
Abstract
Parametric models of humans, faces, hands and animals have been widely used for a range of tasks such as image-based reconstruction, shape correspondence estimation, and animation. Their key strength is the ability to factor surface variations into shape and pose dependent components. Learning such models requires lots of expert knowledge and hand-defined object-specific constraints, making the learning approach unscalable to novel objects. In this paper, we present a simple yet effective approach to learn disentangled shape and pose representations in an unsupervised setting. We use a combination of self-consistency and cross-consistency constraints to learn pose and shape space from registered meshes. We additionally incorporate as-rigid-as-possible deformation(ARAP) into the training loop to avoid degenerate solutions. We demonstrate the usefulness of learned representations through a number of tasks including pose transfer and shape retrieval. The experiments on datasets of 3D humans, faces, hands and animals demonstrate the generality of our approach. Code is made available at https://virtualhumans.mpi-inf.mpg.de/unsup_shape_pose/.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction

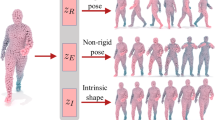
Our model learns a disentangled representation of shape and pose for mesh. In the middle are two source subjects taken from AMASS and SMAL datasets respectively. On the left are meshes with the same pose but varying shapes which we construct by transferring shape codes extracted from other meshes using our method. On the right are meshes with the same subject identity but varying poses which we construct by transferring pose codes.
Parameterizing 3D mesh deformation with different factors, such as pose and shape, is crucial in computer graphics for efficient 3D shape manipulation, and for computer vision, to extract structure and understand human and animal motion in videos.
Although parametric models of meshes such as SCAPE [1], SMPL [25], Dyna [31], Adam [20] for bodies, MANO [34] for hands, SMAL [45] for animals, basel face model [29], FLAME [23] and their combinations [30] for faces, have been extremely useful for many applications. Learning them is a difficult task that requires expert knowledge and manual intervention. SMPL for example, is learned from a set of meshes in correspondence, and requires defining a skeleton hierarchy, manually initializing blendweights to bind each vertex to body parts, carefully unposing meshes, and a training procedure that requires several stages.
In this paper, we address the problem of unsupervised disentanglement of pose and shape for 3D meshes. Like other models such as SMPL, our method requires a dataset of meshes registered to a template for training. But unlike other methods, we learn to factor pose and shape based on the data alone without making assumptions on the number of parts, the skeleton or the kinematic chain. Our model only requires that the same shape can be seen in different poses, which is available for datasets collected from scanners or motion capture devices. We call our model unsupervised because we do not make use of meshes annotated with pose or shape codes, and we make no assumptions on the underlying parts or skeleton. This flexibility makes our model applicable to a wide variety of objects, such as humans, hands, animals and faces.

A schematic overview of shape and pose disentangling mesh auto-encoder. The input mesh \(\mathbf {X}\) is separately processed by a shape branch and a pose branch to get shape code \(\varvec{\beta }\) and pose code \(\varvec{\theta }\). The two latent codes are subsequently concatenated and decoded to the reconstructed mesh \(\mathbf {\hat{X}}\)(top). The shape codes of two deformations of the same subject are swapped to reconstruct each other (bottom left). The pose code of one subject is used to reconstruct itself after a cycle of decoding-encoding (bottom right).
Unsupervised disentanglement from meshes is a challenging task. Most datasets [23, 25, 27, 34] contain the same shape in different poses, e.g., they capture a human or an animal moving. However, real world datasets do not contain two different shapes in the same pose – two different humans, or animals are highly unlikely to be captured performing the exact same pose or motion. This makes disentangling pose and shape from data difficult.
We achieve disentanglement with an auto-encoding neural network based on two key observations. First, we should be able to auto-encode a mesh in two codes (pose and shape), which we achieve with two separate encoder branches, see Fig. 2(top). Second, given two meshes \(\mathbf {X}_{1}^{s}\) and \(\mathbf {X}_{2}^{s}\) of the same subject s in two different poses, we should be able to swap their shape codes and reconstruct exactly the two input meshes. This is imposed with a cross-consistency loss, see Fig. 2(lower left). These two constraints however, are not sufficient and lead to degenerate solutions, with shape information flowing into pose code.
If we had access to two different shapes in the exact same pose, we could impose an analogous cross-consistency loss on the pose. But as mentioned, such data is not available. Our idea is to generate such pairs of different shapes with the exact same pose on the fly during training with our disentangling network.
Given two meshes with different shapes and poses \(\mathbf {X}_1^s\) and \(\mathbf {X}^t\), we generate a proxy mesh \(\tilde{\mathbf {X}}^{t}\) with the pose of mesh \(\mathbf {X}^{s}_1\) and the shape of mesh \(\mathbf {X}^t\) within the training loop. If disentanglement is effective, we should recover the original pose code from the proxy mesh, and mix it with the shape code of mesh \(\mathbf {X}_1^s\), to decode it into mesh \(\mathbf {X}_{1}^{s}\). We ask the network to satisfy this constraint with a self-consistency loss. For the self-consistency constraint to work well, the proxy mesh must not contain any shape characteristic of mesh \(\mathbf {X}_1^s\), which occurrs if the pose code carries shape information. To resolve this, we replace the initially decoded proxy mesh \(\mathbf {\tilde{X}}^t\) with an As-Rigid-As-Possible [38] approximate. Self-consistency is best understood with the illustration in Fig. 2 (lower right).
