
Abstract
In this study, sliding mode controller (SMC) with PID surface is designed for the trajectory tracking control of robot manipulator using antlion optimization algorithm (ALO) compared with another technique called gray wolf optimizer (GWO). The idea is to determine optimal parameters (Kp, Ki, Kd, and lamda) ensuring best performance of robot manipulator system minimizing the integral time absolute error (ITAE) criterion or the integral time square error (ISTE) criterion; the modeling and the control of the robot manipulator were realized in MATLAB environment. The simulation results prove the superiority of ALO in comparison with GWO algorithm.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The use of robotic arms in industrial applications has significantly been increased. The robot motion tracking control which required high accuracy, stability, and safety is one of the challenging problems due to highly coupled and nonlinear dynamic. In the presence of model uncertainties such as dynamic parameters (e.g., inertia and payload conditions), dynamic effects (e.g., complex nonlinear frictions), and unmodeled dynamics, conventional controllers have many difficulties in treating these uncertainties. Sliding mode control (SMC) is one of the most robust approaches to overcome this problem. The most distinguished property of the sliding mode control lies in its insensitivity to dynamic uncertainties and external disturbances.
However, this approach exhibits high-frequency oscillations called chattering when the system state reaches the sliding surface, which has negative effects on the actuator control and excite the undesirable unmodeled dynamics.
Recently, sliding mode, integral sliding mode controllers (ISMC), and proportional integral sliding mode controllers (PI-SMC) were examined by many researchers as a powerful nonlinear controller in [1,2,3,4,5,6,7]. An adaptive sliding mode control is designed in several papers [8,9,10,11,12]. The proportional integral derivative sliding mode controller (PID-SMC) was designed to control the robot manipulator in several works. The investigation of fuzzy logic and neuro-fuzzy logic control to design an adaptive sliding mode control are found in [13,14,15,16].
Currently, evolutionary algorithms have appeared as an alternative design method for robotic manipulator. M. Vijay and Debaschisha design a PSO-based backstepping sliding mode controller and observer for robot manipulators [17]. This authors used PSO to tune the sliding surface parameters of SMC coupled with artificial neuro-fuzzy inference system (ANFIS) [18].
The optimization of the PID-SMC parameters using ALO is outperformed in comparison with GA and PSO algorithms by Mokeddem and Draidi to control a nonlinear system [19].
This paper presents the use of novel optimization algorithms to tune SMC with PID surface for the trajectory tracking control of robot manipulator. These algorithms are described in Sect. 3. Section 2 designates the mathematical model of robot manipulator. The principle of SMC and its application on the robot manipulator are titled in Sect. 4. The simulation results are presented in Sect. 5.
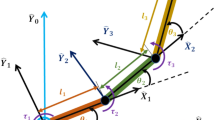
2 Dynamic Model of Robot Manipulator
By applying Lagrange’s principle, the dynamic model of two-degree-of-freedom (2DOF) robot manipulator is given by
where qi, \( {\dot{q}}_i \), and \( {\ddot{q}}_i \) present the link position, velocity, and acceleration vectors, respectively. M(q) is the matrix inertia given by
where
\( C\left(q,\dot{q}\right) \) is the Coriolis centripetal force matrix given by
where
is given by
Finally, \( F\left(\dot{q}\right)={\left[{F}_{11}\kern0.5em {F}_{21}\right]}^T \) is the friction force vector given by
and τ is the vector of the torque control signal, where mi and li are the link mass and length, respectively.
3 Evolutionary Algorithms
3.1 Gray Wolf Optimizer (GWO)
GWO is a recent meta-heuristic optimizer inspired by gray wolves and proposed by [20]. It mimics the leadership hierarchy and the hunting mechanism of gray wolves in nature.
As described in literature, the GWO algorithm includes two mathematical models: encircling prey and hunting prey.
The encircling behavior: During the hunting, the gray wolves encircle prey. The mathematical model is presented in the following equations:
where D is the distance, \( \overset{\rightharpoonup }{\ {X}_p}(t) \) is the position vector of prey, \( \overset{\rightharpoonup }{\ X}(t) \) indicates the position of the gray wolf, t indicates the current iteration, and\( \overset{\rightharpoonup }{A} \) and \( \overset{\rightharpoonup }{C} \) are coefficient vectors calculated as follows:
where components of a are linearly decreased from 2 to 0 over the course of iterations and r1 and r2 are random vectors in [0 1].
