
Abstract
Quantitative understanding of the mechanical behavior of the external and middle ear is important, not only in the quest for improved diagnosis and treatment of conductive hearing loss but also in relation to other aspects of hearing that depend on the conductive pathways. Mathematical modeling is useful in arriving at that understanding. This chapter starts with some background modeling topics: the modeling of three-dimensional geometry and of material properties and the verification and validation of models, including uncertainty analysis and parameter fitting. The remainder of the chapter discusses models that have been presented for the external ear canal, middle ear air cavities, eardrum, ossicular chain, and cochlea. The treatment deals mainly with circuit models and finite-element models and to a lesser extent with two-port, rigid-body, and analytical models. Nonlinear models are discussed briefly. The chapter ends by briefly discussing the application of modeling to pathological conditions, some open questions in middle ear modeling, and the disadvantages and advantages of the finite-element method.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others
Keywords
- Air cavities
- Circuit models
- Eardrum
- External ear canal
- Finite-element models
- Image segmentation
- Material properties
- Mathematical models
- Mesh generation
- Ossicular chain
- Parameter fitting
- 3-D shape measurement
- Tympanic membrane
- Uncertainty analysis
- Verification and validation
7.1 Introduction
Quantitative understanding of the mechanical behavior of the external and middle ear is important, not only in the quest for improved diagnosis and treatment of conductive hearing loss but also in relation to other aspects of hearing that depend on the conductive pathways. Mathematical modeling is useful in arriving at that understanding.
The middle ear is of course more than just a mechanical system: it has physiological aspects (e.g., muscle contraction, healing) and biochemical aspects (e.g., gas exchange) that directly affect its mechanical behavior. Even when it is studied only from a mechanical point of view, however, it presents considerable challenges. For one thing, it has a complicated and irregular geometry involving a number of distinct structures encompassing a wide range of sizes. Its overall dimensions are in the range of tens of millimeters but it has important dimensions measured in micrometers (e.g., the thickness of the eardrum). One can go even further down the scale and consider the dimensions of the collagen fibers that are mechanically important in the eardrum. The displacements that one must be able to measure to characterize middle ear mechanics are as small as nanometers in response to sound pressures but as large as millimeters in response to static pressures. The time scales for the mechanical responses of the middle ear range from tens of microseconds for high-frequency sounds to tens of seconds for changes of static pressure, and even millions of seconds for the mechanical changes involved in development and healing.
The challenge of the external and middle ear is increased by the many different tissue types involved with very different mechanical behaviors: bone; fibrous connective tissue, with its collagen, elastin, and ground substance; muscle, both striated and smooth; cartilage, both calcified and uncalcified; and synovial fluid. The mechanical properties of low-density air (in the canal and cavities) and high-density water (in the cochlea) are also involved.
This chapter starts by reviewing some background modeling topics: Sects. 7.2 and 7.3 discuss some general issues related to the modeling of geometry and of material properties as required for realistic models, while Sect. 7.4 is a discussion of model verification and validation, including the issues of uncertainty analysis and parameter fitting. (See Funnell et al. (2012) for a tutorial review of the underlying mechanical principles and modeling approaches.) Sect. 7.5 is a review of models that have been presented for the outer and middle ear, divided into canal, air cavities, eardrum, ossicular chain, and cochlea, followed by a very brief treatment of nonlinearity. The chapter ends with the discussion in Sect. 7.6.
7.2 Geometry Modeling
Realistic modeling requires more or less accurate three-dimensional (3-D) shapes. This section includes a brief and qualitative review of the sources of such shape data, and then a discussion of the processing required for preparation of the geometric meshes used in finite-element models.
7.2.1 Sources of Shape Data
This section discusses various sources of 3-D shape data. Most of the techniques involve cross-sectional images of some kind, but section “Surface-Shape Measurement” includes techniques that work directly from the surfaces of objects. Decraemer et al. (2003) presented a brief overview of some of these methods as used in the middle ear. Clinical techniques are reviewed by Popelka and Hunter in Chap. 8.
7.2.1.1 Light Microscopy
Precise 3-D shape data may be obtained from serial-section histology. This technique is very time consuming and involves many processing steps: fixation, decalcification, dehydration, embedding, sectioning, staining, and mounting. Some of these processes can be automated (e.g., Odgaard et al. 1994). The embedding step may be replaced by freezing. Histology is particularly challenging for the ear because the petrosal part of the temporal bone is very dense and hard; because the eardrum is unsupported and extremely thin; and because the ossicles are suspended in air by small ligaments.
It is challenging to make 3-D reconstructions from histological sections because of the need to align the images to one another. The alignment problem is made worse by the fact that individual sections are typically stretched, folded, and torn in unpredictable ways. The processing also involves some degree of tissue shrinkage (e.g., Kuypers et al. 2005a for the eardrum). Alignment problems can be reduced by photographing the surface of the tissue block as each successive slice is removed (e.g., Sørensen et al. 2002; Jang et al. 2011), but the resolution is limited to that of the camera.
In confocal microscopy the sectioning is done optically by using pinhole apertures or very narrow slits (e.g., Koester et al. 1994). This technique is often combined with the use of fluorescent dyes. The effectiveness of optical sectioning can be greatly improved by the use of multiphoton microscopy. In second-harmonic generation (SHG) and third-harmonic generation (THG) microscopy, two or three photons are transformed into one photon with two or three times the energy (e.g., Sun 2005). Because the amount of energy emitted is the same as the amount of energy absorbed, there is no net energy absorption and the photo-bleaching and damage problems of conventional fluorescence do not occur. Jackson et al. (2008) used a combination of two-photon fluorescence and SHG to visualize collagen fibers in human eardrums. Lee et al. (2010) used SHG and THG on the rat eardrum; unlike previous users of confocal microscopy, they did not need to excise and flatten the eardrum, so they could observe the conical shape of the drum as well as its thickness and layered structure.
Optical coherence tomography (OCT) obtains the effect of optical sectioning by effectively measuring the different travel times of light reflected from different depths, either directly in the time domain or in the frequency domain (Fercher 2010; Wojtkowski 2010). OCT has shown promise in imaging the middle ear (Just et al. 2009) and can also be used for vibration measurements (Subhash et al. 2012).
These various types of optical sectioning can be used in vivo, and much effort is being put into minimizing the amount of light required and maximizing the speed with which changes can be tracked (e.g., De Mey et al. 2008; Carlton et al. 2010).
Another light-microscopy technique is orthogonal-plane fluorescence optical sectioning (OPFOS), in which the effect of sectioning is obtained by shining a thin sheet of laser light through the specimen from the side. Voie et al. (1993) introduced the use of this technique for the inner ear, and Buytaert et al. (2011) have developed a higher-resolution version and applied it to the middle ear. It requires tissue processing similar to that required for histological sections, but it provides very high resolution without any of the alignment problems associated with physical sections.
7.2.1.2 X-Ray Computed Tomography
X-rays can provide information about the interiors of solid objects because they penetrate further than visible light does. Computed tomography (CT) uses image-processing algorithms to combine multiple X-ray images, from many different angles around an object, to produce cross-sectional images of the interior. Compared with histology, this provides the dramatic advantages that it is not necessary to physically cut (and thus destroy) the object, and that there are no alignment problems at all.
The spatial resolution of current clinical CT scanners is such that the outer ear and the general form of the middle ear air cavities are fairly clear (e.g., Egolf et al. 1993), but few details of the ossicles can be seen and none of the ligaments (e.g., Lee et al. 2006). However, Vogel and Schmitt (1998) demonstrated the use of a “microfocus” X-ray tube for microtomography for the ear. At about the same time, Sasov and Van Dyck (1998) described a desktop microCT scanner built with commercially available components and demonstrated its use for the ear. That scanner was quickly used to support the analysis of middle ear vibration measurements (Decraemer and Khanna 1999). Several models of microCT scanner are now commercially available and further development continues (e.g., Salih et al. 2012). Resolutions down to a few micrometers can be obtained for small, dissected specimens; scan times tend to be tens of minutes.
X-ray absorption increases as bone density increases, and this can be used to estimate variations of Young’s modulus within a bone. This is often done for large bones and has been attempted for the middle ear ossicles (Yoo et al. 2004).
One limitation of current microCT scanners is that their X-ray sources produce a fairly broad band of frequencies. The fact that softer (lower-frequency) X-rays are absorbed more than harder ones leads to a phenomenon known as beam hardening, which causes image artifacts that are difficult to avoid. It is possible to filter out some of the softer X-rays, but this greatly reduces the already limited intensity of the beam. Synchrotron radiation, however, although available only in a few centers, provides very bright and highly collimated X-ray beams, with a very narrow (practically monochromatic) frequency range. Vogel (1999) used it for the middle and inner ear. Both absorption-contrast and phase-contrast modes can be used. It is possible to use multiple beam energies and to combine the individual gray-scale images to produce false-color images. Synchrotron-radiation CT has not been much used for the middle ear, but the appearance of some recent papers (Neudert et al. 2010; Kanzaki et al. 2011) suggests that it may become more common.
The resolutions of clinical CT scanners will continue to improve, and hand-held X-ray scanners are possible (Webber et al. 2002).
7.2.1.3 Magnetic Resonance Imaging
The resolution of current clinical magnetic resonance (MR) imaging is even lower than that of clinical X-ray CT. However, Johnson et al. (1986) first reported on MR “microscopy” using a modified clinical MR scanner. The resolution that is obtained can be improved by attention to many factors, including smaller coils (and thus smaller specimens), more averaging (and thus longer acquisition time), higher magnetic-field gradients, and larger image-matrix size. In that year, three different groups reported resolutions of tens of micrometers in two axes but hundreds of micrometers in the third axis (e.g., Johnson et al. 1986). The resolutions that they achieved depended in part on what they chose to image. Within a few years, Henson et al. (1994) obtained an isotropic voxel size of 25 × 25 × 25 μm in the ear.
MR imaging provides good contrast between different types of soft tissue. Although MR images are inherently monochromatic, multiple data-acquisition parameters can be used to emphasize different tissue types and the individual gray-scale images can be combined to produce false-color images. Given that MR depends on the presence of protons (e.g., Reiser et al. 2008), it provides practically no contrast between air and cortical bone because neither has many protons. This is a problem for imaging the middle ear air space and ossicles but it can be circumvented by filling the air cavities with a liquid gadolinium–based contrast agent (Wilson et al. 1996). The filling has to be done very carefully to avoid air bubbles, and it is likely to displace the eardrum significantly.
MR scanners, both clinical and microscopic, are more expensive and less widely available than their X-ray CT counterparts but are becoming more common.
7.2.1.4 Electron Microscopy
Electron microscopy (EM) can provide much higher spatial resolutions than light microscopy, but there is no possibility of using different stains to enhance contrast. Scanning EM is analogous to looking at solid objects under a microscope by reflected light, while transmission EM is analogous to looking at histological sections. EM is currently the method of choice for imaging details like the fibrous ultrastructure of the eardrum (e.g., Lim 1995). 3-D reconstructions have been performed using both physical sectioning with scanning EM (Denk and Horstmann 2004) and computed tomography with transmission EM (e.g., Koning and Koster 2009). In addition to electrons, various ions can be used for surface microscopy, and helium ions are particularly attractive (e.g., Bell 2009).
7.2.1.5 Ultrasound
Conventional ultrasound imaging has not had high enough resolution for use in the ear, but high-frequency ultrasound has recently shown promise (Brown et al. 2009). One disadvantage is that it does not work with structures in air.
7.2.1.6 Surface-Shape Measurement
In addition to the use of sequences of cross-sectional images, shape can also be measured from purely surface measurements. Surface shape can be measured optically by taking advantage of small depths of focus and varying the position of the focal plane (e.g., Danzl et al. 2011). With larger depths of focus it is possible to reconstruct the 3-D shape of an object from photographs taken from multiple orientations, even without knowledge of the camera positions (Snavely et al. 2008). This can also be done with tilted images from scanning electron microscopy.
Many other optical methods for surface-shape measurement exist, including moiré topography and laser range finding, which are mentioned in section “Finite-Element Models” as having been used for the eardrum, and estimation from silhouettes (e.g., Weistenhöfer and Hudde 1999 for the ossicles). The concepts of plenoptic functions and light fields, combined with the availability of microlens arrays, make 3-D photography and microscopy possible (e.g., Georgiev et al. 2011).
Techniques that have been used for the inside surfaces of cavities, such as the external ear canal, include the use of molds (Stinson and Lawton 1989), acoustical measurements (Hudde 1983), and fluorescence (Hart et al. 2010). Information about surfaces, such as texture, can be obtained using, for example, near-field optical techniques (e.g., Novotny 2011) and tactile techniques, including atomic force microscopy (e.g., Leach 2010).
7.2.2 Model Creation
7.2.2.1 Introduction
“Why is building 3D content so expensive and time-consuming?” Polys et al. (2008, p. 94) answer their own question largely in terms of the variety of approaches used and the lack of standards, but part of the answer is simply that building 3-D models is hard. The difficulty is especially great when dealing with complex dynamic natural structures (anatomical, biological, geological, etc.) composed of large numbers of irregular and inhomogeneous parts that are attached to multiple other parts at shared surfaces, which themselves have arbitrarily complex shapes.
