
Abstract
Automatically generating natural language descriptions from an image is a challenging problem in artificial intelligence that requires a good understanding of the visual and textual signals and the correlations between them. The state-of-the-art methods in image captioning struggles to approach human level performance, especially when data is limited. In this paper, we propose to improve the performance of the state-of-the-art image captioning models by incorporating two sources of prior knowledge: (i) a conditional latent topic attention, that uses a set of latent variables (topics) as an anchor to generate highly probable words and, (ii) a regularization technique that exploits the inductive biases in syntactic and semantic structure of captions and improves the generalization of image captioning models. Our experiments validate that our method produces more human interpretable captions and also leads to significant improvements on the MSCOCO dataset in both the full and low data regimes.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


1 Introduction
In recent years there has been a growing interest to develop end-to-end learning algorithms in computer vision tasks. Despite the success in many problems such as image classification [17] and person recognition [21], the state-of-the-art methods struggle to reach human-level performance in solving more challenging tasks such as image captioning within limited time and data which involves understanding the visual scenes and describing them in a natural language. This is in contrast to humans who are effortlessly successful in understanding the scenes which they have never seen before and communicating them in a language. It is likely that this efficiency is due to the strong prior knowledge of structure in the visual world and language [11].
Motivated by this observation, in this paper we ask “How can such prior knowledge be represented and utilized to learn better image captioning models with deep neural networks?”. To this end, we look at the state-of-the-art encoder-decoder image captioning methods [3, 39, 41] where a Convolutional Neural Network (CNN) encoder extracts an embedding from the image, a Recurrent Neural Network (RNN) decoder generates the text based on the embedding. This framework typically contains two dynamic mechanisms to model the sequential output: i) an attention module [4, 41] that identifies the relevant parts of the image embedding based on the previous word and visual features and ii) the RNN decoder that predicts the next words based on the its previous state and attended visual features. While these two components are very powerful to model complex relations between the visual and language cues, we hypothesize that they are also capable of and at the same time prone to overfitting to wrong correlations, thus leading to poor generalization performance when the data is limited. Hence, we propose to regulate these modules with two sources of prior knowledge.

Our Final Model with Conditional Latent Topic Attention (CLTA) and Sentence Prior (Sentence Auto-Encoder (SAE) regularizer) both rely on prior knowledge to find relevant words and generate non-template like and generalized captions compared to the same Baseline caption for both images - A man hitting a tennis ball with a racket.
First, we propose an attention mechanism that accurately attends to relevant image regions and better cope with complex associations between words and image regions. For instance, in the example of a “man playing tennis”, the input visual attention encoder might only look at the local features (tennis ball) leaving out the global visual information (tennis court). Hence, it generates a trivial caption as “A man is hitting a tennis ball”, which is not the full description of the image in context (as shown in Fig. 1). We solve this ambiguity by incorporating prior knowledge of context via latent topic models [7], which are known to identify semantically meaningful topics [8], into our attention module. In particular we introduce a Conditional Latent Topic Attention (CLTA) module that models relationship between a word and image regions through a latent shared space i.e. latent topics to find salient regions in an image. Tennis ball steers the model to associate this word with the latent topic, “tennis”, which further is responsible for localizing tennis court in the image. If a region-word pair has a higher probability with respect to a latent topic and if the same topic has a higher probability with respect to some other regions, then it is also a salient region and will be highly weighted. Therefore, we compute two sets of probabilities conditioned on the current word of the captioning model. We use conditional-marginalized probability where marginalization is done over latent topics to find salient image regions to generate the next word. Our CLTA is modeled as a neural network where marginalized probability is used to weight the image region features to obtain a context vector that is passed to a image captioning decoder to generate the next word.
