
Abstract
Remote sensing image scene interpretation has many applications on land use land covers; thanks to many satellite technologies innovations that generate high-quality images periodically for analysis and interpretation through computer vision techniques. In recent literature, deep learning techniques have demonstrated to be effective in image feature learning thus aiding several computer vision applications on land use land cover. However, most deep learning techniques suffer from problems such as the vanishing gradients, network over-fitting, among other challenges of which the different literature works have attempted to address from varying perspectives. The goal of machine learning in remote sensing is to learn image feature patterns extracted by computer vision techniques for scene classification tasks. Many applications that utilize data from remote sensing are on the surge, this include, aerial surveillance and security, smart farming, among others. These applications require to process satellite image information effectively and reliably for appropriate responses. This research proposes the deep residual feature learning network that is effective in image feature learning which can be utilizable in a networked environment for appropriate decision making processes. The proposed strategy utilizes short-cut connections and mapping functions for deep feature learning. The proposed technique is evaluated on two publicly available remote sensing datasets and it attains superior classification accuracy results of 96.30% and 92.56% respectively on the Ucmerced and Whu-siri datasets, improving the state-of-the-art significantly.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others
Keywords
- Remote sensing
- Inception architecture
- Batch normalization
- Activation functions
- Residual feature learning
1 Introduction
Remote sensing is a topic of great interest owing its capability to power many applications such as, change detection and classification [1, 2], scene labeling [5], image recognition [6], scene parsing [13], feature localization [14] street scene segmentation [15] among other applications. There are huge volumes of image data that have been collected due to the advancements of satellite and remote sensing sensor technologies. The remotely sensed images contain diverse semantic information on land cover land use. The key problem in remote sensing is to develop algorithms for effective image feature processing to recognize and classify scene images into correct categories independent of scale, illumination, color, clutter, pose positions among the other image features. An interpretation of remote sensing images is a challenging undertaking whose implications are of significance to the many land use applications. The fundamental question is, how can a remote sensing system learn image feature representations effectively given the ever-increasing volumes of image data which are periodically generated with sensor and satellite technology?
To achieve high scene classification accuracy results on remote sensing applications, effective image feature extraction is a key prerequisite [2] before the classification tasks. Most recent literature of remote sensing [1, 2] demonstrate that state-of-the-art classification-results are attained with the deep learning feature extraction techniques. Deep learning [16] provides an architecture for models that are made up of multiple processing layers to learn feature representations of data with many levels of abstractions. Deep learning uncovers complex structures in large datasets by applying effective algorithms to show how a machine should modify its internal parameters that apply to compute the image feature representations, in each layer depending on those in a former layer. The effectiveness of deep learning in feature characterization is apparent in current literature [1, 2] on remote sensing image scene classification tasks. Deep convolutional neural network architectures [23, 24] combine low, mid, and high-level features; extracted by lower, mid, and upper layers of the network respectively. Literature evidence [23, 24] show that the network-depth is of significance in feature-representation thus yields superior classification results [1, 3] on several image datasets. Since deep learning models attain superior classification results, a question arises, is better image-feature learning-dependent entirely by stacking several layers? An interesting finding from literature [2, 6, 24] is that the classification performance with deep learning model seem to depend on their architectural designs. The vanishing/exploding gradient is another problem to deep learning models which hinders network convergence [25, 26]; the layer normalization [28] strategy mitigates [6] this problem. Further, the network degradation problem which is apparent with the increase in depth of the deep learning network models has been proven to be drastically alleviated through adjustments of the network weights by gradually varying the learning rates [29] as the network depth increases. Furthermore, in their work [30, 33], they show that network overfitting is not as a consequence of network-degradation, but rather a network design issue.
