
Abstract
In this paper a reduced complexity eye tracking technique is introduced. The proposed technique is based on a recently introduced eye localization method [5]. In order to exploit its accuracy and robustness under difficult illumination conditions, the presence of occlusions, shadows and pose variations, and making possible its use in real-time applications, we drastically reduce its computational cost while in the same time its accuracy is increased, by the use of an efficient tracking scheme. We also implement the proposed method in low-level C++ programming, using the OpenCV library, thus reducing even more its computational cost. All experiments we have conducted confirm our claims.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The tremendous progress of robotic systems over the last decades and their penetration in almost every aspect of the contemporary life has inevitably induced a growing interest in improving the Human-Robot Interaction (HRI). Except from the traditional input devices (keyboards, mouses, touch surfaces, sensors), an input modality which is lately gaining momentum is eye gaze. Systems that exploit the eye gaze, offer a convenient and natural means of interaction without the requirement of physical contact. Eyes constitute the most distinctive features of the human face, while the iris positions with respect to the head pose and gaze are significant sources of information regarding the cognitive and affective state of human beings. Specifically, the information about the location of the eyes centers are commonly used in applications such as face alignment, face recognition, human-computer interaction, human-robot interaction, control devices for disabled people, user attention and gaze estimation (e.g. driving and marketing) [1, 2]. Although many commercial products for eye detection and tracking are available in the market, they all require dedicated, high-priced hardware. The most common approaches in research and commercial systems use active infrared (IR) illumination, to obtain accurate eye location through corneal reflection [3], contact lenses and special helmets or glasses [4]. However, despite the sufficient accuracy of these systems, they cause discomfort to the users and introduce limitations for everyday applications. Thus, image and computer vision-based techniques constitute a challenge to incorporate the eye center and gaze information in many applications, where the use of extra dedicated hardware is impracticable. Despite the active research in this field, precise eye center localization and tracking remains a challenging problem due to many limitations that downgrade the accuracy of the detected eye centers. These limitations are related to the great variety in shape and color of human eyes, the eye state (open or closed), the iris direction, the facial expressions, the head pose etc. The localization accuracy can be also reduced under the presence of occlusions from hair, glasses, reflections and shadows and is strongly affected by the lighting conditions and the camera resolution. Precise eye localization and tracking problem becomes even more challenging in the cases of incorporating it into robotic systems, where of real-time performance is crucial. This constitutes the main motivation of this work, to speed-up our previously presented (precise eye localization) method [5] and introduce a reduced complexity eye tracking technique and an implementation of this in low-level C++ programming, using the OpenCV library.
2 Related Work
Over the last decades many techniques have been proposed in the literature for the eye center detection and its tracking. Eye localization methods, working under different illumination conditions, the presence of occlusions and shadows can be roughly divided into the following two main categories:
-
(i)
Feature-based methods and
-
(ii)
Appearance-based methods.
Feature based methods use a priori knowledge to detect candidate eye centers from simple pertinent features based on shape, geometry, color and symmetry. These features are obtained from the application of specific filters on the image and don’t require any learning or model fitting techniques. They are also robust to shape and scale changes. A number of methods have been employed trying to model the eye shape parametrically by matching a deformable template to the image and minimizing an energy based cost function [6, 7] thus achieving the desired localization. Exploiting the circularity of the iris, Hough transform is another widely used eye localization method [8, 9]. However, its use is constrained only in frontal or near frontal and well illuminated faces in high resolution images. The idea of isophote curvatures proposed by Valenti et al. [10,11,12] as a voting scheme for detecting eye locations. However, this method can lead to eyebrow or eye corner wrong detections when the number of features in the eye region is insufficient. To enhance this method Valenti in [12] proposed the use of the SHIFT descriptor and a k-NN based classifier in a machine learning framework. Filter responses and especially Gabor filters have attracted much popularity. Radial symmetry operators have also been studied and their use, mostly in combination with other operators, for the automatic eye detection has been proposed [15]. Yang et al. in [16] presented an algorithm for first detecting the eye region with Gabor filters and then localizing the center of the iris with the use of the radial symmetry operator. Unfortunately, the accuracy of this technique heavily depends on the location of the iris and rapidly degrades as it moves to the eye corners. In our previous work [5] we introduced a new high precision eye center localization technique, based on a modified version of the Fast Radial Symmetry Transform [13]. This method emphasizes on the shape of the iris, by computing the components of the transform from different modalities of the original image. In this way we succeeded to improve the accuracy of the eye center localizer and achieved precise localization even in the presence of strong photometric distortions, shadows and occlusions (e.g. glasses). Finally, color information has been used to distinguish the eye from the skin area. Skodras et al. in [14] proposed a method based on the synergy of color and radial symmetry of the eyes to localize their centers. However, the accuracy of this method degrades in the presence of glasses because often the color of the frame of the glasses and the iris are similar and therefore they equally enhanced by the eye map operator. In general, appearance based methods employ a prior model of the eye holistic appearance and surrounding structures and try to detect the location of the eyes by fitting the trained model. For this purpose, many machine learning algorithms have been proposed. Specifically, Niu et al. in [24] introduced a two-direction cascaded AdaBoost framework for eye localization, Campadelli et al. in [21] proposed an eye localization technique using a SVM trained on properly selected Haar wavelet coefficients, while techniques based on artificial neural networks, Bayesian models and hidden Markov models (HMM) were proposed in [17,18,19] and [20] respectively. Moreover, in [22] Pentland was the first who tried to describe facial eigenfeatures (i.e. eigeneyes, eigennoses, eigenmooths) using a multi-observer eigenspace technique. Wang et al. [23] proposed a method that first applies statistically learned non-parametric discriminant features to characterize eye patterns, then determines probabilistic classifiers to separate eye and non-eye features, and finally combines multiple classifiers in an AdaBoost framework to accurately detect the eye center. Despite their enhanced accuracy in detecting the eye area, in the case of pose and illumination variations the appearance-based methods fail to locate precisely the eye centers. In addition, a large amount of training data is required to be collected in order the high variability of the eyes to be reliably learned by the algorithms.
Eye tracking methods throughout the literature can be broadly divided in three main categories according to the representation of the target to be tracked:
-
(i)
Point Tracking
-
(ii)
Kernel Tracking
-
(iii)
Contour Tracking.
In point tracking, the eyes detected in consecutive frames are represented by points and the association of the points is based on the previous object state which can include object position and motion. Kim et al. in [25] locate the iris region using a contrast operator to amplify differences between the center and its neighboring region, and the detection accuracy is further enhanced using a Kalman tracker. In kernel tracking, the shape and appearance of the eyes are modeled. They are tracked by estimating the motion in consecutive frames and calculating an affine transformation between them. A real time tracking scheme using a mean-shift color tracker and an Active Appearance model is proposed in [26]. Tian et al. [27] propose a method of tracking the eye locations, detecting the eye states, and estimating its parameters. Finally, in contour tracking approaches the eyes are tracked using shape matching. The shape is usually a circle or an ellipse and tracking is performed by estimating the object region in each frame. Hansen and Pece [28] model the iris as an ellipse, fitting locally the ellipse to the image through an EM and RANSAC optimization scheme, while Wu et al. [29], track the iris contour as a 3D eye model in order to estimate gaze direction. The performance, in terms of accuracy, of our technique proposed in [5] seems to outperform all the aforementioned methods. In this paper, in order to incorporate this method into real-time applications and systems, we introduce a speed-up procedure and a tracking scheme. We also implement the proposed method in low-level C++ programming, using the OpenCV library, reducing in this way dramatically the speed of the computational time.
3 Proposed Algorithm
3.1 Precise Eye Center Localization
The proposed algorithm is based on the Precise Eye Center Localization Technique presented in [5]. The Eye Center Localization Technique is based on a two-stage modified radial symmetry transform (RST) that is used to localize the eye centers. This transform constitutes a voting procedure that emphasizes on circular shapes and exploits the symmetry of the eyes to detect precisely their centers. Every stage of the transform is applied to a different modality of the original image. Specifically:
-
(i)
The Magnitude-based RST is applied to the Red color component to take advantage of the enhanced contrast between the eyes and the skin.
