
Abstract
Environment semantic maps provide essential information for autonomous vehicles to navigate in complex road scenarios. In this paper, an adversarial network to complement the conventional encoder-decoder semantic segmentation network is introduced. A newly proposed adversarial discriminator is piggybacked to the segmentation network, which is used to improve the spatial continuity and label consistency in a scene without explicitly specifying the contextual relationships. The segmentation network itself serves as a generator to produce an initial segmentation map (pixel-wise labels). The discriminator then takes the labels and compare them with the ground truth data to further update the generator in order to enhance the accuracy of the labeling result. Quantitative evaluations were conducted which show significant improvement on spatial continuity.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
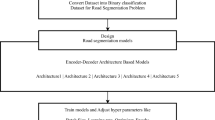
Surrounding understanding is critical to the safety of autonomous vehicles. The ability to recognize the drivable areas and dynamic objects on the road enables the safe navigation. Conventionally, camera frames are used to detect pedestrians, cars, motorcycles, roads, and sidewalks in pixel-level. The goal of this task is to produce semantic segmentations by assigning each input data point, namely a pixel, a unique class label. With the advancements of LiDAR sensor technology in recent years, many commercial products can detect points beyond 200 m. In this paper, we tackled the semantic segmentation task using a rotating LiDAR scanners. Comparing to solely using camera frames, 3D point clouds obtained by LiDAR provide a richer spatial and geometry information. However, the unstructured and sparse nature of the 3D data presents another level of challenges.
The major contribution of this paper is a novel method which can efficiently improve 3D LiDAR point cloud segmentation. We complemented an end-to-end encoder decoder segmentation pipeline with an adversarial network which is derived from Generative Adversarial Network (GAN) [1]. The network improves the spatial continuity and label consistency without explicitly specifying the contextual information. The adversarial network was only applied during model training, and was removed during the online inference stage. The complexity of the overall architecture is kept in minimum.
2 Related Work
Semantic segmentation is one of the most important deep learning applications. In 2D image segmentation, U-Net [2] pioneered the encoder-decoder CNN architecture adoption, they transferred the entire feature map from encoders to the corresponding decoders and concatenates them to up-sampled (via deconvolution) decoder feature maps. In order to reduce memory requirements, Kendall [3] proposed to store the max pooling indices instead of concatenation with fewer parameters for decoder reconstruction.
Nowadays, 360° revolving LiDAR is the most common laser scanner for autonomous driving. In order to address 3D point cloud segmentation using aforementioned 2D segmentation paradigm, common approach is to spherically project the 3D point cloud data onto 2D range image plane. Leading the online frame-rate processing for practical applications, Wu [4] proposed a light weighted model derived from SqueezeNet to process data in 2D image plane. SqueezeSegV2 [5] extended V1 with Contextual Aggregation Module (CAM) [6] to mitigate LiDAR sensor data drop out issues.
A synthetic point cloud generation using GTA-V game engine with intensity rendering was also proposed to augment the training data. Due to nonhomogeneous spatial distribution of point cloud, SqeeuzeSegV3 [7] proposed Spatial-Adaptive Convolutions (SAC) which may change the weights according to the input data location. Miliotos [8] extended Wu [4] 3 label classes to 19 classes and replace extended the label classes from three to nineteen, and replaced the 2D CRF to 3D GPU-based nearest neighbor search acting directly on the full, un-ordered point cloud. This last step helps the retrieval of labels for all points in the cloud, even if they are occluded in the range image.
Cortinhal [9] transformed the deep network with Bayesian treatment by introducing uncertainty measures, epistemic and aleatoric noises. Luc [10] introduced an adversarial network to discriminate the predicted segmentation maps either from the ground truth or segmentation network to mitigate the higher order label inconsistencies. Souly [11] introduced a semi-supervised segmentation using weakly labelled data for the generator. In this paper, the proposed MamboNet was inspired by many of these approaches and mostly by Luc’s adversarial network.
3 Method
-
A.
3D to 2D Projection
The projection method as mentioned in [4, 5, 7,8,9] has been applied for data preprocessing. Each raw 3D point cloud in 360° surrounding is spherical projected onto a 2D grid point on a range image as illustrated in Fig. 1. A 3D point (x, y, z) with respect to the world coordinate system originated at the sphere center is projected to the image with coordinates of (\(\theta_{loc}\), \(\varphi_{loc}\)), which is calculated as follows:
Here, \(\Delta \theta\) and \(\Delta \phi\) are quantization steps. Each grid point represents a five-dimensional feature vector: three for its associated 3D location (x, y, z), one for the intensity value, and the other for the range value.

Spherical projection
-
B. Architecture
The main objective of applying adversarial network is to enforce the spatial continuity and label consistency. Conventional encoder-decoder network [3] creates a segmentation map (pixel-wise labeling), and then follows up with conditional random field (CRF) to impose pixel grouping constraints. We replaced CRF with a discriminator which is only used during the training and can be dropped in inference to maintain minimum network complexity and it is similar to bag of freebies in [11]. Our adversarial network (shown in Fig. 2) is similar to [10], the discriminator takes two inputs, namely, predicted and ground truth maps. Both maps are concatenated with the same 2D input data. The predicted map is generated by the encoder-decoder semantic segmentation network.