The improvements in deep learning network architecture design’s quality improve the performance of many computer vision tasks that rely on well-learned visual-features [24]. The VGGNet [44] has an impressive architecture on feature representation, however, evaluating this network architecture entails high computation cost [24]. The inception network [23] has been utilized in big-data applications [31, 32] for processing huge volume of data with less computational costs. The inception network is complex to modify on different use-cases, for instance, if it is scaled up without considerations of its computations parts, the computation cost can increase significantly, this scenario is elaborated further in [24]. The residual learning [6] achieves superior accuracy in the ImageNet Challenge [6] with a lower computational cost (that is, quick convergence) hence faster training. Inspired with this finding, this work proposes a deep-residual-feature-learning network that is effective in image feature learning in the context of remote sensing. The operation mechanisms of the proposed deep residual feature learning are grounded on the various literature philosophies, i.e., the inception architecture [21], batch normalization [28], residual connections [6], and network layer weight’s adjustments [29]. The subsequent sections of the paper are structured as follows: Sect. 2 provides a concise and comprehensive literature review on works related to this work, Sect. 3.1 presents this paper’s proposed deep residual feature learning method while Sect. 3 discusses the materials and methods which apply in this work. Section 4 presents the results, analysis and discussions. Finally, Sect. 5 concludes this paper.
2 Related Work
This section reviews literature works that are related to this work from seven aspects; this entails 1. inception architecture, 2. activation functions, 3. batch- Normalization, 4. weight initialization, 5. residual feature learning, 6. residual mapping functions, 7. Machine learning, remote sensing, computer vision, and networking.
2.1 Inception Architecture
Result of Arora et al. [34] states that for a dataset to be representable enough with the probability distribution of a very sparse deep-network, then the network architecture can be assembled layer after another through the analysis of correlation statistics for the predecessor layer activations and neurons with very correlated outputs. This statement resonates with the Hebbian principle [35]: neurons that fire together, wire together. Achieving this requires to establish how the structure of an optimum local sparse convolutional-vision network may be approximated and represented with existing dense components [23]. An essential need is the determination of an optimum local architecture which repeats its spatiality, following the claim [34]. Correlated cluster groups form high-correlated units. Units from the initial layers are connected to subsequent ones. It is taken that every unit from the initial layer corresponds to a given region of an input image which groups to feature maps. The fundamental idea of the inception architecture [21] is the introduction of sparsity by replacing fully connected layers with sparse ones, even within the convolutions. This forms “Inception-modules” and they are stacked layer-wise. Given that their output-correlation statistics can vary since high abstraction of features is captured with higher layers, there is a decrease of spatial-concentration. This necessitates feature embedding in dense compressed form to reduce high dimensionality problem [23]. Szegedy et al. [23] apply \( 1 \times 1\) convolutions for dimensionality reduction prior to utilizing the costly \( 3 \times 3\) and \(5 \times 5\) convolutions. Additionally, the inception architecture uses the rectified linear unit (ReLU) activation’s with the convolutions (see Fig. 1(c)) to improve on the network sparse representation. Figure 1 depicts the various versions of the inception architecture. Inception networks are generally very deep and they do replace a filter integration phase of inception architectures with residual connections. This allows the inception to take advantage of the residual strategy whereas it retains its computation efficiency [21].

2.2 Activation Function: Rectified Linear Unit
The use of an appropriate activation function can greatly improve the CNN performance [21]. The rectified linear unit (ReLU) [42] is a common non-saturated activation function which is defined as:
In this case, \(z_{h,i,j}\) is the activation function’s input at position (h, i) on the \(j^{th}\) channel. The ReLU function retains the positive part and it discards the negative part. The operation max(.) of the ReLU computes faster than tanh or sigmoid functions. Further, it introduces sparsity to the units of the hidden layer thereby allowing the network to achieve sparse representations.
