
Abstract
To solve the problem of rapid retrieval of Chinese-Hmong mixed text, a multi-pattern matching algorithm in double-bytes unit combined with the idea of AC algorithm and the mismatch processing strategy of Horspool algorithm is proposed for the Chinese-Hmong mixed strings. In this algorithm, a deterministic finite automaton is constructed based on the pattern-set according to the idea of AC algorithm, and the moving distance of the pattern is calculated by the bad-character rule of the Horspool algorithm, and the text is only traversed once to complete the quick search task of all patterns by using the finite automata. The experimental results show that the proposed algorithm has a good performance in multi-pattern matching for Chinese-Hmong mixed texts in different scale, even for the mixed texts containing more than 100,000 characters, the matching efficiency is also significantly higher than the AC algorithm.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Square Hmong characters were created in the late Qing Dynasty of China and have been mainly used in the Hmong settlements such as Wuling Mountain District. Hmong informatization is one of great significances to promote the development of the local national cultural tourism industry and the digital protection of the intangible heritage of the Hmong culture. Information retrieval is a bottleneck to hinder the further research of the Hmong informatization. A high-performance pattern matching algorithm for strings is crucial to realize the fast retrieval of the square Hmong information.
According to the word formation, a square Hmong character represents a morpheme or word [1]. The square Hmong words in practical applications mainly containing single character or two characters, and few words containing 3 characters or more. Moreover, the square Hmong characters are usually mixed with Chinese characters, appear in the Chinese-Hmong songbook and script. The information retrieval mainly searches for a meaningful square Hmong string or Chinese-Hmong string from the mixed text. Obviously, compared to English, the mixed character set of the square Hmong characters and Chinese characters is a large character set, and the probability that the Chinese-Hmong string is repeated in the text is very low, so mismatches are common. In previous research, Zeng et al. proposed a Horspool extension algorithm for matching the square Hmong string [2]. This algorithm directly extend a byte unit to a word unit, and treats the double-bytes of square Hmong character as a whole. Only when the double bytes are completely equal, it is regarded as a square Hmong character matched. The experimental results show that the mentioned algorithm can solve the string search problem of square Hmong text. However, the algorithm is a single-pattern matching algorithm, which cannot search for multiple Chinese-Hmong mixed strings in text at one time. This paper presents an AC-EH algorithm, which combines the above Horspool extension algorithm with the AC algorithm, and can used to solve the multi-pattern matching problem of Chinese-Hmong mixed strings.
The rest of this paper is organized as follows. Section 2 introduces the basic principles of AC algorithm and Horspool algorithm. Section 3 depicts the proposed AC-EH algorithm. Section 4 verifies the feasibility of proposed algorithm by using the case study and experiment analysis. Section 5 concludes the paper.
2 Principles of AC Algorithm and Horspool Algorithm
2.1 AC Algorithm
Aho-Corasick automata algorithm (AC algorithm) is one of the most famous multi-pattern matching algorithms, and it utilizes the common prefix relationship among patterns to achieve efficient jumps in pattern mismatch. To some extent, AC algorithm can be regarded as an extension of the KMP algorithm in a multi-pattern context, but it has far better performance than the KMP algorithm [3, 4]. Similar to the contribution of the KMP algorithm to the field of single pattern matching, AC algorithm has had a profound impact on the development of multi-pattern matching algorithms, it and its improved algorithms are still widely applied in various fields of pattern matching.
AC algorithm is based on the Deterministic Finite Automata (DFA) constructed according to the pattern-set, and converts the comparison of characters into the transition of the states of the DFA. The AC automata is represented as a six-tuple M = (K, A, g, f, S, Z), where the following hold.
-
(1)
K is a finite set, and each element of it is called a state.
-
(2)
A is a finite alphabet set, and each element of it is called an input symbol.
-
(3)
g is a state transition function, which is a map on K × A→K, corresponding to the function goto.
-
(4)
f is a failure function, which is also a map on K × A→K, indicating a state transition when a pattern mismatch occurs, corresponding to the function failure.
-
(5)
\( S \in K \), is the only initial state.
-
(6)
\( Z\, \subset \,K \), is the final state set. The final state marked as double circles is also called an acceptable state or an ending state, corresponding to the function output.