Our experiments show that these two simple—but not immediately obvious—losses allow to discover independent pose and shape factors from 3D meshes directly. To demonstrate the wide applicability of our method, we use it to disentangle pose and shape in four different publicly available datasets of full body humans [27], hands [34], faces [23] and animals [45]. We show several downstream applications, such as pose transfer, pose-aware shape retrieval, and pose and shape interpolation. We will make our code and model publicly available so that researchers can learn their own models from data.
2 Related Work
Disentangled Representations for 2D Images. The motivation behind feature disentanglement is that images can be synthesized from individual factors of variation. A pioneering work for disentanglement learning is InfoGAN [7], which maximizes the variational lower bound for the mutual information between latent code and generator distribution. Beta-VAE [15] and its follow-up work [6] penalized a KL divergence term to reduce variable correlations. Similarly, Kim et al. [21] encouraged fatorial marginal distribution of latent variables.
Another line of work incorporates Spatial Transformer Network [17] to explicitly model object deformations [26, 36, 37]. Iosanos et al. [35] recovered a 3D deformable template from a set of images and transformed it to fit image coordinates. Recently, adversarial training is exploited to enforce feature disentanglement [10, 11, 24, 28, 40]. Our work has similarities with [16, 43], where latent features are mixed and then separated. But unlike them, our method does not depend on auxiliary classifiers or adversarial loss, which are notoriously hard to train and tune. The idea of swapping codes (cross-consistency) to factor out appearance or identity as been also used in [33], but we additionally introduce the self-consistency loss which is critical for disentanglement. Furthermore, all these works focus on 2D images while we focus on disentanglement for 3D meshes.
Deep Learning for 3D Reconstructions. With the advances in geometric deep learning, a number of models have been proposed to analyse and reconstruct 3D shapes. Particularly related to us are mesh auto-encoders. Tan et al. [41] designed a mesh variational auto-encoder using fully-connected layers. Instead of operating directly on mesh vertices, the model deals with a rotation-invariant mesh representation [12]. Ranjan et al. [32] generalized downsampling and upsampling layers to meshes by collapsing unimportant edges based on quadric error measure. DEMEA [42] performs mesh deformation in a low-dimensional embedded deformation layer which helps reduce reconstruction artifacts. These models do not separate shapes from poses when embedding meshes into the latent space. Jiang et al. [19] decomposed 3D facial meshes into identity code and expression code. Their approach needs supervision on expression labels to work. Similarly, Jiang et al. [18] trained a disentangled human body model in a hierarchical manner with a predefined anatomical segmentation. Deng et al. [9] conditions human shape occupancy on pose, but requires pose labels for training. Levinson et al. [22] trained on pairs of shapes with the exact same poses, which is unrealistic for non-synthetic datasets. LIMP [8] explicitly enforced that change in pose should preserve pairwise geodesic distances. Although it works well for small datasets, the intensive computations make it unsuitable for larger datasets. Geometrically Disentangled VAE(GDVAE) [3] is capable of learning shape and pose from pointclouds in a completely unsupervised manner. GDVAE utilizes the fact that isometric deformations preserve spectrum of the Laplace-Beltrami Operator(LBO) to disentangle shape. While we require meshes in correspondence and GDVAE does not, we obtain significantly better disentanglement and reconstruction quality. Furthermore, in practice GDVAE uses meshes in correspondence to compute the LBO spectrum of each mesh. While the spectrum should be invariant to connectivity, in practice it is known to be very sensitive to noise and different discretizations. Instead of relying on LBO spectrum, we assume the subject identity is known which requires no extra labelling, and impose shape and pose consistency by swapping and mixing codes during training.
3D Deformation Transfer. Traditional deformation transfer methods solve an optimization problem for each pair of source and target meshes. The seminal work of Sumner et al. [39] transfers deformation via per-triangle affine transformations assuming correspondence. While general, this approach produces artifacts when transferring between significantly different shapes. Ben-Chen et al. [4] formulated deformation transfer as a space deformation problem. Recently, Lin et al. [13] achieved automatic deformation transfer between two different domains of meshes without correspondence. They build an auto-encoder for each of the source and target domain. Deformation transfer is performed at latent space by a cycle-consistent adversarial network [44]. For every new pair of shapes, a new model needs to be trained, whereas we train on multiple shapes simultaneously, and our training procedure is much simpler. These approaches focus on transferring pose deformations between pairs of meshes, whereas our ability to transfer deformation is just a natural consequence of the learned disentangled representation.