Batch-Normalization. When the data flow via a deep CNN, the distribution of input-data to inner layers is altered, thereby the network loses capacity of learning. An efficient technique to partly address this problem is Batch-Normalization (BN) [28]. The BN alleviates a so-called “covariate-shift-problem” through a “normalization-step” which estimates the means and variances for layer inputs. The approximations of means and variances are calculated for every mini-batch instead of the whole training set. Consider a layer with k input dimensions that require normalization, that is, \(\textit{x} = \{x_1,x_2,\dots ,x_k \}^T \). The computation for \(l^{th}\) normalization is:
In this case, \(\mu _B\) is the mean and \(\delta ^2_B\) variance of the mini-batch while C is a constant. The normalized input \(\hat{\mathbf{x }}_l\) representation power is improved through transformation to:
The parameters \(\beta \) and \(\gamma \) are learned. Batch-normalization is advantageous to global data-normalization in many ways. First, it minimizes the inner layers covariant-shift. Second, Batch-normalization minimizes the reliance of gradients on the ratio of parameters, this yields a beneficial result on the flow of gradient through CNN. Additionally, batch-normalization regularizes the model therefore there is no need for Dropouts. Finally, with BN, the use of saturating nonlinear functions is possible as the BN mitigates risks of getting stuck into a model-saturated-state.
2.3 Weight Initialization
Overfitting is a major problem in deep CNN that can be minimized by network parameter regularization. A Deep convNet contains a massive number of parameters and it is difficult to train it given the non-convex nature of its loss function [17]. To attain quick convergence in training while avoiding the vanishing gradient problem, an appropriate weight initialization of the network is a key prerequisite [18, 19]. Appropriate weight initialization can ensure attainment in breaking the symmetry between inner units of the same layer and the bias parameter can be set to zero. Poor network initialization, for instance, if every layer scales their input with a factor k, the resultant output scales the original inputs by \(k^L\), L denotes the number of network layers. It follows that the value for \(k>1\) leading very large values in output layers whereas if \(k<1\) results to the problem of diminishing gradients and output values. [22] uses a Gaussian distribution with a zero-mean and standard deviation of 0.01 for initialization. Xavier [26] apply Gaussian distribution with a variance of \(2/(n_{input} + n_{output})\) and a zero-mean. In this case, \(n_{input}\) denotes the number of neurons inputs while \(n_{output}\) depicts the number of output neurons that feed to another layer. Therefore, the weight initialization [26] automatically establishes the initialization scale from the number of inputs and outputs. Caffe [20] is a variant of the Xavier method and it applies the \(n_{input}\) only, thus its easier to implement. He et al. [29] extends the Xavier model and derives a robust weight initialization method that considers ReLU. Their method [29] facilitates training of very deep models [23] which converges whereas with the Xavier technique [26] it does not converge.
2.4 Residual Feature Learning
In image classification, the integration of local image descriptors form compact encoded feature representations, that is, Vector of Locally Aggregated Descriptors (VLAD) [36] that can be seen as visual vocabularies of a dictionary [38]. Fisher Vectors [39] can also be thought of as probabilistic representations of VLAD. These aggregation strategies are very powerful for shallow image feature representation in image classification [40]. With vector quantization, residual vector encoding [27] demonstrates to be more effective [6] as compared to original vector encoding.
2.5 Residual Mapping Functions
To address the network degradation problem, [6] proposes explicit fitting of residual mappings to layers instead of the implicit stacking of layers which assumes “desired fits of underlying mappings”. Formally, the “desired-underlying mapping” is depicted as H(x), where the stacked-nonlinear layers fits a different mapping of \(F(x):= H(x) - x\) [6]. This means that original mapping can be reformulated to \(F(x) + x\), thus it is simpler to optimize the residual mapping function compared to optimizing the original and un-referenced mapping. The formulation of residual mapping \(F(x) + x\) is realizable through the feed-forward-networks with “shortcut-connections” Fig. 2. The shortcut-connections [21, 41] skips one or more network layers. Their purpose is to achieve “identity” mapping while their outputs are included in the stacked layer’s outputs, see Fig. 2. The advantage of identity shortcut-connections mappings is that they add no extra computational cost or parameter.

