e.g., Mauk and Donegan (1997) for review). The essence of eyeblink conditioning models is how to represent the passage of time during the CS. Most studies attempted to include the timing mechanisms in the granular layer. The first model used tapped delay lines (Desmond & Moore, 1988; Moore et al., 1989), in which neurons are connected in series and activated one by one sequentially. Tapped delay lines are found in superior colliculus for sound localization; this is known as the Jefress model (Jefress, 1948). Fujita’s adaptive filter model (section “Eye Movement Control”) was also extended and applied (Gluck et al., 1990). In the model, granule cells were assumed to exhibit different sinusoidal temporal activity patterns with various frequencies and phases, which could perform Fourier expansion. Another extension was a spectral timing model (Bullock et al., 1994), which assumed multiple Golgi cells with different membrane time constants and generated transient activities of granule cells with different timings and amplitudes. Buonomano and Mauk (1994) focused on the network dynamics in the granular layer and proposed that granule cells exhibit sparse and chaotic or random activity patterns through recurrent inhibitory connections with Golgi cells. These models led to the refinement of general computational principles of the cerebellum (Sect. 2.7).
Other studies attempted to represent the passage-of-time outside of the granular layer. Braitenberg et al. (1997) proposed that parallel fibers provide delay lines by assuming large conduction delays. The concept of spectral timing models (Bullock et al., 1994) was followed by Fiala et al. (1996), Steuber and Willshaw (2004), and Majoral et al. (2020), which proposed that parallel fiber synapses on Purkinje cells could exhibit various temporal activity patterns lasting for seconds through the activation of metabotropic glutamate receptors. Kotaleski et al. (2002) assumed that biochemical interactions within Purkinje cells produce an increase in protein kinase C (PKC) activation, which could contribute to temporal sensitivity of Purkinje cells lasting for seconds. Hong and Optican (2008) proposed a similar timing mechanism through interactions between Purkinje cells and molecular layer interneurons.
These models provide theoretical support for sparse coding in granule cells (Sect. 2.3), which has long stood in opposition to a similar coding hypothesis (section “Distributed Versus Similar Coding in the Granular Layer”).
For timing models, more detailed reviews are provided elsewhere (Yamazaki & Tanaka, 2009).
2.3 Granular Layer Encoding
One of the important concepts of the Marr-Albus-Ito model is the granular layer encoding of mossy fiber inputs. After the publication of Albus (1971), Albus published another paper that aimed to apply the cerebellar control mechanisms for engineering applications (Albus, 1975). The model called Cerebellar Model Architecture Control (CMAC) introduced a tile coding scheme within the granular layer. Models for VOR/OKR and eyeblink conditioning assumed various encoding schemes in the granular layer (Sect. 2.2). Tyrrell and Willshaw (1992) examined the possibility and efficiency of the granular layer encoding by a large-scale computer simulation for the first time. Later, the notion of sparse coding (Olshausen & Field, 1996) was introduced for the granular layer encoding, which was realized by anti-Hebbian learning mechanisms (Schweighofer et al., 2001), principal component analysis (PCA) (Dean et al., 2002), and chaotic spatiotemporal dynamics (Rössert et al., 2015). These studies were followed by those for unified gain and timing mechanisms and general computational principles (Sect. 2.7). Recently, the information capacity of sparse coding in the granular layer was examined mathematically (Cayco-Gajic et al., 2017), adding a new approach to an abundance of studies of the information capacity of Purkinje cells (Sect. 2.4). However, not all experimental data support the sparse encoding hypothesis, which is discussed later (section “Distributed Versus Similar Coding in the Granular Layer”).
2.4 Information Capacity of Purkinje Cells
Another issue of neural encoding is the information encoding by parallel fibers on Purkinje cells. Purkinje cells receive excitatory inputs from about 200,000 parallel fibers, but 80% of them are silent. This massive convergence may play an important functional role in cerebellar computation. The first influential study was reported by Brunel et al. (2004). The authors calculated how many spatial patterns are embedded in parallel fiber synapses on a Purkinje cell while assuming that parallel fibers and Purkinje cells are binary neurons by using the same technique for analyzing associative memory capacity (Hopfield, 1982). Later, the study was extended for temporally correlated input patterns (Clopath et al., 2012) and for analog but not binary neurons (Clopath & Brunel, 2013). Independently from these studies, Porrill and Dean (2008) reported that adaptive filter models using a covariance learning rule could achieve optimal synaptic weights against noisy parallel fiber inputs, suggesting that long-term potentiation (LTP) at parallel fiber-Purkinje cell synapses is also important (Medina & Mauk, 1999).