Faithful models of natural structures must be created from experimental shape data, often in the form of sets of images of parallel sections, whether derived from physical cutting or from tomographic imaging. The process of creating 3-D models from such data may be considered to consist of four steps: (1) definition of relationships, (2) segmentation, (3) surface generation, and (4) volume mesh generation. These four steps are briefly discussed in sections “Relationships,” “Segmentation,” “Surface Generation,” and “Volume Mesh Generation.” In view of the considerable anatomical variability among individual ears, it is important to make the creation of models easier than it now is.
7.2.2.2 Relationships
Three types of relationships are relevant here. The first type involves an object hierarchy (e.g., manubrium is part of malleus). In making models from 3-D image data, this type of hierarchy has generally been dealt with on a voxel-by-voxel basis (e.g., Gehrmann et al. 2006) rather than with the more efficient surface or solid models used in computer-aided design (CAD). The second type of relationship involves a class hierarchy (e.g., cortical bone is a kind of bone). This type of hierarchy has not generally been made explicit—both a cause and an effect of the fact that models have been oversimplified. It is also complicated to simultaneously handle both types of relationships systematically (e.g., Cerveri and Pinciroli 2001). The third type of relationship concerns physical attachments (e.g., a surface shared between tendon and bone). These relationships have generally been ignored because they are not necessary for the visualization of static models, but they are very important for interactive and dynamic models. They also make it much easier to create variants of a model to represent, for example, anatomical variability or pathological cases.
7.2.2.3 Segmentation
Segmentation involves identifying the outlines of structures of interest within images. Considerable research has been and is being done on methods for automatic segmentation (e.g., Zhang 2006, Chap. 1). Most currently available systems represent individual structures either by filled regions or by closed contours. In neither case is it possible to explicitly represent the shared surface between two adjoining structures, often resulting in unwanted gaps or overlaps. The use of explicitly connected open contours can address this problem, as well as the representation of very thin structures like the eardrum (Decraemer et al. 2003).
Automatic techniques are fast but so far are successful only for relatively simple segmentation tasks (e.g., distinguishing between bone and non-bone). Even an image that seems very easy to segment may be very difficult for an automatic algorithm. The human visual system after all is very good at pattern recognition (e.g., von Ahn et al. 2008), sometimes too good (e.g., Lowell 1908).
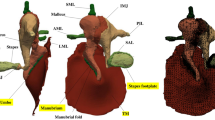
It is generally accepted that manual intervention is often required, and attention is increasingly being given to integrating user interaction with powerful segmentation tools (e.g., Liang et al. 2006). Figure 7.1a shows an example of semi-automatic 2-D segmentation. Often what is needed is 3-D segmentation, and applying 2-D algorithms slice by slice often gives poor results. Fully 3-D algorithms are available but tend to be difficult to visualize and control.

Examples of stages in finite-element modeling of gerbil middle ear. (a) Example of semi-automatic 2-D segmentation of microCT data. Red = malleus, green = incus. The image in which the segmentation is done has been median filtered; the side-view images have not. (b) Surface meshes generated from results of segmentation. Red = malleus, green = incus, blue = pars flaccida. (c) Volume mesh of incus, with some elements removed to show that the interior is filled with tetrahedra
7.2.2.4 Surface Generation
Surface generation often involves the generation of triangular meshes. Voxel-based algorithms such as “marching” cubes (Schroeder et al. 1996) or tetrahedra (Bourke 1997) must typically be followed by a step to greatly reduce the number of polygons, and automatic polygon-reduction algorithms often give unsatisfactory results, with many unnecessary polygons in some regions and/or excessive loss of detail in other regions. One also generally loses the original serial-section slice structure.
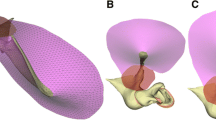
Alternatively, the surface can be formed by triangulating at the desired resolution between vector-based contours in different slices. Figure 7.1b shows surfaces created in this way. Determining which of the many possible triangulations to use can be done heuristically or by globally minimizing a cost function, but the choice of cost function can have a drastic effect on the quality of the triangulation (e.g., Funnell 1984). The quality is critical if the model is to be used for simulation and not just for visualization. For an extended, thin structure like the eardrum, the smoothness of the surface mesh is critical to its mechanical behavior; any local curvature will have a strong effect, as do ripples on a potato chip.
7.2.2.5 Volume Mesh Generation
Volume mesh generation involves creating a mesh of solid elements (e.g., hexahedra, tetrahedra) to fill the volume enclosed by a surface mesh, as shown in Fig. 7.1c. This is necessary for many applications, including finite-element modeling. A great deal of work has been done on methods for 3-D mesh generation but research continues, especially for image-based models (e.g., Young et al. 2008).
Meshes to be used for finite-element modeling must fulfill certain requirements. First, they must be topologically correct, that is, there must be no overlaps between neighboring elements and no unintended gaps. Second, the elements must not be too long and thin, because this leads to numerical problems when doing the finite-element calculations. Third, the mesh must be fine enough to avoid excessive discretization errors but not so fine as to require excessive computation. On the one hand, a mesh that is too coarse will usually tend to lead to model behavior that is too stiff. On the other hand, the computational requirements increase dramatically as the number of elements increases. Figure 7.2 shows an eardrum model with three different mesh resolutions, and the resulting low-frequency displacement patterns. Higher frequencies will lead to more complicated patterns that require finer meshes. The trade-off between accuracy and computational expense must be judged according to the requirements of the analysis, and it is often desirable to make the mesh finer in some parts of the model than in others. It is important to undertake convergence testing, that is, to test a model with varying mesh resolutions, under a variety of load conditions, to make sure that the mesh is acceptable. Automatic mesh-generation software makes it feasible to generate meshes of varying coarseness for such testing.

Finite-element models of eardrum and corresponding low-frequency displacement patterns, with three different mesh resolutions: nominally 10, 20, and 60 elements/diameter. The elements (triangles) are indicated by gray lines. Displacements are color coded from black (zero) to white (maximum). The finer meshes produce more accurate displacement patterns
7.2.2.6 Software
The software used for creating 3-D models may be divided into three classes: (1) CAD software intended for design and manufacturing, (2) software for the artistic “design” of naturalistic objects, and (3) software specifically intended for the reconstruction of natural objects. Class 1 is taken here to include the model-generation facilities built into many finite-element packages. Currently, none of these three classes is very well equipped to handle complex natural systems. In class 1, some CAD software can deal with relationships among parts in complex assemblies, but (a) the multiple parts are simply adjacent or in contact, or perhaps occasionally bonded at simple interface surfaces; and (b) such software is not well suited to modeling arbitrary natural shapes. Software in class 2 is generally intended only for visualization; relationships among multiple parts, if handled at all, are generally limited to interactions between geometric control points. Software in class 3 is generally intended only for visualization and for quantification of properties such as length and volume. Some software does exist for deriving finite-element models from imaging data but such software generally does not attempt to model the physical interactions and relationships among multiple component parts with widely varying sizes and properties.
7.3 Material Modeling
To take full advantage of the power of the finite-element method, one should have a priori information about the material properties, rather than simply adjust parameters to fit particular experimental results. There are many different materials involved in the outer and middle ear, including air, bone, ligament, tendon, muscle, cartilage, synovial fluid, epithelium, mucosa, fat, and nerve, as well as specialized structures such as the lamina propria of the eardrum and the fibrocartilaginous ring. The connective-tissue components include various forms, both dense and loose, and with both regularly and irregularly organized fibers.
Until recently the only explicit measurements of middle ear material properties were for the eardrum (e.g., von Békésy 1949; Kirikae 1960; Wada et al. 1996) and the interpretation of even those data requires great care (e.g., Fay et al. 2005). In the past few years, material properties have been measured for other middle ear structures (e.g., Cheng and Gan 2007; Soons et al. 2010) and a variety of new techniques have been used for the eardrum (e.g., Luo et al. 2009; Zhang and Gan 2010; Aernouts and Dirckx 2012). With care, values can also be estimated from measurements in supposedly similar tissues elsewhere in the body.
The purpose here is not to review these different measurements but to summarize the ways in which material properties are represented in finite-element models. Issues of tissue nonuniformity and inhomogeneity are not addressed here. They can be handled either by benign neglect, by averaging, or by applying different material properties to different elements in the finite-element mesh.
Also ignored here are many biomechanical issues related to phenomena of living tissue, such as metabolic processes in general; actively maintained chemical gradients (leading, for example, to gas exchange as discussed by Dirckx, Chap. 5); development, growth, and remodeling; healing and osseo-integration; and many sources of variability related to genetics, environment, and history.
The simplest form of material property is linear elasticity, for which the material properties are specified by Young’s modulus and Poisson’s ratio. The material may be isotropic or not. For dynamic problems, one also needs parameters for mass density and for damping. Mass density is relatively easy to estimate. Damping is more difficult and is often represented by rather arbitrary parameters, such as the α and β of Rayleigh damping (e.g., Funnell et al. 1987). Zhang and Gan (2011) recently used a simple viscoelastic representation based on experimental measurements.
Nonlinearities may arise for geometric reasons, even if the stress–strain relationship of the material is linear. In this case a St. Venant–Kirchhoff material model can be used, which is formulated like a nonlinear material but has the same Young’s modulus and Poisson’s ratio as for a linear formulation.
Many different finite-element formulations are available for truly nonlinear hyperelastic materials. The results with different material models are sometimes similar and the available experimental data are not always good enough to justify a preference for one model over another. As an example, Fig. 7.3 shows stress–strain curves for three different material models compared with experimental data. The curves for the Ogden model (magenta, short dashes) and the Veronda–Westmann model (green, long dashes) are very similar. The solid blue curve for the model of Decraemer et al. (1980), based on a simple structural model, is also similar but does appear to fit the data better than the curves for the other two models, which are purely phenomenological.

Comparison of experimental data (black dots) with three different material models (solid blue, long-dash green, and short-dash magenta lines). See text for discussion
7.4 Model Verification and Validation
7.4.1 Introduction
ASME (originally known as the American Society of Mechanical Engineers) has formulated general guidance for the iterative verification and validation of computational models (ASME 2006; Schwer 2007). The guidelines are aimed primarily at the modeling of designed and manufactured systems but are also relevant for natural systems such as the middle ear. The building of confidence in the results of computational models is analogous to the building of confidence in experimental measurements (e.g., Parker 2008; Winsberg 2010). In this section, brief overviews of model verification and model validation are presented, followed by discussions of the specific topics of uncertainty analysis and parameter fitting.
7.4.2 Model Verification
Model verification is considered to include both code verification and calculation verification. Code verification involves checking that the mathematics of the model have been correctly implemented in the software. This may be considered to be the responsibility of the software developer, but wise modelers may want to check things for themselves by comparison with analytical solutions comparable to the real model, by the use of “manufactured solutions” (Roache 2002), or by comparison with other software. It is also useful to explore simulation results in depth, looking for odd behavior, although this will tend to be biased by expectations.
The second step, calculation verification, is very much the responsibility of the modeler, and includes running the model with different mesh resolutions and, for time-domain solutions, different time steps, to make sure that the discretization is fine enough that it does not affect the results too much (cf. section “Volume Mesh Generation”).
7.4.3 Model Validation
Model validation is an evaluation of how closely the behavior of a model matches the experimentally measured behavior of the system being modeled, with the experimental data not having been used in formulating or refining the model. The match is expressed quantitatively in terms of some validation metric that is appropriate to the intended use of the model. Ideally the match is expressed not only as a measure of the difference, but together with a measure of the uncertainty of the results and a confidence level, for example, “the relative error between the experiment and simulations was 18 ± 6 % with [an] 85 % confidence level” (Schwer 2007, p. 251). The estimation of uncertainty is addressed in Sect. 7.4.4. Note that there are two different types of uncertainty here: epistemic (or reducible) uncertainty, due to lack of knowledge about parameters, and aleatory (or stochastic, or irreducible) uncertainty, due to inherent randomness (e.g., Helton et al. 2006). These concepts are not really mutually exclusive and usage of the terminology is rather inconsistent (e.g., Moens and Vandepitte 2005, p. 1529).
Validation metrics (or adequacy criteria) can be expressed in terms of either response measures (raw model outputs) or response features derived from those outputs (e.g., Mayes 2009). For a static middle ear simulation, for example, interesting response measures might be the umbo displacement or the complete spatial displacement pattern of the eardrum. Response features might be the maximum displacement on the eardrum, or the location of that maximum, or the ratio of the maximum displacement to the umbo displacement. For a dynamic linear model, response measures could be the magnitudes and phases of the frequency response at multiple frequencies, and response features might be the average low-frequency magnitude and the frequency of the lowest resonance.
A validation metric quantifies the difference between a response measure or feature as produced by the model and the same measure or feature as measured experimentally. Obviously the available choice of metrics depends on what experimental data are available. There are many ways of formulating validation metrics, including correlations and sums of differences. It is desirable to have a relatively small number of metrics, for ease of interpretation and decision making. If one is interested in matching the shape of a frequency-response function, rather than using the frequency-by-frequency differences between simulated and measured magnitudes, one might use the means of the squared differences over selected frequency bands, or frequency shifts between simulated and measured resonance frequencies.