A building block for residual learning [6]
2.6 Machine Learning, Remote Sensing, Computer Vision, and Networking
Machine learning [7] enables computer systems to process data and make deductions based on knowledge learned. Pattern recognition problems that leverage machine learning include, classification, clustering, and regression [7]. The softmax logistic regression [9], and support vector machine [8] are the popular machine learning techniques utilized in scene classification of remote sensing images. The goal of machine learning in remote sensing is to learn image feature patterns extracted by computer vision techniques for scene classification tasks. Of recent years, machine learning applications which utilize remote sensing data are on the surge, this include, smart farming [10], crop diseases/pests [11], aerial surveillance and security [12], among others. These applications require to process satellite image information effectively and reliably for appropriate responses. Convolutional neural networks extract image features effectively [2], and this information should be transmittable to various monitoring centers reliably through computer networks. This work focuses on effective feature processing of satellite images which can be utilizable in a networked environment for appropriate decision making processes.
3 Materials and Methods
This section presents and discusses the operation mechanism of the deep residual feature learning method. Further, the section discusses properties of remote sensing datasets which apply in evaluating the effectiveness of the proposed deep residual feature learning technique. Furthermore, details on the experimental procedures are given in this section.
3.1 Residual Feature Learning Network
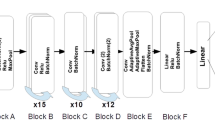
This work develops and presents an algorithm and network architecture that utilizes the principle of residue learning [6] in remote sensing images scene classification. Figure 3 shows the architecture and algorithm of the proposed deep residual learning method. The deep residual-learning-network-architecture has 20 layers, further, its design adopts principles of the inception module [21, 24] (depicted in Fig. 1; b and c).

Deep residual learning network architecture for remote sensing image scene classification
3.2 A Residual Feature Learning Algorithm
Consider a mapping function H(x) that fit some stacked layers, where x depicts the input into first layers. Multiple nonlinear layers can approximate asymptotically functions which are complex [6], similarly, they can approximate asymptotically the residual functions, that is, \(H(x) - x\) (for same input and output dimensions). Therefore, instead of stacked functions approximating H(x), they approximate a residual function \(F(X):= H(x)-x\), this can be reformulated to \(F(x) + x\) (a form that is equivalent to the original function H(x)). The reformulation \(F(x) + x\) addresses the network degradation problem. This means that, with added network layers configured as identity-mappings, more deep models should contain same training errors as the shallower counterpart network models. The residual learning algorithm learns the residual mapping building blocks Fig. 2 which as formulated as:
where x and y are vectors for the input and output of the considered layers. Whereas \(F(x\{W_i\})\) is residue mapping function that is learned; for stacked layers (e.g. Fig. 2) where they are two, \(F= W_2\sigma (W_1x)\), in this case \(\sigma \) depict a nonlinear learning function ReLU [42]. The residual mapping operation \(F + x\) is conducted via short-cut connection with element wise addition. And for subsequent stacked layers with shortcut connection, where the dimensions of F and x are different, a linear projection \(W_s\) is performed with the shortcut-connections so as to achieve dimension matching:
The function \(F(x,\{W_i\})\) represents many convolutional layers.

3.3 Deep Residual Feature Learning Architecture
Figure 3 depicts the residual network learning architecture which is motivated by the VGG net [44] philosophy and deep residual learning [6] works. The convolutional layer comprises \(3 \times 3\) filters that apply two design principles: 1) for outputs of feature maps with the same size, the network layers comprise the same filter numbers. 2) when sizes of the feature maps are halved, the filter numbers are doubled to maintain the time complexity in every layer. Downsampling is done on convolutional layers with strides of 2. Shortcut connections are placed in Fig. 2 to the network layers turning it to a residual learning network; Eq. (4) achieves this. Equation (5) performs shortcut projections for dimension matching (normally done with \(1 \times 1\) convolutions).
3.4 Remote Sensing Datasets
This section discusses the properties of remote sensing datasets which apply in evaluating the effectiveness of the deep residual feature learning method that is proposed in this study.