2.5 Distributed Synaptic Plasticity
One of the most active debates on the cerebellum is probably the location of motor memory in the cerebellum. As seen the above (section “Eye Movement Control”), Miles and Lisberger (1981) proposed that mossy fiber-vestibular nuclei synapses store the memory on eye movement gain in VOR, whereas Ito et al. (1982) proposed parallel fiber-Purkinje cell synapses for the memory site (Kandel et al., 2000). Medina and Mauk (1999) built a computer simulation model that has two synaptic plasticity mechanisms for mossy fiber-vestibular nuclei and parallel fiber-Purkinje cell synapses. They found that learned memory on mossy fiber-vestibular nuclei synapses is stable at the resting state if the memory formation is guided by Purkinje cells innervating the nuclei. Dual plasticity models have also been studied in depth mathematically (Masuda & Amari, 2008; Clopath et al., 2014). These models mainly address the formation of motor memory, not the consolidation process of learned memory. Yamazaki et al. (2015) integrated both formation and consolidation processes in a single model and succeeded in reproducing various experimental results including spacing effects.
These studies were accompanied by experimental findings of multiple distributed synaptic plasticity within the cerebellum (e.g., Boyden et al. (2004) and D’Angelo (2014) for review). Among them, plasticity at parallel fiber synapses on molecular layer interneurons is considered a mechanism that could supersede parallel fiber-Purkinje cell LTD. Parallel fiber-molecular layer interneuron synapses undergo LTP with conjunctive activation of a presynaptic parallel fiber and a postsynaptic molecular layer interneuron that could be activated by spillover of glutamate secreted from nearby climbing fibers, whereas molecular layer interneurons inhibit Purkinje cells. This suggests that parallel fiber-molecular layer interneuron LTP could provide the same function for the cerebellar cortex as a supervised learning machine (Jörntell et al., 2010). Yamazaki and Lennon (2019) built a model of the cerebellar cortex that takes both parallel fiber-Purkinje cell LTD and parallel fiber-molecular layer interneuron LTP into account and analyzed the system dynamics. Contrary to the classical hypothesis of the cerebellar cortex as a supervised learning machine, the authors suggested that the cerebellar cortex could act as a reinforcement learning machine. We will discuss this issue in Sect. 2.7.
2.6 Internal Models
Ito (1970) already described the role of internal feedbacks from the cerebellum to the cerebral cortex that could act as a forward model. Forward models are well-known in engineering and control theory, and so they were readily adopted in the context of motor control by the cerebellum. A Kalman filter model (Paulin, 1989) and a Smith predictor model (Miall & Stein, 1993) were successful examples. Inverse models, closely related to forward models, were proposed by Kawato et al. (1987). Inverse models are acquired by a feedback error learning scheme (Kawato & Gomi, 1992), which was proposed as a model of cerebro-cerebellar interactions. Furthermore, a general architecture consisting of multiple paired forward and inverse models was proposed (Wolpert & Kawato, 1998) and was finalized as MOSAIC (modular selection and identification for control) architecture (Haruno et al., 2001). The concept has been even adopted for cognitive processes (Ramnani, 2006, 2014). A tandem architecture of forward and inverse models was applied for interpreting adaptation of voluntary movements (Honda et al., 2018). In general, forward and inverse models are called internal models. Internal models may be the most successful of all theoretical studies in the history of cerebellar research. A comprehensive review on internal models has been provided elsewhere (Wolpert et al., 1998).
2.7 General Computational Principles
Theoretical models for VOR/OKR (section “Eye Movement Control”) and eyeblink conditioning (section “Eyeblink Conditioning”) led to generalization of the computational principles. Liquid state machines (Yamazaki & Tanaka, 2007) and generalized adaptive filter models (Dean et al., 2010) were proposed as a general computational principle of the cerebellum as an extension of the Marr-Albus-Ito model. These studies were able to explain gain learning (e.g., VOR adaptation) and timing learning (e.g., eyeblink conditioning) by a single computational principle (Yamazaki & Nagao, 2012). Another theoretical study examined the potential of the cerebellar cortical circuit as a universal functional approximator based on mathematical functional analysis (Fujita, 2016).
Pursuing general computational principles of the cerebellum led to studies that would supersede the classical view of the cerebellum as a supervised learning machine. In supervised learning, learning is driven by teacher or error signals (Raymond & Medina, 2018). However, various different learning schemes would be used as well in the cerebellar cortex (Streng et al., 2018; Hull, 2020). An early attempt was made by Kitazawa (2002), who proposed noise-driven learning at Purkinje cells. The same idea was elaborated recently with the name stochastic gradient descent (SGD), which is a general technique to find optimal solutions used in the field of machine learning (Bouvier et al., 2018). These schemes enable the cerebellar cortex to search optimal solutions autonomously. Further elaboration proposes that the cerebellar cortex is a reinforcement learning machine. In reinforcement learning, an agent (i.e., the cerebellum) acquires an optimal action strategy called a policy for a given environment by maximizing expected future reward through trial and error (Sutton & Barto, 2018). Yamazaki and Lennon (2019) proposed that Purkinje cells and molecular layer interneurons act as an actor and a critic, respectively, in an actor-critic model of reinforcement learning, while assuming that climbing fibers convey reward information.
