
Abstract
The proliferation in the number of available online reviews provides an excellent opportunity to use this accumulated enormous information of any product in a more strategic way to improve the quality of the product and services of the e-commerce company. Due to the non-uniform quality of online reviews, it is crucial to identify those helpful reviews from the pile of a large amount of low quality and low informative other reviews. This system will help the customers to form an unbiased opinion quickly by looking at its level of helpfulness. The e-commerce companies measure the helpfulness of a review using the number of votes it gets from other customers. This situation arises problems to newly-authored potentially helpful reviews due to lack of votes. Thus it is essential to have an automated process to estimate and predict helpfulness of any review. This paper identifies the essential characteristics of online reviews influencing the helpfulness of it. This study categorized all characteristics of reviews collected from previous literature in four main categories and then study the combined effect of the four aspects in predicting the helpfulness of a review. The product type (Search or Experience) acts as a control variable in the factors identification model of helpful prediction of a review. An analysis of total 14782 reviews from Amazon.com across five different product category shows the factors influencing the helpfulness of a review varies across product categories. Then a comparative study of two widely used machine learning, Artificial Neural Network and Multiple Adaptive Regression Spline are presented to predict the helpfulness of online review across five different categories and a better method of predicting helpfulness of online reviews are suggested based on the type of product. This study solves the starvation problem of potential newly-authored or infamous reviews without any manual votes along with high accuracy of helpfulness prediction.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
An increasing number of online reviews, e-commerce websites have offered customers their platforms to give their opinions and reviews of products, services, and the seller of the product. These reviews are given by those customers who have already bought or used the products from that e-commerce website or any other sources and are considered as a proxy for the product quality in offline word-of-mouth (WoM) communication. Online customer reviews are defined as “peer-generated product evaluations posted on company or third party websites” [17]. Ecommerce websites allow the customer to share their views about the products and services provided by them in two ways: (a) by numerical star ratings ranging 1 to 5, (b) by providing an area to write your opinion about the product. The availability of customer reviews on an e-commerce website has proved to make a better perception in the customer about its importance, social presence [1], and “stickiness” (time spent on a particular e-commerce site). Increasing the availability of online reviews also proliferate the opportunity of using it more strategically to improve the product and service of the e-commerce company. Now, the quality of these online reviews is not likely to be uniform, and this could range from an excellently vivid description and evaluation to spam with no value addition to make any decision about the purchase. The reviews which are helpful to customers in decision making generally lies under the heap of a large amount of low quality and low informative or fake (and spam) reviews and hence it is challenging for customers to identify and use those helpful reviews to form an unbiased opinion about any product or service.
To solve this problem, e-commerce websites allow the customer to vote for or against the review to show their support or disagreement with that particular review content. For example, “100 out of 140 people found the review helpful” shows the fact that 100 people apart from the reviewer found the review helpful to make their decision and rest 40 people did not find it helpful. The website also allows sorting all customer reviews as per helpfulness of it. However, there is found no such theoretically grounded specific explanation of what are the factors determining the helpfulness of a review and how they are being calculated to sort it. A massive portion of reviews contains no votes or have few votes, and this makes it more challenging to understand their helpfulness and social validity. As per Yang et al. [29], only 20% of the reviews from Amazon dataset [6] have more than five votes, and rest of them either do not have any votes or lesser than five votes. This situation arises problems to the newly authored potential reviews, which does not get the chance to be read by other customers due to lack of votes or infamous products. Therefore, it is essential to have an automated system to estimate helpfulness of any review instead of some manual process (Fig. 1).

An example of the structure of a review on Amazon.com.
The purpose of this study predicts a score denoting the helpfulness of a review automatically by identifying and analyzing linguistic, psychological, and peripheral factors of any review. Previous researches on this issue mostly address either linguistic determinants of psychological features affecting the helpfulness of any review. This study allows focusing on all possible aspect of factors possibly drive the helpfulness of online reviews together. The four identified an aspect of factors that determines helpfulness can be categorized into four types, e.g., Linguistic, Psychological, Text complexity, and peripheral cues. This study identifies the fact that considering only one type of factor to determine review helpfulness might neglect the other aspect of features, which can play a significant part in it. Therefore, apart from the confirmed variables (Rating, Positive emotion, Negative emotion etc.) from previous literature, this study considered not only considered the linguistic features (word count, word per sentence, adjective, etc.) but also the psychological (Analytical thinking, Tone, Authenticity, and Confidence) thought process of the reviewer.
