
Abstract
The design of digital circuits using Cartesian Genetic Programming (CGP) has been widely investigated but the evolution of complex combinational logic circuits is a hard task for CGP. We introduce here a new mutation operator for CGP that aims to reduce the number of evaluations needed to find a feasible solution by modifying the subgraph of the worst output of the candidate circuits. Also, we propose a variant of the standard evolutionary strategy commonly adopted in CGP, where (i) the Single Active Mutation (SAM) and (ii) the proposed mutation operator is used in order to improve the capacity of CGP in generating feasible circuits. The proposals are applied to a benchmark of combinational logic circuits with multiple outputs and the results obtained are compared to those found by a CGP with SAM. The main advantages observed when both mutation operators are combined are the reduction of the number of objective function evaluations required to find a feasible solution and the improvement in the success rate.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The design of digital electronic circuits is a task that requires time and knowledge of specific rules. These circuits design’s complexity increases when the number of inputs and outputs become greater. The traditional design of electronic circuits is aided by several methods, such as the Karnaugh Maps and ESPRESSO [1]. On the other hand, evolutionary computation proved to be a powerful tool in this task. The so-called Evolvable Hardware (EH) consists of the use of evolutionary computation techniques in the design and implementation of hardware in general.
The first efforts for evolving electronic circuits were made by Koza [7], using Genetic Programming. Later, EH methods were also developed by Coello and his collaborators [2,3,4] and Miller and his collaborators [11,12,13]. In particular, Miller proposed Cartesian Genetic Programming (CGP), in which programs are represented as directed acyclic graphs (DAGs), encoded by a matrix of nodes. In addition, CGP is pointed out as the most efficient technique for the evolution of digital circuits [18]. Most of these circuits are combinational logic circuits (CLCs), i.e., digital circuits whose outputs are represented only by a combination of its inputs. There are no memory elements.
Despite the great success of CGP’s application in this task, several works recently published in [16] point out that the EH researches still works with the same problems of 15 years ago and are walking through a very challenging scenario for balancing the real needs of the industry with the capacity of designing circuits via CGP, where the most complex circuit already evolved is 28-input benchmark [19]. The evolution of more complex circuits using CGP can be found only minimizing the number of gates of known models [18].
Although CGP has difficulties in evolving complex circuits, this metaheuristic is still used as it proved to be efficient obtaining circuits that escape the traditionalism of human design, especially when the goal is to find more compact circuits in terms of reducing the number of logic gates. One of the reasons that CGP finds it difficult to evolve larger circuits is the problem of scalability, that is, the complexity of the circuit design increases exponentially with the number of inputs [12]. This is directly linked to the very definition of CLCs. As a consequence, several works aim to increase and to improve the CGPs capability of exploring the search space, such as [5, 6, 9, 10, 14, 15]. This exploitation capacity is directly linked to the search space and to the genetic operators involved. CGP normally only uses mutation to generate new individuals, and point mutation and SAM (Single Active Mutation) are the most adopted approaches.
We propose a new mutation operator for designing CLCs, where the solutions created in each generation aim to improve the subgraphs whose outputs present the minimum amount of hits with respect to the truth table, increasing the assurance that the mutations will not be harmful to the good subgraphs already obtained by the evolutionary process. The Evolution Strategy (ES) commonly used in CGP is also modified. In this way, we propose (i) a new mutation operator to CGP when applied to CLCs and, (ii) the combination of the proposed mutation with SAM modifying the ES 1 + \(\lambda \) commonly used in CGP. The results of the proposals are compared to those obtained by a baseline CGP using SAM.
2 Cartesian Genetic Programming
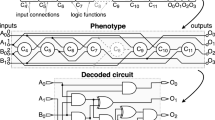
Cartesian Genetic Programming (CGP) is a type of Genetic Programming proposed by Miller [12]. In CGP, the programs are DAGs represented by a matrix of processing nodes and each node contains genes that describe its function and connections to the other nodes. Each node of this matrix is represented by its inputs and one function. Here, the functions represent logic gates. Also, each node connects to other ones on its left columns in the matrix. Figure 1 illustrates a CGP individual with a \(3 \times 3\) matrix when solving a problem with 3 inputs and 3 outputs. CGP has three user-defined parameters: number of columns (\(n_{c}\)) and rows (\(n_{r}\)) of the matrix that encodes the graph, and levels-back (lb). Levels-back is the number of columns (on the left side) in which each node can be connected.