The hunting model: Four types of gray wolves participate in chasing prey; alpha, beta, delta, and omega denote the wolf group and are employed as solutions (fittest, best, and candidate) for simulating the leadership hierarchy.
The optimization algorithm is guided by α, β, and δ; with three best solutions obtained so far, the other search agents follow them and update their positions according to the best search agent as follows:
3.2 The Ant Lion Optimizer
Another novel nature-inspired algorithm called ant lion optimizer (ALO) mimics the hunting mechanism of antlions in nature [21]. Five main steps of hunting prey such as the random walk of ants, building traps, entrapment of ants in traps, catching preys, and rebuilding traps are implemented in this algorithm.
Since ants move stochastically in nature when searching for food, a random walk is chosen for modeling ants’ movement as follows:
where cumsum calculates the cumulative sum, n is the maximum number of iteration, t shows the step of random walk (iteration in this study), and r(t) is a stochastic function defined as follows:
and rand is a random number generated with uniform distribution in the interval of [0,1]. The position of ants is saved and utilized during optimization in the following matrix:
where Ai. j shows the value of the jth variable (dimension) of ith ant, n is the number of ants, and d is the number of variables. The position of an ant refers to the parameters for a particular solution. A fitness (objective) function is utilized during optimization, and the following matrix stores the fitness value of all ants:
where f is the objective function. In addition to ants, we assume the antlions are also hiding somewhere in the search space. In order to save their positions and fitness values, the following matrices are utilized:
ALi. j shows the jth dimension value of ith antlion, n is the number of antlions, and d is the number of variables (dimension), where MOAL is the matrix for saving the fitness of each antlion.
Random walks of ants: Random walks are all based on the Eq. (1). Ants update their positions with random walk at every step of optimization, which is normalized using the following equation (min–max normalization) in order to keep it inside the search space:
where ai is the minimum of random walk, di is the maximum of random walk, \( {c}_i^t \) is the minimum, and \( {d}_i^t \) indicates the maximum of ith variable at tth iteration.
Trapping in antlion’s pits: The ants walk in a hypersphere defined by the vectors c and d around a selected antlion are affected by antlions’ traps. In order to mathematically model this supposition, the following equations are proposed:
where ct is the minimum of all variables at tth iteration, dt indicates the vector including the maximum of all variables at tth iteration, \( {c}_i^t \) is the minimum of all variables for ith ant, \( {d}_i^t \) is the maximum of all variables for ith ant, and \( {\mathrm{Antlion}}_j^t \) shows the position of the selected jth antlion at tth iteration.
Building trap: In order to model the antlions’s hunting capability, a roulette wheel is employed for selecting antlions based of their fitness during optimization. Ants are assumed to be trapped in only one selected antlion. This mechanism gives high chances to the fitter antlions for catching ants.
Sliding ants towards antlion: Once antlions realize that an ant is in the trap they shoot sands outwards the center of the pit. This behavior slides down the trapped ant that is trying to escape. For mathematically modelling this behavior, the radius of ants’s random walks hyper-sphere is decreased adaptively. The following equations are proposed in this regard:
where I is a ratio, ct is the minimum of all variables at tth iteration, and dt indicates the vector including the maximum of all variables at tth iteration. In Eqs. (21) and (22), \( I={10}^W\frac{t}{T} \) where T is the maximum number of iterations and w is a constant defined based on the current iteration. Basically, the constant w can adjust the accuracy level of exploitation.
Catching prey and rebuilding the pit: For mimicking the final stage of hunt this process, it is assumed that catching prey occur when ants becomes fitter (goes insides and) than its corresponding antlion, which is required to update its position to the latest position of the hunted ant. The following equation is proposed in this regard:
where \( {\mathrm{Antlion}}_j^t \)shows the position of selected jth antlion at tth iteration and \( {\mathrm{Ant}}_i^t \) indicates the position of ith ant at tth iteration.
Elitism: In this algorithm the best antlion obtained so far in each iteration is saved and considered as an elite.
Since the elite is the fittest antlion, it should be able to affect the movements of all the ants during iterations. Therefore, it is assumed that every ant randomly walks around a selected antlion by the roulette wheel and the elite simultaneously as follows:
where\( {R}_A^t \) is the random walk around the antlion selected by the roulette wheel at tth iteration, \( {R}_E^t \) is the random walk around the elite at tth iteration, and \( {\mathrm{Ant}}_i^t \) indicates the position of ith ant at tth iteration.
