
Abstract
With the goal of recovering high-quality image content from its degraded version, image restoration enjoys numerous applications, such as in surveillance, computational photography and medical imaging. Recently, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this paper, we present an architecture with the collective goals of maintaining spatially-precise high-resolution representations through the entire network and receiving strong contextual information from the low-resolution representations. The core of our approach is a multi-scale residual block containing several key elements: (a) parallel multi-resolution convolution streams for extracting multi-scale features, (b) information exchange across the multi-resolution streams, (c) spatial and channel attention mechanisms for capturing contextual information, and (d) attention based multi-scale feature aggregation. In a nutshell, our approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details. Extensive experiments on five real image benchmark datasets demonstrate that our method, named as MIRNet, achieves state-of-the-art results for image denoising, super-resolution, and image enhancement. The source code and pre-trained models are available at https://github.com/swz30/MIRNet.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image content is exponentially growing due to the ubiquitous presence of cameras on various devices. During image acquisition, degradations are often introduced because of the physical limitations of cameras and inappropriate lighting conditions. For instance, smartphone cameras have narrow aperture and small sensors with limited dynamic range. Consequently, they frequently generate noisy and low-contrast images. Similarly, images captured under unsuitable lighting are either too dark or too bright. The art of recovering the original image from its corrupted measurements is studied under the image restoration task.
Recently, deep learning models have made significant advancements for image restoration and enhancement, as they can learn strong (generalizable) priors from large-scale datasets. Existing CNNs typically follow one of the two architecture designs: 1) an encoder-decoder, or 2) high-resolution (single-scale) feature processing. The encoder-decoder models [17, 59, 84, 124] first progressively map the input to a low-resolution representation, and then apply a gradual reverse mapping to the original resolution. Although these approaches learn a broad context by spatial-resolution reduction, on the downside, the fine spatial details are lost, making it extremely hard to recover them in the later stages. On the other side, the high-resolution (single-scale) networks [27, 50, 120, 127] do not employ any downsampling operation, and thereby produce images with spatially more accurate details. However, these networks are less effective in encoding contextual information due to their limited receptive field.
Image restoration is a position-sensitive procedure, where pixel-to-pixel correspondence from the input image to the output image is needed. Therefore, it is important to remove only the undesired degraded image content, while carefully preserving the desired fine spatial details (such as true edges and texture). Such functionality for segregating the degraded content from the true signal can be better incorporated into CNNs with the help of large context, e.g., by enlarging the receptive field. Towards this goal, we develop a new multi-scale approach that maintains the original high-resolution features along the network hierarchy, thus minimizing the loss of precise spatial details. Simultaneously, our model encodes multi-scale context by using parallel convolution streams that process features at lower spatial resolutions. The multi-resolution parallel branches operate in a manner that is complementary to the main high-resolution branch, thereby providing us more precise and contextually enriched feature representations.
The main difference between our method and existing multi-scale image processing approaches is the way we aggregate contextual information. First, the existing methods [37, 71, 97] process each scale in isolation, and exchange information only in a top-down manner. In contrast, we progressively fuse information across all the scales at each resolution-level, allowing both top-down and bottom-up information exchange. Simultaneously, both fine-to-coarse and coarse-to-fine knowledge exchange is laterally performed on each stream by a new selective kernel fusion mechanism. Different from existing methods that employ a simple concatenation or averaging of features coming from multi-resolution branches, our fusion approach dynamically selects the useful set of kernels from each branch representations using a self-attention approach. More importantly, the proposed fusion block combines features with varying receptive fields, while preserving their distinctive complementary characteristics. Our main contributions include:
-
A novel feature extraction model that obtains a complementary set of features across multiple spatial scales, while maintaining the original high-resolution features to preserve precise spatial details.
-
A regularly repeated mechanism for information exchange, where the features across multi-resolution branches are progressively fused together for improved representation learning.
-
A new approach to fuse multi-scale features using a selective kernel network that dynamically combines variable receptive fields and faithfully preserves the original feature information at each spatial resolution.
-
A recursive residual design that progressively breaks down the input signal to simplify the learning process, and allows building very deep networks.
-
Comprehensive experiments are performed on five real image benchmark datasets for different image processing tasks including, image denoising, super-resolution and image enhancement. Our method achieves state-of-the-results on all five datasets. Furthermore, we extensively evaluate our approach on practical challenges, such as generalization ability across datasets.
2 Related Work
With the rapidly growing image content, there is a pressing need to develop effective image restoration and enhancement algorithms. In this paper, we propose a new method capable of performing image denoising, super-resolution and image enhancement. Unlike existing works for these problems, our approach processes features at the original resolution in order to preserve spatial details, while effectively fuses contextual information from multiple parallel branches. Next, we briefly describe the representative methods for each of the studied problems.
Image Denoising. Classic denoising methods are mainly based on modifying transform coefficients [30, 90, 115] or averaging neighborhood pixels [78, 86, 91, 98]. Although the classical methods perform well, the self-similarity [31] based algorithms, e.g., NLM [10] and BM3D [21], demonstrate promising denoising performance. Numerous patch-based algorithms that exploit redundancy (self-similarity) in images are later developed [28, 38, 43, 70]. Recently, deep learning-based approaches [5, 9, 11, 35, 39, 80, 119,120,121] make significant advances in image denoising, yielding favorable results than those of the hand-crafted methods.