UCMerced Dataset. UCMerced dataset [38] consist of 21 classes (Fig. 4) and each class contain 100 images with three color channels. Each image dimension is \(256\times 256\) pixels and they have a spatial resolution of 1-ft. The classes are highly overlapped e.g. (agricultural and forest are differ by vegetation cover; dense residence and medium residence differ by the number of units), this diverse image content pattern is a challenge for effective feature representations. Further, the images of ucmerced dataset have many common low-level features with multipurpose visible images hence they are suitable candidates for fine-tuning with pre-trained convolutional neural networks.

Sample images of UCMerced dataset [38]
WHU-SIRI Dataset. WHU-SIRI Dataset [49] comprises of 12 classes (Fig. 5) with a total of 2400 aerial images with three color channels. Each class contains 200 image samples with a size of \(200\times 200\) pixels and 2 m of spatial resolution. WHUR-SIRI images are in different scales, orientations under differing lighting conditions. These dataset properties are diverse and challenging thus requiring effective feature learning techniques for accurate scene analysis and interpretation.

Sample images of WHU-SIRI dataset [49]
3.5 Experiment Setups
The experiments evaluate the effectiveness and efficiency of the deep residual learning network on two publicly available datasets Ucmerced [38] and WHU-SIRI [49] whose properties are described under the Sect. 3.4 remote sensing datasets above. The datasets are split into different train, validation and test ratios (i.e. 70:20:10, for UCMerced) and (150:40:10, WHU-SIRI) with 30, 20, 30 epochs; in batches of 32. Five experiments are conducted and optimal results are reported in both cases.
The training experiment is set up on TensorFlow [43] and implementation adopts the practices in [6, 44]. Input images are sampled at [256/200] on scale augmentation of 0.2, and shear of 0.2 is applied (refer to the source-code: a link provided in the appendix). This research uses batch normalization (BN) [28] immediately after every convolution prior to applying the ReLU [42] activation function. The weight initialization follows [29] while the residual feature learning network is trained from scratch. This research applies the Adam optimizer [45] that utilizes stochastic gradient descent to attain faster convergence. The deep residual-feature learning-network is trained with CHPC-GPU, on the lengau cluster (This a high performance GPU owned by the ministry of education, South Africa).
4 Results, Analysis, and Discussion
The experimental results are shown in Tables 1 and 2. For performance evaluation, overall accuracy [3] metrics and confusion matrix [3] are applied.

Confusion matrix of deep residual feature learning network on Whu dataset

Confusion matrix of deep residual feature learning network on UCMerced dataset
4.1 Analysis and Discussion of Results
From Tables (1 and 2), it is observed that the deep networks image feature learning techniques [4, 47, 50], attain superior classification result with the two remote sensing datasets as compared to low-level feature learning methods [38, 48, 49]. This is consistent with the fact that deep learning [16] provides an architecture for models that are made up of multiple processing layers to learn feature representations of data with many levels of abstractions to uncovers complex structures in large datasets. Figures 6 and 7 gives the confusion matrices with test images on Whu and Ucmerced datasets respectively. It can be observed that there are few confusions in predictions for Fig. 6 than those of Fig. 7. A possible reason for this maybe that in pattern recognition problems feature learning algorithms to exhibit performance variations on different datasets. This means that the utilization of a particular algorithm can result in powerful classifiers with some databases however with the same classifiers trained different datasets utilizing the identical algorithm may be unsteady [46]. This is consistent to the fact that ucmerced dataset has 21 classes whereas the Whu-dataset has 12 classes. Furthermore, a close analysis on Fig. 7 depicts that there is confusion among dense residential and medium residence, visually the classes are similar even challenging for humans to distinguish. Even though the deep feature-based learning techniques attain good results, there are those deep learning techniques that attain superior classification results. This fact can be attributed to the different design and operation mechanisms that determine how optimal the deep learning technique can be in feature extraction. For instance, the VGG-16 [44] and GoogleNet [23] have 16 and 22 layers respectively. This paper utilizes (a 20-layer network) an intermediate number of layers to the aforementioned network architectures with different design principles, (i.e. residual-connections). Results of Tables 1 and 2 shows the deep residual feature learning network is of significant improvement as compared to the other deep feature learning methods on the same datasets. These show the effectiveness of feature learning of the residual learning network. Owing to these findings, it can be observed that the effectiveness of a deep feature learning network is dependent on the design principles which are taken into consideration when building a deep learning model.
