
Abstract
In this paper we introduce a simplified approach to sentiment analysis: a lexicon-driven method based upon only adjectives and adverbs. This method is compared in cross-validation with other known techniques and then compared directly to the gold standard, a sample of human subjects asked to deliver the same class of judgments computed by the method. We prove that the method is similar in accuracy and precision with the other methods. We finally argue that the approach we employ is more valid than others for it is scalable, and exportable to languages other than English.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
- Sentiment Analysis (SA)
- Sentiment Lexicon
- Synsets
- Term Frequency-Inverse Document (TFIDF)
- Dependency Parsing
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Sentiment Analysis (SA) concerns the use of natural language processing and text mining for the automatic tagging of a text as positive, negative or neutral, on the basis of its content. Natural language, however, is inherently vague and often unstructured. As a consequence, the automatic understanding of the “polarity” of a text is a challenging problem, that can be expressed in term of questions we should answer as follows: “What is an opinion?” and “How can we summarize a set of opinions?”
An opinion is a judgment expressed by someone over an object, individual, animal, or fact. In [16] authors draw special attention to the fact that there are several kind of sentences, each of which can express “sentiment” in different ways. Therefore, we ought to consider several kinds of opinions, formally summarised in the following classification:
- Direct Opinions: :
-
the opinion is clearly expressed in the words of the sentence so that it can be extracted using only the words themselves: i.e. “image quality is perfect”).
- Indirect Opinions: :
-
the opinion is not clearly expressed in the words of the sentence, which contains also some implicit knowledge so that it cannot be extracted without the additional use of this knowledge: i.e. “I bought this mattress two months ago and now there is a sinking in the middle”. To understand the underlying opinion we need to know what to expect from a mattress.
- Comparative Opinions: :
-
they express a comparison: i.e. “Image quality is better in Iphone than in Blackberry”.
- Subjective Opinions: :
-
they express a personal judgment: i.e. “I like the new smartphone”
- Objective Opinions: :
-
they express a fact: i.e. “My new smartphone doesn’t work any longer”
Several algorithms for opinion mining, also called sentiment analysis based on a statical approach over single words in sentences have been proposed as specific procedures: they can extract sentiment of a particular kind, e.g. direct opinions rather than indirect ones. In other words, algorithms for Sentiment Analysis are hardly scalable, i.e. enough general to address the detection of a general opinion.
This is principally due to the fact that sentiment analysis algorithm are often based on very strong assumption about the language, specifically oriented to the detection of a single form: for example, comparative opinions are recognized thanks to some regular constructs such as “but, nevertheless, even if, etc.”: Unfortunately, since written natural language is generally unstructured, these constructs might or might not be present. This clearly provides an irremediable failure in the opinion mining. A simple example is the sentences “I do prefer Iphone to Blackberry thanks to image quality”: it contain a comparative form, but it can not be detected by regular constructs mentioned above.
It is evident that efficiency and scalability are two strongly related goals in Sentiment Analysis algorithm design.
The recognition of subjective and objective opinions is a subtask in Sentiment Analysis: in some work [13] authors state that subjective sentences are more likely to contain opinions than objective ones and thanks to this they use subjectivity detection techniques as pre-computation steps in sentiment analysis.
Consider the sentence below, where more than one opinion is summarised
Example 1
I bought an iPhone a few days ago. It is such a nice phone. The touch screen is really cool. The voice quality is clear too. It is much better than my old Blackberry, which was a terrible phone and so difficult to type with its tiny keys. However, my mother was mad with me as I did not tell her before I bought the phone. She also thought the phone was too expensive.
We can have several analysis aspects:
-
document level: is the review a “+” or a “–” ?
-
sentence level: each sentence is a “+” or a “–” ?
-
entity and feature/aspect level: bind any subject (entity) in the sentence to adjectives which can describe one or more aspect of these subjects and then evaluate the sentiment of these adjectives, who expressed it (opinion holder) and the time frame in which it has been stated.
To better model all these analysis aspects, in [12] Liu formally defines an opinion as a tuple:
given that, an opinion document can be defined a collection of opinions.
Sentiment Analysis goal is therefore to find all the tuples in an opinion document.
This can be a quite complicated task, due to the complexity and the lack of fixed structure in natural language, so that using current algorithms entity-aspects detection and opinion holder detection are complex task, linking them is a challenging task while sentiment determination is somehow simpler.
Distinguishing between direct and indirect opinions and identification of sarcasm and irony are still open problems.
