
Abstract
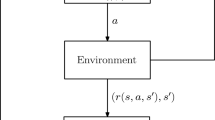
Reinforcement learning (RL) is a general framework for adaptive control, which has proven to be efficient in many domains, e.g., board games, video games or autonomous vehicles. In such problems, an agent faces a sequential decision-making problem where, at every time step, it observes its state, performs an action, receives a reward and moves to a new state. An RL agent learns by trial and error a good policy (or controller) based on observations and numeric reward feedback on the previously performed action. In this chapter, we present the basic framework of RL and recall the two main families of approaches that have been developed to learn a good policy. The first one, which is value-based, consists in estimating the value of an optimal policy, value from which a policy can be recovered, while the other, called policy search, directly works in a policy space. Actor-critic methods can be seen as a policy search technique where the policy value that is learned guides the policy improvement. Besides, we give an overview of some extensions of the standard RL framework, notably when risk-averse behavior needs to be taken into account or when rewards are not available or not known.
Olivier Buffet, Olivier Pietquin and Paul Weng—Equally contributed in this chapter.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
This section is mainly inspired by Deisenroth et al. (2011), although that survey focuses on a robotic framework.
- 2.
Transformations can bring us in this setting.
References
Abbeel P, Coates A, Ng AY (2010) Autonomous helicopter aerobatics through apprenticeship learning. Int J Robot Res 29(13):1608–1639
Abbeel P, Ng A (2004) Apprenticeship learning via inverse reinforcement learning. In: International conference machine learning
Akrour R, Schoenauer M, Sebag M (2013) ECML PKDD. Interactive robot education. Lecture notes in computer science
Akrour R, Schoenauer M, Souplet J-C, Sebag M (2014) Programming by feedback. In: ICML
Anderson BDO, Moore JB (2005) Optimal filtering. Dover Publications
Antos A, Szepesvári C, Munos R (2008) Fitted Q-iteration in continuous action-space MDPs. In: Advances in neural information processing systems, pp 9–16
Argall B, Chernova S, Veloso M, Browning B (2009) A survey of robot learning from demonstration. Robot Auton Syst 57(5):469–483
Artzner P, Delbaen F, Eber J, Heath D (1999) Coherent measures of risk. Math Financ 9(3):203–228
Babes-Vroman M, Marivate V, Subramanian K, Littman M (2011) Apprenticeship learning about multiple intentions. In: ICML
Bagnell JA, Schneider JG (2001) Autonomous helicopter control using reinforcement learning policysearch methods. In: Proceedings of the international conference on robotics and automation, pp 1615–1620
Bagnell JA, Schneider JG (2003) Covariant policy search. In: Proceedings of the international joint conference on artifical intelligence
Bai A, Wu F, Chen X (2013) Towards a principled solution to simulated robot soccer. In: RoboCup-2012: robot soccer world cup XVI. Lecture notes in artificial intelligence, vol 7500
Baird L et al (1995) Residual algorithms: Reinforcement learning with function approximation. In: Proceedings of the twelfth international conference onmachine learning, pp 30–37
Barbera S, Hammond P, Seidl C (1999) Handbook of utility theory. Springer, Berlin
Bäuerle N, Rieder U (2011) Markov decision processes with applications to finance. Springer Science and Business Media
Baxter J, Bartlett P (2001) Infinite-horizon policy-gradient estimation. J Artif Intell Res 15:319–350
Baxter J, Bartlett P, Weaver L (2001) Experiments with infinite-horizon, policy-gradient estimation. J Artif Intell Res 15:351–381
Bellman R, Dreyfus S (1959) Functional approximations and dynamic programming. Math Tables Aids Comput 13(68):247–251
Bellman R, Kalaba R, Kotkin B (1963) Polynomial approximation-a new computational technique in dynamic programming: allocation processes. Math Comput 17(82):155–161
Bogert K, Lin JF-S, Doshi P, Kulic D (2016) Expectation-maximization for inverse reinforcement learning with hidden data. In: AAMAS