The previous studies [12, 13, 17] also address the fact that product type act as a control variable, and for different types of products (Search good or Experience good), the factors driving helpfulness can differ. Therefore, this study considers this constraint and chooses five different categories of products to address whether and how the determinants of review helpfulness differ as per product type. For example, a highly analytical review may be more useful for cellphone category product customers than the grocery category of products. The five categories are chosen in such a way that it includes not only pure search type (cellphone, clothing) or experience type (beauty, grocery) of good but also products which do not have any physical presence (digital music) and can be considered both search and experience type.
Our research addresses three research questions. First, what are the linguistic and psychological features across different product categories and whether it is needed to study them separately or not? Second, what are the determinants driving the perceived helpfulness of an online review based on different product categories? Third, which method, among the two most used machine learning supervised methods, better predict the helpfulness of an online review?
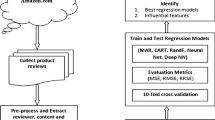
To address these three research questions, a significantly large number of online reviews from Amazon.com are collected, and these reviews belong to five different categories of products (beauty, grocery, cellphone, clothing, and digital music). The linguistic and psychological variables of online reviews of each product category are extracted using R and Linguistic Inquiry and Word Count (LIWC) software. Then, to address our first research question, one-way ANOVA is performed across all five product categories on all the chosen variables (linguistics and linguistics, etc.) from literature. Next, to explore the factors determining the review helpfulness, the most widely adopted method, Linear regression (LR), is used. Due to the non-linear structure of the data, LR performed poorly and hence a wrapper built around Random Forest classification algorithm, Boruta, is performed, and a subset of variables are selected to predict the helpfulness of reviews of that particular product category reviews. Finally, two widely used machine learning algorithms, Artificial Neural Network (ANN), and Multiple Adaptive Regression Splines (MARS) are used to predict the helpfulness of online reviews using R 3.4.4 software. These two prediction methods are then compared in terms of their Mean Squared Error (MSE) to select the better performing model for each of five product categories.
In short, this study helps to process a large number of online reviews efficiently in an automated way even if reviews do not have any manually entered votes and generate a helpfulness score based on different types of characteristics of a review for each written review. Customers can quickly sort the reviews as per their helpfulness score to make a better purchase decision.
This paper is organized in the following sections. Section 2 presents the previous literature reviews related to these topics. Section 3 presents the method of data collection. Section 4 presents the selection of various variables for this study from the literature. Section 5 gives a clear stepwise idea of the research methodology to solve our research questions. Section 6 presents the result of the experiments and the analysis of the results. Finally, the implication of this study and future scopes are concluded in Sect. 7.
2 Literature Review
Previous researches on the helpfulness of reviews were mainly addressed two typical questions: (i) finding out the critical factors influencing review helpfulness, and (ii) propose a suitable method to predict review helpfulness. The next two sections will address the studies focused on these two issues separately.
2.1 Important Factors Influencing Review Helpfulness
A customer review can have a set of different features, such as Numerical rating, Number of words used in that review, Polarity (Positive, Negative) of the review content, the readability of the text, Style of the writing, etc. Mudambi and Schuff [17] studied the influence of several words in a review, as well as the extremity of a review on the helpfulness of that review. They experimented with their hypothesis using Amazon.com review datasets. The results of this experiment (Tobit Regression) indicate a positive relationship between several words in a review and helpfulness of that review by considering the product type (search or experienced) as a moderator. Korfiatis et al. [10] studied the effect of readability of the review content with the helpfulness of it. In this paper, they measured readability in following four ways: Gunning Fog Index, Flesch reading scale, Coleman-Liau index, and Automated readability index and suggested that readability of review has a more significant impact on helpfulness than several words in it. Ghose and Ipeirotis [3] considered reviewer information, subjectivity, spelling error, and another six type of readability index to study the relationship of these factors with the helpfulness of review. Their study also shows a significant influence of these six readability indexes on review helpfulness. Krishnamoorthy [11], in his research, considered a set of linguistic characteristics (adjective terms, state and action verbs) and compared with other factors (readability, subjectivity). The results from his study showed that rather than considering only readability measure and numerical rating as essential factors, a hybrid model with some linguistic variables could better explain review helpfulness in terms of predictive accuracy. Ghose and Ipeirotis [3] and Forman [2] et al. also supported this explanation given by Krishnamoorthy, showing that a combination of subjective and objective features of review better explains the review helpfulness than considering any of them separately.
In our study, we adopted linear regression primarily to understand the relationship between the dependent (Helpfulness ratio) and an independent variable. Then Boruta algorithm [14] is applied to measure the variable importance as a better explanation of the dependent variable. The methods addressed in the literature did not take into the nonlinear data structure of the Amazon.com dataset. Thus, using linear regression or other methods with linearity assumption will not be appropriate to derive important factors of review helpfulness.