3 Method
Given a set of meshes with the same topology, our goal is to learn a latent representation with disentangled shape and pose components. In our context, we refer to shape as the intrinsic geometric properties of a surface (height, limb lengths, body shape etc.), which remain invariant under approximately isometric deformations. We refer to the other properties that vary with motion as pose.
Our model is built on three mild assumptions. i) All the meshes should be registered and have the same connectivity. ii) There are enough shape and pose variations in the training set to cover the latent space. iii) The same shape can be seen in different poses, which naturally occurs when capturing a body, face, hand or animal in motion. Note that models like SMPL [25] are built on the same assumptions, but unlike those models we do not hand-define the number of parts, skeleton nor the surface-to-part associations.
3.1 Overview
Our model follows the classical auto-encoder architecture. The encoder function \(f_\mathrm {enc}\) embeds input mesh \(\mathbf {X}\) into latent shape space and latent pose space: \(f_\mathrm {enc}(\mathbf {X}) = \left( f_{\varvec{\beta }}(\mathbf {X}), f_{\varvec{\theta }}(\mathbf {X})\right) = (\varvec{\beta }, \varvec{\theta })\), where \(\varvec{\beta }\) denotes shape code, and \(\varvec{\theta }\) denotes pose code. The encoder consists of two branches for shape \(f_{\varvec{\beta }}(\mathbf {X})= \varvec{\beta }\) and for pose \(f_{\varvec{\theta }}(\mathbf {X})=\varvec{\theta }\) respectively, which are independent and do not share weights. The decoder function \(g_\mathrm {dec}\) takes shape and pose codes as inputs, and transforms them back to the corresponding mesh: \(g_\mathrm {dec}(\varvec{\beta }, \varvec{\theta })=\tilde{\mathbf {X}}\).
The challenge is to disentangle pose and shape in an unsupervised manner, without supervision on \(\varvec{\theta }\) or \(\varvec{\beta }\) coming from an existing parametric model. We achieve this with a cross-consistency and a self-consistency loss during training. An overview of our approach is given in Fig. 2.
3.2 Cross-Consistency
Given two meshes, \(\mathbf {X}_{1}^{s}\) and \(\mathbf {X}_{2}^{s}\) (superscript indicates subject identity and subscript labels individual meshes of a given subject), of subject s in different poses we should be able to swap their shape codes and recover exactly the same meshes.
We randomly sample a mesh pair \((\mathbf {X}_1^s, \mathbf {X}_2^s)\) of the same subject from the training set and decompose it into \((\varvec{\beta }_{1}^{s}, \varvec{\theta }_{1}^{s})\) and \((\varvec{\beta }_{2}^{s}, \varvec{\theta }_{2}^{s})\) respectively. The cross-consistency implies that the original meshes should be recovered by swapping shape codes \(\varvec{\beta }_{1}^{s}\) \(\varvec{\beta }_{2}^{s}\):
Since the cross-consistency constraint holds in both directions, optimizing one loss term suffices. The loss is defined as
where \(\mathcal {T}\) is a family of pose invariant mesh transformations such as random scaling and uniform noise corruption, which serves as data augmentation to improve generalization and robustness of the pose branch. The cross-consistency is useful to make the model aware of the distinction between shape and pose, but as we discussed in the introduction, it alone does not guarantee disentangled representations. This motivates our self-consistency loss, which we explain next.
3.3 Self-consistency
Having pairs of meshes with different shapes and the exact same pose would simplify the task, but such data is never available in real world datasets. The key idea of self-consistency is to generate such mesh pairs consisting of two different shapes in the same pose on the fly during the training process.
We sample a triplet \((\mathbf {X}_{1}^{s}, \mathbf {X}_{2}^{s}, \mathbf {X}^{t})\), where mesh \(\mathbf {X}^t\) shares neither shape nor pose with \((\mathbf {X}_1^s, \mathbf {X}_2^s)\). We combine the shape from \(\mathbf {X}^t\) and pose from \(\mathbf {X}_1^s\) to generate an intermediate mesh \(\mathbf {\tilde{X}}^t = g_\mathrm {dec}(\varvec{\beta }^t, \varvec{\theta }_1^s)\).
Since \(\mathbf {\tilde{X}}^t\) should have the same pose \(\varvec{\tilde{\theta }}^{t} = f_{\varvec{\theta }}(\mathbf {\tilde{X}}^t)\) as \(\mathbf {X}_1^s\), and \(\mathbf {X}_2^s\) has the same shape \(\varvec{\beta }_{2}^{s}\) as \(\mathbf {X}_1^s\), we should be able to reconstruct \(\mathbf {X}_1^s\) with
The intuition behind this constraint is that the encoding and decoding of pose code should remain self-consistent with changes in the shape.
Although this loss alone is already quite effective, degeneracy can occur in the network if the proxy mesh \(\tilde{\mathbf {X}}^{t}\) inherits shape attributes of \(\mathbf {X}_1^s\) through the pose code. We make sure this does not happen by incorporating ARAP deformation [38] within the training loop.