Bojarski M, Testa DD, Dworakowski D, Firner B, Flepp B, Goyal P, Jackel LD, Monfort M, Muller U, Zhang J, Zhang X, Zhao J (2016) End to end learning for self-driving cars. Technical report, NVIDIA
Borkar V, Jain R (2014) Risk-constrained Markov decision processes. IEEE Trans Autom Control 59(9):2574–2579
Borkar VS (2010) Learning algorithms for risk-sensitive control. In: International symposium on mathematical theory of networks and systems
Bou Ammar H, Tutunov R, Eaton E (2015) Safe policy search for lifelong reinforcement learning with sublinear regret. In: ICML
Boularias A, Kober J, Peters J (2011) Relative entropy inverse reinforcement learning. In: AISTATS
Boutilier C, Dearden R, Goldszmidt M (1995) Exploiting structure in policy construction. In: Proceedings of the fourteenth international joint conference on artificial intelligence, pp 1104–1111
Boutilier C, Dearden R, Goldszmidt M (2000) Stochastic dynamic programming with factored representations. Artif Intell 121(1–2):49–107
Bradtke SJ, Barto AG (1996) Linear least-squares algorithms for temporal difference learning. Machine Learning 22:33–57
Burchfield B, Tomasi C, Parr R (2016) Distance minimization for reward learning from scored trajectories. In: AAAI
Busa-Fekete R, Szörenyi B, Weng P, Cheng W, Hüllermeier E (2014) Preference-based reinforcement learning: evolutionary direct policy search using a preference-based racing algorithm. Mach Learn 97(3):327–351
Busoniu L, Babuska R, De Schutter B (2010) Innovations in multi-agent systems and applications – 1, vol 310, chapter Multi-agent reinforcement learning: an overview, Springer, Berlin, pp 183–221
Chernova S, Veloso M (2009) Interactive policy learning through confidence-based autonomy. J Artif Intell Res 34:1–25
Choi D, Van Roy B (2006) A generalized Kalman filter for fixed point approximation and efficient temporal-difference learning. Discret Event Dyn Syst 16(2):207–239
Choi J, Kim K-E (2011) Inverse reinforcement learning in partially observable environments. JMLR 12:691–730
Choi J, Kim K-E (2012) Nonparametric Bayesian inverse reinforcement learning for multiple reward functions. In: NIPS
Chow Y, Ghavamzadeh M (2014) Algorithms for CVaR optimization in MDPs. In: NIPS
Chow Y, Ghavamzadeh M, Janson L, Pavone M (2016) Risk-constrained reinforcement learning with percentile risk criteria. JMLR 18(1)
da Silva VF, Costa AHR, Lima P (2006) Inverse reinforcement learning with evaluation. In: IEEE ICRA
Daniel C, Neumann G, Peters J (2012) Hierarchical relative entropy policy search. In: Proceedings of the international conference of artificial intelligence and statistics, pp 273–281
de Boer P, Kroese D, Mannor S, Rubinstein R (2005) A tutorial on the cross-entropy method. Ann Oper Res 134(1):19–67
de Farias D, Van Roy B (2003) The linear programming approach to approximate dynamic programming. Oper Res 51(6):850–865
Degris T, Sigaud O, Wuillemin P-H (2006) Learning the structure of factored Markov decision processes in reinforcement learning problems. In: Proceedings of the 23rd international conference on machine learning
Deisenroth MP, Neumann G, Peters J (2011) A survey on policy search for robotics. Found Trends Robot 2(1–2):1–142
Deisenroth MP, Rasmussen CE (2011) PILCO: a model-based and data-efficient approach to policy search. In: Proceedings of the international conference on machine learning, pp 465–472
Denuit M, Dhaene J, Goovaerts M, Kaas R, Laeven R (2006) Risk measurement with equivalent utility principles. Stat Decis 24:1–25
Dimitrakakis C, Rothkopf CA (2011) Bayesian multitask inverse reinforcement learning. In: EWRL
El Asri L, Laroche R, Pietquin O (2012) Reward function learning for dialogue management. In: STAIRS
El Asri L, Piot B, Geist M, Laroche R, Pietquin O (2016) Score-based inverse reinforcement learning. In: AAMAS
Engel Y, Mannor S, Meir R (2005) Reinforcement learning with Gaussian processes. In: Proceedings of the 22nd international conference on Machine learning, ACM, pp 201–208
Ernst D, Geurts P, Wehenkel L (2005) Tree-based batch mode reinforcement learning. J Mach Learn Res 6(Apr):503–556
Fürnkranz J, Hüllermeier E, Cheng W, Park S (2012) Preference-based reinforcement learning: a formal framework and a policy iteration algorithm. Mach Learn 89(1):123–156