Second, the complexity in the structure of natural language makes it harder to generate fluent sentences while preserving a higher amount of encoded information (high Bleu-4 scores). Although current image captioning models are able to model this linguistic structure, the generated captions follow a more template-like form, for instance, “A man hitting a tennis ball with a racket.” As shown in Fig. 1, visually similar images have template-like captions from the baseline model. This limitation might be due to the challenge of learning an accurate mapping from a high-dimensional input (millions of pixels) to an exponentially large output space (all possible word combinations) with limited data. As the sentences have certain structures, it would be easier to learn the mapping to a lower dimensional output space. Inspired from sequence-to-sequence (seq2seq) machine translation [16, 28, 35, 40], we introduce a new regularization technique for captioning models coined SAE Regularizer. In particular, we design and train an additional seq2seq sentence auto-encoder model (“SAE”) that first reads in a whole sentence as input, generates a lower fixed dimensional vector and, then the vector is further used to reconstruct the input sentence. Our SAE is trained to learn the structure of the input (sentence) space in an offline manner by exploiting the regularity of the sentence space.
Specifically, we use SAE-Dec as an auxiliary decoder branch (see Fig. 3). Adding this regularizer forces the representation from the image encoder and language decoder to be more representative of the visual content and less likely to overfit. SAE-Dec is employed along with the original image captioning decoder (“IC-Dec”) to output the target sentence during training, however, we do not use SAE regularizer at test time reducing additional computations.
Both of the proposed improvements also help to overcome the problem of training on large image-caption paired data [26, 27] by incorporating prior knowledge which is learned from unstructured data in the form of latent topics and SAE. These priors – also known as “inductive biases” – help the models make inferences that go beyond the observed training data. Through an extensive set of experiments, we demonstrate that our proposed CLTA module and SAE-Dec regularizer improves the image captioning performance both in the limited data and full data training regimes on the MSCOCO dataset [26].
2 Related Work
Here, we first discuss related attention mechanisms and then the use of knowledge transfer in image captioning models.
Attention Mechanisms in Image Captioning. The pioneering work in neural machine translation [4, 9, 29] has shown that attention in encoder-decoder architectures can significantly boost the performance in sequential generation tasks. Visual attention is one of the biggest contributor in image captioning [3, 15, 19, 41]. Soft attention and hard attention variants for image captioning were introduced in [41]. Bottom-Up and Top-Down self attention is effectively used in [3]. Attention on attention is used in recent work [19]. Interestingly, they use attention at both encoder and the decoder step of the captioning process. Our proposed attention significantly differs in comparison to these attention mechanisms. First, the traditional attention methods, soft-attention [4] and scaled dot product attention [36] aims to find features or regions in an image that highly correlates with a word representation [3, 4, 34]. In contrast, our conditional-latent topic attention uses latent variables i.e. topics as anchors to find relationship between word representations and image regions (features). Some image regions and word representations may project to the same set of latent topics more than the others and therefore more likely to co-occur. Our method learns to model these relationships between word-representations and image region features using our latent space. We allow competition among regions and latent topics to compute two sets of probabilities to find salient regions. This competing strategy and our latent topics guided by pre-trained LDA topics [7] allow us to better model relationships between visual features and word representations. Hence, the neural structure and our attention mechanism is quite different from all prior work [3, 4, 19, 41].
Knowledge Transfer in Image Captioning. It is well known that language consists of semantic and syntactic biases [5, 30]. We exploit these biases by first training a recurrent caption auto-encoder to capture this useful information using [35]. Our captioning auto-encoder is trained to reconstruct the input sentence and hence, this decoder encapsulates the structural, syntactic and semantic information of input captions. During captioning process we regularize the captioning RNN with this pretrained caption-decoder to exploit biases in the language domain and transfer them to the visual-language domain. To the best of our knowledge, no prior work has attempted such knowledge transfer in image captioning. Zhou et al. [46] encode external knowledge in the form of knowledge graphs using Concept-Net [27] to improve image captioning. The closest to ours is the work of [42] where they propose to generate scene graphs from both sentences and images and then encode the scene graphs to a common dictionary before decoding them back to sentences. However, generation of scene graphs from images itself is an extremely challenging task. Finally, we propose to transfer syntactic and semantic information as a regularization technique during the image captioning process as an auxiliary loss. Our experiments suggest that this leads to considerable improvements, specially in more structured measures such as CIDEr [37].
3 Method
In this section, we first review image captioning with attention, introduce our CLTA mechanism, and then our sentence auto-encoder (SAE) regularizer.
3.1 Image Captioning with Attention
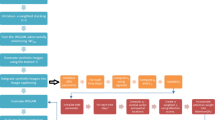
Image captioning models are based on encoder-decoder architecture [41] that use a CNN as image encoder and a Long Short-Term Memory (LSTM) [18] as the decoder – see Fig. 1.