Overall network architecture
A detailed version of the generator is shown in Fig. 3, each yellow block of the encoder is an Inception [13] like module with a group of mixed kernel sizes and dilation rates. Each block has three parallel convolution layers, the outputs are concatenated and then summed up with forth convolution layer. Between encoder and decoder, an Astrous Spatial Pyramid Pooling (ASPP) [2] module is inserted for exploiting multi-scale features and enlarging the receptive field. ASSP is employed to capture small street objects, such as pedestrian and cyclists. In decoder, the conventional transpose convolution layer is replaced with the low computation pixel-shuffle layer, similar to super resolution [14]. It can leverage low resolution feature map to generate up-sampled feature maps by converting information of the channel dimension to the spatial dimension. The operation is to convert a feature map of \(\left( {H\, \times \,{ }W\,{ } \times { }\,Cr^{2} } \right)\) to \(\left( {Hr\,{ } \times \,{ }Wr\, \times { }\,C} \right),\) where H, W, C and r are the height, width, number of channel, and up-sampling factor.

Details of the generator
The discriminator is a VGG based convolutional network shown in Fig. 4. The data size is 2048 × 64 × 6. The first two dimensions are the image width and height, and the third dimension includes x, y, z, intensity, range, and class label. Each layer uses 3 × 3 convolution kernel and is followed by a 2 × 2 max pooling except for the 1st layer. The sizes of the last three fully connected layers are 2048, 512, and 512, respectively.

Discriminator: VGG based convolutional network
-
C.
Loss Function and Training
The training, shown in Fig. 5, is based on conditional GAN (cGAN) [15] architecture. The discriminator, D, learns to classify fake (predicted semantic map) and real (ground truth map). Both generator and discriminator observe the same 2D range imagery input.

Conditional GAN training: map 2D range imagery to segmentation map.
There are three lost terms, the first term is the general cross-entropy term for segmentation network (generator), \(S\left( \cdot \right),\) to predict each location (pixel-wise) of the output map with independent class label. It is a weighted cross-entropy loss as is expressed as.
where Y and S are the one-hot vector maps for ground truth and predicted label, respectively. Due to the imbalance data nature of the street scene, pedestrians and cyclists are less seen compared to other cars, the way to mitigate the network biases toward to the classes with higher frequency of occurrence is to add a weighted factor f. The second term is the Lovász -Softmax loss [16]. The loss is used to improve the intersection-of-union (IoU) or Jaccard index. The convex Lovász extension of submodular losses relaxes the IoU hypercube constraint where each vertex is a plausible combination of the class labels. Therefore, IoU score can be defined anywhere inside the hypercube. This term is expressed as
where xi(c) ∈ [0,1] is the pixel-wise predicted probability, yi(c) is the predicted label. The loss will penalize the wrong prediction.
The third term is the adversarial loss which can be expressed as.
where D is the discriminator which produces Real and Fake binary outputs, and G generates the predicted label, x is the 2D range image, z is the optional random noise input, \(P_{gt}\) is the distribution of ground truth label, y, and \(P_{p}\) is the distribution of the predicted label.
D tries to maximize the Jensen-Shannon divergence [1] between \(P_{gt} { }\) and \(P_{p}\). On the contrary, G tries to minimize the same distribution divergence in order to make \(P_{p}\). Indistinguishable from \(P_{gt}\). The final objective is a mix-max optimization of the loss summation of cross entropy, Lovász -Softmax and adversarial terms as shown in Eq. (5)
4 Experiments
Semantic KITTI data set [17] was used for algorithm evaluation. The dataset contains 28 classes including classes of non-moving and moving objects. The scanned sequences of 0–10 except 8 were used for training, and sequence 8 was used for validation. Sequences 11–21 was used for testing, however, the annotations for the testing sequence are not available to the general public. In order to evaluate the performance, the labeled data were submitted to Semantic KITTI official server for test results. The evaluation metric is based on Jaccard Index or mean Intersection-over-Union (IoU) metric as shown in the Eq. (6).
where TP, FP, and FN correspond to the number of true positive, false positive, and false negative predictions for class c, and C is the number of classes.
-
A.
Quantitative Results
In Table 1, our method not only out performs most of the 3D point-wise methods [18,19,20,21], but also is superior to other projection based methods, especially in small object segmentation, such as person, bicyclist, and motor-cyclist categories. We compare our method with two other networks, the first one is the SalsaNext baseline [9], and the second one is the SalsaNext augmented with a discriminator. The discriminator is a VGG-based convolutional network. In the beginning, we trained the SalsaNext baseline using their open source Github repository, and the test result of mIOU is 57.2, which is a little lower than the published result (59.5) [9]. The discrepancy can be due to the limited batch size [15] in our single board training configuration. In Table 1, SalsaNext with discriminator outperforms baseline in 15 out of 19 categories, and the mIOU of 57.9 is slightly improved. Our method, MamboNet, achieves over one percent mOUT improvement of 58.5.
-
B.
Qualitative Results
In Fig. 6, four blocks of segmented map results are shown for visual examination. Each block has three maps, the top is the SalsaNext baseline, the middle one is our method with adversarial discriminator, and the bottom one is the ground true for comparison.