Therefore a simpler goal, but more likely to be achieved, is a reduced version of the original goal such as determining the sentiment only, without entity-aspects detection.
2 Basics
In Sentiment analysis there are several features that can be taken into account, either combined or by themselves, to try and understand the polarity of a text.
Most important sentiment indicators are words called sentiment words also called opinion words. These words are commonly used to express appositive or negative sentiment, such as “good, bad, amazing, etc.” In addition to single words there are also small sentences or part of speech (PoS) like “cost someone an arm and a leg”.
A sentiment lexicon is a list of such words and PoS each coupled with a polarity value typically ranging between \(-1\) and 1. It might be generated either manually or automatically: in this latter case from each seed word in a given list is considered along with its lexical relationships such as hyponym or hyperonym. In [21] the authors choose synonyms and antonyms using the dictionary Wordnet [14]. The most widely used sentiment lexicon for english language is named “Sentiwordnet” [10]. For other languages there isn’t any renown efficient public available sentiment lexicon; for instance for italian language there is a tool named “Sentix”, built in a completely automatic way, which presents some drawbacks such as errors in polarity and low coverage (ca. 60.000 word and PoS compared to the 117.000 in Sentiwordnet).
Frequency Term. A classical feature in Sentiment analysis is a vector in which every component corresponds to a word or word sequence (n-gram), meaning that the value on the \(i^{th}\) axes is the relative frequency within the document (or document collection) of the corresponding word. Often used are sophisticated measures like Term Frequency Inverse Document Frequency (TFIDF) in which the ratio between word occurrences and number of documents is taken into account. These features are typical of the discipline of text retrieval and text classification.
Part of Speech (PoS tag). Natural Language Processing (NLP) techniques allow the coupling of words to their Part of Speech (POS tag) so that a label can be applied to a word to determine whether it is a verb, noun, adjective or adverb. Current Part of Speech tagger are known to achieve an accuracy close to 95%. This is quite relevant in sentiment analysis because of the importance of the knowledge of the kind of a word: it has been shown that adjective and adverbs are relevant indicators when dealing with the polarity of a text, as stated originally in Pang and Lee [15].
Sentiment Shifters. Sentiment shifters are words used to change the orientation such as negation words, (e.g. not, don’t) or intensifier (very, absolutely, rarely).
Dependency Parser. A dependency parser is a method to analyse the grammatical structure of a sentence so that relationships between subsets of words can be inferred. These subsets represent periods in a sentence, verbal predicates, nominal predicates and relationships can be organised in a tree to better represent internal hierarchies. Root node identifies the whole text, its descendants represents sentences, incidental phrases, verbal predicates, nominal predicates conjunctions down to the leafs which stands for PoS tag and single words.
3 Related Work
Sentiment analysis main approaches can be divided in two macroclasses: (1) Lexicon-based, and (2) Machine learning-based. There are also some hybrid approaches that combine these above mentioned.
Sentiment lexicon based methods makes extensive use of the polarity of single words as a mean to create a measure of the overall sentence sentiment. Turney [19] proposes the use of the mean of adjective and adverb polarities to help predict the sentiment orientation, while Taboada et al. [18] lexicon-based approaches made also use of negation and intensifiers (i.e. very, really, extremely etc.) Lexicon-based methods can be considered accurate in classification task but they suffer a few drawbacks:
-
A single word can have both a legitimate positive or negative orientation, depending on the context. A simple example is the word cheap can be generally considered positive, such as in This hotel is cheap, nevertheless can be use in negative meaning, such as in as cheap as it’s worth.
-
a sentence may include sentiment word even though it does non express any opinion, i.e. Can you tell me which Sony camera is good? or If I can find a good camera in the shop, I will buy it.
-
a sentence without sentiment words may legitimately express a sentiment, and almost all indirect opinions are in this form.
These methods are based on machine learning and more specifically supervised classification techniques. Given that some kind of words are relevant indicators of the polarity of the sentence in which these words appear, the probability of a text to belong to a certain polarity class (positive, negative, neutral) can be devised from the presence and the number of these kind of words in the text. This is similar to a traditional classification problem, when a text has to be classified based on topic (i.e. sport, politics or science), so that a common approach is using words as features (bag of words) and then apply supervised classification methods such as naïve Bayes classifier or support vector machine (SVM) [11]. Among the advantages these technique allows, we can count the possibility to adapt the training set to fit the context of the application, whereas with lexicon based approaches we cannot easily adapt the lexicon to the specific problem at hand.