2.8 Olivocerebellar System
In the Marr-Albus-Ito model, inferior olive is considered as the source of teacher or error signals conveyed by climbing fibers that drives learning. Neurons in the inferior olive are connected electrically by gap junctions and exhibit subthreshold oscillation of membrane potentials (Llinás & Sugimori, 1980). A research group has been proposing that inferior olive is not the site for motor learning but a site for controlling motor timing (Welsh et al., 2005) by using temporal dynamics of the subthreshold oscillation (see Llinás (2011) for review). Tokuda et al. (2010) proposed that such subthreshold oscillation combined with chaotic dynamics accelerates learning owing to chaotic resonance mechanisms. A recent theoretical study proposes that gap junctions in the inferior olive constrain motor learning by controlling the degrees of freedom of a system (Hoang et al., 2020). This study could interpret the role of the subthreshold oscillation in the inferior olive, which was the basis of the motor timing hypothesis, within the context of the Marr-Albus-Ito model. Another group studying the olivocerebellar system develops a recurrent network model composed of the inferior olive, Purkinje cells, and cerebellar nuclei via nucleo-olivary connections that could control learning rate and suppress overlearning (Kenyon et al., 1998a, b).
3 Perspectives
3.1 Summary of the Evolutionary Tree
The evolutionary tree could provide several interesting observations. First, the node that has the largest number of outgoing paths is Fujita (1982a), suggesting that the model is the most influential one from which many followers were born. On the other hand, the node that has the largest number of incoming paths is Dean et al. (2010), which is also a variant of adaptive filter models. Thus, adaptive filter models could be regarded as a backbone of all theoretical models on the cerebellum. Second, various important concepts have been introduced from the outside of cerebellar research, such as perceptron, adaptive filtering, sparse coding, and reinforcement learning. The “crossover” has improved and expanded the original concept of the Marr-Albus-Ito model continuously for the next generations. In turn, the original concept has not been altered largely against the crossover, indicating the robustness and concreteness of the original concept. Third, a number of excellent review papers have been available in a timely manner. These review papers help researchers to obtain the latest and consistent view of the computational principles of the cerebellum at the age. The evolution will be able to continue further, as long as we regularly incorporate new concepts from the outside and publish many review papers.
3.2 Unresolved Issues
Although various issues have been resolved through the evolution of the Marr-Albus-Ito model, there are still several unresolved issues, including:
-
Distributed versus a similar coding in the granular layer
-
Information representation by mossy fiber and climbing fiber signals
-
Local versus global computation revealed by distributed climbing fiber activity
3.2.1 Distributed Versus Similar Coding in the Granular Layer
While the granular layer encoding, in which granule cells receive mossy fibers transmitting different information, has theoretical as well as experimental supports (Billings et al., 2014; Ishikawa et al., 2015; Gilmer & Person, 2017), another group suggests that granule cells receive mossy fibers that represent the same information (Bengtsson & Jörntell, 2009). The scheme, which those authors called “similar coding,” may enable granule cells to transmit weak sensory inputs in a graded manner. The similar coding hypothesis suggests that the timing mechanism in eyeblink conditioning (section “Eyeblink Conditioning”) exists not in the granular layer but at Purkinje cells, which is supported by experimental observations (e.g., Johansson et al. (2016) for review). To resolve this argument, large-scale, wide field-of-view imaging studies of the granule cells has provided an essential perspective (Knogler et al., 2017; Giovannucci et al., 2017; Wagner et al., 2017). For comprehensive reviews, see Spanne and Jörntell (2015) and Gilmer and Person (2018).
3.2.2 Information Representation by Mossy Fiber and Climbing Fiber Signals
Classical debates on the information conveyed by mossy and climbing fibers were basically on sensory versus motor, because the cerebellum is known as a central locus for motor control. However, recent imaging studies have revealed that various types of information are represented by mossy and climbing fibers. Notably, even reward-related information is represented in both mossy fiber and climbing fiber signals (Badura & Zeeuw, 2017; Gilmer & Person, 2018). Furthermore, anatomical connections with the ventral tegmental area have been found (Carta et al., 2019). These findings suggest the involvement of the cerebellum in reinforcement learning.
