
Abstract
This paper proposes a novel crossing-workflow fragment discovery mechanism, where an activity knowledge graph (AKG) is constructed to capture partial-ordering relations between activities in scientific workflows, and parent-child relations specified upon sub-workflows and their corresponding activities. The biterm topic model is adopted to generate topics and quantify the semantic relevance of activities and sub-workflows. Given a requirement specified in terms of a workflow template, individual candidate activities or sub-workflows are discovered leveraging their semantic relevance and text description in short documents. Candidate fragments are generated through exploring the relations in AKG specified upon candidate activities or sub-workflows, and these fragments are evaluated through balancing their structural and semantic similarities. Evaluation results demonstrate that this technique is accurate and efficient on discovering and recommending appropriate crossing-workflow fragments in comparison with the state of art’s techniques.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
Considering the fact that developing a scientific workflow from scratch is typically a knowledge- and effort-intensive, and error-prone mission, reusing and repurposing the best-practices which have been evidenced by legacy scientific workflows in the repository is considered as a cost-effective and risk-avoiding strategy. Techniques have been proposed to facilitate the reuse and repurposing of workflows. The similarity of workflows (or business processes) can be assessed to evaluate whether a workflow can be replaced (or reused) by another one, and they can be categorized into annotation-based, structure-based, and data-driven mechanisms. A layer-hierarchial technique is developed to compute the similarity of scientific workflows in the myExperiment repository, where a layer hierarchy represents the relations between a workflow, its sub-workflows and activities [8]. Generally, these techniques aim to calculate the similarity for pairs of workflows, and they can promote the reuse or repurposing of workflows as the whole. It is worth emphasizing that a novel requirement may be relevant with multiple workflows. In this setting, this requirement should be achieved through discovering appropriate fragments contained in corresponding workflows, and assembling these crossing-workflow fragments accordingly. A crossing-workflow fragments discovery mechanism is developed in [6], which aims to discover fragments whose activities may be contained in various workflows. Note that parent-child relations, besides invocation ones, may exist between workflows, their sub-workflows and activities, and they have not been considered in this technique. Consequently, the discovery of crossing-workflow fragments containing activities in various granularities can hardly be implemented.
To address this challenge, we propose a novel crossing-workflow fragments discovery mechanism as follows:
-
An activity knowledge graph (denoted AKG) is constructed, where edges represent partial-ordering relations between activities in workflows, and parent-child relations specified upon sub-workflows and corresponding activities.
-
After transferring the name and text description of activities and sub-workflows into short documents, the semantic relevance of these activities and sub-workflows is quantified by their representative topics, where topics are generated by biterm topic model [7].
-
Given an activity description in the requirement as represented in terms of a workflow fragment, candidate activities or sub-workflows are discovered independently w.r.t. their semantic relevance, and then, are selected according to their short documents. Candidate crossing-workflow fragments are generated by instantiating relations in AKG specified upon candidate activities or sub-workflows, and these fragments are evaluated through balancing their structural and semantic similarities.
Experimental evaluation is conducted, and the results demonstrate that this technique is accurate and efficient on discovering and recommending appropriate crossing-workflow fragments in comparison with the state of art’s techniques.
The rest of this paper is organized as follows. Section 2 presents the technique for constructing activity-based knowledge graph. Section 3 explores the topic relevance of activities and sub-workflows. Section 4 discovers fragments crossing scientific workflows. Section 5 presents experimental setting, and Sect. 6 compares the evaluation results of this technique with the state of arts. Section 7 discusses related techniques, and Sect. 8 concludes this paper.
2 Activity Knowledge Graph Construction
As presented in our previous work [8], a scientific workflow represents invocation and parent-child relations upon sub-workflows and activities. Specifically,
Definition 1
\(\varvec{({ Scientific}~{ Workflow}).}\) A scientific workflow swf is a tuple (tl, dsc, \(SWF_{sub}\), ACT, LNK), where: (i) tl is the title of swf, (ii) dsc is the text description of swf, (iii) \(SWF_{sub}\) is a set of sub-workflows contained in swf, (iv) ACT is a set of activities contained in swf, and (v) LNK = {\(LNK_{inv}\), \(LNK_{pch}\)} is a set of links, where \(LNK_{inv}\) specifies invocation relations upon \(SWF_{sub}\) and ACT, and \(LNK_{pch}\) specifies parent-child relations upon sub-workflows in \(SWF_{sub}\) and their corresponding activities in ACT.
Note that a sub-workflow can be regarded as an activity with relatively coarse granularity. A sample scientific workflow is from Taverna 2 of myExperiment repository with the title “PubMed Search” as shown in Fig. 1, and its corresponding layer hierarchy is shown at Fig. 2(a), respectively.

A sample scientific workflow from Taverna 2 of myExperiment repository with the title “PubMed Search”.