5 Conclusion
This research proposes a deep residual feature learning network that demonstrates to be effective in image feature extraction as evaluated with the ucmerced and whu-rs datasets in Sect. 4. On analysis of the results in Tables 1 and 2, it is evident that the residual learning network achieves better than most deep learning methods in the literature. Additionally, it can be observed from Tables 1 and 2 that the proposed method classification accuracy surpasses the results of other non-deep learning computer vision methods in the literature. Although the results attained by the proposed method are close to those of the other deep learning feature extraction methods in literature; this works gives alternative insights on the novel design approach which utilizes recent literature principles in the context of remote sensing.
Future research work will investigate combining of residual learning networks multiple classifier-fusion in enhancing class prediction accuracies with remote sensing datasets that have more diverse features instead of utilizing only one classifier such as the softmax or the SVM. The recent literature [46] indicate promising trends in this direction.
References
Ma, L., Liu, Y., Zhang, X., Ye, Y., Yin, G., Johnson, B.A.: Deep learning in remote sensing applications: a meta-analysis and review. ISPRS J. Photogrammetry Remote Sens. 152, 166–177 (2019)
Bazi, Y., Al Rahhal, M.M., Alhichri, H., Alajlan, N.: Simple yet effective fine-tuning of deep CNNs using an auxiliary classification loss for remote sensing scene classification. Remote Sens. 11(24), 2908 (2019)
Cheng, G., Han, J., Lu, X.: Remote sensing image scene classification: benchmark and state of the art. Proc. IEEE 105(10), 1865–1883 (2017)
Xia, G.S., et al.: AID: a benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 55(7), 3965–3981 (2017)
Zhou, Q., Zheng, B., Zhu, W., Latecki, L.J.: Multi-scale context for scene labeling via flexible segmentation graph. Pattern Recogn. 59, 312–324 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Boutaba, R., et al.: A comprehensive survey on machine learning for networking: evolution, applications and research opportunities. J. Internet Serv. Appl. 9(1), 16 (2018)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Bishop, C.M.: Pattern Recognition and Machine Learning. Springer, New York (2006)
Tombe, R.: Computer vision for smart farming and sustainable agriculture. In: 2020 IST-Africa Conference (IST-Africa), pp. 1–8. IEEE, May 2020
Wójtowicz, M., Wójtowicz, A., Piekarczyk, J.: Application of remote sensing methods in agriculture. Commun. Biometry Crop Sci. 11(1), 31–50 (2016)
Ghassemian, H.: A review of remote sensing image fusion methods. Inf. Fusion 32, 75–89 (2016)
Bu, S., Han, P., Liu, Z., Han, J.: Scene parsing using inference embedded deep networks. Pattern Recogn. 59, 188–198 (2016)
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2921–2929 (2016)
Pohlen, T., Hermans, A., Mathias, M., Leibe, B.: Full-resolution residual networks for semantic segmentation in street scenes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4151–4160 (2017)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521(7553), 436–444 (2015)
Choromanska, A., Henaff, M., Mathieu, M., Arous, G.B., LeCun, Y.: The loss surfaces of multilayer networks. In: Artificial Intelligence and Statistics, pp. 192–204, February 2015
Mishkin, D., Matas, J.: All you need is a good init. arXiv preprint arXiv:1511.06422 (2015)
Sutskever, I., Martens, J., Dahl, G., Hinton, G.: On the importance of initialization and momentum in deep learning. In: International Conference on Machine Learning. pp. 1139–1147, February 2013
Jia, Y., et al.: Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM International Conference on Multimedia, pp. 675–678. ACM, November 2014
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.A.: Inception-v4, Inception-ResNet and the impact of residual connections on learning. In: Thirty-First AAAI Conference on Artificial Intelligence, February 2017