The encoder takes an image as input and extracts a feature set \(v=\{\varvec{v}_1,\ldots ,\varvec{v}_R\}\) corresponding to R regions of the image, where \(\varvec{v}_i \in \mathbb {R}^D\) is the D-dimensional feature vector for the \(i^{th}\) region. The decoder outputs a caption y by generating one word at each time step. At time step t, the feature set v is combined into a single vector \(\varvec{v}^t_a\) by taking weighted sum as follows:
where \(\alpha ^t_i\) is the CLTA weight for region i at time t, that is explained in the next section. The decoder LSTM \(\phi \) then takes a concatenated vector \([\varvec{v}^t_a|\varvec{y}_{t-1}]\) and the previous hidden state \(\mathbf {h_{t-1}}\) as input and generates the next hidden state \(\mathbf {h_t}\):
where, | denotes concatenation, \(\varvec{y}_{t-1}\in \mathbb {R}^K\) is the one-hot vector of the word generated at time \(t-1\), K is the vocabulary size, \(\varvec{h}^t \in \mathbb {R}^{n}\) is the hidden state of the LSTM at time t, n is the LSTM dimensionality, and \(\varTheta _{\phi }\) are trainable parameters of the LSTM. Finally, the decoder predicts the output word by applying a linear mapping \(\psi \) on the hidden state and \(\varvec{v}^t_a\) as follows:
where \(\varTheta _{\psi }\) are trainable parameters. Our LSTM implementation closely follows the formulation in [45]. The word embedding matrix \(E \in \mathbb {R}^{m\times K}\) is trained to translate one-hot vectors to word embeddings as in [41], where m is the word embedding dimension. In the next section, we describe our proposed CLTA mechanism.
3.2 CLTA: Conditional Latent Topic Attention
At time step t, our CLTA module takes the previous LSTM hidden state (\(\varvec{h}^{t-1}\)) and image features to output the attention weights \(\alpha ^t\). Specifically, we use a set of latent topics to model the associations between textual (\(\varvec{h}^{t-1}\)) and visual features (\(\varvec{v}\)) to compute the attention weights. The attention weight for region i is obtained by taking the conditional-marginalization over the latent topic l as follows:
where l is a topic variable in the C-dimensional latent space. To compute \(P(l|h^{t-1}, \varvec{v}_i)\), we first project both textual and visual features to a common C-dimensional shared latent space, and obtain the associations by summing the projected features as follows:
where \(W_{sc}\in \mathbb {R}^{C\times D}\) and \(W_{hc}\in \mathbb {R}^{C\times n}\) are the trainable projection matrices for visual and textual features, respectively. Then the latent topic probability is given by:
Afterwards, we compute the probability of a region given the textual, vision features and latent topic variable as follows:
where \(W_{sr}\in \mathbb {R}^{C\times D}\) and \(W_{hr}\in \mathbb {R}^{C\times n}\) are the trainable projection matrices for visual and textual features, respectively.
The latent topic posterior in Eq. (6) is pushed to the pre-trained LDA topic prior by adding a KL-divergence term to the image captioning objective. We apply Latent Dirichlet Allocation (LDA) [7] on the caption data. Then, each caption has an inferred topic distribution \(Q_T\) from the LDA model which acts as a prior on the latent topic distribution, \(P_L\). For doing this, we take the average of the C-dimensional latent topics at all time steps from \(0,\ldots ,t-1\) as:
Hence, the KL-divergence objective is defined as:
This learnt latent topic distribution captures the semantic relations between the visual and textual features in the form of visual topics, and therefore we also use this latent posterior, \(P_L\) as a source of meaningful information during generation of the next hidden state. The modified hidden state \(\mathbf {h_t}\) in Eq. (2) is now given by:
We visualize the distribution of latent topics in Fig. 2. While traditional “soft-max” attention exploit simple correlation among textual and visual information, we make use of latent topics to model associations between them.

Image-Caption pairs generated from our CLTA module with 128 dimensions and visualization of Top-20 words from the latent topics.