To facilitate the discovery of crossing-workflow fragments, we construct an AKG to represent workflows, and their sub-workflows and activities. For a set of scientific workflows {swf}, AKG is defined as follows:
Definition 2
\(\varvec{({ Activity~Knowledge~Graph}).}\) An activity knowledge graph is a tuple (E, R, S), where: (i) E is a set of entities, which includes workflows, their sub-workflows and activities in {swf}, (ii) R is a set of relation types including PrtOf to specify that a sub-workflow or activity belongs to a workflow, Invok to specify an invocation relation between a pair of sub-workflows or activities, and PrtCld to specify a parent-child relation for a sub-workflow with its corresponding set of activities, and (iii) S \(\subset \) E \(\times \) R \(\times \) E is a set of triples, which specify relations prescribed upon entities.

Layer hierarchy and the corresponding snippet of AKG. (Color figure online)
A snippet of AKG is shown at Fig. 2(b), where (i) entities for workflows are denoted by nodes in orange, and \(swf_{1}\) is an example, (ii) entities for sub-workflows are denoted by nodes in pink, and “Retrive_abstracts” is an example, and (iii) entities for activities are denoted in blue, and \(act_3\) is an example. Relations are denoted as triples, and sample relations are presented as follows: \(s_1\) = (\(swf_{sub4}\), PrtOf, \(swf_{1}\)), \(s_2\) = (\(act_5\), PrtOf, \(swf_{1}\)), \(s_3\) = (\(act_5\), Invok, \(act_{6}\)), and \(s_4\) = (\(act_5\), PrtCld, \(swf_{sub4}\)).
3 Topic-Based Activity Relevance
Short documents are constructed according to the name and text description of activities and sub-workflows in order to generate their topics. Due to the briefness of the name which may hardly convey complete knowledge, words in the text description are evaluated and combined with the name to form short documents as the representation of activities or sub-workflows. A word in text description is considered as relevant when this word is (i) semantically similar with a word in the name by word similarity calculation (i.e., semantic relevance), or (ii) it co-occurs frequently with a word which is semantically equivalent or similar with a word in the name through word co-occurrence evaluation (i.e., co-occurrence relevance). Representative words are selected and appended to enhance their names, and short documents are generated accordingly.
3.1 Topic Discovery Using BTM
Leveraging short documents generated for activities and sub-workflows, this section aims to discover topics, where biterm topic model (BTM) [7] is assumed as the most suitable for handling the above constructed short documents. Generally, topics are represented as groups of correlated words in topic models like BTM. Topics are learnt by modeling the generation of word co-occurrence patterns (i.e. biterms) in our Short Document-based corpus, where the problem of sparse word co-occurrence patterns can be addressed at the document-level. The procedure of topic discovery includes the following steps:
Biterm Extraction. Based to the principle of BTM, a short text in short documents can be treated as a separate text fragment. Any pair of distinct words is extracted as a biterm, and these biterms are treated as the training data set of topic probability distribution.
BTM Training. The corpus of short documents can be regarded as a mixture of topics, where each biterm is drawn from a specific topic independently. The probability that a biterm drawn from a specific topic is further captured by the chances that both words in the biterm are drawn from the topic. The generative procedure is presented as follows, where \(\alpha \) and \(\beta \) are Dirichlet priors.
-
Step 1: For each topic z, draw a topic-specific word distribution \(\phi _{z}\) \(\sim \) Dir(\(\beta \));
-
Step 2: Draw a topic distribution \(\theta \) \(\sim \) Dir(\(\alpha \)) for the whole corpus of short documents;
-
Step 3: For each biterm b in the set of biterms B, draw a topic assignment z \(\sim \) Multi(\(\theta \)), and draw two words: \(w_i\), \(w_j\) \(\sim \) Multi(\(\phi _z\)).
The joint probability of a biterm b = (\(w_i\), \(w_j\)) according to the above procedure can be calculated as follows:
Therefore, the likelihood for the corpus of short documents is calculated:
Inferring Topics of Activities and Sub-workflows. Since BTM does not model the document generation process, topic proportions for activities and sub-workflows cannot be discovered directly during the topic learning process. To infer topics for each short document d, the expectation of topic proportions of biterms generated from d is calculated as follows:
Based on the parameters estimated by BTM, P(z|b) is obtained using Bayes’ formula while P(b|d) is nearly a uniform distribution over all biterms in d.
3.2 Determination of an Optional Topic Number K
The topic identification and topic similarity are closely related. The lower the topic similarity and the higher the topic identification, K should be determined.
Perplexity. The perplexity is often used to evaluate the quality of the probabilistic language model. Generally, the perplexity decreases along with the increase of the number of topics. A small value of perplexity is supposed to generate a better predictive effect on testing text corpus. In a topic model, the perplexity is calculated as follows:
where M represents the number of short documents, and \(N_d\) is the number of words contained in a certain document d. The parameter \(w_d\) denotes the word in d, while \(p(w_d)\) is the probability produced by \(w_d\) leveraging the document-topic and topic-word distributions. When Per approaches to 0, a better generalization ability is assumed to be achieved.