The AC algorithm first preprocesses the pattern-set, establishes a function table corresponding to the functions goto, failure and output, and constructs a DFA used for pattern matching with a mismatch pointer accordingly. Then, with the DFA, the three functions described above are used to scan the text to be matched to find all occurrence positions of each pattern in the text. If the current state fails to match, it goes to the state indicated by the mismatch pointer of the current state, and the matching is continued.
AC algorithm eliminates the influence of the pattern-set size on the matching speed by preprocessing. For the text T to be matched with length n and the pattern-set P = \( \left\{ {p_{ 1} ,p_{ 2} ,p_{ 3} , \ldots ,p_{q} } \right\} \) with q patterns, AC algorithm only needs to scan T once to complete the searching for each pattern in P without backtracking, and can find all the patterns that have been successfully matched. Obviously, the time complexity of the AC algorithm is only related to the length n of T, is O(n).
2.2 Horspool Algorithm
The Horspool algorithm is derived from the BM algorithm. The BM algorithm with a time complexity of O(n) is one of the most famous single pattern matching algorithms, which calculates the maximum value of pattern shift distance using bad-character rule and good-suffix rule at the same time [5]. Due to skipping a lot of characters that don’t need to match, the performance of the BM algorithm is 3–5 times better than that of the KMP algorithm in practical applications [6, 7]. There are many improved versions of the BM algorithm [8,9,10,11,12], and the Horspool algorithm is one of them, which fixes the last character of the current matching-window as a bad-character, and only uses the bad-character rule to calculate the moving distance of the pattern [12]. Because the calculation of the distance based on good-suffix rule and the selection of the maximum value in BM algorithm are all avoided, its efficiency is significantly higher than that of the BM algorithm in practical applications.
For simplicity, the substring currently matched in T to be matched is denoted as \( T\left[ i \right] \ldots T\left[ {i\, + \,m - 1} \right] \). Where, i is the starting position of the substring, and \( 0\, \le \,i \le n - m. \) \( T\left[ i \right] \ldots T\left[ {i\, + \,m - 1} \right] \) is also called a matching-window. Suppose \( T\left[ {i\, + \,j} \right] \) and P[j] represent the currently processed character in T and P, respectively. Where, j is the matching position of the substring, and \( 0\, \le \,j \le m - 1 \). The algorithm takes the last character \( T\left[ {i\, + \,m - 1} \right] \) in window as a bad-character, and compares it with the last character P[m − 1] of the pattern. If the matching successes, the algorithm continues to compare the remaining characters in T and P one by one from right to left until they are completely equal or there is a mismatch at a certain character position. If the matching fails, \( T\left[ {i\, + \,m - 1} \right] \) acts as a bad-character, and the algorithm tries to find the last position \( k( - 1\, \le \,k \le m - 2) \) where the bad-character \( T\left[ {i\, + \,m - 1} \right] \) appears in P, and then moves P to the position where \( T\left[ {i\, + \,m - 1} \right] \) and P[k] are aligned, and the next match will be continued.
To get the moving distance the pattern, for each character in T, the rightmost k of the positions it appears in P, and the distance of position k from P[m − 1] must be stored in advance. This distance is denoted as shift[P[k]], which indicates the moving distance of P when \( T\left[ {i\, + \,m - 1} \right] \) is a bad-character, and is calculated by the following Eq. (1).
In Eq. (1), k = −1 means that the current character does not appear in P, and the moving distance P is m.
Horspool algorithm performs character comparison from right to left, shifts the pattern from left to right, and fixes the last character of the current matching-window as a bad-character, and only needs to scan the text T to be matched once to find all the substrings that match the pattern, so the time complexity is O(n). Obviously, the more common the character mismatch, the better the performance of the Horspool algorithm.