-
(ii)
The Orientation-based RST is applied to the Self-Quotient Image [31] to take into consideration the edge-preserving filtering to distinguish the eye shape.
-
(iii)
The final result is calculated by adding the individual results from the Magnitude and Orientation Radial Symmetry Transforms, after their normalization.
The interested reader can refer to [5] for all the details of the algorithm.
3.2 Efficient Eye Center Tracking
The appearance of the same target in an image sequence is continuously affected by changes in lighting, occlusions, camera imperfections etc. Thus, the target is difficult to be detected precisely in every frame and the exploitation of temporal information can enhance the detection accuracy. Tracking is performed in order to smooth the eye detection noise by taking advantage from the continuity of the motion between successive frames. The eye localization method presented above achieves high accuracy even in the most challenging circumstances. However, it depends on the accuracy of the Viola and Jones face detector [30]. This means that the eye localizer cannot be applied when the face detector fails to detect the candidate face. Considering that the Viola and Jones presents reduced efficiency in the cases of non-frontal faces and pose variations, inevitably the eye localizer is also affected. However, this problem can be overcome in the case of a sequence of images by exploiting the information from the previous frames of the video. Considering that the positions of the eyes between the consecutive frames are moved imperceptibly, the eye ROIs can be selected regardless of the face detection results. In this way, the eye localizer becomes rotation invariant and achieves precise detection independently of the head pose variations.
3.3 Proposed Tracking Scheme
The proposed eye center tracking technique takes into consideration the previous eye center positions to define the next frame eye ROIs. These ROIs can appear in different levels, depending on the rotation of the head, and form an angle between the vertical axis and their line as shown in Fig. 1. This rotation angle \(\theta \) permits the tracking of the eyes in any pose and ensures that the entire eyes are inside the ROIs.

Rotation angle between the eye ROIs and the horizontal axis

The proposed eye tracking scheme

The proposed threshold prevents (frames shown in the second row) the ROIs selection from trapping (frames shown in the first row) due to inaccurate localizations (please see text)
The proposed eye center tracking technique consists of the following steps, also depicted in Fig. 2:
- \(S_1\)::
-
In the first step, the face is detected using the Viola and Jones detector and the two eye ROIs are selected.
- \(S_2\)::
-
Then, the precise eye center localization is performed and the two eye centers are detected at the positions where the modified RST attains its maximum values.
- \(S_3\)::
-
Finally, a threshold T is computed as the ratio of the global maximum \(M_1\) and the second in magnitude maximum \(m_1\) of the transform (Fig. 3), that is:
$$\begin{aligned} T=\frac{M_1}{m_1}. \end{aligned}$$(1)
By taking into account that the uncertainty of the correct detection is proportional to this ratio, the value of this threshold is crucial in avoiding errors propagation. When this ratio overcomes the defined threshold, the ROIs are defined using the Viola and Jones face detector, otherwise, they are selected based on the previous eye center positions. In this way, the Viola and Jones algorithm is used for ROIs correction only in the cases where the eyes are not clearly detected. The necessity of this correction is obvious in the example depicted in Fig. 4, where the ROIs in the case of not using it are trapped in an invalid area due to inaccurate eye localization (first row). However, the use of the threshold T can prevent these undesirable situations and preserve the entire eyes inside the ROIs (second row).

The ratio of the global maximum and the second in magnitude maximum, strongly affects the uncertainty of the detection (please see text)
4 Experimental Results
4.1 Parameters Specification
The set of radii N is selected based on the expected iris size in relation to the face dimensions. The minimum radius is defined as FaceWidth/60 and the maximum as FaceWidth/6. The threshold T is defined as \(T=0.8\), meaning that in the cases when the second maximum overcomes the \(80\%\) of the global maximum, the Viola and Jones algorithm will be used for error correction. This value results from the experiments performed in the Talking Face Video database, as it gives us better results in terms of accuracy.
4.2 Experimental Setup
In order to evaluate the performance of the proposed method, we have conducted several experiments in two publicly available face databases. Specifically, the selected Gi4E [32] and Talking Face Video databases are among the most challenging and characteristic datasets and were widely used in previous eye-center localization and tracking techniques.