Topic Similarity. Topic similarity is calculated through adopting Jenson-Shannon (JS) divergence. We introduce the variance of random variables into the potential topic space, which can measure the overall difference of a topic space.
where \(\bar{\xi }\) is the mean probability distribution of different words obtained by the topic-word probability distribution T. K represents the number of topics, and \(D_{JS}\) denotes the JS divergence. When Var is large, the difference between topics is greater, and thus, the distinction between topics is higher and the topic structure is more stable.
Topic Number K Determination. Based on the perplexity and topic similarity afore-calculated, the factor \(Per\_Var\) is calculated as follows:
When \(Per\_Var\) is small in value, the corresponding topic model is optimal. The range for an optimal K can be determined by testing candidate K. As an example, values for Per, Var, and \(Per\_Var\) are presented at Table 1. An optimal K as 370 is determined when \(Per\_Var\) is the smallest in value as 35.801, while Per is the smallest as 11.288 and Var is the largest as 0.315.
3.3 Representative Topics Discovery
In most scenarios, a small number of topics can have a large probability score for each activity or sub-workflow, and these topics are assumed as representative to represent latent semantic information of activities or sub-workflows. The procedure of determining representative topics is presented as follows. For a certain topic, the average of probability is calculated w.r.t. all activities and sub-workflows. A threshold \(thd_{tp}\), which is usually set to several times of this probability average, is determined to specify the significance of this topic. When the value is larger than \(thd_{tp}\), this topic is assumed as significant. Consequently, the probability of this topic is reserved, and this topic is assumed as representative for a certain activity or sub-workflow. Since the probability for non-representative topics is set to zero, a probability normalization procedure is conducted for the topics of activities and sub-workflows.
4 Crossing-Workflow Fragments Discovery
This section presents our crossing-workflow fragments discovery mechanism leveraging the relevance of representative topics for activities and sub-workflows and the query processing upon AKG constructed in Sect. 2.
4.1 Candidate Activity and Sub-workflow Discovery
A requirement is shown at Fig. 3(a), and this requirement is assumed to be satisfied by the composition of activities \(act_{4}\), \(act_{5}\), \(act_{6}\) and \(act_{7}\), and sub-workflows \(swf_{sub3}\) from \(swf_1\), and activities \(act_{5}\), \(act_{6}\), \(act_{7}\) and \(act_{8}\), and sub-workflows \(swf_{sub9}\) from \(swf_2\). A scientific workflow fragment specified in the requirement may be similar to an existing one in the repository. Therefore, activities or sub-workflows are discovered and optimally composed accordingly.

A certain requirement and a testing requirement that have changed.
It is worth emphasizing that topics can be regarded as a high-level categorization somehow. When two activities (or sub-workflows) are highly relevant in their topics, this fact can hardly specify that they are equivalent or highly similar. Taking this into concern, the semantic similarity between short documents is adopted to improve the accuracy of the discovery for activities or sub-workflows. Consequently, the relevance of a candidate activity or sub-workflow \(act_{cnd}\) and an activity stub in the requirement \(act_{rq}\) is calculated as follows:
where \(sim_{T}\) represents the similarity for representative topics, which is calculated through adopting European Distance. \(sim_{T}\) returns a value between 0 and 1, where 1 means the equivalent. \(sim_{S}\) represents the semantic similarity between short documents, which is calculated through adopting the minimum cost and maximum flow algorithm, while WordNet is used to calculate the semantic similarity for words. The calculation method of \(sim_{S}\) refers to the part of semantic similarity for activity name in our previous work [6]. \(sim_{S}\) returns a value between 0 and 1, where 0 means totally different while 1 means the equivalent. The factor \(\alpha \) \(\in \) [0, 1] reflects the relative importance of \(sim_{T}\) w.r.t. \(sim_{S}\). For instance, \(\alpha \) is set to 0.7 in this paper to obtain the optimal efficiency, which is determined through experiments where \(\alpha \) is set from 0.1 to 0.9 with an increment of 0.1. When candidate activities and sub-workflows are determined according to their relevance, top K1 candidates should be recommended for a certain activity stub. It is proved that K1 is set to 7 as an optimal value according to our experiments.
