
Abstract
Several deep learning methods have been proposed for completing partial data from shape acquisition setups, i.e., filling the regions that were missing in the shape. These methods, however, only complete the partial shape with a single output, ignoring the ambiguity when reasoning the missing geometry. Hence, we pose a multi-modal shape completion problem, in which we seek to complete the partial shape with multiple outputs by learning a one-to-many mapping. We develop the first multimodal shape completion method that completes the partial shape via conditional generative modeling, without requiring paired training data. Our approach distills the ambiguity by conditioning the completion on a learned multimodal distribution of possible results. We extensively evaluate the approach on several datasets that contain varying forms of shape incompleteness, and compare among several baseline methods and variants of our methods qualitatively and quantitatively, demonstrating the merit of our method in completing partial shapes with both diversity and quality.
R. Wu and X. Chen—Equal contribution.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Shape completion, which seeks to reason the geometry of the missing regions in incomplete shapes, is a fundamental problem in the field of computer vision, computer graphics and robotics. A variety of solutions now exist for efficient shape acquisition. The acquired shapes, however, are often incomplete, e.g., incomplete work in the user modeling interface, and incomplete scans resulted from occlusion. The power of shape completion enables the use of these incomplete data in downstream applications, e.g., virtual walk-through, intelligent shape modeling, path planning.
With the rapid progress made in deep learning, many data-driven methods have been proposed and demonstrated effective in shape completion [5, 7, 11, 12, 18, 24, 26, 28, 30,31,32,33, 36, 37]. However, most approaches in this topic have focused on completing the partial shape with a single result, learning a one-to-one mapping for shape completion. In contrast, we model a distribution of potential completion results, as the shape completion problem is multimodal in nature, especially when the incompleteness causes significant ambiguity. For example, as shown in Fig. 1, a partial chair can be completed with different types of chairs. Hence, we pose the multimodal shape completion problem, which seeks to associate each incomplete shape with multiple different complete shapes.

We present a point-based shape completion network that can complete the partial shape with multiple plausible results. Here we show a sampling of our results, where a partial chair is completed with different types of chairs.
In this work, we propose a first point-based multimodal shape completion method, in which the multimodality of potential outputs is distilled in a low-dimensional latent space, enabling random sampling of completion results at inference time. The challenge to achieve this is two-fold. First, modeling the multimodality in the high-dimensional shape space and mapping it into a low-dimensional latent space is challenging. A common problem is mode collapse, where only a subset of the modes are represented in the low-dimensional space. Second, the ground-truth supervision data, on which most learning-based methods rely for success, is extremely hard to acquire in our problem. Without the availability of particular supervision data (i.e., for each training incomplete shape, multiple corresponding complete shapes are required), it is challenging to learn the multimodal mapping for shape completion in an unsupervised manner without any paired data.
We address the challenge by completing the partial shape in a conditional generative modeling setting. We design a conditional generative adversarial network (cGAN) wherein a generator learns to map incomplete training data, combined with a latent vector sampled from a learned multimodal shape distribution, to a suitable latent representation such that a discriminator cannot differentiate between the mapped latent variables and the latent variables obtained from complete training data (i.e., complete shape models). An encoder is introduced to encode mode latent vectors from complete shapes, learning the multimodal distribution of all possible outputs. We further apply this encoder to the completion output to extract and recover the input latent vector, forcing the bijective mapping between the latent space and the output modes. The mode encoder is trained to encode the multimodality in an explicit manner (Sect. 3.3), alleviating the aforementioned mode collapse issue. By conditioning the generation of completion results on the learned multimodal shape distribution, we achieve multimodal shape completion.
We extensively evaluate our method on several datasets that contain varying forms of shape incompleteness. We compare our method against several baseline methods and variants of our method, and rate the different competing methods using a combination of established metrics. Our experiments demonstrate the superiority of our method compared to other alternatives, producing completion results with both high diversity and quality, all the while remaining faithful to the partial input shape.