2.2 Prediction Methodology of Review Helpfulness
Mudambi and Schuff [17], Yin et al. [30], Yang et al. [29], Korfiatis et al. [10] and Forman et al. [2] defined helpfulness of a review as the ratio of helpful votes to total number of votes (Helpful votes + Unhelpful votes). They mostly adopted the commonly used method, Linear Regression (LR), to examine the critical factors and prediction of the helpfulness of reviews. Forman et al. [2] transformed the helpfulness ratio in two-class, Helpful, and Unhelpful based on a threshold value and then predicted the helpfulness using linear regression.
Another commonly used method in this research is Support Vector Machine (SVM), as it handles both linear and nonlinear data. Kim et al. [9] applied Support Vector Regression (SVR) for review prediction. Hu and Chen [4] adopted M5P, SVR, and linear regression to measure their prediction performance and did a comparative analysis. Krishnamoorthy [11] used three techniques, e.g., Support vector classification, Random forest, and Naïve Bayes, to predict review helpfulness and then compared them to propose the best prediction model.
Khashei and Bijari [8] proposed a prediction model using Artificial Neural Network (ANN) due to its data-driven and self-adaptive features. Lee et al. [15] adopted a multilayer perceptron neural network (BPN) to predict review helpfulness and compared it with linear regression analysis.
In our study, we adopted three methods (linear regression, Multiple Adaptive Regression Splines, and ANN) and compared their results to find the best suitable method to predict helpfulness. Linear regression was chosen as it is a convenient method addressed in the literature. The other two methods (Multiple Adaptive Regression Splines and ANN) were selected due to their capability of handling nonlinearity in data and better accuracy in prediction.
3 Data Collection
We gathered data for this study from http://jmcauley.ucsd.edu/data/amazon/ [6] since 2005–2014. Amazon product reviews are collected category wise, and the categories are Beauty, Grocery, Cell phone, Clothing, and Digital music. These five product types were chosen in the study based on the following reasons:
-
These five categories contain a large number of customer reviews to be analyzed and modeled for training and testing purposes.
-
Based on the Nelson [18, 19] study, we included both search (Cell phone) and experience (beauty, grocery) type of products category.
-
Our study addresses the fact that a product can exist along a continuum from simple search to pure experience type of product and hence, considers product categories involving mix (Clothing) of search and experience features.
-
Digital products are the latest kind of products in the market with no physical presence. Thus, digital music category reviews are included in this study.
For each category mentioned above, all reviews are collected along with their respective numerical rating, Title, review text, the number of helpful and unhelpful votes. After preprocessing and cleansing of data, we excluded those reviews from analysis, which does not have a minimum of ten votes as minimal helpful votes can introduce biases in the model.
A total of 14782 reviews are finally collected after pre-processing to be analyzed after removing all reviews having lesser than ten votes (Table 1).
The structure of the data collected is presented below (Fig. 2):

An example of the structure of data collected from Amazon.com.
4 Variable Selection
Due to the unstructured form of review text apart from some explicit information (Numerical rating, Number of helpful votes, and several total votes), the review text is transformed into a standard structural format using LIWC (Linguistic Inquiry and Word Count) 2015 software.
LIWC is a text analysis software proposed by Pennebaker [22] to transform the unstructured text into approximately 90 output scores. This 90 output variable evaluates not only the structural and style feature if the text, but also the psychological thought process of reviewer [23,24,25, 27]. This tool is extensively used and validated by many articles and research papers [7, 20].
The LIWC output is shown below (Fig. 3):

An example of the output processed by LIWC software.
All variables are selected from previous literature studies and are categorized into four broad categories: (i) Linguistic, (ii) Psychological, (iii) Text complexity, and (iv) Peripheral cues.
The linguistic category of variables is based on the structure of sentence, punctuations, part of speech, polarity or tone of sentences, etc. Example: pronoun, article, preposition, auxiliary verb, word count, word per sentence, adjective.
The psychological category of variables focuses on feeling and thought processes using semantics. Example: comparative words (bigger, better), Analytic, Clout, Percept, Positive emotion, Tone, Negative emotion.
The text complexity category of variables includes those helping the review to understand or read easily or with difficulty. Example: Flesch reading ease index, Syllable, Dictionary word.
The peripheral ques category contains those variables which are independent of review text. Example: Rating, Time of the review posted.
In our study, the dependent variable (Helpfulness) is defined as the ratio of several helpful votes to the total votes (helpful +Unhelpful). For example, for a review where “100 people out of 150 found this review helpful”, the helpfulness of the review will be (100/150) 0.67.
The independent variables are chosen from different kinds of literature listed below:
-
Linguistic variables:
-
Compare: It is defined as the total number of comparative words (bigger, smaller, greater, etc.) used in the review.