3.3 SAE Regularizer
Encoder-decoder methods are widely used for translating one language to another [4, 10, 35]. When the input and target sentences are the same, these models function as auto-encoders by first encoding an entire sentence into a fixed-(low) dimensional vector in a latent space, and then reconstructing it. Autoencoders are commonly employed for unsupervised training in text classification [13] and machine translation [28].
In this paper, our SAE regularizer has two advantages: i) acts as a soft constraint on the image captioning model to regularize the syntactic and semantic space of the captions for better generalization and, ii) encourages the image captioning model to extract more context information for better modelling long-term memory. These two properties of the SAE regularizer generates semantically meaningful captions for an image with syntactic generalizations and prevents generation of naive and template-like captions.
Our SAE model uses network architecture of [35] with Gated Recurrent Units (GRU) [12]. Let us denote the parameter of the decoder GRU by \(\varTheta _{\text {D}}\). A stochastic variation of the vanilla sentence auto-encoders is de-noising auto-encoders [38] which are trained to “de-noise” corrupted versions of their inputs. To inject such input noise, we drop each word in the input sentence with a probability of 50% to reduce the contribution of a single word on the semantics of a sentence. We train the SAE model in an offline stage on training set of the captioning dataset. After the SAE model is trained, we discard its encoder and integrate only its decoder to regularize the captioning model.
As depicted in Fig. 3, the pretrained SAE decoder takes the last hidden state vector of captioning LSTM \(\varvec{h}\) as input and generates an extra caption (denoted as \(y_{\text {sae}}\)) in addition to the output of the captioning model (denoted as \(y_{\text {lstm}}\)). We use output of the SAE decoder only in train time to regulate the captioning model \(\phi \) by implicitly transferring the previously learned latent structure with SAE decoder.

Illustration of our proposed Sentence Auto-Encoder (SAE) regularizer with the image captioning decoder. The captioning model is trained by adding the SAE decoder as an auxiliary branch and thus acting as a regularizer.
Our integrated model is optimized to generate two accurate captions (i.e. \(y_{\text {sae}}\) and \(y_{\text {lstm}}\)) by minimizing a weighted average of two loss values:
where L is the cross-entropy loss computed for each caption, word by word against the ground truth caption \(y^*\), \(\lambda \) is the trade-off parameter, and \(\varOmega \) are the parameters of our model. We consider two scenarios that we use during our experimentation.
-
First, we set the parameters of the SAE decoder \(\varTheta _D\) to be the weights of the pre-trained SAE decoder and freeze them while optimizing Eq. (12) in terms of \(\varOmega =\{ \varTheta _{\phi },\varTheta _{\psi },E \}\).
-
Second, we initialize \(\varTheta _D\) with the weights of the pre-trained SAE decoder and fine-tune them along with the LSTM parameters, i.e. \(\varOmega =\{\varTheta _{\phi },\varTheta _{\psi },E,\varTheta _{\text {D}}\}\).
As discussed in Sect. 3.2, we also minimize the KL divergence in Eq. (10) along with the final regularized objective in Eq. (12) as:
where, \(\gamma \) is the weight for the KL divergence loss.
Discussion. An alternative way of exploiting the information from the pre-trained SAE model is to bring the representations from the captioning decoder closer to the encodings of the SAE encoder by minimizing the Euclidean distance between the hidden state from the SAE encoder and the hidden state from the captioning decoder at each time-step. However, we found this setting is too restrictive on the learned hidden state of the LSTM.
4 Experiments
Dataset. Our models are evaluated on the standard MSCOCO 2014 image captioning dataset [26]. For fair comparisons, we use the same data splits for training, validation and testing as in [22] which have been used extensively in prior works. This split has 113,287 images for training, 5k images for validation and testing respectively with 5 captions for each image. We perform evaluation on all relevant metrics for generated sentence evaluation - CIDEr [37], Bleu [31], METEOR [14], ROUGE-L [25] and, SPICE [2].
Implementation Details. For training our image captioning model, we compute the image features based on the Bottom-Up architecture proposed by [3], where the model is trained using a Faster-RCNN model [32] on the Visual-Genome Dataset [24] with object and attribute information. These features are extracted from R regions and each region feature has D dimensions, where R and D is 36 and 2048 respectively as proposed in [3]. We use these \(36\times 2048\) image features in all our experiments.