3.2.3 Localized Versus Distributed Computation Revealed by Distributed Climbing Fiber Activity
Previous theoretical studies have examined computational capability of a single microcomplex, which is thought of as a functional module of the cerebellum (Ito, 1984). Over the cerebellar surface, a number of microcomplexes are arranged regularly in space to constitute the entire cerebellar circuit. Different microcomplexes could have different functional roles, so for each specific task, a subset of microcomplexes might be employed to achieve the task, while the rest remain silent. In other words, microcomplexes are organized in a task-specific manner. MOSAIC models seem consistent with this observations (Haruno et al., 2001).
However, a striking Ca2+ imaging study by Michikawa et al. (2020) has revealed that all microzones are always activated simultaneously, suggesting that all cerebellar modules could function in a holistic manner. This study implies that many rather than a small subset of microcomplexes share functions for a given task. Many questions would arise: how do different microcomplexes share a task? And do they interact with each other to accomplish the task? To address this issue, we must examine how multiple microcomplexes share a task on the fly. This could provide new insights on distributed computations over the entire cerebellum.
3.3 Future Directions
A future direction of cerebellar research will be to uncover the role of the cerebellum embedded in the whole brain network for higher-order cognitive functions, for which internal models of mental processes called “mental models” would play essential roles (Ito, 2008, 2012), while sharing the same computational principles with motor functions (Koziol et al., 2012). The interactions will be made through the cerebro-cerebellar communication loop (Allen & Tsukahara, 1974). For such higher- order functions, a whole brain learning mechanism would be necessary including the cerebral cortex,
basal ganglia, and cerebellum. In a pioneering study, Doya pointed out different roles of the cerebral cortex, basal ganglia, and cerebellum and argued how these regions interact with each other (Doya, 1999, 2000). In particular, direct interactions between the basal ganglia and cerebellum have been found experimentally (Carta et al., 2019), suggesting that the cerebellum is involved in even social tasks (D’Angelo, 2019). The whole brain learning architecture model has been extended recently (Caligiore et al., 2019).
These studies have assumed that the cerebellum is a supervised learning machine. However, Yamazaki and Lennon (2019) proposed that the cerebellum might act as a reinforcement learning machine by incorporating synaptic plasticity at parallel fiber-molecular layer interneurons as well as conventional parallel fiber-Purkinje cell LTD. Furthermore, the paper proposed that the whole brain could act as a hierarchical deep reinforcement learning machine, where the cerebral cortex stores deep representation of states and actions, the cerebro-basal ganglia loop performs higher reinforcement learning for goal setting and planning by decomposing a global task into a number of smaller subtasks, and the cerebro-cerebellar loop performs lower reinforcement learning that solves the subtasks in parallel (Fig. 11.3). Deep hierarchical reinforcement learning has proven to be a powerful machine learning algorithm (Kulkarni et al., 2016), which would be suitable for higher-order cognitive and social functions realized by the whole brain (Kawato et al., 2021).

A hypothetical role of cerebro-basal ganglia loop and cerebro-cerebellar loop for hierarchical reinforcement learning (Yamazaki & Lennon, 2019). The cerebral cortex (green) stores deep representation of states and actions. The cerebro-basal ganglia (blue) loop performs higher reinforcement learning that decomposes a global task into a number of smaller subtasks for goal setting and planning. The cerebro-cerebellar (yellow) loop performs lower reinforcement learning to solve subtasks for action execution in parallel. The thalamus (red) would play a certain role in the interactions of the dual loops. Abbreviation: RL reinforcement learning
4 Conclusion
The Marr-Albus-Ito model has cultivated a vast research field for theoretical models. The evolution of our knowledge of the cerebellum will continue to expand, including interactions with other brain regions towards understanding the whole brain learning mechanism.
References
Albus, J. S. (1971). A theory of cerebellar function. Mathematical Biosciences, 10, 25–61.
Albus, J. S. (1975). A new approach to manipulator control: The cerebellar model articulation con- troller (CMAC). Journal of Dynamics Systems, Measurement, and Control, 97(3), 220–227.
Allen, G. I., & Tsukahara, N. (1974). Cerebrocerebellar communication systems. Physiological Reviews, 54(4), 957–1006.
Badura, A., & Zeeuw, C. I. D. (2017). Cerebellar granule cells: Dense, rich and evolving representa- tions. Current Biology, 27(11), R415–R418.
Bengtsson, F., & Jörntell, H. (2009). Sensory transmission in cerebellar granule cells relies on similarly coded mossy fiber inputs. Proceedings of the National Academy of Sciences, 106(7), 2389–2394.
Billings, G., Piasini, E., Lörincz, A., Nusser, Z., & Silver, R. A. (2014). Network structure within the cerebellar input layer enables lossless sparse encoding. Neuron, 83(4), 960–974.
