
Abstract
Delineation of scientific domains (fields, areas of science) is a preliminary task in bibliometric studies at the mesolevel, far from straightforward in domains with high multidisciplinarity, variety, and instability. The Sect. 2.2 shows the connection of the delineation problem to the question of disciplines versus invisible colleges, through three combinable models: ready-made classifications of science, classical information-retrieval searches, mapping and clustering. They differ in the role and modalities of supervision. The Sect. 2.3 sketches various bibliometric techniques against the background of information retrieval ( ), data analysis, and network theory, showing both their power and their limitations in delineation processes. The role and modalities of supervision are emphasized. The Sect. 2.4 addresses the comparison and combination of bibliometric networks (actors, texts, citations) and the various ways to hybridize. In the Sect. 2.5, typical protocols and further questions are proposed.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others
- scientific field/domain delineation/delimitation
- science mapping/clustering
- science networks
- scientific information retrieval
- science classification
- citation mapping/clustering
- text mining
- text clustering benchmark
- community detection
- hybrid text-citation mapping
1 Shaping the Landscape of Scientific Fields
Collecting literature that is both relevant and specific to a domain is a preliminary step of many scientometric studies: description of strategic fields such as nanosciences, genomics and proteomics, environmental sciences; research monitoring and international benchmarks; science community analyses. Although our focus here is on the intermediate levels, informally described in such terms as areas, specialties, subfields, fields, subdisciplines… this subject is connected to general science classification and, at the other end of the range, to narrow topic search.
In Sect. 2.2 we place delineation at the crossroads of two concepts: the first one is disciplinarity (what is a scientific discipline?), which crystallizes various dimensions of scientific activity in epistemology and sociology. The second one is invisible colleges in resonance with the core of bibliometrics, the study of networks created explicitly or implicitly by publishing actors. From this point of view, domains of science can be viewed as a generalized form of invisible colleges, sometimes in the form of relatively dense and segregated areas—at some scale. In other cases however, the structure is less clear and bounded, with high levels of both internal diversity and external connections and overlaps. Given a target domain, its expected diversity, interdisciplinarity, and instability are challenging issues. We outline the main approaches to delineation: external formalized resources, such as science classifications; ad hoc information retrieval (IR) search; network exploration resources (clustering–mapping).
Section 2.3 is devoted to the main approaches in domain delineation, IR search, and science clustering–mapping, when off-the-shelf classifications are not sufficient. Both take root in the information networks of science, but start from different vantage points, with some simplification: ex ante heavy supervision for IR search, typically with bottom-up ad hoc queries; ex post supervision for bibliometric mapping, with top-down pruning. In difficult cases, these approaches appear complementary, often within multistep protocols. As a result of the complex structure and massive overlaps of aspects of science, of the multiple bibliometric networks involved, of the multiple points of view, the frontiers are far from unique at a given scale of observation. The experts' supervision process is a key element. Its organization depends on the studies' context and demand, to reach decisions through confrontation and negotiation, especially in high-stakes contexts. Beforehand, we shall briefly address the toolbox of data analysis methods for clustering–mapping purposes.
Section 2.4 focuses on the multinetwork approach for delineation tasks, stemming from pragmatic practices of information retrieval ( ) and bibliometrics . The main networks are actor's graphs and other relations connected with invisible colleges based on documents and their main attributes, texts, and citations. Other scientometric networks (teaching, funding, science social networks, etc.) offer potential resources. The hybridization covers a wide scope of forms. There is a strong indication that multinetwork methods improve IR performance and offer a richer substance to experts'/users' discussions.
2 Context
2.1 Background: Disciplinarity and Invisible Colleges
Generally speaking there is no ground truth basis for defining scientific domains. Given a target domain, assigned by sponsors in broad and sometimes fuzzy terms, delineation is the first stage of a bibliometric study. It is tantamount to a rule of decision involving sponsors/stakeholders, scientists/experts, and bibliometricians on extraction of the relevant literature. Delineation also matters as research communities are an object of science sociology as well as a playground for network theoreticians.
The delineation of scientific domains should be understood in the context of the structure of science and scientific communities, especially through the game between diversity, source of speciation, and interdisciplinarity drive towards reunification. Disciplinarity and invisible colleges are two concepts from the sociology of science that symbolize two kinds of communities, the first one more formal and institutional, the second one constructed on informal linkages made visible by bibliometric analysis of science networks . The tradition of epistemology has contributed to highlight the specificity of science by contrast to other conceptions of knowledge. Auguste Comte proposed the first modern classification of science and at the same time condemned the drift of specialization [2.1], considered a threat to a global understanding of positive science. In reaction both to epistemology and normative Mertonian tradition [2.2, 2.3], Kuhn emphasized the role of central paradigms in disciplines at some point of their evolution [2.4]. The post-Kuhnian social constructivism proceeded along two lines—at times conflicting [2.5]—of relativist thinking: the strong programme (see Barnes et al [2.6]) and the no less radical actor–network theory ( ). The first one was initiated by Barnes and Bloor [2.7] and flourished in the science studies movement [2.8, 2.9]. The ANT also borrowed from Serres (translation concept [2.10]) and from the poststructuralist French theory (Foucault, Derrida, Bourdieu, Baudrillard), see [2.11, 2.12, 2.13]. These schools of thought emphasize disciplinarity rather than unity. Lenoir notes that [2.14, pp. 71–72, 82]:
A major consequence of [social constructivism] has been to foreground the heterogeneity of science. [… Disciplines are] crucial sites where the skills [originating in labs] are assembled and political institutions that demarcate areas of academic territory, allocate privileges and responsibilities of expertise, and structure claims on resources.
Bourdieu stressed the importance of personal relationship and shared habitus. Disciplines exhibit both a strong intellectual structure and a strong organization. The institutional framework , with, in most countries, an integration of research and higher education systems, ensures evaluation and career management. Some communities coin their own jargon, amongst signs of differentiation, and norms and patterns. Potentially, all dimensions of research activity (paradigms and theories, classes of problems, methodology and tools, shared vocabulary, corroboration protocols, construction of scientific facts and interpretation) appear as discipline-informed, with particular tensions between superdisciplines, natural sciences and social sciences and humanities. Scientists discuss, within their own disciplines, the subfield breakdown and the structuring role of particular dimensions, for example research objects in microbiology, versus integration drive [2.15, 2.16].
The endless process of specialization and speciation in science, erecting barriers to the mutual understanding of scientists, is partly counteracted by interdisciplinary linkages which maintain and create solidarity between neighbor or remote areas of research. Piaget [2.17] coined the term transdisciplinarity as the new paradigm re-engaging with unity of science. A few rearrangements of large magnitude, such as the movement of convergence between nanosciences, biomedicine, information, and cognitive sciences and technologies ( , Nanotechnology, biotechnology, information technology, and cognitive science; concept coined by NSF (National Science Foundation) in 2002), tend to reunite distant areas or at least create active zones of overlap.
In contrast with disciplinarity, the concept of invisible college in its modern acceptation, popularized by Price and Beaver [2.18] and Crane [2.19], chiefly refers to informal communication networks, personal relationship, and possibly interdisciplinary scope. These direct linkages tend to limit the size of the colleges, although no precise limit can be given. Science studies devote a large literature to those informal groups, which exemplify how networks of actors operate at various levels of science [2.20, 2.21].
Although more formal expressions emerge from the self-organization of those microsocieties (workshops, conferences, journals), the invisible colleges do not claim the relative stability and the social organization of disciplines. The various communication phenomena of the colleges are revealed by sociological studies or, more superficially but systematically, by analysis of bibliometric networks such as coauthorship, text relations and citations. The bibliometric hypothesis assumes that the latter process mirrors essential aspects of science: the traceable publication activity, in a broad sense, expresses the collective behavior of scientific communities in most relevant aspects (contents and certification, production and structure of knowledge, diffusion and reward, cooperation and self-organization). It does not follow that bibliometrics can easily operationalize all hypotheses [2.22]. Affiliations can, in the background, connect to the layers of academic institutions or corporate entities. Mentions to funding bodies are increasingly required in articles reporting grant-supported works. These relations, however, as well as personal interactions, generally require extrabibliometric information. Variants of the invisible colleges in sociology of science are known as epistemic communities, involving scientists and experts with shared convictions and norms [2.23, 2.8] and community of practice [2.24]. The mix of behavior, stakes and power games, in the interaction of virtual colleges and institutions, remains an appealing question. A revival of the interest for delineation studies has been observed at the crossroads of sociology of science and analyses of networks [2.25, 2.26].
Disciplinary views, as well as colleges revealed by bibliometrics, lead to different partitions of literature, depending on the vantage points. In particular, bibliometricians can be confronted with conflictual situations when revealed networks and institutional normative perceptions and claims as to the disciplinary structure and boundaries diverge. The exercise of delineation generally consists in reaching some form of consensus, or at least a few consensual alternatives amongst sponsors, stakeholders, experts, and scientists. The toolbox contains information retrieval, data analysis, and mapping. Bibliometricians act as organizers of experts' supervision, suppliers of quantitative information, and facilitators of negotiations (Fig. 2.1).


Actors' models/bibliometric models . This scheme evokes the interaction between actors' mental or social models of science, disciplines, and domains on the one hand and models from data analyses (clustering–mapping) on bibliometric data sources, based on different methods and networks on the other. The two sides are engaged separately or together in negotiated combinations to reach (almost) consensual views. Two ways of domain delineation are singled out, ad hoc IR search and extraction from maps, with different degrees and moments of supervision. A third way, allowing direct IR search, supposes permanent classification resources
2.2 Operationalization: Three Models of Delineation
In their review of (inter)disciplinarity issues, Sugimoto and Weingart [2.27] stress that the rich conceptualization of disciplinarity, quite elaborate in sociology and iconic of science diversity, does not imply clear operationalization solutions for defining fields. Scientists' claims and co-optation (‘‘Mathematicians are people who make theorems'' with several formulations, including a humoristic one by Alfréd Rényi), university organizations and traditions, epistemology, sociology, bibliometrics offer many entry points. The stakes associated to disciplinary interests and funding, for both scientists and policy makers may interfere with definitions. Introducing the national dimension, for example, shows that the coverage of disciplines is perceived differently in national research systems. Bibliometrics cannot capture the deep sociocognitive identity of disciplines but contributes to enlighten some of the facets that collective scientists' behavior let appear. The difficulty extends to multidisciplinarity measurement.
In practice, the description of disciplines available in scientific information systems takes the form of classification schemes at some granularity (articles, journals) from a few sources: higher education or research organizations for management and evaluation needs (international bodies or national institutions, for example the National Center for Scientific Research (CNRS ) in France); schemes associated to databases from academic societies, generally thematic; and/or from publishers or related corporations (Elsevier, ISI/Thomson Reuters/Clarivate Analytics) dedicated to scientific information retrieval.
We term model A the principle of these institutional science classifications, which do not chiefly proceed from bibliometrics but from the interaction between scientists and librarians. Subcategories and derived sets offer ready-made delineation solutions. The effect of methodological options, the social construction of disciplines by institutions or scientific societies, with struggles for power and games of interests are unlikely to yield convergence: the various classifications of science available, not necessarily compatible, should be taken with caution. Depending on the update system, they also tend to give a cold image of science. Often based on nonoverlapping schemes, they tend to handle multidisciplinarity phenomena poorly. Resources associated with classifications in S&T databases which often include various nomenclatures (species, objects) are a distinct advantage. With its limitations this model nevertheless offers a rich substance to bibliometric studies. Since the development of evaluative scientometrics in the 1970s, in the wake of Garfield and Narin's works, categories are used as bases for normalization of bibliometric measures, especially citation indicators , but classification-free alternatives exist (Sect. 2.3.2). The rigidity of classifications has an advantage, making a virtue out of a necessity, the easy measure of knowledge exchanges between categories over time. Techniques of coclassification [2.28, 2.29], coindex, or coword methods (see below) make it possible to transcend the rigidity of the classification scheme.
The concept of virtual college, originally thought of as micro- or mesoscale communities with informal contours, exchanging in various ways, can be generalized to communities in science networks at any scale. Since the 1980s, this is implicit in most bibliometric studies [2.30]. Global models of science, either small worlds or self-similar fractal models, are consistent with this perspective. This scheme, termed here model C, is the very realm of bibliometrics. Formal and institutional aspects are partly visible through bibliometric networks but need other scientometric information on institutional structure of science systems. Bibliometrics and also scientometrics are blind to other networks/relations such as interpersonal networks and to the complete picture of science funding and science society relations. It follows that the delineation of fields in model A, which accounts for complex mixes nontotally accessible to bibliometric networks, cannot be retrieved by model C approaches. The other way round, model C makes visible implicit structures ignored by the panel of actors involved in model A classification design.
For large academic disciplines, model C merely proposes high-level groupings which might emulate the categories disciplines from model A and share the same label, however with a quite coarse correspondence. In the practice of model C, large groups receive a sort of discipline label through expert supervision. Neither the bibliometric approach nor model A have the property of uniqueness. Various tests were conducted by external bibliometricians on (Science Citation Index of the Web of Science) subject categories, and the agreement is not, usually, that good [2.31] and the existing ready-made classifications cannot pretend to the status of ground truth or gold standard for domain delineation. Depending on the organization, the clustering–mapping operations often fulfill two needs in bibliometric studies, first helping domain delineation, secondly identifying subdomains/topics within the target. In the absence of ground truth, the challenge of model C is to find trade-offs for reflecting a fractal reality quite difficult to break down, since boundaries are hardly natural except for configurations with clear local minima. They are then subject to optimization with partial information and negotiations [2.32, 2.33].
Model B based on IR search, borrows from both A and C. In model A, the operationalization of discipline definition and classification relied on heavily supervised schemes, aiming chiefly at information retrieval. Model B shares the same ground, with an ad hoc search strategy established by bibliometricians and experts for the needs of the study. Ad hoc search is sometimes necessary in order to go beyond the synthetic views provided by clustering and mapping, and to address analytical questions from users (in terms of theory, methods, objects, interpretation). The default granularity is the document level.
The three models can incorporate a semantic folder. Some indexing and classifications systems provide elaborate structures of indexes and keywords: thesaurus and ontologies (Sect. 2.2.4). Model B depends on expert's competence and resources of queried databases to coin semantically robust queries. Model C can treat metadata of controlled language, indexes of any kind, as well as natural language texts, and reciprocally shed light, through data/queries treatment, on the revealed semantic structures of universes.
Reflexivity is present under many aspects: scientists are involved in heavy ex ante input in ready-made classifications (model A), in IR ad hoc search (model B), and in softer ad hoc intervention on bibliometric maps (model C). The supervision/expertise question goes beyond within-community reflexivity, with partners associated to projects: decision-makers and stake-holders and bibliometricians.
Table 2.1 sums up the main features of the three models. They are just archetypes: in practice, blending is the rule. If classical disciplinary classification schemes belong to the first model, the Science Citation Index and variants incorporate bibliometric aspects. Purely bibliometric classifications, if maintained and widely available, give birth to ready-made solutions. In the background of the three models, the progressive rapprochement of bibliometrics and IR tools, addressed below in Sect. 2.3 should be kept in mind.
2.3 Challenges at the Mesolevel
2.3.1 Interdisciplinarity
Interdisciplinarity is quite an old question and rose to the forefront in the early 1970s with an OECD (Organization for Economic Cooperation and Development) conference devoted to the topic, which gave rise to a wealth of literature and programs. The distinction between multi-, inter-, and transdisciplinarity formulates various degrees of integration, see [2.34, 2.5]. As Choi and Park put it [2.35]:
Multidisciplinarity draws on knowledge from different disciplines but stays within their boundaries. Interdisciplinarity analyses, synthesizes and harmonizes links between disciplines into a coordinated and coherent whole.
Jahn et al [2.36] examine two interpretations of transdisciplinarity in literature. Both make sense in a delineation context. One privileges the science–society relationship: integration between social sciences and humanities ( ) and natural sciences with the participation of extrascientific actors, as a response to heavy and controversial socioscientific problems such as climatic change, genetically modified organisms, medical ethics, etc. The second interpretation considers that transdisciplinarity simply pushes the logic of interdisciplinarity towards integration. Russell et al [2.37], cited by Jahn et al [2.36],
emphasize that where interdisciplinarity still relies on disciplinary borders in order to define a common object of research in areas of overlap […] between disciplines, transdisciplinarity truly transgresses or transcends [them].
Klein [2.38] and Miller et al [2.39] stress the theoretical and problem-solving capability of the transdisciplinary view. Many publications evoke the paradox of multidisciplinarity, a source of radical discoveries, laboring however to convince evaluators in the science reward system. Yegros-Yegros et al [2.40] list a few controversial studies on the topic, and note a specific difficulty for distal transfers. Solomon et al [2.41] recall that the impact of many multidisciplinary journals is misleading in this respect, since their individual articles are not especially multidisciplinary.
Bibliometric operationalization has to account for those different multi/inter/transdisciplinarity forms. Multidisciplinarity involves sustained knowledge exchanges in a roughly stable structure; interdisciplinarity, with an organization and systematization nuance, supposes strong exchanges creating some structural strain, between domain overlap and autonomization of merging fractions; transdisciplinarity paves the way for the autonomy of the overlapping region, within the strong interpretation involvement of SSH and possibly of extrascientific considerations. Clearly model C is apter than A to depict those forms and their transitions when they occur, rather than waiting for the institutionalization of the emerging structures.
Interdisciplinarity may be outlined at the individual level by copublications of scholars with different educational or publication backgrounds, by measures of knowledge flows (citations), contents proximity, authors' coactivity or thematic mobility—if such data exist [2.42]. Other sources include joint programs, joint institutions or labs claiming disciplinary affiliation, generally found in metadata. Most disciplinary databases lagged behind the Garfield SCI model as to the integral mention of all authors' affiliations on an article. The large scope of bibliometric measures of multidisciplinarity was reviewed in many articles, e.g., [2.27, 2.43].
In model A the first entry point to multidisciplinary phenomena is the category classification schemes, with measures of knowledge exchanges by citation flows between categories (Pinski and Narin's seminal work on journal classifications [2.44], Rinia et al [2.45]), transposable to textual proximity (on patents [2.46]) or authors coactivity. Despite the heavy input of experts in science classification, the delimitation of particular fields varies across information providers and none can be held as a gold standard. It finds its limits in the inertia and often the hard scheme of classes, albeit the derived coclassification and coindex treatments noticed above relax the constraint and instil some of the bibliometric potential of model C.
Model C is more realistic in depicting the combinatory, flexible, multinetwork relationships in science and the demography of topics. Ignoring disciplinarity as such, it conveys a broader definition of interdisciplinarity, ranging from close to distant connections, the latter loosely interpretable, in the common acceptation, as interdisciplinary and possibly forerunners of more integrated relations. More generally, the network perspective of model C builds bridges between networks formalization and scientific communities life, leaving open the question of how profoundly the sociocognitive phenomena are captured. Data analysis methods such as correspondence analysis ( ), latent semantic analysis ( ), latent Dirichlet allocation ( ) addressed below, claim light semantic capabilities at least. Bibliometrics cannot substitute for sociological analysis, which exploits the same tools but goes further with specific surveys. Similarly, it is dependent on computational linguistics and semantic analysis for deep investigations of the knowledge contents. Model C is a potential competitor for offering taxonomies, with recent advances (Sect. 2.2.4). It does not follow that dynamics captured by this model are easy to handle: for example, flow variations in a fixed structure (A) read more conveniently than multifaceted structural change (C).
2.3.2 Internal Diversity
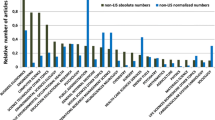
Diversity and multidisciplinarity are two facets of a coin. Internal diversity in a delineation process qualifies communities inside the target domain. Figure 2.2a-cb,c expresses the internal diversity of multidisciplinary domains , already striking for nanosciences and massive for proteomics (Fig. 2.2a-c).


Map of science and multidisciplinary projections . (a) A world-map-type science map from a spherical representation [2.47]. (b) and (c) Hotspots of activity of nanoscience and proteomics projected in a fraction of a global science map. It basically crosses the map's holistic picture with an overlay of hits from simple term queries. After Boyack and Klavans [2.48]
Internal diversity is treated in quite different ways depending on the model. In the cluster analysis part of model C, the balance of internal diversity and external connectivity (multidisciplinarity in the looser sense) is part of the mechanism which directly or indirectly rules the formation of groups, with a wide choice of protocols. Many solutions of density measurement are available in clustering or network analysis, with some connections with diversity measures developed in ecology and economics especially. The synthetic Rao index discussed by Stirling [2.49] combines three measures on forms/categories: variety (number of categories), balance (equality of category populations), and disparity (distance of categories). Delineation through mapping will use smaller scale clusters rather than attempting to capture the target as a whole large-scale cluster. There is no risk of missing large parts of the domain, but the way the different methods conduct the process raises questions about the homogeneity of clusters obtained and the loss of weak signals especially in hard clustering (Sect. 2.3).
In model B internal diversity, especially when generated by projected multidisciplinarity, is a threat on recall. Entire subareas may be missed out if the diversity in supervision (panels of experts) does not match the diversity of the domain. Unseen parts will alter the results. In contrast, on prerecognized areas, model B can be tuned to recover weak signals.