The most common search technique used in CGP is an Evolutionary Strategy (ES) (1 + \(\lambda \)) [12], where \(\lambda \) is the number of new solutions generated at each iteration, as presented in Algorithm 1. In this case, the best individual between the parent and the \(\lambda \) new generated solutions is selected to the next generation.

Example of a CGP individual with levels-back = number of columns. The continuous lines connect the active nodes (in gray) which form the phenotype. The value into each node represents its function which is applied to its inputs.

In CGP, the most used mutation is the point mutation [12]. However, when using the point mutation, the changes may occur in nodes which do not interfere in the output of the solutions (inactive nodes) leading to a lack of modifications in the phenotype. These nodes are the white ones in Fig. 1. The single active mutation (SAM) [5] is another common mutation and was proposed for reducing the wasted evaluations of objective functions, where (i) one node and one of its elements (inputs or function) are selected at random, and (ii) the value is changed to another valid value. The steps (i) and (ii) are repeated until an active node is modified. So SAM ensures that one active node is changed.
Here, the evolutionary process is divided into two steps where the objectives are (i) to maximize the number of correct outputs when compared to the truth table (to obtain a feasible solution) and (ii) to minimize the number of logic gates. In the first step, the best individual is the one with the most matches with respect to the truth table. After a feasible solution is found, the best is the feasible individual with the smaller number of logic gates. The best individual is promoted as father to the subsequent generation.
2.1 Binary Decision Diagrams
Binary Decision Diagrams (BDDs) can be used to evaluate the individuals [19]. BDD is a directed acyclic graph with one root and two terminal nodes that are referred to as 0 and 1. All other nodes are called non-terminal nodes. Each non-terminal node (v) is labeled with a boolean variable (var), and have two child nodes, representing high (var(v) = 1) and low (var(v) = 0) levels. An Ordered Binary Decision Diagram (OBDD) is a BDD with a defined variable ordering, a tuple T(\(z_{1},...,z_{m}\)). A node labeled as \(z_{i}\) has two child nodes \(z_{j}\) and \(z_{k}\). The node labeled as \(z_{j}\) has a higher index in T than its father (\(i< j\)). The same occurs for the other child node. This ordering allows for the simplification of OBDDs.
A Reduced Ordered Binary Decision Diagram (ROBDD) is an OBDD where each node represents a unique logic function [19], and can be reduced using two rules: elimination and isomorphism. In elimination, the nodes which children point to the same node can be removed, keeping only the children. In isomorphism, given nodes v and w, v can be removed and all its incoming edges can be redirected to w when: (i) v and w are terminals and have the same value, and (ii) v and w are inner nodes, they are labeled by the same boolean variable, and their children are the same. ROBDDs can be used to evaluate the candidate circuits in CGP once it is canonical for a particular function and variable order.
Given a XOR gate with the outputs of two CLCs (\(C_{A}\) and \(C_{B}\) with outputs \(y_{1},...,y_{m}\) and \(y'_{1},...,y'_{m}\) respectively) as its inputs, these two circuits, represented by ROBDDs, are functionally equivalent when for all output i, the result of \(k_{i} = y_{i}\) XOR \(y'_{i}\) is an empty set in the set(\(k_{i}\)). It is possible to use the Sat-Count function on all \(k_{i}\) outputs and count all the results. The resulting value represents the Hamming distance between \(C_{A}\) and \(C_{B}\). When the result of the Sat-Count is equal to zero, the circuits \(C_{A}\) and \(C_{B}\) are functionally equivalent.
The desired circuit and the candidate solution are represented by independent ROBDDs. Thus, the fitness function adopted is to minimize the Sat-Count between their outputs. The Sat-Count function used is provided by the Buddy Package [8]. The use of ROBDD for the individuals’ representation and the Sat-Count as fitness function used in this work are the same presented in [19].