4.1 Experimental Setup
LDA Topic Models. The LDA [7] model is learned in an offline manner to generate a C dimensional topic distribution for each caption. Briefly, the LDA model treats the captions as word-documents and group these words to form C topics (cluster of words), learns the word distribution for each topic \((C \times V)\) where V is the vocabulary size and also generates a topic distribution for each input caption, \(Q_T\) where each \(C^{th}\) dimension denotes the probability for that topic.
Sentence Auto-encoder. The Sentence Auto-encoder is trained offline on the MSCOCO 2014 captioning dataset [26] with the same splits as discussed above. For the architecture, we have a single layer GRU for both the encoder and the decoder. The word embeddings are learned with the network using an embedding layer and the dimension of both the hidden state and the word embeddings is 1024. During training, the decoder is trained with teacher-forcing [6] with a probability of 0.5. For inference, the decoder decodes till it reaches the end of caption token. The learning rate for this network is 2e−3 and it is trained using the ADAM [23] optimizer.
Image Captioning Decoder with SAE Regularizer. The architecture of our image captioning decoder is same as the Up-Down model [3] with their “soft-attention” replaced by our CLTA module and trained with the SAE regularizer. We also retrain the AoANet model proposed by Huang et al. [19] by incorporating our CLTA module and the SAE regularizer. In the results section, we show improvements over the Up-Down and AoANet models using our proposed approaches. Note, the parameters for training Up-Down and AoANet baselines are same as the original setting. While training the captioning models together with the SAE-decoder, we jointly learn an affine embedding layer (dimension 1024) by combining the embeddings from the image captioning decoder and the SAE-decoder. During inference, we use beam search to generate captions from the captioning decoder using a beam size of 5 for Up-Down and a beam-size of 2 for AoANet. For training the overall objective function as given in Eq. (13), the value of \(\lambda \) is initialized by 0.7 and increased by a rate of 1.1 every 5 epochs until it reaches a value of 0.9 and \(\gamma \) is fixed to 0.1. We use the ADAM optimizer with a learning rate of 2e−4. Our code is implemented using PyTorch [1] and will be made publicly available.
5 Results and Analysis
First, we study the caption reconstruction performance of vanilla and denoising SAE, then report our model’s image captioning performance on MS-COCO dataset with full and limited data, investigate multiple design decisions and analyze our results qualitatively.
5.1 Sentence Auto-encoder Results
An ideal SAE must learn mapping its input to a fixed low dimensional space such that a whole sentence can be summarized and reconstructed accurately. To this end, we experiment with two SAEs, Vanilla-SAE and Denoising-SAE and report their reconstruction performances in terms of Bleu4 and cross-entropy (CE) loss in Fig. 4.

Error Curve for the Sentence Auto-Encoder on the Karpathy test split. The error starts increasing approximately after 20 epochs.
The vanilla model, when the inputs words are not corrupted, outperforms the denoising one in both metrics. This is expected as the denoising model is only trained with corrupted input sequences. The loss for both the Vanilla and Denoising SAE start from a relatively high value of approximately 0.8 and 0.4 respectively, and converge to a significantly low error of 0.1 and 0.2. For a better analysis, we also compute the Bleu-4 metrics on our decoded caption against the 5 ground-truth captions. As reported in Fig. 1, both models obtain significantly high Bleu-4 scores. This indicates that an entire caption can be compressed in a low dimensional vector (1024) and can be successfully reconstructed.
5.2 Image Captioning Results
Here we incorporate the proposed CLTA and SAE regularizer to recent image-captioning models including Up-Down [3] and AoANet [19] and report their performance on MS-COCO dataset in multiple metrics (see Table 2). The tables report the original results of these methods from their publications in the top block and the rows in cyan show relative improvement of our models when compared to the baselines.
The baseline models are trained for two settings - 1) Up-Down\(^{\dagger }\), is the model re-trained on the architecture of Anderson et al. [3] and, 2) AoANet\(^{\dagger }\), is the Attention-on-Attention model re-trained as in Huang et al. [19]. Note that for both Up-Down and AoANet, we use the original source code to train them in our own hardware. We replace the “soft-attention” module in our Up-Down baseline by CLTA directly. The AoANet model is based on the powerful Transformer [36] architecture with the multi-head dot attention in both encoder and decoder. For AoANet, we replace the dot attention in the decoder of AoANet at each head by the CLTA which results in multi-head CLTA. The SAE-decoder is added as a regularizer on top of these models as also discussed in Sect. 4.1. As discussed later in Sect. 5.5, we train all our models with 128 dimensions for the CLTA and with the Denoising SAE decoder (initialized with \(\varvec{h}^{last}\)).