These techniques have been used to classify movie reviews as positive or negative [15]; using single words (unigrams) as features and combining bag of word and SVM the results outperformed the ones obtained using other classical classifiers. Moreover, PartOfSpeech tags, bigram, adjectives and their combinations have been tested.
A well known approach involves the combination of Natural Language Processing (NLP), machine learning and lexicon-based techniques. In [8] a dependency parser is used as preprocessing step of an algorithm named “sentiment propagation”. A dependency parser identifies relationships between words set of words so that a tree structure representation can be created. The authors makes the assumption that every linguistic element such as nouns, verbs, etc. has a latent sentiment value, which is propagated throughout the tree structure identified by the dependency parser. Propagation rules var according to construct: adverbial modifiers (i.e. very, weaken) may strengthen or weaken the sentiment of a specific word. Prepositions such as to, with, in are considered as channels through which sentiment flows across words. In another paper [17] has been shown that the majority of sentiment analysis techniques are based on semantic of single words, which suffer the drawback of missing to understand the relationship between words and therefore phrasal semantics. The authors therefore propose a method based on recursive neural network in which words are represented with a matrix and a vector. The latter catches the meaning of the item (word, sentence, PoS) while the matrix identifies the meaning of elements related to the item itself.
Some investigations have also been performed about multi language sentiment analysis algorithms. These need at least sentiment lexicon for each language and a wide ground truth for each language (hopefully context aware).
It has been shown that performance of sentiment analysis applied to an automatically traduced text are comparable with the ones given by english language [2].
4 A Simple Method for Scalable Sentiment Extraction
In this section we introduce the methodology we developed to make easier and more efficient multi language sentiment analysis. Our goal can be summarised in the following main objectives:
-
to reduce lexical resources needed to mine the polarity of a word (this aims to make easier the multi language approach)
-
to efficiently identify discriminant lexical pattern for sentiment analysis.
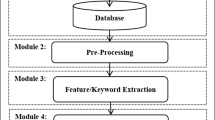
It is known from literature [3] that different POS methods have different effect on the results of SA extraction, and that a simple POS tagging is not enough to obtain efficient performances [15]; moreover we need to keep trace of shifters such as negations. We therefore try to design an efficient word labeling based on finite sequence of POS tagging to be later coupled with an efficient use of the sentiment lexicon and we named it SiSeSa, acronym for “Simple Sentiment Scalable Algorithm”. The result has been a vectorial description of information related of a word (POS tag plus polarity prevision), that we will called information vector. In the following sections we describe the main phases of the method: text preprocessing and creation of the information vector.
4.1 Lexicon Based Polarity Analysis
Each document we process (a customer review, as exploited in the following) is preprocessed in order to simplify further computation. In particular, we extract, for each word, a part of speech tag, a polarity and a probability. Given a text, it is possible to classify each word into a lexical category (with a related probability) by a Part of Speech algorithm. We use very standard subroutines such as tokenisation, lemmization and we retrieve POS information with the OpenNLP packageFootnote 1.
Since word polarity is strongly influenced by the presence of negation in phrases, we exploit a dependency parser to detect negations and their scopes [8]. The presence of a negation influences the polarity of a word with a negative multiplicative factor \((-1)\).
Once POS-tagging and negation information have been detected, the polarity of a word can is finally extracted. We use the sentiment lexicon SentiwordnetFootnote 2 [1] which associates to each group of word with equivalent or similar meaning (named synset) in its knowledge base a triple of values \(ps_s\), \(ns_s\) and \(os_s\), where \(ps_s\) denotes the positivity degree, \(ns_s\) denotes the negativity degree, \(os_s\) denotes the objectivity of the words so that neutral polarized words can be easily detected; we have \(ps_s+ns_s=1\). The overall polarity of the synset is computed as \(p_s=ps_s - ns_s\). To each synset can be associated more than a single lemma (a word \(p_w\) in the text), and to each POS-tagged lemma can be associated more than a single synset.
To relate a single score to each word \(p_w\), a weighted average of the valued of all synset \(p_w\) is associated to is computed. The weights come from the ranking of the synsets, and is a function of the probabilities that link \(p_w\) to each synset. Therefore we have \(p_w=\frac{1}{r_s}\sum _{s\in S}p_s\), where S is the set of the synsets related to w and \(r_s\) is the rank of the synset s.