3 The Proposed Approaches
Here two proposals are presented. First, a new mutation operator focused on mutating the worst individuals’ subgraph (GAM). Then, a proposal combining both mutation operators (SAM and GAM) are presented.
3.1 Guided Active Mutation
The proposed mutation operator, labeled here as GAM (Guided Active Mutation) consists of modifying active(s) node(s) on the subgraph from the inputs to the outputs with the smallest number of correct values when compared to the truth table. Thus, GAM does not mutate nodes in subgraphs which already match their corresponding values in the truth table. This feature is important due to the reduction of wasted evaluations. Modifications in subgraphs which generate correct outputs will be worst or equal to the preliminary candidate circuit, as it already matches its full truth table.
GAM is presented in Algorithm 2 and the procedure is as follows: (i) select the output of the circuit with the smallest number of correct values with respect to the truth table (called here worst output), (ii) choose one of the worst outputs randomly when a tie occurs, (iii) select the active nodes in the subgraph from the inputs to this selected output (even if the nodes are in the path of other outputs), and (iv) mutate one (or more) randomly selected active node this subgraph. This mutation is made by changing one of the node’s inputs or function. In (i), there is an array that stores the fitness value of each individual’s outputs. In (ii), the active nodes of each individual’s outputs are also stored in arrays.

Here we modify only one active node in each new candidate solution, but this can be modified (while instruction in Algorithm 2). One can notice that GAM tries to improve the worst subgraph of the candidate solution. Also, GAM always modifies an active node only, differently of SAM, in which inactive nodes are modified up to an active note is changed.

(a) Are the parent of generation 1 and its subgraph that composes the output O1 is showed in (b), in red. (c) is the parent of generation 2 created by a mutation in node 10 from the previous parent with its respective subgraph in red. Both subgraphs in red of (c) and in blue of (d) match 6 of 8 bits with respect to the truth table. One of them will be randomly chosen to receive the GAM operator to generate the subsequent offspring. (Color figure online)
Figure 2 illustrates the GAM operator with an individual with three inputs (I0, I1, and I2) and three outputs (O0, O1, and O2). The numbered circles represent the nodes of the individual (gates of the circuit). The nodes in gray are the active ones, and those in white are the inactive ones. The arrows represent the directed connections between the nodes and the continuous lines connect the active nodes. The phenotype (circuit) is composed of inputs, active nodes and the connections between them, and outputs. In this way, the path to the output O2 of the first individual is formed by I2, and nodes 5, 8 and 11.
For this illustrative example, the number of correct values of the outputs of the individuals of iterations 1 and 2 is presented in Table 1. In generation 1, output O1 is the worst one, as it matches 3 of 8 possible bits of the truth table. The other outputs of this circuit hit 8 and 6 of the values of the truth table. Then, GAM modifies only the active nodes in the subgraph of output O1, which are the red nodes highlighted in Fig. 2(b).
Considering that the offspring created during generation 1 is the parent of generation 2, generated by a mutation in node 10, as presented in Fig. 2(c), such modification improved output O1: 6 values are correct now. In this case, the worst output of this individual can be O1 or O2. So, the GAM procedure will randomly choose one of them. The subgraphs of these outputs are shown in Fig. 2(c) and (d). Furthermore, in cases that outputs share active nodes, a mutation can improve an output and deteriorate another one with respect to the matches to the truth table, as shown in Fig. 2(c) and (d), where the node 5 is shared by all outputs and node 8 is shared between outputs O1 and O2.
Preliminary experiments using GAM demonstrated that the proposed mutation operator is capable of reducing the number of evaluations needed to find a feasible solution. However, GAM did not reach high success rates (number of independent runs in which a feasible solution is found). Thus, a new approach is also proposed here, where SAM and GAM are applied together.