In model A, the existence of a systemic silence risk particularly depends on how interdisciplinary bridges are managed.
2.3.3 Unsettlement
The third challenge of domain delineation lies in the science network dynamics. Conventional model A classifications hardly follow evolutions and need periodic adjustments. The convenience of measures within a fixed structure is paid for by structural biases. Bibliometric mapping can translate evolutions in cluster or factor reconfiguration, but the handling of changes in a robust way remains delicate (Sect. 2.3). Model B pictures networks, but intuitively, a fast rhythm of reconfiguration in the somewhat chaotic universe of science networks makes it particularly difficult to settle delineation on firm roots. This casts a shadow on the time robustness of the solutions reached on one-shot exercises, but also on the predictive value of extrapolations on longitudinal trends. We will return later to dynamic studies and semantic characterization (Sect. 2.3.2). Emerging domains seldom embody institutional organization but bear bibliometric signatures of early activity. The difficulty is to capture weak signals with a reasonable immediacy. Fast manifestations of preferential attachment around novel publications, whatever the measure (citations, concept markers, or altmetric linkages) are amongst the classical alerts of topic emergence at small scale, to confirm by later local cluster growth.
2.3.4 Source Coverage
For memory's sake, the question of data coverage is recurrent in practical bibliometrics and is raised at the delineation stage of any study. The literature on the subject is abundant, conveying different points of view: Hicks [2.50] first stressed the limitations of both the reference database SCI and the mapping algorithm of cocitation for research policy purposes. Moed's review [2.51, esp. Sect. 6.2.2] and Van Raan et al [2.52] showed the differential coverage of disciplines by journals in SCI-WoS using references to nonsource items. Keeping pace with the growth of visible science is another challenge. The latest United Nations Educational, Scientific and Cultural Organization (UNESCO) science report estimates that \(\mathrm{7.8}\) million scientists worldwide publish \(\mathrm{1.3}\) million publications a year [2.53]. SCI-WoS producers proposed new products beginning to fill the gap of book literature, essential to social sciences and humanities (SSH) and conference proceedings, essential to computer science [2.54]. The coverage of social science and humanities with issues of publication practices and national biases was addressed in many works, e.g., [2.55, 2.56, 2.57]. This is distinct from the within-discipline approach where an extensive coverage causes instability of indicators due to tails (language biases, national journals biases), to document types or adaptation issues [2.58, 2.59, 2.60, 2.61]. Former studies' figures are outdated but the basic principles remain.
Extensive databases with enhanced coverage for IR purposes (modern WoS, Scopus) might require truncation of tails for comparative international studies. The PageRank selection tool limits the noise of a massive extension of sources in Google. However, Google Scholar is not considered a substitute for bibliographic databases for common librarian tasks, but rather a complement especially for coverage extension in long tails [2.62] with variations amongst disciplines. The same applies to another large bibliographic database: the Microsoft Academic Graph [2.63, 2.64, 2.65]. The lack of transparency in the inclusion process and the lack of tools beyond original ranking (sorting, subject filters) are stressed by Gray et al [2.66]. Strong concerns with the quality of bibliographic records were also reported [2.67, 2.68]. The coverage of databases has recently been compared by several authors [2.69, 2.70], with an extension to alternative sources such as altmetrics: http://mendeley.com, http://academia.edu, http://citeulike.org, http://researchgate.com, http://wikipedia.org, http://twitter.com, etc. [2.71, 2.72]. Online personal libraries like Mendeley shed new light on knowledge flows between disciplines through publication records stored together [2.73]—a kind of cocitation data from readers instead of authors. In addition, these sources, often difficult to qualify properly [2.74], have been addressed by altmetric studies [2.42, 2.75, 2.76]. The way scientists and the general public communicate about science on (social) media is field-dependent and it is not easy for now to anticipate the complementary role of altmetrics and traditional data in delineation of fields. Altmetric resources can help exploratory and supervision tasks.
In emerging and multidisciplinarity topics that typically justify careful delineation, controversies and conflicting interests are frequent and the importance of transdisciplinary problems makes the issues of sources coverage, experts panel selection, and supervision organization more acute.
2.4 Ready-Made Classifications
2.4.1 Classifications
Table 2.2 presents some types of science classifications valuable in domain delineation. These coexisting classification schemes reflect various perspectives, such as cognitive, administrative, organizational, and qualification-based rationales according to Daraio and Glänzel [2.77] who stress the difficulties arising when trying to harmonize them.
The first named classifications directly stem from professional expertise of scientists and librarians (pure model A). Some are linked to institutional or national research systems, mainly oriented towards staff management or evaluation, or international instances (UNESCO). More relevant for bibliometric uses are classifications within complete information systems on S&T literature, proceeding from a few sources: specialized academic societies ( (Chemical Abstracts Service), Inspec, Biosis, MathSciNet, Econlit, etc. which usually extend beyond their core discipline) and/or scientific publishers, and patent offices for technology. Classifications are typically hierarchical, complemented by metadata (keywords of various kinds, indexes from object nomenclatures: vegetable or chemical species, stellar objects, and so on).
Bibliometrics then entered the competition for science classifications, in contrast with the traditional documentation model involving heavy manpower for indexing individual documents. The prototype is Garfield's SCI/WoS based on the journal molecule and a selection tool, the impact factor [2.81, 2.82]. The supervision was still heavy in the elaboration of classification, although the journal citation report is a powerful auxiliary for actual bibliometric classification based on journals' citation exchanges [2.83]. The model of citation index inspired Elsevier's Scopus [2.84, 2.85]. The Google Scholar alternative, with a larger scope of less normalized sources, is the extreme case with very little supervision and does not include a classification scheme.
Following Narin's works, several journal classifications were developed (factor analysis in [2.86], core–periphery clustering in [2.87]). Many others have been proposed over the past decades, some with overlay facilities for positioning activities [2.88]. Other proposals use prior categories and expert judgments as seeds [2.89, 2.90], with reassignment of individual papers. Boyack and Klavans, whose experience covers mapping and clustering at several granularity levels (journals, papers) [2.91], recently reviewed seven journal-level classifications (Elsevier/Scopus (All Science Journal Classification), UCSD (University of California San Diego), Science-Metrix, (Australian Research Council), ECOOM (The Center for Research and Development Monitoring), (Web of Science), NSF, (Journal IDentification) and ten article-level classification (five from ISI and Center for Research Planning (CRP), four from MapOfScience, one from CWTS (Center for Science and Technology Studies)) [2.92]. The latter authors privilege the concentration of references in review articles (\(> {\mathrm{100}}\) references) considered as gold standard literature, as an accuracy measure (a heavy hypothesis). They conclude in favor of paper-level (versus journal-level approaches) and in favor of direct citations (versus cocitations or bibliographic coupling) for long-term smoothed taxonomies, distinguished from current literature analysis, for which they rank first bibliographic coupling.
Those developments mark a new turn in the competition between institutional classification and bibliometric approaches for long-term classifications of science. It is not clear, however, whether the variety of classifications from bibliometric research, not always publicly available, can supersede the quasistandards of SCI type for current use in bibliometric studies. High-quality delineation of fields cannot solely rely on journal-level granularity, and this is still more conspicuous for emerging and complex domains.
2.4.2 Semantic Resources
Science institutions and database producers have a continuous tradition of maintenance of linguistic and semantic resources, in relation to document indexing. The best known is probably the (Medical Subject Headings; National Library of Medicine) used in Medline/PubMed. INSPEC, CAS, and now Public Library of Science ( ) offer such resources. Controlled vocabulary and indexes, archetypal tools of traditional IR search were also the main support of new coword analysis in the 1980s. A revival of controlled vocabulary and linguistic resources is observed in recent works, associated to the description of scholarly documents [2.93] and bibliometric mapping [2.94]. We shall return to the role of statistical tools in the shaping of semantic resources.
2.5 Conclusion
Science, seen through scientific networks, is highly connected, including long-range links reflecting interdisciplinary relations of many kinds. Global maps of science, with the usual reservation on methods settings and artifacts, display a kind of continuity of clouds along preferential directions (Fig. 2.2a-cc, from [2.47]). The extension of domains has to be pragmatically limited by IR trade-off with the help, in the absence of ground truth, of more or less heavy supervision. Three models of delineation appear: ready-made delimitation in databases, rather limited and rigid as is, but prone to creative diversions from strict model A (coclassification, etc.); model B, ad hoc search strategies combining several types of information; model C, by extraction of the field from a more extended map, regional or global.
Networks of science may locally show cases of domains ideal for trivial delineation: a perfect correspondence between the target and ready-made categories, or insulated continents surrounded by sea. Such domains will not require sophisticated delineation. This is the exception not the rule.
Areas such as environmental studies, nanosciences, biomedicine, information and cognitive sciences and technologies (converging NBIC, concept coined by NSF in 2002) exhibit both internal diversity and strong multidisciplinary connections. Commissioned studies often target emerging and/or high-tech strategic domains which witness science in action prone to socioscientific controversies à la Latour. These areas combine high levels of instability and interdisciplinarity. As to transdisciplinarity, the question arises of whether to include SSH and alternative sources in data sources and panels of experts.
3 Tools: Information Retrieval (IR) and Bibliometrics
This section focuses on some technical approaches to the delineation problem: information retrieval and bibliometric mapping. They share the same basic objects and networks, chiefly actors and affiliations, publication supports, textual elements, and citation relations. Although the general principles of bibliometric relation studies are quite well established, new techniques from data analysis and network analysis, including fast graph clustering, open new avenues for achieving delineation tasks on big data at the fine-grained level. The quality of results remains an open issue. Domain delineation confronts or combines the three approaches previously stated: ready-made categories (model A) are seldom sufficient; we shall envision ad hoc IR search (model B) with an occasional complement of ready-made categories; and bibliometric processes of mapping/clustering along the lines of model C.
3.1 IR Term Search
The question of delineation spontaneously calls for a response in terms of information-retrieval search. The only particularity is the scale of the search or more exactly, as mentioned before, the diversity expected in large domains, which is particularly demanding for the a priori framework of information search . The verbal description of the domain requires, beforehand, an intellectual model of the area. In addition to the methodological background brought by IR models, a broad range of search techniques address delineation issues:
-
Ready-made solutions in the most favorable cases, with previously embodied expertise, sketched above.
-
Search strategies of various levels of complexity, also depending on the type of data, relying on expert's sayings.
-
Multistep protocols: Query expansion, combination with bibliometric mapping.
IR models are outside the scope of this chapter. In the tools section below, we recall some of the techniques shared by IR and bibliometrics, especially the vector-space-derived models.
3.1.1 IR Tradeoff at the Mesolevel
The recall–precision trade-off is particularly difficult to reach at the mesolevel of domains exhibiting high diversity. Generic terms (say the nano prefix if we wish to target nanosciences and technology) present an obvious risk to precision. A collection of narrower queries (such as self-assembly, quantum dots, etc.) is expected to achieve much better precision. In the simpler Boolean model, this will privilege the union operator of subarea descriptors (examples for nanoscience [2.33, 2.95, 2.96]). However, nothing guarantees a goodness of coverage of the whole area by this bottom-up process. An a priori supervision of the process by a panel of experts is required, but the experts' specialization bias, especially in diverse and controversial areas, generates a risk of silence. Similar risks are met in the selection of training sets in learning processes. Another shortcoming is the time-consuming nature of supervision, again worsened by the diversity and multidisciplinarity of the domain. A light mapping stage beforehand may reduce the risk of missing subareas. As mentioned above, focused IR searches are, in contrast, able to retrieve weak signals lost in hard clustering.
3.1.2 Polyrepresentation and Pragmatism
Scientific texts contain rich information, most of it made searchable in the digital era. Pragmatically, all searchable parts of a bibliographic record, data or metadata are candidates for delineating domains: word \(n\)-grams in titles, abstracts, and full texts; authors, affiliations, date, journal or book, citations, acknowledgements, transformed data (classification codes, index, controlled vocabulary, related papers…) depending on the database. These various elements exhibit quite different properties. In theoretical terms, the variety of networks associated to these elements are one aspect of the polyrepresentation of scientific literature [2.97]. We will return to this question later (Sect. 2.3.2). A specific advantage of lexical search is the easy understanding of queries—whereas other elements (aggregated elements such as journals; citations) are more indirect. However, the ambiguity of natural language reduces this advantage.
Bibliometric literature is packed with examples of pragmatic delineation of domains based on IR search. By and large, apart from ready-made schemes when available (indexes, classification codes), a typical exploration combines a search for specialized journals if any, and a lexical search in complement. At times, an author-affiliation entry is used, especially in connection with citation data. Bradford and Lotka ranked lists are therefore good auxiliaries, with evident precautions on journals' or authors' degree of specialization .
3.1.3 Granularity
We noted above that some ready-made classifications such as the SCI scheme (journals or journal issues) are essentially based on full journals—or journal sections. These ready-made categories very seldom fit the needs of targeted studies. Instead, ad hoc groupings of selected journals relatively easy to set up with the help of experts, are a convenient starting point within a Bradfordian logic. The journal level presents obvious advantages. Journals exhibit a relative stability in the medium term; they are institutionalized centers of power through gatekeeping, and a (controversial) evaluation entity in the impact factor tradition.
However, the journal level is problematic for delineation studies. Journals whose specialization is such that they indisputably belong to the target domain, can be taken as a whole, but of course target domain literature are rarely covered by specialized journals only, and investigations should be extended to moderately or heavily multidisciplinary sources. Conditions of diversity and multidisciplinarity—which prevail in the targets of studies where elaborate delineation is worthwhile—hinders the efficiency of global Bradford/Lotka-based selections, with problems of normalization (refer also to [2.98]). We will return to these issues in the Sect. 2.3.2 devoted to clustering and mapping.
To conclude, the IR resources in scientific texts, data and metadata, suggest a polyrepresentation of scientific information (cognitive model [2.97]), which is akin to the multinetwork representation of the scientific universe. Ingwersen and Järvelin [2.99, p. 19] propose a typology of IR models and the perspective of the cognitive actor. IR protocols generally involve multistep approaches, with various core–periphery schemes. In conventional search, heavy ex ante supervision is needed for covering the variety of domains, ideally with good analytic/semantic capability. In the absence of a gold standard, proxy measures of relevance are needed.
3.1.4 Multistep Process
Multistep processes, possibly associated with combinations of various bibliometric attributes, are run-of-the-mill procedures (for example [2.32]).
Core–periphery rationale is common, in accordance with the selective power of concentration laws, both in IR and bibliometrics (journal cores in [2.100], cocitation cores in [2.101], \(h\)-core in [2.102], emerging topics in [2.103]). For example, working on highly cited objects—authors, journals, or articles—gives a set of reasonable size, amenable to further expansion with enhanced recall. Cores inspired from the Price law on Lotka distributions or from application of the \(h\)-index are helpful. Proxies such as seeds obtained from initial high-precision search stages can do as well. The core or seed expansion process is global or cluster-based. The risk of core–periphery schemes, by and large favorable to robustness, is to miss lateral or emerging signals. This may need some input of dynamic characterization of hotspots at the fine granularity level.
A parent method is bibliometric expansion on citations, which also uses information from a first run (set of documents retrieved by a search formula or a prior top cited selection, considered as the core) to enhance the recall through the citation connections, typically operating at the document level with or without a clustering/mapping step. In this line the Lex\(+\)Cite approach mentioned in Sect. 2.3 relies on a default global expansion, rather than a cluster-based one, to limit the risk of an exclusive focus on cluster-level signals that would miss across-network bridges.
Query expansion by adaptive search is along the same lines. Interactive retrieval with relevance feedback identifies the terms, isolated or associated (co-occurrences), specifically present in the most relevant documents retrieved according to various measures [2.104, 2.105, 2.106]. An efficient but heavy process consists in submitting the output of a search stage to data analysis/topic modeling , able to reconstruct the probable structure likely to have generated the data. By providing information on the linguistic context—also citation, authoring context, etc.—they in turn help to improve the search formulas by a kind of retro-querying. This ranges from simple synonym detection to construction of topics, orthogonal or not, suggesting the rephrasing of queries. Variants of itemset mining uncovering association rules ([2.107], with earlier forerunners) are promising in this respect (see below). Evaluation of output from unsupervised stages can also call for a manual improvement of queries.
Delineation protocols may also use the seed as a training set for learning algorithms. A difference is that core–periphery schemes usually rely on the selective power of bibliometric laws, whereas the training set might be extracted on various sampling methods, provided that the seed does not miss the variety of the target. As big data grows bigger, semisupervised approaches are gaining popularity in the machine learning community. This recent approach should prove attractive in the bibliometrics community, as there seems to be considerable interest in linking metadata groups and algorithmically defined communities [2.108].
To conclude on this part, whilst typical IR search relies on an a priori understanding of the field, multistep schemes involve stages of data analyses quite close to bibliometric mapping practices, the topic of the next subsection. IR and bibliometrics share roots and features, which soften the differences: adaptive loops, learning processes, seed-expansion, and core–periphery schemes. Bibliographic coupling, at the very origin of bibliometric mapping, came from the IR community [2.109] and the cluster hypothesis about relevant versus nonrelevant documents [2.110] voices the common interests of IR and bibliometrics, beyond the background methodology of information models (Boolean, vector space, or probabilistic) and general frameworks such as the above-mentioned cognitive model. The tightening of bibliometrics–IR relations has been echoed in a series of workshops and in dedicated issues of Scientometrics ([2.111, 2.112], see also [2.113] for a focus on domain delineation) and in the International Journal on Digital Libraries [2.114].
3.2 Clustering and Mapping
In contrast with conventional IR search, bibliometric mapping starts at a larger extension level than the targeted domain. This broad landscape, typically built by unsupervised methods, is scrutinized by experts to rule out irrelevant areas. The supervision task is limited to the postmapping stage. This is in principle less demanding than the a priori conception of a search formulation or of a training set. The default solution is a zoomable general or regional map of science, with availability and cost constraints. The alternative is the construction of a limited overset including almost certainly the anticipated domain, using a general search set for massive recall, an operation much lighter than setting up a precise search formula. In terms of scale, the final result is tantamount to the outcome of a top-down elimination process, although the selection modalities are diverse. There is currently great interest in delineation through mapping. IR and mapping are complementary in various ways. Firstly, we briefly describe the data analysis toolbox, before addressing the main bibliometric applications and a few problematic points.
3.2.1 Background Toolbox
The data structure of matrices in the standard bibliometric model allows scholars to mobilize the large scope of automatic clustering, factor/postfactor methods, and graph analysis. Classical methods of clustering and factor analysis continue to be used in bibliometrics, but in the last decade(s) novel methods came of age, more computer-efficient and fit for big data, an advantage for mapping science and delineating large domains. Starting with bibliometric data of the standard model and some metrics of proximity or distances, clustering and community detection methods produce groups. Elements are mapped using various dimension reduction algorithms. Factor methods produce groups through clustering applied to factor loadings, with an integrated two-dimensional (2-D) or three-dimensional (3-D) display when just two or three factors are needed in the analysis.
A major driving force of bibliometric methodology is the general network theory, which took large networks of science, especially collaboration and citation, as iconic objects [2.115, 2.116, 2.117]. Quite a few mechanisms have been proposed to explain or generate scale-free networks since Price's cumulative advantage model for citations [2.118] along the lines of Yule and Simon, and later studied in new terms (preferential attachment) by Albert and Barabási [2.119], see also [2.120]. These models have some common features with the Watts–Strogatz small worlds model, but also differences that are empirically testable [2.121]. Amongst other mechanisms: homophily [2.122], geographic proximity [2.123], thematic proximity inferred from linguistic or citation proximity. Börner et al reviewed a few issues in science dynamics modeling [2.124]. Of great interest in bibliometrics and especially delineation, community detection algorithms exhibit a general validity beyond real social networks, and belong to the general toolbox of mathematical clustering and graph theory—applicable to various markers of scientific activity, document citations, words, altmetric networks, etc., see also [2.120].
Hundreds of clustering and mapping methods have been designed during one century of uninterrupted research. This section can only provide a basic overview of the main method families, in the perspective of domain delineation. More comprehensive descriptions and references, as well as a basic benchmark of various methods, applied to a sample of textual data, can be found in [2.125].
3.2.1.1 Clustering Methods
Although hierarchical clustering algorithms sometimes seem old-fashioned because of their computing complexity, \(O(n^{2})\) in the very best cases, some of them show good performances for relative small universes. For large ones, they can be coupled beforehand to data-reduction stages, classical (SAS Fastclus \(O(n)\)), preclustering algorithms for big data (Canopy clustering [2.126]), or sampling methods. All-science bibliometric maps use rather faster algorithms today, not without limitations however. Discipline-level maps, or simply internal clustering of the domain set at various stages of delineation may still rely on the classical techniques.
Hierarchical ascending algorithms are local, deterministic and produce hard clusters, with a few exceptions (pyramidal classification), properties favorable to dynamic representations. They do not constrain the number of clusters and provide a multiscale view through embedded partitions, with some indication of robustness of forms in scale changes. Most hierarchical descending (divisive) methods are heavier. Hierarchical methods typically rely on ultrametrics, which has downsides, see [2.125].