Bouvier, G., Aljadeff, J., Clopath, C., Bimbard, C., Ranft, J., Blot, A., Nadal, J.-P., Brunel, N., Hakim, V., & Barbour, B. (2018). Cerebellar learning using perturbations. eLife, 7, e31599.
Boyden, E. S., Katoh, A., & Raymond, J. L. (2004). Cerebellum-dependent learning: The role of multiple plasticity mechanisms. Annual Review of Neurosciences, 27, 581–609.
Braitenberg, V., Heck, D., & Sultan, F. (1997). The detection and generation of sequences as a key to cerebellar function: Experiments and theory. Behavioral and Brain Sciences, 20, 229–277.
Brunel, N., Hakim, V., Isope, P., Nadal, J.-P., & Barbour, B. (2004). Optimal information storage and the distribution of synaptic weights: Perceptron versus Purkinje cell. Neuron, 43(5), 745–757.
Bullock, D., Fiala, J. C., & Grossberg, S. (1994). A neural model of timed response learning in the cerebellum. Neural Networks, 7, 1101–1114.
Buonomano, D. V., & Mauk, M. D. (1994). Neural network model of the cerebellum: Temporal discrimination and the timing of motor responses. Neural Computation, 6, 38–55.
Caligiore, D., Arbib, M. A., Miall, R. C., & Baldassarre, G. (2019). The super-learning hypoth- esis: Integrating learning processes across cortex, cerebellum and basal ganglia. Neuroscience & Biobehavioral Reviews, 100, 19–34.
Carta, I., Chen, C. H., Schott, A. L., Dorizan, S., & Khodakhah, K. (2019). Cerebellar modulation of the reward circuitry and social behavior. Science, 363(6424), eaav0581t.
Cayco-Gajic, N. A., Clopath, C., & Silver, R. A. (2017). Sparse synaptic connectivity is required for decorrelation and pattern separation in feedforward networks. Nature Communications, 8(1), 1116.
Clopath, C., Badura, A., De Zeeuw, C. I., & Brunel, N. (2014). A cerebellar learning model of vestibulo-ocular reflex adaptation in wild-type and mutant mice. Journal of Neuroscience, 34(21), 7203–7215.
Clopath, C., & Brunel, N. (2013). Optimal properties of analog perceptrons with excitatory weights. PLoS Computational Biology, 9(2), 1–6.
Clopath, C., Nadal, J.-P., & Brunel, N. (2012). Storage of correlated patterns in standard and bistable Purkinje cell models. PLoS Computational Biology, 8(4), 1–10.
D’Angelo, E. (2014). The organization of plasticity in the cerebellar cortex: From synapses to control. Progress in Brain Research, 210, 31–58.
D’Angelo, E. (2019). The cerebellum gets social. Science, 363(6424), 229.
Dean, P., Porrill, J., Ekerot, C.-F., & Jörntell, H. (2010). The cerebellar microcircuit as an adaptive filter: Experimental and computational evidence. Nature Reviews Neuroscience, 11, 30–43.
Dean, P., Porrill, J., & Stone, J. (2002). Decorrelation control by the cerebellum achieves oculomotor plant compensation in simulated vestibulo-ocular reflex. Proceedings of the Royal Society B: Biological Sciences, 269, 1895–1904.
Desmond, J. E., & Moore, J. W. (1988). Adaptive timing in neural networks: The conditioned response. Biological Cybernetics, 58, 405–415.
Doya, K. (1999). What are the computations of the cerebellum, the basal ganglia and the cerebral cortex? Neural Networks, 12, 961–974.
Doya, K. (2000). Complementary roles of basal ganglia and cerebellum in learning and motor control. Current Opinion in Neurobiology, 10(6), 732–739.
Eccles, J. C., Ito, M., & Szentágothai, J. (1967). The cerebellum as a neuronal machine. Springer.
Fiala, J. C., Grossberg, S., & Bullock, D. (1996). Metabotropic glutamate receptor activation in cerebellar Purkinje cells as substrate for adaptive timing of the classically conditioned eye-blink response. Journal Neuroscience, 16, 3760–3774.
Fujita, M. (1982a). Adaptive filter model of the cerebellum. Biological Cybernetics, 45, 195–206.
Fujita, M. (1982b). Simulation of adaptive modification of the vestibulo-ocular reflex with an adaptive filter model of the cerebellum. Biological Cybernetics, 45, 207–214.
Fujita, M. (2016). A theory of cerebellar cortex and adaptive motor control based on two types of universal function approximation capability. Neural Networks, 75, 173–196.
Gilmer, J. I., & Person, A. L. (2017). Morphological constraints on cerebellar granule cell combina- torial diversity. Journal of Neuroscience, 37(50), 12153–12166.