3.2 CGP with SAM and GAM: \((1+\lambda _{SAM}+\lambda _{GAM})\)-ES
In order to increase the success rate, we proposed to modify the commonly used \((1+\lambda )\)-ES to a \((1+\lambda _{SAM}+\lambda _{GAM})\)-ES. In this proposal, \(\lambda _{SAM}\) individuals are generated using SAM and \(\lambda _{GAM}\) individuals are created using GAM. Thus, we take advantage of both mutation operators into a single approach (SAMGAM). This is justified as the SAM can mutate inactive nodes, which favors the Neutral Genetic Drift (NGD) reported as an important characteristic of CGP [12, 17]. So, even if SAM and GAM are applied independently, each operator will be responsible for acting differently on the genotype. SAM is applied to an active node and one or more inactive nodes, and GAM is applied only to the outputs’ subgraphs that are considered the worst, trying to improve them.
4 Computational Experiments
Computational experiments were performed in order to comparatively analyze the performance of the proposals. We considered here: CGP with Single Active Mutation (labeled as SAM and 4+0), CGP with the proposed Guided Active Mutation (labeled as GAM and 0+4), and CGP with an \((1+\lambda _{SAM} + \lambda _{GAM})\)-ES (labeled as SAMGAM and, its variants 1+3, 2+2 and 3+1). Thus, 5 techniques were tested. The problems used in all experiments are benchmarks and arithmetic circuits, and its characteristics are presented in Table 2, where name, number of inputs (ni), number of outputs (no), number of columns (nc) used by CGP, the number of Gates related in RevLibFootnote 1, and the maximum number of evaluations allowed (Eval.) are shown. Also, Balancing (Bal.) represents the ratio between the number of 0s observed in the outputs of the truth table and the total the number of outputs of the truth table (number of outputs \(\times \) number of lines), and Simplification (Simp.) is the ratio between the number of gates related in column Gates and the number of gates required to form the circuit through the sum of products. Previous studies have shown that CGP has ease in solving problems whose the boolean expressions are simplifiable (smaller values of Simp. imply simplifiable circuits). In addition, balancing of the number of 0s and 1s in the outputs of the truth tables also can affect the performance of the methods. This is similar to the unbalancing problem in machine learning. Thus, the number of objective function evaluations allowed to the search methods are based on the number of inputs of the circuit, and the rates of balancing and simplification. The number of function evaluations is ni \(\times \,(obj_{\text{ balancing }}\,+\,obj_{\text{ simplification }})\), where \(obj_{\text{ balancing }}\,=\,800,000\) if the balancing ratio is in [0.5, 0.75], and 1, 600, 000 otherwise, and \(obj_{\text{ simplification }}\,=\,1,600,000\) if the simplification ratio is in [0, 0.0138], and 800, 000 otherwise. These values were chosen empirically.
The search process is (i) to find a feasible solution and (ii) to minimize the number of gates. The parameters adopted here are \(\lambda = 4\), \(n_{r} = 1\) and lb = \(n_{c}\)/2, as lower values of lb tends to reduce the number of active nodes [10]. The number of independent runs is 30 and the function set is \(\varGamma \) = {AND, OR, NOT, NAND, NOR, XOR, XNOR} for all the tested problems. Also, the algorithm runs until the maximum number of evaluations of the objective function is reached. The source-codes of the proposals and supplementary material are availableFootnote 2.
The median of the number of objective function evaluations observed to find a feasible solution and the percentage of the number of independent runs in which a circuit that produces the same outputs observed in the truth table (success rate: SR) are presented in Table 3. Kruskal-Wallis test was performed in order to compare the results statistically. The best results are highlighted in boldface. SAM was capable of achieving the highest success rate on all problems, except for inc. When compared to SAM (4+0), GAM (0+4) is able to reduce the number of objective function evaluations needed to find a feasible solution in 6 out of 12 problems in median but obtained the worst success rates. SAMGAM approaches (1+3, 2+2 and 3+1) obtained the best results in median (8 of 12 problems). Also, approaches in which GAM generates more than one offspring, the best median results are obtained in 7 of 12 problems. This means that the major influence of SAM when using SAMGAM is perceptible only in problem z4ml. Regarding the statistical tests, only 4 of the 12 problems presented statistical differences between the proposals.