Amongst popular methods in bibliometrics are ascending methods: single linkage, average linkage, and Ward. Single linkage is relatively fast and exhibits good mathematical properties in relation to spanning trees but produces disastrous chain effects which must be limited in various ways. Ward and especially group average linkage give better results. Group average linkage, advocated for bibliometric sets by Zitt and Bassecoulard [2.127] and used by Boyack and Klavans in various works [2.128], is slightly biased towards equal variance and is not too sensitive to outliers. Ward is biased towards equal size with a strong sensitivity to outliers. Properties and biases were studied especially by Milligan [2.129, 2.130] using Monte Carlo techniques.
Density methods are appealing: deterministic too, local, and as such prone to dynamic representations of publication or citation flows. [2.131] (density-based spatial clustering of applications with noise) is the most popular to the point of becoming synonymous with density clustering. The SAS clustering toolbox includes hierarchical methods with prior density estimation, with good properties towards sampling and the ability to capture elongated or irregular classes. However, this property is disputable in bibliometric uses (Sect. 2.3.2, Shape/Properties of Clusters). More recently, density peaks [2.132] has implemented an original and graphical semiautomatic procedure for determining the cluster seeds.
Not directly hierarchical is the venerable \(K\)-means clustering family, still popular, thanks both to its excellent time/memory performance and sensitivity to different cluster densities. A shortcoming of not being deterministic, they converge to local optima of their objective function, depending on their random (or supervised) initialization. In comparative analyses, they are not considered too sensitive to outliers. They optionally allow for soft/fuzzy clusters, and approximate dynamic data-flow analysis.
Factor methods are basically dimension-reduction techniques, indirectly linked to the partition problem. A quick-and-dirty heuristics for extracting a limited number \(k\) of dominant clusters from \(k\) factors consists of assigning each entity to the factor axis which maximizes the mode of its projection, subject to the constraint of a common factor sign for the majority of entities assigned to this cluster—which eliminates few of them in practice. For a more rigorous procedure, see the descending hierarchical clustering method Alceste [2.133] in the dataspace of correspondence analysis. Factor methods rely on the mathematical foundation of singular value decomposition ( ) of data matrices for reducing dimensionality and filtering noise. The interesting metrics used by correspondence analysis ( [2.134]) explains the attention over half a century from many scholars in relation to mapping or clustering limited to a few dominant factor dimensions. Dropping this limit, i. e., taking into account factor spaces with hundreds of dimensions [2.135], latent semantic analysis (LSA [2.136]) unleashed the potential of singular value decomposition and fostered the integration of semantics in textual applications, in a lighter but more convenient form than handmade ontologies, costly to edit and update.
Hybrid factor/clustering methods, sometimes coined topic models , result in representing each cluster as a local, oblique factor, with a progressive scale from core elements to peripheral ones, opened to fuzzy or overlapping interpretations or extensions. Generally powered by the expectation maximization algorithm ( ), they converge to local optima, too. Non-negative matrix factorization ( ) and self-organizing maps ( ) are well-known examples. Axial \(k\)-means ( in [2.137]) has been used in a comparative citations/words bibliometric context (Sect. 2.4).
Also known as topic models, the probabilistic models try to lay solid statistical foundations for their hybrid-looking representation: they produce explicit generative probabilistic models for the utterance of topics and terms [2.138]. Probabilistic LSA (pLSA in [2.139]) and latent Dirichlet allocation ( in [2.140]) are the best-known examples, claiming good semantic capabilities. The older fuzzy C-means method ( ) is akin to this family, which uses the EM scheme for converging to local optima of their objective function.
The graph clustering family, also known as network analysis, or community detection methods, does not operate on the raw (entities \(\times\) descriptors) matrix, as the previous families do, but on the square (entities \(\times\) entities) similarity matrix, whose visual counterpart is a graph. Most of these methods operate directly on the graph, detecting cliques or relaxed cliques (modal classification), e.g., Louvain [2.141], InfoMap [2.142], and smart local moving algorithm ( in [2.143]). Some of them operate on the reduced Laplacian space drawn from the graph (spectral clustering [2.144]). Quite a few comparative studies are available [2.145, 2.146, 2.147].
3.2.1.2 Note on Deep Neural Networks
While neural networks were somewhat in standby mode during the 1995–2005 decade, challenged by more manageable mathematical methods, several factors like the pressure of big data availability and progress in hardware ( , i. e., graphics processing units) triggered a renewal under the banners deep neural nets and deep learning. Allowing learning by backpropagation of errors in many layers networks, they gave form to the dream of knowledge acquisition by growing levels of abstraction: for images, extraction of local features; contours, homogeneous areas, shapes; for written language: character \(n\)-grams, words, word \(n\)-grams, expressions/phrases, sentences. Typically, they avoid heavy natural language processing ( ) preprocessing (parsing, unification, weighting, selection…). These techniques are already widely used in supervised learning, with spectacular progress in automatic translation, face recognition, listening/oral comprehension, with important investment from the largest internet-related companies (e.g., Google, Apple, Facebook, Amazon), especially. As far as informetrics and IR are concerned, the main domain impacted so far is logically large-scale retrieval ([2.148] which uses a robust letter-trigram-based word-\(n\)-gram representation). There have also been some attempts in relation to nonsupervised processes for information retrieval [2.149].
A promising technique is neural word embeddings ( ). Millions of texts now available online make it possible to develop vector representations of words in a semantic space in a more elaborate way than LSA—a method coined neural word embeddings. For example, the Word2Vec algorithm [2.150] processes raw texts so as to list billions of words-in-context occurrences (e.g., word \(+\) previous word \(+\) next word), then factorize [2.151] the word \(\times\) context matrix (tens of thousands of words, a few hundreds of thousands, or millions of unique contexts) and extract some hundreds or thousands of semantic and syntactic dimensions. We will return later to the semantic capabilities of NWE.
3.2.1.2.1 Note on the Definition of Distances
Whether starting from a binary presence/absence matrix or from occurrence or co-occurrence counts, some methods embed a specific weighting scheme, i. e., a metric, for computing distances, or similarities between items. This is the case of probabilistic models, correspondence analysis, and axial \(K\)-means. Other methods allow for a limited and controlled choice, as aggregative hierarchical methods do. In the case of graph clustering methods, the user may freely choose his preferential distance definition prior to building the adjacency matrix, which adds an extra degree of freedom beyond the choice of the degree of nonlinearity, via a threshold value. For word-based matrices, heavier than citation-based ones, the methods of the \(k\)-means family also make it possible to choose a weighting scheme (Salton's term frequency-inverse document frequency (TF-IDF ), Okapi BestMatch25 [2.152]).
Whereas factor/SVD methods combine the metrics and mapping capability, e.g., two-factor planes or 3-D displays, at the native granularity level (e.g., document \(\times\) words), other mapping algorithms may operate on rectangular or on square (distance) matrices of elements or on groups from a clustering stage, or institutional aggregates (journals). Families of mapping techniques rely on various principles: equilibrium between antagonistic forces—repulsion between nodes, attraction alongside edges (e.g., the Fruchterman and Reingold algorithm [2.153], implemented in Gephi [2.154], alone or combined with clustering (Sandia VxOrd/DrL/OpenOrd [2.155], CWTS VOSviewer [2.143])); optimization of diverse functions: projection stress minimization in the case of (multidimensional scaling), with Euclidean distances in the case of metric MDS, a variant of (principal component analysis), and other distances or nonlinear functions of these distances in the case of nonmetric MDS, one of the nonlinear unfolding techniques; maximizing inertia in the case of Correspondence analysis, minimizing edge-cuts in a 2-D projection plane; or maximizing local edge densities [2.156].
3.2.1.2.2 Itemset Techniques
Itemset techniques are used for describing a data universe in terms of simple procedures, typically Boolean queries with AND, OR, and NOT operators. This may be used for building a stable procedural equivalent of data, e.g., for updating a delineation task (like probabilistic factor analyses). It may also be used for query expansion, as mentioned above in Sect. 2.3.1. The problem amounts to duplicating a reference partition in a new universe: machine learning techniques are basically fit to this problem, and, in the particular context of textual descriptions, itemset techniques. They are akin to generating Boolean queries with AND, OR, and NOT operators, for extracting approximations of the delineated domain, within precision and recall limits established in the machine learning phase [2.107, 2.157].
3.2.1.3 A Benchmark
To illustrate the capabilities of these various methods with an example, in the absence of a bibliometric dataset labeled with indisputable ground truth classes, we turned towards a reference dataset popular in the machine learning community, the Reuters 21 578 ModApté split (the corpus description is available online at http://www.daviddlewis.com/resources/testcollections/rcv1/. The website http://www.cad.zju.edu.cn/home/dengcai/Data/TextData.html has made a preprocessed version of this corpus available to the public, as supplementary material to [2.158]). The main features are:
-
Source: A set of short texts: newswires from Reuters' press.
-
Contents: In the six-class selection used, the number of texts (\(\approx{\mathrm{7000}}\)) and terms (\(\approx{\mathrm{4000}}\)) is sufficient with regards to text statistics.
-
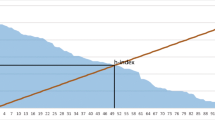
Class structure considered as ground truth: Built by experts, visually glaring in Fig. 2.3: two big classes, one very dense, the other not, and four small classes, two of which are linked together. In this way, two major problems of real-life datasets are addressed: the imbalance between cluster sizes, and between cluster densities.


Benchmark structure (ground truth). Spy plot of the cosines between document vectors of the top six classes Reuters ModApté split collection. The rows and column ordering is that of the six Reuters classes. Black pixels mean: cosine \(> {\mathrm{0.5}}\)
We challenge 17 clustering/mapping methods to retrieve this class structure. The similarity of their cluster solution to ground truth partition is measured by two indicators, adjusted Rand index ( [2.159]) and normalized mutual information ( [2.160]). The results are detailed in [2.125]. Let us summarize them in a user-oriented view, sorted by number of required parameters: the lesser the better, ideally, facing a bibliometric dataset without prior knowledge, no parameter:
-
Two methods of network analysis require no internal parameterization, Louvain and InfoMap. However, the similarity matrix generally requires a threshold setting, here fixed to \(\mathrm{0.1}\) in the cosine intertext similarity matrix. Infomap obtains the best result in terms of NMI (\(\mathrm{0.436}\) value versus \(\mathrm{0.423}\)), the index considered the best match for human comparison criteria. This value is rather poor, and this method does not distinguish classes 1, 2, 3, 4, and splits class 6.
-
Nine methods require one parameter: The three hierarchical clusterings need a level cut parameter, possibly adjusted for 6 resulting clusters, while for CA, NMF, AKM, (probabilistic latent semantic analysis), LDA and spectral clustering, the number of desired clusters (6) has to be specified. As the latter group converges to local optima, we kept the best results in terms of their own objective function out of 20 runs. The indisputable winner is average link clustering, in both ARI (\(\mathrm{0.62}\)) and NMI (\(\mathrm{0.71}\)) terms. The lists of the four following challengers are contrasted: with regard to ARI, first Mac Quitty hierarchical clustering (\(\mathrm{0.50}\)), then LDA, AKM, CA; with regard to NMI, first AKM (\(\mathrm{0.51}\)), then Mac Quitty, CA, LDA. If one optimizes ARI over all 20 runs with prior knowledge of the six-clusters structure—a heroic hypothesis—, average link clustering still performs best (with a ten-clusters cut, ARI \(={\mathrm{0.71}}\), NMI \(={\mathrm{0.64}}\)) while the followers reach, at best, ARI \(={\mathrm{0.55}}\) and NMI \(={\mathrm{0.55}}\).
-
The last group of methods ( (independent component analysis), DBSCAN, FCM, affinity propagation, SLMA, density peaks) require at least two parameters, a handicap in the absence of prior knowledge of the corpus structure. SLMA obtains the best rating (ARI \(={\mathrm{0.60}}\), NMI \(={\mathrm{0.55}}\)).
Our general conclusion is that one must be very cautious regarding domain delineation resulting from one run of one method. Multiple samplings, if necessary, and level cuts of average links as well as multiple runs of LDA, AKM, and SLMA may help determine core clusters, and possibly continuous gateways between them. Limitations of this benchmark exercise should be kept in mind. It would benefit from tests on different reference datasets: any method can be trapped in particular data structures, and the results cannot be extrapolated without caution. As advocated below, processing multiple sources (lexical, citations, authors …) and investigating the analogies and differences in their results will always prove rewarding. A number of in-depth benchmarking studies are found for hierarchical clustering (Milligan [2.129, 2.130] not covering the last techniques), discussing the generation of test data as well as comparisons of algorithms. For community detection, usually taken as a synonym of graph-based clustering rather than clustering of true social (actors) communities, [2.145] ranked first Infomap, then Louvain and Pott's model approach [2.161]. Leskovec et al [2.146] studied the behavior of algorithms with increasing graph size. Yang and Leskovek [2.147] reflect on the principles of clustering outcomes compared to institutional classifications.
3.2.2 Bibliometric Mapping
3.2.2.1 Classical Way
Most classical bibliometric mapping, as well as information retrieval, relies on substantive (feature) representations of words, word combinations, citation, indexes, and so forth. Substantive representation implies legibility and interpretation by experts or users, and a condition for bibliometricians or sociologists to check and possibly deconstruct the document linkages. It contrasts with featureless machine representation applicable for example to distances of texts (see below). In contrast, the substantive approach is deepened in semantic studies: ontologies and semantic networks suppose more elaborate investigation of term relationships. Bibliometric mapping and IR techniques are both a client of ready-made semantic resources, and providers of studies, supported by data analyses, likely to help the construction of thesauri and ontologies.
The standard bibliometric model starts from the data structure of articles, essentially a series of basic article \(\times\) attributes matrices, one of these reflexive: article \(\times\) cited references, where references can also stand as attributes. The derived article \(\times\) article matrices (e.g., bibliographic coupling, lexical coupling) and elements \(\times\) elements matrices (e.g., coword or profiles, cocitation or profiles) cover a wide range of needs. Clusters of words are candidates for conceptual representation, concepts which in turn can index the documents. Likewise, clustering of cited articles reveal intellectual structures and in turn index the citing universe. Basically, the attributes (words from title, abstract, full text; keywords list, indexes—other fields like authoring) are processed in bags of monoterms or multiterms, recognized expressions or word \(n\)-grams. Standard bibliometric treatments rarely go further, semantic studies do, for example by using chain modeling of the texts. All these forms allow for control and interpretation of linguistic information.
Assuming that the final purpose is to classify or delineate literature, the access is dual: direct classification of articles after their profile on the structuring elements (words, cited references), or a detour by the structuring items: word profile (especially coword), citation profile (cocitation), index (or class profile) including coclassification, when applicable. The basics of citation-based mapping were established in the 1960s and the 1970s: bibliographic coupling [2.109], chained citations [2.162], cocitation [2.101, 2.163], author cocitation [2.164], coclassification, etc. The lexical counterpart, with its first technical foundations in Salton's pioneer works [2.165], was reinvested by English and French social constructivism in the 1980s [2.166, 2.167, 2.168] with a stress on local network measures quite in line with the development of social network analysis in that period [2.169]. In bibliometrics, the true metric approach of text-based classification, Benzécri's correspondence analysis [2.134], remained confidential. For convenience reasons, many large-scale classifications relied on proximity indexes and MDS or hierarchical single-linkage (ISI cocitation). We return later to word–citation comparison and combination (Sect. 2.4).
3.2.2.2 Developments
The principles above, mutatis mutandis, are kept in further developments of citation mapping: the approach through citation exchanges, mentioned in Sect. 2.2, assumes predefined entities, journals for example. At the article level, symmetrical linkages between articles, or between structuring elements, are classical: large-scale cocitation (CiteSpace [2.170]). Glänzel and Czerwon [2.171] advocated bibliographic coupling. As already mentioned, direct citation linkage clustering, the first benchmark for cocitation and coupling in Small's princeps paper [2.101], is considered as particularly able to reflect long-period phenomena [2.172, 2.173, 2.92] but not short-term evolutions. It turns out that the time range picked and the granularity of groupings desired might suggest the choice between the three families of citation methods to reflect structure and changes in science.
From the theoretical point of view, cocitation (respectively coword) is semantically superior to coupling, by visualizing the structure of the intellectual (cognitive) base, but requires a secondary assignment of current citing literature. Coupling as such, because it by default spares the dual analysis (the cited structure; the lexical content), is semantically poor but bibliographic coupling handles immediacy better than cocitation does. However, this depends on the computer constraints and the settings: the thresholding unavoidable in cocitation analysis drastically reduces weak signals that are accounted for in coupling. The dependence of the maximum retrieval on the threshold of citation and the assignment strength (number of references), in a close field, is modeled in [2.59]. Quite a few authors compared the methods empirically [2.128] over a short time range, [2.173, 2.174]. These studies are not always themselves comparable in their criteria, nor are they convergent in their outcome, so that it is difficult to come to a conclusion on this basis alone.
The new data analysis toolbox (fast graph unfolding, topic modeling) gradually pervades large-scale studies. From the domain delineation perspective, a general answer in terms of single best cannot be expected. The benchmark above reminds us that classical methods, apparently outdated in the big data era, still prove to perform quite well. Let us recall a few issues in clustering/mapping for bibliometric purposes, especially delineation.
3.2.3 A few Clustering/Mapping Issues
As other decision-support tools, maps in bibliometrics receive contrasted interpretations. In a social constructivist view, maps are mainly viewed as tools of stimulation of sociocognitive analysis and also as supports of negotiation with/amongst actors. If technicalities are not privileged, there is clear preference for local network maps, preferably lexical or actors-based, connected to sociocognitive thinking. Bibliometricians and librarians are keener on quantitative properties and retrieval performances. Expectations as to ergonomics, granularity, robustness, clusters properties, and semantic depth, largely vary depending on the type of study.
3.2.3.1 Ergonomics
Map usage benefits from new displays with interaction facilities. A tremendous variety of mapping methods is available ([2.175] although in practice a few efficient solutions prevail). The progress in interfaces (scale zooms, bridges between attributes, interaction with users…) changed the landscape of mapping. If adding cluster features to cluster maps is trivial [2.176], the systematization of overlay maps by Leydesdorff and Rafols [2.177] is quite appealing. Since delineation tasks often deal with multidisciplinarity, multiassignments, and cluster expansion, various types of cross-representations (Sect. 2.4) including overlay maps are quite convenient tools for discussion.
3.2.3.2 Granularity
The granularity considered here is the smallest unit handled. Progress of data analysis allows large-scale work with a fine granularity. Document-level maps are now regularly proposed by Boyack and Klavans [2.91]. The classical alternative in bibliometrics uses the journal molecule instead of publications, with the advantages and shortcomings already discussed. Delineation tasks used to be conducted at the journal level and this convenient solution can be somewhat improved using a core–periphery scheme with multidisciplinary qualification [2.178]. The interest of journal granularity for delineation remains dependent on the specialization profile at the scale considered, so is quite field-dependent. The best fit to the journal approach is found in fields with a strong editorial focus, such as Astrophysics, but [2.179] recalls that the general rule is the superiority of document granularity. At the global science level, journals or even journal categories are an option for sketching great regions [2.177], with low precision ambitions. In favor of journals, their persistence as institutional entities with slow demography, facilitates longitudinal approaches, again at the expense of precision (Sect. 2.3.2, Dynamic Clustering). Granularity does not reduce to the question of journals versus document level. It can also suggest methodological choices, e.g., the family of citation method to select, depending on the objective, taxonomies of disciplines or finer level research fronts in a broad sense.
3.2.3.3 Shape/Properties of Clusters
Ex post supervision of clusters (built by unsupervised methods) is a critical stage of studies. Discussion on the cluster aggregate features, or sampled articles, is much easier if clusters are reasonably homogenous. Therefore, the ability to recover clusters of any shape (elongated, nonconvex…), which is essential in other contexts (say image analysis), may not be desirable in bibliometric mapping. A few strongly linked compact clusters is easier to assess than the equivalent elongated class. The skewness of cluster distribution is another concern, especially in citation clustering, and the inflation of microclusters with poor connections is inconvenient—an argument voiced in favor of a direct citation approach for high-level taxonomies. From this point of view, the slight tendency of average linkage towards homogeneity and the tendency of \(k\)-means towards size balance, giving a moderately skewed distribution of cluster size, may be seen as desirable biases (refer to [2.146] in the context of community detection) with respect to further cluster supervision. As the benchmark exercise has shown, this does not prevent average linkage from recovering heterogeneous structures.
3.2.3.3.1 Soft Versus Hard Clusters
For reasons of convenience and computer efficiency, hard clustering is widespread but remains a violent approximation of the complexity and intrication of community networks and semantic relations in scientific literature. Hard clustering is sometimes the first stage of a two-stage classification: Cocitation analysis usually combines hard clustering for cores in the cited universe, and assignment of the citing literature is tantamount to soft clustering of research fronts. Reciprocally, starting from hard bibliographic coupling clusters makes it possible to generate a soft image of cited clusters. The conditions of assignment parameters in the second stage determine the degree of overlap. This is true also for factor analyses more suitable for overlapping entities, especially with oblique factors, i. e., principal axes of clusters upon which any entity, in or out, has a projection. The query expansion or bibliometric expansion practiced at the cluster level also builds soft clusters from an existing hard partition on the same data, therefore enhancing the recall at the cluster level. More generally, the wide development of probabilistic clustering is consistent with fuzzy approaches of assignment of particular articles/items.