Whether the model matches the experimental data well enough depends on the purpose of the modeling. In general one wants some confidence that the modeling approach can be trusted to make predictions beyond the specific details of the model and experiment for which the validation is done, but this is a difficult matter of judgment. (Obviously one must always keep in mind the ranges of frequency, load, and displacement for which the underlying assumptions of the model are valid.) If it is decided that the match is not good enough, then either the model or the experiment may be revised and refined. Revision of the model (model updating) may involve not only the computational model itself (parameter fitting) but also the underlying conceptual model (choices of what physical phenomena to include) and mathematical model (how the physical phenomena are formulated).
7.4.4 Uncertainty Analysis
Uncertainty analysis has two related purposes: (1) to characterize the uncertainty of a model’s output; and (2) to determine which model parameters are mainly responsible for that uncertainty (sensitivity analysis). The amount of uncertainty in the output is important because it gives insight into how much faith to put in conclusions based on the simulation results and how much weight to give them when making decisions. If a model predicts a 50 % improvement in some clinical outcome, but the model uncertainty is ± 70 %, clearly the model will not be used to try to influence a clinician’s practice. Sensitivity analysis, that is, determining which parameters account for most of the output uncertainty, is important because it gives guidance in deciding how to try to improve the model. The improvement can be made either by adjusting parameter values or, preferably, by obtaining better a priori estimates of the parameter values. If a model is very sensitive to a particular parameter then that parameter is a good candidate for additional experimental efforts to determine its value. On the other hand, if a model is insensitive to a parameter then that parameter can just be fixed and attention can be directed elsewhere.
Sensitivity analysis is discussed in terms of a parameter space. If a model has three parameters, then it has a 3-D parameter space. If it has k parameters then it has a k-dimensional parameter space. For each parameter there will be a best-guess estimate for its value (the baseline value), plus a range of values that it might reasonably have, and perhaps a probability distribution of values within that range or some other characterization of the possible values (e.g., Helton et al. 2006). Some parameters may have much narrower ranges of likely values than others. For a soft biological tissue, for example, which is mostly water, the mass density parameter is known to within a much smaller tolerance than the stiffness parameter.
To estimate the uncertainty of a model, one should ideally run simulations for all possible combinations of many different values of every parameter, to see how the model output changes. If one uses n different values of each of k parameters, one would need n k simulations. If there are, say, four parameters, and one uses only the minimum, best-guess and maximum value for each, then already 34 = 81 different simulations are needed. This is the full-factorial method of choosing combinations of parameter values, and it quickly becomes impractical for the numbers of parameters often encountered, for a reasonably generous number of values per parameter, and particularly when the model is computationally expensive, which finite-element models often are.
It is therefore desirable to reduce the number of parameter combinations. The most common approach is the one-at-a-time method: first one parameter is varied over its range with all of the other parameters at their baseline values, then that parameter is returned to its baseline value and a second parameter is varied, and so on. This approach certainly reduces the number of simulations, but its great drawback is its failure to provide any information about parameter interactions. For example, suppose that when parameter a is at its baseline value then increasing parameter b from its baseline value increases the model output, but that when a has some other value then increasing b actually decreases the model output. This is an interaction between the two parameters. Such interactions are not uncommon in complex systems and obviously they will have a substantial impact on the uncertainty of the model’s behavior.
Clearly it is necessary to obtain a more complete sampling of points in the parameter space. A distinction can be made between preliminary screening analyses and more complete, quantitative analyses. A number of strategies have been used for selecting the points, such as random sampling, quasi-random sampling, importance sampling, Latin Hypercube sampling, and the Morris (or elementary-effects) method (e.g., Helton et al. 2006). Campolongo et al. (2011) describe a strategy that involves doing multiple one-at-a-time parameter variations. Thus, a modeler can do the usual one-at-a-time analysis around the baseline parameter values; then do a few more one-at-a-time analyses around other points to obtain screening information about interactions; and then do a larger number of one-at-a-time analyses (perhaps with some parameters omitted) for a full quantitative result.
The actual results of an uncertainty analysis may simply be visualized, for example, as scatter plots, or they may be subjected to sophisticated statistical machinery (e.g., Helton et al. 2006).
7.4.5 Parameter Fitting
7.4.5.1 Introduction
Parameter fitting is part of model updating, and consists of trying to find the set of parameter values that causes a model to best fit some experimental data. It is also known as parameter identification or model calibration; some authors have used the term “model validation” but that term should be reserved for the broader activity described in Sect. 7.4.3. Parameter fitting is usually preceded by a sensitivity analysis to provide insight into which parameters are most important for the fitting. For a small number of parameters it may be feasible to try to find the best fit by manually adjusting parameters, but it is often necessary to use some algorithmic approach. This involves two steps: choice of a cost function (section “Cost Function”) and the actual algorithm for minimizing that function (section “Minimization Algorithms”).
Before these two issues are addressed, it is important to mention the strategy of trying to reduce the number of parameters by using different pathological or experimental conditions. For example, Zwislocki (1957) exploited the pathological conditions of otosclerosis and of an interrupted incudostapedial joint to simplify his middle ear circuit models. Experimentally, methods that have been used for the middle ear include removing structures (e.g., Wever and Lawrence 1954, pp. 124 ff.); blocking the motion of the stapes (e.g., Margolis et al. 1978) or malleus (e.g., von Unge et al. 1991); and draining the liquid from the cochlea (e.g., Lynch et al. 1982). (The second of these should perhaps be worded as “attempting to block” because it is not always easy to produce the desired easy-to-model effect (e.g., Ladak et al. 2004).) This approach involves the assumption that the effects of the remaining parameters are not affected by the experimental change. This is particularly serious for lumped-parameter models—draining the cochlea, for example, may change the mode of vibration of the stapes, thereby changing its effective inertia and the effective stiffness of the annular ligament. The problem may also be present, to a lesser extent, in finite-element models.
7.4.5.2 Cost Function
For most minimization algorithms, the cost function to be minimized must be a single number, so for a particular model the various validation metrics of interest must be combined together, often as some sort of weighted average. In the best possible scenario, a cost minimum will be found such that all of the validation metrics have very small values. In real life, however, the minimum may correspond to parameter values that make some of the metrics very good and others very bad, so the formulation of a cost function will be a delicate matter.
There is a family of multiobjective minimization algorithms (e.g., Erfani and Utyuzhnikov 2011) that address the existence of multiple, conflicting cost functions. They do so by producing a family of solutions rather than a single solution, so the final decision is left to the user. The delicate decision making is thus done at the end rather than at the beginning of the process.
7.4.5.3 Minimization Algorithms
One can visualize the minimization problem for two parameters as searching for the lowest point on a response surface, with the x and y coordinates corresponding to the parameter values, and the z value (height) corresponding to the value of the cost function. The brute-force method of minimization is just to calculate the cost function at closely spaced points over the whole surface, but this is impractical for more than a few parameters or for any but the simplest cost functions. When evaluation of the cost function depends on running a high-resolution dynamic finite-element simulation, and especially if it is nonlinear, then each exploratory step is expensive.
As a result, various strategies have been devised to try to reduce the number of parameter-value combinations that must be tried. A major problem is the distinction between the global minimum of a function and possible local minima. The minimization strategy may appear to have found a minimum, but it may be just a small valley on a high plateau, with a much lower minimum in some region that has not been explored. The most common approach to this problem is to try the minimization algorithm multiple times from multiple starting points. Another problem is in deciding what step sizes to use when varying parameters. If the step size is too large, some narrow deep valleys may be missed, but excessively small step sizes will be impractically time consuming. One family of strategies attempts to continuously adapt the step size to the shape of the surface in the immediate vicinity.
There are many minimization algorithms available, and they continue to multiply. One major subdivision is between those that require an explicit formulation of the derivative of the cost function with respect to each parameter, and those that do not. For models of any complexity, it is much easier if one does not need explicit derivatives, but the price is generally increased computational time. Another major division is between deterministic algorithms, which use some sort of sequential strategy to patiently seek locations with lower cost, and stochastic algorithms, which use a shotgun approach. Marwala (2010) compares a variety of minimization algorithms for finite-element model updating.
7.4.5.4 Discussion
Parameter fitting in general is difficult, and becomes dramatically more difficult as the number of parameters increases, so it is highly desirable to reduce the number of uncertain parameters, and to understand which parameters have the largest impacts. If a fitting algorithm fails to find an acceptable fit for a given model and set of parameter ranges, it may be that no acceptable fit exists, but it is possible that the algorithm has missed it. A fitting algorithm may also fail to recognize a situation where there are many combinations of parameter values that give equally good results.
Compared with models of artificial systems, models of natural systems are likely to have much more parameter variability and uncertainty, and modelers are likely to rely more on parameter fitting than on the rest of the validation process as defined at the beginning of Sect. 7.4.3. Another point about models of natural systems is that there may be considerable uncertainty about the geometry as well as about material properties. It is important to keep in mind that the predictive power of a model is likely to be much reduced if its parameters have had to be fitted to obtain agreement with the available experimental data.
Extensive parameter fitting tends to negate the whole philosophy of finite-element modeling. This is particularly true if parameter values are set without regard to physiological plausibility. For example, in the absence of a specific rationale to the contrary, all ligaments in a model should have the same material properties. If it is necessary to give them different properties to fit specific experimental data, then something is wrong somewhere.
Ideally, modelers should be blind to the specific experimental data that will be used to validate their model (ASME 2006, p. 7), so as to strengthen confidence in its predictive power. For example, Funnell and Laszlo (1978) claimed that their model structure and material properties were established a priori, but since there was no formal blinding of the modelers to the experimental data, one cannot be sure that there was not some bias, unconscious or otherwise, in the definition of the model. Such blinding is not often practical, but it can at least be acknowledged as an ideal.
7.5 Models of the Outer and Middle Ear
7.5.1 Summary of Modeling Approaches
The interconnections of the various anatomical units of the outer, middle, and inner ear may be represented as in Fig. 7.4. Three of the blocks are in the form of two-port networks. All sound energy must flow through the first block, which stands for whatever portion of the external ear lies between the sound source and the middle ear itself. The energy leaving this block must pass through the eardrum into the middle ear cavities. In the process some of the energy enters the ossicular chain, whence it passes into the cochlea.

Block diagram of the ear canal, middle ear, and cochlea
The sections that follow will provide summaries of how the five major blocks have been modeled, generally starting with circuit models and ending with finite-element models. Figure 7.5 is a pastiche of most of the circuit models that have been described in the literature, organized in blocks corresponding to those in Fig. 7.4. No single published model has included so many components, but the figure gives an idea of the potential complexity. Many of the groups of components in the figure are common to more than one published model. Two noteworthy features are the three-piston eardrum model of Shaw and Stinson (1986) and the multipart air-cavity model of Onchi (1961); both of these are mentioned again below. Most authors have established the structures of their models based on the mechanical structure of the system, but Wever and Lawrence (1954, pp. 394 ff.) established the simplest model structure that they could find that would fit their data, and then treated the relationships between model elements and anatomical structures as being “of course a matter of conjecture.”

Circuit model of outer, middle, and inner ear, organized into the same major blocks as shown in Fig. 7.4. This figure combines features from a variety of published circuit models
There are places in circuit models where it is strictly required to put ideal transformers, both to represent transitions between acoustical and mechanical parts of a system, and to make explicit the various lever mechanisms of the middle ear. In practice either they can be included explicitly, or their effects can be absorbed into the parameter values. In the discussions here, specific circuit parameter values will not be given in any case, because they vary considerably from species to species and from individual to individual, and according to the structure selected for the model and the data used to estimate the parameters.
Most models are parametric, although Teoh (1996, p. 132) effectively used a nonparametric model of the pars tensa, ossicular chain and cochlea, in combination with parametric models of the other parts of the system.
In discussions of middle ear function in terms of analogous electrical circuits, it is important to know the frequency range over which it is legitimate to use lumped-parameter models. For example, Beranek (1954) says that for a closed tube to be modeled by a capacitor, the length (in meters) must be less than 30/f (where f is the frequency in Hz) for an error of 5 %. For a length of, say, l0 mm, which is typical of the middle ear, this constraint corresponds to an upper frequency limit of 3 kHz, which is rather low. Note, however, that an error of 5 % corresponds to only 0.5 dB. If one can accept an error at the highest frequency of l dB, the upper frequency limit can be extended to over l0 kHz. An acceptable error of 2 dB means an upper limit of almost 15 kHz.
The middle ear is linear up to sound pressures of at least l20 or l30 dB SPL (e.g., Guinan and Peake 1967). Linearity will be assumed here for responses to sounds but not for responses to large quasi-static pressures.
7.5.2 Ear Canal
At low frequencies the ear canal can be modeled as a simple rigid-walled cavity characterized just by its volume. In a circuit model, this can be corrected for in the experimental data (e.g., Zwislocki 1957) or it can be explicitly represented by just a single capacitance. At higher frequencies the wavelength starts to become comparable to the canal length and standing-wave patterns start to form along the canal. As a first approximation this can easily be modeled as a single mass-spring combination to produce the first natural frequency (e.g., Onchi 1949, 1961) or the canal can be modeled analytically as a uniform transmission line (Wiener and Ross 1946). A one-dimensional modified horn equation can be used to model the effects of the nonuniformity of the transverse canal dimensions (Khanna and Stinson 1985) as well as the effect of the distributed acoustical impedance of the eardrum (Stinson and Khanna 1989). Such effects have also been approached using coupled mechanical and acoustical finite-element models. For example, Koike et al. (2002) compared the effects of a more or less realistic canal shape (curved, but with the drum not tilted in a realistic way) with those of a simple cylindrical canal. At 7 kHz, the variation of the pressure across the drum was less than 2 dB.