As-rigid-as-possible Deformation. We use ARAP to deform \(\mathbf {X}^{t}\) to match the pose of the network prediction \(\mathbf {\tilde{X}}^{t}\) while preserving the original shape as much as possible,
where \(\mathbf {\tilde{X}}^{t'}\) is the desired deformed shape, see Fig. 3. Specifically, we deform \(\mathbf {X}^{t}\) to match a few randomly selected anchor points of the network prediction \(\mathbf {\tilde{X}}^{t}\). ARAP is a detail-preserving surface deformation algorithm that encourages locally rigid transformations. Note that we can successfully apply ARAP because the shape of \(\mathbf {\tilde{X}}^{t}\) should converge to the shape of \(\mathbf {X}^{t}\) during training. Hence, when only pose is different in the pair \((\mathbf {X}^{t},\mathbf {\tilde{X}}^{t})\), the ARAP loss approaches zero, and disentanglement is successful.
In the following, we provide a brief introduction to the optimization procedure of ARAP. We refer interested readers to [38] for more details. Let \(\mathbf {X}\) be a triangle mesh embedded in \(\mathbb {R}^3\) and \(\mathbf {\tilde{X}}\) be the deformed mesh. Each vertex i has an associated cell \(\mathcal {C}_i\), which covers the vertex itself and its one-ring neighbourhood \(\mathcal {N}(i)\). If a cell \(\mathcal {C}_i\) is rigidly transformed to \(\mathcal {\tilde{C}}_{i}\), the transformation can be represented by a rotation matrix \(\mathbf {R}_i\) satisfying \(\varvec{\tilde{e}}_{ij}=\mathbf {R}_i\textit{\textbf{e}}_{ij}\) for every edge \(\textit{\textbf{e}}_{ij} = (\textit{\textbf{v}}_j-\textit{\textbf{v}}_i)\) incident at vertex \(\textit{\textbf{v}}_i\). If \(\mathcal {\tilde{C}}_{i}\) and \(\mathcal {C}_{i}\) cannot be rigidly aligned, then \(\mathbf {R}_i\) is the optimal rotation matrix that aligns \(\mathcal {C}_i\) and \(\mathcal {\tilde{C}}_{i}\) with minimal non-rigid distortion. This objective can be formulated as follows.
where \(w_{ij}\) adjusts the importance of each edge. ARAP deformation minimizes Eq. (6) for all vertices i by an iterative procedure. It alternates between first estimating the current optimal rotation \(\mathbf {R}_i\) for cell \(\mathcal {C}_i\) while keeping the vertices \(\varvec{\tilde{v}}_i\) (and hence the edges \(\varvec{\tilde{e}}_{ij}\)) fixed, and second computing the updated vertices \(\varvec{\tilde{v}}_i\) based on the updated \(\mathbf {R}_i\). Let the covariance matrix \(\mathbf {S}_i=\sum _{j\in \mathcal {N}\left( i \right) }{w_{ij}\textit{\textbf{e}}_{ij}\varvec{\tilde{e}}_{ij}^{T}}\) have a singular value decomposition, \(\mathbf {S}_i=\mathbf {U}_i\mathbf {\Sigma } _i\mathbf {V}_i\). Then the relative rotation \(\mathbf {R}_i\) between them can be analytically calculated as \(\mathbf {R}_i = \mathbf {V}_i\mathbf {U}_i^T\) up to a change of sign [2]. Fixing \(\mathbf {R}_i\) simplifies Eq. (6) to a weighted least squares problem (over the vertices ) of the form

ARAP corrects artifacts in network prediction caused by embedding shape information in pose code. Notice how the circled region in the initial prediction resembles that of the pose source. This is rectified after applying ARAP for only 1 iteration.
which can be solved efficiently by a sparse Cholesky solver.
Note that Eq. (7) is an underdetermined problem so at least one anchor vertex needs to be fixed to obtain a unique solution. We take \(\mathbf {\tilde{X}}^{t}\) as an initial guess and randomly fix a small number of anchor vertices across its surface that should be matched by deforming the source mesh \(\mathbf {X}^t\) (i.e. \(\varvec{\tilde{v}}^{t}_j:=\textit{\textbf{v}}^{t}_j\) for all anchor vertices \(\textit{\textbf{v}}^{t}_j\)). There is a tradeoff when determining the number of anchor vertices; fixing too many does not improve the shape much while fixing too few could incur a deviation of pose. We found that fixing 1%–10% vertices gives good results in most cases. For training efficiency considerations, we only run ARAP for 1 iteration. This is sufficient since ARAP runs on every input training batch. We also adopted uniform weighting instead of cotangent weighting for \(w_{ij}\) and we did not observe any performance drop under this choice.