In Table 4, the mean of the total number of gates are presented for the first feasible solution and for the best solution found. The column Red. (Reduction) presents the relative difference between the values observed in the first feasible solution and the best solution. When SAM (4+0) is used, its first feasible solutions (10 of 12 problems) and its best solutions (9 of 12 problems) have fewer logic gates. Also, the circuits found by GAM are not compact. With respect to the reduction capability between the first feasible solution and the best solution obtained, approaches using SAM and GAM were able to find the best values for reducing the number of logic gates in 7 of the 12 problems. Based on the information of the problems in which each of the methods was better, it is possible to conclude that GAM shows a good performance for circuits (i) with smaller values of Simp., (ii) with higher values of Bal., and (iii) with a larger number of inputs. SAMGAM presented good results for circuits that (i) are not simplifiable, (ii) have high unbalance rate, and (iii) fewer inputs. No common features were observed in the problems in which SAM achieved the best performance.
5 Concluding Remarks and Future Work
A new mutation operator for Cartesian Genetic Programming (CGP) was introduced here in order to design combinational logic circuits. The proposed mutation operator was compared to a baseline CGP with Single Active Mutation (SAM). Also, the proposed Guided Active Mutation (GAM) was combined with SAM to increase the capability of GAM in finding feasible solutions and performed better than the other approaches considered here.
GAM modifies the subgraphs of the individuals which can still be improved, reducing wasted mutations on full match subgraphs. Thus, GAM was able to find feasible solutions with a reduced number of objective function evaluations when compared to the baseline CGP with SAM in most of the problems.
It is possible to conclude that SAM (i) obtained the highest success rates for most problems, (ii) obtains first feasible solution with lower number of logic gates for most problems, and (iii) obtains the best solution with the least number of logic gates in 9 of the 12 problems. The proposed GAM operator (i) requires less number of objective function evaluations to find a feasible solution when compared to SAM, (ii) obtains low success rates for all problems, (iii) does not have the capacity to find compact circuits (fewer logic gates) and, (iv) works well for circuits that are simplifiable, unbalanced and with a larger number of inputs. In order to obtain an approach that reaches high success rates (SAM) and low number of objective functions for finding a feasible solution (GAM), it is possible to conclude that the SAMGAM approaches (i) obtained the best results for most problems in the median, (ii) obtained high success rates, and (iii) works well for the circuits that are not simplifiable, have high unbalance rate, and fewer inputs.
It is important to notice that when the solutions share active nodes, GAM can improve one output but deteriorating the other one. The crossover operator proposed in [14] can take advantage of this specific improvement and discard the deterioration in the other output. Thus, the exploration of using this crossover into SAMGAM is an interesting research avenue. Finally, we also intend to apply the proposed SAMGAM to more complex problems and conduct a study regarding the mutation of more than one active node when using GAM.
References
Brayton, R.K., Hachtel, G.D., McMullen, C., Sangiovanni-Vincentelli, A.: Logic Minimization Algorithms for VLSI Synthesis, vol. 2. Springer, Heidelberg (1984). https://doi.org/10.1007/978-1-4613-2821-6
Coello, C.A.C., Aguirre, A.H.: Design of combinational logic circuits through an evolutionary multiobjective optimization approach. AI EDAM 16(1), 39–53 (2002)
Coello, C.A.C., Alba, E., Luque, G.: Comparing different serial and parallel heuristics to design combinational logic circuits. In: Proceedings of the NASA/DoD Conference on Evolvable Hardware, pp. 3–12 (2003)