3 Proposed AC-EH Algorithm
3.1 Basic Principle of AC-EH Algorithm
The proposed AC-EH algorithm takes double-bytes as a matching-unit to execute matching for Chinese-Hmong mixed strings by combining the basic idea of AC algorithm with the mismatch processing strategy of Horspool algorithm. Similar to the AC algorithm, the AC-EH algorithm preprocesses the pattern-set before performing matching, that is, constructs three lookup tables corresponding to functions goto, output, and shift based on the pattern-set. The values of the three tables will be filled in during the calculation of the three functions. And then, the algorithm includes three stages. Firstly, the DFA is constructed and the corresponding functions goto and output are calculated according to the basic AC algorithm. Secondly, the function shift of the pattern is generated by using the bad-character heuristic rule of Horspool algorithm. Finally, the pattern matching is operated on the DFA. In the matching process, the functions goto, output and shift are used to scan the text to be matched and search for the patterns by moving DFA. When a mismatch occurs, the last character in the matching-window is fixed as a bad-character according to the mismatch processing strategy of the Horspool algorithm and the bad-character-based heuristic rule, and the pattern is moved based on the shift value of the current bad-character, and the matching is continued.
3.2 Construction of DFA and Calculation of Function goto
Construction of DFA and calculation of function goto are crossed. AC-EH algorithm creates an initial state 0 of the DFA, and starts from the initial state 0, for each pattern \( p_{i} \left[ { 1\ldots Len} \right] \) of the pattern-set P \( ( 1\, \le \,i \le q) \), generates the value of the function goto and other states of DFA. Suppose that the length of the text T to be matched is n, the pattern-set with q patterns is \( P\, = \,\left\{ {p_{ 1} ,p_{ 2} ,p_{ 3} , \ldots ,p_{\text{q}} } \right\} \), and the maximum and minimum lengths of each pattern in P are MaxLen and MinLen, respectively. Let’s denote the current state as Dk, the steps for generating DFA and function goto are as follows.
-
Step1: Take the initial state 0 as Dk.
-
Step2: When Dk faces the input character pi[j] (1 ≤ j ≤ Len), it is checked whether there is such a state Dt in the direct successors of Dk (i.e. goto(Dk, pi[j]) = Dt). If it does, goto Step3, otherwise, goto Step4.
-
Step3: Dk = Dt, take the next character pi[j + 1] as the current input character, and goto Step2.
-
Step4: Construct goto(Dk, pi[j]) = Dt and check if the current input character is the last character pi[Len] of the pattern pi. If yes, goto Step5; otherwise, goto Step3.
-
Step5: Dt is denoted as the final state.
3.3 Calculation of Function Output and Function Shift
Assume that the current state Dk is a final state, and there is a path from the initial state 0 to the state Dk. If all characters on the path are sequentially connected to obtain the string t1, then output(Dk) = t1.
In the process of pattern matching with DFA, if the input character a is faced in the current state Dk, and a state Dt that makes goto(Dk, a) = Dt is not found, the shift value is calculated by the following Eq. (2).
3.4 Description of AC-EH Algorithm
The AC-EH algorithm steps of multi-pattern matching using DFA for Chinese-Hmong mixed strings are as follows:
Step1: Preprocess pattern-set, generate functions goto and output, and construct DFA.
Step2: Traverse DFA, calculate the shift value of each character in T according to Eq. (2), and record it in the shift table.
Step3: Align the last character of the pattern pMinLen with a length of MinLen in DFA with the last character of T, take the character a in the position where T is aligned with the first character of pMinLen as the current character, and let the matching pointer point to a.
Step4: Take the initial state 0 as the current state Dk, record the position Pos of the character a in T, and move the matching pointer from a, then match characters one by one from left to right.
Step5: If match fails, move both pointer and DFA to the left based on the shift value at the position of character a, and then goto Step4. Otherwise, Dk = goto(Dk, a), that is, take the next state goto(Dk, a) as the current state.
Step6: Check if state Dk is a final state. If yes, call the function output, store the value of output(Dk) and Pos value in the output table, then move the pointer and DFA to the left to MinLen characters, and then goto Step4. Otherwise, take the next character in T as the current character a, start the next comparison.
Step7: End the matching process. At this time, if the output table is empty, it means that T does not contain any pattern in P. Otherwise, the contents of the output table are just those patterns in P that appear in T.
4 Case Study and Related Experiment Analysis
4.1 Case Study
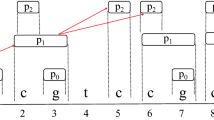
Given the Chinese-Hmong mixed text T to be matched and the pattern-set P = {p1, p2, p3, p4, p5} as shown in Fig. 1. The MinLen value of the pattern in P is 5. The shift value of each character in T is calculated according to Eq. (2) as shown in Fig. 2.