Self-consistency Loss. Let \(\mathbf {\tilde{X}}^{t'}\) be the output of ARAP, which should have the pose of \(\mathbf {X}_1^s\) with the shape of \(\mathbf {X}^t\). We enforce the equality in Eq. (4) with the following self-consistency loss:
where again, the intuition is that the pose extracted \(f_{\varvec{\theta }}(\mathcal {T}(\mathbf {\tilde{X}}^{t'}))\) should be independent of shape. Note that while ARAP is computed on the fly during training, we do not backpropagate through it.
3.4 Loss Terms and Objective Function
The overall objective we seek to optimize is
In all our experiments we set \(\lambda _C = \lambda _S = 0.5\). We also experimented with edge length constraints and other local shape preserving losses, but observed no benefit or worse performance.
3.5 Implementation Details
We preprocess the input meshes by centering them around the origin. For the disentangling mesh auto-encoder, we use an architecture similar to [5]. In particular, we adopt the spiral convolution operator, which aggregates and orders local vertices in a spiral trajectory. Each encoder branch consists of four consecutive mesh convolution layers and downsampling layers. The last layer is fully-connected which maps flattened features to latent space. The decoder architecture is a symmetry of the encoder except that mesh downsampling layers are replaced by upsampling layers. We follow the practice in [32] which downsamples and upsamples meshes based on quadric error metrics. We choose leaky ReLU with a negative slope of 0.02 as activation function. The model is optimized by ADAM solver with a cosine annealing learning rate scheduler.
4 Experiments
In this section, we evaluate our proposed approach on a variety of datasets and tasks. We conduct quantitative evaluations on AMASS dataset and COMA dataset. We compare our model to the state-of-the-art unsupervised disentangling models proposed in [3, 19]. We also perform an ablation study to evaluate the importance of each loss. In addition, we qualitatively show pose transfer results on four datasets (AMASS, SMAL, COMA and MANO) to demonstrate the wide applicability of our method. Finally, we show the usefulness of our disentangled codes for the tasks of shape and pose retrieval and motion sequence interpolation.
4.1 Datasets
We use the following four publicly available datasets to evaluate our method:
AMASS [27] is a large human motion sequence dataset that unifies 15 smaller datasets by fitting SMPL body model to motion capture markers. It consists of 344 subjects and more than 10k motions. We follow the protocol splits and sample every 1 out of 100 frames for the middle 90% portion of each sequence.
SMAL [45] is a parametric articulated body model for quadrupedal animals. Since there are not sufficient scans in this dataset, we synthesize SMAL shapes and poses using the procedure in [14]. Finally, we get 100 shapes and 160 poses distinct for each shape. We use a 9:1 data split.
MANO [34] is the 3D hand model used to fit AMASS together with SMPL. We treat it as a standalone dataset since its training scans contain more pose variations. To keep things simple without losing generality, we train the model specifically on right hands and flipped left hands. The official training set contains less than 2000 samples, hence we augment it by sampling shape and pose parameters of MANO from a Gaussian distribution.
COMA [32] is a facial expression dataset consisting of 12 subjects under 12 types of extreme expressions. We follow the same splits as in [32].
4.2 Quantitative Evaluation
AMASS Pose Transfer. In the following, we show quantitative results of our model trained on AMASS. Since AMASS comes with SMPL parameters, we utilize the SMPL model to generate pseudo-groundtruth for evaluating pose-transferred reconstructions. We sample a subset of paired meshes (with different shapes and poses) along with their pose-transferred pseudo-groundtruth. The error is calculated between model-predicted transfer results and the pseudo-groundtruth. We use 128-dimensional latent codes, 16 for shape and 112 for pose.
We compare our method to Geometric Disentanglement Variational Autoencoder(GDVAE) [3], a state-of-the-art unsupervised method which can disentangle pose and shape from 3D pointclouds. It is important to note that a fair comparison to GDVAE is not possible as we make different assumptions. They do not assume mesh correspondence while we do. However, GDVAE uses LBO spectra computed on meshes which are in perfect correspondence. Since the LBO spectra is sensitive to noise and the type of discretization, the performance of GDVAE could be significantly deteriorated when computed on meshes not in correspondence. Furthermore, we assume we can see the same shape in different poses. But as argued earlier, this is the typical case in datasets with dynamics. Hence, despite the differences in assumptions, we think the comparison is meaningful.
We report the one-side Chamfer distance for GDVAE (i.e., average distance between every point and its nearest point on groundtruth surface) and report the vertex-to-vertex error for our method. Note that the Chamfer distance would be lower for our method, but we want the metric to reflect how well we predict the semantics (body part locations) as well.
We also compare our method with a supervised baseline, which leverages pose labels from the SMPL. In that case, the intermediate mesh \(\mathbf {\tilde{X}}^{t'}\) is replaced by the pseudo-groundtruth coming from the SMPL model.