2 Related Work
Shape Completion. With the advancement of deep learning in 3D domain, many deep learning methods have been proposed to address the shape completion challenge. Following the success of CNN-based 2D image completion networks, 3D convolutional neural networks applied on voxelized inputs have been widely adopted for 3D shape completion task [7, 12, 24, 26, 28, 30,31,32,33]. To avoid geometric information loss resulted from quantizing shapes into voxel grids, several approaches [5, 11, 18, 36, 37] have been develop to work directly on point sets to reason the missing geometry. While all these methods resort to learning a parameterized model (i.e., neural networks) as a mapping from incomplete shapes to completed shapes, the learned mapping function remains injective. Consequently, these methods can only complete the partial shape with a single deterministic result, ignoring the ambiguity of the missing regions.
Generative Modeling. The core of generative modeling is parametric modeling of the data distribution. Several classical approaches exist for tackling the generative modeling problem, e.g., restricted Boltzmann machines [25], and autoencoders [13, 29]. Since the introduction of Generative Adversarial Networks (GANs) [8], it has been widely adopted for a variety of generative tasks. In 2D image domain, researchers have utilized GANs in tasks ranging from image generation [2, 3, 19], image super-resolution [15], to image inpainting in 2D domain. In the context of 3D, a lot of effort has also been put on the task of content generation [1, 6, 9, 21]. The idea of using GANs to generatively model the missing regions for shape completion has also been explored in the pioneering works [5, 11]. In this work, we achieve multimodal shape completion by utilizing GANs to reason the missing geometry in a conditional generative modeling setting.
Deep Learning on Points. Our method is built upon recent success in deep neural networks for point cloud representation learning. Although many improvements to PointNet [22] have been proposed [16, 17, 23, 27, 38], the simplicity and effectiveness of PointNet and its extension PointNet++ make them popular in many other analysis tasks [10, 34,35,36]. To achieve point cloud generation, [1] proposed to train GANs in the latent space produced by a PointNet-based autoencoder, reporting significant performance gain in point cloud generation. Similar to [5], we also leverage the power of such point cloud generation model to complete shapes, but conditioning the generation on a learned distribution of potential completion outputs for multimodal shape completion.

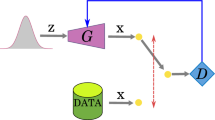
The proposed network architecture for learning multimodal shape completion. We use the encoder \(E_{\text {VAE}}\) of a shape variational autoencoder as the mode encoder \(E_z\) to encode the multimodality from shapes explicitly.
3 Method
Given a partial shape domain \(\mathcal {P}\subset \mathbb {R}^{K \times 3}\), we seek to learn a multimodal mapping from \(\mathcal {P}\) to the complete shape domain \(\mathcal {C}\subset \mathbb {R}^{N \times 3}\), achieving the goal of multimodal shape completion. Unlike existing methods, which are primarily limited to producing a single deterministic completion output \(\hat{\mathbf{C }}\) from a partial shape \(\mathbf{P} \in \mathcal {P}\), our method learns a mapping that could sample the completion \(\hat{\mathbf{C }}\) from the conditional distribution of possible completions, producing diverse completion results. During training, our method only requires access to a set of partial point sets, and a set of complete point sets. It is important to note that there is no any paired completion instances in \(\mathcal {C}\) for point sets in \(\mathcal {P}\).
Following the spirit of [5], without paired training data, we address the multimodal shape completion problem via adversarial training on the latent space learned from point sets, while introducing a low-dimensional code \(\mathbf{z} \in \mathbb {R}^{\text {Z}}\), of which the latent space is learned by modeling the multimodality presented in possible outputs, as a conditional input in addition to the partial shape. To enable stochastic sampling, we desire \(\mathbf{z} \) to be drawn from a prior distribution \(p(\mathbf{z} )\); a standard Gaussian distribution \(\mathcal {N}(0, \mathcal {I})\) is used in this work.