4.2 Crossing-Workflow Fragments Discovery
This section aims to discover crossing-workflow fragments, where relations prescribed by AKG are obtained to connect activities or sub-workflows for respective activity stubs in the requirement specification. This procedure is presented by Algorithm 1, where the requirement RQ = {\(ACT_{rq}\), \(LNK_{rq}\)} presents a certain requirement, where rq refers the parts of the requirement to be involved. \(ACT_{rq}\) represents the set of activity stubs, and \(LNK_{rq}\) represents links connecting activity stubs in RQ. \(|ACT_{rq}|\) and \(|LNK_{rq}|\) refer to the number of activity stubs or links in \(ACT_{rq}\) or \(LNK_{rq}\). Without loss of generality, RQ is assumed to have a single initial activity stub \(act_{int}\). To facilitate the fragment discovery, activity stubs are numbered in an incremental manner by adopting the breadth-first search on RQ starting at \(act_{int}\). Given an activity stub \(act_{rq}^{i}\) \(\in \) \(ACT_{rq}\), \(ACT_{cnd}^{i}\) \(\in \) \(ACT_{cnd}\) represents the set of candidate activities and sub-workflows generated in Sect. 4.1. Algorithm 1 is presented as follows:

Step 1: Instantiated relations are examined whether they exist in AKG. (lines 1–10). For a link given in the requirement, the sets of candidate activities and sub-workflows are obtained w.r.t. its source and sink activity stubs (line 2). For an activity stub \(act_{rq}^{i}\) in \(ACT_{rq}\), \(ACT_{cnd}^{i}\) \(\in \) \(ACT_{cnd}\) represents the set of candidate activities and sub-workflows generated in Sect. 4.1. Candidate activities or sub-workflows in \(ACT_{cnd}^{src}\) compose as a series of relations rl with those in \(ACT_{cnd}^{snk}\). rl is represented as (\(act_{cnd}^{src}\), r, \(act_{cnd}^{snk}\)), where r refers to an invocation relation upon activities or sub-workflows evidenced in legacy scientific workflows. Note that rl is verified through a query function QryAKG upon AKG (line 4), and this query statement is presented as follows:
-
MATCH (\(e_{1}\): \(E\{act_{cnd}^{src}\}\)) - [\(r_{1}\): \(R\{r\}\)] -> (\(e_{2}\): \(E\{act_{cnd}^{snk}\}\))
RETURN \(e_{1}\) as Source, \(r_{1}\) as Rel, \(e_{2}\) as Sink
where the MATCH clause specifies the relation as constraints. Entities are written inside “( )” brackets (e.g., (\(e_{1}\): \(E\{act_{cnd}^{src}\}\)) and edges inside “[ ]” brackets (e.g., [\(r_{1}\): \(R\{r\}\)]). Filters for labels is written following the node separated with the symbol “:”, such that (\(e_{1}\): E) represents a node \(e_{1}\) that must match to certain entity label in E. Certain values for properties can be specified within “\(\{\) \(\}\)” (e.g., \(\{act_{cnd}^{src}\}\)). The RETURN clause aims to project the output variables. If rl exits in AKG, the triple (Source, Rel, Sink) is set to (\(act_{cnd}^{src}\), r, \(act_{cnd}^{snk}\)), and to null otherwise. rl is inserted into the candidate relation set as the corresponding link (line 7). To reduce unnecessary combinations, unrelated activities or sub-workflows are removed. Source and sink activities of rl, i.e., \(act_{cnd}^{src}\) and \(act_{cnd}^{snk}\), are inserted into new candidate sets \(NACT_{cnd}^{src}\) and \(NACT_{cnd}^{snk}\) w.r.t. corresponding activity stubs in \(ACT_{rq}\) (line 8).
Step 2: Crossing-workflow fragments are generated (lines 11–37). Fragments are initially constructed through the inclusion of a certain activity or sub-workflow (lines 12–17). Given a fragment frg in FRG, we examine each candidate activity or sub-workflow \(act_{cnd}^{k}\) for the activity stub \(act_{rq}^{i}\), and its related relations, to evaluate whether frg can be extended to generate new fragments. A tag is adopted to specify whether \(act_{cnd}^{k}\) has extended certain relations to produce new fragments (line 20). The set of indexes for links in \(LNK_{rq}\) are obtained associated with \(act_{rq}^{i}\) being processed and those activity stubs that have already been processed, where each index will be handled (lines 20–22). Involved candidate relations are decomposed into source and sink activities, which allows the indexes of their source and sink activity stubs, i.e., \(idx_{1}\) and \(idx_{2}\), to be determined for promoting the selection of extended relations (line 23).
When source and sink activities of a candidate relation are equal to (i) the activity for the corresponding index \(idx_{1}\) of frg and the candidate activity being processed \(act_{cnd}^{k}\), respectively, or (ii) \(act_{cnd}^{k}\) and the activity at the corresponding index \(idx_{2}\) of frg (line 24), it indicates that a satisfied relation is found, and the tag can be updated as true (line 25). In this setting, the growth procedure for new fragments is executed on frg. In particular, \(act_{cnd}^{k}\) is inserted into the activity set of this new fragment while the satisfied relation is supplemented to the corresponding relation set (lines 25–26). Since \(act_{cnd}^{k}\) and the associated activity in frg are deterministic, there is at most one satisfied relation in the corresponding candidate relation set. Once this relation is discovered, the loop about its candidate relation set terminates (line 26). On the other hand, when no suitable relations are considered, i.e., the tag is false, we need to simply insert \(act_{cnd}^{k}\) into a new fragment without corresponding relations (lines 30–33), which contributes to the fragment discovery for the following phase \(act_{rq}^{i+1}\). When the extension generation task of frg is complete, frg is removed from FRG.