Table 1 summarizes reconstruction errors of pose-transferred meshes on AMASS dataset using different models. The supervised baseline with pose supervision achieves the lowest error, which serves as the performance upper bound for our model. Remarkably, our unsupervised model is only 4mm worse than the supervised baseline, suggesting that our proposed approach, which only requires seeing a subject in different poses, is sufficient to disentangle shape from pose. In addition, our approach achieves a much lower error compared to GDVAE. Again, we compare for completeness, but we do not want to claim we are superior as our assumptions are different, and the losses are conceptually very different.
We can also observe from Table 1 that training solely with cross-consistency constraint leads to degenerate solutions. This shows that our approach can only exploit the weak signal of seeing the same subject in different poses when combined with the self-consistency loss. Notably, enforcing the self-consistency constraint already drives the model to learn a reasonably well-disentangled representation, which is further improved by incorporating ARAP in-the-loop. We hypothesize that without ARAP, the intermediate mesh \(\tilde{X}^t\) is noisy in shape but relatively accurate in pose at early stages of training, thus helping disentanglement.
AMASS Pose-Aware Shape Retrieval. Shape retrieval refers to the task of retrieving similar objects given a query object. Our model learns disentangled representations for shape and pose; hence we can retrieve objects either similar in shape or similar in pose. Our evaluation of shape retrieval accuracy follows the experiment settings in [3]. Specifically, we evaluate on AMASS dataset which comprises groundtruth SMPL parameters. To avoid confusion of notations, we denote with \(\varvec{\dot{\beta }}\) the SMPL shape parameters and denote with \(\varvec{\dot{\theta }}\) the SMPL pose parameters. For each queried object \(\mathbf {X}\), we encode it into a latent code and search for its closest neighbour \(\mathbf {Y}\) in latent space. The retrieval accuracy is determined by the Euclidean error between SMPL parameters of \(\mathbf {X}\) and \(\mathbf {Y}\): \(E_{\varvec{\dot{\beta }}}(\mathbf {X}, \mathbf {Y}) = \Vert \varvec{\dot{\beta }}(\mathbf {X}) - \varvec{\dot{\beta }}(\mathbf {Y}) \Vert _2\), \(E_{\varvec{\dot{\theta }}}(\mathbf {X}, \mathbf {\mathbf {Y}}) = \Vert q(\varvec{\dot{\theta }}(\mathbf {X})) - q(\varvec{\dot{\theta }}(\mathbf {Y})) \Vert _2\), where \(q(\cdot )\) converts axis-angle representations to unit quaternions. Again, to properly compare with GDVAE which uses 5 dimensions for shape and 15 dimensions for pose, we reduce the latent dimension of our model with principal component analysis(PCA). We show results for shape retrieval and pose retrieval in Table 2.
Ideally if the shape code is disentangled from the pose code, we should get a low \(E_{\varvec{\dot{\beta }}}\) and high \(E_{\varvec{\dot{\theta }}}\) when retrieving with \(\varvec{\beta }\), and vice versa. This is in accordance with our results. Interestingly, dimensionality reduction with PCA boosts the shape difference for pose retrieval. This indicates that some degree of entanglement is still present in our pose code. An example of pose retrieval is demonstrated in Fig. 4 – notice the pose similarity for the retrieved shapes.

An example of pose retrieval with our model. Bottom left: top three meshes most similar with the query in pose code. Bottom right: top three meshes of different subjects most similar with the query in pose code.
COMA Expression Extrapolation. COMA dataset spans over twelve types of extreme expressions. To evaluate the generalization capability of our model, we adopt the expression extrapolation setting of [32]. Specifically, we run a 12-fold cross-validation by leaving one expression class out and training on the rest. We subsequently evaluate reconstruction on the left-out class. Table 3 shows the average reconstruction performance of our model compared with FLAME [23] and Jiang et al.’s approach [19] (see supplementary material for the full table). Both Jiang et al. and our model allocate 4 dimensions for identity and 4 dimensions for expression, while FLAME allocates 8 dimensions for each. Our model consistently outperforms the other two by a large margin.

Pose transfer from pose sources to shape sources. Please see supplementary video at https://virtualhumans.mpi-inf.mpg.de/unsup_shape_pose/ for transferring animated sequences.

Latent interpolation of shape and pose codes on AMASS dataset. The leftmost column are source meshes, while the rightmost are target meshes. Intermediate columns are linear interpolation of specific codes at uniform time steps \(s=0\) and \(s=1\). First two rows show interpolation of pose, and last two rows show interpolation of shape.
4.3 Qualitative Evaluation
Pose Transfer. We qualitatively evaluate pose transfer on AMASS, SMAL, COMA and MANO. In each dataset, a pose sequence is transferred to a given shape. Ideally if our model learns a disentangled representation, the outputs should preserve the identity of shape source, while inheriting the deformation from pose sources. Figure 5 visualizes the transfer results. We can observe subject shape is preserved well under new poses. The results are most obvious for bodies, animals and faces. It is less obvious for hands due to their visual similarity.