At even higher frequencies, the wavelength becomes comparable to the transverse canal dimensions and the pressure starts to be nonuniform across the canal (e.g., Stinson and Daigle 2005). At very high frequencies, the precise orientation and shape of the canal termination at the eardrum also become important. Rabbitt and Holmes (1988) modeled this analytically using asymptotic approximations. Tuck-Lee et al. (2008) used a special adaptive finite-element approach to facilitate the calculations for high frequencies. In a finite-element model of the human ear canal, Hudde and Schmidt (2009) found acoustical modes that raise interesting questions about the notion of a midline axis that is often assumed in canal modeling.
Although Tuck-Lee et al. (2008) did allow for some absorption in the walls of the canal and cavities, most models of the canal have assumed that its walls are effectively rigid. It appears that this is not a reasonable approximation in human newborns. For the newborn human canal, in which the bony canal wall has not yet formed, Qi et al. (2006) found that the response of a hyperelastic finite-element model to large static pressures (as used in tympanometry) is strongly affected by the flexibility of the canal wall. Preliminary results indicate that this is also true of the response to auditory frequencies (Gariepy 2011).
Most ear-canal modeling has treated the common experimental situation in which the sound source is characterized by sound-pressure measurements with a probe microphone in the canal. Small probe tubes can have significant effects in some circumstances (e.g., Zebian et al. 2012). In modeling the response of the ear to free-field sound with the microphone outside the canal, it is necessary to take into account the shape of the pinna (e.g., Hudde and Schmidt 2009) and perhaps even the shape and dimensions of the whole head.
7.5.3 Air Cavities
In some species, the middle ear air cavities include multiple chambers with relatively narrow passages between them (see Rosowski, Chap. 3). Circuit modeling of the cavities for any given species is relatively straightforward: identify the distinct chambers, associate each one with a capacitor, and associate the passages between the chambers with series R-L branches. Figure 7.6 shows a model with one main chamber and one secondary chamber. The capacitance values can be calculated from the chamber volumes. The resistance and inductance values will often be determined from measured frequency characteristics because the estimation of R and L parameters for short narrow tubes is an approximate business at best (e.g., Beranek 1954, Chap. 5) and the intercavity passages are more irregularly shaped than simple tubes. The interconnected chambers will introduce resonances. Since the capacitances are known, the inductances can be estimated from the resonance frequencies, and the resistance can then be estimated from the width and sharpness of the resonance.

Circuit model for middle ear cavities with one main chamber (Cb1), one secondary chamber (Cb2), and a narrow passage between them (Rb2 and Lb2)
For the human, Cb1 represents the tympanum and epitympanum, while Cb2 represents the mastoid antrum and air cells. Although the air cells have a complex form and could be more accurately modeled (Onchi 1961; Stepp and Voss 2005), it is often sufficient simply to include their volume with that of the antrum because at high frequencies, where their form is more critical, the increasing reactance of Lb2 will tend to isolate them from the tympanum (Zwislocki 1962). In the cat, Cb1 and Cb2 represent the ectotympanic and entotympanic cavities, respectively (Møller 1965; Peake and Guinan 1967). In the guinea pig, they represent the tympanum and epitympanum, respectively (Funnell and Laszlo 1974). In the rabbit there is only one cavity (Møller 1965). Zwislocki (1962) added an extra resistor for energy absorption in the tympanic cavity, Eustachian tube and mastoid air cells but did not find it necessary for the guinea pig (Zwislocki 1963).
The finite-element model of Gan et al. (2006) included an explicit model of the middle ear cavities as well as of the canal, but the sound-pressure differences between locations within the cavities were very small at frequencies up to 10 kHz, the maximum frequency considered. As mentioned previously for the canal, Tuck-Lee et al. (2008) used a special algorithm for the air cavities; they also used a special approach (involving perfectly matched layers) for modeling the common experimental condition of opened air cavities, avoiding the need for explicitly modeling the infinite (or at least very large) surrounding air space. Their analysis of the effects of having two cavities communicating through a small opening supported previous suggestions (Puria 1991; Huang et al. 2000) that this configuration in the cat avoids a notch in the frequency response at around 10 kHz that could interfere with acoustic cues used for sound localization.
In the living animal, the middle ear cavities are criss-crossed by mucosal strands and folds, some of them carrying blood vessels or nerves or even connective-tissue fibers (e.g., Palva et al. 2001). Their possible acoustical effects have never been investigated but are assumed to be small.
7.5.4 Eardrum
7.5.4.1 Helmholtz Versus von Békésy
The first attempted quantitative model of eardrum function was the “curved-membrane” hypothesis of Helmholtz (1868). This was a distributed-parameter analytical model that depended critically on the curvature of the eardrum. It also made use of anisotropy, assuming differences between the radial and circumferential directions. The model was later elaborated by Esser (1947) and by Guelke and Keen (1949), and an error in Helmholtz’ calculations was pointed out by Hartman (1971). In the meantime, however, von Békésy (1941) had made capacitive-probe measurements of eardrum vibrations and described the eardrum as vibrating, at frequencies up to about 2.4 kHz, “as a stiff surface along with the manubrium” with a very flexible region around the periphery (as translated von Békésy 1960, p. 101). This view of the eardrum, as being mostly a rigid structure tightly coupled to the malleus, dominated subsequent modeling for many years.
7.5.4.2 Lumped-Parameter Models
In the circuit model of Onchi (1949, 1961), the human eardrum was represented by a single mass attached by springs to the tympanic annulus and to the manubrium. Zwislocki (1957) represented the human eardrum with two parts, one branch in parallel with the ossicular chain, corresponding to “the compliance and the resistance of the eardrum … when the ossicular chain is rigidly fixed” (with negligible inertia) and a second branch in series with the ossicular chain, corresponding to “the portion of the eardrum that may be considered rigidly coupled to the malleus” (and incorporating the effect of the middle ear air cavity). The first branch allows sound energy to pass through the eardrum directly into the middle ear air cavities without driving the ossicles. Møller (1961) represented the human eardrum in essentially the same way. Zwislocki (1962) refined his model by adding an inductor to represent eardrum mass. For higher frequencies where “the eardrum vibrates in sections” he suggested that “a transmission line would probably constitute the best analog” but he confined himself to adding an empirically chosen series resistor-capacitor combination in parallel with the inductor. The extra resistor and capacitor were not found necessary for the guinea pig (Zwislocki 1963).
Møller (1965) modeled the cat and rabbit eardrum as a single branch in parallel with the branch representing the ossicular chain and cochlea, with the part of the eardrum tightly coupled to the malleus being implicitly included in the latter branch. The detailed nature of each branch was not specified. Peake and Guinan (1967), in their model for the cat, did not find it necessary to include a parallel branch for the eardrum.
In the early 1970s, eardrum vibration-pattern measurements by laser holography made it clear that the mode of eardrum vibration described by von Békésy was incorrect (Khanna and Tonndorf 1972). Even at low frequencies, no part of the drum acts like a rigid plate. In recognition of this new evidence, and with the goal of extending eardrum circuit models to higher frequencies, Shaw and Stinson (1983) reinterpreted the nature of the two eardrum “piston” components, associating them with (1) the small part rigidly coupled to the manubrium and (2) all of the rest of the eardrum. They also added an explicit coupling element between the two parts. They later refined the model further by adding a third “piston” (Shaw and Stinson 1986). Kringlebotn (1988) did not include multiple branches for the eardrum itself but did include a parallel branch after the series branch, to represent coupling between the eardrum and the manubrium. A branch was also included to represent the suspension of the eardrum at the tympanic annulus; this will be mentioned again in section “Finite-Element Models.” In an attempt to deal with higher frequencies, Puria and Allen (1998) presented a delay-line model of the eardrum; it was further explored by O’Connor and Puria (2008) and extended by Parent and Allen (2007, 2010).
Lumped-circuit models of the eardrum continue to be useful in some applications. For example, Teoh et al. (1997) made good use of such a model to elucidate the effects of the large pars flaccida of the gerbil eardrum. Two-port models have also been used productively (e.g., Shera and Zweig 1991; O’Connor and Puria 2008). Such models are particularly appropriate for describing experimental data that describe eardrum behavior by a single number such as umbo displacement or, especially, acoustical impedance. However, it is clear that lumped models cannot model the spatial vibration patterns of the eardrum, nor can they address questions arising from those patterns.
7.5.4.3 Analytical Models
To address spatial patterns of the eardrum, in addition to the work by Esser (1947) and Guelke and Keen (1949) mentioned in section “Helmholtz Versus von Békésy,” analytical models were formulated by Frank (1923), Gran (1968, Chap. 2), and Wada and Kobayashi (1990), but all were forced to make many oversimplifications, including the critical one of taking the eardrum as flat rather than conical. Asymptotic analytical models have been more successful (Rabbitt and Holmes 1986; Fay 2001) and are mentioned again later. Goll and Dalhoff (2011) recently presented a 1-D string model of the eardrum that can be viewed as a distributed variant of the lumped delay-line models mentioned in section “Lumped-Parameter Models.”
7.5.4.4 Finite-Element Models
In direct response to the new holographic spatial-pattern data of Khanna and Tonndorf (1972), the finite-element method was applied to the middle ear, with particular attention to the eardrum (Funnell and Laszlo 1978; Funnell 1983). These 3-D models were based on a review of the anatomical, histological, and biomechanical nature of the eardrum (Funnell and Laszlo 1982). All of the mechanical parameters except damping were based on a priori estimates, so very little parameter fitting was required. (The possibility of doing this is one of the strengths of the finite-element method.) The displacement patterns and frequency responses calculated with these models were qualitatively similar to those observed experimentally by Khanna and Tonndorf (1972).
These first finite-element models were for the cat middle ear because of the high-quality experimental data that were available. Subsequently, Williams and Lesser (1990) published a finite-element model of the human eardrum and manubrium, but the ossicular chain and cochlea were not modeled, and the model did not produce reasonable natural frequencies with realistic parameters. Wada et al. (1992) published the first model of the human middle ear that included both the eardrum and the ossicles. See Volandri et al. (2011) for a recent survey of finite-element models of the human eardrum. In many of these models, values for many of the parameters were established by fitting the model behavior to specific experimental data, rather than by a priori estimates. In models with many parameters, unless the fitting is done very carefully and with very good data, it can lead to parameter values that have questionable physical significance. It has happened, when published models were revised somewhat or compared with different data, that some of the material-property parameters changed dramatically with no rationale other than data fitting.
The 3-D shapes of the eardrum in these early models were qualitatively based on rather imprecise and coarse shape measurements (e.g., Kojo 1954; Funnell 1981). Representing the shape parametrically (Funnell and Laszlo 1978) made it possible to evaluate the effects of changing both the depth of the cone and the degree of curvature; Rabbitt and Holmes (1986) represented the shape with a function describing the deviation from a conical shape. Much better shape measurements became available later using moiré topography (Dirckx et al. 1988), and a method was developed of incorporating the measurements directly into finite-element models (Funnell and Decraemer 1996). Both these results and the earlier parametric studies showed that 3-D eardrum shape has a significant effect on the behavior of middle ear models, indicating the importance of good shape measurements and of models that reflect those measurements. Beer et al. (1999) used a parameterized shape based on 40 points measured with a scanning laser microscope as described by Drescher et al. (1998). Sun et al. (2002a, 2002b) based their model geometry on serial histological sections, but this is problematic for the shape of a very delicate structure such as the eardrum, which is very vulnerable to distortion during histological processing. Fay et al. (2005, 2006) assumed a conical shape near the manubrium and a toroidal shape near the annulus, fitted to the moiré data of Funnell and Decraemer (1996).
The eardrum thickness in the early models either was assumed to be constant or was made variable to correspond to the rather coarse observations that were available, such as the measurements at ten locations on histological sections by Uebo et al. (1988). The best thickness measurements so far have been done using confocal microscopy for cat and gerbil (Kuypers et al. 2005a, b) and later for human (Kuypers et al. 2006), and they have started to appear in finite-element models (Tuck-Lee et al. 2008 for cat; Maftoon et al. 2011 for gerbil).
Kringlebotn (1988), Wada et al. (1992), and Williams et al. (1996) all included a spring term at the boundary of the eardrum. However, experimental measurements seem to indicate that the drum can be thought of as having zero displacement at the boundary (e.g., Gea et al. 2009) and the thickness of the fibrocartilaginous ring is so much greater than that of the drum that its displacements can be expected to be much smaller. The need for nonzero displacements at the boundary may result from inadequacies in the model, such as inappropriate eardrum curvature or rigid ossicular joints. It is true, however, that the drum thickens gradually toward the boundary, and the fibrocartilaginous ring itself tapers down (albeit rapidly) to the thickness of the drum, so the question of the boundary condition depends on exactly where the boundary is taken to be.
In most species, the eardrum and malleus are tightly connected together along the whole length of the manubrium, but in the human ear this is not the case. The soft connection in the middle region of the manubrium has been explicitly modeled (Koike et al. 2002; Sun et al. 2002b) but does not appear to make much difference.