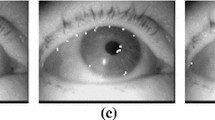
Precise eye center localization results
The Gi4E dataset consists of 1380 color images of 103 subjects of high resolution (800\(\,\times \,\)600). All the images are captured at indoor conditions with an illumination and background variation. The subjects are asked to look at 12 different points on the screen causing a wide pose variation. The head movements, lighting changes, movement of the eyes and eyelid occlusions compose realistic conditions for eye localization and tracking systems. The Talking Face video consists of 5000 frames (576\(\,\times \,\)720 pixels) taken from a person engaged in a natural conversation. The data set has also been tracked with an AAM using a 68 point model. Although the annotation was performed semi-automatically, it has been checked visually and is generally sufficiently accurate to represent the facial movements during the sequence. The main purpose of the database is to evaluate how tracking improves the eye localization procedure in a controlled indoor environment, simulating an office or a home workstation. The main challenges for eye localization on the Talking Face video stem from the unconstrained head motion and eye closures. In order to evaluate the accuracy of the proposed method a normalized error is adopted, representing the worst eye center estimation of the two eyes. The normalized error e is defined as [37]:
where, \(\tilde{C}_l,~\tilde{C}_r\) are the localized by the proposed method left and right eye center coordinates and \(C_l,~C_r\) are the manually labeled corresponding coordinates. The term in the denominator represents the distance between the two real eye centers and is used as a normalization factor for the localization error. The accuracy of the algorithm is expressed by the ratio of the number of the eye center localizations that fall below the assigned error threshold and their total number. Finally, the threshold \(e\le 0.25\) represents the distance between the eye center and the eye corners, the \(e\le 0.1\) represents the range of the iris and the \(e\le 0.05\) represents the pupil area.
4.3 Results
The evaluation of the proposed method leads us to the conclusion of a robust and highly precise localization method. The method deals successfully with the most challenging circumstances including shadows, pose variations, occlusions by hair or strong reflections, out-of-plane rotations and presence of glasses (Fig. 5). The proposed method fails to accurately locate the eye centers only in cases when the eyes are totally closed and in extreme cases of irregular illuminations, shadows and occlusions where the eyes can be semi-hidden. A comparison of the proposed method with the state of the art methods is carried out and the results are presented on the following table. Table 1 provides supporting evidence that the eye localization method outperforms its rivals. This table contains the results, in terms of the accuracy, obtained from the application of the proposed method in Gi4E face database. Due to high resolution images and absence of occlusions and irregular illuminations, the proposed method achieves almost accurate localization in every error category.
To consistently evaluate the improvement in performance using the proposed tracking scheme, experiments were performed in the Talking Face Video database. The performance of the eye localization method was compared against the basic Kalman filter approach, and the proposed eye tracking method. Table 2 presents the tracking results for the Talking Face, where there is an advantage improvement for all normalized errors. This improvement stems from the fact that, in the cases of head pose rotations, the eyes are reaching the ROIs limits and the accuracy of the detection is degraded. Instead, the proposed tracking scheme reassures that the entire eyes will be included inside the ROIs, even in great rotation angles. It should be also noted that the upper limit in the accuracy of eye localization was almost reached using detection only and thus the margin for improvement using the proposed tracking is limited.
4.4 Low Level \(C_{++}\) Implementation and Speed-Up Procedure
In order to reduce the computational time, it is possible to use a non-continuous integer values between the defined limits without any noticeable loss of accuracy. Moreover, the set of the used radii N could be restricted between the limits FaceWidth/45 for the minimum radius and the FaceWidth/15 for maximum one, reducing in this way even more the computational complexity. The proposed eye tracking scheme does not provide only enhanced accuracy, especially in the cases of great rotations and pose variations, but also decreases the computational cost of the technique. This happens because the face detection step using the Viola and Jones detector is not performed and instead, the selection of the ROIs is based on the previous eye center positions. To quantify this claim, experiments performed in the Talking Face Video database shows that the proposed tracking scheme provides reduced complexity by decreasing the computational time for \(12\%\). This percentage will be increased in the cases of lower resolution images, as the proposed eye localization speed is proportionate to the resolution of the image. Furthermore, the proposed method is implemented in low level \(C_{++}\) programming, using the OpenCV library. This implementation is tested on an intel i7 system (single core implementation) and achieved real-time performance with a frame rate between 16–20 fps for \( 800 \times 600\) pixels video resolution. This variation stems from the distance variations between the face and the camera and thus the resolution variations of the face image.