Latent Interpolation. Latent representations learned by our model should ideally be smooth and vary continuously. We demonstrate this via linearly interpolating our learned shape codes and pose codes. When interpolating shape, we always fix the pose code to that of the source mesh. The same holds when we interpolate pose. Interpolation results are shown in Fig. 6. We can observe the smooth transition between nearby meshes. Furthermore, we can see that mesh shapes remain unchanged during pose interpolation, and vice versa. This indicates that variations in shape and pose are independent of each other.
5 Conclusion and Future Work
In this paper, we introduced an auto-encoder model that disentangles shape and pose for 3D meshes in an unsupervised manner. We exploited subject identity information, which is commonly available when scanning or capturing shapes using motion capture. We showed two key ideas to achieve disentanglement, namely a cross-consistency and a self-consistency loss coupled with ARAP deformation within the training loop. Our model is straightforward to train and it generalizes well across various datasets. We demonstrated the use of latent codes by performing pose transfer, shape retrieval and latent interpolation. Although our method provides an exciting next step in unsupervised learning of deformable models from data, there is still room for improvement. In contrast to hand-crafted models like SMPL, where every parameter carries meaning (joint axes and angles per part), we have no control over specific parts of the mesh with our pose code. We also observed that interpolation of large torso rotations squeezes the meshes. In future work, we plan to explore a more structured pose space for easier part manipulation, which allows easy user manipulation, and plan to generalize our method to work with un-registered pointclouds as input. Since our model builds on simple yet effective ideas, we hope researchers can build on it and make further progress in this exciting research direction.
References
Anguelov, D., Srinivasan, P., Koller, D., Thrun, S., Rodgers, J., Davis, J.: Scape: shape completion and animation of people. In: ACM SIGGRAPH 2005 Papers, pp. 408–416. Association for Computing Machinery (2005)
Arun, K.S., Huang, T.S., Blostein, S.D.: Least-squares fitting of two 3-D point sets. IEEE Trans. Pattern Anal. Mach. Intell. PAMI 9(5), 698–700 (1987)
Aumentado-Armstrong, T., Tsogkas, S., Jepson, A., Dickinson, S.: Geometric disentanglement for generative latent shape models. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 8181–8190 (2019)
Ben-Chen, M., Weber, O., Gotsman, C.: Spatial deformation transfer. In: Proceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, pp. 67–74 (2009)
Bouritsas, G., Bokhnyak, S., Ploumpis, S., Bronstein, M., Zafeiriou, S.: Neural 3D morphable models: spiral convolutional networks for 3D shape representation learning and generation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 7213–7222 (2019)
Chen, T.Q., Li, X., Grosse, R.B., Duvenaud, D.K.: Isolating sources of disentanglement in variational autoencoders. In: Advances in Neural Information Processing Systems, pp. 2610–2620 (2018)
Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., Abbeel, P.: Infogan: interpretable representation learning by information maximizing generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2172–2180 (2016)
Cosmo, L., Norelli, A., Halimi, O., Kimmel, R., Rodolà, E.: Limp: learning latent shape representations with metric preservation priors (2020)
Deng, B., et al.: Neural articulated shape approximation. In: The European Conference on Computer Vision (ECCV), December 2020
Denton, E.L., et al.: Unsupervised learning of disentangled representations from video. In: Advances in Neural Information Processing Systems, pp. 4414–4423 (2017)
Esser, P., Haux, J., Ommer, B.: Unsupervised robust disentangling of latent characteristics for image synthesis. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2699–2709 (2019)
Gao, L., Lai, Y.K., Liang, D., Chen, S.Y., Xia, S.: Efficient and flexible deformation representation for data-driven surface modeling. ACM Trans. Graph. (TOG) 35(5), 1–17 (2016)
Gao, L., et al.: Automatic unpaired shape deformation transfer. ACM Trans. Graph. (TOG) 37(6), 1–15 (2018)
Groueix, T., Fisher, M., Kim, V.G., Russell, B.C., Aubry, M.: 3D-CODED: 3D correspondences by deep deformation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11206, pp. 235–251. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01216-8_15
Higgins, I., et al.: beta-vae: Learning basic visual concepts with a constrained variational framework. ICLR 2(5), 6 (2017)
Hu, Q., Szabó, A., Portenier, T., Favaro, P., Zwicker, M.: Disentangling factors of variation by mixing them. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3399–3407 (2018)
Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: Advances in Neural Information Processing Systems, pp. 2017–2025 (2015)
Jiang, B., Zhang, J., Cai, J., Zheng, J.: Disentangled human body embedding based on deep hierarchical neural network. IEEE Trans. Vis. Comput. Graph. 26(8), 2560–2575 (2020)
Jiang, Z.H., Wu, Q., Chen, K., Zhang, J.: Disentangled representation learning for 3D face shape. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 11957–11966 (2019)