4 Sliding Mode Control
The principle of this type of control consists in bringing, whatever the initial conditions, the representative point of the evolution of the system on a hypersurface of the phase space representing a set of static relationships between the state variables.
The sliding mode control generally includes two terms:
Ueq: A continuous term, called equivalent command. Un: a discontinuous term, called switching command.
4.1 Equivalent Command
The method, proposed by Utkin, consists to admit that in sliding mode, everything happens as if the system was driven by a so-called equivalent command . The latter corresponds to the ideal sliding regime, for which not only the operating point remains on the surface but also for which the derivative of the surface function remains zero \( \dot{S}(t)=0 \)(that mean, invariant surface over time).
4.2 Switching Control
The switching command requires the operating point to remain at the neighborhood of the surface. The main purpose of this command is to check the attractiveness conditions:
The gain λ is chosen to guarantee the stability and the rapidity and to overcome the disturbances which can act on the system. The function sign (S(x, t)) is defined as
The PID sliding surface for the sliding mode control can be indicated using the following equation:
with kp, ki, and kd mentioned as PID parameters.\( e(t)={q}_{\mathrm{d}}-q,\dot{e(t)}={\dot{q}}_{\mathrm{d}}-\dot{q.} \)
qd and q are the desired and actual position of the robot articulations. \( {\dot{q}}_{\mathrm{d}} \) and \( \dot{q} \) are the desired and actual speed of the robot articulations.
According to Eq. (26)
To calculate Ueq, it is necessary that\( \dot{S}(t)=0 \)
with
Finally, the PID-SMC torque presented as in [18], with the demonstration of the Lyapunov stability condition, becomes
5 Simulation and Results
The main goal of this work is to optimize the parameters of SMC with PID surface for the trajectory control of 2DOF robot manipulator by the minimization of ITAE and ISTE objective functions mentioned as
The parameters of the robot that have been taken in application are m1 = 10 kg, m2 = 5 kg, l1 = 1 m, l2 = 0.5 m, and the gravity g = 9.8 m/s2. First, we apply the algorithms described above to tune SMC controller. The objective function values for different optimization algorithms obtained with ITAE and ISTE criteria, defined in Eqs. (30) and (31), respectively, have been shown in Table 1.
It can be seen from the Table 1 that ALO algorithm gives minimum to the objective function compared with those of GWO, which means that ALO algorithm gives the best optimum that has minimum objective function better then GWO algorithm. The corresponding optimum parameters of PIDSMC were recapitulated in Table 2.
Figure 1 shows the control input applied to the first and second articulations obtained so far by both optimization algorithms. In order to avoid the chattering effect of the “sign” function, used in Eq. (29), the latter is replaced by the “tanh” (hyperbolic tangent) function. It can be seen from Fig. 2 that the resulting torque was almost close for both chosen criteria and the two optimization algorithms.

Control torque of link 1 and link 2 with (sign) function ITAE criteria

Control torque signal of SMCPID controller with (tanh) function: (a) ISTE criteria and (b) ITAE criteria
Figures 3 and 4 show the error of the robot manipulator to track the desired trajectory by the minimization of ISTE and ITAE criteria, respectively. We can see from the figures that ALO algorithm, which has smaller cost function, outperforms GWO algorithm even if we change the objective function. The convergence curve of the used functions was represented in Fig. 5. The corresponding position of robot manipulator controlled by SMCPID controller optimized by the two algorithms was shown in Fig. 6.

Tracking error of both articulations with ISTE criteria and (tanh) function

Tracking error of both articulations with ITAE criteria and (tanh) function

Convergence curve of cost function: (a) ITAE criteria and (b) ISTE criteria

Position of two articulations controlled by SMCPID controller with (tanh) function: (a) ITAE criteria and (b) ISTE criteria
6 Conclusion
In this paper the optimization of the SMC with PID surface was realized with new techniques of optimization called ALO and GWO algorithms; the ALO presents more robustness in trajectory tracking control of 2DOF robot manipulator, regarding the convergence curve of the cost function, even if we change the objective function. From the observations of the simulations, we can realize the benefits of using evolutionary algorithms to tune the controller parameters than the traditional methods, especially when the system is highly nonlinear or in presence of disturbances where an online optimization is recommended.
References
Adhikary, N., & Mahanta, C. (2018). Sliding mode control of position commanded robot manipulators. Control Engineering Practice, 81, 183–198.