Gilmer, J. I., & Person, A. L. (2018). Theoretically sparse, empirically dense: New views on cerebellar granule cells. Trends in Neurosciences, 41(12), 874–877.
Giovannucci, A., et al. (2017). Cerebellar granule cells acquire a widespread predictive feedback signal during motor learning. Nature Neuroscience, 20, 727–734.
Gluck, M. A., Reifsnider, E. S., & Thompson, R. F. (1990). Adaptive signal processing and the cerebellum: Models of classical conditioning and VOR adaptation. In M. A. Gluck & D. E. Rumelhart (Eds.), Neuroscience and connectionist theory (pp. 131–186). Erlbaum.
Haruno, M., Wolpert, D. M., & Kawato, M. (2001). Mosaic model for sensorimotor learning and control. Neural Computation, 13(10), 2201–2220.
Hebb, D. O. (1949). The organization of behavior; A neuropsychological theory. Wiley.
Hoang, H., Lang, E. J., Hirata, Y., Tokuda, I. T., Aihara, K., Toyama, K., Kawato, M., & Schweighofer, N. (2020). Electrical coupling controls dimensionality and chaotic firing of infe- rior olive neurons. PLoS Computational Biology, 16(7), 1–26.
Honda, T., Nagao, S., Hashimoto, Y., Ishikawa, K., Yokota, T., Mizusawa, H., & Ito, M. (2018). Tandem internal models execute motor learning in the cerebellum. Proceedings of the National Academy of Sciences, 115(28), 7428–7433.
Hong, S., & Optican, L. M. (2008). Interaction between Purkinje cells and inhibitory interneurons may create adjustable output waveforms to generate timed cerebellar output. PLoS One, 3(7), e2770.
Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences, 79, 2554–2558.
Hull, C. (2020). Prediction signals in the cerebellum: Beyond supervised motor learning. eLife, 9, e54073.
Ishikawa, T., Shimuta, M., & Häusser, M. (2015). Multimodal sensory integration in single cerebellar granule cells in vivo. eLife, 4, e12916.
Ito, M. (1970). Neurophysiological aspects of the cerebellar motor control system. International Journal of Neurology, 7(2), 162–176.
Ito, M. (1975). Learning control mechanisms by the cerebellum investigated in the flocculo-vestibulo-ocular system. In D. Tower (Ed.), The nervous system (Vol. 1, pp. 245–252). Raven Press.
Ito, M. (1982). Cerebellar control of the vestibulo-ocular reflex–around the flocculus hypothesis. Annual Review of Neuroscience (Palo Alto, CA), 5, 275–297.
Ito, M. (1984). The cerebellum and neural control. Raven Press.
Ito, M. (1989). Long-term depression. Annual Review of Neuroscience (Palo Alto, CA), 12, 85–102.
Ito, M. (2008). Control of mental activities by internal models in the cerebellum. Nature Reviews Neurology, 9, 304–313.
Ito, M. (2012). The cerebellum: Brain for the implicit self. FT Press.
Ito, M., Sakurai, M., & Tongroach, P. (1982). Climbing fibre induced depression of both mossy fibre responsiveness and glutamate sensitivity of cerebellar purkinje cells. The Journal of Physiology, 324, 113–134.
Jefress, L. A. (1948). A place theory of sound localization. Journal of Comparative and Physiological Psychology, 41(1), 35–39.
Johansson, F., Hesslow, G., & Medina, J. F. (2016). Mechanisms for motor timing in the cerebellar cortex. Current Opinion in Behavioral Sciences, 8, 53–59.
Jörntell, H., Fredrik, B., Schonewille, M., & Zeeuw, C. I. D. (2010). Cerebellar molecular layer interneurons - computational properties and roles in learning. Trends in Neurosciences, 33, 524–532.
Kandel, E. R., Schwartz, J. H., & Jessell, T. M. (Eds.). (2000). Principles of neural science (4th ed.). McGraw-Hill Medical.
Kawato, M., Furukawa, K., & Suzuki, R. (1987). A hierarchical neural-network model for control and learning of voluntary movement. Biological Cybernetics, 57, 169–185.
Kawato, M., & Gomi, H. (1992). A computational model of four regions of the cerebellum based on feedback-error learning. Biological Cybernetics, 68, 95–103.
Kawato, M., Ohmae, S., Hoang, H., & Sanger, T. (2021). 50 years since the marr, ito, and albus models of the cerebellum. Neuroscience, 462, 151–174.
Kenyon, G. T., Medina, J. F., & Mauk, M. D. (1998a). A mathematical model of the cerebellar-olivary system I: Self-regulating equilibrium of climbing fiber activity. Journal of Computational Neuroscience, 5, 17–33.