Geibel P, Wysotzky F (2005) Risk-sensitive reinforcement learning applied to control under constraints. JAIR 24:81–108
Geist M, Pietquin O (2010a) Kalman temporal differences. J Artif Intell Res 39:483–532
Geist M, Pietquin O (2010b) Statistically linearized least-squares temporal differences. In: 2010 international congress on ultra modern telecommunications and control systems and workshops (ICUMT), IEEE, pp 450–457
Geist M, Pietquin O (2011) Parametric value function approximation: a unified view. In: ADPRL
Geist M, Pietquin O (2013) Algorithmic survey of parametric value function approximation. IEEE Trans Neural Netw Learn Syst 24(6):845–867
Ghavamzadeh M, Mannor S, Pineau J, Tamar A (2015) Bayesian reinforcement learning: a survey. Found Trends Mach Learn 8(5–6):359–492
Gilbert H, Spanjaard O, Viappiani P, Weng P (2015) Solving MDPs with skew symmetric bilinear utility functions. In: International joint conference in artificial intelligence (IJCAI), pp 1989–1995
Gilbert H, Weng P (2016) Quantile reinforcement learning. In: Asian workshop on reinforcement learning
Gilbert H, Zanuttini B, Viappiani P, Weng P, Nicart E (2016) Model-free reinforcement learning with skew-symmetric bilinear utilities. In: International conference on uncertainty in artificial intelligence (UAI)
Gordon GJ (1995) Stable function approximation in dynamic programming. In: Proceedings of the twelfth international conference onmachine learning, pp 261–268
Gosavi AA (2014) Variance-penalized Markov decision processes: dynamic programming and reinforcement learning techniques. Int J General Syst 43(6):649–669
Grollman DH, Billard A (2011) Donut as I do: learning from failed demonstrations. In: IEEE ICRA
Guestrin C, Hauskrecht M, Kveton B (2004) Solving factored MDPs with continuous and discrete variables. In: AAAI, pp 235–242
Hansen N, Muller S, Koumoutsakos P (2003) Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES). Evol Comput 11(1):1–18
Heidrich-Meisner V, Igel C (2009) Neuroevolution strategies for episodic reinforcement learning. J Algorithms 64(4):152–168
Hussein A, Gaber MM, Elyan E, Jayne C (2017) Imitation learning: a survey of learning methods. ACM Comput Surv
Jiang DR, Powell WB (2017) Risk-averse approximate dynamic programming with quantile-based risk measures. Math Oper Res 43(2):347–692
Julier SJ, Uhlmann JK (2004) Unscented filtering and nonlinear estimation. Proc IEEE 92(3):401–422
Klein E, Geist M, Piot B, Pietquin O (2012) Inverse reinforcement learning through structured classification. In: NIPS
Kober J, Oztop E, Peters J (2010) Reinforcement learning to adjust robot movements to new situations. In: Proceedings of the 2010 robotics: science and systems conference
Kober J, Peters J (2010) Policy search for motor primitives in robotics. Mach Learn 1–33
Kulkarni T, Narasimhan KR, Saeedi A, Tenenbaum J (2016) Hierarchical deep reinforcement learning: integrating temporal abstraction and intrinsic motivation. In: NIPS
Lagoudakis MG, Parr R (2003) Least-squares policy iteration. J Mach Learn Res 4(Dec):1107–1149
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436–444
Lesner B, Zanuttini B (2011) Handling ambiguous effects in action learning. In: Proceedings of the 9th European workshop on reinforcement learning, p 12
Lillicrap TP, Hunt JJ, Pritzel A, Heess N, Erez T, Tassa Y, Silver D, Wierstra D (2016) Continuous control with deep reinforcement learning. In: ICLR
Lin L-H (1992) Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach Learn 8(3/4):69–97
Liu Y, Koenig S (2006) Functional value iteration for decision-theoretic planning with general utility functions. In: AAAI, AAAI, pp 1186–1193
Lopes M, Melo F, Montesano L (2009) Active learning for reward estimation in inverse reinforcement learning. In: ECML/PKDD. vol 5782, Lecture notes in computer science, pp 31–46
Machina M (1988) Expected utility hypothesis. In: Eatwell J, Milgate M, Newman P (eds) The new palgrave: a dictionary of economics. Macmillan, pp 232–239
Matignon L, Laurent GJ, Le Fort-Piat N (2006) Reward function and initial values: better choices for accelerated goal-directed reinforcement learning. Lect Notes CS 1(4131):840–849