Joo, H., Simon, T., Sheikh, Y.: Total capture: a 3D deformation model for tracking faces, hands, and bodies. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8320–8329 (2018)
Kim, H., Mnih, A.: Disentangling by factorising. In: Proceedings of the 35th International Conference on Machine Learning (ICML) (2018)
Levinson, J., Sud, A., Makadia, A.: Latent feature disentanglement for 3D meshes. arXiv preprint arXiv:1906.03281 (2019)
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4D scans. ACM Trans. Graph. 36(6), 194:1–194:17 (2017). Two first authors contributed equally
Liu, A.H., Liu, Y.C., Yeh, Y.Y., Wang, Y.C.F.: A unified feature disentangler for multi-domain image translation and manipulation. In: Advances in Neural Information Processing Systems, pp. 2590–2599 (2018)
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: a skinned multi-person linear model. ACM Trans. Graph. (TOG) 34(6), 1–16 (2015)
Lorenz, D., Bereska, L., Milbich, T., Ommer, B.: Unsupervised part-based disentangling of object shape and appearance. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10955–10964 (2019)
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: Amass: archive of motion capture as surface shapes. In: IEEE International Conference on Computer Vision (ICCV). IEEE, October 2019
Mathieu, M.F., Zhao, J.J., Zhao, J., Ramesh, A., Sprechmann, P., LeCun, Y.: Disentangling factors of variation in deep representation using adversarial training. In: Advances in Neural Information Processing Systems, pp. 5040–5048 (2016)
Paysan, P., Knothe, R., Amberg, B., Romdhani, S., Vetter, T.: A 3D face model for pose and illumination invariant face recognition. In: 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, pp. 296–301 (2009)
Ploumpis, S., Wang, H., Pears, N., Smith, W.A., Zafeiriou, S.: Combining 3D morphable models: a large scale face-and-head model. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10934–10943 (2019)
Pons-Moll, G., Romero, J., Mahmood, N., Black, M.J.: Dyna: a model of dynamic human shape in motion. ACM Trans. Graph. (Proc. SIGGRAPH) 34(4), 120:1–120:14 (2015)
Ranjan, A., Bolkart, T., Sanyal, S., Black, M.J.: Generating 3D faces using convolutional mesh autoencoders. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11207, pp. 725–741. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01219-9_43
Rhodin, H., Salzmann, M., Fua, P.: Unsupervised geometry-aware representation for 3D human pose estimation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11214, pp. 765–782. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01249-6_46
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: modeling and capturing hands and bodies together. ACM Trans. Graph. (ToG) 36(6), 245 (2017)
Sahasrabudhe, M., Shu, Z., Bartrum, E., Alp Guler, R., Samaras, D., Kokkinos, I.: Lifting autoencoders: unsupervised learning of a fully-disentangled 3D morphable model using deep non-rigid structure from motion. In: Proceedings of the IEEE International Conference on Computer Vision Workshops (2019)
Shu, Z., Sahasrabudhe, M., Alp Güler, R., Samaras, D., Paragios, N., Kokkinos, I.: Deforming autoencoders: unsupervised disentangling of shape and appearance. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11214, pp. 664–680. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01249-6_40
Skafte, N., Hauberg, S.R.: Explicit disentanglement of appearance and perspective in generative models. In: Advances in Neural Information Processing Systems 32, pp. 1018–1028. Curran Associates, Inc. (2019)
Sorkine, O., Alexa, M.: As-rigid-as-possible surface modeling. In: Symposium on Geometry Processing, vol. 4, pp. 109–116 (2007)
Sumner, R.W., Popović, J.: Deformation transfer for triangle meshes. ACM Trans. Graph. (TOG) 23(3), 399–405 (2004)
Szabó, A., Hu, Q., Portenier, T., Zwicker, M., Favaro, P.: Challenges in disentangling independent factors of variation. arXiv preprint arXiv:1711.02245 (2017)
Tan, Q., Gao, L., Lai, Y.K., Xia, S.: Variational autoencoders for deforming 3d mesh models. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5841–5850 (2018)
Tretschk, E., Tewari, A., Zollhöfer, M., Golyanik, V., Theobalt, C.: Demea: Deep mesh autoencoders for non-rigidly deforming objects. arXiv preprint arXiv:1905.10290 (2019)
Zhang, J., Huang, Y., Li, Y., Zhao, W., Zhang, L.: Multi-attribute transfer via disentangled representation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 9195–9202 (2019)
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2223–2232 (2017)
Zuffi, S., Kanazawa, A., Jacobs, D.W., Black, M.J.: 3D menagerie: modeling the 3D shape and pose of animals. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6365–6373 (2017)
Acknowledgements
This work is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - 409792180 (Emmy Noether Programme, project: Real Virtual Humans). We also want to thank members of Real Virtual Humans group for useful discussion.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary material 2 (mp4 39996 KB)
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhou, K., Bhatnagar, B.L., Pons-Moll, G. (2020). Unsupervised Shape and Pose Disentanglement for 3D Meshes. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12367. Springer, Cham. https://doi.org/10.1007/978-3-030-58542-6_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-58542-6_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58541-9
Online ISBN: 978-3-030-58542-6
eBook Packages: Computer ScienceComputer Science (R0)