More specifically, we learn two class-specific point set manifolds, \(\mathbb {X}_p\) for the partial shapes, and \(\mathbb {X}_c\) for the complete shapes. Solving the multimodal shape completion problem then amounts to learning a mapping \(\mathbb {X}_p\rightarrow \mathbb {X}_c\) in a conditional generative modeling setting between respective latent spaces. Hence, we train a generator \(G:(\mathbb {X}_p, p(\mathbf{z} )) \rightarrow \mathbb {X}_c\), to perform the multimodal mapping with the latent code \(\mathbf{z} \) as a condition input. In absence of paired training data, we opt to use adversarial training to complete shapes in a generative modeling setting. Furthermore, to force the generator to use the latent code \(\mathbf{z} \), we introduce a encoder \(E_z\) to recover \(\mathbf{z} \) from the completion output, forcing the connection between the latent space and the shape space to be invertible. Figure 2 shows the setup of the proposed multimodal shape completion network. All network modules are detailed next.
3.1 Learning Latent Spaces for Point Sets
The latent space of a given set of point sets is obtained by training an autoencoder, which encodes the given input to a low-dimension latent feature and then decodes to reconstruct the original input.
For point sets coming from the complete point sets \(\mathcal {C}\), we learn an encoder network \(E_{\text {AE}}\) that maps \(\mathbf{C} \) from the original parameter space \(\mathbb {R}^{N \times 3}\), defined by concatenating the coordinates of the N points, to a lower-dimensional latent space \(\mathbb {X}_c\). A decoder network \(D_{\text {AE}}\) performs the inverse transformation back to \(\mathbb {R}^{N \times 3}\) giving us a reconstructed point set \(\tilde{\mathbf{C }}\) with also N points. The encoder-decoders are trained with reconstruction loss:
where \(\mathbf{C} \sim p(\mathbf{C} )\) denotes point set samples drawn from the set of complete point sets, \(d^{\text {EMD}}(X_1, X_2)\) is the Earth Mover’s Distance (EMD) between point sets \(X_1, X_2\). Once trained, the network weights are held fixed and the complete latent code \(\mathbf{x} _c= E_{\text {AE}}(\mathbf{C} ),\ \mathbf{x} _c\in \mathbb {X}_c\) for a complete point set \(\mathbf{C} \) provides a compact representation for subsequent training and implicitly captures the manifold of complete data. As for the point set coming from the partial point sets \(\mathcal {P}\), instead of training another autoencoder for its latent parameterization, we directly feed the partial point sets to \(E_{\text {AE}}\) obtained above for producing partial latent space \(\mathbb {X}_p\), which in [5] is proved to yield better performance in subsequent adversarial training. Note that, to obtain \(\mathbf{x} _p\in \mathbb {X}_p\), we duplicate the partial point set of K points to align with the number of complete point set before feed it to \(E_{\text {AE}}\).
3.2 Learning Multimodal Mapping for Shape Completion
Next, we setup a min-max game between the generator and the discriminator to perform the multimodal mapping between the latent spaces. The generator is trained to fool the discriminator such that the discriminator fails to reliably tell if the latent variable comes from original \(\mathbb {X}_c\) or the remapped \(\mathbb {X}_p\). The mode encoder is trained to model the multimodal distribution of possible complete point sets, and is further applied to the completion output to encode and recover the input latent vector, encouraging the use of conditional mode input.