Mihatsch O, Neuneier R (2002) Risk-sensitive reinforcement learning. Mach Learn 49:267–290
Mnih V, Badia AP, Mirza M, Graves A, Lillicrap TP, Harley T, Silver D, Kavukcuoglu K (2016) Asynchronous methods for deep reinforcement. learning. In: ICML
Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D (2015) Human-level control through deep reinforcement learning. Nature 518:529–533
Moldovan T, Abbeel P (2012) Risk aversion Markov decision processes via near-optimal Chernoff bounds. In: NIPS
Neu G, Szepesvari C (2007) Apprenticeship learning using inverse reinforcement learning and gradient methods. In: UAI
Neu G, Szepesvari C (2009) Training parsers by inverse reinforcement learning. Mach Learn 77:303–337
Neumann G (2011) Variational inference for policy search in changing situations. In: Proceedings of the international conference on machine learning, pp 817–824
Ng A, Russell S (2000) Algorithms for inverse reinforcement learning. In: ICML, Morgan Kaufmann
Ng AY, Jordan M (2000) PEGASUS : A policy search method for large MDPs and POMDPs. In: Proceedings of the conference on uncertainty in artificial intelligence
Nguyen QP, Low KH, Jaillet P (2015) Inverse reinforcement learning with locally consistent reward functions. In: NIPS
Pasula HM, Zettlemoyer LS, Kaelbling LP (2007) Learning symbolic models of stochastic domains. J Artif Intell Res 29:309–352
Peters J, Mülling K, Altun Y (2010) Relative entropy policy search. In: Proceedings of the national conference on artificial intelligence
Peters J, Schaal S (2007) Applying the episodic natural actor-critic architecture to motorprimitive learning. In: Proceedings of the European symposium on artificial neural networks
Peters J, Schaal S (2008a) Natural actor-critic. Neurocomputation 71(7–9):1180–1190
Peters J, Schaal S (2008b) Reinforcement learning of motor skills with policy gradients. Neural Netw 4:682–697
Piot B, Geist M, Pietquin O (2013) Learning from demonstrations: is it worth estimating a reward function? In: ECML PKDD, Lecture notes in computer science
Piot B, Geist M, Pietquin O (2014) Boosted and Reward-regularized classification for apprenticeship learning. In: AAMAS, France, Paris, pp 1249–1256
Pomerleau D (1989) Alvinn: an autonomous land vehicle in a neural network. In: NIPS
Prashanth L, Ghavamzadeh M (2016) Variance-constrained actor-critic algorithms for discounted and average reward MDPs. Mach Learn
Puterman M (1994) Markov decision processes: discrete stochastic dynamic programming. Wiley, New York
Ramachandran D, Amir E (2007) Bayesian inverse reinforcement learning. In: IJCAI
Randløv J, Alstrøm P (1998) 1998. Learning to drive a bicycle using reinforcement learning and shaping. In: ICML
Ratliff N, Bagnell J, Zinkevich M (2006) Maximum margin planning. In: ICML
Ratliff N, Bradley D, Bagnell JA, Chestnutt J (2007) Boosting structured prediction for imitation learning. In: NIPS
Riedmiller M (2005) Neural fitted Q iteration-first experiences with a data efficient neural reinforcement learning method. In: ECML, vol 3720. Springer, Berlin, pp 317–328
Roijers D, Vamplew P, Whiteson S, Dazeley R (2013) A survey of multi-objective sequential decision-making. J Artif Intell Res 48:67–113
Russell S (1998) Learning agents for uncertain environments. In: Proceedings of the eleventh annual conference on Computational learning theory, ACM, pp 101–103
Samuel A (1959) Some studies in machine learning using the game of checkers. IBM J Res Dev 3(3):210–229
Schaul T, Quan J, Antonoglou I, Silver D (2016) Prioritized experience replay. In: ICLR
Schulman J, Levine S, Abbeel P, Jordan M, Moritz P (2015) Trust region policy optimization. In: ICML
Sebag M, Akrour R, Mayeur B, Schoenauer M (2016) Anti imitation-based policy learning. In: ECML PKDD, Lecture notes in computer science
Sehnke F, Osendorfer C, Rückstieß T, Graves A, Peters J, Schmidhuber J (2010) Parameter-exploring policy gradients. Neural Netw 23(4):551–559
Silver D, Huang A, Maddison CJ, Guez A, Sifre L, van den Driessche G, Schrittwieser J, Antonoglou I, Panneerschelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, Hassabis D (2016) Mastering the game of Go with deep neural networks and tree search. Nature 529:484–489