Jung, S. (2018). Improvement of tracking control of a sliding mode controller for robot manipulators by a neural network. International Journal of Control, Automation and Systems, 16(2), 937–943.
Yoo, D. (2009). A comparison of sliding mode and integral sliding mode controls for robot manipulators. Transactions of the Korean Institute of Electrical Engineers, 58(1), 168–172.
Liu, R., & Li, S. (2014). Optimal integral sliding mode control scheme based on pseudo spectral method for robotic manipulators. International Journal of Control, 87(6), 1131–1140.
Zhao, Y., Sheng, Y., & Liu, X. (2014). A novel finite time sliding mode control for robotic manipulators. IFAC Proceedings, 47, 7336–7341.
Azlan, N. Z., & Osman, J. H. S. (2006). Proportional integral sliding mode control of hydraulic robot manipulators with chattering elimination. In: First International Conference on Industrial and Information Systems, Sri Lanka.
Das, M., & Mahanta, C. (2014). Optimal second order sliding mode control for nonlinear uncertain systems. ISA Transactions, 53, 1191–1198.
Adelhedi, F., Jribi, A., Bouteraa, Y., & Derbe, N. (2015). Adaptive sliding mode control design of a SCARA robot manipulator system under parametric variations. Journal of Engineering Science and Technology Review, 8(5), 117–123.
Jiang, S., Zhao, J., Xie, F., Fu, J., Wang, X., & Li, Z. (2008). A novel adaptive sliding mode control for manipulator with external disturbance. In: 37th Chinese Control Conference (CCC).
Yi, S., & Zhai, J. (2019). Adaptive second-order fast nonsingular terminal sliding mode control for robotic manipulators. ISA Transactions, 90, 41–51.
Jing, C., Xu, H., & Niu, X. (2019). Adaptive sliding mode disturbance rejection control with prescribed performance for robotic manipulators. ISA Transactions, 91, 41–51.
Mirshekaran, M., Piltan, F., Esmaeili, Z., Khajeaian, T., & Kazeminasab, M. (2013). Design sliding mode modified fuzzy linear controller with application to flexible robot manipulator. International Journal of Modern Education and Computer Science, 10, 53–63.
Tran, M.D., & Kang, H.J. (2015). Adaptive fuzzy PID sliding mode controller of uncertain robotic manipulator. In: International Conference on Intelligent Computing: Intelligent Computing Theories and Methodologies, ICIC, pp. 92–103.
Ataei, M., & Shafiei, S. E. (2008). Sliding mode PID-controller design for robot manipulators by using fuzzy tuning approach. In: 27th Chinese Control Conference.
Nejatbakhsh Esfahani, H., & Azimirad, V. (2013). A new fuzzy sliding mode controller with PID sliding surface for underwater manipulators. International Journal of Mechatronics, Electrical and Computer Technology, 3(9), 224–249.
Kharabian, B., Bolandi, H., Ehyaei, A. F., Mousavi Mashhadi, S. K., & Smailzadeh, S. M. (2017). Adaptive tuning of sliding mode-PID control in free floating space manipulator by sliding cloud theory. American Journal of Mechanical and Industrial Engineering, 2(2), 64–71.
Vijay, M., & Jena, D. (2018). PSO based backstepping sliding mode controller and observer for robot manipulators. In: International Conference on Power, Instrumentation, Control and Computing (PICC).
Vijay, M., & Jena, D. (2017). PSO based neuro fuzzy sliding mode control for a robot manipulator. Journal of Electrical Systems and Information Technology, 4(1), 243–256.
Mokeddem, D., & Draidi, H. (2018). Optimization of PID sliding surface using Antlion optimizer. International Symposium on Modelling and Implementation of Complex Systems MISC, pp. 133–145.
Mirjalili, S., Mirjalili, S. M., & Lewis, A. (2014). Grey wolf optimizer. Advances in Engineering Software, 69, 46–61.
Mirjalili, S. (2015). The ant lion optimizer. Advances in Engineering Software, 83, 80–98.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Loucif, F., Kechida, S. (2020). Sliding Mode Control with PID Surface for Robot Manipulator Optimized by Evolutionary Algorithms. In: Farouk, M., Hassanein, M. (eds) Recent Advances in Engineering Mathematics and Physics. Springer, Cham. https://doi.org/10.1007/978-3-030-39847-7_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-39847-7_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-39846-0
Online ISBN: 978-3-030-39847-7
eBook Packages: Physics and AstronomyPhysics and Astronomy (R0)