Super-Resolution (SR). Prior to the deep-learning era, numerous SR algorithms have been proposed based on the sampling theory [53, 55], edge-guided interpolation [4, 122], natural image priors [58, 110], patch-exemplars [15, 33] and sparse representations [113, 114]. Currently, deep-learning techniques are actively being explored, as they provide dramatically improved results over conventional algorithms. The data-driven SR approaches differ according to their architecture designs [6, 13, 106]. Early methods [26, 27] take a low-resolution (LR) image as input and learn to directly generate its high-resolution (HR) version. In contrast to directly producing a latent HR image, recent SR networks [48, 56, 94, 95] employ the residual learning framework [42] to learn the high-frequency image detail, which is later added to the input LR image to produce the final super-resolved result. Other networks designed to perform SR include recursive learning [3, 41, 57], progressive reconstruction [60, 105], dense connections [99, 104, 127], attention mechanisms [23, 125, 126], multi-branch learning [22, 60, 64, 66], and generative adversarial networks (GANs) [63, 76, 87, 104].
Image Enhancement. Oftentimes, cameras generate images that are less vivid and lack contrast. For image enhancement, histogram equalization is the most commonly used approach. However, it frequently produces under- or over-enhanced images. Motivated by the Retinex theory [61], several enhancement algorithms mimicking human vision have been proposed in the literature [8, 54, 74, 83]. Recently, CNNs have been successfully applied to general, as well as low-light, image enhancement problems [52]. Notable works employ Retinex-inspired networks [89, 107, 124], encoder-decoder networks [18, 68, 81], and GANs [19, 25, 51].

The proposed network MIRNet is based on a recursive residual design. In the core of MIRNet is the multi-scale residual block (MRB) whose main branch is dedicated to maintaining spatially-precise high-resolution representations through the entire network and the complimentary set of parallel branches provide better contextualized features. It also allows information exchange across parallel streams via selective kernel feature fusion (SKFF) in order to consolidate the high-resolution features with the help of low-resolution features, and vice versa.
3 Proposed Method
In this section, we first present an overview of the proposed MIRNet for image restoration and enhancement, illustrated in Fig. 1. We then provide details of the multi-scale residual block, which is the fundamental building block of our method, containing several key elements: (a) parallel multi-resolution convolution streams for extracting (fine-to-coarse) semantically-richer and (coarse-to-fine) spatially-precise feature representations, (b) information exchange across multi-resolution streams, (c) attention-based aggregation of features arriving from multiple streams, (d) dual-attention units to capture contextual information in both spatial and channel dimensions, and (e) residual resizing modules to perform downsampling and upsampling operations.
Overall Pipeline. Given an image \(\mathbf {I} \in \mathbb {R}^{H\times W \times 3}\), the network first applies a convolutional layer to extract low-level features \(\mathbf {X_0} \in \mathbb {R}^{H\times W \times C}\). Next, the feature maps \(\mathbf {X_0}\) pass through N number of recursive residual groups (RRGs), yielding deep features \(\mathbf {X_d} \in \mathbb {R}^{H\times W \times C}\). We note that each RRG contains several multi-scale residual blocks, which is described in Sect. 3.1. Next, we apply a convolution layer to deep features \(\mathbf {X_d}\) and obtain a residual image \(\mathbf {R} \in \mathbb {R}^{H\times W \times 3}\). Finally, the restored image is obtained as \(\mathbf {\hat{I}} = \mathbf {I} + \mathbf {R}\). We optimize the proposed network using the Charbonnier loss [16]:
where \(\mathbf {I}^*\) denotes the ground-truth image, and \(\varepsilon \) is a constant which we empirically set to \(10^{-3}\) for all the experiments.
3.1 Multi-scale Residual Block (MRB)
In order to encode context, existing CNNs [7, 72, 73, 77, 84, 109] typically employ the following architecture design: (a) the receptive field of neurons is fixed in each layer/stage, (b) the spatial size of feature maps is gradually reduced to generate a semantically strong low-resolution representation, and (c) a high-resolution representation is gradually recovered from the low-resolution representation. However, it is well-understood in vision science that in the primate visual cortex, the sizes of the local receptive fields of neurons in the same region are different [47, 49, 82, 88]. Therefore, such a mechanism of collecting multi-scale spatial information in the same layer needs to be incorporated in CNNs [32, 46, 92, 93]. In this paper, we propose the multi-scale residual block (MRB), as shown in Fig. 1. It is capable of generating a spatially-precise output by maintaining high-resolution representations, while receiving rich contextual information from low-resolutions. The MRB consists of multiple (three in this paper) fully-convolutional streams connected in parallel. It allows information exchange across parallel streams in order to consolidate the high-resolution features with the help of low-resolution features, and vice versa. Next, we describe the individual components of MRB.
Selective Kernel Feature Fusion (SKFF). One fundamental property of neurons present in the visual cortex is to be able to change their receptive fields according to the stimulus [65]. This mechanism of adaptively adjusting receptive fields can be incorporated in CNNs by using multi-scale feature generation (in the same layer) followed by feature aggregation and selection. The most commonly used approaches for feature aggregation include simple concatenation or summation. However, these choices provide limited expressive power to the network, as reported in [65]. In MRB, we introduce a nonlinear procedure for fusing features coming from multiple resolutions using a self-attention mechanism. Motivated by [65], we call it selective kernel feature fusion (SKFF).