-
Pronoun: It is measured by the number of pronouns in the text.
-
Ppron: It is defined as the number of personal pronouns (I, you, he, she, etc.) in the review and is calculated as the percentage of several pronouns.
-
Article: It is defined as the number of articles (a, an, the, etc.) mentioned in the text.
-
Preposition: It is measured by the total number of preposition in the review.
-
Auxiliary verb: It is defined as the total number of the auxiliary verb (might, must, could, etc.) used in the review.
-
Adverb: It is defined as the total number of adverb verb (very, slowly, quickly, etc.) used in the review.
-
Adjective: It is defined as the total number of adjectives (better, bright, dull, thick, etc.) used in the review.
-
AllPunctuation: It is defined as the total number of sentences with complete and with grammatically correct punctuations used in the review.
-
I: It is defined as the percentage number of occurrences of the word ‘I’ in the review.
-
-
Psychological variables:
-
Analytic: It is known as the categorical dynamic index (CDI) and addresses the level of the formal, logical, and hierarchical thought process of the reviewer. A high score implies more formal, logical, and hierarchical thinking.
-
Clout: It is defined as the level of expertise or leadership in some context, or how much one is confident about his or her opinions. A higher clout score indicates a more professional and confident opinion, while a lower score indicates a tentative or humble style.
-
Tone: It defines the sentimental and emotional tone of the whole text. A score higher than 50 indicates a positive tone, and lower than 50 scores indicate tone with sadness or anxiety or hostility. The exact score of 50 indicates either a lack of emotion or ambivalence.
-
Authentic: It is defined as the level of honesty and disclosing thinking of the reviewer, i.e., expressing more personal, humble, and authentic opinions about something. A higher score indicates more honest and vulnerable thinking.
-
Cogproc: It is measured as the ratio words evoking the cognitive thought process (cause, know, etc.) of the thinker. A high cogproc score will indicate a more cognitive opinion rather than thorough normal senses.
-
Percept: It is measured as the ratio words evoking perceptual thought process (“look,” “feeling,” etc.) of the thinker. A high percept score will indicate that the opinion is generated and backed up by using the sensed of the reviewer rather than any cognitive information.
-
Posemo: It is measured by the ratio of positive emotion words to the total words in the text. It is identified as one of those confirmed factors determining review helpfulness [5, 11, 16, 19, 21, 24, 26].
-
Negemo: It is measured by the ratio of negative emotion words to the total words in the text. It is identified as one of those confirmed factors determining review helpfulness [5, 11, 16, 19, 21, 24, 26].
-
-
Text complexity:
-
WC: It is defined as the total number of words in the review. It is a certain factor of review helpfulness studied in previous literature. It is used as a proxy for text complexity [15, 19].
-
WPS: It is defined as the number of words per sentence. It is used for sentence complexity [2, 3, 9].
-
Sixltr: It is defined as the number of words longer than six letters and is used as a proxy for word complexity.
-
Dic: It is defined as the percentage of target words captured by the LIWC dictionary.
-
Flesch Kincaid Readability: It is defined as the measure of difficulty in reading and understanding a text in English. A higher score indicates that the text piece is easy to read and understand.
-
-
Peripheral Cues:
-
Rating: Rating is a numeric score (1 to 5) given by the customer. It is identified as a confirmatory factor of review helpfulness as studies in the literature [5, 9, 15].
-
5 Research Methodology
The research methodology of this study is described here stepwise below:
Firstly, reviews collected were collected and cleaned, and the preprocessed to get a basic format as below to proceed further (Fig. 4):

A glimpse of input data after data cleaning and pre-processing.
In the second step, the reviews written in the English language is transformed into a various numeric score using LIWC dictionary. If any target word is matched with the dictionary word, then the corresponding variable’s (out of those 90 variables) score is incremented by one. Figure 5 shows an example of this process.

Cataloging target words using LIWC 2015 into different linguistic and psychological variables scores.
Next, the exploratory data analysis is performed on our five datasets to calculate the mean and standard deviations of reviews of all categories. To address our first research question, one-way ANOVA is performed on all the variables selected to test whether the product categories are significantly different or not.
In the next step, the determinants of the review helpfulness are explored using linear regression and the Boruta algorithm. Though linear regression is easy to understand and explainable, due to the nonlinear structure of data, it is not suitable to explore the relationship between determinants and the target variable. Hence, Boruta algorithm is performed to explore which independent variables affect the target variable.
In the final step, the helpfulness of online reviews is predicted using the two most widely used techniques for nonlinear data, i.e., Multiple Adaptive Regression Splines (MARS) and Artificial Neural Network (ANN). These two methods to predict online helpfulness of reviews are then compared to determine the suitable method to predict the helpfulness. The helpfulness is predicted considering 70% of training data, and then the mean squared error (MSE) is calculated for both to compare their results for each of five categories.