We evaluate our models with the cross-entropy loss training and also by using the CIDEr score oprimization [33] after the cross-entropy pre-training stage (Table 2). For the cross-entropy one, our combined approach consistently improves over the baseline performances across all metrics. It is clear from the results that improvements in CIDEr and Bleu-4 are quite significant which shows that our approach generates more human-like and accurate sentences. It is interesting to note that AoANet with CLTA and SAE-regularizer also gives consistent improvements despite having a strong transformer language model. We show in Sect. 5.4 the differences between our captions and the captions generated from Up-Down and AoANet. Our method is modular and improves on state-of-the-art models despite the architectural differences. Moreover, the SAE decoder is discarded after training and hence it brings no additional computational load during test-time but with significant performance boost. For CIDEr optimization, our models based on Up-Down and AoANet also show significant improvements in all metrics for our proposed approach.
5.3 Learning to Caption with Less Data
Table 3 evaluates the performance of our proposed models for a subset of the training data, where x% is the percentage of the total data that is used for training. All these subsets of the training samples are chosen randomly. Our CLTA module is trained with 128 dimensions for the latent topics along with the Denoising SAE Regularizer initialized with the last hidden state of the LSTM (Up-Down+CLTA+SAE-Reg). Despite the number of training samples, our average improvement with CLTA and SAE-Regularizer is around 1% in Bleu-4 and 2.9% in CIDEr for the Up-Down model and 0.8% in Bleu-4 and 1.2% in CIDEr for the AoANet model. The significant improvements in Bleu-4 and CIDEr scores with only 50% and 75% of the data compared to the baseline validates our proposed methods as a form of rich prior.
5.4 Qualitative Results
In Fig. 5, we show examples of images and captions generated by the baselines Up-Down and AoANet along with our proposed methods, CLTA and SAE-Regularizer. The baseline models have repetitive words and errors while generating captions (in front of a mirror, a dog in the rear view mirror). Our models corrects these mistakes by finding relevant words according to the context and putting them together in a human-like caption format (a rear view mirror shows a dog has the same meaning as a rear view mirror shows a dog in the rear view mirror which is efficiently corrected by our models by bringing in the correct meaning). From all the examples shown, we can see that our model overcomes the limitation of overfitting in current methods by completing a caption with more semantic and syntactic generalization (e.g.: different flavoured donuts and several trains on the tracks).

Example of generated captions from the baseline Up-Down, AoANet, our proposed CLTA and, our final models with both CLTA and SAE Regularizer.
5.5 Ablation Study
Conditional Latent Topic Attention (CLTA). Table 4a depicts the results for the CLTA module that is described in Sect. 3.2. Soft-attention is used as a baseline and corresponds to the attention mechanism in [41] which is the main attention module in Up-Down image captioning model by Anderson et al. [3]. We replace this attention with the CLTA and evaluate its performance for different number of latent dimensions, i.e. topics (C). The models trained with latent topic dimensions of 128, 256 and 512 all outperform the baseline significantly. The higher CIDEr and Bleu-4 scores for these latent topics show the model’s capability to generate more descriptive and accurate human-like sentences. As we increase the dimensions of latent topics from 128 to 512, we predict more relevant keywords as new topics learnt by the CLTA module with 512 dimensions are useful in encoding more information and hence generating meaningful captions.
Image Captioning Decoder with SAE Regularizer. Table 4b reports ablations for our full image captioning model (Up-Down with CLTA) and the SAE regularizer. As discussed in Sect. 3.3, SAE decoder (parameters defined by \(\varTheta _D\)) is initialized with the hidden state of the image captioning decoder. During training, we test different settings of how the SAE decoder is trained with the image captioning decoder: (1) Vanilla vs Denoising SAE and, (2) \(\varvec{h}^{\text {first}}\) vs \(\varvec{h}^{\text {last}}\), whether the SAE decoder is initialized with the first or last hidden state of the LSTM decoder. For all the settings, we fine-tune the parameters of GRU\(_\text {D}\) (\(\varTheta _D\)) when trained with the image captioning model (the parameters are initialized with the weights of the pre-trained Vanilla or Denoising SAE decoder).