Schematic for selective kernel feature fusion (SKFF). It operates on features from multiple convolutional streams, and performs aggregation based on self-attention.
The SKFF module performs dynamic adjustment of receptive fields via two operations –Fuse and Select, as illustrated in Fig. 2. The fuse operator generates global feature descriptors by combining the information from multi-resolution streams. The select operator uses these descriptors to recalibrate the feature maps (of different streams) followed by their aggregation. Next, we provide details of both operators for the three-stream case, but one can easily extend it to more streams. (1) Fuse: SKFF receives inputs from three parallel convolution streams carrying different scales of information. We first combine these multi-scale features using an element-wise sum as: \(\mathbf {L = L_1 + L_2 + L_3}\). We then apply global average pooling (GAP) across the spatial dimension of \(\mathbf {L} \in \mathbb {R}^{H\times W \times C}\) to compute channel-wise statistics \(\mathbf {s} \in \mathbb {R}^{1\times 1 \times C}\). Next, we apply a channel-downscaling convolution layer to generate a compact feature representation \(\mathbf {z} \in \mathbb {R}^{1\times 1 \times r}\), where \(r=\frac{C}{8}\) for all our experiments. Finally, the feature vector \(\mathbf {z}\) passes through three parallel channel-upscaling convolution layers (one for each resolution stream) and provides us with three feature descriptors \(\mathbf {v_1}, \mathbf {v_2}\) and \(\mathbf {v_3}\), each with dimensions \(1\times 1\times C\). (2) Select: this operator applies the softmax function to \(\mathbf {v_1}, \mathbf {v_2}\) and \(\mathbf {v_3}\), yielding attention activations \(\mathbf {s_1}, \mathbf {s_2}\) and \(\mathbf {s_3}\) that we use to adaptively recalibrate multi-scale feature maps \(\mathbf {L_1}, \mathbf {L_2}\) and \(\mathbf {L_3}\), respectively. The overall process of feature recalibration and aggregation is defined as: \(\mathbf {U = s_1 \cdot L_1 + s_2\cdot L_2 + s_3 \cdot L_3}\). Note that the SKFF uses \(\sim 6\times \) fewer parameters than aggregation with concatenation but generates more favorable results.
Dual Attention Unit (DAU). While the SKFF block fuses information across multi-resolution branches, we also need a mechanism to share information within a feature tensor, both along the spatial and the channel dimensions. Motivated by the advances of recent low-level vision methods [5, 23, 125, 126] based on the attention mechanisms [44, 103], we propose the dual attention unit (DAU) to extract features in the convolutional streams. The schematic of DAU is shown in Fig. 3. The DAU suppresses less useful features and only allows more informative ones to pass further. This feature recalibration is achieved by using channel attention [44] and spatial attention [108] mechanisms. (1) Channel attention (CA) branch exploits the inter-channel relationships of the convolutional feature maps by applying squeeze and excitation operations [44]. Given a feature map \(\mathbf {M} \in \mathbb {R}^{H\times W \times C}\), the squeeze operation applies global average pooling across spatial dimensions to encode global context, thus yielding a feature descriptor \(\mathbf {d} \in \mathbb {R}^{1\times 1 \times C}\). The excitation operator passes \(\mathbf {d}\) through two convolutional layers followed by the sigmoid gating and generates activations \(\mathbf {\hat{d}} \in \mathbb {R}^{1\times 1 \times C}\). Finally, the output of CA branch is obtained by rescaling \(\mathbf {M}\) with the activations \(\mathbf {\hat{d}}\). (2) Spatial attention (SA) branch is designed to exploit the inter-spatial dependencies of convolutional features. The goal of SA is to generate a spatial attention map and use it to recalibrate the incoming features \(\mathbf {M}\). To generate the spatial attention map, the SA branch first independently applies global average pooling and max pooling operations on features \(\mathbf {M}\) along the channel dimensions and concatenates the outputs to form a feature map \(\mathbf {f} \in \mathbb {R}^{H\times W \times 2}\). The map \(\mathbf {f}\) is passed through a convolution and sigmoid activation to obtain the spatial attention map \(\mathbf {\hat{f}} \in \mathbb {R}^{H\times W \times 1}\), which we then use to rescale \(\mathbf {M}\).

Dual attention unit incorporating spatial and channel attention mechanisms.

Residual resizing modules to perform downsampling and upsampling.
Residual Resizing Modules. MIRNet employs a recursive residual design (with skip connections) to ease the flow of information during the learning process. In order to maintain the residual nature of our architecture, we introduce residual resizing modules to perform downsampling (Fig. 4a) and upsampling (Fig. 4b) operations. In MRB, the size of feature maps remains constant along convolution streams; but across streams it changes depending on the input resolution index i and the output resolution index j. If \(i<j\), the feature tensor is downsampled, and if \(i>j\), the feature map is upsampled. To perform \(2\times \) downsampling (halving the spatial dimension and doubling the channel dimension), we apply the module in Fig. 4a only once. For \(4\times \) downsampling, the module is applied twice. Similarly, one can perform \(2\times \) and \(4\times \) upsampling by applying the module in Fig. 4b once and twice, respectively. Note in Fig. 4a, we integrate anti-aliasing downsampling [123] to improve the shift-equivariance of our network.