6 Results and Discussion
6.1 ANOVA Analysis Across Product Categories
Our first research question was whether review characteristics varied across different product categories and if the result is positive, then how they were different. The averages of review features were identified from the literature, and one-way ANOVA was performed to examine the differences, as presented in Table 2. The hypothesis for the ANOVA test is as follow:
-
H Null: The mean of each feature across five categories are same, i.e.,
$$ \upmu1 =\upmu2 =\upmu3 =\upmu4 =\upmu5 $$ -
H Alternative: Means of features across five categories are not all equal.
The ANOVA result shows that the p values for all identified features are less than 0.01, which indicates that all research variables are significantly different at the 99% confidence interval across the five product types. Thus, the null hypothesis is rejected.
The F critical value is 2.37, which is much lesser than the F value of each feature. Therefore, the ANOVA result indicates to the fact that review characteristics vary across different product categories, and so it should be analyzed separately.
The results of Table 2 and Fig. 6 can be interpreted as follows. Product reviews for the Digital Music category (average 260 words) are found to be the longest among the five product types based on WC, and approximately twice the average length of reviews for Clothing (123 words) and Grocery category (153 words). Moreover, WPS (27.48) and Analytic (72.22) for Digital Music are the highest. This means that the reviews for Digital Music are composed of lengthy and analytical sentences. The reason can be explained as reviewers may require more words to write reviews containing the personal experience and analytical expressions of the music for Digital Music category products. The level of Clout shows the highest score (54.67) for Music, but the lowest score (27.40) for Beauty category.

Comparison of average scores of WC, Analytic, Clout, Authentic, WPS, Percept, Tome, and Flesch Kincaid score across five product categories.
On the other hand, the Authentic scores showed the opposite results. Reviews for beauty have the highest Authentic scores (58.83), while the video has the lowest Authentic (23.70) scores. In other words, product reviews for Digital Music tend to be written expertly, whereas those of beauty is written authentically in a personal manner. Additionally, Tone (75.72) scores are highly positive in all five categories and are highest in the Clothing category pf products. This can be because reviewers express their personal experience of using and fitting of the product as per their product quality more elaborately than Cell phone category (64.33) products. The score of Percept for beauty Category (5.54) is found to be the highest among five categories as reviewers may use many sensory-based expressions such as “looked,” “heard,” or “feeling” for beauty, the quality of which is evaluated based on senses. The Flesch Kincaid score of Digital Music category (12.13) is highest as reviewers mostly write their personal feeling of that music is a very informal easy way to express emotion involved with it.
In conclusion, as seen in the previous results, reviews for different product categories have different characteristics. Thus it would be necessary to analyze review helpfulness for each product category separately.
6.2 Factors Determining Review Helpfulness
Our second research question was to identify the determinant factors in the perceived helpfulness of reviews depending on their product category. To do so primarily, Linear regression (LR) is performed across product categories (Table 3).
From the above table, it is seen that the R-square value is very small except for the Digital Music category (0.47). The reason may be due to the nonlinear nature of the data set. To visualize the structure of five data sets, the high dimensional (25 dimensions) data is transferred to a lower dimension (2 dimensions using t-Distributed Stochastic Neighbor Embedding (t-SNE). t-Distributed Stochastic Neighbor Embedding (t-SNE) is a nonlinear method to reduce dimensionality for better visualization of data.
This algorithm works in the following way:
-
Calculate the probability of similarity of points in high-dimensional space
-
Calculating the probability of similarity of points in the corresponding low-dimensional (2D in this case) space.
-
The similarity of data points is calculated as the conditional probability that a point X would select point Y as its neighbor if neighbors were chosen in proportion to their probability density under a Gaussian centered at X.
-
The objective function is to minimize the difference between these similarities in high dimensional and low dimensional space to give a suitable representation of data in lower-dimensional space.
However, after this transformation, it is not possible to identify the input features and make any conclusions based on the output (Fig. 7).

A two-dimensional transformation of five datasets (a) grocery dataset, (b) beauty dataset, (c) cellphone dataset, (d) music dataset, and (e) clothing dataset.
Since the data is appeared to be nonlinear in shape, the Pearson correlation method cannot be used here to analyze the relationship between the dependent variable (Helpfulness Ratio) and Independent Variables.
Feature selection is a necessary procedure to reduce the high dimensional data into lower dimensions extracting the important variables among all variables. For this generally, Principal Component Analysis, Singular Value Decomposition, etc. methods are used. However, the primary assumption for the process mentioned above is that the data is linear. Also, these techniques do not consider feature values and target values. Therefore, using these methods shall not be applied in our data set.