The content of the text T and the pattern-set P

The shift value of each character in T
The following Figs. 3, 4, 5, 6 and 7 show the execution of the AC-EH algorithm.

The 1st diagram of algorithm execution case

The 2nd diagram of algorithm execution case

The 3rd diagram of algorithm execution case

The 4th diagram of algorithm execution case

The 5th diagram of algorithm execution case
In Fig. 3, since the MinLen value is 5, the last 5 characters of T are aligned with the characters of the shortest pattern in the DFA. Starting from the initial state 0 in DFA and the current character ‘东’ in T, the pointer is moved from left to right. The comparison in a character-by-character manner is done. When the final state 8 is reached, the pattern p2 matches successfully. At this time, the output value of the final state 8 is p2, and the position where p2 appears in T is 19. Then, values p2 and 19 are stored in the output table. And then, according to MinLen value, the pointer and the DFA are both moved 5 character-positions to the left as shown in Fig. 4.
In Fig. 4, matching is performed from the initial state 0. At this time, the current character ‘方’ in T does not match the character ‘东’ in the aligned position of DFA. Since the shift value of the character ‘方’ is 1, the pointer and the DFA are both moved 1 character-position to the left as shown in Fig. 5.
In Fig. 5, matching is performed from the initial state 0. At this time, the current character ‘东’ in T matches the character ‘东’ of the aligned position in the DFA. Starting from the character ‘东”, the pointer is moved from left to right, and the comparison in a character-by-character manner is done again. When the final state 16 is reached, the pattern p5 matches successfully. At this time, the output value of the final state 16 is p5, and the position where p5 appears in T is 13. Then values p5 and 13 are stored in the output table. According to MinLen value, the pointer and the DFA are both moved 5 character-positions to the left as shown in Fig. 6.
In Fig. 6, similar to the method described above, the pointer and the DFA are both moved to the left by 2, 3, and 2 character-positions in sequence until the current character ‘东’ in T matches the character ‘东’ of the aligned position in the DFA (as shown in Fig. 7). Starting from the character ‘东’, the matching pointer is moved from left to right, the comparison in a character-by-character manner is done again. When the final state 5 is reached, the pattern p1 matches successfully. At this time, the output value of the final state 5 is p1, and the position where p1 appears in T is 1. Then, values p1 and 1 are also stored in the output table. Finally, the matching is completed and the result is obtained by output table, that is, {(p2,19), (p5, 13), (p1,1)}.
4.2 Experiment Analysis
AC-EH algorithm was implemented in Java, all multi-pattern matching experiments were carried out under the conditions of Intel(R) Core(TM) i5-3470 CPU @ 3.20 GHz, 4G memory and Win7 operating system. For the pattern-set composed of 5 patterns of length 1–10 and 3 mixed texts T1, T2 and T3 to be matched with lengths of 5185, 37770 and 147645 words, both AC-EH algorithm and AC algorithm had an accuracy of 100%. Time-consuming data of two algorithms in experiments are shown in Table 1. The TNo, TLen, PLen1-PLen5, AC-EH_Time(ms), and AC_Time(ms) in the table respectively represent the number and length of the text to be matched, length of the five patterns, and time-consuming data of the AC-EH algorithm and the AC algorithm.
According to Table 1, the time-consuming line chart of the two algorithms for matching different length patterns is shown in Fig. 8.

Time-consuming of two algorithms for patterns with different length
From Table 1 and Fig. 8, it is easy to find that: (1) When the text such as T1 to be matched is very short, the time performance of the AC-EH algorithm is significantly better than that of the AC algorithm regardless of the pattern length. (2) When the text to be matched is longer but the pattern is relatively shorter (for case, T2 matches the pattern with length 1, T3 matches the pattern of length 1–5), the time performance of the AC-EH algorithm is slightly inferior to the AC algorithm. (3) When the length of the pattern is gradually increased (for case, T2 matches the pattern with the length 2 to 10, T3 matches the pattern with the length 6 to 10), the time performance of the AC algorithm remains basically stable, and that of the AC-EH algorithm is gradually improved, which is significantly better than that of the AC algorithm.