4 Experiments
We perform qualitative and quantitative assessment of the results produced by our MIRNet and compare it with the previous best methods. Next, we describe the datasets, and then provide the implementation details. Finally, we report results for (a) image denoising, (b) super-resolution and (c) image enhancement.
4.1 Real Image Datasets
Image Denoising. (1) DND [79] consists of 50 images. Since the images are of very high-resolution, the dataset providers extract 20 crops of size \(512\times 512\) from each image, yielding 1000 patches in total. All these patches are used for testing (as DND does not contain training or validation sets). The ground-truth noise-free images are not released publicly, therefore the PSNR and SSIM scores can only be obtained through an online server [24]. (2) SIDD [1] is particularly collected with smartphone cameras. Due to the small sensor and high-resolution, the noise levels in smartphone images are much higher than those of DSLRs. SIDD contains 320 image pairs for training and 1280 for validation.
Super-Resolution. RealSR [14] dataset contains real-world LR-HR image pairs of the same scene captured by adjusting the focal-length of the cameras. RealSR has both indoor and outdoor images taken with two cameras. The number of training image pairs for scale factors \(\times 2\), \(\times 3\) and \(\times 4\) are 183, 234 and 178, respectively. For each scale factor, 30 test images are also provided in RealSR.
Image Enhancement. (1) LoL [107] is created for low-light image enhancement problem. It provides 485 images for training and 15 for testing. Each image pair in LoL consists of a low-light input image and its corresponding well-exposed reference image. (2) MIT-Adobe FiveK [12] contains 5000 images captured with DSLR cameras. The tonal attributes of all images are manually adjusted by five trained photographers (labelled as experts A to E). Same as in [45, 75, 100], we also consider the enhanced images of expert C as the ground-truth. Moreover, the first 4500 images are used for training and the last 500 for testing.
4.2 Implementation Details
The proposed architecture is end-to-end trainable and requires no pre-training of sub-modules. We train three different networks for three different restoration tasks. The training parameters, common to all experiments, are the following. We use 3 RRGs, each of which further contains 2 MRBs. The MRB consists of 3 parallel streams with channel dimensions of 64, 128, 256 at resolutions \(1, \frac{1}{2}, \frac{1}{4}\), respectively. Each stream has 2 DAUs. The models are trained with the Adam optimizer (\(\beta _1 = 0.9\), and \(\beta _2=0.999\)) for \(7\times 10^5\) iterations. The initial learning rate is set to \(2\times 10^{-4}\). We employ the cosine annealing strategy [69] to steadily decrease the learning rate from initial value to \(10^{-6}\) during training. We extract patches of size \(128\times 128\) from training images. The batch size is set to 16 and, for data augmentation, we perform horizontal and vertical flips.

Denoising example from DND [79].
4.3 Image Denoising
In this section, we demonstrate the effectiveness of the proposed MIRNet for image denoising. We train our network only on the training set of the SIDD [1] and directly evaluate it on the test images of both SIDD and DND [79] datasets. The PSNR and SSIM scores are summarized in Table 1 and Table 2 for SIDD and DND, respectively. Both tables show that our MIRNet performs favourably against the data-driven, as well as conventional, denoising algorithms. Specifically, when compared to the recent best method VDN [118], our algorithm demonstrates a gain of 0.44 dB on SIDD and 0.50 dB on DND. Furthermore, it is worth noting that CBDNet [39] and RIDNet [5] use additional training data, yet our method provides significantly better results (8.94 dB improvement over CBDNet [39] on the SIDD dataset and 1.82 dB on DND).
In Fig. 5 and Fig. 6, we present visual comparisons of our results with those of other competing algorithms. It can be seen that our MIRNet is effective in removing real noise and produces perceptually-pleasing and sharp images. Moreover, it is capable of maintaining the spatial smoothness of the homogeneous regions without introducing artifacts. In contrast, most of the other methods either yield over-smooth images and thus sacrifice structural content and fine textural details, or produce images with chroma artifacts and blotchy texture.

Denoising examples from SIDD [1]. Our method effectively removes real noise from challenging images, while better recovering structural content and fine texture.
Generalization Capability. The DND and SIDD datasets are acquired with different cameras having different noise characteristics. Since the DND benchmark does not provide training data, setting a new state-of-the-art on DND with our SIDD trained network indicates the good generalization of our approach.
4.4 Super-Resolution (SR)
We compare our MIRNet against the state-of-the-art SR algorithms (VDSR [56], SRResNet [63], RCAN [125], LP-KPN [14]) on the testing images of the RealSR [14] for upscaling factors of \(\times 2\), \(\times 3\) and \(\times 4\). Note that all the benchmarked algorithms are trained on the RealSR [14] dataset for a fair comparison. In the experiments, we also include bicubic interpolation [55], which is the most commonly used method for generating super-resolved images. Here, we compute the PSNR and SSIM scores using the Y channel (in YCbCr color space), as it is a common practice in the SR literature [6, 14, 106, 125]. The results in Table 3 show that the bicubic interpolation provides the least accurate results, thereby indicating its low suitability for dealing with real images. Moreover, the same table shows that the recent method LP-KPN [14] provides marginal improvement of only \(\sim 0.04\) dB over the previous best method RCAN [125]. In contrast, our method significantly advances state-of-the-art and consistently yields better image quality scores than other approaches for all three scaling factors. Particularly, compared to LP-KPN [14], our method provides performance gains of 0.45 dB, 0.74 dB, and 0.22 dB for scaling factors \(\times 2\), \(\times 3\) and \(\times 4\), respectively. The trend is similar for the SSIM metric as well.