The feature selection process can be categorized into three following process:
-
Filter Methods: This method does not depend on the machine learning algorithm. Here, features are chosen based on various statistical tests for their correlation with the target variable. Example: Pearson Correlation, Spearman Correlation, Chi-squared test, Fisher’s Score, etc.
-
Wrapper Methods: This method of feature selection considers subsets of features that allow interaction with other variables by adding or removing features from that subset using a predictive model. Each subset is used to train the model and tested on a hold-out set. This is a computationally extensive algorithm but generally gives the best performing feature set for that model. Example: Recursive feature elimination, Sequential feature selection algorithms, Genetic algorithms, etc.
-
Embedded Methods: Embedded feature selection method combines the advantages of both filter and wrapper selection methods and performs feature selection and classification together. This method of selection is not computationally extensive, like wrapper methods. Example: Lasso, Forward selection with Decision trees, Forward selection with Gram Schmidt, etc.
In our study, we used a wrapper built algorithm Boruta [14], which captures essential features with the target variable. Boruta is a wrapper build algorithm implemented in R package. In Boruta, Z score is used as a vital measure to consider the fluctuations of mean. This algorithm decides whether any feature is essential or not to predict the dependent variable. To do so, directly using Z score will not be ideal for measuring the importance of each variable as random fluctuations can mislead in this case. To handle this random fluctuations problem. For each variable, a corresponding shadow variable are defined whose values are assigned by shuffling the actual variables. And then the importance of shadow variables is used to decide the important variables.
Boruta algorithm ensures the randomness in the feature selection procedure and gives a better prediction on the importance of variables. Thus, in this paper, the Boruta algorithm is chosen for the feature selection procedure.
The final features identified important by Boruta algorithm is given below (Fig. 8):

Graphical plot of confirmed and rejected variables for the product category Clothing generated via Boruta algorithm.
From the above table, it is seen that for all five category product types, Rating, Analytic, WPS, posemo, Tone, Clout, pronoun, ppron, article, aux verb, adj, verb, I and Dic have a significant impact on review helpfulness. This implies these are the significant features to predict helpfulness scores where the rest of the variables only influence the helpfulness score of review specific to some product category. For example, Authentic variable is essential for all five categories of products. This implies a review comprising more honest and personal opinions with high involvement is perceived as more helpful to determine all five types of products. Compare variable is seen critical in Grocery, Cellphone, and Clothing category indicating usage of more comparative words (e.g., bigger, smaller, best, etc.) in the reviews. The negemo variables found vital features to predict the helpfulness score in Grocery and Cellphone category types of products. The percept variable is found necessary for Cellphone and Clothing category, which implies the usage of more perceptual words (e.g., feeling, hearing, etc.) in these product category reviews. The variable sixltr found crucial in only two product categories, namely Grocery and Digital Music, which implies the usage of more complex words (words longer than six letters). Adverb, Flesch Kincaid Readability, and All punc (Punctuation) are found prominent in only Digital Music category reviews. In other words, the usage of adverb words to express a more subjective view of the products in an easily readable manner with punctuation adequately used is an essential feature for Digital Music category products.
This concludes that with the conventional variables, for example, Rating, Word Count (WC), Word per Sentence (WPS), positive emotion (posemo), the other variables used as linguistic features of review, for example, Analytic, Clout, Tone, pronoun, personal pronoun, article, aux verb, adjective, verb, usage of I and Dictionary words are also have a significant impact on review helpfulness of any five categories of product reviews. The other variables (e.g., percept, negemo, compare, Sixltr, Flesch Kincaid Readability score, Allpunc, preposition, and adverb) also influence partially the target variables helpfulness for specific product categories.
The p-value for each of these Boruta results is 0.01, indicating the significance of the process of feature selection.
6.3 Prediction of Review Helpfulness Using Various Datamining Methods
The feature selection process gives us the critical variables affecting the target variable for each of the five category datasets. With the help of these variables, five different prediction models can be developed. In our study, we used Artificial Neural Network and Multiple Adaptive Regression Splines for prediction purposes and presented a comparative analysis of these two prediction models suggesting the best model choose for a specific category.
Multiple Adaptive Regression Splines (MARS) proposed by Friedman is a non-parametric statistical procedure to determine the relationship between a set of input variables and the dependent variable. This algorithm does not make any prior assumptions about the relationship between independent and dependent variables and works perfectly fine in both linear and nonlinear relationships. This flexibility in determining any relationship gives the idea of using MARS in this case (Fig. 9).

Model summary capturing GCV R2 (left-hand y-axis and solid black line) based on the number of terms retained (x-axis), which is based on the number of predictors used to make those terms (right-hand side y-axis) for (a) beauty dataset. (b) grocery dataset, (c) cellphone dataset, (d) Clothing dataset and (e) digital music dataset.