Multilevel visualization of partitions is valuable for discussing topic or domain borders, especially when obtained from techniques which do not favor cluster homogeneity, or exploring strongly multidisciplinary phenomena. For example, assuming a strong proximity of two topics A and B, it is interesting to know whether this proximity is localized—say to subclusters A1 and B1—or distributed. Local intense linkages may prefigure capture of a subcomponent or merge A1–B1. Such interpretation only makes sense with robust methodology.
In a cluster selection process for delineation, all things being equal, soft or fuzzy clusters are allowed to extend towards shared areas, and then slanted towards recall at the cluster level. This applies to the boundary clusters, with an effect on a domain's delineation. However, bibliometric use of soft clustering remains limited and does not usually depart from the holistic perspective (Sect. 2.3.2, Semantics, Statistics, Informatics).
3.2.3.4 Robustness and Evaluation Issues
Robustness is an essential aspect of data analysis applied to bibliometrics. Sensitivity to data issues, to the type of network, to metrics and clustering algorithms, lead to rather different solutions. Ground truth or even gold standards are generally unavailable. In empirical studies, analysts have to get along both with biased representation of panels and divergences of techniques, as well as sensitivity to settings within one technique. We already mentioned general problems of bibliometric data, especially coverage. Within a given data corpus, the skewness of informetric distributions is a powerful foundation of robustness, but many sources of instability remain. The particular question of time robustness is sketched later.
3.2.3.4.1 Sensitivity to the Network Weighting and Metrics
For memory's sake, some prior transformation of bibliometric networks is practised to compensate across-domain differences, such as citing behavior. In such case, the value of linkages are weighted by a function of the number of inlinks of given groups (tantamount to classical cited-side normalization) or the number of outlinks. The latter is present both in influence measures (Pinski and Narin [2.44], revival in the last decade [2.180]) and the limit case of citing-side normalization which presents original properties [2.181, 2.182]. Citing-side normalization of the citation network is a limit case (removing iteration) of Pinski and Narin influence weights [2.44]. It is strictly classification-free if the basic normalization unit is the paper or the journal [2.181]. It exhibits interesting properties for any basic unit making sense, e.g., domains: the dispersion of domains' impacts calculated this way with normalization at the domain level is a measure of interdisciplinarity of science in a steady state system [2.183].
A major native characteristic of bibliometric networks is the skewness of node degree distribution and resulting polarization: citations, Zipf–Mandelbrot word usage, Bradford concentration—in connection with concentration generating models recalled above in social network theory. Concentration gives tremendous selective power and at the same time, calls for corrections in IR context for information retrieval and usage, depending on the context. A vast choice of metrics or quasimetrics (similarity indexes) is available, introducing weightings with some inverse function of frequency, especially useful in a mapping context. It is common knowledge that various similarity indexes produce contrasted perspectives. Coword analysis pioneers, notably, compared the unweighted index (raw), the asymmetrical (inclusion) index, the partially weighted index (Jaccard, Ochiai among others), the strongly weighted index (\(p\)-index or affinity amenable to a similarity). After thresholding, the landscape of the transformed networks is quite different: the first two indexes tend to keep the frequent items as hubs, the last one highlights infrequent words and associations at some risk of overexposure of rare forms, amongst them typing errors.
Analogous normalizations, from the abundant repertoire of similarity indexes, are frequent for cocitation [2.184] and coauthorship analysis [2.185, 2.186]. Clustering algorithms build on the final network in various ways. Obviously, any delineation based on such weighted networks of structuring elements—where skew distribution is the rule—will be quite sensitive to methodology. In bibliometrics, the contrast is extreme between steep landscapes generated by raw measures, dominated by the centrality of hubs, and information-driven strongly corrected configurations, at the risk of instability and errors on very low frequencies. Intermediary options are often picked, for example Ochiai–Salton and Jaccard measure. Document coupling relations, similarly, depend on the normalization of term frequency, typically inverse frequency weighting, Hellinger, etc. built-in or not in data analysis methods (TF-IDF, \(\chi^{2}\) in correspondence analysis, etc.).
3.2.3.4.2 Asymmetrical Relations
Specific to citations, a complete model of citation exchanges requires some native or constructed aggregation with relatively stable entities (authors, journals, pre-existing categories, etc.) in order to allow both in- and out-linkages while document-level direct citation is unidirectional—with exceptions. Asymmetry at the journal level inspired the CHI classification of journals after their theoretical versus applied orientation [2.44] on the hypothesis that applied science journals tend to import knowledge and export citations, and reciprocally for basic science journals. The same phenomenon appears at the field level (cell biology versus medical research, for example).
The valuation of bilateral relations calls for methodological choices which can largely affect mapping and delineation. Take the simplest case where \(i\) and \(j\) denote two aggregates (journals, domains…) and assume the \(ij\) link is normalized on the basis of the total outflow of \(i\) and the total inflow of \(j\), and conversely for the \(ji\) link. Let us calculate the bilateral link between \(i\) and \(j\) by the arithmetic mean, the geometric mean, and the maximum of these two unidirectional normalized flows, a simplified variant of [2.187, 2.87] for the sake of the example. Should these valued networks be used for delineation purposes, they would tend to produce rather different results. The multiplicative indexes trivially penalize one-way relations typical of vertical channels, and tend to group entities with balanced relations, either particularly integrated channels or basic science fields with multidisciplinarity relations, or else clients sharing methods or products. In contrast, the maximum index tends to retrieve vertical channels (say cell biology–medical research) regardless of flows dissymmetry. Additive indexes stand in intermediary position, and appear as a middle-ground choice.
3.2.3.5 Semantics, Statistics, Informatics
Scientific domains at the mesolevel represent a considerable amount of data, especially in longitudinal series. The computing requirements, even with sparse bibliometric matrixes, are high, driving towards clustering or spectral analysis algorithms with high efficiency. The trade-off between computer efficiency and semantic power is far from simple. Correspondence analysis [2.134] was amongst the first factor technique to exhibit some semantic power in textual applications, especially a robust capability to group quasisynonyms with the distributional equivalence property. In its wake, postfactor analyses keep claiming some semantic power (Sect. 2.3.2) and built-in mapping capability. In parallel, local similarity techniques associated with traditional or innovative clustering methods from network analysis privilege the native graph of proximity and elements/links groupings. In those approaches the duality (structuring elements \(\times\) documents) needs assignment decisions (e.g., research front assigned to cocited core) with a semantic dissymmetry as to the internal scrutiny of clusters: while the detailed map of structuring elements is appealing for cluster evaluation (cited cores; within cluster word-map), the document coupling map, internal to a cluster, is hardly interpretable alone as stressed before.
Now, if word-maps present high potential for sociological interpretation, mere lexical associations remain semantically shallow with regard to truly semantic analyses. A common limitation to all these methods is the bag of words overlooking the rank of words and the structure of statements—the downside partly alleviated by multiterm treatment (noun phrases). Citations present a fuzzier relation to semantics (Sect. 2.4) but cocitation cores are nevertheless understandable for experts. Labels or lists of descriptors directly issued from cocitation or coword cores, for example a ranked list of specific terms, or indirectly rebuilt from clusters obtained by coupling, are common but limited auxiliaries for evaluating clusters. Cards might be reshuffled with new competitors to LSA such as neural word embeddings (Sect. 2.3.2). In addition to the similarity calculations in the word–context, useful for information retrieval, semantic calculations on word vectors are possible, allowing good performance in analogy tests (i. e., ‘‘Find X so as X is to A what B is to C'') or inference operations on these vectors, such as king \(-\) man \(+\) woman \(\to\) queen. This gain in semantic precision suggests that, applied to scientific corpora—now increasingly available in full text—it could allow in the future for an analyst to select the semantic dimensions relevant for delineating scientific fields and constitute crisp or overlapping groups of articles (or parts of these) in this subspace.
A recurrent problem of more traditional bibliometric representations, a counterpart of statistical simplicity and computer efficiency, is the holistic character of linkages, especially if combined with hard clustering. In document coupling techniques, either word-based or citation-based, the standard linkage measure is the weighted and normalized number of words shared. In lexical coupling, an implicit hypothesis is that the (weighted-normalized) number of shared tokens reflects the dominant semantic dimensions of the paper. For example, if very few words or references refer to methodology, this dimension will contribute less, all things being equal, to the shaping of bibliometric similarity, which can be misleading. In the opposite case, if methodology markers prevail, a transdisciplinary corpus will tend to be split between hard science literature and soft science literature on the domain, whereas mixed clusters would probably reflect the domain structure in a better way. Should the linkage between two clusters need explanation, this should be inferred from the features and given the titles of the two clusters, unless the technique includes indicators of contribution. In clusters of structuring elements (word graphs, cocitation cores) the relations are interpretable when zooming in on the fine-grained networks of words or cited articles, but without semantic characterization.
In a delineation context, a minimum of semantic break-up would make the scrutiny of the border region easier and faster. It could especially orient discussions on preferential extensions of a core zone towards neighbor clusters with shared methodology but new objects, shared object with new methods, etc. Ad hoc simple characterization of vocabulary has been successfully applied for other purposes, e.g., the level of application of biomedical research journals [2.188]. However, manual semantic tagging is quite intensive and field-specific. At the document level, many natural sciences articles can be labeled with simple semantic combinations. In computational linguistics , many works since Teufel et al [2.189] (argumentative zoning) address this issue of categorization of scientific discourses and automatic annotation, applicable for example to the summarization of scientific texts. Several proposals on categorization of arguments have been made, many of them at the experimental stage. Liakata et al [2.190] developed and automatized the core scientific concept ( ) categorization whose first layer distinguishes 11 categories: objective (hypothesis, goal, motivation, object), approach (method, model, experiment), and outcome (observation, result, conclusion). This line of research is extremely promising for bibliometric studies, especially domain delineation, but remains for the time being limited to small universes. In the meantime, oversimplified semantic indexing would help a lot in qualifying interdocument or intercluster relations. Figure 2.4 shows a fictitious configuration where documents are naively described by semantic triplets with various degrees of kinship. The graph display could be replaced by a superimposition of three partitions, each one upon a different semantic dimension.


Semantic and bibliometric linkages. This figure sketches bibliometric holistic distance versus decomposition into semantic links, with the (heroic) hypothesis of tagging with only three criteria, e.g., a \(=\) theory–hypothesis, b \(=\) experimental method, c \(=\) observation–test. For example a1, a2, a3 on the figure denote different hypotheses. The second panel represents three kinds of semantic relations. An article is described by a triplet a, b, c. For example, the documents G, I, and J are described by the same triplet {a1, b2, c2}. Documents G and I, for example, are connected by three links. The second panel aggregates information in a single type of linkages with varying degree of intensity. Here the bibliometric linkage is assumed proportional to the number of shared semantic instances, which is of course arbitrary. In the real bibliometric world, the lexical coupling linkage heavily depends on the most developed aspect(s)
More intensive semantic mapping relies on sophisticated ontologies, knowledge models, and semantic networks. If such resources have not been established beforehand and published, bibliometric studies cannot generally afford such heavy developments, however see [2.191].
Directly opposed to semantic approaches are nonfeature methods from computer science, which ignore the substantive representations and even more so the semantic content. In various IR/bibliometric applications (disambiguation of authors and affiliations, proximity of documents, detection of plagiarism) similarity between texts may be calculated on the basis of character \(n\)-grams [2.192] rather than feature word \(n\)-grams which is somewhat standard. The link to the minimal unit with semantic load, the word, is lost (almost completely for low values of \(n\)). The usual metrics can be applied to \(n\)-grams. A more radical way using the bit sequence representation with further compression, is the basis of measures like normal compression distance ( in [2.193]). NCD is a dissimilarity measure which is an approximation of the general Kolmogorov information distance [2.194, 2.195], parametrized by the compression algorithm. A normal compressor should satisfy four properties:
-
1.
Idempotence
-
2.
Monotonicity
-
3.
Symmetry
-
4.
Distributivity.
From the linguistic point of view the compression method is a black box. It nevertheless exhibits rather good performances for calculating text similarity with a most indirect semantic power of forms unification. The normalized Google distance ( in [2.196]) is the transposition to Google searches, at the word level, of the NCD, keeping the feature characteristics of the coword analysis and its semantic power. Its native application builds on lexical associations from millions of users.
Table 2.3 summarizes the degree of semantic ambition in the case of lexical approaches—transposable to citation attributes.
3.2.3.6 Dynamic Clustering
The delineation process has to face changes in the configuration of networks [2.124], affecting the value of a delineation solution at a particular moment. Dynamic clustering is understood in two (related) acceptations.
A first point of view is the adaptation of algorithms—and computer resources—to processing massive data streams, typically texts, an example today being online social networks. The initial \(k\)-means algorithm of MacQueen [2.197] was already an online incremental one, generating a cluster structure in one pass over the dataset—the usual iterative version, which converges to a solution independent of the presentation order of the data vectors, is due to Forgy [2.198]. Dynamic text stream mining is a growing topic in the machine learning and big data mining research communities. Changes in the cluster structure may reflect algorithmic artifacts as well as real phenomenona, hence ideal methodological characteristics are a) global optimum seeking and b) insensitivity to data ordering. An example of an incremental hierarchical clustering method for texts is [2.199], and a frequent itemsets dynamical clustering example is [2.200].
A second point of view focuses on the domains/topics picture and their description over time, through cluster time series, including the issue of time robustness in one-shot pictures. Again the distinction between clustering/mapping on structuring elements (e.g., cocited articles or lexical relations) and direct clustering of literature (e.g., bibliographic or lexical coupling), in techniques privileging classification in one space matters. The first family offers solutions with some durability. The repertoire of words gradually evolves. Change of the intellectual repertoire of cited literature, subject to an aging process, is usually faster but, except in emergent or revolutionary fields and in intrinsically rapid ones (e.g., computer science), it respects a mix of new and old literature. This gives some clue of robustness, in the short term, to the cluster solutions. By and large, in slow evolution processes, information cores are more persistent than peripheries. In one-shot clustering, working on pluri-annual window data reinforce the robustness of the breakdown and permit the cross-characterization of novelty (median of the cocited core) and internal growth in the span of the window (average date of front) [2.176]. Characterizing fine granularity hotspots in the network, such as local preferential attachment processes, may help to spot promising weak signals. Taxonomic applications of direct citation linkages might still benefit more from long time window settings. This would sketch, as noted earlier, a possible trend towards division of tasks between direct citation, cocitation, and bibliographic coupling in function of targeted granularity and immediacy of results.
By construction, direct clustering of documents over a time period (say the year) favors immediacy, but is not prolongable without a detour by the structuring elements and derived cluster labels. Another way consists in picking a coarser granularity, especially the journal level, at the expense of a heavy loss of precision. Short-time changes may be addressed by projecting a solution for a period on the reference solution of another period, a classical process in factor analysis applicable to other methods; an early example within bibliometrics is found in Noyons and van Raan [2.32].
A delineation process of any kind may be run on successive slices of time [2.201] of different lengths, with or without rolling averaging filters. A dynamic variant of LDA is [2.202], in which the word distributions of each topic varies in each time slice, where the number of clusters is fixed. Interesting historiographic insights accounting for cluster demography (emergence, death, splitting, merging…) are exhibited by longitudinal chaining of clusters, known since ISI's Atlas of Science, see [2.203, 2.204, 2.205, 2.206]. The latter work is based on lexical series. The predictive value of such series, along with life-cycle models, remains a quite difficult issue.
Last but not least, the rendering of change is closely linked to dynamic models of science where structure emerges from local properties, for example in the preferential attachment model. In this view, over time, breakthroughs (scientific or technological) shape the citation profiles of followers, a common mechanism in (co)citation bibliometrics. Local accretions around hot papers are amongst the signs of emergence. The symmetrical question over whether the referencing (or lexical) profile of papers has some predictive value, remains open. This connects to the controversies about interdisciplinary distal transfers in the discovery process, quoted above, which echo the combinatory nature of invention and innovation stressed by Schumpeter. The intuitive but bold hypothesis stating that the more distant the knowledge transfer, the more radical the discovery or invention is, nevertheless, tricky to test (definition of scientific or technological distance from models A or B–C, scale issues). Attempts to characterize scientific breakthrough and radical inventions, with an ex ante notion, are found for example in [2.207], using both citations and patent classification [2.208], using changes in forwards and backwards citation profiles [2.209], using citation contexts of outstanding discoveries.
3.3 Conclusion
By and large, bibliometric mapping provides landscapes with aggregate groups (clusters; local factors, etc.) likely to be assessed, and implementation of multistep and cross points of views help to distinguish cores and border regions, the latter calling for cluster evaluation, see Sect. 2.5.2. No mapping method is superior on all criteria and many factors are at play: the bulk of data, the type of network, the nature of the problem, and the ergonomics of outcomes for an easy supervision. IR search remains an alternative or a valuable complement to mapping. The next section focuses on hybrid techniques.
4 Multiple Networks and Hybridization
This section addresses the multinetwork approaches. We shall especially develop the combination of textual and citation networks but most types of bibliometric (and altmetric) networks can naturally contribute where appropriate. The forms of hybridization encompass a wide scope from fully integrated approaches to parallel schemes aiming at comparison and eventual combination, with intermediate sequential schemes.
4.1 Multiple Networks
A given document may be accessed by search strategies pointing at all searchable fields of data or metadata. Modern IR, going beyond the direct query–document similarity, integrates, with the cluster hypothesis and later the cognitive model, the documents' multiple spaces and networks, including citations and collaborations. Bridges between lexical and citation universes were built, especially for labeling purposes (e.g., keyword-plus [2.210]).
Likewise, major streams of study in the sociology of science have coined general theories accounting for the various manifestations of scientists behavior in communities: communication, collaboration , publication, rhetoric, citation, evaluation. The networks of science, although diverse, originate in the same ground. As a result, many classes of bibliometric questions (topic identification, characterization of emergence, static and dynamic mapping, diffusion processes, knowledge flows in science and more generally in the science–technology–innovation system ) can be answered by working on different networks, with respect to their specificity. The multinetwork approach to bibliometrics, both in terms of comparison and complementarity, appears as a natural mode of thought.
With the coming of age of data representation models such as entity–relationship for relational database management system ( ) implementation and of network analysis methods, IR scholars and bibliometricians in the early 1990s found flexible tools for easy handling of different dimensions of publication data. In the last decades, the culture of data mining encouraged mixes between several networks for pragmatic purposes [2.211]. We recall the key role of author networks (Sect. 2.4.2) before focusing on text and citation networks (Sect. 2.4.3) and finally their hybridization (Sect. 2.4.4).
4.2 Networks of Actors
The first analyses of scientific communities in the 1970s led to some disappointing results as to the unambiguous assignment of particular scientists to a particular group. In a short history of domain delineation Gläser et al [2.26] recall among others Mulkay et al's work [2.9] and Verspagen and Werker findings [2.212]. The archetype is the coauthorship graph. Price and Beaver [2.18], Beaver and Rosen [2.213], Luukkonen et al [2.214], Kretschmer [2.215], and Katz and Martin [2.216] laid the first layers of collaboration studies in connection with invisible colleges. Author-based models of science are amongst the central topics in science studies and bibliometrics. Studies on scientific collaboration are out of the scope of this work, but let us recall the macrolevel studies of the determinants of cooperation in the wake of Luukkonen et al [2.185], geographic proximity [2.217, 2.218], cultural links [2.186], and individual/collective behavior [2.219]. Those studies emphasize the importance of metrics and normalization in the interpretation. At the microlevel, proposals for mechanisms explaining the structure and dynamics of social networks were recalled in Sect. 2.3.
Networks of actors present a major theoretical interest: they stand at the crossroads of actual social networks' mathematical modeling and sociology of research, and bridge invisible colleges with cognitive structures [2.220]. They also show some drawbacks, echoing the scholars' disappointment noted above. Communities detection in practice faces the issue of names unification. For a long time, the problem has been both terribly costly and time consuming for data producers and bibliometricians, at both the institutional level and the author level, as stressed again in the name game project APE-INV (Academic Patenting in Europe Project), e.g., [2.221]. Great progress is ongoing due to the (Open Researcher and Contributor IDentifier; with the unique identifier of researchers), (International Standard Name Identifier), and (Global Research Identifier Database) initiatives among others.
Another issue, especially for small topics detection, is the width of the competence spectrum of productive authors likely to produce some noise, but this shortcoming is alleviated at the level of large domains. In this case perhaps, community detection (in a narrow sense) has arguments to compete with citation or lexical clustering. However, in most practical studies multiscale vision is required: not only does the target domain matter, but also the subdomains. At this scale, the polyvalence of authors limits precision. The problem may be reduced by time-restriction filters, the link-level technique, external information, or hybridization with citation or word information. Similar issues appear in author cocitation versus article cocitation [2.164, 2.222]. Author cocitation opened insights in the study of invisible colleges, with connection to researchers' sociology. Topics mapping as such is better addressed by document-level cocitation.
The interplay of coauthorship, citation, and linguistic networks as a mirror of sociocognitive activity is increasingly gaining attention: relations between contents and actors' positions [2.223, 2.224], between citations and coauthorship, and any or both of these with texts [2.220]. Is the multiple approach a step towards more powerful models of authors and community behavior, able to unify the diverse representations? This unification would spread benefits over bibliometric analysis, including delineation tasks. Nonfeature methods have not waited for unification (see below) to mix up all types of information, but they sacrifice the substantive depth of analysis.