In our classification, after the labeling of each word by one of the three possible polarity classes (positive, negative and neutral), we further classify as neutral those words showing very small positive or negative polarity. In particular we empirically choose \({\pm }0,1\) as a threshold for the classification of neutrals.
4.2 Information Vector Creation Using Markov Model
Following [9], a sequence of n POS-tags can be viewed as a Markov chain of order n. In the rest of the paper, we will denote a Markov Model (MM). Each state k of the chain represents a triple \(\langle l, s, p\rangle \), where: l is a POS-tag; s is an information about the polarity of the word; p is a probability associated to the state, depending on the \(k-1\) predecessor states; As previously stated, in the context of SA the component s is crucial, in particular when the word is classified as an adjective. This information ranges over a set of polarity value, i.e. negative, positive and neutral.
We define an eight state MM, claiming that each state assumes one of the following possible overall values: (i) negative adjective, (ii) neutral adjective, (iii) positive adjective, (iv) adverb, (v) noun, (vi) negative verb, (vii) neutral verb, (viii) positive verb.
Overall state values are determined by the component l and s. When l tag the word as an adverb or a noun, we assume to have the “neutral element” polarity \(\epsilon \) in s.
Once a text has been converted into a sequence of states, we can calculate the transition matrix. Let us denote state variables as \(S_{t}\), with \(t\in \{1,\ldots ,N\}\). Expressions of the form \(P(S_{t}|S_{t-1},S_{t-2}\ldots ,S_{t-k})\) denote transition probabilities for a k-order MM. Throughout the analysis of transition matrices, an algorithm can detect sequences of states which may identify relevant sentiment information.
We recall that weights of a Markov chain can be estimated by counting state frequencies. The associated transition matrix has dimension \(N \times N \times k\), where N is the number of states and k is the order of the chain.
The transition matrix can be successively converted into a vector and, following a discriminative approach, can be viewed as a point in a l-dimension space, for a suitable dimension l.
We therefore apply a supervised discriminative classification technique, such as the well known support vector machine (SVM) [20].
5 Experiment
The initial data set we consider for our experiment is built upon 380 costumer reviews from the web sites Amazon.com and TripAdvisor.com. Reviews from Amazon concern books and technological devices, whereas reviews form Trip Advisor are about evaluation of restaurants. Each review is written in English language and contains at least 40 characters. To create a gold standard we performed a manual revision: all reviews in the dataset have been manual annotated by 38 students in Foreign Language. The reviewer’s task has been to express a positive, negative or neutral judgment about the review, in a blind setting. In order to make the annotation more sharp, each review has been evaluated twice (by different reviewers) and, following a standard praxis in reference standard creation, a third opinion has been provided. The third opinion is directly represented by the numeric overall judgment (the “star” evaluation), ranging in the interval 1 to 5. Following [15], numerical judgments have been converted into the corresponding qualitative classes: negative judgement (values 1 and 2), positive judgment (values 4 and 5) and neutral judgment (value 3).
One of the most important aspect of the gold standard is of course the quality: in other word, we aim to compare experimental results against a robust reference truth. To this end, is central to evaluate it, or, at least, to know and predict possible errors can occur.
In our setting, errors can be related to the following aspects: (i) subjective judgement, occurring when the user and the reviewers evaluate the product or the service in a different way; (ii) wrong description, when word in the text are not enough to correctly express the judgement, and (iii) textual description and overall evaluation (“stars”) disagree; inaccuracy, when the user is not able to express a fair and consistent opinion.
Looking for manual reviews, a percentage of \(78,6\%\) received coincident judgements (no review has been evaluated as both negative and positive). Reviews that obtained the agree between the user and only one reviewer reach the \(89\%\). Only the \(0.15\%\) of the total received three discordant opinion.
In the experiment described below, we will use the two following datasets, built upon the initial data set of 380 Amazon and Trip Advisor reviews:
-
Dataset MA (Manual Annotation): includes all reviews that received equal judgment by reviewer and the gold standard is represented by reviewers’ evaluations.
-
Dataset CSR (Costumer Satisfaction Rating): includes all the reviews in the main dataset and the gold standard is represented by users’ evaluations.

Feature selection curves for 1-order MM using SVM classifiers on MA dataset
For each review, an eight state MM has been trained, with states representing, as in Sect. 4.2: (i) negative adjective, (ii) neutral adjective, (iii) positive adjective, (iv) adverb, (v) noun, (vi) negative verb, (vii) neutral verb, (viii) positive verb.