Artificial Neural Network (ANN) tries to model the human brain with the most straightforward definition where the building blocks are neurons. In multilayer artificial Neural Networks, each neuron is connected to others with some coefficients, and learning of the network is done by proper distribution of information through these connections. The capability of processing parallel and nonlinear behavior gives the reason use this algorithm in this paper (Fig. 10).

Model summary for Artificial Neural Network capturing inputs and weights at each layer for grocery dataset.
The selected features across five categories in Table 4 used to build five different models using MARS and ANN each to calculate the Mean Squared Error (MSE). The MSE gives the idea of the accuracy of the model across product categories. From the above Fig. 11, it is clear that Multiple Adaptive Regression Splines (MARS) produces lesser MSE than Artificial Neural Network (ANN) except the clothing category. Hence, it can be concluded that MARS gives more accurate results than the Artificial Neural Network for all categories except clothing product category. Therefore, it can be suggested that using the MARS algorithm would be better to predict review helpfulness in Beauty, Grocery, Cellphone and Digital Music category. The ANN produces lower MSE than MARS and hence can be used to predict the review helpfulness in case of clothing category.

Comparisons of mean square error: Multiple Adaptive Regression Splines Vs. Artificial Neural Network.
7 Conclusion
This study addresses three research questions. First, along with the conventional explicit variable (Rating), this paper explored several psychological and linguistic features from directly the product reviews across five different categories and examined whether these features are different for a different category using ANOVA analysis. The review of the Digital music category found to have the highest word count and written more analytically with maximum criticism. The authenticity of this category is least among all five categories.
On the other hand, Beauty category reviews are found to have the highest authenticity score but the lowest clout score indicating low expertise of reviewer. Also, it contained the most comparison words to describe the quality of the products. The ANOVA result shows that there are significant differences in review features among five different categories of product reviews at a 99% confidence interval. Secondly, the critical variables influencing the target variable (Helpfulness ratio) are explored using boruta algorithm. It is found that for all five category product types, Rating, Analytic, WPS, posemo, Tone, Clout, pronoun, ppron, article, aux verb, adj, verb, I, and Dic have a significant impact on review helpfulness. The other variables (e.g., percept, negemo, compare, Sixltr, Flesch Kincaid Readability score, Allpunc, preposition, and adverb) also influence partially the target variables helpfulness for specific product categories.
Finally, among two extensively used machine learning algorithms, the better method for review helpfulness prediction is determined. The result shows that both Multiple Adaptive Regression Splines and Artificial Neural Network performs very well as their Mean squared error is less than 5%. However, the MSE of the MARS algorithm is much lower than ANN except for the clothing category. Hence, the MARS algorithm should be used to predict review helpfulness for Beauty, Cellphone, Grocery, and Digital Music category reviews, and ANN should be used to predict the helpfulness score of Clothing category reviews.
This paper also solves the cold start problem, which arises when reviews do not receive any manual votes but have the potential to be a helpful review. Due to starvation, most of the reviews generally do not get the chance to get voted all the time. This prediction method will solve this problem by identifying important psychological, linguistic, and explanatory variables and producing a helpfulness score in the absence of any manual vote.