However, the quest for unification might be hindered by the specific features of every bibliometric network. Changing the type and parameters of the network is like observing the universe in various wavelengths. The most dense objects produce various forms of energy and tend to be retrieved albeit with diverse volume and appearance. Less-dense objects like clouds of various composition can be seen only in specific parts of the spectrum. Likewise, we may conjecture that dense and isolated objects will be retrieved from any network fit for precise analysis [2.113], especially words and citations and perhaps coauthorship clusters. Sociological investigation is expected to confirm such configurations as bounded invisible colleges. In less dense and more connected areas, each network is likely to produce nonsuperimposable images, with different sensibilities. The convergences suggest strong forms with easy sociocognitive interpretation, while the divergences ask for careful tests and investigation. The sociology of translation associated less dense areas to emergence or ultimate evaporation phases.
4.3 Citations and Words
Lexical and citation characterization classically used in bibliometrics are appropriate for clustering of themes and mapping at various scales, on the basis of the toolbox sketched in Sect. 2.3.
4.3.1 A few Analogies and Differences
4.3.1.1 General
One difference naturally lies in the nature of the original relation: direct attributes for linguistic elements, reflexive interarticles for citations, with several consequences. Firstly, the granularity: words are an ultimate attribute (in classical feature methods) whereas cites target the full article semantic aggregate. Then, the linguistic content of citations is not explicit, and requires a statistical detour via the text fields and the data model, to emerge (automatic labeling of clusters with their specific vocabulary, citation contexts). Secondly, the time relation, not explicit in lexical relations, directly appears in the citation link, both cited and citing article being dated. Bibliometrics makes a large use of this diachronic relation in immediacy–aging studies. In contrast, the word content of an article is readily legible, but deprived of temporal information beyond the article date of submission/publication. Going further requires statistical studies to date the word in terms of chronological profile of use. Longitudinal studies on words have to rely on time statistics of use, typically with the assumption of achronicity: constant meaning over time. This is a bold statement in some cases. Beyond classical dating of word or word linkages after their usage, determined by the obsolescence of topics, natural language analysis paved the way for analyses of word transformations in a scientific context [2.225].
With respect to these constraints, a large class of bibliometric, IR, or altmetrics issues can be addressed by the lexical method or the (generalized) citation method with the exception of specific direct chaining [2.162]. Symmetrized relations (cocitation, coupling) mitigate the diachronicity, albeit underlying time features can be invoked if required. The reformulation of the dynamic chaining research fronts [2.205] is emulated by word-based clusters [2.202, 2.206]. Only the former directly contains citing–cited information for immediacy characterization.
Because of limitations (indexer effect) and lack of reactivity of controlled language, modern bibliometrics moved gradually towards natural language, building on the increasing availability of full text resources and lexical treatment. In spite of progress in computational linguistics, the NLP remains tricky, a counterpart of language richness and versatility. Polysemy, metonymy, synonymy, figures of speech, metaphors, acronyms, and disciplinary jargon are well-known linguistic traps of linguistic difficulties that users, bibliometricians, and retrieval specialists have to cope with. Unification (stemming and lemmatization, synonymy detection) also benefits from clustering techniques. Unsupervised homonymy tracking is a more challenging problem, since bridges in word clusters may be rooted in concept transfers or polysemy or else simple homonymy. This issue is somewhat alleviated in small (narrow context) studies. If elaborate ontology or semantic networks are seldom off-the-shelf, useful tools for term extraction, parsing, and coword exploration are available. Stemmers (with Porter's stemmer milestone [2.226]) or, a step further, lemmatizers are efficient with some risk in precision. New massive techniques, such as the above-mentioned deep learning-based or neural networks or targeted methods such as neural word embeddings, might bypass or alleviate costly preprocessing. Constraints of bibliometric studies dealing with large data universes are usually incompatible with refined semantic treatments, but the supply of large-scale statistical semantics resources might spare costly ad hoc developments. We mentioned (Sect. 2.2.4) a possible revival of controlled vocabulary supported by bibliometric treatments.
4.3.1.2 Statistical Background
The common feature is the skewness of frequency distribution found, among other disciplines, in information processes (Bradford–Lotka–Zipf trilogy, see [2.227]). The classical model to fit word distributions is the hyperbolic Zipf–Mandelbrot model. Other Paretian distributions are also used for citation frequency analogous to node degrees in the native oriented graph of citations. Similar skewed distributions are found in authors' collaboration graphs, with a distinction between scale-free distributions and small-world distributions (Sect. 2.3). The parameters of citation distributions are modulated by the citation windows, the parameters of word distribution are modulated by the type of lexical sources (title, abstract, full text…), the type of lexical unit picked, the language, and the richness of vocabulary.
Comparing the distributions of citations and words on the same corpus, some authors found that the latter appears more concentrated and less complex [2.33], thus less favorable in principle to precision—without forgetting the different granularity. Frequency weighting of linkages of the native word or citation networks, or similarity indexes with various types and degrees of normalization, may be implemented for retrieval or mapping purposes, for favoring information-rich elements in low and/or medium frequency. The precision of citation approaches was underlined in comparative retrieval tests, and especially the interest of cross-retrieval [2.228, 2.229]. As to co-occurrences, coword matrices tend to be less sparse but noisier than cocitations relations.
For the delineation work, the distribution of words or citations designs the background, with implications for interpretation, but what directly matters is the arrangement of documents after their texts or their bibliography. For this purpose, the typical approaches are the direct profile proximity on either type of structuring elements, words or references (coupling rationale or profile metrics in vector space), or the secondary assignment on prior classes of structuring elements such as coword, cocitation, or corresponding profiles. The distribution of node degrees in bibliographic coupling tends to be less skewed than in the original citation graph. Again normalization of distances or similarity by some function of inverse frequency can reduce the unevenness. The recall advantage of word-based techniques suggested their use in the large-scale mapping of clusters defined, beforehand, by citations [2.91]. There is some evidence in the same direction for patent–publication relations. Composite word–citation metrics are addressed in Sect. 2.4.4. Technicalities involved in term unification are also different. As information tokens, references are less difficult to match than natural language elements. Keys on cited references reveal effectivity and improve with standardization of entries, with residual difficulties in particular cases like citation analysis of patents towards science.
4.3.1.3 Sociological Background
The textual contents of an article and its bibliography are both the results of authors' choice in their community context. Both involve an intricate mix of scientific and social aspects: words and cited references are community markers and reflect the sociability of invisible colleges . A large body of literature (refer to the review [2.230]) has been devoted to citation behavior, including Cronin's classic work [2.231]. Whatever their determinants can be, Merton's rewards, Small's symbolic beacons or concept symbols [2.232], Gilbert's persuasion tools [2.223] or Latourian interests, the references mainly point towards the thematic groups where founding fathers, gatekeepers, and potential partners are found, which matters in science mapping . On the textual side, rhetoric and jargon expressing community habits, in addition to general words voicing interests, rejoin focused scientific terms—especially specific multiterms with medium frequency—to define topics. A substantial amount of convergence between texts and citations is therefore expected when the delineation of topics and communities are at stake. Some degree of parallelism may be found between relatively high frequency expressions (after filtering of stop-words) and highly cited articles in generic knowledge and multidisciplinary linkages. The measured convergence depends on the information unit and is likely to increase with small lexical units of citation contexts (see below).
However, the question arose as to which network is the more appropriate for describing science, at a time (the 1980s) where citation evaluation, indexing, and mapping were gaining interest. The social constructivist stream and the actor network theory mentioned above (Sect. 2.2) favored the coword networks [2.166] against citations to represent knowledge on a background of actor's interests. Texts appeared abler to depict more completely science in action [2.233] especially in controversial areas where social and cognitive aspects are inseparable, while citations were supposed confined to the capture of cold science with delays and incompleteness. The delay argument alone is less convincing for bibliographic coupling. Typical cocitation research fronts rely on a high-pass filter on citation or cocitation scores, favoring old articles, to reduce the data volume. Bibliographic coupling often works on the whole reference lists, letting recent and less cited references play. A residual effect of the publication cycle of the citing side nevertheless subsists. Similar delays may also occur in the use of new words or expressions qualifying a scientific technique.
In its very realm, academic science, citation analysis encountered lasting problems in quite a few disciplines, especially in a fraction of SSH, because of citation sparsity, incomplete processes of internationalization, and lack of coverage in databases . This argument is somewhat weakened nowadays because of data source progress and changing behavior of scholars confronted with science globalization and bibliometric evaluation. Citation analysis proved an appealing tool, including for the borderlines of standard literature, for example transfer documents (guidelines and even magazines and newspapers) explored in biomedicine by translational research for improving health system services [2.234]. See also the EUSTM website at https://eutranslationalmedicine.org. As to the coverage of technology, the transposition of citation analysis to patents was revealed to be rather successful [2.235] competing with lexical approaches [2.236]. It nevertheless requires acquaintance with specific citation rules and behavior in patent systems. The Internet produces linkages with an exploitable analogy with citations, as the Google search engine has demonstrated in the wake of Pinski and Narin's influence weights.
Citations are not without their shortcomings, stressed in voluminous literature from various horizons; see Bornmann and Daniel's aforementioned extensive review [2.230], and for the defense, mostly, see [2.51]. For the reason stated above, citation biases are somewhat less severe in mapping applications than in citation evaluation (impact, composite indexes) which concentrate controversies. Latourian citations or rare negative citations do not add much noise to cocitation topics. Other downsides are more serious. The bandwagon effect in citation behavior tends to create spurious cliques in native cocitation networks, possibly hindering the discriminating power of citation relations. The inflation of the number of references in authors’ practice, which is a long-term trend [2.237], also brings noise to conventional citation clustering. The disciplinary insertion affects the number of references (propensity to cite) justifying citing-side normalization approaches mentioned above.
Albeit language-dependent, textual analysis is media-free, which is valuable in fields where academic sources with standard citation behavior are not sufficient. Topics peripheral to the academic mainstream, or demanding a mix of heterogeneous data may be confined to text-based delineation.
In cases where no differential data coverage issue is faced, differences may arise between these expressions of scientists' behavior, resulting in alternative breakdowns into topics, independently from statistical properties. The expectation is that citations, albeit in a blurred and biased way, are more capable of tracking the intellectual inheritance. A single difference in the semantic mix, for example different methodology on the same category of problem, will probably better discriminate amongst microcommunities than lexical analysis, at least as long as those microcommunities do not secrete specific terminology.
Let us turn towards limit cases, special forms of particularism, especially perhaps in SSH where intellectual traditions resist globalization. Words as well as citations would distinguish between schools of thought with opposing theories, strong community preference, and distinct jargon: say in postwar period marginalist versus Marxist economists. In contrast, if the linguistic repertoire is shared by the two communities while they diverge in the intellectual base, the outcomes of the two approaches will be different. The reverse can be true, with a common recognition of the intellectual base but divergent traditions in terminology, perhaps again for reasons of national tradition. Such configurations, relatively rare, limit the generality of the conjecture stated above about local convergence of bibliometric networks in zones with high-gradient borders. Most of the time, a set of clustered papers belonging to a strong overlap of a word-based cluster and a citation-based one may be considered as a strong form, in a rationale already present in the first comparisons by McCain [2.228] on term versus citation indexing. The cognitive overlaps between information types was a keypoint in Ingwersen's model mentioned above.
4.3.2 Empirical Comparisons
The cross-check of cluster contents is a run-of-the-mill operation. For example, the enhancement of cocitation coverage by two-step expansion could be controlled by lexical means [2.127]. A few specific comparisons of the two mapping approaches on the same data are found in the literature. The scale is therefore different (subareas rather than a large domain) but the method can be applied to an overset expected to contain the targeted domain, as seen before. In an extensive study of a few promising fields in the 2000s, using bibliometric mapping, Noyons et al [2.238, 2.239] warned about the difference of concepts: publications and keywords and concluded they were “totally different structures”.
An opposite conclusion was reached by Zitt et al [2.240] on nanosciences and Laurens et al [2.241] on genomics, previously delineated as a whole by a hybrid sequence method. They implemented a more direct comparison scheme on clusters respectively from bibliographic coupling and lexical coupling (natural language, titles–abstracts), using the same axial \(k\)-means method ( ). Cross-tabulate cluster overlaps [2.242, 2.243] were reordered, giving a quasilandscape with a heavy and narrow diagonal load (Fig. 2.5a,b). This gives evidence of a fairly good convergence of lexical and citation solutions, also confirmed by direct indicators.


Archipelago display: Nanosciences (a) and Genomics (b). Data: Reordered cross-tabulate matrix of axial \(K\)-means clusters respectively from bibliographic and lexical coupling \({\mathrm{50}}\times{\mathrm{50}}\)). Relative overlap (\(z\)-axis) measured by the Ochiai index. Reordering: ranks on 1-dim MDS, making the diagonal accumulation showing the visual convergence between the two breakdowns apparent. The line is sinuous because of discrepancies between c-cluster versus w-cluster size distribution. The visual rendering suggests superclusters at a larger scale. In the nano figure, the area of nanotubes as a whole is retrieved by both methods, but with two different breakdowns and more discriminative power on the citation side (after [2.113])
On their high-level maps, Klavans and Boyack [2.244] and Leydesdorff and Rafols [2.245] also observe a reasonable degree of convergence. More general comparisons of mapping methods including textual are found in [2.173, 2.246, 2.247]. A recent exercise of mapping comparing cluster methods is reported by Velden et al [2.248]. Most experiments, however, lack a ground truth reference, and techniques presented as gold standards are disputable.
More generally, suppose we built clusters of documents from several origins: lexical coupling, bibliographic coupling, fronts from cocitation, author coupling, etc. Those various cluster solutions may be individually mapped. They can also be simultaneously represented using normalized overlaps between w-clusters, c-clusters, a-clusters, with appropriate metrics. Profiles distance may be required to overcome the zero overlap between hard clusters of the same family, say w-clusters. Resulting matrices are still quite small and amenable to MDS display.
The fact that the agreement between citation and lexical approaches is good but not complete brings one more argument in favor of complementarity. One thing to keep in mind: because of the imperfect optimization of reordering and choice of the article rather than sentences or narrow contexts as the lexical unit, the global convergence tends to be underestimated.
4.3.3 Complementarity
Complementarity, rather than competition, already inspired the citations in context researches, initiated in cocitation studies [2.249, 2.250] which are a natural space to connect referencing, intellectual base, and linguistic aspects. In a step further than linguistic labeling entities in (co)citation analysis, the studies of citation in context range from simple context visualization in citation engines to investigations in the dynamics of science. They tend to reinvest research in action, associating language and communities' life. The linguistic and semantic analysis of citation contexts contribute to topics such as the citation types or motives [2.251], the classification and cross-analysis of the contents of the citing or the cited documents [2.252], the fine-grained relation of citation contexts and abstract terms [2.253], the exploration of new dimensions of scientific texts [2.254]. Some of these advances influence citation techniques in return. An example is the improvement of cocitation accuracy [2.255, 2.256].
As a result of multinetwork or polyrepresentation hypotheses, some issues typical of one representation can receive a solution from the other. Convergence at the local level also creates spaces for complementarity: synonyms of any kind, for example, tend to be retrieved in the same citation-based clusters. Citation techniques escape linguistic polysemy and the reverse is true, but citation homonymy often due to matching keys, is a less important risk.
Finally, textual information preserves its advantages of availability, intuitiveness, and interpretation, with easy transposition to concepts and topics. A major shortcoming is the complexity and ambiguity of natural language, resulting in poor precision in the case of unsupervised protocols. In spite of the composite unit handled (the full article rather than the narrow concept), citations are appealing for tracking intellectual influences and often less noisy, at the expense of lower recall in weak signal configurations.
The capability of pure lexical approaches to emulate citation-based or hybrid approaches in challenging topics such as the aforementioned description/anticipation of early stages of domain emergence, remains a challenge.
4.4 Hybridization Modes
Looking for optimal exploitation of these contrasting properties is the quest of hybrid techniques, in line with pragmatic mixes of dimensions in IR-type delineation for bibliometric purposes. The same pragmatism inspired mixed information classification of web sources [2.257]. The detail of the more sophisticated techniques are not on the table: millions of Google users benefit from hybrid IR processes every day, but in spite of expansive literature devoted to the PageRank algorithm itself starting with [2.258] and published works on lexical/semantic processing [2.196], the detailed combination of multinetwork operations in the search engine is not documented. We will limit ourselves here to quite basic combinations, readily available in bibliometric literature.
The scope of hybridization is quite large: words and citations, on which we focus, may be taken either as variants of information tokens likely to be indistinctly treated under certain conditions, in a typical informetric posture; or seen as elements of quite different relations with their own fundamental properties and interpretation, suggesting their use in sequential or parallel protocols. Parallel exploitation, particularly, is sociology-compatible allowing for separate interpretations and comparison before final combination if necessary.
4.4.1 Full Hybrid
The structuring/clustering of fields using a common metric mixing citation and term distances at the finer grain level, from the start, is a promising path [2.259, 2.260]. Boyack and Klavans [2.128] on a large dataset, observed that even a hybrid naive coupling outperformed pure bibliographic coupling. Statistical differences between word and citation distribution can be reduced through a normalization of the similarity measures with different distributions ([2.261] with later simplification in [2.262]) achieving a full and flexible integration. Koopman et al [2.263] established cluster similarities using a combination of tokens, for comparing clustering solutions based on direct vocabulary and indirect vocabulary associated with authors, journals, citation, etc.
Those developments remain within the framework of feature methods keeping the substance of information elements, words, and citations. In Sect. 2.3, we mentioned purely computational methods (character \(n\)-grams on text flow, compression) for calculating generalized text distances regardless of linguistic features. An option is to stay within the textual domain (full text, abstract, title…) or to enlarge to the full article including authors, affiliations, list of references, etc. We get a massive and blind form of hybridization, dissolving both terms and references into signals, ignoring all forms of normalization including zones length (text versus bibliography). Such black boxes are deprived of any semantic interpretation, but in our experience prove efficient for quick calculation of interdocument distances.
We have seen above (Sect. 2.3.2) that deep neural networks have proven in many areas of supervised learning, including information retrieval , their ability to do without prior weighting of the variables. Their unsupervised variants, building upon their success in very constrained fields like the Go game, should be able to do the same from an informal collection of data—such as full hybrid data—and so an application to domain delineation might be to consider the last layers of a network collecting the many traces of scientific activity: whatever citations, texts, and so on in the wake of present limited attempts of hybridization. Research in unsupervised deep learning, though, is still at a preliminary stage [2.264]. There is no doubt, however, that in the next few years progress—and controversy—are to be expected from deep learning's entry into the competition. These processes, however, remain black boxes, with quite difficult interpretations. Perhaps high-level semantic categorization resulting from the careful interpretation of the last layers might allow experts to select a subset of explicit dimensions in order to take into account the users' expectations of a delineation process. Whether this could reconcile cognitive classification and institutional expectations, an issue mentioned above, is another question.
4.4.2 Sequential Hybrid: Citations \(\to\) Terms
Sequential protocols of delineation may rely on more iterations; we limit ourselves here to pointing out the basic sequences. We mentioned the tradition of completing citation objects by textual tagging above. The question of the validity of cocitation research fronts (Sect. 2.2.3) triggered further developments in terms of retrieval and recall rate and the means to foster it, possibly with the help of texts. Braam et al [2.265] developed a systematic complementation of cocitation cluster coverage by lexical means, a first operational example of hybrid delineation. The citation \(\to\) text sequence keeps being explored for other purposes, especially in global science maps. Boyack and Klavans [2.91] use textual metrics for display of cocitation cluster relations at the large scale where citation signals are weak.
4.4.3 Sequential Hybrid: Terms \(\to\) Citations
Here, the perspective is reversed. The remote ancestor is a classical application of citation indexing, when title words or KeyWords PlusTM were used to query a citation index to harvest papers on a given (set of) topics. The rationale is simple: starting a multistep process with experts’ help is easier with word queries. In a second step, the expansion is carried out on the citation network, where unsupervised or lightly supervised procedures are safer than on texts, with proper precautions. General conditions for citation analysis are required, especially not too scarce reference lists. There is some analogy with the boomerang effect on citations [2.266]. An example of protocol is the Lex\(+\)Cite process explored in Laurens et al [2.241], especially for emerging or transverse domains, where classical methods tend to fall short.
Quite a few options exist for expansion. If the seed is considered globally, literature with reference combinations present in the seed, but not in particular papers, is recalled. However, unspecific cites should be ruled out, which may require information from the whole database. Conversely, if only combinations at the paper level are allowed (strict bibliographic coupling), some broad-scope literature is missed; cluster-level enrichment, if a previous breakdown into clusters is available, stands in the middle. Besides the recall-oriented aim, these hybrid protocols may also enhance precision by submitting the core itself to bibliographic coupling constraints. Along the same lines, an elaborate strategy starting with lexical queries and query expansion, completed by journal selection and ending by collecting citing papers, is proposed in [2.267].