Formally, the latent representation of the input partial shape \(\mathbf{x} _p= E_{\text {AE}}(\mathbf{P} )\), along with a Gaussian-sampled condition \(\mathbf{z} \), is mapped by the generator to \(\hat{\mathbf{x }}_c= G(\mathbf{x} _p, \mathbf{z} )\). Then, the task of the discriminator \(F\) is to distinguish between latent representations \(\hat{\mathbf{x }}_c\) and \(\mathbf{x} _c= E_{\text {AE}}(\mathbf{C} )\). The mode encoder \(E_z\) will encode the completion point set, which can be decoded from the completion latent code \(\hat{\mathbf{C }}= D_{\text {AE}}(\hat{\mathbf{x }}_c)\), to reconstruct the conditional input \(\tilde{\mathbf{z }}= E_z(\hat{\mathbf{C }})\). We train the mapping function using a GAN. Given training examples of complete latent variables \(\mathbf{x} _c\), remapped partial latent variables \(\hat{\mathbf{x }}_c\), and Gaussian samples \(\mathbf{z} \), we seek to optimize the following training losses over the generator \(G\), the discriminator \(F\), and the encoder \(E_z\):
Adversarial Loss. We add the adversarial loss to train the generator and discriminator. In our implementation, we use least square GAN [19] for stabilizing the training. Hence, the adversarial losses minimized for the generator and the discriminator are defined as:
where \(\mathbf{C} \sim p(\mathbf{C} )\), \(\mathbf{P} \sim p(\mathbf{P} )\) and \(\mathbf{z} \sim p(\mathbf{z} )\) denotes samples drawn from, respectively, the set of complete point sets, the set of partial point sets, and \(\mathcal {N}(0, \mathcal {I})\).
Partial Reconstruction Loss. Similar to previous work [5], we add a reconstruction loss to encourage the generator to partially reconstruct the partial input, so that the completion output is faithful to the input partial:
where \(d^{\text {HL}}\) denotes the unidirectional Hausdorff distance from the partial point set to the completion point set.
Latent Space Reconstruction. A reconstruction loss on the \(\mathbf{z} \) latent space is also added to encourage G to use the conditional mode vector \(\mathbf{z} \):
Hence, our full objective function for training the multimodal shape completion network is described as:

where \(\alpha \) and \(\beta \) are importance weights for the partial reconstruction loss and the latent space reconstruction loss, respectively.
3.3 Explicitly-Encoded Multimodality
To model the multimodality of possible completion outputs, we resort to an explicit multimodality encoding strategy, in which \(E_z\) is trained as a part to explicitly reconstruct the complete shapes. More precisely, a variational autoencoder \((E_{\text {VAE}}, D_{\text {VAE}})\) is pre-trained to encode complete shapes into a standard Gaussian distribution \(\mathcal {N}(0, \mathcal {I})\) and then decode to reconstruct the original shapes. Once trained, \(E_{\text {VAE}}\) can encode complete point sets as \(\mathbf{x} ^{\text {v}}_c\in \mathbb {X}^{\text {v}}_c\), and can be used to recover the conditional input \(\mathbf{z} \) from the completion output. Hence, the mode encoder is set to \(E_z= E_{\text {VAE}}\) and held fixed during the GAN training.
Another strategy is to implicitly encode the multimodality, in which the \(E_z\) is jointly trained to map complete shapes into a latent space without being trained as a part of explicit reconstruction. Although it has been shown effective to improve the diversity in the multimodal mapping learning [39, 40], we demonstrate that using explicitly-encoded multimodality in our problem yields better performance. In Sect. 4.2, we present the comparison against variants of using implicit multimodality encoding.
3.4 Implementation Details
In our experiments, a partial shape is represented by \(K=1024\) points and a complete shape by \(N=2048\) points. The point set (variational) autoencoder follows [1, 5]: using a PointNet [22] as the encoder and a 3-layer MLP as the decoder. The autoencoder encodes a point set into a latent vector of fixed dimension \(|\mathbf{x} |=128\). Similar to [1, 5], we use a 3-layer MLP for both generator \(G\) and discriminator \(F\). The \(E_z\) also uses the PointNet to map a point set into a latent vector \(\mathbf{z} \), of which the length we set to \(|\mathbf{z} |=64\). Unless specified, the trade-off parameters \(\alpha \) and \(\beta \) in Eq. 6 are set to 6 and 7.5, respectively, in our experiments. For training the point set (variational) autoencoder, we use the Adam optimizer [14] with an initial learning rate 0.0005, \(\beta _1=0.9\) and train 2000 epochs with a batch size of 200. To train the GAN, we use the Adam optimizer with an initial learning rate 0.0005, \(\beta _1=0.5\) and train for a maximum of 1000 epochs with a batch size of 50. More details about each network module are presented in the supplementary material.