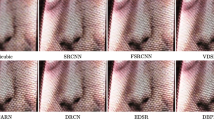
Comparisons for \(\times 4\) super-resolution from the RealSR [14] dataset. The image produced by our MIRNet is more faithful to the ground-truth than other competing methods (see lines near the right edge of the crops).

All example crops are taken from different images.
Additional examples for \(\times 4\) super-resolution, comparing our MIRNet against the previous best approach [14].
Visual comparisons in Fig. 7 show that our MIRNet recovers content structures effectively. In contrast, VDSR [56], SRResNet [63] and RCAN [125] reproduce results with noticeable artifacts. Furthermore, LP-KPN [14] is not able to preserve structures (see near the right edge of the crop). Several more examples are provided in Fig. 8 to further compare the image reproduction quality of our method against the previous best method [14]. It can be seen that LP-KPN [14] has a tendency to over-enhance the contrast (cols. 1, 3, 4) and in turn causes loss of details near dark and high-light areas. In contrast, the proposed MIRNet successfully reconstructs structural patterns and edges (col. 2) and produces images that are natural (cols. 1, 4) and have better color reproduction (col. 5).
Cross-Camera Generalization. The RealSR [14] dataset consists of images taken with Canon and Nikon cameras at three scaling factors. To test the cross-camera generalizability of our method, we train the network on the training images of one camera and directly evaluate it on the test set of the other camera. Table 4 demonstrates the generalization of competing methods for four possible cases: (a) training and testing on Canon, (b) training on Canon, testing on Nikon, (c) training and testing on Nikon, and (d) training on Nikon, testing on Canon. It can be seen that, for all scales, LP-KPN [14] and RCAN [125] shows comparable performance. In contrast, our MIRNet exhibits more promising generalization.
4.5 Image Enhancement
In this section, we demonstrate the effectiveness of our algorithm by evaluating it for the image enhancement task. We report PSNR/SSIM values of our method and several other techniques in Table 5 and Table 6 for the LoL [107] and MIT-Adobe FiveK [12] datasets, respectively. It can be seen that our MIRNet achieves significant improvements over previous approaches. Notably, when compared to the recent best methods, MIRNet obtains 3.27 dB performance gain over KinD [124] on the LoL dataset and 0.69 dB improvement over DeepUPE [100] on the Adobe-Fivek dataset.
We show visual results in Fig. 9 and Fig. 10. Compared to other techniques, our method generates enhanced images that are natural and vivid in appearance and have better global and local contrast.

Comparison of low-light enhancement approaches on the LoL [107] dataset.

Image enhancement results on the MIT-Adobe FiveK [12] dataset. Compared to the state-of-the-art, MIRNet makes better color and contrast adjustments.
5 Ablation Studies
We study the impact of each of our architectural components and design choices on the final performance. All the ablation experiments are performed for the super-resolution task with \(\times 3\) scale factor. Table 7 shows that removing skip connections causes the largest performance drop. Without skip connections, the network finds it difficult to converge and yields high training errors, and consequently low PSNR. Furthermore, the information exchange among parallel convolution streams via SKFF is helpful and leads to improved performance. Similarly, DAU also makes a positive influence to the final image quality.
Next, we analyze the feature aggregation strategy in Table 8. It shows that the proposed SKFF generates favorable results compared to summation and concatenation. Moreover, our SKFF uses \(\sim 6\times \) fewer parameters than concatenation. Finally, in Table 9 we study how the number of convolutional streams and columns (DAU blocks) of MRB affect the image restoration quality. We note that increasing the number of streams provides significant improvements, thereby justifying the importance of multi-scale features processing. Moreover, increasing the number of columns yields better scores, thus indicating the significance of information exchange among parallel streams for feature consolidation.
6 Concluding Remarks
Conventional image restoration and enhancement pipelines either stick to the full resolution features along the network hierarchy or use an encoder-decoder architecture. The first approach helps retain precise spatial details, while the latter one provides better contextualized representations. However, these methods can satisfy only one of the above two requirements, although real-world image restoration tasks demand a combination of both conditioned on the given input sample. In this work, we propose a novel architecture whose main branch is dedicated to full-resolution processing and the complementary set of parallel branches provides better contextualized features. We propose novel mechanisms to learn relationships between features within each branch as well as across multi-scale branches. Our feature fusion strategy ensures that the receptive field can be dynamically adapted without sacrificing the original feature details. Consistent achievement of state-of-the-art results on five datasets for three image restoration and enhancement tasks corroborates the effectiveness of our approach.