4.4.4 Parallel Design
As described above in Sect. 2.4.3, parallel design allows for comparison especially when metrics and clustering methods are identical, so that the final outcomes can be compared by factor analyses, parallel clustering–mapping, and reordered cross-tabulations. In parallel clustering, a similarity between clusters from different origins is defined after their degree of overlap, and then the intercluster matrix, of small size, is easily displayed using an MDS-type method. The cross-tabulation for example highlights strong relative overlaps with two strategies in addition to choosing either the c-cluster or the w-cluster on a topic: (a) precision-oriented: a heavy intersection between c-cluster and w-cluster suggests a strong form of topic, strategy possibly extended to superclusters (b) recall-oriented strategy, taking the union of c-cluster and w-cluster.
4.5 Conclusion
The various publication-linked networks, at least words and citations offer globally convergent views but not at the point that one can be happy with a single solution: sociology of citing, collaborating behavior and writing rhetorics keep some distance, and bibliometric protocols can choose to mix up all information tokens or to combine parallel approaches at the final stage only. Comparison and complementarity merit further endeavor. In practice, delineation cannot avoid supervision and actors' negotiation. Protocols of experts' guidance for evaluation purposes are desirable. Cross-validation of parallel processes, and even in some cases of sequential processes [2.241], may alleviate the burden of multistep external validation. There are strong indications that multinetwork methods improve recall and offer richer substance to expert/user discussions, but more benchmark studies against ground truth are needed.
5 Delineation Schemes and Conclusion
5.1 Delineation Schemes
5.1.1 IR Search First
A scheme of a bibliometric study asking for careful delineation may be as follows:
-
For memory's sake, selection of the expert/peers panel, matching the expected variety of the domain.
-
Supervised IR search on specialized journals and specific vocabulary, aiming at precision, building up the core of the domain. Alternatively, use of cited cores at the article or author level. The granularity is, typically, the document level. In favorable cases, some partial query formulas are found in the literature.
-
Query expansion or bibliometric expansion with citations (the latter usually requiring lighter supervision). The query expansion is conducted globally or query by query. Optionally, a round of data analysis/clustering can suggest query rephrasing or complementing (Fig. 2.6a-da,b).
-
Evaluation of outcomes especially on the borderline. In multilevel processes, the border region typically stands between the high-precision cores/seeds (or low-recall expanded set) and the high-recall expanded set. Circles of expansion with expected relevance indexes (example in Sect. 2.4) enlighten decision-making, again optionally supported by thematic clustering/mapping.


IR search and mapping approaches. (a) IR process: bottom-up queries and expansion of individual queries. Assumed at the paper-level. (b) Variant of (a): Expansion based on the entire set (lexical or citation-based). The border area, to be discussed, is typically determined by the region between the high-precision seed (or a low-recall expanded set) and a high-recall set. Circles of expansion in the border region, if indirect indicators or relevance are available, can drive the choice of delineation. (Optional (c)) Local clustering from B data (alternatively: from A data). Clusters are helpful for discussion but the border region and the decision tools may exist in A or B stages. The map is local and in the general case is not superimposable to a fraction of the global map D. A discussion on global versus local mapping is found in [2.179]. (d) Global mapping/clustering: top-down from global or overset map to the target; detection of border area with the help of information from projection. The example in the next panel (Fig. 2.6ee) assumes no external information, it relies on clustering outcomes only to define core, periphery and outside regions
5.1.2 Clustering/Mapping First
Regional overset maps are expected to contain all the target, and the decisions on border regions are typically made at the cluster level. Granularity obviously matters: we cannot expect that any high-level clustering of global or superlocal science will directly produce a class retrieving the target domain as a whole. A lower-level breakdown yielding fine-grained delineation of the frontier will be preferred, with a number of subareas large enough to match the diversity of the domain and eventually increase precision, but small enough to make cluster-level expertise feasible. Reasonably, the granularity picked fulfils two objectives, aiding the delineation and preparing the study of the domain's subareas.
In the perspective of a cluster evaluation procedure, possibly time-consuming and costly, it is recommended that one relies on a lightly supervised preselection of the border region, located between the internal core, a priori deemed in, and the external zone deemed out. Depending on the clustering–mapping protocols chosen (see the sketch Fig. 2.6a-dc,d), various solutions can address this preselection, for example:
-
Clustering with IR search projection. For this preselection, most helpful is the simultaneous representation of a global map (or at least of an overset-map) obtained on one criterion and cluster-level properties on another criterion. The projection of local features over a large context is often used: in two-step protocols, seeds for example are projected on clusters in the expanded set [2.241] with the ratio of seed articles as the indicator for delineation. Another combination: a global map conveys a particular vision depending on the network represented and the methodological choices made, and the hits of an IR search on a lexical marker (with a generous setting for recall) alerts one to clusters of interest. In Fig. 2.2a-c for example, the central communities might be considered as belonging to a core, whereas distant colonies, on the borders, require evaluation. Such cases illustrate the complementarity of IR and mapping techniques for avoiding silence both on weak and strong signals, as mentioned above. An alleviated process uses the projection of specialized journal literature onto a global map [2.177]. Such processes help pinpoint clusters forming the border region as the decision area and/or suggest journals or groups of papers as candidates for extending a core. Clusters may also undergo a complementary stage of query expansion or bibliometric expansion, typically transforming—in a given universe—a hard partition into an overlapping structure. For the domain delineation, only the overlaps involving the border region will matter for the final outcome.
-
Crossing methods. An alternative is the crossing of literature sets produced by different techniques or upon different networks. Instead of the standard core–periphery schemes, visualization may confront cognitive viewpoints, where areas of convergence (overlaps) are considered as strong forms (another form of core) and nonoverlapping parts as possible extensions to be validated. An example of crossmaps was shown in Sect. 2.4. In the limit case of Boolean formulas addressing the whole domain to delineate, this would be equivalent to running a word-based search AND/OR a citation-based search. The AND clause yields the strong form and the OR clause a possible expansion along two branches, words and citations.
The principle can be extended in a pragmatic way, given that (a) data analysis methods are not very robust and tend to yield quite different outcomes; (b) data from different networks do not lead to identical results (polyrepresentation). Therefore the combination of methods, or the combination of networks, provides both ways to enhance precision (strong forms where outcomes of different reliable methods converge), and ways to enhance recall, in divergence areas, at some risk.
-
Decision region and cluster evaluation (Fig. 2.6ee):
-
Evaluation at the cluster level. Again, thematic clusters are understood here in a broad meaning, whatever the data analysis method used. As a rule, there is no ground truth making the evaluation of recall, precision, and F-scores or variants straightforward, so the relevance of each cluster has to be assessed by indirect indicators and/or supervision based on available cluster data. A light manual scrutiny can rely on cluster aggregate information such as label, pseudotitle recomposed from most specific words or phrases, a ranked list of words, specific journals, cited authors/institutions, etc. Specificity of attributes is calculated by TF-IDF or other indexes. Features from a previous IR or mapping process, say ratios of expansion to core, or results from crossmaps, are particularly helpful. Map displays using pleasant interfaces make the task easier.
-
Evaluation at a finer granularity level. Finer-grained information can be available from the delineation protocol: IR projections of good quality onto a map; cluster crossings from hybrid methods; combination with zones of bibliometric expansion, etc. In such cases the border region may be treated at the infracluster or the document level. In pure mapping exercises, the cluster level may simply reveal too coarse, with exceedingly large or heterogeneous groupings. In this case, one has to go deeper into cluster content, through sampling for detailed analysis or further breakdown, at a cost.
-
The driving of evaluation is conditioned by the mastering of methodological effects and biases, likely to yield very different outputs. A particular attention, at the domain level, should be brought to the tendency of metrics and methods to favor particular semantic dimensions: To what extent can a domain be extended towards its intellectual base, especially theoretical foundations? Towards its tools and techniques? Towards its objects and products? Decision rules, in absence of a IR standard, will be based on quantitative indicators of the process, for example the intensity of bibliometric linkages in expansion stages, and experts' advices in terms of subjective precision, recall, and their balance (tantamount to variants of F-score). The convergence of experts' preferences, with the help of self-rating, may be taken into account.


IR search and mapping approaches. Evaluation and decision on clusters in border area. Example of direct selection of a bibliometric map on some criteria without input of other projected information
5.2 To Conclude
Delineation at the mesolevel deals with intermediary objects. Models in Price's tradition cast some light on the dynamics of the whole scientific system, whereas network theory proposes, at the microlevel, various mechanic models explaining emergence of mesostructures. The connection with practical solutions for topic and domain delineation, a rather multidisciplinary issue, will stimulate many research projects.
In practical studies, delineation operations should respect the proportionality principle. In simple cases, specialized and mature fields, the domain can be defined by using ready-made resources: official classifications, databases schemes. The complex cases which typically justify scientometric field studies—multidisciplinary, generic and emerging/unsettled domains—are precisely those where delineation and expertise are the more challenging. Coarse-grained approaches (journal-level) are easier to implement, but again hindered by a locally complex network and abundance of nonspecific media.
Bibliometrics both exploits and feeds science classification resources, literature searching and mapping models and human skill. Validation procedures include cross-analyses and direct supervision. The delineation tasks pull together multiple strands of bibliometrics and IR. They inherit progress in data and network analysis, as well as common limitations in data coverage, robustness issues, ergonomy challenges with respect to supervision and discussions with sponsors. Bibliometrics cannot pretend to operationalize in a standard manner all questions from decision-makers nor, in cognitive applications, all questions from sociologists of science and other scholars.
Within the scope where bibliometric hypothesis applies, a horizon of delineation is the comparison and combination of solutions from the networks which reflect scientific activity, essentially actors and institutions, citations and texts. Taking advantage of all available facets of data is a pragmatic choice, to which the concept of polyrepresentation has given a theoretical support. The cross-study of the three main universes associated to documents is also gaining attention in bibliometrics and sociology of research, supported by social network analysis. The theoretical profusion around models of growth and decline of communities is perhaps not settled now, but is very promising for understanding the invisible colleges in its various aspects. Will this multinetwork research track converge towards unified hypotheses? There is little doubt that progress in this matter will enlighten the delineation issue especially in emerging areas. Meanwhile, the question remains whether networks should be fully hybridized with more or less radical techniques—substantive or featureless—or various network solutions be conducted in parallel with final synthesis. In the background, the tremendous potential of deep learning on big science data is likely to reshuffle the cards in retrieval and classification methods. The prospects are unclear right now, as their lack of explainability is a serious drawback in the bibliometric delineation context.
The management of supervision is central to the feasibility of bibliometric studies and their delineation tasks. Configurations are diverse, one cannot compare simple problems requiring light supervision, with large studies on controversial areas. In the latter case, the operators of the study deal with a possibly complex managerial organization, with steering committees and expert panels mixing policy makers, stakeholders, and scientists, possibly with multiple roles. The selection of data sources and the methods of supervision, and finally the perimeter of the domain, will reflect those social stakes. The definition of fields or disciplines is particularly sensitive to academic interests, epistemic convictions and border issues, likely to create conflictual visions, sometimes between external observers and established players. The panel composition, to be efficient, should match the diversity of the domain, both in terms of thematic specialization and social stakes, with possibly some help from a few high-level generalists. In the mediation role, bibliometrics is also a social practice.
Bibliometric studies, if commissioned by administrations or institutions, enter a complex landscape of decision–help procedures where quantitative proposals are elements of discussion and decision among others. The question is vaster, however. Gläser et al [2.26] underline the differences between operational definitions (say method outputs), pragmatic definitions (for clients and sponsors), and theoretical definitions (talking to science studies) of topics or domains. The notion of scientific domains is mobilized for a wide scope of purposes, labeling, information, and evaluation in scientific institutions, science administrations, IR databases of any kinds, laboratory life, scientists' self-positioning, and last but not least the reflexive work of scientometricians and social scientists on understanding the mechanisms of scientific activity.
References
A. Comte: Cours de Philosophie Positive, Vol. 1 (Rouen Frères, Paris 1830)
R.K. Merton: Science and technology in a democratic order, J. Leg. Political Sociol. 1(1), 115–126 (1942)
R.K. Merton: The Sociology of Science: Theoretical and Empirical Investigations (Univ. Chicago Press, Chicago 1973)
T.S. Kuhn: The Structure of Scientific Revolutions, 2nd edn. (Univ. Chicago Press, Chicago 1970)
H.M. Collins, S. Yearley: Epistemological chicken. In: Science as Practice and Culture, ed. by A. Pickering (Univ. Chicago Press, Chicago 1992) pp. 301–326
B. Barnes, D. Bloor, J. Henry: Scientific Knowledge: A Sociological Analysis (Univ. Chicago Press, Chicago 1996)
D. Bloor: Knowledge and Social Imagery (Routledge Kegan Paul, London 1976)
K.D. Knorr-Cetina: Scientific communities or transepistemic arenas of research? A Critique of quasi-economic models of science, Soc. Stud. Sci. 12(1), 101–130 (1982)
M.J. Mulkay, G.N. Gilbert, S. Woolgar: Problem areas and research networks in science, Sociology 9(2), 187–203 (1975)
M. Serres: La Traduction, Hermès III, Collection ‘Critique' (Les Éditions de Minuit, Paris 1974)
B. Latour, S. Woolgar: Laboratory Life: The Social Construction of Scientific Facts (SAGE, Beverly Hills 1979)
M. Callon, B. Latour: Unscrewing the big leviathan: How actors macro-structure reality and how sociologists help them to do so. In: Advances in Social Theory and Methodology: Toward an Integration of Mirco- and Macro-Sociologies, ed. by K. Knorr-Cetina, A.V. Cicourel (Routledge Kegan Paul, London 1981) pp. 277–303
J. Law, J. Hassard: Actor Network Theory and After (Blackwell, Oxford 1999)
T. Lenoir: Instituting Science: The Cultural Production of Scientific Disciplines (Stanford Univ. Press, Stanford 1997)
V. DiRita: Microbiology is an integrative field, so why are we a divided society?, Microbe Mag. 8(10), 384–385 (2013)
A. Casadevall, F.C. Fang: Field science—The nature and utility of scientific fields, mBio 6(5), e01259–15 (2015)
J. Piaget: L'épistémologie des relations interdisciplinaires. In: Interdisciplinarity: Problems of Teaching and Research in Universities, ed. by L. Apostel, G. Berger, A. Briggs, G. Michaud (OECD, Paris 1972) pp. 127–140
D.J.D. Price, D.D. Beaver: Collaboration in an invisible college, Am. Psychol. 21(11), 1011–1018 (1966)
D. Crane: Invisible Colleges: Diffusion of Knowledge in Scientific Communities (Chicago Univ. Press, Chicago 1972)
D.E. Chubin: Beyond invisible colleges: Inspirations and aspirations of post-1972 social studies of science, Scientometrics 7(3–6), 221–254 (1985)
A. Zuccala: Modeling the invisible college, J. Am. Soc. Inf. Sci. Technol. 57(2), 152–168 (2005)
J. Gläser, G. Laudel: Integrating scientometric indicators into sociological studies: Methodical and methodological problems, Scientometrics 52(3), 411–434 (2001)
P.M. Haas: Introduction: Epistemic communities and international policy coordination, Int. Organization 46(1), 1–35 (1992)
É. Wenger: Communities of Practice: Learning, Meaning, and Identity (Cambridge Univ. Press, New York 1998)
R.P. Smiraglia: Domain analysis of domain analysis for knowledge organization: Observations on an emergent methodological cluster, Knowl. Organ. 42(8), 602–611 (2015)
J. Gläser, A. Scharnhorst, W. Glänzel: Same data—Different results? Towards a comparative approach to the identification of thematic structures in science, Scientometrics 111(2), 979–979 (2017)
C.R. Sugimoto, S. Weingart: The kaleidoscope of disciplinarity, J. Documentation 71(4), 775–794 (2015)
R. Todorov: Representing a scientific field: A bibliometric approach, Scientometrics 15(5/6), 593–605 (1989)
R.J.W. Tijssen: A quantitative assessment of interdisciplinary structures in science and technology: Co-classification analysis of energy research, Res. Policy 21(1), 27–44 (1992)
C.S. Wagner: The New Invisible College: Science for Development (Brookings Institution, Washington 2008)
A. Suominen, H. Toivanen: Map of science with topic modeling: Comparison of unsupervised learning and human-assigned subject classification, J. Assoc. Inf. Sci. Technol. 67(10), 2464–2476 (2016)
E.C.M. Noyons, A.F.J. van Raan: Monitoring scientific developments from a dynamic perspective: Self-organized structuring to map neural network research, J. Am. Soc. Inf. Sci. 49(1), 68–81 (1998)
M. Zitt, E. Bassecoulard: Delineating complex scientific fields by an hybrid lexical-citation method: An application to nanosciences, Inf. Process. Manag. 42(6), 1513–1531 (2006)