The order in Markov chain has been varied between 1 and 3 given 64, 512 and 4096 transition probabilities which we will call feature.
The goal being to understand which features were relevant in determine whether a sentiment was neutral, positive or negative, we made extensive use of support vector machine technique. Having a limited set of valid samples, we used a cross validation “leave one out” approach, iteratively considering each review as test element while all the others were the training set.
We tested our framework against two scenario each including the three classes of positive (PosR), neutre (NeuR) and negative (NegR) reviews:
-
(A) PosR versus NegR;
-
(B) PosR versus NeuR versus NegR.
Due to feature vector dimension, we applied some feature strategies in order to better understand the most significant transition probability subset: individual selection, forward selection, backword selection [9].
Each strategy leads to a particular feature ordering. Classification performances have been evaluated using single class F-score, the classifier being a Support Vector Machine with a 10 fold cross validation to avoid overfitting. \( Fscore_{A}= 2\cdot \frac{pre_{}\cdot rec}{pre + rec} \) where pre and rec respectively are class “A” precision and recall. Strategies:
-
1.
Original ranking: no strategy. No changes in feature order.
-
2.
Individual selection: discriminative power of each feature is evaluated based on classification error: involved classifier is “Nearest Neighbour”, using a cross validation “leave one out” approach.
-
3.
Forward feature selection [9]: feature subset evaluation criteria are based upon classification error where the classifier is “Nearest Neighbour”, using a cross validation “leave one out” approach.
-
4.
Backword feature selection [9]: same as above.

Individual feature selection curves for 1-order MM using 4 different classifiers on MA dataset.
As shown in Fig. 1 for order 1 markov chains, “individual selection” is the best strategy. We applied several classifier such as K-Nearest Neigbour classifier (KNN), Naive Bayes classifier (NB), Quadratic Bayes Normal classifier (QBN), Support Vector Machine (SVM) and we observed their behavior when varying feature number. As can be seen in Fig. 2 individual behavior are similar up to almost 30 features, whereas SVM and NB maintain their performances even with larger number of features.
Classification results shown in Table 1 highlights performances of the method, while in Table 2 precision and recall are detailed with respect to both positive and negative polarity classes.
We tested the method SiSeSa against other well known from the literature, such as Term Frequency (TF), Term Frequency Inverse Document Frequency(TFIDF), POStag and sentiment lexicon. We performed the comparison on dataset MA, using SVM classifier following [15] with a “leave one out” cross validation technique; results are summarised in Tables 2, 3 and 4.
As can be seen in these tables SiSeSa outperforms current techniques.
6 Conclusions
In this paper we dealt with the problem of building a method for sentiment analysis that results scalable. The core idea of the method consists in using only adjectives and adverbs as indicators of orientation of a document. In particular we settle an experiment for comparing the results of the method with the gold standard of human subjects expressing the same judgments. The method is proven to be effective and shows the potential of being applied to languages other than English, both properties that are not general for sentiment analysis methods.
Further investigations will be performed towards specific lexicon-driven methods, similarly to what has been done with other methods in various context, in particular in pharmacology [4,5,6, 22,23,24]. One application that is consequent to a study performed by some of the authors regards viral experiments on-line [7].
Notes
- 1.
OpenNLP package (http://opennlp.sourceforge.net).
- 2.