The \(C_{++}\) code is publicly available in the web site of the Signal Processing and Communications lab.Footnote 1
5 Conclusion
In this paper, an eye tracking technique of reduced complexity was introduced, based on a recently proposed eye localization method. The new tracking scheme was achieving higher accuracy and robustness in challenging conditions with a lower computational cost. The proposed method was implemented in low-level C++ programming, using the OpenCV library, thus its execution time was drastically reduced. In all experiments were conducted, the real time performance and the enhanced accuracy of the proposed tracker was confirmed.
References
Ghinea, G., Djeraba, C., Gulliver, S., Coyne, K.P.: Introduction to the special issue on eye-tracking applications in multimedia systems. ACM Trans. Multimedia Comput. Commun. Appl. 3(4) (2007)
Bohme, M., Meyer, A., Martinetz, T., Barth, E.: Remote eye tracking: state of the art and directions for future development. In: Conference on Communication by Gaze Interaction (2006)
Morimoto, C.H., Koons, D., Amir, A., Flickner, M.: Pupil detection and tracking using multiple light sources. Image Video Comput. 18, 331–335 (2000)
Orman, Z., Battal, A., Kemer, E.: A study on face, eye detection and gaze estimation. Int. J. Comput. Sci. Eng. 2, 29–46 (2011)
Poulopoulos, N., Psarakis, E.Z.: A new high precision eye center localization technique. In: International Conference on Image Processing (ICIP), Beijing, China, pp. 2806–2810 (2017)
Yuille, A., Hallinan, P., Cohen, D.: Feature extraction from faces using deformable templates. Int. J. Comput. Vis. 8(2), 99–111 (1992)
Xie, X., Sudhakar, R., Zhuang, H.: On improving eye feature extraction using deformable templates. Pattern Recogn. 27(6), 791–799 (1994)
Dobes, M., Martinek, J., Skoupil, D., Dobesova, Z., Pospisil, J.: Human eye localization using the modified Hough transform. Optik Int. J. Light Electron Opt. 117(10), 468–473 (2006)
Van Huan, N., Kim, H.: A novel circle detection method for iris segmentation. In: 2008 Congress on Image and Signal Processing, CISP 2008, vol. 3, pp. 620–624. IEEE (2008)
Valenti, R., Gevers, T.: Accurate eye center location and tracking using isophote curvature. In: International Conference on Computer Vision and Pattern Recognition (CVPR 2008), pp. 1–8. IEEE (2008)
Valenti, R., Yucel, Z., Gevers, T.: Robustifying eye center localization by head pose cues. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2009, pp. 612–618. IEEE (2009)
Valenti, R., Gevers, T.: Accurate eye center location through invariant isocentric patterns. IEEE Trans. Pattern Anal. Mach. Intell. 34(9), 1785–1798 (2012)
Loy, G., Zelinsky, A.: Fast radial symmetry for detecting points of interest. IEEE Trans. Pattern Anal. Mach. Intell. 25, 959973 (2003)
Skodras, E., Fakotakis, N.: Precise localization of eye centers in low resolution color images. Image Vision Comput. J. 36, 51–60 (2015)
Bai, L., Shen, L., Wang, Y.: A novel eye location algorithm based on radial symmetry transform. In: International Conference on Pattern Recognition (ICPR 2006), vol. 3, pp. 511–514. IEEE (2006)
Yang, P., Du, B., Shan, S., Gao, W.: A novel pupil localization method based on GaborEye model and radial symmetry operator. In: International Conference on Image Processing (ICIP 2004), vol. 1, pp. 67–70. IEEE (2004)
Zhu, Z., Ji, Q.: Eye and gaze tracking for interactive graphic display. Mach. Vis. Appl. 15(3), 139–148 (2004)