Our multimodal shape completion results. We show result examples, where the input partial shape is colored in grey and is followed by five different completions in yellow. From top to bottom: PartNet (rows 1–3), PartNet-Scan (rows 4–6), and 3D-EPN (rows 7–9).

Shape completion guided by reference shapes. The completion result varies accordingly when the reference shape changes.
4 Experiments
In this section, we present results produced from our method on multimodal shape completion, and both quantitative and qualitative comparisons against several baseline methods and variants of our method, along with a set of experiments for evaluating different aspects of our method.
Datasets. Three datasets are derived to evaluate our method under different forms of shape incompleteness: (A) PartNet dataset simulates part-level incompleteness in the user modeling interface. With the semantic segmentation provided in the original PartNet dataset [20], for each provided point set, we remove points of randomly selected parts to create a partial point set with at least one part. (B) PartNet-Scan dataset resembles the scenario where the partial scan suffers from part-level incompleteness. For each shape in [20], we randomly remove parts and virtually scan residual parts to obtain a partial scan with part-level incompleteness. (C) 3D-EPN dataset [7] is derived from ShapeNet [4] and provides simulated partial scans with arbitrary incompleteness. Scans are represented as Signed Distance Field but we only use the provided point cloud representations. Last, the complete point sets provided in PartNet [20] serve as the complete training data for the first two datasets, while for 3D-EPN dataset, we use the complete virtual scan of ShapeNet objects as the complete training data. We use Chair, Table and Lamp categories for PartNet and PartNet-scan, and use Chair, Airplane and Table categories for 3D-EPN. In all our experiments, we train separate networks for each category in each dataset. More details about data processing can be found in the supplementary material.
Evaluation Measures. For each partial shape in the test set, we generate \(k=10\) completion results and adopt the following measures for quantitative evaluation:
-
Minimal Matching Distance (MMD) measures the quality of the completed shape. We calculates the Minimal Matching Distance (as described in [1]) between the set of completion shapes and the set of test shapes.
-
Total Mutual Difference (TMD) measures the completion diversity for a partial input shape, by summing up all the difference among the k completion shapes of the same partial input. For each shape i in the k generated shapes, we calculate its average Chamfer distance \(d_i^{\text {CD}}\) to the other \(k - 1\) shapes. The diversity is then calculated as the sum \(\sum _{i=1}^{k} d_i^{\text {CD}}\).
-
Unidirectional Hausdorff Distance (UHD) measures the completion fidelity to the input partial. We calculate the average Hausdorff distance from the input partial shape to each of the k completion results.
More in-depth description can be found in the supplementary material.
4.1 Multimodal Completion Results
We first present qualitative results of our method on multimodal shape completion, by using randomly sampled \(\mathbf{z} \) from the standard Gaussian distribution. Figure 3 shows a collection of our multimodal shape completion results on the aforementioned datasets. More visual examples can be found in supplementary material.
To allow more explicit control over the modes in completion results, the mode condition \(\mathbf{z} \) can also be encoded from a user-specified shape. As shown in Fig. 4, this enables us to complete the partial shape under the guidance of a given reference shape. The quantitative evaluation of our results, along with the comparison results, is presented next.
4.2 Comparison Results
We present both qualitative and quantitative comparisons against baseline methods and variants of our method:
-
pcl2pcl [5], which also uses GANs to complete via generative modeling without paired training data. Without the conditional input, this method, however, cannot complete with diverse shapes for a single partial input.
-
KNN-latent, which retrieves a desired number of best candidates from the latent space formed by our complete point set autoencoder, using k-nearest neighbor search algorithm.
-
Ours-im-l2z, a variant of our method as described in Sect. 3.3, jointly trains the \(E_z\) to implicitly model the multimodality by mapping complete data into a low-dimensional space. The \(E_z\) can either take input as complete latent codes (denoted by Ours-im-l2z) or complete point clouds (denoted by Ours-im-pc2z) to map to \(\mathbf{z} \) space.
-
Ours-im-pc2z, in which, as stated above, the \(E_z\) takes complete point clouds as input to encode the multimodality in an implicit manner.