Step 3: Candidate fragments are discovered and recommended (lines 38–46). The activity set of afore-generated fragments may contain irrelevant activities. Therefore, the activity set needs to be updated according to activities related to the relation set (line 39). Meanwhile, the fragment similarity frg.sim is calculated as two parts, e.g., structural similarity \(sim_{st}\) and semantic similarity \(sim_{sm}\)(line 45), where \(\beta \) \(\in \) [0, 1] reflects the importance of \(sim_{st}\) w.r.t. \(sim_{sm}\). Note that \(sim_{st}\) refers to the structural similarity between frg and RQ, which is the relation ratio of the number of relations in frg.RL to the number of total relations in \(LNK_{rq}\) (line 44). Besides, \(sim_{sm}\) represents the average semantic similarity between frg and RQ, which is calculated leveraging similarities between each activity in frg and the corresponding activity stub, and the number of activities in frg.ACT. Their similarities are obtained through the similarity calculation function SimCal (line 42).
Generally, fragments with high structural similarity should be more appropriate to be recommended. In this setting, \(sim_{st}\) is assigned a high weight than \(sim_{sm}\) (i.e., \(\beta \) is set to 0.7). The similarity of each fragment returns a value between 0 and 1, where 1 means the equivalent. Consequently, top K2 (like 10) fragments \(\{frg\}\) are selected and recommended according to their ranked fragment similarities (line 47).
5 Experimental Setting
5.1 Data Cleaning and Experimental Setup
We have collected 1573 scientific workflows in the category of Taverna 2 of the myExperiment repository. Scientific workflows are cleansed as follows: (i) the titles or text descriptions of scientific workflows lacks specification. In this case, similarity computation for activities cannot be conducted, and the topic discovery is inaccurate, and (ii) activities corresponding to slim services are mostly the glue code, and they don’t capture invocation relations between functionalities.
The semantic similarity between words is computed by WordNet. However, improper words which are not recognized by WordNet are contained in names or text descriptions of activities and sub-workflows, and they are handled case-by-case as mentioned in our previous work [8]. Besides, stopwords such as can, of, and and, are removed. Words like accessed, accesses, and accessing have a common word root access. Affixes are removed to keep the root only. This is important for topic model algorithms. Otherwise, these words are treated as different word entities, and thus, their topic relevance is not well-recognized. Therefore, the lemmatization technology is applied.
In order to ensure the rationality and universality of our technique, we have carefully selected samples from fragments which cross multiple scientific workflows in the activity knowledge graph, and modified them as novel requirements according to certain principles. These samples should cover most scale levels of crossing-workflow fragments to satisfy various complexity requirements. By observing scientific workflows in AKG, fragments span 2 \(\sim \) 4 mostly, or even cross 5 or 6 scientific workflows. We select 20 samples among fragments crossing different scales of workflows, e.g., 1 \(\sim \) 6, and samples across 2 to 4 are chosen at a high ratio. Particularly, we can simulate that the requirement is completely satisfied by a scientific workflow when the scale of is 1 in terms of the number of crossing-workflow fragments. Experiments are conducted when these sample fragments are remained as they are, or to be changed according to certain principles.
5.2 No Changes Applied to Sample Fragments
Experiments are conducted when sample fragments are remained as they are retrieved from the dataset. An expected result should be an exact matched fragments compared with the requirement fragment. Experiments for 20 sample crossing-workflow fragments return the right recommendations, which contain original sample fragments, and they are ranked as the first in terms of similarities. For instance, given the sample fragment \(swf_{smpl4}\), which spans 3 scientific workflows (e.g., \(swf_{1687}\), \(swf_{1768}\) and \(swf_{1757}\)). The representation of \(swf_{smpl4}\) based on AKG is transferred as follows:
-
\(E = \{act_0, act_2, act_3, act_6, act_7\}\)
-
\(R = \{Invok\}\)
-
S = \(\{\)(\(act_2\), Invok, \(act_7\)), (\(act_7\), Invok, \(act_0\)), (\(act_0\), Invok, \(act_3\)), (\(act_6\), Invok, \(act_3\)), (\(act_6\), Invok, \(act_0\))\(\}\)
where 5 relation triples are contained, and the fifth candidate crossing-workflow fragment is shown according to ranked similarity values:
-
Candidate 5 =
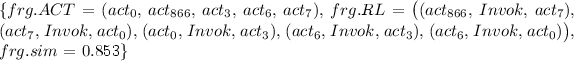
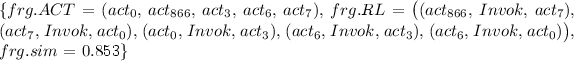
This sample shows that most of the same or similar relations can be discovered, and most suitable candidate fragments can be recommended.