Peixoto, H.M., Guerreiro, A.M.G., Neto, A.D.D.: Image processing for eye detection and classification of the gaze direction. In: 2009 International Joint Conference on Neural Networks, pp. 2475–2480. IEEE (2009)
Everingham, M., Zisserman, A.: Regression and classification approaches to eye localization in face images. In: 2006 7th International Conference on Automatic Face and Gesture Recognition, FGR 2006, pp. 441–446. IEEE (2006)
Samaria, F., Young, S.: Hmm-based architecture for face identification. Image Vis. Comput. 12(8), 537–543 (1994)
Campadelli, P., Lanzarotti, R., Lipori, G.: Precise eye localization through a general-to specific model definition. In: BMVC, vol. 1, pp. 187–196. Citeseer (2006)
Pentland, A., Moghaddam, B., Starner, T.: View-based and modular eigenspaces for face recognition. In: 1994 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Proceedings CVPR 1994, pp. 84–91. IEEE (1994)
Wang, P., Green, M.B., Ji, Q., Wayman, J.: Automatic eye detection and its validation. In: IEEE Workshop on Face Recognition Grand Challenge Experiments, p. 164 (2005)
Niu, Z., Shan, S., Yan, S., Chen, X., Gao, W.: 2D cascaded adaboost for eye localization. In: ICPR (2006)
Kim, B.S., Lee, H., Kim, W.Y.: Rapid eye detection method for non-glasses type 3D display on portable devices. IEEE Trans. Consum. Electron. 56, 2498–2505 (2010)
Hansen, D.W., Nielsen, M., Hansen, J.P., Johansen, A.S., Stegmann, M.B.: Tracking eyes using shape and appearance. In: MVA, pp. 201–204 (2002)
Tian, Y.L., Kanade, T., Cohn, J.F.: Dual-state parametric eye tracking. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition, pp. 110–115 (2000)
Hansen, D.W., Pece, A.E.: Eye tracking in the wild. Comput. Vis. Image Underst. 98, 155–181 (2005)
Wu, H., Kitagawa, Y., Wada, T., Kato, T., Chen, Q.: Tracking iris contour with a 3D eye-model for gaze estimation. In: Computer Vision-ACCV, pp. 688–697 (2007)
Viola, P., Jones, M.: Robust real-time face detection. Int. J. Comput. Vis. 57(2), 137–154 (2004)
Wang, H., Li, S.Z., Wang, Y., Zhang, J.: Self quotient image for face recognition. In: ICIP, vol. 2, pp. 1397–1400 (2004)
Anjith, G., Routray, A.: Fast and accurate algorithm for eye localization for gaze tracking in low resolution images. arXiv preprint arXiv:1605.05272 (2016)
Baek, S.-J., Choi, K.-A., Ma, C., Kim, Y.-H., Ko, S.-J.: Eyeball model-based iris center localization for visible image-based eye gaze tracking systems. IEEE Trans. Consum. Electron. 59(2), 415–421 (2013)
Daugman, J.: How iris recognition works. IEEE Trans. Circ. Syst. Video Technol. 14(1), 21–30 (2004)
Wang, J., Sung, E., Venkateswarlu, R.: Eye gaze estimation from a single image of one eye. In: 2003 Proceedings of the Ninth IEEE International Conference on Computer Vision, pp. 136–143. IEEE (2003)
Jesorsky, O., Kirchbergand, K.J., Frischholz, R.: Robust face detection using the Hausdorff distance. In: Audio and Video-Based Biometric Person Authentication, pp. 90–95 (1992)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Poulopoulos, N., Psarakis, E.Z. (2019). Real Time Eye Localization and Tracking. In: Aspragathos, N., Koustoumpardis, P., Moulianitis, V. (eds) Advances in Service and Industrial Robotics. RAAD 2018. Mechanisms and Machine Science, vol 67. Springer, Cham. https://doi.org/10.1007/978-3-030-00232-9_59
Download citation
DOI: https://doi.org/10.1007/978-3-030-00232-9_59
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00231-2
Online ISBN: 978-3-030-00232-9
eBook Packages: EngineeringEngineering (R0)