References
Chevalier, J.A., Mayzlin, D.: The effect of word of mouth on sales: online book reviews. J. Mark. Res. 43, 345–354 (2006)
Forman, C., Ghose, A., Wiesenfeld, B.: Examining the relationship between reviews and sales: the role of reviewer identity disclosure in electronic markets. Inf. Syst. Res. 19, 291–313 (2008)
Ghose, A., Ipeirotis, P.G.: Estimating the helpfulness and economic impact of product reviews: mining text and reviewer characteristics. IEEE Trans. Knowl. Data Eng. 23, 1498–1512 (2011)
Hu, Y.H., Chen, K.: Predicting hotel review helpfulness: the impact of review visibility, and interaction between hotel stars and review ratings. Int. J. Inf. Manag. 36, 929–944 (2016)
Hu, N., Koh, N.S., Reddy, S.K.: Ratings lead you to the product, reviews help you clinch it? The mediating role of online review sentiments on product sales. Decis. Support Syst. 57, 42–53 (2014)
McAuley, J., Targett, C., Shi, Q., van den Hengel, A.: Image-based recommendations on styles and substitutes. In: SIGIR (2015)
Kacewicz, E., Pennebaker, J.W., Davis, M., Jeon, M., Graesser, A.C.: Pronoun use reflects standings in social hierarchies. J. Lang. Soc. Psychol. 33, 125–143 (2013)
Khashei, M., Bijari, M.: An artificial neural network (p, d, q) model for time series forecasting. Expert Syst. Appl. 37(1), 479–489 (2010)
Kim, S.M., Pantel, P., Chklovski, T., Pennacchiotti, M.: Automatically assessing review helpfulness. In: Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006, pp. 423–430 (2006)
Korfiatis, N., Garcia-Bariocanal, E., Sanchez-Alonso, S.: Evaluating content quality, and helpfulness of online product reviews: the interplay of review helpfulness vs. review content. Electron. Commer. Res. Appl. 11, 205–217 (2012)
Krishnamoorthy, S.: Linguistic features for review helpfulness prediction. Expert Syst. Appl. 42, 3751–3759 (2015)
Kuan, K.K., Hui, K.L., Prasarnphanich, P., Lai, H.Y.: What makes a review voted? An empirical investigation of review voting in online review systems. J. Assoc. Inf. Syst. 16, 48–71 (2015)
Kumar, N., Benbasat, I.: The influence of recommendations on consumer reviews on evaluations of websites. Inf. Syst. Res. 17(4), 425–439 (2006)
Kursa, M., Rudnicki, W.: Feature selection with the Boruta package. J. Stat. Softw. 36(11), 1–13. http://dx.doi.org/10.18637/jss.v036.i11
Lee, S., Choeh, J.Y.: Predicting the helpfulness of online reviews using multilayer perceptron neural networks. Expert Syst. Appl. 41(6), 3041–3046 (2014)
McAuley, J., Leskovec, J.: Hidden factors and hidden topics: understanding rating dimensions with review text. In: Proceedings of the 7th ACM Conference on Recommender Systems, RecSys’, Hong Kong, China, 12–16 October 2013, pp. 165–172 (2013)
Mudambi, S.M., Schuff, D.: What makes a helpful online review? A study of customer reviews on Amazon.com. MIS Q. 34, 185–200 (2010)
Nelson, P.: Information and consumer behavior. J. Polit. Econ. 78(20), 311–329 (1970)
Nelson, P.: Advertising as information. J. Polit. Econ. 81(4), 729–754 (1974)
Newman, M.L., Pennebaker, J.W., Berry, D.S., Richards, J.M.: Lying words: predicting deception from linguistic style. Pers. Soc. Psychol. Bull. 29, 665–675 (2003)
Pan, Y., Zhang, J.Q.: Born unequal: a study of the helpfulness of user-generated product reviews. J. Retail. 87, 598–612 (2011)
Pennebaker, J.W., Booth, R.J., Francis, M.E.: Linguistic inquiry and word count (LIWC2007), LIWC, Austin, TX, USA (2007). http://www.liwc.net. Accessed 27 Apr 2018
Pennebaker, J.W., Francis, M.E.: Cognitive, emotional, and language processes in disclosure. Cogn. Emot. 10, 601–626 (1996)
Pennebaker, J.W., Boyd, R.L., Jordan, K., Blackburn, K.: The development and psychometric properties of LIWC2015. http://hdl.handle.net/2152/31333. Accessed 27 Apr 2018
Pennebaker, J.W., Chung, C.K., Frazee, J., Lavergne, G.M., Beaver, D.I.: When small words foretell academic success: the case of college admissions essays. PLoS ONE 9, e115844 (2014)
Sen, S., Lerman, D.: Why are you telling me this? An examination into negative consumer reviews on the web. J. Interact. Mark. 21, 76–94 (2007)
Tausczik, Y.R., Pennebaker, J.W.: The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 29, 24–54 (2010)
Willemsen, L.M., Neijens, P.C., Bronner, F., De Ridder, J.A.: “Highly recommended!” The content characteristics and perceived usefulness of online consumer reviews. J. Comput. Mediat. Commun. 17, 19–38 (2011)
Yang, Y., Yan, Y., Qiu, M., Bao, F.: Semantic analysis and helpfulness prediction of text for online product reviews. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015, pp. 38–44 (2015)
Yin, D., Bond, S., Zhang, H.: Anxious or angry? Effects of discrete emotions on the perceived helpfulness of online reviews. MIS Q. 38, 539–560 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Dey, D., Kumar, P. (2019). A Novel Approach to Identify the Determinants of Online Review Helpfulness and Predict the Helpfulness Score Across Product Categories. In: Madria, S., Fournier-Viger, P., Chaudhary, S., Reddy, P. (eds) Big Data Analytics. BDA 2019. Lecture Notes in Computer Science(), vol 11932. Springer, Cham. https://doi.org/10.1007/978-3-030-37188-3_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-37188-3_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-37187-6
Online ISBN: 978-3-030-37188-3
eBook Packages: Computer ScienceComputer Science (R0)