Coello, C.A.C., Luna, E.H., Aguirre, A.H.: Use of particle swarm optimization to design combinational logic circuits. In: Tyrrell, A.A.M., Haddow, P.C., Torresen, J. (eds.) ICES 2003. LNCS, vol. 2606, pp. 398–409. Springer, Heidelberg (2003). https://doi.org/10.1007/3-540-36553-2_36
Goldman, B.W., Punch, W.F.: Reducing wasted evaluations in cartesian genetic programming. In: Krawiec, K., Moraglio, A., Hu, T., Etaner-Uyar, A.Ş., Hu, B. (eds.) EuroGP 2013. LNCS, vol. 7831, pp. 61–72. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-37207-0_6
Husa, J., Kalkreuth, R.: A comparative study on crossover in cartesian genetic programming. In: Castelli, M., Sekanina, L., Zhang, M., Cagnoni, S., García-Sánchez, P. (eds.) EuroGP 2018. LNCS, vol. 10781, pp. 203–219. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-77553-1_13
Koza, J.R.: Genetic Programming II, Automatic Discovery of Reusable Subprograms. MIT Press, Cambridge (1992)
Lind-Nielsen, J., Cohen, H.: Buddy - a binary decision diagram package (2014). https://sourceforge.net/projects/buddy/
Manfrini, F.A.L., Bernardino, H.S., Barbosa, H.J.C.: A novel efficient mutation for evolutionary design of combinational logic circuits. In: Handl, J., Hart, E., Lewis, P.R., López-Ibáñez, M., Ochoa, G., Paechter, B. (eds.) PPSN 2016. LNCS, vol. 9921, pp. 665–674. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-45823-6_62
Manfrini, F.A.L., Bernardino, H.S., Barbosa, H.J.C.: On heuristics for seeding the initial population of cartesian genetic programming applied to combinational logic circuits. In: Proceedings of GECCO, pp. 105–106 (2016)
Miller, J.F.: An empirical study of the efficiency of learning boolean functions using a cartesian genetic programming approach. In: Proceedings of the 1st Annual Conference on Genetic and Evolutionary Computation, vol. 2, pp. 1135–1142. Morgan Kaufmann Pub. Inc. (1999)
Miller, J.F.: Cartesian genetic programming. In: Miller, J. (ed.) Cartesian Genetic Programming, pp. 17–34. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-17310-3_2
Miller, J.F., Job, D., Vassilev, V.K.: Principles in the evolutionary design of digital circuits - Part I. Genet. Program Evolvable Mach. 1(1–2), 7–35 (2000)
da Silva, J.E., Bernardino, H.: Cartesian genetic programming with crossover for designing combinational logic circuits. In: Proceedings of the 7th Brazilian Conference on Intelligent Systems (BRACIS), pp. 145–150. IEEE (2018)
da Silva, J.E.H., Manfrini, F.A., Bernardino, H.S., Barbosa, H.J.: Biased mutation and tournament selection approaches for designing combinational logic circuits via cartesian genetic programming. In: ENIAC, pp. 835–846 (2018)
Stepney, S., Adamatzky, A. (eds.): Inspired by Nature: Essays Presented to Julian F. Miller on the Occasion of his 60th Birthday. ECC, vol. 28. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-67997-6
Turner, A.J., Miller, J.F.: Neutral genetic drift: an investigation using cartesian genetic programming. GP Evolvable Mach. 16(4), 531–558 (2015)
Vasicek, Z.: Cartesian GP in optimization of combinational circuits with hundreds of inputs and thousands of gates. In: Machado, P., et al. (eds.) EuroGP 2015. LNCS, vol. 9025, pp. 139–150. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-16501-1_12
Vasicek, Z., Sekanina, L.: How to evolve complex combinational circuits from scratch? In: Proceedings of the Conference on Evolvable Systems (ICES), pp. 133–140. IEEE (2014)
Acknowledgments
We thank the reviewers for your suggestions and the support provided by CNPq (grant 312682/2018-2), FAPEMIG (grant APQ-00337-18), Capes, PPGCC/UFJF, PPGMC/UFJF.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
da Silva, J.E.H., de Souza, L.A.M., Bernardino, H.S. (2019). Cartesian Genetic Programming with Guided and Single Active Mutations for Designing Combinational Logic Circuits. In: Nicosia, G., Pardalos, P., Umeton, R., Giuffrida, G., Sciacca, V. (eds) Machine Learning, Optimization, and Data Science. LOD 2019. Lecture Notes in Computer Science(), vol 11943. Springer, Cham. https://doi.org/10.1007/978-3-030-37599-7_33
Download citation
DOI: https://doi.org/10.1007/978-3-030-37599-7_33
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-37598-0
Online ISBN: 978-3-030-37599-7
eBook Packages: Computer ScienceComputer Science (R0)