The results in Table 4b are reported on different combinations from the settings described above, with the CLTA having 128 and 512 dimensions in the image captioning decoder. Adding the auxiliary branch of SAE decoder significantly improves over the baseline model with CLTA and in the best setting, Denoising SAE with \(\varvec{h}^{\text {last}}\) improves the CIDEr and Bleu-4 scores by 1.2 and 0.6 respectively. As the SAE decoder is trained for the task of reconstruction, fine-tuning it to the task of captioning improves the image captioning decoder.
Initializing the Vanilla SAE decoder with \(\varvec{h}^{\text {last}}\) does not provide enough gradient during training and quickly converges to a lower error, hence this brings lower generalization capacity to the image captioning decoder. As \(\varvec{h}^{\text {first}}\) is less representative of an entire caption compared to \(\varvec{h}^{\text {last}}\), vanilla SAE with \(\varvec{h}^{\text {first}}\) is more helpful to improve the captioning decoder training. On the other hand, the Denoising SAE being robust to noisy summary vectors provide enough training signal to improve the image captioning decoder when initialized with either \(\varvec{h}^{\text {first}}\) or \(\varvec{h}^{\text {last}}\) but slightly better performance with \(\varvec{h}^{\text {last}}\) for Bleu-4 and CIDEr as it forces \(\varvec{h}^{\text {last}}\) to have an accurate lower-dim representation for the SAE and hence better generalization. It is clear from the results in Table 4b, that Denoising SAE with \(\varvec{h}^{\text {last}}\) helps to generate accurate and generalizable captions. From our experiments, we found that CLTA with 128 topics and Denoising SAE (with \(\varvec{h}^{\text {last}}\)) has better performance than even it’s counterpart with 512 topics. Hence, for all our experiments in Sect. 5.2 and Sect. 5.3 our topic dimension is 128 with Denoising SAE initialized with \(\varvec{h}^{\text {last}}\).
6 Conclusion
In this paper, we have introduced two novel methods for image captioning that exploit prior knowledge and hence help to improve state-of-the-art models even when the data is limited. The first method exploits association between visual and textual features by learning latent topics via an LDA topic prior and obtains robust attention weights for each image region. The second one is an SAE regularizer that is pre-trained in an autoencoder framework to learn the structure of the captions and is plugged into the image captioning model to regulate its training. Using these modules, we obtain consistent improvements on two investigate models, bottom-up top-down and the AoANet image captioning model, indicating the usefulness of our two modules as a strong prior. In future work, we plan to further investigate potential use of label space structure learning for other challenging vision tasks with limited data and to improve generalization.
References
Pytorch. https://pytorch.org/
Anderson, P., Fernando, B., Johnson, M., Gould, S.: SPICE: semantic propositional image caption evaluation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9909, pp. 382–398. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46454-1_24
Anderson, P., et al.: Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6077–6086 (2018)
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Bao, Y., et al.: Generating sentences from disentangled syntactic and semantic spaces. arXiv preprint arXiv:1907.05789 (2019)
Bengio, S., Vinyals, O., Jaitly, N., Shazeer, N.: Scheduled sampling for sequence prediction with recurrent neural networks. In: Advances in Neural Information Processing Systems, pp. 1171–1179 (2015)
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent dirichlet allocation. J. Mach. Learn. Res. 3(Jan), 993–1022 (2003)
Chang, J., Gerrish, S., Wang, C., Boyd-Graber, J.L., Blei, D.M.: Reading tea leaves: how humans interpret topic models. In: Advances in Neural Information Processing Systems, pp. 288–296 (2009)
Cho, K., van Merrienboer, B., Bahdanau, D., Bengio, Y.: On the properties of neural machine translation: encoder-decoder approaches. In: Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, pp. 103–111 (2014)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
Chomsky, N.: Aspects of the Theory of Syntax, vol. 11. MIT press (2014)
Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014)
Dai, A.M., Le, Q.V.: Semi-supervised sequence learning. In: Advances in Neural Information Processing Systems, pp. 3079–3087 (2015)
Denkowski, M., Lavie, A.: Meteor universal: language specific translation evaluation for any target language. In: Proceedings of the Ninth Workshop on Statistical Machine Translation, pp. 376–380 (2014)