References
Baccianella, S., Esuli, A., Sebastiani, F.: Sentiwordnet 3.0: an enhanced lexical resource for sentiment analysis and opinion mining. In: Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC 2010). European Language Resources Association (ELRA) (2010)
Balahur, A., Turchi, M.: Multilingual sentiment analysis using machine translation? In: Proceedings of the 3rd Workshop in Computational Approaches to Subjectivity and Sentiment Analysis, WASSA 2012, pp. 52–60 (2012)
Benamara, F., Cesarano, C., Picariello, A., Reforgiato, D., Subrahmanian, V.S.: Sentiment analysis: adjectives and adverbs are better than adjectives alone. In: Proceedings of the International Conference on Weblogs and Social Media (ICWSM) (2007)
Combi, C., Zorzi, M., Pozzani, G., Arzenton, E., Moretti, U.: Normalizing spontaneous reports into MedDRA: some experiments with MagiCoder. IEEE J. Biomed. Health Inform. 1–8 (2018). https://doi.org/10.1109/JBHI.2018.2861213
Combi, C., Zorzi, M., Pozzani, G., Moretti, U., Arzenton, E.: From narrative descriptions to MedDRA: automagically encoding adverse drug reactions. J. Biomed. Inform. 84, 184–199 (2018)
Cristani, M., Bertolaso, A., Scannapieco, S., Tomazzoli, C.: Future paradigms of automated processing of business documents. Int. J. Inf. Manag. 40, 67–75 (2018)
Cristani, M., Olivieri, F., Tomazzoli, C.: Viral experiments. In: 3rd International Workshop on Knowledge Discovery on the WEB, KDWeb 2017, vol. 1959. CEUR Workshop Proceedings, pp. 27–35 (2017)
Di Caro, L., Grella, M.: Sentiment analysis via dependency parsing. Comput. Stand. Interfaces 35(5), 442–453 (2013)
Duda, R.O., Hart, P.E., Stork, D.G.: Pattern Classification. Wiley, New York (2001)
Esuli, A., Sebastiani, F.: Sentiwordnet: a publicly available lexical resource for opinion mining. In: Proceedings of the 5th Conference on Language Resources and Evaluation, LREC 2006, pp. 417–422 (2006)
Joachims, T.: Making large-scale SVM learning practical. In: Advances in Kernel Methods - Support Vector Learning. MIT Press (1999)
Liu, B.: Sentiment analysis and opinion mining (2012)
Lyu, K., Kim, H.: Sentiment analysis using word polarity of social media. Wirel. Pers. Commun. 89(3), 941–958 (2016)
Miller, G.A.: Wordnet: a lexical database for English. Commun. ACM 38(11), 39–41 (1995)
Pang, B., Lee, L., Vaithyanathan, S.: Thumbs up? Sentiment classification using machine learning techniques. In: Proceedings of the ACL02 Conference on Empirical Methods in Natural Language Processing, EMNLP 2002, vol. 10, pp. 79–86. Association for Computational Linguistics (2002)
Ramanathan, N., Bing, L., Alok, C.: Sentiment analysis of conditional sentences. In: Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1, EMNLP 2009, vol. 1, pp. 180–189 (2009)
Socher, R., Huval, B., Manning, C.D., Ng, A.Y.: Semantic compositionality through recursive matrix-vector spaces. In: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, EMNLP-CoNLL 2012, pp. 1201–1211 (2012)
Taboada, M., Brooke, J., Tofiloski, M., Voll, K., Stede, M.: Lexicon-basedmethods for sentiment analysis. Comput. Linguist. 37(2), 267–307 (2011)
Turney, P.D., Littman, M.L.: Measuring praise and criticism: inference of semantic orientation from association. ACM Trans. Inf. Syst. 21(4), 315–346 (2003)
Vapnik, V.: The Nature of Statistical Learning Theory. Springer, New York (1995). https://doi.org/10.1007/978-1-4757-3264-1
Williams, G.K., Anand, S.S.: Predicting the polarity strength of adjectives using wordnet. In: ICWSM. The AAAI Press (2009)
Zorzi, M., Combi, C., Lora, R., Pagliarini, M., Moretti, U.: Automagically encoding adverse drug reactions in MedDRA. In: Proceedings of the 2015 IEEE International Conference on Healthcare Informatics, ICHI 2015, pp. 90–99 (2015)
Zorzi, M., Combi, C., Pozzani, G., Arzenton, E., Moretti, U.: A co-occurrence based MedDRA terminology generation: some preliminary results. In: ten Teije, A., Popow, C., Holmes, J.H., Sacchi, L. (eds.) AIME 2017. LNCS (LNAI), vol. 10259, pp. 215–220. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-59758-4_24
Zorzi, M., Combi, C., Pozzani, G., Moretti, U.: Mapping free text into MedDRA by natural language processing: a modular approach in designing and evaluating software extensions. In: Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, ACM-BCB 2017, pp. 27–35 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Cristani, M., Cristani, M., Pesarin, A., Tomazzoli, C., Zorzi, M. (2018). Making Sentiment Analysis Algorithms Scalable. In: Pautasso, C., Sánchez-Figueroa, F., Systä, K., Murillo Rodríguez, J. (eds) Current Trends in Web Engineering. ICWE 2018. Lecture Notes in Computer Science(), vol 11153. Springer, Cham. https://doi.org/10.1007/978-3-030-03056-8_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-03056-8_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03055-1
Online ISBN: 978-3-030-03056-8
eBook Packages: Computer ScienceComputer Science (R0)