Silver D, Lever G, Heess N, Degris T, Wierstra D, Riedmiller M (2014) Deterministic policy gradient algorithms. In: ICML
Singh S, Kearns M, Litman D, Walker M (1999) Reinforcement learning for spoken dialogue systems. In: NIPS
Spaan MT (2012) Reinforcement Learning, chapter Partially observable Markov decision processes. Springer, Berlin
Sutton R, Maei H, Precup D, Bhatnagar S, Silver D, Szepesvári C, Wiewiora E (2009) Fast gradient-descent methods for temporal-difference learning with linear function approximation. In: ICML
Syed U, Schapire RE (2008) A game-theoretic approach to apprenticeship learning. In: NIPS
Szita I, Lörincz A (2006) Learning tetris using the noisy cross-entropy method. Neural Comput 18:2936–2941
Tamar A, Chow Y, Ghavamzadeh M, Mannor S (2015a) Policy gradient for coherent risk measures. In: NIPS
Tamar A, Di Castro D, Mannor S (2012) Policy gradient with variance related risk criteria. In: ICML
Tamar A, Di Castro D, Mannor S (2013) Temporal difference methods for the variance of the reward to go. In: ICML
Tamar A, Glassner Y, Mannor S (2015b) Optimizing the CVaR via sampling. In: AAAI
Taylor ME, Stone P (2009) Transfer learning for reinforcement learning domains: a survey. J Mach Learn Res 10:1633–1685
Tesauro G (1995) Temporal difference learning and td-gammon. Commun ACM 38(3):58–68
Van Hasselt H, Guez A, Silver D (2016) Deep reinforcement learning with double q-learning. In: AAAI, pp 2094–2100
van Otterlo M (2009) The logic of adaptive behavior. IOS
Walsh T, Szita I, Diuk C, Littman M (2009) Exploring compact reinforcement-learning representations with linear regression. In: Proceedings of the 25th conference on uncertainty in artificial intelligence
Wen M, Papusha I, Topcu U (2017) Learning from demonstrations with high-level side information. In: IJCAI
Weng P, Busa-Fekete R, Hüllermeier E (2013) Interactive Q-learning with ordinal rewards and unreliable tutor. In: Workshop reinforcement learning with. generalized feedback, ECML/PKDD
Werbos PJ (1990) Consistency of HDP applied to a simple reinforcement learning problem. Neural Netw 3:179–189
Wierstra D, Schaul T, Glasmachers T, Sun Y, Peters J, Schmidhuber J (2014) Natural evolution strategies. JMLR 15:949–980
Williams R (1992) Simple statistical gradient-following algorithms for connectionnist reinforcement learning. Mach Learn 8(3):229–256
Wilson A, Fern A, Ray S, Tadepalli P (2007) Multi-task reinforcement learning: A hierarchical Bayesian approach. In: ICML
Wilson A, Fern A, Tadepalli P (2012) A Bayesian approach for policy learning from trajectory preference queries. In: Advances in neural information processing systems
Wirth C, Neumann G (2015) Model-free preference-based reinforcement learning. In: EWRL
Wu Y, Tian Y (2017) Training agent for first-person shooter game with actor-critic curriculum learning. In: ICLR
Wulfmeier M, Ondruska P, Posner I (2015) Maximum entropy deep inverse reinforcement learning. In: NIPS, Deep reinforcement learning workshop
Xu X, Hu D, Lu X (2007) Kernel-based least squares policy iteration for reinforcement learning. IEEE Trans Neural Netw 18(4):973–992
Yu T, Zhang Z (2013) Optimal CPS control for interconnected power systems based on SARSA on-policy learning algorithm. In: Power system protection and control, pp 211–216
Yue Y, Broder J, Kleinberg R, Joachims T (2012) The k-armed dueling bandits problem. J Comput Syst Sci 78(5):1538–1556
Zhao Q, Chen S, Leung S, Lai K (2010) Integration of inventory and transportation decisions in a logistics system. Transp Res Part E: Logist Transp Rev 46(6):913–925
Ziebart B, Maas A, Bagnell J, Dey A (2010) Maximum entropy inverse reinforcement learning. In: AAAI
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Buffet, O., Pietquin, O., Weng, P. (2020). Reinforcement Learning. In: Marquis, P., Papini, O., Prade, H. (eds) A Guided Tour of Artificial Intelligence Research. Springer, Cham. https://doi.org/10.1007/978-3-030-06164-7_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-06164-7_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-06163-0
Online ISBN: 978-3-030-06164-7
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)