More details of the above methods can be found in the supplementary material.

Qualitative comparison on each three categories of PartNet (top), PartNet-Scan (middle) and 3D-EPN (bottom) dataset. Our method produces results that are both diverse and plausible.

Comparisons using metrics combinations. Our results present high diversity, quality and fidelity in comparisons using combinations of metrics. Relative performance is plotted, and pcl2plc is excluded as it fails to present completion diversity.
We present quantitative comparison results in Table 1. We can see that, by rating these methods using the combination of the established metrics, our method outperforms other alternatives with high completion quality (low MMD) and diversity (high TMD), while remains faithful to the partial input. More specifically, pcl2pcl has the best fidelity (lowest UHD) to the input partial shape, the completion results, however, present no diversity; Ours-im-l2z presents the best completion diversity, but fails to produce high partial matching between the partial input and the completion results; Ours-im-pc2z suffers from severe mode collapse; our method, by adopting the explicit multimodality encoding, can complete the partial shape with high completion fidelity, quality and diversity.
To better understand the position of our method among those competing methods when rating with the established metrics, we present Fig. 6 to visualize the performance of each method in comparisons using combinations of the metrics. Note that the percentages in Fig. 6 are obtained by taking the performance of our method as reference and calculating the relative performance of other methods to ours.
We also show qualitative comparison results in Fig. 5. Compared to other methods, our method shows the superiority on multimodal shape completion: high completion diversity and quality while still remains faithful to the input, as consistently exhibited in the quantitative comparisons. Note that pcl2pcl cannot complete the partial shape with multiple outputs, thus only a single completion result is shown in the figure.
4.3 Results on Real Scans
The nature of unpaired training data setting enables our method to be directly trained on real scan data with ease, which has been demonstrated in [5]. We have also trained and tested our method on the real-world scans provided in [5], which contains around 550 chairs. We randomly picked 50 of them for testing and used the rest for training. Qualitative results are shown in Fig. 7. For quantitative results on real scans, our method achieved \(2.42 \times 10^{-3}\) on MMD, \(3.17\times 10^{-2}\) on TMD and \(8.60\times 10^{-2}\) on UHD.

Examples of our multimodal shape completion results on real scan data.
4.4 More Experiments
We also present more experiments conducted to evaluate different aspects of our method.
Effect of Trade-Off Parameters. Minimizing the \(\mathcal {L}^{\text {GAN}}\), \(\mathcal {L}^{\text {recon}}\) and \(\mathcal {L}^{\text {latent}}\) in Eq. 6 corresponds to the improvement of completion quality, fidelity, and diversity, respectively. However, conflict exists when simultaneously optimizing these three terms, e.g., maximizing the completion fidelity to the partial input would potentially compromise the diversity presented in the completion results, as part of the completion point set is desired to be fixed. Hence, we conduct experiments and show in Fig. 8 to see how the diversity and fidelity vary with respect to the change of trade-off parameters \(\alpha \) and \(\beta \).

Effect of trade-off parameters. Left: the completion fidelity (UHD) decreases and the completion diversity (TMD) increases as we set \(\beta \) to be larger. Right: t-SNE visualization of completion latent vectors under different parameter settings. Dots with identical color indicates completion latent vectors resulted from the same partial shape. a) setting a larger weight for \(\mathcal {L}^{\text {recon}}\) to encourage completion fidelity leads to mode collapse within the completion results of each partial input; b)-d) setting larger weights for \(\mathcal {L}^{\text {latent}}\) to encourage completion diversity results in more modes.

Effect of input incompleteness. Completion results tend to show more variation as the input incompleteness increases. Left: the completion diversity (TMD) increases as the number of missing parts in the partial input rises. Right: we show an example of completion results for each input incompleteness.
Effect of Input Incompleteness. The shape completion problem has more ambiguity when the input incompleteness increases. Thus, it is desired that the model can complete with more diverse results under increasing incompleteness of the input. To this end, we test our method on PartNet dataset, where the incompleteness can be controlled by the number of missing parts. Fig. 9 shows how diversity in our completion results changes with respect to the number of missing parts in the partial input.