7.5.4.5 Layers and Fibers
In many models the eardrum has been assumed to be uniform throughout its thickness and to be isotropic. This has been in spite of ultrastructural observations suggesting both nonuniformity, because of the layered structure of the eardrum, and anisotropy, because of highly organized fiber orientations (e.g., Lim 1995). (Note that Schmidt and Hellström (1991) described the fiber layers as being somewhat different in the guinea pig than in rat and human.) It has also often been assumed that there is negligible resting tension in the eardrum. It is still not clear how acceptable these assumptions are; certainly anisotropy, for example, can have significant effects (e.g., Funnell and Laszlo 1978).
The mechanical properties of the eardrum will depend on the mechanical properties of the fibers and of the ground substance in which the fibers are embedded; on the numbers, orientations, and packing of the fibers; on the mechanical coupling between the fibers and the ground substance; and on the variable thicknesses of the different layers. Rabbitt and Holmes (1986) included these features in their asymptotic analytical model. They pointed out that the anisotropic arrangement of the fibers may lead to more anisotropy in the in-plane (membrane) mechanical properties than in the transverse (bending) mechanical properties. It is important to keep this in mind when interpreting the results of different methods for measuring eardrum mechanical properties. Fay et al. (2005, 2006) also took the layers, fibers, and variable thicknesses into account. They emphasized the gradual transition from a very flexible, nearly isotropic region near the annulus to a stiffer, anisotropic region near the manubrium.
Finite-element modeling has been done of the effects of holes in the eardrum (Gan et al. 2006, 2009), and a model of the effects of slits in the drum has been used to address the relative contributions of the radial and circular fibers (Tuck-Lee et al. 2008). They discussed the apparent need in their model for a shear stiffness that is higher than might be expected for a material for which the stiffness is assumed to arise primarily from stiff parallel fibers. However, there is still much to be learned about the biochemistry and mechanics of collagenous materials, and of the eardrum in particular (e.g., Broekaert 1995; Buehler 2008).
As noted previously (Funnell and Laszlo 1982), the outermost layer of the epidermis, the stratum corneum, is thin but very dense and it may have some effect on the mechanical properties of the eardrum. Yuan and Verma (2006) reported Young’s moduli for the stratum corneum that are comparable to some estimates for the eardrum fiber layers, and the thicknesses of the two layers in the eardrum may also be comparable.
7.5.5 Ossicular-Chain Models
7.5.5.1 Lumped-Parameter Models
Circuit models of the ossicular chain generally include mass (inductor) elements for the malleus (possibly including the tightly coupled part of the eardrum), incus, and stapes. As a first approximation the malleus and incus are considered to rotate about an axis joining the anterior mallearFootnote 1 and posterior incudal processes, so the mass term actually represents the moment of inertia of the bones as they move about that axis. If the stapes is considered to move like a piston, then its mass term actually corresponds to its mass, but if it is considered to rotate about one part of the annular ligament (e.g., Møller 1961), then its mass term corresponds to a moment of inertia.
A circuit model may include spring (capacitor) elements corresponding to the suspensory ligaments (and possibly the tensor tympani and stapedius muscles) and to the malleus-incus (incudomallear) and incus-stapes (incudostapedial) joints. If one of the joints is considered to be rigid, then the capacitor is omitted and the inductors corresponding to the two ossicles can be combined. For example, for the human ear, Møller (1961) and Peake and Guinan (1967) included flexibility of the incudomallear joint, but Zwislocki (1957, 1962) did not. The guinea pig malleus and incus are actually fused together so no joint is required (Zwislocki 1963). None of these early models included flexibility of the incudostapedial joint.
Damping elements (resistors) are included in various places to represent energy dissipation. Sometimes they are associated with inductors and sometimes with capacitors; the latter seems more appropriate.
The effects of the tensor tympani and stapedius muscles were represented explicitly by Onchi (1949, 1961), but more often they have been represented by changes in the elasticities and resistances of the branches representing the malleus and the stapes. Although it is possible that the muscles affect the effective masses of the ossicles, for example, by modifying the rotational axis of the malleus and incus, such effects are probably secondary to the changes of elasticity and resistance.
One disadvantage of circuit models is that their parameter values may need to be changed to accommodate changes in modes of vibration because of frequency, muscle contractions, different applied loads, or other effects. This greatly limits their predictive power. As is the case for the eardrum, however, both circuit models (e.g., O’Connor and Puria 2008) and two-port models (e.g., Shera and Zweig 1992a, b) of the ossicular chain continue to have value as concise representations of experimentally observed phenomena.
7.5.5.2 Distributed-Parameter Models
Early finite-element modeling of the middle ear concentrated on the eardrum because its inherently distributed nature represented the weakest part of available lumped-parameter middle ear models. In these models the axis of rotation was taken as fixed (e.g., Funnell and Laszlo 1978; Wada et al. 1992). Distributed models of the ossicles, ligaments, and muscles were needed, however, to cope with changes of vibration mode such as those resulting from muscle contractions (e.g., Pang and Peake 1986), and the need became even more clear as it became more and more obvious that the 3-D motions of the ossicular chain are very complex, with the position of the ossicular axis of rotation varying greatly with frequency and even within one cycle (e.g., Decraemer et al. 1991).
Eiber and Kauf (1994) described a model in which the ossicles were represented as distributed rigid bodies but the ligaments and joints were represented by lumped-parameter springs and dashpots. Hudde and Weistenhöfer (1997) described a model based on a 3-D generalization of circuit modeling, combining some features of the two-port and rigid-body approaches. These kinds of models are intermediate between circuit models and finite-element models. (The finite-element method can also incorporate perfectly rigid bodies by the use of “master” and “slave” degrees of freedom [e.g., Funnell 1983], thus reducing the computational cost when parts of the model are assumed to have negligible deformations.)
A finite-element model of the cat middle ear was developed based on a 3-D reconstruction from serial histological sections (Funnell and Funnell 1988; Funnell et al. 1992), with 20-μm sections and every second one used. Complete models of three different human middle ears were created from histological sections by Gan’s group (Gan et al. 2004; Gan and Wang 2007). The usual practice was followed of cutting 20-μm sections and using only every tenth one, which of course limits the resolution for small structures. Much higher resolution was obtained by cutting 1-μm sections and using every one (Funnell et al. 2005), but this was feasible only for a small portion of the middle ear.
Finite-element models of the ossicles have also been based on magnetic-resonance microscopy (e.g., Van Wijhe et al. 2000) and X-ray microCT (e.g., Hagr et al. 2004). Other 3-D middle ear models that could be adapted to finite-element modeling have been created recently, based on histology (Wang et al. 2006; Chien et al. 2009) and OPFOS (Buytaert et al. 2011).
Illustrating the complementary nature of the different types of data, Elkhouri et al. (2006) created a model of the gerbil middle ear based primarily on magnetic-resonance microscopy data, but used microCT data for some small bony features, histological data to clarify some even smaller features, and moiré data for the shape of the eardrum. Although MR imaging distinguishes soft tissues better than X-ray CT does, it is possible to identify and model soft tissues with the latter (e.g., Sim and Puria 2008; Gea et al. 2009).
Even when detailed 3-D models of the ossicles were used, the shapes of the ligaments have often been very approximate. The annular ligament in particular, being so narrow, has often been represented by some number of springs whose stiffnesses were estimated either by using its dimensions and assumed material properties or by fitting to experimental data.
So far this section has focused on the generation of geometry for models of the ossicular chain. In terms of mechanics, a few examples will now be given of the kinds of issues that cannot be addressed with lumped-parameter models. To begin with, it is interesting to note that although in circuit models of the ossicular chain the incudostapedial joint has often been omitted, it must be present in some form in 3-D models because it represents the place where the (more or less) rotational motions of the malleus and incus are converted into the (more or less) translational motion of the stapes. Having a rigid joint would cause a very unphysiological constraint. The incudomallear joint, on the other hand, can be and often is omitted from both circuit and finite-element models as a first approximation. When included, both joints are generally treated rather simplistically. It may be important for some purposes to explicitly model the ligamentous joint capsules, the synovial fluid, the cartilaginous joint surfaces, and perhaps even the transition from bone to calcified cartilage to uncalcified cartilage.
The ossicles are generally considered to be rigid, but detailed modeling has indicated that there may be significant flexibility in the manubrium of the malleus (Funnell et al. 1992), in the stapes (Beer et al. 1999), and in the bony pedicle between the long process of the incus and the lenticular plate (Funnell et al. 2005, 2006).
Finite-element models are able to produce complex ossicular motions, and permit exploration of the conditions required for rotation about the supposed anatomical incudomallear axis, for example, or for piston-like motion of the stapes. Such models can be used, for example, to replicate and to predict the different effects of different ligaments (Dai et al. 2007) and to explore a hypothesized high-frequency twisting mode of the malleus (Puria and Steele 2010).
7.5.6 Cochlea
The load presented by the cochlea was considered by Zwislocki (1962) to have both resistive and reactive components, but to be mainly resistive, and it has often been modeled as a simple dashpot. Puria and Allen (1998) modeled it as a nonparametrically specified frequency-dependent impedance. In the early finite-element models there was a single damping representation for the whole model so the cochlear load was insufficient, but Koike et al. (2002) introduced additional damping for it. Recently middle ear models have been coupled to explicit finite-element models of the cochlea (Gan et al. 2007; Kim et al. 2011).
7.5.7 Nonlinearity
The middle ear behaves linearly for the purposes of normal hearing but becomes nonlinear in response to very loud sounds, to explosions, and to the large quasi-static pressures involved in large changes of altitude and in clinical tympanometry. The finite-element method was used by Stuhmiller (1989) to study the effects of blast, but with a linear model, and by Wada and Kobayashi (1990) to study the effects of tympanometric pressures, but with the eardrum assumed to be flat and circular. Price and Kalb (1991) and Pascal et al. (1998) attempted to model nonlinearity with a circuit model by empirically modifying parameter values and outputs. More recently, models have included both nonlinearities and realistic geometries (Ladak et al. 2006; Qi et al. 2006; Wang et al. 2007). Homma et al. (2010) modeled the effects of large static pressures, but by adjusting the material properties for the different pressures rather than by using nonlinear properties. Nonlinear simulation of the eardrum is complicated by its curvature, which may lead to wrinkles and unstable “snap-through” for large positive ear-canal pressures.
7.6 Summary
Apart from reviewing a few basic concepts involved in modeling, this chapter has summarized some of the work that has been done on modeling normal outer-ear and middle ear function. Modeling has also been done of various special conditions. In particular, finite-element models have been used to simulate such things as middle ear prostheses and implants, eardrum abnormalities, ventilation tubes, reverse transmission and otoacoustic emissions, liquid in the middle ear cavity, and bone conduction. Such studies may be where the true value of middle ear modeling lies, but the conclusions can only be as valid as the models themselves, and the models are far from definitive at this point. Modeling studies of the effects of anatomical variability have been few, but the great variability of human ears (e.g., Todd 2005) makes this an important factor in the interpretation of model results.
Apart from a few models for cat and gerbil, the only finite-element middle ear models have been for human ears even though the best experimental data for validation are from other species. More nonhuman models would probably be valuable in the development of better validated models. In the guidelines for model validation discussed in Sect. 7.4.3, the recommendation is that “validation of a complex system should be pursued in a hierarchical fashion from the component level to the system level” (Schwer 2007, p. 247). This has not been the approach for the middle ear, although recent experimental and modeling work on individual components (cf. Sect. 7.3) may lead in that direction.
Modeling has not yet been done of the effects of the smooth muscle present in the fibrocartilaginous ring surrounding the eardrum (Henson et al. 2005). This would be interesting for its own sake, and is also related to the open question of how much tension there is in the eardrum under normal operating conditions and how important it is.
Another open question is about the high-frequency behavior of the middle ear. Some experimental data (e.g., Olson 1998; Puria and Allen 1998) have shown a high-frequency middle ear response that has a relatively flat magnitude and a phase lag that increases more or less linearly with frequency. These are the characteristics of a delay line, and some modeling has been done that starts from the pure-delay hypothesis (cf. Voss et al., Chap. 4). Naturally, such models can reproduce delay-like behavior, but it may not be entirely clear how they are related to actual physical and mechanical mechanisms. Not all experimental data show the delay-like behavior. Moreover, some data that have been interpreted as having delay-like high-frequency magnitudes can be equally well described (from a different bias) as combinations of roll-offs and peaks. Most experimental data are not clean enough to be unambiguous.
Measurements at very high frequencies are very difficult to do reliably and repeatably. For one thing, sound-pressure fields become very nonuniform over very short distances. For another thing, the vibration modes of the middle ear become extremely complex and frequency-dependent. The very notions of input and output become difficult to define.
Finite-element models will necessarily show delay-like behavior if (1) that is how the middle ear really behaves and (2) the models are adequate representations of the middle ear. If a finite-element model does not satisfactorily replicate some set of experimental data, it does not condemn finite-element modeling as an approach, but rather indicates that that particular model was missing some features. It is possible, of course, that the missing features include unrecognized artefacts and errors of the experiments.