Qualitative evaluation with four examples: the top strip of each example is the result without adversary training, the middle strip is with adversary training, and the bottom strip is the ground-truth label.
In the top strip of the first example, there is a small mis-classified pink circle inside the dark purple region (road). The middle strip of the same example, the circle disappears due to the discriminator power of enforcing regional consistency. The same rectification can be observed in the second and third examples, all middle strips correctly identify the fence region (brown), while the top strip mis-classify part of the fence to be the building regions (yellow). Finally in the fourth example, the top strip also misclassifies portion of light green (terrain) to be dark green (vegetation), however, the middle strip correctly identifies the terrain area.
5 Conclusion
We augmented an encoder-decoder segmentation network with an adversarial network to improve the semantic segmentation performance. Adversarial network can implicitly enforce the regional contextual continuity. Unlike conventional CRF and KNN post processing techniques, the adversarial is learnt only during the offline training and is not active during the test. Therefore, the online computation is greatly reduced and yet the comparable results are still attainable.
References
Goodfellow, I.J., et al.: Generative adversarial networks. In: NIPS (2014)
Ronneberger, O., Fischer, P., Brox, T.: U-net: convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention (2015)
Kendall, A., Badrinarayanan, V., Cipolla, R.: Bayesian SegNet: model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. In: Proceedings of the British Machine Vision Conference (BMVC), pp. 57.1–57.12. BMVA Press (2017)
Wu, B., Wan, A., Yue, X., Keutzer, K.: Squeezeseg: convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D lidar point cloud. In: ICRA (2018)
Wu, B., Zhou, X., Zhao, S., Yue, X., Keutzer, K.: Squeezesegv2: improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In: ICRA (2019)
Yu, F., Koltun, V.: Multi-scale context aggregation by dilated convolutions. In: ICLR (2016)
Xu, C., et al.: Squeezesegv3: spatially-adaptive convolution for efficient point-cloud segmentation, arXiv:2004.01803 (2020)
Milioto, A., Vizzo, I., Behley, J., Stachniss, C.: RangeNet++: fast and accurate LiDAR semantic segmentation. In: IROS (2019)
Cortinhal, T., Tzelepis, G., Aksoy, E.E., SalsaNext: fast, uncertainty-aware semantic segmentation of LiDAR point clouds for autonomous driving, arXiv:2003.03653 (2020)
Luc, P., Couprie, C., Chintala, S., Verbeek, J.: Semantic segmentation using adversarial network. In: 2016, Workshop on Adversarial Training, in NIPS (2016)
Souly, N., Spampinato, C., Shah, M.: Semi supervised semantic segmentation using generative adversarial network. In: ICCV (2017)
Bochkovskiy, A., Wang, C.Y., Liao, H.Y.M.: YOLOv4: Optimal Speed and Accuracy of Object Detection, arXiv:2004:10934 (2020)
Szegedy, C., et al.: Going deeper with convolutions. In: CVPR (2015)
Shi, W., et al.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: CVPR (2016)
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-Image translation with conditional adversarial networks. In CVPR (2017)
Berman, M., Triki, A.R., Blaschko, M.B.: The Lovász-softmax loss: a tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In: CVPR (2018)
Behley, J., et al.: SemanticKITTI: a dataset for semantic scene understanding of LiDAR sequences. In: Proceedings of International Conference on Computer Vision, Seoul, Korea, p. 17 (2019)
Hu, Q., et al.: Randla-net: efficient semantic segmentation of largescale point clouds. In: CVPR (2020)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: deep learning on point sets for 3D classification and segmentation. In: CVPR (2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: deep hierarchical feature learning on point sets in a metric space. In: NIPS (2017)
Rosu, R.A., Schütt, P., Quenzel, J., Behnke, S.: LatticeNet: Fast Point Cloud Segmentation Using Permutohedral Lattices, arXiv:1912.05905 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, JL., Tsai, A., Fuh, CS., Huang, F. (2021). MamboNet: Adversarial Semantic Segmentation for Autonomous Driving. In: Nguyen, M., Yan, W.Q., Ho, H. (eds) Geometry and Vision. ISGV 2021. Communications in Computer and Information Science, vol 1386. Springer, Cham. https://doi.org/10.1007/978-3-030-72073-5_27
Download citation
DOI: https://doi.org/10.1007/978-3-030-72073-5_27
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-72072-8
Online ISBN: 978-3-030-72073-5
eBook Packages: Computer ScienceComputer Science (R0)