Russakovsky, O., et al.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 115(3), 211–252 (2015)
Szegedy, C., et al.: Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–9 (2015)
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818–2826 (2016)
Bengio, Y., Simard, P., Frasconi, P.: Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5(2), 157–166 (1994)
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 249–256, March 2010
Martinez-Covarrubias, J.: Algorithms for large-scale multi-codebook quantization. Doctoral dissertation, University of British Columbia (2018)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1026–1034 (2015)
He, K., Sun, J.: Convolutional neural networks at constrained time cost. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5353–5360 (2015)
Schroff, F., Kalenichenko, D., Philbin, J.: FaceNet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815–823 (2015)
Movshovitz-Attias, Y., Yu, Q., Stumpe, M.C., Shet, V., Arnoud, S., Yatziv, L.: Ontological supervision for fine grained classification of street view storefronts. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1693–1702 (2015)
Srivastava, R.K., Greff, K., Schmidhuber, J.: Highway networks. arXiv preprint arXiv:1505.00387 (2015)
Arora, S., Bhaskara, A., Ge, R., Ma, T.: Provable bounds for learning some deep representations. In: International Conference on Machine Learning, pp. 584–592, January 2014
Wadhwa, A., Madhow, U.: Bottom-up deep learning using the Hebbian principle (2016)
Jegou, H., Perronnin, F., Douze, M., Sánchez, J., Perez, P., Schmid, C.: Aggregating local image descriptors into compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 34(9), 1704–1716 (2011)
Liu, Q., Hang, R., Song, H., Zhu, F., Plaza, J., Plaza, A.: Adaptive deep pyramid matching for remote sensing scene classification. arXiv preprint arXiv:1611.03589 (2016)
Yang, Y., Newsam, S.: Bag-of-visual-words and spatial extensions for land-use classification. In: Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, pp. 270–279, November 2010
Perronnin, F., Dance, C.: Fisher kernels on visual vocabularies for image categorization. In: 2007 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE, June 2007
Chatfield, K., Lempitsky, V.S., Vedaldi, A., Zisserman, A.: The devil is in the details: an evaluation of recent feature encoding methods. In: BMVC, vol. 2, no. 4, p. 8, September 2011
Ripley, B.D.: Pattern Recognition and Neural Networks. Cambridge University Press, Cambridge (2007)
Nair, V., Hinton, G.E.: Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning, ICML 2010, pp. 807–814 (2010)
Abadi, M., et al.: TensorFlow: large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467 (2016)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Zhao, H.H., Liu, H.: Multiple classifiers fusion and CNN feature extraction for handwritten digits recognition. Granular Comput. 5(3), 411–418 (2020)
Cheriyadat, A.M.: Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 52(1), 439–451 (2013)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2006, vol. 2, pp. 2169–2178. IEEE, June 2006
Xia, G.S., Yang, W., Delon, J., Gousseau, Y., Sun, H., Maître, H.: Structural high-resolution satellite image indexing, July 2010
Gong, X., Xie, Z., Liu, Y., Shi, X., Zheng, Z.: Deep salient feature based anti-noise transfer network for scene classification of remote sensing imagery. Remote Sens. 10(3), 410 (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Tombe, R., Viriri, S. (2021). Remote Sensing Scene Classification Based on Effective Feature Learning by Deep Residual Networks. In: Renault, É., Boumerdassi, S., Mühlethaler, P. (eds) Machine Learning for Networking. MLN 2020. Lecture Notes in Computer Science(), vol 12629. Springer, Cham. https://doi.org/10.1007/978-3-030-70866-5_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-70866-5_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-70865-8
Online ISBN: 978-3-030-70866-5
eBook Packages: Computer ScienceComputer Science (R0)