It is sometimes stated that a disadvantage of finite-element models is that they have too many parameters. Two things must be kept in mind, however. First, the number of parameters is directly related to the amount of realism included in the model. Because only as much realism needs to be included as is necessary to match the behavior of interest as closely as desired, the number of parameters might be claimed to be the minimum necessary. The second thing to keep in mind is that the real concern is not the number of parameters but rather the number of parameters that have to be assigned values by fitting to the experimental data being modeled. In principle, all of the parameters of a finite-element model can be assigned values based on experimental data (e.g., measurements of material properties) that are completely distinct from the situation being modeled, so the number of free parameters can be very small. In practice, of course, finite-element models, like others, are sometimes given additional free parameters because of a lack of knowledge or to make up for shortcomings in the models.
Another disadvantage sometimes ascribed to finite-element models is that their complexity can hinder insight into the fundamental principles involved in a system. It is certainly true that some simple lumped models have provided substantial insight into middle ear mechanics. If, however, the relevant fundamental principles include the asymmetrical distributed nature of the system, then complex models are required to elucidate it.
A third disadvantage ascribed to finite-element models is their computational expense, and that can indeed become a serious issue, with some simulations being very time-consuming. Again, however, it depends on the degree of realism required for the purposes of the model. If the realism is not necessary, it can be removed. If it is necessary, then, in the words of an esteemed graduate-studies supervisor, slow work takes time.
Notes
- 1.
The adjective corresponding to malleus is mallear (cf. Latin adjective mallearis), not malleal as sometimes seen, and certainly not malleolar, which is the adjective for malleolus.
References
Aernouts, J., & Dirckx, J. (2012). Static versus dynamic gerbil tympanic membrane elasticity: Derivation of the complex modulus. Biomechanics and Modeling in Mechanobiology, 11(6), 829–840.
American Society of Mechanical Engineers (ASME). (2006). Guide for verification and validation in computational solid mechanics. New York: American Society of Mechanical Engineers.
Beer, H.-J., Bornitz, M., Hardtke, H.-J., Schmidt, R., Hofmann, G., Vogel, U., Zahnert, T., & Hüttenbrink K.-B. (1999). Modelling of components of the human middle ear and simulation of their dynamic behaviour. Audiology and Neuro-Otology, 4(3–4), 156–162.
Bell, D. C. (2009). Contrast mechanisms and image formation in helium ion microscopy. Microscopy and Microanalysis, 15(2), 147–153.
Beranek, L. L. (1954). Acoustics. New York: McGraw-Hill.
Bourke, P. (1997). Polygonising a scalar field using tetrahedrons. Geometry, Surfaces, Curves, Polyhedra. Retrieved from: http://paulbourke.net/geometry/polygonise/#tetra. Accessed July 19, 2011.
Broekaert, D. (1995). The tympanic membrane: A biochemical updating of structural components. Acta Oto-Rhino-Laryngologica Belgica, 49, 127–137.
Brown, J. A., Torbatian, Z., Adamson, R. B., Van Wijhe, R., Pennings, R. J., Lockwood, G. R., & Bance, M. L. (2009). High-frequency ex vivo ultrasound imaging of the auditory system. Ultrasound in Medicine & Biology, 35(11), 1899–1907.
Buehler, M. J. (2008). Nanomechanics of collagen fibrils under varying cross-link densities: Atomistic and continuum studies. Journal of the Mechanical Behavior of Biomedical Materials, 1(1), 59–67.
Buytaert, J. A. N., Salih, W. H. M., Dierick, M., Jacobs, P., & Dirckx, J. J. J. (2011). Realistic 3D computer model of the gerbil middle ear, featuring accurate morphology of bone and soft tissue structures. Journal of the Association for Research in Otolaryngology, 12(6), 681–696.
Campolongo, F., Saltelli, A., & Cariboni, J. (2011). From screening to quantitative sensitivity analysis. A unified approach. Computer Physics Communications, 182(4), 978–988.
Carlton, P. M., Boulanger, J., Kervrann, C., Sibarita, J.-B., Salamero, J., Gordon-Messer, S., Bressan, D., Haber, J.E., Haase, S., Shao, L., Winoto, L., Matsuda, A., Kner, P., Uzawa, S., Gustafsson, M., Kam, Z., Agard, D.A., & Sedat, J.W. (2010). Fast live simultaneous multiwavelength four-dimensional optical microscopy. Proceedings of the National Academy of Sciences of the USA, 107(37), 16016–16022.
Cerveri, P., & Pinciroli, F. (2001). Symbolic representation of anatomical knowledge: Concept classification and development strategies. Journal of Biomedical Informatics, 34(5), 321–347.
Cheng, T., & Gan, R. Z. (2007). Mechanical properties of stapedial tendon in human middle ear. Journal of Biomechanical Engineering, 129(6), 913–918.
Chien, W., Northrop, C., Levine, S., Pilch, B. Z., Peake, W. T., Rosowski, J. J., & Merchant, S. N. (2009). Anatomy of the distal incus in humans. Journal of the Association for Research in Otolaryngology, 10(4), 485–496.
Dai, C., Cheng, T., Wood, M. W., & Gan, R. Z. (2007). Fixation and detachment of superior and anterior malleolar ligaments in human middle ear: Experiment and modeling. Hearing Research, 230(1–2), 24–33.
Danzl, R., Helmli, F., & Scherer, S. (2011). Focus variation—A robust technology for high resolution optical 3D surface metrology. Strojniski Vestnik/Journal of Mechanical Engineering, 57(3), 245–256.
Decraemer, W. F., & Khanna, S. M. (1999). New insights into vibration of the middle ear. In The function and mechanics of normal, diseased and reconstructed middle ears (pp. 23–38). Presented at the 2nd International Symposium on Middle-Ear Mechanics in Research and Otosurgery, Boston, October 21–24.
Decraemer, W. F., Maes, M. A., & Vanhuyse, V. J. (1980). An elastic stress–strain relation for soft biological tissues based on a structural model. Journal of Biomechanics, 13(6), 463–468.
Decraemer, W. F., Khanna, S. M., & Funnell, W. R. J. (1991). Malleus vibration mode changes with frequency. Hearing Research, 54(2), 305–318.
Decraemer, W. F., Dirckx, J. J. J., & Funnell, W. R. J. (2003). Three-dimensional modelling of the middle-ear ossicular chain using a commercial high-resolution X-ray CT scanner. Journal of the Association for Research in Otolaryngology, 4(2), 250–263.
De Mey, J. R., Kessler, P., Dompierre, J., Cordelières, F. P., Dieterlen, A., Vonesch, J.-L., & Sibarita, J.-B. (2008). Fast 4D Microscopy. In Methods in cell biology, Vol. 85: Fluorescent proteins (pp. 83–112). Philadelphia: Elsevier.
Denk, W., & Horstmann, H. (2004). Serial block-face scanning electron microscopy to reconstruct three-dimensional tissue nanostructure. PLoS Biology, 2(11), 1901–1909.
Dirckx, J. J. J., Decraemer, W. F., & Dielis, G. (1988). Phase shift method based on object translation for full field automatic 3-D surface reconstruction from moire topograms. Applied Optics, 27(6), 1164–1169.
Drescher, J., Schmidt, R., & Hardtke, H. J. (1998). Finite-Elemente-Modellierung und Simulation des menschlichen Trommelfells. HNO, 46(2), 129–134.
Egolf, D. P., Nelson, D. K., Howell, H. C., III, & Larson, V. D. (1993). Quantifying ear-canal geometry with multiple computer-assisted tomographic scans. The Journal of the Acoustical Society of America, 93(5), 2809–2819.
Eiber, A., & Kauf, A. (1994). Berechnete Verschiebungen der Mittelohrknochen unter statischer Belastung. HNO, 42(12), 754–759.
Elkhouri, N., Liu, H., & Funnell, W. R. J. (2006). Low-frequency finite-element modeling of the gerbil middle ear. Journal of the Association for Research in Otolaryngology, 7(4), 399–411.
Erfani, T., & Utyuzhnikov, S. V. (2011). Directed search domain: A method for even generation of the Pareto frontier in multiobjective optimization. Engineering Optimization, 43(5), 467–484.
Esser, M. H. M. (1947). The mechanism of the middle ear: II. The drum. Bulletin of Mathematical Biophysics, 9, 75–91.
Fay, J. (2001). Cat eardrum mechanics. Ph.D. thesis, Stanford University.
Fay, J., Puria, S., Decraemer, W. F., & Steele, C. (2005). Three approaches for estimating the elastic modulus of the tympanic membrane. Journal of Biomechanics, 38(9), 1807–1815.
Fay, J. P., Puria, S., & Steele, C. R. (2006). The discordant eardrum. Proceedings of the National Academy of Sciences of the USA, 103(52), 19743–19748.
Fercher, A. F. (2010). Optical coherence tomography – development, principles, applications. Zeitschrift für Medizinische Physik, 20(4), 251–276.
Frank, O. (1923). Die Leitung des Schalles im Ohr. Sitzungsberichte der mathematisch-physikalischen Klasse der Bayerischen Akademie der Wissenschaften zu München, 1923, 11–77.
Funnell, S. M., & Funnell, W. R. J. (1988). An approach to finite-element modelling of the middle ear. In Proceedings of the 14th Canadian Medical & Biological Engineering Conference (pp. 101–102). Montréal, June 28–30.
Funnell, W. R. J. (1981). Image processing applied to the interactive analysis of interferometric fringes. Applied Optics, 20(18), 3245–3250.
Funnell, W. R. J. (1983). On the undamped natural frequencies and mode shapes of a finite-element model of the cat eardrum. The Journal of the Acoustical Society of America, 73(5), 1657–1661.
Funnell, W. R. J. (1984). On the choice of a cost function for the reconstruction of surfaces by triangulation between contours. Computers and Structures, 18(1), 23–26.
Funnell, W. R. J., & Decraemer, W. F. (1996). On the incorporation of moiré shape measurements in finite-element models of the cat eardrum. The Journal of the Acoustical Society of America, 100(2), 925–932.
Funnell, W. R. J., & Laszlo, C. A. (1974). Dependence of middle-ear parameters on body weight in the guinea pig. The Journal of the Acoustical Society of America, 56(5), 1551–1553.
Funnell, W. R. J., & Laszlo, C. A. (1978). Modeling of the cat eardrum as a thin shell using the finite-element method. The Journal of the Acoustical Society of America, 63(5), 1461–1467.
Funnell, W. R. J., & Laszlo, C. A. (1982). A critical review of experimental observations on ear-drum structure and function. ORL: Journal for Oto-Rhino-Laryngology and Its Related Specialties, 44(4), 181–205.
Funnell, W. R. J., Decraemer, W. F., & Khanna, S. M. (1987). On the damped frequency response of a finite-element model of the cat eardrum. The Journal of the Acoustical Society of America, 81(6), 1851–1859.
Funnell, W. R. J., Khanna, S. M., & Decraemer, W. F. (1992). On the degree of rigidity of the manubrium in a finite-element model of the cat eardrum. The Journal of the Acoustical Society of America, 91(4), 2082–2090.
Funnell, W. R. J., Heng Siah, T., McKee, M. D., Daniel, S. J., & Decraemer, W. F. (2005). On the coupling between the incus and the stapes in the cat. Journal of the Association for Research in Otolaryngology, 6(1), 9–18.
Funnell, W. R. J., Daniel, S. J., Alsabah, B., & Liu, H. (2006). On the coupling between the incus and the stapes. In Auditory mechanisms: Processes and models, Proceedings of the Ninth International Symposium (pp. 115–116). Portland, OR, July 23–28, 2005.
Funnell, W. R. J., Maftoon, N., & Decraemer, W. F. (2012). Mechanics and modelling for the middle ear. Retrieved from: http://audilab.bme.mcgill.ca/mammie/. (Accessed November 11, 2012).
Gan, R. Z., & Wang, X. (2007). Multifield coupled finite element analysis for sound transmission in otitis media with effusion. The Journal of the Acoustical Society of America, 122(6), 3527–3538.
Gan, R. Z., Feng, B., & Sun, Q. (2004). Three-dimensional finite element modeling of human ear for sound transmission. Annals of Biomedical Engineering, 32(6), 847–859.
Gan, R. Z., Sun, Q., Feng, B., & Wood, M. W. (2006). Acoustic-structural coupled finite element analysis for sound transmission in human ear—Pressure distributions. Medical Engineering & Physics, 28(5), 395–404.
Gan, R. Z., Reeves, B. P., & Wang, X. (2007). Modeling of sound transmission from ear canal to cochlea. Annals of Biomedical Engineering, 35(12), 2180–2195.
Gan, R. Z., Cheng, T., Dai, C., Yang, F., & Wood, M. W. (2009). Finite element modeling of sound transmission with perforations of tympanic membrane. The Journal of the Acoustical Society of America, 126(1), 243–253.
Gariepy, B. (2011). Finite-element modelling of the newborn ear canal and middle ear. M. Eng. Thesis, McGill University, Montréal.
Gea, S. L. R., Decraemer, W. F., Funnell, W. R. J., Dirckx, J. J. J., & Maier, H. (2009). Tympanic membrane boundary deformations derived from static displacements observed with computerized tomography in human and gerbil. Journal of the Association for Research in Otolaryngology, 11(1), 1–17.
Gehrmann, S., Höhne, K. H., Linhart, W., Pflesser, B., Pommert, A., Riemer, M., Tiede, U., Windolf, J., Schumacher, U., & Rueger, J. M. (2006). A novel interactive anatomic atlas of the hand. Clinical Anatomy, 19(3), 258–266.