References
Abdelhamed, A., Lin, S., Brown, M.S.: A high-quality denoising dataset for smartphone cameras. In: CVPR (2018)
Aharon, M., Elad, M., Bruckstein, A.: K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation. Trans. Sig. Proc. (2006)
Ahn, N., Kang, B., Sohn, K.-A.: Fast, accurate, and lightweight super-resolution with cascading residual network. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11214, pp. 256–272. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01249-6_16
Allebach, J., Wong, P.W.: Edge-directed interpolation. In: ICIP (1996)
Anwar, S., Barnes, N.: Real image denoising with feature attention. ICCV (2019)
Anwar, S., Khan, S., Barnes, N.: A deep journey into super-resolution: a survey. arXiv (2019)
Badrinarayanan, V., Kendall, A., Cipolla, R.: SegNet: a deep convolutional encoder-decoder architecture for image segmentation. TPAMI (2017)
Bertalmío, M., Caselles, V., Provenzi, E., Rizzi, A.: Perceptual color correction through variational techniques. TIP (2007)
Brooks, T., Mildenhall, B., Xue, T., Chen, J., Sharlet, D., Barron, J.T.: Unprocessing images for learned raw denoising. In: CVPR (2019)
Buades, A., Coll, B., Morel, J.M.: A non-local algorithm for image denoising. In: CVPR (2005)
Burger, H.C., Schuler, C.J., Harmeling, S.: Image denoising: can plain neural networks compete with BM3D? In: CVPR (2012)
Bychkovsky, V., Paris, S., Chan, E., Durand, F.: Learning photographic global tonal adjustment with a database of input/output image pairs. In: CVPR (2011)
Cai, J., Gu, S., Timofte, R., Zhang, L.: Ntire 2019 challenge on real image super-resolution: methods and results. In: CVPRW (2019)
Cai, J., Zeng, H., Yong, H., Cao, Z., Zhang, L.: Toward real-world single image super-resolution: a new benchmark and a new model. In: ICCV (2019)
Chang, H., Yeung, D.Y., Xiong, Y.: Super-resolution through neighbor embedding. In: CVPR (2004)
Charbonnier, P., Blanc-Feraud, L., Aubert, G., Barlaud, M.: Two deterministic half-quadratic regularization algorithms for computed imaging. In: ICIP (1994)
Chen, C., Chen, Q., Xu, J., Koltun, V.: Learning to see in the dark. In: CVPR (2018)
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 833–851. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_49
Chen, Y.S., Wang, Y.C., Kao, M.H., Chuang, Y.Y.: Deep photo enhancer: unpaired learning for image enhancement from photographs with GANs. In: CVPR (2018)
Chen, Y., Yu, W., Pock, T.: On learning optimized reaction diffusion processes for effective image restoration. In: CVPR (2015)
Dabov, K., Foi, A., Katkovnik, V., Egiazarian, K.: Image denoising by sparse 3-D transform-domain collaborative filtering. TIP (2007)
Dahl, R., Norouzi, M., Shlens, J.: Pixel recursive super resolution. In: ICCV (2017)
Dai, T., Cai, J., Zhang, Y., Xia, S.T., Zhang, L.: Second-order attention network for single image super-resolution. In: CVPR (2019)
https://noise.visinf.tu-darmstadt.de/benchmark/ (2017). Accessed 29 Feb 2020
Deng, Y., Loy, C.C., Tang, X.: Aesthetic-driven image enhancement by adversarial learning. In: ACM Multimedia (2018)
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8692, pp. 184–199. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10593-2_13
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. TPAMI (2015)
Dong, W., Shi, G., Li, X.: Nonlocal image restoration with bilateral variance estimation: a low-rank approach. TIP (2012)
Dong, X., et al.: Fast efficient algorithm for enhancement of low lighting video. In: ICME (2011)
Donoho, D.L.: De-noising by soft-thresholding. Trans. Inf. Theor. (1995)
Efros, A.A., Leung, T.K.: Texture synthesis by non-parametric sampling. In: ICCV (1999)
Fourure, D., Emonet, R., Fromont, É., Muselet, D., Trémeau, A., Wolf, C.: Residual conv-deconv grid network for semantic segmentation. In: BMVC (2017)
Freedman, G., Fattal, R.: Image and video upscaling from local self-examples. TOG (2011)
Fu, X., Zeng, D., Huang, Y., Zhang, X.P., Ding, X.: A weighted variational model for simultaneous reflectance and illumination estimation. In: CVPR (2016)
Gharbi, M., Chaurasia, G., Paris, S., Durand, F.: Deep joint demosaicking and denoising. TOG (2016)
Gharbi, M., Chen, J., Barron, J.T., Hasinoff, S.W., Durand, F.: Deep bilateral learning for real-time image enhancement. TOG (2017)
Gu, S., Li, Y., Gool, L.V., Timofte, R.: Self-guided network for fast image denoising. In: ICCV (2019)
Gu, S., Zhang, L., Zuo, W., Feng, X.: Weighted nuclear norm minimization with application to image denoising. In: CVPR (2014)
Guo, S., Yan, Z., Zhang, K., Zuo, W., Zhang, L.: Toward convolutional blind denoising of real photographs. In: CVPR (2019)
Guo, X., Li, Y., Ling, H.: Lime: Low-light image enhancement via illumination map estimation. TIP (2016)
Han, W., Chang, S., Liu, D., Yu, M., Witbrock, M., Huang, T.S.: Image super-resolution via dual-state recurrent networks. In: CVPR (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Hedjam, R., Moghaddam, R.F., Cheriet, M.: Markovian clustering for the non-local means image denoising. In: ICIP (2009)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: CVPR (2018)
Hu, Y., He, H., Xu, C., Wang, B., Lin, S.: Exposure: A white-box photo post-processing framework. TOG (2018)