5.3 Changes Applied to Sample Fragments
Novel requirements may not be exactly the same as crossing-workflow fragments in the repository. In this case, sample fragments are changed to generate novel requirements. Changing operations include insertion, deletion and replacement. Besides, some novel activities or sub-workflows are constructed in sample fragments, which reflects new features in novel requirements. Consequently, 10 fragments are generated to conduct novel experiments. An example is shown in Fig. 3(b), where activity \(act_{i1}\) named “extractDates” is inserted into \(act_{7}\) to build a new relation triple (\(act_{7}\), Invok, \(act_{i1}\)). A new relation triple (\(act_{4}\), Invok, \(act_{i2}\)) is generated, where an inserted activity \(act_{i2}\) named “concat_abstract_ids” is reconnected to \(act_{4}\). Sub-workflow \(swf_{sub3}\) and activity \(act_8\) are deleted, and activity \(act_6\) is replaced by a newly constructed activity \(act_{r6}\). Results for 4 testing fragments return the right recommendations that contain sample fragments.
Since 6 experiments (e.g., \(swf_{tst21}\), \(swf_{tst22}\), \(swf_{tst28}\) and so on), which cannot recommend exact fragments w.r.t. their requirements, are set to add newly constructed activities, e.g., \(act_{r6}\) in Fig. 3(b). Their results can only discover relatively similar crossing-workflow fragments existed in AKG. Note that \(swf_{tst}\) refers to the testing requirements that have been changed on the basis of original samples. An example is \(swf_{tst28}\), which spans 4 scientific workflows (e.g., \(swf_{1702}\), \(swf_{1687}\), \(swf_{1598}\), and \(swf_{1754}\)), whose representation based on AKG is shown as follows:
-
\(E = \{act_{new}\), \(act_7\), \(act_{69}\), \(act_{201}\), \(act_{732}\), \(act_{738}\), \(act_{740}\}\)
-
\(R = \{Invok\}\)
-
\(S = \{(act_{69}\), Invok, \(act_{new}\)), (\(act_{new}\), Invok, \(act_{7}\)), (\(act_{201}\), Invok, \(act_{7}\)), (\(act_{201}\), Invok, \(act_{732}\)), (\(act_{740}\), Invok, \(act_{732}\)), (\(act_{738}\), Invok, \(act_{740}\))\(\}\)
where \(act_{new}\) is a newly constructed activity and \(swf_{tst28}\) is changed through the operation of insertion, deletion and replacement. The fifth recommended crossing-workflow fragment is presented according to ranked similarity values:
-
Candidate 5 =


Generally, when changes are applied upon sample fragments, our technique can discover appropriate crossing-workflow fragments in most scenarios.
6 Experimental Evaluation
6.1 Performance Metrics
Precision and recall are adopted for the evaluation purpose. Given a testing fragment \(swf_{tst}\), a reusable fragment \(swf_{ept}\) contained in the repository is assumed to be included in the expected list of recommendation (denoted \(SWF_{ept}\)) when the similarity between \(swf_{tst}\) and \(swf_{ept}\) is no less than a pre-specified threshold \(thrd_{ept}\). In our experiments, each activity stubs in \(swf_{tst}\) is replaced by all activities and sub-workflows in dataset, to obtain a series of expected crossing-workflow fragments, where links on activities and sub-workflows are checked whether they are retained leveraging the relations specified upon scientific workflows in the repository. Importantly, similarities of fragments are calculated through line 45 in Algorithm 1 through balancing their structural and semantic similarity w.r.t. \(swf_{tst}\). We use the notation \(SWF_{rec}\) to denote the set of workflow fragments, which are actually recommended. Precision and recall are computed:
where “\(| SWF_{rec} |\)” refers to the number of fragments in the set \(SWF_{rec}\) while “\(| SWF_{ept}|\)” specifies the number of elements in the set \(SWF_{ept}\). “\(|SWF_{ept} \cap SWF_{rec}|\)” returns the number of fragments in \(SWF_{ept}\) in \(SWF_{rec}\).
6.2 Baseline Methods
The following methods are chosen as the baseline:
-
Sub-graphRec: The sub-graph matching algorithm [5, 6] is adopted to discover and recommend fragments w.r.t. certain requirements. The sub-graph matching algorithm is applied to discover candidate fragments in a constructed activity network model, where edges reflect invocation relations between activities. Top K2 fragments are selected according to fragment similarities.
-
ClusteringRec: Clustering has demonstrated its performance in [2, 6]. We adopt a modularity-based clustering algorithm to generate activity clusters. When a certain requirement is to be satisfied, the target cluster is determined with respect to each activity stub, and candidate activities or sub-workflows are discovered to construct a series of crossing-workflow fragments. Top K2 fragments are selected according to fragment similarities.
Below, we present experimental results of our technique (denoted AKGRec), Sub-graphRec, and ClusteringRec w.r.t. the following three parameters: (i) \(thrd_{ept}\): the pre-specified threshold of the similarity when generating \(SWF_{ept}\), (ii) K2: the number of recommended fragments, and (iii) \(\beta \): the relative importance of the structural similarity w.r.t. the semantic similarity for the calculation of fragment similarity.

Precision and recall for AKGRec, Sub-graphRec and ClusteringRec when K2 is set to 10, \(\beta \) is set to 0.7, and \(thrd_{ept}\) is set from 0.72 to 0.98 with an increment of 0.02.