Georgiev, T., Lumsdaine, A., & Chunev, G. (2011). Using focused plenoptic cameras for rich image capture. IEEE Computer Graphics and Applications, 31(1), 62–73.
Goll, E., & Dalhoff, E. (2011). Modeling the eardrum as a string with distributed force. The Journal of the Acoustical Society of America, 130(3), 1452–1462.
Gran, S. (1968). Analytische Grundlage der Mittelohrmechanik. Ein Beitrag zur Anwendung der akustischen Impedanz des Ohres. Ph.D. thesis, Universität Oslo.
Guelke, R., & Keen, J. A. (1949). A study of the vibrations of the tympanic membrane under direct vision, with a new explanation of their physical characteristics. The Journal of Physiology, 110, 226–236.
Guinan, J. J., & Peake, W. T. (1967). Middle-ear characteristics of anesthetized cats. The Journal of the Acoustical Society of America, 41(5), 1237–1261.
Hagr, A. A., Funnell, W. R. J., Zeitouni, A. G., & Rappaport, J. M. (2004). High-resolution X-ray computed tomographic scanning of the human stapes footplate. The Journal of Otolaryngology, 33(4), 217–221.
Hart, D. P., Frigerio, F., & Marini, D. M. (2010). Three-dimensional imaging using an inflatable membrane. Retrieved from: http://www.google.ca/patents/US20100042002. (Accessed November 11, 2012).
Hartman, W. F. (1971). An error in Helmholtz’s calculation of the displacement of the tympanic membrane. The Journal of the Acoustical Society of America, 49(4B), 1317.
Helmholtz, H. L. F. (1868). Die Mechanik der Gehörknöchelchen und des Trommelfells. Pflügers Archiv für die gesammte Physiologie (Bonn), 1, 1–60.
Helton, J. C., Johnson, J. D., Sallaberry, C. J., & Storlie, C. B. (2006). Survey of sampling-based methods for uncertainty and sensitivity analysis. Reliability Engineering & System Safety, 91(10–11), 1175–1209.
Henson, M., Madden, V., Raskandersen, H., & Henson, O. W., Jr. (2005). Smooth muscle in the annulus fibrosus of the tympanic membrane in bats, rodents, insectivores, and humans. Hearing Research, 200(1–2), 29–37.
Henson, M. M., Henson, O. W., Jr., Gewalt, S. L., Wilson, J. L., & Johnson, G. A. (1994). Imaging the cochlea by magnetic resonance microscopy. Hearing Research, 75(1–2), 75–80.
Homma, K., Shimizu, Y., Kim, N., Du, Y., & Puria, S. (2010). Effects of ear-canal pressurization on middle-ear bone- and air-conduction responses. Hearing Research, 263(1–2), 204–215.
Huang, G. T., Rosowski, J. J., & Peake, W. T. (2000). Relating middle-ear acoustic performance to body size in the cat family: measurements and models. Journal of Comparative Physiology A: Sensory, Neural, and Behavioral Physiology, 186(5), 447–465.
Hudde, H. (1983). Estimation of the area function of human ear canals by sound pressure measurements. The Journal of the Acoustical Society of America, 73(1), 24–31.
Hudde, H., & Schmidt, S. (2009). Sound fields in generally shaped curved ear canals. The Journal of the Acoustical Society of America, 125(5), 3146–3157.
Hudde, H., & Weistenhöfer, C. (1997). A three-dimensional circuit model of the middle ear. Acta Acustica united with Acustica, 83(3), 535–549.
Jackson, R. P., Chlebicki, C., Krasieva, T. B., & Puria, S. (2008). Multiphoton microscopy imaging of collagen fiber layers and orientation in the tympanic membrane. Photonic Therapeutics and Diagnostics IV, Proceedings of SPIE - Int. Soc. Opt. Eng. (Vol. 6842, p. 68421D). San Jose, CA, January 19.
Jang, H. G., Chung, M. S., Shin, D. S., Park, S. K., Cheon, K. S., Park, H. S., & Park, J. S. (2011). Segmentation and surface reconstruction of the detailed ear structures, identified in sectioned images. The Anatomical Record: Advances in Integrative Anatomy and Evolutionary Biology, 294(4), 559–564.
Johnson, G. A., Thompson, M. B., Gewalt, S. L., & Hayes, C. E. (1986). Nuclear magnetic resonance imaging at microscopic resolution. Journal of Magnetic Resonance, 68(1), 129–137.
Just, T., Lankenau, E., Hüttmann, G., & Pau, H. W. (2009). Optische Kohärenztomographie in der Mittelohrchirurgie. HNO, 57(5), 421–427.
Kanzaki, S., Takada, Y., Niida, S., Takeda, Y., Udagawa, N., Ogawa, K., Nango, N., Momose, A., & Matsuo, K. (2011). Impaired vibration of auditory ossicles in osteopetrotic mice. The American Journal of Pathology, 178(3), 1270–1278.
Khanna, S. M., & Tonndorf, J. (1972). Tympanic membrane vibrations in cats studied by time-averaged holography. The Journal of the Acoustical Society of America, 51(6B), 1904–1920.
Khanna, S. M., & Stinson, M. R. (1985). Specification of the acoustical input to the ear at high frequencies. The Journal of the Acoustical Society of America, 77(2), 577–589.
Kim, N., Homma, K., & Puria, S. (2011). Inertial bone conduction: Symmetric and anti-symmetric components. Journal of the Association for Research in Otolaryngology, 12(3), 261–279.
Kirikae, I. (1960). The structure and function of the middle ear. Tokyo: University Press.
Koester, C. J., Khanna, S. M., Rosskothen, H. D., Tackaberry, R. B., & Ulfendahl, M. (1994). Confocal slit divided-aperture microscope: Applications in ear research. Applied Optics, 33(4), 702–708.
Koike, T., Wada, H., & Kobayashi, T. (2002). Modeling of the human middle ear using the finite-element method. The Journal of the Acoustical Society of America, 111(3), 1306–1317.
Kojo, Y. (1954). [Morphological studies of the human tympanic membrane]. Nippon Jibiinkoka Gakkai Kaiho (The Journal of the Oto-Rhino-Laryngological Society of Japan), 57(2), 115–126.
Koning, R. I., & Koster, A. J. (2009). Cryo-electron tomography in biology and medicine. Annals of Anatomy - Anatomischer Anzeiger, 191(5), 427–445.
Kringlebotn, M. (1988). Network model for the human middle ear. Scandinavian Audiology, 17(2), 75–85.
Kuypers, L. C., Decraemer, W. F., Dirckx, J. J. J., & Timmermans, J.-P. (2005a). Thickness distribution of fresh eardrums of cat obtained with confocal microscopy. Journal of the Association for Research in Otolaryngology, 6(3), 223–233.
Kuypers, L. C., Dirckx, J. J. J., Decraemer, W. F., & Timmermans, J.-P. (2005b). Thickness of the gerbil tympanic membrane measured with confocal microscopy. Hearing Research, 209(1–2), 42–52.
Kuypers, L. C., Decraemer, W. F., & Dirckx, J. J. J. (2006). Thickness distribution of fresh and preserved human eardrums measured with confocal microscopy. Otology & Neurotology, 27(2), 256–264.
Ladak, H. M., Decraemer, W. F., Dirckx, J. J. J., & Funnell, W. R. J. (2004). Response of the cat eardrum to static pressures: Mobile versus immobile malleus. The Journal of the Acoustical Society of America, 116(5), 3008–3021.
Ladak, H. M., Funnell, W. R. J., Decraemer, W. F., & Dirckx, J. J. J. (2006). A geometrically nonlinear finite-element model of the cat eardrum. The Journal of the Acoustical Society of America, 119(5 Pt 1), 2859–2868.
Leach, R. (2010). Fundamental principles of engineering nanometrology. Oxford: Elsevier.
Lee, C.-F., Chen, P.-R., Lee, W.-J., Chen, J.-H., & Liu, T.-C. (2006). Three-dimensional reconstruction and modeling of middle ear biomechanics by high-resolution computed tomography and finite element analysis. The Laryngoscope, 116(5), 711–716.
Lee, W.-J., Lee, C.-F., Chen, S.-Y., Chen, Y.-S., & Sun, C.-K. (2010). Virtual biopsy of rat tympanic membrane using higher harmonic generation microscopy. Journal of Biomedical Optics, 15(4), 046012.
Liang, J., McInerney, T., & Terzopoulos, D. (2006). United snakes. Medical Image Analysis, 10(2), 215–233.
Lim, D. J. (1995). Structure and function of the tympanic membrane: A review. Acta Oto-Rhino-Laryngologica Belgica, 49(2), 101–115.
Lowell, P. (1908). Mars as the abode of life. New York: Macmillan Co.
Luo, H., Dai, C., Gan, R. Z., & Lu, H. (2009). Measurement of Young’s modulus of human tympanic membrane at high strain rates. Journal of Biomechanical Engineering, 131(6), 064501.
Lynch, T. J., III, Nedzelnitsky, V., & Peake, W. T. (1982). Input impedance of the cochlea in cat. The Journal of the Acoustical Society of America, 72(1), 108–130.
Maftoon, N., Nambiar, S., Funnell, W. R. J., Decraemer, W. F., & Daniel, S. J. (2011). Experimental and modelling study of gerbil tympanic-membrane vibrations. In 34th Midwinter Research Meeting, Association for Research in Otolaryngology Baltimore, February 19–23.
Margolis, R. H., Osguthorpe, J. D., & Popelka, G. R. (1978). The effects of experimentally-produced middle ear lesions on tympanometry in cats. Acta Oto-Laryngologica, 86(5–6), 428–436.
Marwala, T. (2010). Finite-element-model updating using computional intelligence techniques. London: Springer.
Mayes, R. L. (2009). Developing adequacy criterion for model validation based on requirements. Proceedings of the IMAC-XXVII. Orlando, FL, February 8–12.
Moens, D., & Vandepitte, D. (2005). A survey of non-probabilistic uncertainty treatment in finite element analysis. Computer Methods in Applied Mechanics and Engineering, 194(12–16), 1527–1555.
Møller, A. R. (1961). Network model of the middle ear. The Journal of the Acoustical Society of America, 33(2), 168–176.
Møller, A. R. (1965). An experimental study of the acoustic impedance of the middle ear and its transmission properties. Acta Oto-Laryngologica, 60(1–6), 129–149.
Neudert, M., Beleites, T., Ney, M., Kluge, A., Lasurashvili, N., Bornitz, M., Scharnweber, D., & Zahnert, T. (2010). Osseointegration of titanium prostheses on the stapes footplate. Journal of the Association for Research in Otolaryngology, 11(2), 161–171.
Novotny, L. (2011). From near-field optics to optical antennas. Physics Today, 64(7), 47–52.
O’Connor, K. N., & Puria, S. (2008). Middle-ear circuit model parameters based on a population of human ears. The Journal of the Acoustical Society of America, 123(1), 197–211.
Odgaard, A., Andersen, K., Ullerup, R., Frich, L. H., & Melsen, F. (1994). Three-dimensional reconstruction of entire vertebral bodies. Bone, 15(3), 335–342.
Olson, E. S. (1998). Observing middle and inner ear mechanics with novel intracochlear pressure sensors. The Journal of the Acoustical Society of America, 103(6), 3445–3463.
Onchi, Y. (1949). A study of the mechanism of the middle ear. The Journal of the Acoustical Society of America, 21(4), 404–410.
Onchi, Y. (1961). Mechanism of the middle ear. The Journal of the Acoustical Society of America, 33(6), 794–805.
Palva, T., Northrop, C., & Ramsay, H. (2001). Aeration and drainage pathways of Prussak’s space. International Journal of Pediatric Otorhinolaryngology, 57(1), 55–65.
Pang, X. D., & Peake, W. T. (1986). How do contractions of the stapedius muscle alter the acoustic properties of the ear? In Peripheral Auditory Mechanisms (pp. 36–43). Berlin: Springer-Verlag.
Parent, P., & Allen, J. B. (2007). Wave model of the cat tympanic membrane. The Journal of the Acoustical Society of America, 122(2), 918–931.
Parent, P., & Allen, J. B. (2010). Time-domain “wave” model of the human tympanic membrane. Hearing Research, 263(1–2), 152–167.
Parker, W. S. (2008). Franklin, Holmes, and the epistemology of computer simulation. International Studies in the Philosophy of Science, 22(2), 165–183.
Pascal, J., Bourgeade, A., Lagier, M., & Legros, C. (1998). Linear and nonlinear model of the human middle ear. The Journal of the Acoustical Society of America, 104(3 Pt 1), 1509–1516.
Peake, W. T., & Guinan, J. J. (1967). Circuit model for the cat’s middle ear. Quarterly Progress Report No. 84 (pp. 320–326). Cambridge, MA: Research Laboratory of Electronics, Massachusetts Institute of Technology.
Polys, N. F., Brutzman, D., Steed, A., & Behr, J. (2008). Future standards for immersive VR. IEEE Computer Graphics and Applications, 28(2), 94–99.
Price, G. R., & Kalb, J. T. (1991). Insights into hazard from intense impulses from a mathematical model of the ear. The Journal of the Acoustical Society of America, 90(1), 219–227.
Puria, S. (1991). A theory of cochlear input impedance and middle ear parameter estimation. Ph.D. thesis, City University New York.