Huang, G., Chen, D., Li, T., Wu, F., van der Maaten, L., Weinberger, K.Q.: Multi-scale dense networks for resource efficient image classification. In: ICLR (2018)
Hubel, D.H., Wiesel, T.N.: Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. (1962)
Hui, Z., Wang, X., Gao, X.: Fast and accurate single image super-resolution via information distillation network. In: CVPR (2018)
Hung, C.P., Kreiman, G., Poggio, T., DiCarlo, J.J.: Fast readout of object identity from macaque inferior temporal cortex. Science (2005)
Ignatov, A., Kobyshev, N., Timofte, R., Vanhoey, K., Van Gool, L.: DSLR-quality photos on mobile devices with deep convolutional networks. In: ICCV (2017)
Ignatov, A., Kobyshev, N., Timofte, R., Vanhoey, K., Van Gool, L.: WESPE: weakly supervised photo enhancer for digital cameras. In: CVPRW (2018)
Ignatov, A., Timofte, R.: NTIRE 2019 challenge on image enhancement: methods and results. In: CVPRW (2019)
Irani, M., Peleg, S.: Improving resolution by image registration. CVGIP (1991)
Jobson, D.J., Rahman, Z.U., Woodell, G.A.: A multiscale retinex for bridging the gap between color images and the human observation of scenes. TIP (1997)
Keys, R.: Cubic convolution interpolation for digital image processing. TASSP (1981)
Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very deep convolutional networks. In: ICCV (2016)
Kim, J., Kwon Lee, J., Mu Lee, K.: Deeply-recursive convolutional network for image super-resolution. In: CVPR (2016)
Kim, K.I., Kwon, Y.: Single-image super-resolution using sparse regression and natural image prior. TPAMI (2010)
Kupyn, O., Martyniuk, T., Wu, J., Wang, Z.: DeblurGAN-v2: deblurring (orders-of-magnitude) faster and better. In: ICCV (2019)
Lai, W.S., Huang, J.B., Ahuja, N., Yang, M.H.: Deep Laplacian pyramid networks for fast and accurate superresolution. In: CVPR (2017)
Land, E.H.: The retinex theory of color vision. Sci. Am. (1977)
Lebrun, M., Colom, M., Morel, J.M.: The noise clinic: a blind image denoising algorithm. IPOL (2015)
Ledig, C., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: CVPR (2017)
Li, J., Fang, F., Mei, K., Zhang, G.: Multi-scale residual network for image super-resolution. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11212, pp. 527–542. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01237-3_32
Li, X., Wang, W., Hu, X., Yang, J.: Selective kernel networks. In: CVPR (2019)
Lim, B., Son, S., Kim, H., Nah, S., Mu Lee, K.: Enhanced deep residual networks for single image super-resolution. In: CVPRW (2017)
Liu, Y., Wang, R., Shan, S., Chen, X.: Structure inference net: object detection using scene-level context and instance-level relationships. In: CVPR (2018)
Lore, K.G., Akintayo, A., Sarkar, S.: LLNet: a deep autoencoder approach to natural low-light image enhancement. Pattern Recogn. (2017)
Loshchilov, I., Hutter, F.: SGDR: stochastic gradient descent with warm restarts. In: ICLR (2017)
Mairal, J., Bach, F., Ponce, J., Sapiro, G., Zisserman, A.: Non-local sparse models for image restoration. In: ICCV (2009)
Nah, S., Kim, T.H., Lee, K.M.: Deep multi-scale convolutional neural network for dynamic scene deblurring. In: CVPR (2017)
Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose estimation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 483–499. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_29
Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: ICCV (2015)
Palma-Amestoy, R., Provenzi, E., Bertalmío, M., Caselles, V.: A perceptually inspired variational framework for color enhancement. TPAMI (2009)
Park, J., Lee, J.Y., Yoo, D., So Kweon, I.: Distort-and-recover: Color enhancement using deep reinforcement learning. In: CVPR (2018)
Park, S.-J., Son, H., Cho, S., Hong, K.-S., Lee, S.: SRFeat: single image super-resolution with feature discrimination. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11220, pp. 455–471. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01270-0_27
Peng, X., Feris, R.S., Wang, X., Metaxas, D.N.: A recurrent encoder-decoder network for sequential face alignment. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 38–56. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_3
Perona, P., Malik, J.: Scale-space and edge detection using anisotropic diffusion. TPAMI (1990)
Plotz, T., Roth, S.: Benchmarking denoising algorithms with real photographs. In: CVPR (2017)
Plötz, T., Roth, S.: Neural nearest neighbors networks. In: NeurIPS (2018)
Ren, W., et al.: Low-light image enhancement via a deep hybrid network. TIP (2019)
Riesenhuber, M., Poggio, T.: Hierarchical models of object recognition in cortex. Nat. Neurosci. (1999)
Rizzi, A., Gatta, C., Marini, D.: From retinex to automatic color equalization: issues in developing a new algorithm for unsupervised color equalization. J. Electron. Imaging (2004)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Roth, S., Black, M.J.: Fields of experts. IJCV (2009)
Rudin, L.I., Osher, S., Fatemi, E.: Nonlinear total variation based noise removal algorithms. Physica D (1992)
Sajjadi, M.S., Scholkopf, B., Hirsch, M.: EnhanceNet: single image super-resolution through automated texture synthesis. In: ICCV (2017)
Serre, T., Wolf, L., Bileschi, S., Riesenhuber, M., Poggio, T.: Robust object recognition with cortex-like mechanisms. TPAMI (2007)