Kenyon, G. T., Medina, J. F., & Mauk, M. D. (1998b). A mathematical model of the cerebellar-olivary system II: Motor adaptation through systematic disruption of climbing fiber equilibrium. Journal of Computational Neuroscience, 5, 71–90.
Kitazawa, S. (2002). Optimization of goal-directed movements in the cerebellum: A random walk hypothesis. Neuroscience Research, 43(4), 289–294.
Knogler, L. D., Markov, D. A., Dragomir, E. I., Stih, V., & Portugues, R. (2017). Sensorimotor representations in cerebellar granule cells in larval zebrafish are dense, spatially organized and non-temporally patterned. Current Biology, 27(9), 1288–1302.
Kotaleski, J. H., Lester, D., & Blackwell, K. T. (2002). Subcellular interactions between parallel fibre and climbing fibre signals in Purkinje cells predict sensitivity of classical conditioning to interstimulus interval. Integrative Physiological and Behavioral Science, 37, 265–292.
Koziol, L. F., et al. (2012). From movement to thought: Executive function, embodied cognition, and the cerebellum. Cerebellum, 11(2), 505–525.
Kulkarni, T. D., Narasimhan, K., Saeedi, A., & Tenenbaum, J. (2016). Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, & R. Garnett (Eds.), Advances in neural information processing systems 29 (pp. 3675–3683). Curran Associates, Inc.
Lisberger, S. G. (1988). The neural basis for learning of simple motor skills. Science, 242(4879), 728–735.
Lisberger, S. G. (1994). Neural basis for motor learning in the vestibuloocular reflex of primates. III. Computational and behavioral analysis of the sites of learning. Journal of Neurophysiology, 72(2), 974–998.
Lisberger, S. G., & Sejnowski, T. J. (1992). Motor learning in a recurrent network model based on the vestibulo–ocular reflex. Nature, 360, 159–161.
Llinás, R., & Sugimori, M. (1980). Electrophysiological properties of in vitro purkinje cell somata in mammalian cerebellar slices. The Journal of Physiology, 305, 171–195.
Llinás, R. R. (2011). Cerebellar motor learning versus cerebellar motor timing: The climbing fibre story. Journal of Physiology, 589(14), 3423–3432.
Majoral, D., Zemmar, A., & Vicente, R. (2020). A model for time interval learning in the Purkinje cell. PLoS Computational Biology, 16(2), e1007601.
Marr, D. (1969). A theory of cerebellar cortex. Journal of Physiology (London), 202, 437–470.
Masuda, N., & Amari, S. (2008). A computational study of synaptic mechanisms of partial mem- ory transfer in cerebellar vestibulo-ocular-reflex learning. Journal of Computational Neuroscience, 24, 137–156.
Mauk, M. D., & Donegan, N. H. (1997). A model of Pavlovian eyelid conditioning based on the synaptic organization of the cerebellum. Learning & Memory, 3, 130–158.
Medina, J. F., & Mauk, M. D. (1999). Simulations of cerebellar motor learning: Computational analysis of plasticity at the mossy fiber to deep nucleus synapse. Journal of Neuroscience, 19, 7140–7151.
Miall, R. C., & Stein, J. F. (1993). Is the cerebellum a smith predictor? Journal of Motor Behavior, 25(3), 203–216.
Michikawa, T., Yoshida, T., Kuroki, S., Ishikawa, T., Kakei, S., Itohara, S., & Miyawaki, A. (2020). Distributed sensory coding by cerebellar complex spikes in units of cortical segments. bioRxiv.
Miles, F., & Lisberger, S. (1981). Plasticity in vestibulo-ocular reflex: A new hypothesis. Annual Review of Neuroscience (Palo Alto, CA), 4, 273–299.
Moore, J. W., Desmond, J. E., & Berthier, N. E. (1989). Adaptively timed conditioned responses and the cerebellum: A neural network approach. Biological Cybernetics, 62, 17–28.
Olshausen, B. A., & Field, D. J. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381, 607–609.
Paulin, M. (1989). A Kalman filter theory of the cerebellum. In Dynamic interactions in neural networks: Models and data (pp. 239–259). Springer.
Porrill, J., & Dean, P. (2008). Silent synapses, LTP, and the indirect parallel-fibre pathway: Com- putational consequences of optimal cerebellar noise-processing. PLoS Computational Biology, 4(5), e1000085.
Ramnani, N. (2006). The primate cortico-cerebellar system. Nature Reviews Neuroscience, 7(7), 511–522.
Ramnani, N. (2014). Automatic and controlled processing in the cortico-cerebellar system. In N., R (Ed.), Cerebellar learning (Vol. 210, pp. 255–285). Elsevier.
Raymond, J. L., & Medina, J. F. (2018). Computational principles of supervised learning in the cerebellum. Annual Review of Neuroscience (Palo Alto, CA), 41, 233–253.