5 Conclusion
We present a point-based shape completion framework that can produce multiple completion results for the incomplete shape. At the heart of our approach lies a generative network that completes the partial shape in a conditional generative modeling setting. The generation of the completions is conditioned on a learned mode distribution that is explicitly distilled from complete shapes. We extensively evaluate our method on several datasets containing different forms of incompleteness, demonstrating that our method consistently outperforms other alternative methods by producing completion results with both high diversity and quality for a single partial input.
The work provides a novel approach to indoor scene modeling suggestions and large-scale scene scan completions, rather than object-oriented completions. While the completion diversity in our method is already demonstrated, the explicit multimodality encoding module is, nonetheless, suboptimal and could be potentially improved. Our method shares the same limitations as many of the counterparts: not producing shapes with fine-scale details and requiring the input to be canonically oriented. A promising future direction would be to investigate the possibility of guiding the mode encoder network to concentrate on the missing regions for multimodality extraction, alleviating the compromise between the completion diversity and the faithfulness to the input.
References
Achlioptas, P., Diamanti, O., Mitliagkas, I., Guibas, L.: Learning representations and generative models for 3D point clouds. In: International Conference on Machine Learning (ICML), pp. 40–49 (2018)
Alec, R., Luke, M., Soumith, C.: Unsupervised representation learning with deep convolutional generative adversarial networks. In: International Conference on Learning Representations (ICLR) (2016)
Arjovsky, M., Chintala, S., Bottou, L.: Wasserstein generative adversarial networks. In: International Conference on Machine Learning (ICML), pp. 214–223 (2017)
Chang, A.X., et al.: ShapeNet: an Information-Rich 3D Model Repository. Technical report, arXiv:1512.03012 [cs.GR], Stanford University – Princeton University – Toyota Technological Institute at Chicago (2015)
Chen, X., Chen, B., Mitra, N.J.: Unpaired point cloud completion on real scans using adversarial training. In: International Conference on Learning Representations (ICLR) (2020)
Chen, Z., Zhang, H.: Learning implicit fields for generative shape modeling. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5939–5948 (2019)
Dai, A., Ruizhongtai Qi, C., Nießner, M.: Shape completion using 3D-encoder-predictor CNNs and shape synthesis. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5868–5877 (2017)
Goodfellow, I., et al.: Generative adversarial nets. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 2672–2680 (2014)
Groueix, T., Fisher, M., Kim, V.G., Russell, B., Aubry, M.: AtlasNet: a Papier-Mâché approach to learning 3D surface generation. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Guerrero, P., Kleiman, Y., Ovsjanikov, M., Mitra, N.J.: PCPNET learning local shape properties from raw point clouds. Comput. Graph. Forum. 37, 75–85 (2018)
Gurumurthy, S., Agrawal, S.: High fidelity semantic shape completion for point clouds using latent optimization, pp. 1099–1108. IEEE (2019)
Han, X., Li, Z., Huang, H., Kalogerakis, E., Yu, Y.: High-resolution shape completion using deep neural networks for global structure and local geometry inference. In: International Conference on Computer Vision (ICCV), pp. 85–93 (2017)
Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Science 313(5786), 504–507 (2006)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization (2014)
Ledig, C., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4681–4690 (2017)
Li, J., Chen, B.M., Hee Lee, G.: SO-Net: self-organizing network for point cloud analysis. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9397–9406 (2018)
Li, Y., Bu, R., Sun, M., Wu, W., Di, X., Chen, B.: PointCNN: convolution on X-transformed points. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 820–830 (2018)
Liu, M., Sheng, L., Yang, S., Shao, J., Hu, S.M.: Morphing and sampling network for dense point cloud completion. In: Association for the Advancement of Artificial Intelligence (AAAI) (2019)