J.T. Klein: Interdisciplinarity: History, Theory, and Practice (Wayne State Univ. Press, Detroit 1990)
B.C.K. Choi, A.W.P. Pak: Multidisciplinarity, interdisciplinarity and transdisciplinarity in health research, services, education and policy: 1. Definitions, objectives, and evidence of effectiveness, Clin. Investig. Med. 29(6), 351–364 (2006)
T. Jahn, M. Bergmann, F. Keil: Transdisciplinarity: Between mainstreaming and marginalization, Ecol. Econ. 79, 1–10 (2012)
A.W. Russell, F. Wickson, A.L. Carew: Transdisciplinarity: Context, contradictions and capacity, Futures 40(5), 460–472 (2008)
J.T. Klein: Evaluation of interdisciplinary and transdisciplinary research, Am. J. Prev. Med. 35(2), S116–S123 (2008)
T.R. Miller, T.D. Baird, C.M. Littlefield, G. Kofinas, F.S. Chapin III, C.L. Redman: Epistemological pluralism: Reorganizing interdisciplinary research, Ecol. Soc. 13(2), 46 (2008)
A. Yegros-Yegros, I. Rafols, P. D'Este: Does interdisciplinary research lead to higher citation impact? The different effect of proximal and distal interdisciplinarity, PLOS ONE 10(8), e0135095 (2015)
G.E.A. Solomon, S. Carley, A.L. Porter: How multidisciplinary are the multidisciplinary journals science and nature?, PLOS ONE 11(4), e0152637 (2016)
C.R. Sugimoto, N. Robinson-Garcia, R. Costas: Towards a global scientific brain: Indicators of researcher mobility using co-affiliation data. In: OECD Blue Sky III Forum on Science and Innovation Indicators, ed. by M. Feldman, S. Nagaoka, L. Soete, A. Jaffe, M. Salazar, R. Veugelers (OECD, Paris 2016)
M. Bordons, F. Morillo, I. Gómez: Analysis of cross-disciplinary research through bibliometric tools. In: Handbook of Quantitative Science and Technology Research: The Use of Publication and Patent Statistics in Studies of S&T Systems, ed. by H.F. Moed, W. Glänzel, U. Schmoch (Springer, Dordrecht 2004) pp. 437–456
G. Pinski, F. Narin: Citation influence for journal aggregates of scientific publications: Theory, with application to the literature of physics, Inf. Process. Manag. 12(5), 297–312 (1976)
E.J. Rinia, T.N. van Leeuwen, E.E.W. Bruins, H.G. van Vuren, A.F.J. van Raan: Measuring knowledge transfer between fields of science, Scientometrics 54(3), 347–362 (2002)
E. Bassecoulard, M. Zitt: Patents and publications: The lexical connection. In: Handbook of Quantitative Science and Technology Research: The Use of Publication and Patent Statistics in Studies of S&T Systems, ed. by H.F. Moed, W. Glänzel, U. Schmoch (Springer, Dordrecht 2004) pp. 665–694
K. Börner, R. Klavans, M. Patek, A.M. Zoss, J.R. Biberstine, R.P. Light, V. Larivière, K.W. Boyack: Design and update of a classification system: The UCSD map of science, PLoS ONE 7(7), e39464 (2012)
K.W. Boyack, R. Klavans: The structure of science. In: Places and Spaces: Mapping Science—1st Iteration (2005): The Power of Maps, ed. by K. Börner, D. MacPherson (scimaps.org, Indiana 2005)
A. Stirling: A general framework for analysing diversity in science, technology and society, J. R. Soc. Interface 4(15), 707–719 (2007)
D. Hicks: Limitations and more limitations of co-citation analysis/bibliometric modelling: A reply to Franklin, Soc. Stud. Sci. 18(2), 375–384 (1988)
H.F. Moed: Citation Analysis in Research Evaluation, Information Science and Knowledge Management, Vol. 9 (Springer, Dordrecht 2005)
A.F.J. van Raan, T.N. van Leeuwen, M.S. Visser: Severe language effect in university rankings: Particularly Germany and France are wronged in citation-based rankings, Scientometrics 88(2), 495–498 (2011)
L. Soete, S. Schneegans, D. Eröcal, B. Angathevar, R. Rasiah: A world in search of an effective growth strategy. In: UNESCO Science Report: Towards 2030, UNESCO Reference Works, ed. by S. Schneegans (UNESCO, Paris 2015) pp. 20–55
J. Freyne, L. Coyle, B. Smyth, P. Cunningham: Relative status of journal and conference publications in computer science, Communications ACM 53(11), 124–132 (2010)
A.J. Nederhof: Bibliometric monitoring of research performance in the social sciences and the humanities: A review, Scientometrics 66(1), 81–100 (2006)
M. Huang, Y. Chang: Characteristics of research output in social sciences and humanities: From a research evaluation perspective, J. Am. Soc. Inf. Sci. Technol. 59(11), 1819–1828 (2008)
G. Sivertsen, B. Larsen: Comprehensive bibliographic coverage of the social sciences and humanities in a citation index: An empirical analysis of the potential, Scientometrics 91(2), 567–575 (2012)
T.N. Van Leeuwen, H.F. Moed, R.J.W. Tijssen, M.S. Visser, A.F.J. Van Raan: Language biases in the coverage of the Science Citation Index and its consequences for international comparisons of national research performance, Scientometrics 51(1), 335–346 (2001)
M. Zitt, S. Ramanana-Rahary, E. Bassecoulard: Correcting glasses help fair comparisons in international science landscape: Country indicators as a function of ISI database delineation, Scientometrics 56(2), 259–282 (2003)
V. Larivière, É. Archambault, Y. Gingras, É. Vignola-Gagné: The place of serials in referencing practices: Comparing natural sciences and engineering with social sciences and humanities, J. Am. Soc. Inf. Sci. Technol. 57(8), 997–1004 (2006)
C. Michels, U. Schmoch: The growth of science and database coverage, Scientometrics 93(3), 831–846 (2012)
S. Mikki: Comparing Google Scholar and ISI Web of Science for earth sciences, Scientometrics 82(2), 321–331 (2010)
A. Sinha, Z.Y.S. Shen, H. Ma, D. Eide, B.J.P. Hsu, K. Wang: An overview of Microsoft Academic Service (MAS) and applications. In: Proc. 24th Int. Conf. World Wide Web, Florence, Italy 2015, ed. by A. Gangemi, S. Leonardi, A. Panconesi (ACM, New York 2015) pp. 243–246
D. Herrmannova, P. Knoth: An analysis of the Microsoft Academic Graph, D-Lib Mag. (2016), https://doi.org/10.1045/september2016-herrmannova
A.-W. Harzing, S. Alakangas: Microsoft academic: Is the phoenix getting wings?, Scientometrics 110(1), 371–383 (2017)
J.E. Gray, M.C. Hamilton, A. Hauser, M.M. Janz, J.P. Peters, F. Taggert: Scholarish: Google Scholar and its value to the sciences, Issues Sci. Technol. Librarianship (2012), https://doi.org/10.5062/F4MK69T9
C. Labbé: Ike Antkare, one of the great stars in the scientific firmament, ISSI Newsletter 6(2), 48–52 (2010)
P. Jacsó: Metadata mega mess in Google Scholar, Online Inf. Rev. 34(1), 175–191 (2010)
A.-W. Harzing, S. Alakangas: Google Scholar, Scopus and the Web of Science: A longitudinal and cross-disciplinary comparison, Scientometrics 106(2), 787–804 (2016)
Q. Wang, L. Waltman: Large-scale analysis of the accuracy of the journal classification systems of Web of Science and Scopus, J. Informetrics 10(2), 347–364 (2016)
M. Thelwall, S. Haustein, V. Larivière, C.R. Sugimoto: Do altmetrics work? Twitter and ten other social web services, PLoS ONE 8(5), e64841 (2013)
S. Haustein, I. Peters, J. Bar-Ilan, J. Priem, H. Shema, J. Terliesner: Coverage and adoption of altmetrics sources in the bibliometric community, Scientometrics 101(2), 1145–1163 (2014)
E. Mohammadi, M. Thelwall: Mendeley readership altmetrics for the social sciences and humanities: Research evaluation and knowledge flows, J. Assoc. Inf. Sci. Technol. 65(8), 1627–1638 (2014)
Z. Zahedi, R. Costas, P. Wouters: How well developed are altmetrics? A cross-disciplinary analysis of the presence of “alternative metrics” in scientific publications, Scientometrics 101(2), 1491–1513 (2014)
C.L. González-Valiente, J. Pacheco-Mendoza, R. Arencibia-Jorge: A review of altmetrics as an emerging discipline for research evaluation, Learn. Publ. 29(4), 229–238 (2016)
A.E. Williams: Altmetrics: An overview and evaluation, Online Inf. Rev. 41(3), 311–317 (2017)
C. Daraio, W. Glänzel: Grand challenges in data integration–state of the art and future perspectives: An introduction, Scientometrics 108(1), 391–400 (2016)
OECD: Revised Field of Science and Technology (FOS) Classification in the Frascati Manual—Report number DSTI/EAS/STP/NESTI(2006)19/FINAL (OECD, Paris 2007)
E. Garfield: The evolution of the Science Citation Index, Int. Microbiol. 10(1), 65–69 (2007)
A.I. Pudovkin, E. Garfield: Algorithmic procedure for finding semantically related journals, J. Am. Soc. Inf. Sci. Technol. 53(13), 1113–1119 (2002)
E. Garfield: Citation analysis as a tool in journal evaluation: Journals can be ranked by frequency and impact of citations for science policy studies, Science 178(4060), 471–479 (1972)
E. Garfield: The history and meaning of the journal impact factor, J. Am. Med. Assoc. 295(1), 90–93 (2006)
F. Narin, G. Pinski, H.H. Gee: Structure of the biomedical literature, J. Am. Soc. Inf. Sci. 27(1), 25–45 (1976)
P. Jacsó: As we may search: Comparison of major features of the Web of Science, Scopus, and Google Scholar citation-based and citation-enhanced databases, Curr. Sci. 89(9), 1537–1547 (2005)
F. de Moya-Anegón, Z. Chinchilla-Rodríguez, B. Vargas-Quesada, E. Corera-Álvarez, F.J. Muñoz-Fernández, A. González-Molina, V. Herrero-Solana: Coverage analysis of Scopus: A journal metric approach, Scientometrics 73(1), 53–78 (2007)
L. Leydesdorff, S.E. Cozzens: The delineation of specialties in terms of journals using the dynamic journal set of the SCI, Scientometrics 26(1), 135–156 (1993)
E. Bassecoulard, M. Zitt: Indicators in a research institute: A multi-level classification of scientific journals, Scientometrics 44(3), 323–345 (1999)
I. Rafols, M. Meyer: Diversity and network coherence as indicators of interdisciplinarity: Case studies in bionanoscience, Scientometrics 82(2), 263–287 (2009)
W. Glänzel, A. Schubert: A new classification scheme of science fields and subfields designed for scientometric evaluation purposes, Scientometrics 56(3), 357–367 (2003)
E. Archambault, O.H. Beauchesne, J. Caruso: Towards a multilingual, comprehensive and open scientific journal ontology. In: ISSI'11: Proc. 13th Int. Conf. Int. Soc. Scientometr. Informetrics, Durban, South Africa 2011, ed. by E. Noyons, P. Ngulube, J. Leta (ISSI, Leiden Univ. Zululand 2011) pp. 66–77
K.W. Boyack, R. Klavans: Creation of a highly detailed, dynamic, global model and map of science, J. Assoc. Inf. Sci. Technol. 65(4), 670–685 (2014)
R. Klavans, K.W. Boyack: Which type of citation analysis generates the most accurate taxonomy of scientific and technical knowledge?, J. Assoc. Inf. Sci. Technol. 68(4), 984–998 (2017)
A. Ruiz-Iniesta, O. Corcho: A review of ontologies for describing scholarly and scientific documents. In: SePublica'14: Proc. 4th Workshop on Semantic Publishing Co-Located with the 11th Extended Semantic Web Conference, Anissaras, Greece 2014 (CEUR-WS, Aachen 2014), http://ceur-ws.org/Vol.1155/paper-07.pdf
A.M. Petersen, D. Rotolo, L. Leydesdorff: A triple helix model of medical innovation: Supply, demand, and technological capabilities in terms of medical subject headings, Res. Policy 45(3), 666–681 (2016)
A. Mogoutov, B. Kahane: Data search strategy for science and technology emergence: A scalable and evolutionary query for nanotechnology tracking, Res. Policy 36(6), 893–903 (2007)
A.L. Porter, J. Youtie, P. Shapira, D.J. Schoeneck: Refining search terms for nanotechnology, J. Nanoparticle Res. 10(5), 715–728 (2007)
P. Ingwersen: Cognitive perspectives of information retrieval interaction: Elements of a cognitive IR theory, J. Documentation 52(1), 3–50 (1996)
J. Nicolaisen, B. Hjørland: Practical potentials of Bradford's law: A critical examination of the received view, J. Documentation 63(3), 359–377 (2007)
P. Ingwersen, K. Järvelin: The Turn: Integration of Information Seeking and Retrieval in Context, The Information Retrieval Series, Vol. 18 (Springer, Dordrecht 2005)
T.E. Nisonger: Journals in the core collection: Definition, identification, and applications, Ser. Libr. 51(3/4), 51–73 (2007)
H. Small: Co-citation in the scientific literature: A new measure of the relationship between two documents, J. Am. Soc. Inf. Sci. 24(4), 265–269 (1973)
Q.L. Burrell: On the \(h\)-index, the size of the Hirsch core and Jin’s a-index, J. Informetrics 1(2), 170–177 (2007)
W. Glänzel, B. Thijs: Using “core documents” for detecting and labelling new emerging topics, Scientometrics 91(2), 399–416 (2012)
J. Rocchio: Relevance feedback in information retrieval. In: The SMART Retrieval System: Experiments in Automatic Document Processing, ed. by G. Salton (Prentice Hall, Englewood Cliffs 1971) pp. 313–323
G. Salton, C. Buckley: Improving retrieval performance by relevance feedback, J. Am. Soc. Inf. Sci. 41(4), 288–297 (1990)
C. Carpineto, G. Romano: A survey of automatic query expansion in information retrieval, ACM Comput. Surv. 44(1), 1–50 (2012)
R. Agrawal, T. Imieliński, A. Swami: Mining association rules between sets of items in large databases, ACM SIGMOD Rec. 22(2), 207–216 (1993)
D. Hric, R.K. Darst, S. Fortunato: Community detection in networks: Structural communities versus ground truth, Phys. Rev. E 90(6), 062805 (2014)
M.M. Kessler: Bibliographic coupling between scientific papers, Am. Doc. 14(1), 10–25 (1963)
N. Jardine, C.J. van Rijsbergen: The use of hierarchic clustering in information retrieval, Inf. Storage Retr. 7(5), 217–240 (1971)
P. Mayr, A. Scharnhorst: Combining bibliometrics and information retrieval: Preface, Scientometrics 102(3), 2191–2192 (2015)
P. Mayr, A. Scharnhorst: Scientometrics and information retrieval: Weak-links revitalized, Scientometrics 102(3), 2193–2199 (2015)
M. Zitt: Meso-level retrieval: IR-bibliometrics interplay and hybrid citation-words methods in scientific fields delineation, Scientometrics 102(3), 2223–2245 (2015)
P. Mayr, I. Frommholz, G. Cabanac, M.K. Chandrasekaran, K. Jaidka, M.-Y. Kan, D. Wolfram: Introduction to the special issue on bibliometric-enhanced information retrieval and natural language processing for digital libraries (BIRNDL), Int. J. Digit. Libr. 19(2-3), 107–111 (2018)
M.E.J. Newman: The structure of scientific collaboration networks, Proc. Nat. Acad. Sci. 98(2), 404–409 (2001)
M.E.J. Newman: Coauthorship networks and patterns of scientific collaboration, Proc. Nat. Acad. Sci. 101(Suppl. 1), 5200–5205 (2004)
A.-L. Barabási, H. Jeong, Z. Néda, E. Ravasz, A. Schubert, T. Vicsek: Evolution of the social network of scientific collaborations, Physica A: Stat. Mech. Appl. 311(3/4), 590–614 (2002)
D.J.D. Price: A general theory of bibliometric and other cumulative advantage processes, J. Am. Soc. Inf. Sci. 27(5), 292–306 (1976)
R. Albert, A.-L. Barabási: Statistical mechanics of complex networks, Rev. Mod. Phys. 74(1), 47–97 (2002)
C.S. Wagner, L. Leydesdorff: Network structure, self-organization, and the growth of international collaboration in science, Res. Policy 34(10), 1608–1618 (2005)
G. Csányi, B. Szendrői: Fractal–small-world dichotomy in real-world networks, Phys. Rev. E 70(1), 016122 (2004)
M. McPherson, L. Smith-Lovin, J.M. Cook: Birds of a feather: Homophily in social networks, Annu. Rev. Sociol. 27(1), 415–444 (2001)
N. Carayol, P. Roux: Knowledge flows and the geography of networks: A strategic model of small world formation, J. Econ. Behav. Organ. 71(2), 414–427 (2009)
K. Börner, W. Glänzel, A. Scharnhorst, P. van den Besselaar: Modeling science: Studying the structure and dynamics of science, Scientometrics 89(1), 347–348 (2011)
M. Cadot, A. Lelu, M. Zitt: Benchmarking 17 clustering methods, https://hal.archives-ouvertes.fr/hal-01532894 (2018)
A. McCallum, K. Nigam, L.H. Ungar: Efficient clustering of high-dimensional data sets with application to reference matching. In: KDD'00: Proc. 6th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, Boston, MA 2000, ed. by R. Ramakrishnan, S. Stolfo, R. Bayardo, I. Parsa (Association for Computing Machinery, New York 2000) pp. 169–178
M. Zitt, E. Bassecoulard: Reassessment of co-citation methods for science indicators: Effect of methods improving recall rates, Scientometrics 37(2), 223–244 (1996)
K.W. Boyack, R. Klavans: Co-citation analysis, bibliographic coupling, and direct citation: Which citation approach represents the research front most accurately?, J. Am. Soc. Inf. Sci. Technol. 61(12), 2389–2404 (2010)
G.W. Milligan: A review of Monte Carlo tests of cluster analysis, Multivar. Behav. Res. 16(3), 379–407 (1981)
G.W. Milligan, M.C. Cooper: Methodology review: Clustering methods, Appl. Psychol. Meas. 11(4), 329–354 (1987)
M. Ester, H.-P. Kriegel, J. Sander, X. Xu: A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise. In: KDD'96: Proc. 2nd Int. Con. Knowl. Discovery Data Mining, Portland, OR 1996, ed. by E. Simoudis, J. Han, U. Fayyad (AAAI, Palo Alto 1996) pp. 226–231
A. Rodriguez, A. Laio: Clustering by fast search and find of density peaks, Science 344(6191), 1492–1496 (2014)
M. Reinert: Un logiciel d'analyse lexicale, Cah. Ana. Données 11(4), 471–481 (1986)
J.-P. Benzécri: L'analyse des Correspondances, Analyse des Données, Vol. 2 (Dunod, Paris 1973)
P.D. Turney, P. Pantel: From frequency to meaning: Vector space models of semantics, J. Artif. Intell. Res. 37(1), 141–188 (2010)
S. Deerwester, S.T. Dumais, T.K. Landauer, G.W. Furnas, L. Beck: Improving information retrieval with latent semantic indexing. In: Proc. 51st Annu. Meet. Am. Soc. Inf. Sci., Atlanta (1988) pp. 36–40
A. Lelu: Clusters and factors: Neural algorithms for a novel representation of huge and highly multidimensional data sets. In: New Approaches in Classification and Data Analysis, ed. by E. Diday, Y. Lechevallier, M. Schader, P. Bertrand (Springer, Berlin 1994) pp. 241–248
C.H. Papadimitriou, G. Tamaki, P. Raghavan, S. Vempala: Latent semantic indexing: A probabilistic analysis. In: PODS'98: Proc. 17th ACM SIGACT-SIGMOD-SIGART Symp. Principles Database Syst., Seattle, WA 1998, ed. by A. Mendelson, J. Paredaens (ACM, New York 1998) pp. 159–168
T. Hofmann: Probabilistic latent semantic indexing. In: SIGIR'99: Proc. 22nd Annu. Int. ACM SIGIR Conf. Res. Dev. Inf, Retrieval, Berkeley, CA 1999, ed. by F. Gey, M. Hearst, R. Tong (ACM, New York 1999) pp. 50–57
D.M. Blei, A.Y. Ng, M.I. Jordan: Latent Dirichlet allocation, J. Mach. Learning Res. 3, 993–1022 (2003)
V.D. Blondel, J.-L. Guillaume, R. Lambiotte, E. Lefebvre: Fast unfolding of communities in large networks, J. Stat. Mech. Theory Exp. 2008(10), P10008 (2008)
M. Rosvall, C.T. Bergstrom: An information-theoretic framework for resolving community structure in complex networks, Proc. Natl. Acad. Sci. 104(18), 7327–7331 (2007)
N.J. van Eck, L. Waltman: Software survey: VOSviewer, a computer program for bibliometric mapping, Scientometrics 84(2), 523–538 (2010)
M. Meila, J. Shi: Learning segmentation by random walks. In: NIPS'00: Proc. Neural Inf. Process. Syst. Conf., Denver, CO 2000, ed. by T.K. Leen, T.G. Dietterich, V. Tresp (MIT Press, Cambridge 2000) pp. 873–879
A. Lancichinetti, S. Fortunato: Community detection algorithms: A comparative analysis, Phys. Rev. E 80(5), 056117 (2009)
J. Leskovec, K.J. Lang, M. Mahoney: Empirical comparison of algorithms for network community detection. In: WWW'10: Proc. 19th Int. Conf. World Wide Web, Raleigh, NC 2010, ed. by M. Rappa, P. Jones, J. Freire, S. Chakrabarti (ACM, New York 2010) pp. 631–640
J. Yang, J. Leskovec: Defining and evaluating network communities based on ground-truth. In: ICDM'12: Proc. 12th Int. Conf. Data Mining, Brussels 2012, ed. by M.J. Zaki, A. Siebes, J.X. Yu, B. Goethals, G. Webb, X. Wu (IEEE, Los Alamitos 2012) pp. 745–754
Y. Shen, X. He, J. Gao, L. Deng, G. Mesnil: A latent semantic model with convolutional-pooling structure for information retrieval. In: CIKM'14: Proc. 23rd ACM Conf. Inf. Knowl. Mining, Shanghai 2014, ed. by J. Li, X.S. Wang, M. Garofalakis, I. Soboroff, T. Suel, M. Wang (ACM, New York 2014) pp. 101–110
C. Van Gysel, M. de Rijke, E. Kanoulas: Neural vector spaces for unsupervised information retrieval, ACM Trans. Inf. Syst. 36(4), 1–25 (2018)
T. Mikolov, W. tau Yih, G. Zweig: Linguistic regularities in continuous space word representations. In: NAACL-HLT'13: Proc. Conf. North Am. Chap. Assoc. Comput. Linguistics: Human Lang. Technol., Atlanta, GA 2013, ed. by L. Vanderwende, H. Daume III, K. Kirchhoff (Association for Computational Linguistics, Stroudsburg 2013) pp. 746–751
O. Levy, Y. Goldberg: Neural word embedding as implicit matrix factorization. In: NIPS'14: Proc. Neural Inf. Process. Syst. Conf., Monreéal 2014, ed. by Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence (Curran Associates, Red Hook 2014) pp. 2177–2185