Impact of \(\varvec{thrd}_{\varvec{ept}}\mathbf{.}\) To explore the impact of \(thrd_{ept}\) to precision and recall, we set K2 as 10, \(\beta \) as 0.7, and \(thrd_{ept}\) as a value from 0.72 to 0.98 with an increment of 0.02. Figure 4 shows that precision drops and recall increases along with the increasing of \(thrd_{ept}\), and AKGRec performs better than Sub-graphRec and ClusteringRec in precision and recall. Specifically, the majority of recommended fragments of Sub-graphRec are not expected somehow. In fact, Sub-graphRec guarantees the structural similarity of recommended fragments w.r.t. the requirement, but the semantically matching of activities is not the focus. Therefore, the precision and recall are relatively lower for Sub-graphRec than AKGRec and ClusteringRec. The precision of ClusteringRec is quite high, since recommended fragments are mostly included in \(SWF_{ept}\). However, the recall of ClusteringRec is relatively low. After carefully analyzing the experiments, it is observed that activities are unevenly assigned to various clusters, and some clusters may contain quite a few candidate activities or sub-workflows. Consequently, there may have no enough fragments generated by ClusteringRec to be recommended.
Figure 4 shows that precision decreases, and recall increases, along with the increasing of \(thrd_{ept}\) for AKGRec, Sub-graphRec, and ClusteringRec. In fact, \(SWF_{rec}\) does not change when K2 is set to a certain value. Fragments in \(SWF_{ept}\) may be less in number when \(thrd_{ept}\) is set to a relatively large value. Consequently, more fragments in \(SWF_{rec}\) may be missed in \(SWF_{ept}\), which makes the decreasing of the precision according to Formula 8. Figure 4 shows that precision for AKGRec and ClusteringRec is relatively stable when \(thrd_{ept}\) changes from 0.72 to 0.84, since the similarity for the majority of expected fragments is within these two ranges. The number of fragments in \(SWF_{ept}\) decreases to an extent when \(thrd_{ept}\) is set from 0.86 to 0.98, since expected workflows whose similarity is within this range is quite few. Leveraging the difference of \(|SWF_{ept} \cap SWF_{rec}|\) and the reduction of \(|SWF_{ept}|\), recall increases for AKGRec, Sub-graphRec and ClusteringRec according to Formula 9.

Precision and recall for AKGRec, Sub-graphRec and ClusteringRec when \(thrd_{ept}\) is set to 0.86, \(\beta \) is set to 0.7 and K2 is set from 2 to 30 with an increment of 2.
Impact of K2. To explore the impact of K2 to precision and recall, we set \(thrd_{ept}\) as 0.86, \(\beta \) as 0.7 and K2 as a value from 2 to 30 with an increment of 2. As shown in Fig. 5, the precision and recall are larger for AKGRec than Sub-graphRec and ClusteringRec, due to the similar reason as presented in Fig. 4. In particular, when K2 is set to relatively large values, Fig. 5 shows that precision of all three technique begins to decrease, since more recommended fragments should be discovered, which are actually not that relevant and may not exist in \(SWF_{ept}\). Note that the precision for Sub-graphRec does not perform well, since a large number of fragments are obtained by the sub-graph matching method. When K2 changes from 2 to 16, recall of all three technique increases to a large extent, since more expected fragments are recommended. Meanwhile, recall becomes relatively stable when K2 changes from 16 to 30, since most of expected workflows have been discovered and included in \(SWF_{ept}\).

Precision and recall for AKGRec, Sub-graphRec and ClusteringRec when \(thrd_{ept}\) is set to 0.86, K2 is set to 10, and \(\beta \) is set from 0.1 to 0.9 with an increment of 0.1.
Impact of \({\varvec{\beta }}\mathbf{.}\) As discussed in Sect. 4.2, similarities of recommended fragments to a certain requirement are impacted by \(\beta \). To explore this impact to precision and recall, we set \(thrd_{ept}\) as 0.86, K2 as 10, and \(\beta \) as a value from 0.1 to 0.9 with an increment of 0.1. Due to the similar reason as presented in Figs. 4 and 5, AKGRec performs better in precision and recall than Sub-graphRec and ClusteringRec. Generally, precision and recall increase along with the increasing of \(\beta \), which evidence the strong significance of structural relevance to recommended fragments. Concretely, \(SWF_{rec}\) does not change when K1 is a fix value, and precision increases when \(\beta \) changes from 0.1 to 0.6, since more recommended fragments are contained in \(SWF_{ept}\). As to Sub-graphRec, the semantically matching is not considered in sub-graph matching algorithm. Therefore, most discovered fragments are not contained in \(SWF_{ept}\) and precision is relatively low. The importance of semantics is gradually decreased from the fragment similarity when \(\beta \) is set from 0.6 to 0.9, and results show that precision begins to decrease, since more recommended fragments are not contained in \(SWF_{ept}\), in case the fragment similarity relies on structure while little regard to semantics. A high recall is got when \(\beta \) is set to 0.6. However, the recall of ClusteringRec is lowest. In fact, the number of recommended fragments is not enough compared with recommended fragments as explained for K2, which is affected by clustering effect and selection strategy of candidate activities or sub-workflows.