Mao, X., Li, Q., Xie, H., Lau, R.Y., Wang, Z., Paul Smolley, S.: Least squares generative adversarial networks. In: International Conference on Computer Vision (ICCV), pp. 2794–2802 (2017)
Mo, K., et al.: PartNet: a large-scale benchmark for fine-grained and hierarchical part-level 3D object understanding. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: DeepSDF: learning continuous signed distance functions for shape representation. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 165–174 (2019)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: PointNet: deep learning on point sets for 3D classification and segmentation. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 652–660 (2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: deep hierarchical feature learning on point sets in a metric space. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 5099–5108 (2017)
Sharma, A., Grau, O., Fritz, M.: VConv-DAE: deep volumetric shape learning without object labels. In: Hua, G., Jégou, H. (eds.) ECCV 2016. LNCS, vol. 9915, pp. 236–250. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-49409-8_20
Smolensky, P.: Information processing in dynamical systems: foundations of harmony theory. Technical report. Colorado University at Boulder Department of Computer Science (1986)
Stutz, D., Geiger, A.: Learning 3D shape completion under weak supervision. Int. J. Comput. Vis. (IJCV), 1–20 (2018)
Su, H., et al.: SplatNet: sparse lattice networks for point cloud processing. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2530–2539 (2018)
Thanh Nguyen, D., Hua, B.S., Tran, K., Pham, Q.H., Yeung, S.K.: A field model for repairing 3D shapes. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5676–5684 (2016)
Vincent, P., Larochelle, H., Bengio, Y., Manzagol, P.A.: Extracting and composing robust features with denoising autoencoders. In: International Conference on Machine Learning (ICML), pp. 1096–1103 (2008)
Wang, W., Huang, Q., You, S., Yang, C., Neumann, U.: Shape inpainting using 3D generative adversarial network and recurrent convolutional networks. In: International Conference on Computer Vision (ICCV), pp. 2298–2306 (2017)
Wu, R., Zhuang, Y., Xu, K., Zhang, H., Chen, B.: PQ-NET: a generative part Seq2Seq network for 3D shapes. arXiv preprint arXiv:1911.10949 (2019)
Wu, Z., et al.: 3D ShapeNets: a deep representation for volumetric shapes. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1912–1920 (2015)
Yang, B., Rosa, S., Markham, A., Trigoni, N., Wen, H.: 3D object dense reconstruction from a single depth view. arXiv preprint arXiv:1802.00411 1(2), 6 (2018)
Yin, K., Huang, H., Cohen-Or, D., Zhang, H.: P2P-NET: bidirectional point displacement net for shape transform. ACM Trans. Graph. (TOG) 37(4), 1–13 (2018)
Yu, L., Li, X., Fu, C.-W., Cohen-Or, D., Heng, P.-A.: EC-Net: an edge-aware point set consolidation network. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 398–414. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_24
Yu, L., Li, X., Fu, C.W., Cohen-Or, D., Heng, P.A.: PU-Net: point cloud upsampling network. In: Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2790–2799 (2018)
Yuan, W., Khot, T., Held, D., Mertz, C., Hebert, M.: PCN: point completion network. In: International Conference on 3D Vision (3DV), pp. 728–737 (2018)
Zaheer, M., Kottur, S., Ravanbakhsh, S., Poczos, B., Salakhutdinov, R.R., Smola, A.J.: Deep sets. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 3391–3401 (2017)
Zhu, J.Y., et al.: Toward multimodal image-to-image translation. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 465–476 (2017)
Zhu, J.Y., et al.: Visual object networks: image generation with disentangled 3D representations. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 118–129 (2018)
Acknowledgements
We thank the anonymous reviewers for their valuable comments. This work was supported in part by National Key R&D Program of China (2018YFB1403901, 2019YFF0302902) and NSFC (61902007).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Wu, R., Chen, X., Zhuang, Y., Chen, B. (2020). Multimodal Shape Completion via Conditional Generative Adversarial Networks. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12349. Springer, Cham. https://doi.org/10.1007/978-3-030-58548-8_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-58548-8_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58547-1
Online ISBN: 978-3-030-58548-8
eBook Packages: Computer ScienceComputer Science (R0)