S.E. Robertson, S. Walker, S. Jones, M. Hancock-Beaulieu, M. Gatford: Okapi at TREC-3. In: TREC'94: Proc. 3rd Text Retrieval Conf., Gaithersburg, MA 1994, ed. by D.K. Harman (NIST, Gaithersburg 1994) pp. 109–126
T.M.J. Fruchterman, E.M. Reingold: Graph drawing by force-directed placement, Softw. Pract. Exp. 21(11), 1129–1164 (1991)
M. Bastian, S. Heymann, M. Jacomy: Gephi: An open source software for exploring and manipulating networks. In: ICWSM'09: Proc. 3rd Int. AAAI Conf. Weblogs Soc. Media, San Jose, CA 2009, ed. by W.W. Cohen, N. Nicolov (AAAI, Palo Alto 2009) p. 361
S. Martin, W.M. Brown, R. Klavans, K.W. Boyack: OpenOrd: An open-source toolbox for large graph layout. In: Proc. Visualization Data Analysis 2011, San Francisco, CA 2011, ed. by P.C. Wong, J. Park, M.C. Hao, C. Chen, K. Börner, D.L. Kao, J.C. Roberts (SPIE, Bellingham 2011) p. 786806
W. de Nooy, A. Mrvar, V. Batagelj: Exploratory Social Network Analysis with Pajek, Revised and Expanded, 2nd edn. (Cambridge Univ. Press, New York 2011)
M. Cadot, A. Lelu: Optimized representation for classifying qualitative data. In: DBKDA'10: Proc. 2nd Int. Conf. Adv. Databases, Knowl., Data Applications, Les Menuires, France 2010, ed. by F. Laux, L. Strömbäck (IEEE, Los Alamitos 2010) pp. 241–246
D. Cai, X. He, J. Han: Document clustering using locality preserving indexing, IEEE Trans. Knowl. Data Eng. 17(12), 1624–1637 (2005)
W.M. Rand: Objective criteria for the evaluation of clustering methods, J. Am. Stat. Assoc. 66(336), 846–850 (1971)
T.M. Cover, J.A. Thomas: Elements of Information Theory, Wiley Series in Telecommunications (Wiley, New York 1991)
P. Ronhovde, Z. Nussinov: Multiresolution community detection for megascale networks by information-based replica correlations, Phys. Rev. E 80(1), 016109 (2009)
E. Garfield, A.I. Pudovkin, V.S. Istomin: Why do we need algorithmic historiography?, J. Am. Soc. Inf. Sci. Technol. 54(5), 400–412 (2003)
I. Marshakova: System of document connections based on references, Nauchno-Tekh. Inf. 2 6, 3–8 (1973)
H.D. White, B.C. Griffith: Author cocitation: A literature measure of intellectual structure, J. Am. Soc. Inf. Sci. 32(3), 163–171 (1981)
G. Salton: The SMART Retrieval System: Experiments in Automatic Document Processing (Prentice Hall, Englewood Cliffs 1971)
M. Callon, J.-P. Courtial, W.A. Turner, S. Bauin: From translations to problematic networks: An introduction to co-word analysis, Soc. Sci. Inf. 22(2), 191–235 (1983)
W.A. Turner, G. Chartron, F. Laville, B. Michelet: Packaging information for peer review: New co-word analysis techniques. In: Handbook of Quantitative Science and Technology, ed. by A.F.J. van Raan (Springer, Dordrecht 1988) pp. 291–323
J. Whittaker: Creativity and conformity in science: Titles, keywords and co-word analysis, Soc. Stud. Sci. 19(3), 473–496 (1989)
L.C. Freeman: The Development of Social Network Analysis: A Study in the Sociology of Science (Empirical, Vancouver 2004)
C. Chen: CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature, J. Am. Soc. Inf. Sci. Technol. 57(3), 359–377 (2006)
W. Glänzel, H.-J. Czerwon: A new methodological approach to bibliographic coupling and its application to the national, regional and institutional level, Scientometrics 37(2), 195–221 (1996)
L. Waltman, N.J. van Eck: A new methodology for constructing a publication-level classification system of science, J. Am. Soc. Inf. Sci. Technol. 63(12), 2378–2392 (2012)
N. Shibata, Y. Kajikawa, Y. Takeda, K. Matsushima: Comparative study on methods of detecting research fronts using different types of citation, J. Am. Soc. Inf. Sci. Technol. 60(3), 571–580 (2009)
B. Jarneving: A comparison of two bibliometric methods for mapping of the research front, Scientometrics 65(2), 245–263 (2005)
K. Börner: Atlas of Science: Visualizing What We Know (MIT Press, Cambridge 2010)
M. Zitt, E. Bassecoulard: Development of a method for detection and trend analysis of research fronts built by lexical or cocitation analysis, Scientometrics 30(1), 333–351 (1994)
L. Leydesdorff, I. Rafols: Interactive overlays: A new method for generating global journal maps from web-of-science data, J. Informetrics 6(2), 318–332 (2012)
L. Leydesdorff, P. Zhou: Nanotechnology as a field of science: Its delineation in terms of journals and patents, Scientometrics 70(3), 693–713 (2007)
K.W. Boyack: Investigating the effect of global data on topic detection, Scientometrics 111(2), 999–1015 (2017)
C. Bergstrom: Eigenfactor: Measuring the value and prestige of scholarly journals, College Res. Libr. News 68(5), 314–316 (2007)
M. Zitt, H. Small: Modifying the journal impact factor by fractional citation weighting: The audience factor, J. Am. Soc. Inf. Sci. Technol. 59(11), 1856–1860 (2008)
L. Waltman, N.J. van Eck, T.N. van Leeuwen, M.S. Visser: Some modifications to the SNIP journal impact indicator, J. Informatrics 7(2), 272–285 (2013)
M. Zitt, J.-P. Cointet: Citation impacts revisited: How novel impact measures reflect interdisciplinarity and structural change at the local and global level. In: ISSI'13: Proc. 14th Int. Conf. Int. Soc. Scientometr. Informetrics, Vienna, Austria 2013, ed. by J. Gorraiz, E. Schiebel (Austrian Institute of Technology, Vienna 2013) pp. 285–299
H. Small, E. Sweeney: Clustering the Science Citation Index® using co-citations: I. A comparison of methods, Scientometrics 7(3–6), 391–409 (1985)
T. Luukkonen, R.J.W. Tijssen, O. Persson, G. Sivertsen: The measurement of international scientific collaboration, Scientometrics 28(1), 15–36 (1993)
M. Zitt, E. Bassecoulard, Y. Okubo: Shadows of the past in international cooperation: Collaboration profiles of the top five producers of science, Scientometrics 47(3), 627–657 (2000)
K.W. Boyack, R. Klavans, K. Börner: Mapping the backbone of science, Scientometrics 64(3), 351–374 (2005)
G. Lewison, G. Paraje: The classification of biomedical journals by research level, Scientometrics 60(2), 145–157 (2004)
S. Teufel, J. Carletta, M. Moens: An annotation scheme for discourse-level argumentation in research articles. In: EACL'99: Proc. 9th Conf. Eur. Chap. Assoc. Comput. Linguistics, Bergen, Norway 1999, ed. by H.S. Thompson, A. Lascarides (ACL, Stroudsburg 1999) pp. 110–117
M. Liakata, S. Saha, S. Dobnik, C. Batchelor, D. Rebholz-Schuhmann: Automatic recognition of conceptualization zones in scientific articles and two life science applications, Bioinformatics 28(7), 991–1000 (2012)
S. Teufel, M. Moens: Summarizing scientific articles: Experiments with relevance and rhetorical status, Comput. Linguist. 28(4), 409–445 (2002)
C. Lyon, J. Malcolm, B. Dickerson: Detecting short passages of similar text in large document collections. In: EMNLP'01: Proc. Conf. Empirical Methods Natur. Lang. Process., Pittsburgh, PA 2001, ed. by L. Lee, D. Harman (ACL, Stroudsburg 2001) pp. 118–125
R. Cilibrasi, P.M.B. Vitányi: Clustering by compression, IEEE Trans. Inf. Theory 51(4), 1523–1545 (2005)
C.H. Bennett, P. Gács, M. Li, P.M.B. Vitányi, W.H. Zurek: Information distance, IEEE Trans. Inf. Theory 44(4), 1407–1423 (1998)
M. Li, X. Chen, X. Li, B. Ma, P.M.B. Vitányi: The similarity metric, IEEE Trans. Inf. Theory 50(12), 3250–3264 (2004)
R. Cilibrasi, P.M.B. Vitányi: The Google similarity distance, IEEE Trans. Knowl. Data Eng. 19(3), 370–383 (2007)
J. MacQueen: Some methods for classification and analysis of multivariate observations. In: Proc. 5th Berkeley Symp. Math. Statistics Probabilities, Durban, South Africa 1967, ed. by L.M. Le Cam, J. Neyman (Univ. California, Berkeley 1967) pp. 281–297
E.W. Forgy: Cluster analysis of multivariate data: Efficiency versus interpretability of classifications, Biometrics 21, 768–769 (1965)
N. Sahoo, J. Callan, R. Krishnan, G. Duncan, R. Padman: Incremental hierarchical clustering of text documents. In: CIKM'06: Proc. 15th ACM Int. Conf. Inf. Knowl. Manag., Arlington, VA 2006, ed. by P.S. Yu, V. Tsotras, E. Fox, B. Liu (ACM, New York 2006) pp. 357–366
H. Yu, D. Searsmith, X. Li, J. Han: Scalable construction of topic directory with nonparametric closed termset mining. In: ICDM'04: Proc. 4th IEEE Int. Conf. Data Mining, Brighton 2004, ed. by R. Rastogi, K. Morik, M. Bramer, X. Wu (IEEE, Los Alamitos 2004) pp. 1–4
F. Åström: Changes in the LIS research front: Time-sliced cocitation analyses of LIS journal articles, 1990–2004, J. Am. Soc. Inf. Sci. Technol. 58(7), 947–957 (2007)
D.M. Blei, J.D. Lafferty: Dynamic topic models. In: ICML'06: Proc. 23rd Int. Conf. Mach. Learning, Pittsburgh, PA 2006, ed. by W.W. Cohen, A. Moore (ACM, New York 2006) pp. 113–120
Q. Mei, C.X. Zhai: Discovering evolutionary theme patterns from text: An exploration of temporal text mining. In: KDD'05: Proc. 11th ACM SIGKDD Int. Conf. Knowl. Discov. Data Mining, Chicago, IL 2005, ed. by R.L. Grossman, R. Bayardo, K. Bennett, J. Vaidya (Association for Computing Machinery, New York 2005) pp. 198–207
F. Janssens, W. Glänzel, B. De Moor: Dynamic hybrid clustering of bioinformatics by incorporating text mining and citation analysis. In: KDD'07: Proc. 13th ACM SIGKDD Int. Conf. Knowl. Discov. Data Mining, San Jose, CA 2007, ed. by P. Berkhin, R. Caruana, X. Wu, S. Gaffney (Association for Computing Machinery, New York 2007) pp. 360–369
C. Chen, F. Ibekwe-SanJuan, J. Hou: The structure and dynamics of cocitation clusters: A multiple-perspective cocitation analysis, J. Am. Soc. Inf. Sci. Technol. 61(7), 1386–1409 (2010)
D. Chavalarias, J.-P. Cointet: Phylomemetic patterns in science evolution—the rise and fall of scientific fields, PLOS ONE 8(2), e54847 (2013)
S. Shane: Technological Opportunities and New Firm Creation, Manag. Sci. 47(2), 205–220 (2001)
K.B. Dahlin, D.M. Behrens: When is an invention really radical? Defining and measuring technological radicalness, Res. Policy 34(5), 717–737 (2005)
H. Small, H. Tseng, M. Patek: Discovering discoveries: Identifying biomedical discoveries using citation contexts, J. Informetrics 11(1), 46–62 (2017)
E. Garfield, I.H. Sher: KeyWords Plus™—algorithmic derivative indexing, J. Am. Soc. Inf. Sci. 44(5), 298–299 (1993)
R.N. Kostoff, J.A. del Río, J.A. Humenik, E.O. García, A.M. Ramírez: Citation mining: Integrating text mining and bibliometrics for research user profiling, J. Am. Soc. Inf. Sci. Technol. 52(13), 1148–1156 (2001)
B. Verspagen, C. Werker: The invisible college of the economics of innovation and technological change, Estudios de Economía Aplicada 21(3), 187–203 (1975)
D. D. Beaver, R. Rosen: Studies in scientific collaboration – Part I. The professional origins of scientific co-authorship, Scientometrics 1(3), 231–245 (1979)
T. Luukkonen, O. Persson, G. Sivertsen: Understanding patterns of international scientific collaboration, Sci. Technol. Hum. Values 17(1), 101–126 (1992)
H. Kretschmer: Coauthorship networks of invisible colleges and institutionalized communities, Scientometrics 30(1), 363–369 (1994)
J.S. Katz, B.R. Martin: What is research collaboration?, Res. Policy 26(1), 1–18 (1997)
J.S. Katz: Geographical proximity and scientific collaboration, Scientometrics 31(1), 31–43 (1994)
J. Hoekman, K. Frenken, R.J.W. Tijssen: Research collaboration at a distance: Changing spatial patterns of scientific collaboration within Europe, Res. Policy 39(5), 662–673 (2010)
T. Velden, A. Haque, C. Lagoze: A new approach to analyzing patterns of collaboration in co-authorship networks: Mesoscopic analysis and interpretation, Scientometrics 85(1), 219–242 (2010)
P. Mutschke, A.Q. Haase: Collaboration and cognitive structures in social science research fields. Towards socio-cognitive analysis in information systems, Scientometrics 52(3), 487–502 (2001)
J. Raffo, S. Lhuillery: How to play the “Names Game”: Patent retrieval comparing different heuristics, Res. Policy 38(10), 1617–1627 (2009)
K.W. McCain: The author cocitation structure of macroeconomics, Scientometrics 5(5), 277–289 (1983)
G.N. Gilbert: Referencing as Persuasion, Soc. Stud. Sci. 7(1), 113–122 (1977)
C. Roth, J.-P. Cointet: Social and semantic coevolution in knowledge networks, Soc. Netw. 32(1), 16–29 (2010)
X. Polanco, L. Grivel, J. Royauté: How to do things with terms in informetrics: Terminological variation and stabilization as science watch indicators. In: ISSI'95: Proc. 5th Int. Conf. Int. Soc. Scientometr. Informetrics, River Forest, IL 1995, ed. by M.E.D. Koenig, A. Bookstein (Learned Information, Medford 1995) pp. 435–444
M.F. Porter: An algorithm for suffix stripping, Program 14(3), 130–137 (1980)
L. Egghe, R. Rousseau: Introduction to Informetrics: Quantitative Methods in Library, Documentation, and Information Science (Elsevier, Amsterdam 1990)
K.W. McCain: Descriptor and citation retrieval in the medical behavioral sciences literature: Retrieval overlaps and novelty distribution, J. Am. Soc. Inf. Sci. 40(2), 110–114 (1989)
M.L. Pao: Term and citation retrieval: A field study, Inf. Process. Manag. 29(1), 95–112 (1993)
L. Bornmann, H.-D. Daniel: What do citation counts measure? A review of studies on citing behavior, J. Documentation 64(1), 45–80 (2008)
B. Cronin: The Citation Process: The Role Significance of Citations in Scientific Communication (Taylor Graham, London 1984)
H.G. Small: Cited documents as concept symbols, Soc. Stud. Sci. 8(3), 327–340 (1978)
B. Latour: Science in Action: How to Follow Scientists and Engineers Through Society (Harvard Univ. Press, Cambridge 1987)
A. Cambrosio, P. Keating, S. Mercier, G. Lewison, A. Mogoutov: Mapping the emergence and development of translational cancer research, Eur. J. Cancer 42(18), 3140–3148 (2006)
F. Narin, E. Noma: Is technology becoming science?, Scientometrics 7(3–6), 369–381 (1985)
M. Callon: Pinpointing industrial invention: An exploration of quantitative methods for the analysis of patents. In: Mapping the Dynamics of Science and Technology, ed. by M. Callon, J. Law, A. Rip (Macmillan, Houndmills, London 1986) pp. 163–188
V. Lariviére, É. Archambault, Y. Gingras: Long-term variations in the aging of scientific literature: From exponential growth to steady-state science (1900–2004), J. Am. Soc. Inf. Sci. Technol. 59(2), 288–296 (2008)
E.C.M. Noyons, R.K. Buter, A.F.J. van Raan, H. Schwechheimer, M. Winterhager, P. Weingart: The Role of Europe in World-Wide Science and Technology: Monitoring and Evaluation in a Context of Global Competition—Report for the European Commission (CWTS-Leiden, IWT-Bielefeld, Brussels 2000)
E.C.M. Noyons, R.K. Buter, A.F.J. van Raan, U. Schmoch, T. Heinze, S. Hinze, R. Rangnow: Mapping Excellence in Science and Technology Across Europe Nanoscience and Nanotechnology—Report of Project EC-PPN CT-2002-0001 to the European Commission (CWTS and Fraunhofer ISI, Leiden, Karlsruhe 2003)
M. Zitt, A. Lelu, E. Bassecoulard: Hybrid citation-word representations in science mapping: Portolan charts of research fields?, J. Am. Soc. Inf. Sci. Technol. 62(1), 19–39 (2011)
P. Laurens, M. Zitt, E. Bassecoulard: Delineation of the genomics field by hybrid citation-lexical methods: Interaction with experts and validation process, Scientometrics 82(3), 647–662 (2010)
S.A. Morris, G.G. Yen: Crossmaps: Visualization of overlapping relationships in collections of journal papers, Proc. Natl. Acad. Sci. 101(Suppl. 1), 5291–5296 (2004)
C. Reilly, C. Wang, M. Rutherford: A rapid method for the comparison of cluster analyses, Stat. Sin. 15(1), 19–33 (2005)
R. Klavans, K.W. Boyack: Toward a consensus map of science, J. Am. Soc. Inf. Sci. Technol. 60(3), 455–476 (2009)
L. Leydesdorff, I. Rafols: A global map of science based on the ISI subject categories, J. Am. Soc. Inf. Sci. Technol. 60(2), 348–362 (2009)
P. Ahlgren, B. Jarneving: Bibliographic coupling, common abstract stems and clustering: A comparison of two document-document similarity approaches in the context of science mapping, Scientometrics 76(2), 273–290 (2008)
E. Yan, Y. Ding: Scholarly network similarities: How bibliographic coupling networks, citation networks, cocitation networks, topical networks, coauthorship networks, and coword networks relate to each other, J. Am. Soc. Inf. Sci. Technol. 63(7), 1313–1326 (2012)
T. Velden, K.W. Boyack, J. Gläser, R. Koopman, A. Scharnhorst, S. Wang: Comparison of topic extraction approaches and their results, Scientometrics 111(2), 1169–1221 (2017)
H. Small: Co-Citation Context Analyses and the Structure of Paradigms, J. Documentation 36(3), 183–196 (1980)
H. Small: Maps of science as interdisciplinary discourse: Co-citation contexts and the role of analogy, Scientometrics 83(3), 835–849 (2010)
S. Teufel, A. Siddharthan, D. Tidhar: Automatic classification of citation function. In: EMNLP'06: Proc. Conf. Empirical Methods Nat. Lang. Process., Sydney, Australia 2006, ed. by D. Jurafsky, É. Gaussier (ACL, Stroudsburg 2006) pp. 103–110
A. Ritchie, S. Robertson, S. Teufel: Comparing citation contexts for information retrieval. In: CIKM'08: Proc. 17th ACM Conf. Inf. Knowl. Mining, Napa Valley, CA 2008, ed. by J.G. Shanahan, S. A.-Yahia, I. Manolescu, Y. Zhang, D.A. Evans, A. Kolcz, K.-S. Choi, A. Chowdury (Association for Computing Machinery, New York 2008) pp. 213–222
S. Liu, C. Chen: The differences between latent topics in abstracts and citation contexts of citing papers, J. Am. Soc. Inf. Sci. Technol. 64(3), 627–639 (2013)
H. Small: Interpreting maps of science using citation context sentiments: A preliminary investigation, Scientometrics 87(2), 373–388 (2011)
A. Elkiss, S. Shen, A. Fader, G. Erkan, D. States, D. Radev: Blind men and elephants: What do citation summaries tell us about a research article?, J. Am. Soc. Inf. Sci. Technol. 59(1), 51–62 (2008)
A. Callahan, S. Hockema, G. Eysenbach: Contextual cocitation: Augmenting cocitation analysis and its applications, J. Am. Soc. Inf. Sci. Technol. 61(6), 1130–1143 (2010)
X. He, C.H.Q. Ding, H. Zha, H.D. Simon: Automatic topic identification using webpage clustering. In: ICDM'01: Proc. Int. Conf. Data Mining, San Jose, CA 2001, ed. by N. Cercone, T.Y. Lin, X. Wu (IEEE, Los Alamitos 2001) pp. 195–202
S. Brin, L. Page: The anatomy of a large-scale hypertextual web search engine, Comp. Netw. ISDN Syst. 30(1–7), 107–117 (1998)
P. van den Besselaar, G. Heimeriks: Mapping research topics using word-reference co-occurrences: A method and an exploratory case study, Scientometrics 68(3), 377–393 (2006)
P. Ahlgren, C. Colliander: Document–document similarity approaches and science mapping: Experimental comparison of five approaches, J. Informetrics 3(1), 49–63 (2009)
F. Janssens, W. Glänzel, B. De Moor: A hybrid mapping of information science, Scientometrics 75(3), 607–631 (2008)
W. Glänzel, B. Thijs: Using “core documents” for the representation of clusters and topics, Scientometrics 88(1), 297–309 (2011)
R. Koopman, S. Wang, A. Scharnhorst: Contextualization of topics: Browsing through the universe of bibliographic information, Scientometrics 111(2), 1119–1139 (2017)
Y. LeCun: A path to AI. In: BAI'17: Workshop Beneficial Artif. Intell., Asilomar, CA 2017, ed. by E. Brynjolfsson, E. Horvitz, P. Norvig, F. Rossi, S. Russell, B. Selman (Future of Life Institute, Cambridge 2017), https://futureoflife.org/wp-content/uploads/2017/01/Yann-LeCun.pdf
R.R. Braam, H.F. Moed, A.F.J. van Raan: Mapping of science by combined co-citation and word analysis. I. Structural aspects, J. Am. Soc. Inf. Sci. 42(4), 233–251 (1991)
B. Larsen: Exploiting citation overlaps for information retrieval: Generating a boomerang effect from the network of scientific papers, Scientometrics 54(2), 155–178 (2002)
Y. Huang, J. Schuehle, A.L. Porter, J. Youtie: A systematic method to create search strategies for emerging technologies based on the Web of Science: Illustrated for “Big Data”, Scientometrics 105(3), 2005–2022 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer International Publishing AG, part of Springer Nature
About this chapter
Cite this chapter
Zitt, M., Lelu, A., Cadot, M., Cabanac, G. (2019). Bibliometric Delineation of Scientific Fields. In: Glänzel, W., Moed, H.F., Schmoch, U., Thelwall, M. (eds) Springer Handbook of Science and Technology Indicators. Springer Handbooks. Springer, Cham. https://doi.org/10.1007/978-3-030-02511-3_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-02511-3_2
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-02510-6
Online ISBN: 978-3-030-02511-3
eBook Packages: Economics and FinanceEconomics and Finance (R0)