Results in Figs. 4 and 5 show that precision decreases, while recall increases, when \(thrd_{ept}\) and K2 increase. Therefore, we suggest that \(thrd_{ept}\) and K2 should not be set to relatively large values. Results in Fig. 6 show that the structure relevance should be considered as more important when discovering crossing-workflow fragments to achieve a promising result.
7 Related Work
Discovering crossing-workflow fragments is a promising research topic for supporting the reuse and repurposing of legacy scientific workflows when novel requirements are to be satisfied. The technique can discover fragments whose activities can be contained in various workflows [6]. However, besides invocation relations, hierarchical relations like parent-child ones may exist in workflows, their sub-workflows and activities, and they have not been considered when constructing an activity network. Hence, fragments containing activities in various granularities cannot be discovered. To capture more kinds of relations, besides flat invocation relations, in workflows, knowledge graph is adopted to encode service knowledge and relations manageable by computer systems [4]. Following this trend, this paper constructs AKG to capture various kinds of relations in a semantic fashion. Fragments discovery is reduced into a graph query upon AKG, which can be achieved through the path query [3], and a path reflects a sequence of relations. Topic models like LDA and BTM have been applied to promote the discovery of appropriate Web services w.r.t. user queries. In [1], web service structure is transferred into a weighted directed acyclic graph (WDAG), and BTM is adopted to generate topics upon WDAG. The similarity for the pairs of WDAGs takes the topic similarity into concern, where JS divergence is used to calculate the similarity of topics. Inspired by these methods, this paper constructs an AKG to represent partial-ordering relations between activities, and parent-child relations specified upon sub-workflows and corresponding activities, and adopts BTM to generate representative topis.
8 Conclusion
This paper proposes a novel crossing-workflow fragment discovery mechanism. Specifically, an AKG is constructed to represent partial-ordering relations between activities, and parent-child relations specified upon sub-workflows and corresponding activities. The semantic relevance of activities and sub-workflows is quantified by representative topics obtained by BTM. Given a requirement specified in terms of a workflow template, individual candidate activities or sub-workflows are discovered, and they are composed into fragments according to relations specified by AKG. Candidate fragments are evaluated through balancing their structural and semantic similarities. Evaluation results show that this technique is accurate and efficient on discovering appropriate crossing-workflow fragments in comparison with the state of arts.
References
Baskara, A.R., Sarno, R.: Web service discovery using combined bi-term topic model and WDAG similarity. In: International Conference on Information and Communication Technology and System, pp. 235–240 (2017)
Conforti, R., Dumas, M., García-Bañuelos, L., La Rosa, M.: BPMN miner: automated discovery of BPMN process models with hierarchical structure. Inf. Syst. 56, 284–303 (2016)
Hong, S., Park, N., Chakraborty, T., Kang, H., Kwon, S.: Page: answering graph pattern queries via knowledge graph embedding. In: International Conference on Big Data, pp. 87–99 (2018)
Paulheim, H.: Knowledge graph refinement: a survey of approaches and evaluation methods. Semantic Web 8(3), 489–508 (2017)
Theodorou, V., Abelló, A., Thiele, M., Lehner, W.: Frequent patterns in ETL workflows: an empirical approach. Data Knowl. Eng. 112, 1–16 (2017)
Wen, J., Zhou, Z., Shi, Z., Wang, J., Duan, Y., Zhang, Y.: Crossing scientific workflow fragments discovery through activity abstraction in smart campus. IEEE Access 6, 40530–40546 (2018)
Yan, X., Guo, J., Lan, Y., Cheng, X.: A biterm topic model for short texts. In: Proceedings of the 22nd International Conference on World Wide Web, pp. 1445–1456. ACM (2013)
Zhou, Z., Cheng, Z., Zhang, L.J., Gaaloul, W., Ning, K.: Scientific workflow clustering and recommendation leveraging layer hierarchical analysis. IEEE Trans. Serv. Comput. 11(1), 169–183 (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Wen, J., Zhou, Z., Wang, Y., Gaaloul, W., Duan, Y. (2019). Discovering Crossing-Workflow Fragments Based on Activity Knowledge Graph. In: Panetto, H., Debruyne, C., Hepp, M., Lewis, D., Ardagna, C., Meersman, R. (eds) On the Move to Meaningful Internet Systems: OTM 2019 Conferences. OTM 2019. Lecture Notes in Computer Science(), vol 11877. Springer, Cham. https://doi.org/10.1007/978-3-030-33246-4_32
Download citation
DOI: https://doi.org/10.1007/978-3-030-33246-4_32
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-33245-7
Online ISBN: 978-3-030-33246-4
eBook Packages: Computer ScienceComputer Science (R0)