Fang, H., et al.: From captions to visual concepts and back. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1473–1482 (2015)
Gehring, J., Auli, M., Grangier, D., Yarats, D., Dauphin, Y.N.: Convolutional sequence to sequence learning. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1243–1252. JMLR. org (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Huang, L., Wang, W., Chen, J., Wei, X.Y.: Attention on attention for image captioning. In: The IEEE International Conference on Computer Vision (ICCV), October 2019
Jiang, W., Ma, L., Jiang, Y.G., Liu, W., Zhang, T.: Recurrent fusion network for image captioning. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 499–515 (2018)
Joon Oh, S., Benenson, R., Fritz, M., Schiele, B.: Person recognition in personal photo collections. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3862–3870 (2015)
Karpathy, A., Fei-Fei, L.: Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3128–3137 (2015)
Kingma, D.P., Ba, J.: Adam: method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Krishna, R., et al.: Visual genome: connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 123(1), 32–73 (2017)
Lin, C.Y., Och, F.J.: Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In: Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, p. 605. Association for Computational Linguistics (2004)
Lin, T.-Y., et al.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Liu, H., Singh, P.: Conceptnet-a practical commonsense reasoning tool-kit. BT Technol. J. 22(4), 211–226 (2004)
Luong, M.T., Le, Q.V., Sutskever, I., Vinyals, O., Kaiser, L.: Multi-task sequence to sequence learning. arXiv preprint arXiv:1511.06114 (2015)
Luong, M.T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025 (2015)
Marcheggiani, D., Bastings, J., Titov, I.: Exploiting semantics in neural machine translation with graph convolutional networks. arXiv preprint arXiv:1804.08313 (2018)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, pp. 311–318. Association for Computational Linguistics (2002)
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems, pp. 91–99 (2015)
Rennie, S.J., Marcheret, E., Mroueh, Y., Ross, J., Goel, V.: Self-critical sequence training for image captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7008–7024 (2017)
Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: a cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2556–2565 (2018)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems, pp. 3104–3112 (2014)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: consensus-based image description evaluation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4566–4575 (2015)
Vincent, P., Larochelle, H., Bengio, Y., Manzagol, P.A.: Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th International Conference on Machine Learning, pp. 1096–1103. ACM (2008)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3156–3164 (2015)
Wiseman, S., Rush, A.M.: Sequence-to-sequence learning as beam-search optimization. arXiv preprint arXiv:1606.02960 (2016)
Xu, K., et al.: Show, attend and tell: neural image caption generation with visual attention. In: International Conference on Machine Learning, pp. 2048–2057 (2015)
Yang, X., Tang, K., Zhang, H., Cai, J.: Auto-encoding scene graphs for image captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10685–10694 (2019)
Yao, T., Pan, Y., Li, Y., Mei, T.: Exploring visual relationship for image captioning. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 684–699 (2018)
Yao, T., Pan, Y., Li, Y., Qiu, Z., Mei, T.: Boosting image captioning with attributes. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4894–4902 (2017)
Zaremba, W., Sutskever, I., Vinyals, O.: Recurrent neural network regularization. arXiv preprint arXiv:1409.2329 (2014)
Zhou, Y., Sun, Y., Honavar, V.: Improving image captioning by leveraging knowledge graphs. In: 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 283–293. IEEE (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Goel, A., Fernando, B., Nguyen, TS., Bilen, H. (2020). Injecting Prior Knowledge into Image Caption Generation. In: Bartoli, A., Fusiello, A. (eds) Computer Vision – ECCV 2020 Workshops. ECCV 2020. Lecture Notes in Computer Science(), vol 12536. Springer, Cham. https://doi.org/10.1007/978-3-030-66096-3_26
Download citation
DOI: https://doi.org/10.1007/978-3-030-66096-3_26
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-66095-6
Online ISBN: 978-3-030-66096-3
eBook Packages: Computer ScienceComputer Science (R0)