Rosenblatt, M. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65, 386–408.
Rössert, C., Dean, P., & Porrill, J. (2015). At the edge of chaos: How cerebellar granular layer network dynamics can provide the basis for temporal filters. PLoS Computational Biology, 11, e1004515.
Schweighofer, N., Doya, K., & Lay, F. (2001). Unsupervised learning of granule cell sparse codes enhances cerebellar adaptive control. Neuroscience, 103, 35–50.
Spanne, A., & Jörntell, H. (2015). Questioning the role of sparse coding in the brain. Trends in Neurosciences, 38(7), 417–427.
Steuber, V., & Willshaw, D. (2004). A biophysical model of synaptic delay learning and temporal pattern recognition in a cerebellar Purkinje cell. Journal of Computational Neuroscience, 17, 149–164.
Streng, M. L., Popa, L. S., & Ebner, T. J. (2018). Complex spike wars: A new hope. The Cerebellum, 17, 735–746.
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction (2nd ed.). MIT Press.
Tabata, H., Yamamoto, K., & Kawato, M. (2002). Computational study on monkey vor adaptation and smooth pursuit based on the parallel control-pathway theory. Journal of Neurophysiology, 87, 2176–2189.
Tokuda, I. T., Han, C. E., Aihara, K., Kawato, M., & Schweighofer, N. (2010). The role of chaotic resonance in cerebellar learning. Neural Networks, 23(7), 836–842.
Tyrrell, T., & Willshaw, D. (1992). Cerebellar cortex: Its simulation and the relevance of Marr’s theory. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 336(1277), 239–257.
Wagner, M. J., Kim, T. H., Savall, J., Schnitzer, M. J., & Luo, L. (2017). Cerebellar granule cells encode the expectation of reward. Nature, 544, 96–100.
Welsh, J. P., Yamaguchi, H., Zeng, X.-H., Kojo, M., Nakada, Y., Takagi, A., Sugimori, M., & Llinás, R. R. (2005). Normal motor learning during pharmacological prevention of purkinje cell long-term depression. Proceedings of the National Academy of Sciences, 102(47), 17166–17171.
Widrow, B., et al. (1975). Adaptive noise cancelling: Principles and applications. Proceedings of the IEEE, 63, 1692–1716.
Wolpert, D. M., & Kawato, M. (1998). Multiple paired forward and inverse models for motor control. Neural Networks, 11(7–8), 1317–1329.
Wolpert, D. M., Miall, R. C., & Kawato, M. (1998). Internal models in the cerebellum. Trends in Cogntive Sciences, 2(9), 338–347.
Yamazaki, T., & Lennon, W. (2019). Revisiting a theory of cerebellar cortex. Neuroscience Research, 148(11), 1–8.
Yamazaki, T., & Nagao, S. (2012). A computational mechanism for unified gain and timing control in the cerebellum. PLoS One, 7(3), e33319.
Yamazaki, T., Nagao, S., Lennon, W., & Tanaka, S. (2015). Modeling memory consolidation during posttraining periods in cerebellovestibular learning. Proceedings. National Academy of Sciences. United States of America, 112, 3541–3546.
Yamazaki, T., & Tanaka, S. (2007). The cerebellum as a liquid state machine. Neural Networks, 20, 290–297.
Yamazaki, T., & Tanaka, S. (2009). Computational models of timing mechanisms in the cerebellar granular layer. Cerebellum, 8, 423–432.
Acknowledgments
This article is based on a number of previous and current collaborations with both theoretical and experimental neuroscientists. In particular, we would like to thank Professors Shigeru Tanaka and Soichi Nagao for their mentoring and long-term support on conducting theoretical studies on the cerebellum. We also thank Dr. William Lennon for our international collaboration and stimulating discussions on artificial intelligence and neuroscience. Professor Narender Ramnani and Mr. Ohki Katakura kindly suggested several references. This paper is based on the results obtained by NEDO Next-Generation AI and Robot Core Technologies, and JSPS Kakenhi Grant Number (JP26430009, JP17H06310). Finally, we would like to thank late Dr. Masao Ito for his inspiring leadership and for bringing this mysterious and interesting brain region to the attention of theoretical neuroscientists worldwide.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Yamazaki, T. (2021). Evolution of the Marr-Albus-Ito Model. In: Mizusawa, H., Kakei, S. (eds) Cerebellum as a CNS Hub. Contemporary Clinical Neuroscience. Springer, Cham. https://doi.org/10.1007/978-3-030-75817-2_11
Download citation
DOI: https://doi.org/10.1007/978-3-030-75817-2_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-75816-5
Online ISBN: 978-3-030-75817-2
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)