In summary, the matching speed of the AC-EH algorithm is significantly faster than that of the AC algorithm when the length of Chinese-Hmong mixed text and pattern is increased to a certain extent. Even for the Chinese-Hmong mixed text containing more than 100,000 words, the performance of the AC-EH algorithm can be better. Considering that the length of Chinese-Hmong mixed texts in the actual application are rarely more than 100,000 words, and the patterns that need to be searched (such as a lyrics) is usually longer, the AC-EH algorithm is suitable for solving the problem of multi-pattern matching for Chinese-Hmong mixed strings.
5 Conclusions and Future Work
This paper proposes a multi-pattern matching algorithm for Chinese-Hmong mixed strings by combining AC algorithm with Horspool extension algorithm. This algorithm is simple, easy to implement, has high matching efficiency, and suitable for realizing the rapid retrieval technology of Chinese-Hmong mixed text. In the future, we intend to study the parallel fuzzy search algorithm for Chinese-Hmong mixed strings with fuzzy Petri net.
References
Yang, Z.B., Luo, H.Y.: On the folk coinage of characters of the Miao people in Xiangxi area. J. Jishou Univ. (Soc. Sci. Edn.) 29(6), 130–134 (2008)
Zeng, L., Mo, L.P., Liu, B.Y., et al.: Extended Horspool algorithm and its application in square Hmong string pattern matching. J. Jishou Univ. (Nat. Sci. Edn.) 39(4), 150–156 (2018)
Aho, A.V., Corasick, M.J.: Efficient string matching: an aid to bibliographic search. Commun. ACM 18(6), 333–340 (1975)
Han, G.H., Zeng, C.: Theoretical research of KMP algorithm. Microelectron. Comput. 30(4), 30–33 (2013)
Boyer, R.S., Moore, J.S.: A fast string searching algorithm. Commun. ACM 20(10), 762–772 (1977)
Cole, R., Hariharan, R., Paterson, M., Zwick, U.: Tighter lower bounds on the exact complexity of string matching. SIAM J. Comput. 24(6), 30–45 (1995)
Cole, R., Hariharan, R.: Tighter upper bounds on the exact complexity of string matching. SIAM J. Comput. 26(3), 803–856 (1997)
Zhao, X., He, L.F., Wang, X., et al.: An efficient pattern matching algorithm for string searching. J. Shanxi Univ. Sci. Technol. (Nat. Sci. Edn.) 35(1), 183–187 (2017)
Guibas, L.J., Odlyzko, A.M.: A new proof of the linearity of the Boyer-Moore string searching algorithm. SIAM J. Comput. 9(4), 672–682 (1980)
Sunday, D.M.: A very fast substring search algorithm. Commun. ACM 33(8), 132–142 (1990)
Wang, W.X.: Research and improvement of the BM pattern matching algorithm. J. Shanxi Normal Univ. (Nat. Sci. Edn.) 32(1), 37–39 (2017)
Horspool, R.N.: Practical fast searching in strings. Softw.-Pract. Exper. 10(6), 501–506 (1980)
Acknowledgments
This work was supported by the National Natural Science Foundation of Hunan Province (No. 2019JJ40234), the Natural Science Foundation of China (No. 61462029), the Research Study and Innovative Experimental Project for College Students in Hunan Province (No. 20180599) and the Research Study and Innovative Experimental Project for College Students in Jishou University (No. JDCX20180122).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
He, SP., Mo, LP., Kang, DW. (2019). A Multi-pattern Matching Algorithm for Chinese-Hmong Mixed Strings. In: Tang, J., Kan, MY., Zhao, D., Li, S., Zan, H. (eds) Natural Language Processing and Chinese Computing. NLPCC 2019. Lecture Notes in Computer Science(), vol 11839. Springer, Cham. https://doi.org/10.1007/978-3-030-32236-6_37
Download citation
DOI: https://doi.org/10.1007/978-3-030-32236-6_37
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-32235-9
Online ISBN: 978-3-030-32236-6
eBook Packages: Computer ScienceComputer Science (R0)