Shen, L., Yue, Z., Feng, F., Chen, Q., Liu, S., Ma, J.: MSR-net: low-light image enhancement using deep convolutional network. arXiv (2017)
Simoncelli, E.P., Adelson, E.H.: Noise removal via Bayesian wavelet coring. In: ICIP (1996)
Smith, S.M., Brady, J.M.: SUSAN-a new approach to low level image processing. IJCV (1997)
Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: CVPR (2019)
Szegedy, C., et al.: Going deeper with convolutions. In: CVPR (2015)
Tai, Y., Yang, J., Liu, X.: Image super-resolution via deep recursive residual network. In: CVPR (2017)
Tai, Y., Yang, J., Liu, X., Xu, C.: MemNet: a persistent memory network for image restoration. In: ICCV (2017)
Talebi, H., Milanfar, P.: Global image denoising. TIP (2013)
Tao, X., Gao, H., Shen, X., Wang, J., Jia, J.: Scale-recurrent network for deep image deblurring. In: CVPR (2018)
Tomasi, C., Manduchi, R.: Bilateral filtering for gray and color images. In: ICCV (1998)
Tong, T., Li, G., Liu, X., Gao, Q.: Image super-resolution using dense skip connections. In: ICCV (2017)
Wang, R., Zhang, Q., Fu, C.W., Shen, X., Zheng, W.S., Jia, J.: Underexposed photo enhancement using deep illumination estimation. In: CVPR (2019)
Wang, S., Zheng, J., Hu, H.M., Li, B.: Naturalness preserved enhancement algorithm for non-uniform illumination images. TIP (2013)
Wang, W., Wei, C., Yang, W., Liu, J.: GLADNet: low-light enhancement network with global awareness. In: FG (2018)
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: CVPR (2018)
Wang, X., et al.: ESRGAN: enhanced super-resolution generative adversarial networks. In: ECCVW (2018)
Wang, Z., Liu, D., Yang, J., Han, W., Huang, T.: Deep networks for image super-resolution with sparse prior. In: ICCV (2015)
Wang, Z., Chen, J., Hoi, S.C.: Deep learning for image super-resolution: a survey. TPAMI (2019)
Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement. BMVC (2018)
Woo, S., Park, J., Lee, J.-Y., Kweon, I.S.: CBAM: convolutional block attention module. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 3–19. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_1
Xiao, B., Wu, H., Wei, Y.: Simple baselines for human pose estimation and tracking. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11210, pp. 472–487. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01231-1_29
Xiong, Z., Sun, X., Wu, F.: Robust web image/video super-resolution. TIP (2010)
Xu, J., Zhang, L., Zhang, D.: A trilateral weighted sparse coding scheme for real-world image denoising. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11212, pp. 21–38. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01237-3_2
Xu, J., Zhang, L., Zhang, D., Feng, X.: Multi-channel weighted nuclear norm minimization for real color image denoising. In: ICCV (2017)
Yang, J., Wright, J., Huang, T., Ma, Y.: Image super-resolution as sparse representation of raw image patches. In: CVPR (2008)
Yang, J., Wright, J., Huang, T.S., Ma, Y.: Image super-resolution via sparse representation. TIP (2010)
Yaroslavsky, L.P.: Local adaptive image restoration and enhancement with the use of DFT and DCT in a running window. In: Wavelet Applications in Signal and Image Processing IV (1996)
Ying, Z., Li, G., Gao, W.: A bio-inspired multi-exposure fusion framework for low-light image enhancement. arXiv preprint arXiv:1711.00591 (2017)
Ying, Z., Li, G., Ren, Y., Wang, R., Wang, W.: A new image contrast enhancement algorithm using exposure fusion framework. In: CAIP (2017)
Yue, Z., Yong, H., Zhao, Q., Meng, D., Zhang, L.: Variational denoising network: Toward blind noise modeling and removal. In: NeurIPS (2019)
Zamir, S.W., et al.: CycleISP: real image restoration via improved data synthesis. In: CVPR (2020)
Zhang, K., Zuo, W., Chen, Y., Meng, D., Zhang, L.: Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising. TIP (2017)
Zhang, K., Zuo, W., Zhang, L.: FFDNet: toward a fast and flexible solution for CNN-based image denoising. TIP (2018)
Zhang, L., Wu, X.: An edge-guided image interpolation algorithm via directional filtering and data fusion. TIP (2006)
Zhang, R.: Making convolutional networks shift-invariant again. In: ICML (2019)
Zhang, Y., Zhang, J., Guo, X.: Kindling the darkness: a practical low-light image enhancer. In: MM (2019)
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution using very deep residual channel attention networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 294–310. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_18
Zhang, Y., Li, K., Li, K., Zhong, B., Fu, Y.: Residual non-local attention networks for image restoration. In: ICLR (2019)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image restoration. TPAMI (2020)
Zoran, D., Weiss, Y.: From learning models of natural image patches to whole image restoration. In: ICCV (2011)
Acknowledgment
Ming-Hsuan Yang is supported by the NSF CAREER Grant 1149783.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Zamir, S.W. et al. (2020). Learning Enriched Features for Real Image Restoration and Enhancement. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12370. Springer, Cham. https://doi.org/10.1007/978-3-030-58595-2_30
Download citation
DOI: https://doi.org/10.1007/978-3-030-58595-2_30
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58594-5
Online ISBN: 978-3-030-58595-2
eBook Packages: Computer ScienceComputer Science (R0)