Puria, S., & Allen, J. B. (1998). Measurements and model of the cat middle ear: Evidence of tympanic membrane acoustic delay. The Journal of the Acoustical Society of America, 104(6), 3463–3481.
Puria, S., & Steele, C. (2010). Tympanic-membrane and malleus-incus-complex co-adaptations for high-frequency hearing in mammals. Hearing Research, 263(1–2), 183–190.
Qi, L., Liu, H., Lutfy, J., Funnell, W. R. J., & Daniel, S. J. (2006). A nonlinear finite-element model of the newborn ear canal. The Journal of the Acoustical Society of America, 120(6), 3789–3798.
Rabbitt, R. D., & Holmes, M. H. (1986). A fibrous dynamic continuum model of the tympanic membrane. The Journal of the Acoustical Society of America, 80(6), 1716–1728.
Rabbitt, R. D., & Holmes, M. H. (1988). Three-dimensional acoustic waves in the ear canal and their interaction with the tympanic membrane. The Journal of the Acoustical Society of America, 83(3), 1064–1080.
Reiser, M. F., Semmler, W., & Hricak, H. (Eds.). (2008). Magnetic resonance tomography. Berlin: Springer.
Roache, P. J. (2002). Code verification by the method of manufactured solutions. Journal of Fluids Engineering, Transactions of the ASME, 124(1), 4–10.
Salih, W. H. M., Buytaert, J. A. N., Aerts, J. R. M., Vanderniepen, P., Dierick, M., & Dirckx, J. J. J. (2012). Open access high-resolution 3D morphology models of cat, gerbil, rabbit, rat and human ossicular chains. Hearing Research, 284(1–2), 1–5.
Sasov, A., & Van Dyck, D. (1998). Desktop X-ray microscopy and microtomography. Journal of Microscopy, 191(2), 151–158.
Schmidt, S. H., & Hellström, S. (1991). Tympanic-membrane structure—new views. A comparative study. ORL: Journal for Oto-Rhino-Laryngology and Its Related Specialties, 53(1), 32–36.
Schroeder, W., Martin, K. W., & Lorensen, B. (1996). The Visualization Toolkit: An object-oriented approach to 3-D graphics. Upper Saddle River, NJ: Prentice Hall PTR.
Schwer, L. E. (2007). An overview of the PTC 60/V&V 10: Guide for verification and validation in computational solid mechanics. Engineering with Computers, 23(4), 245–252.
Shaw, E. A. G., & Stinson, M. R. (1983). The human external and middle ear: Models and concepts. Mechanics of Hearing (pp. 3–10). Delft: M. Nijhoff (The Hague) & Delft University Press.
Shaw, E. A. G., & Stinson, M. R. (1986). Eardrum dynamics, middle ear transmission and the human hearing threshold curve. In Proceedings of the 12th International Congress on Acoustics (pp. B6–6), Toronto, July 24–31.
Shera, C. A., & Zweig, G. (1991). Phenomenological characterization of eardrum transduction. The Journal of the Acoustical Society of America, 90(1), 253–262.
Shera, C. A., & Zweig, G. (1992a). Middle-ear phenomenology: The view from the three windows. The Journal of the Acoustical Society of America, 92(3), 1356–1370.
Shera, C. A., & Zweig, G. (1992b). Analyzing reverse middle-ear transmission: Noninvasive Gedankenexperiments. The Journal of the Acoustical Society of America, 92(3), 1371–1381.
Sim, J. H., & Puria, S. (2008). Soft tissue morphometry of the malleus-incus complex from micro-CT imaging. Journal of the Association for Research in Otolaryngology, 9, 5–21.
Snavely, N., Seitz, S. M., & Szeliski, R. (2008). Modeling the world from Internet photo collections. International Journal of Computer Vision, 80(2), 189–210.
Soons, J. A. M., Aernouts, J., & Dirckx, J. J. J. (2010). Elasticity modulus of rabbit middle ear ossicles determined by a novel micro-indentation technique. Hearing Research, 263(1-2), 33–37.
Sørensen, M. S., Dobrzeniecki, A. B., Larsen, P., Frisch, T., Sporring, J., & Darvann, T. A. (2002). The Visible Ear: A digital image library of the temporal bone. ORL: Journal for Oto-Rhino-Laryngology and Its Related Specialties, 64(6), 378–381.
Stepp, C. E., & Voss, S. E. (2005). Acoustics of the human middle-ear air space. The Journal of the Acoustical Society of America, 118(2), 816–871.
Stinson, M. R., & Khanna, S. M. (1989). Sound propagation in the ear canal and coupling to the eardrum, with measurements on model systems. The Journal of the Acoustical Society of America, 85(6), 2481–2491.
Stinson, M. R., & Lawton, B. W. (1989). Specification of the geometry of the human ear canal for the prediction of sound-pressure level distribution. The Journal of the Acoustical Society of America, 85(6), 2492–2503.
Stinson, M. R., & Daigle, G. A. (2005). Comparison of an analytic horn equation approach and a boundary element method for the calculation of sound fields in the human ear canal. The Journal of the Acoustical Society of America, 118(4), 2405–2411.
Stuhmiller, J. H. (1989). Use of modeling in predicting tympanic membrane rupture. The Annals of Otology, Rhinology & Laryngology. Supplement, 140, 53–60.
Subhash, H. M., Nguyen-Huynh, A., Wang, R. K., Jacques, S. L., Choudhury, N., & Nuttall, A. L. (2012). Feasibility of spectral-domain phase-sensitive optical coherence tomography for middle ear vibrometry. Journal of Biomedical Optics, 17(6), 060505.
Sun, C.-K. (2005). Higher harmonic generation microscopy. Advances in Biochemical Engineering/Biotechnology, 95, 17–56.
Sun, Q., Chang, K.-H., Dormer, K. J., Dyer, R. K., Jr., & Gan, R. Z. (2002a). An advanced computer-aided geometric modeling and fabrication method for human middle ear. Medical Engineering & Physics, 24(9), 595–606.
Sun, Q., Gan, R. Z., Chang, K.-H., & Dormer, K. J. (2002b). Computer-integrated finite element modeling of human middle ear. Biomechanics and Modeling in Mechanobiology, 1(2), 109–122.
Teoh, S. W. (1996). The roles of pars flaccida in middle ear acoustic transmission. Ph.D. thesis, Massachusetts Institute of Technology.
Teoh, S. W., Flandermeyer, D. T., & Rosowski, J. J. (1997). Effects of pars flaccida on sound conduction in ears of Mongolian gerbil: Acoustic and anatomical measurements. Hearing Research, 106(1–2), 39–65.
Todd, N. W. (2005). Orientation of the manubrium mallei: inexplicably widely variable. The Laryngoscope, 115(9), 1548–1552.
Tuck-Lee, J. P., Pinsky, P. M., Steele, C. R., & Puria, S. (2008). Finite element modeling of acousto-mechanical coupling in the cat middle ear. The Journal of the Acoustical Society of America, 124(1), 348–362.
Uebo, K., Kodama, A., Oka, Y., & Ishii, T. (1988). [Thickness of normal human tympanic membrane]. Ear Research Japan, 19, 70–73.
Van Wijhe, R., Funnell, W. R. J., Henson, O. W., & Henson, M. M. (2000). Development of a finite-element model of the middle ear of the moustached bat. In Proceedings of the 26th Annual Conference of the Canadian Medical and Biological Engineering Society (pp. 20–21). Halifax, October 26–28.
Vogel, U. (1999). New approach for 3D imaging and geometry modeling of the human inner ear. ORL: Journal for Oto-Rhino-Laryngology and Its Related Specialties, 61(5), 259–267.
Vogel, U., & Schmitt, T. (1998). 3D visualization of middle ear structures. Medical Imaging 1998: Image Display, Proceedings SPIE (Vol. 3335, pp. 141–151). San Diego, February 21.
Voie, A. H., Burns, D. H., & Spelman, F. A. (1993). Orthogonal-plane fluorescence optical sectioning: Three-dimensional imaging of macroscopic biological specimens. Journal of Microscopy, 170, 229–236.
Volandri, G., Di Puccio, F., Forte, P., & Carmignani, C. (2011). Biomechanics of the tympanic membrane. Journal of Biomechanics, 44(7), 1219–1236.
von Ahn, L., Maurer, B., McMillen, C., Abraham, D., & Blum, M. (2008). reCAPTCHA: Human-based character recognition via Web security measures. Science, 321(5895), 1465–1468.
von Békésy, G. (1941). Über die Messung der Schwingungsamplitude der Gehörknöchelchen mittels einer kapazitiven Sonde. Akustische Zeitschrift, 6, 1–16.
von Békésy, G. (1949). The structure of the middle ear and the hearing of one’s own voice by bone conduction. The Journal of the Acoustical Society of America, 21, 217–232.
von Békésy, G. (1960). Experiments in Hearing. New York, NY: McGraw-Hill.
von Unge, M., Bagger-Sjöbäck, D., & Borg, E. (1991). Mechanoacoustic properties of the tympanic membrane: A study on isolated Mongolian gerbil temporal bones. The American Journal of Otology, 12(6), 407–419.
Wada, H., & Kobayashi, T. (1990). Dynamical behavior of middle ear: Theoretical study corresponding to measurement results obtained by a newly developed measuring apparatus. The Journal of the Acoustical Society of America, 87(1), 237–245.
Wada, H., Metoki, T., & Kobayashi, T. (1992). Analysis of dynamic behavior of human middle ear using a finite-element method. The Journal of the Acoustical Society of America, 92(6), 3157–3168.
Wada, H., Onda, N., Date, K., & Kobayashi, T. (1996). Assessment of mechanical properties of tympanic membrane by supersonic wave method. Nippon Kikai Gakkai Ronbunshu, C Hen/Transactions of the Japan Society of Mechanical Engineers, Part C, 62(598), 2289–2292.
Wang, H., Northrop, C., Burgess, B., Liberman, M. C., & Merchant, S. N. (2006). Three-dimensional virtual model of the human temporal bone: A stand-alone, downloadable teaching tool. Otology & Neurotology, 27(4), 452–457.
Wang, X., Cheng, T., & Gan, R. Z. (2007). Finite-element analysis of middle-ear pressure effects on static and dynamic behavior of human ear. The Journal of the Acoustical Society of America, 122(2), 906–917.
Webber, R. L., Webber, S. E., & Moore, J. (2002). Hand-held three-dimensional dental X-ray system: Technical description and preliminary results. Dentomaxillofacial Radiology, 31(4), 240–248.
Weistenhöfer, C., & Hudde, H. (1999). Determination of the shape and inertia properties of the human auditory ossicles. Audiology & Neuro-Otology, 4(3–4), 192–196.
Wever, E. G., & Lawrence, M. (1954). Physiological acoustics. Princeton, NJ: Princeton University Press.
Wiener, F. M., & Ross, D. A. (1946). The pressure distribution in the auditory canal in a progressive sound field. The Journal of the Acoustical Society of America, 18(2), 401–408.
Williams, K. R., & Lesser, T. H. (1990). A finite element analysis of the natural frequencies of vibration of the human tympanic membrane. Part I. British Journal of Audiology, 24(5), 319–327.
Williams, K. R., Blayney, A. W., & Rice, H. J. (1996). Development of a finite element model of the middle ear. Revue De Laryngologie - Otologie - Rhinologie, 117(3), 259–264.
Wilson, J. L., Henson, M. M., Gewalt, S. L., Keating, A. W., & Henson, O. W., Jr. (1996). Reconstructions and cross-sectional area measurements from magnetic resonance microscopic images of the cochlea. American Journal of Otology, 17(2), 347–353.
Winsberg, E. (2010). Science in the age of computer simulation. Chicago: University of Chicago Press.
Wojtkowski, M. (2010). High-speed optical coherence tomography: Basics and applications. Applied Optics, 49(16), D30–61.
Yoo, S. H., Park, K. H., Moon, S. K., Kim, W.-S., & Bae, J. H. (2004). Evaluation of dynamic behavior of the human middle ear with nonhomogeneity by finite element method. Key Engineering Materials, 270–273, 2067–2072.
Young, P. G., Beresford-West, T. B. H., Coward, S. R. L., Notarberardino, B., Walker, B., & Abdul-Aziz, A. (2008). An efficient approach to converting three-dimensional image data into highly accurate computational models. Philosophical Transactions A: Mathematical, Physical, and Engineering Sciences, 366(1878), 3155–3173.
Yuan, Y., & Verma, R. (2006). Measuring microelastic properties of stratum corneum. Colloids and Surfaces B: Biointerfaces, 48(1), 6–12.
Zebian, M., Hensel, J., & Fedtke, T. (2012). How the cross-sectional discontinuity between ear canal and probe affects the ear canal length estimation. The Journal of the Acoustical Society of America, 132(1), EL8–EL14.
Zhang, X., & Gan, R. Z. (2010). Dynamic properties of human tympanic membrane – experimental measurement and modelling analysis. International Journal of Experimental and Computational Biomechanics, 1(3), 252–270.
Zhang, X., & Gan, R. Z. (2011). A comprehensive model of human ear for analysis of implantable hearing devices. IEEE Transactions on Biomedical Engineering, 58(10), 3024–3027.
Zhang, Y.-J. (2006). Advances in image and video segmentation. Hershey, PA: IRM Press.
Zwislocki, J. (1957). Some impedance measurements on normal and pathological ears. The Journal of the Acoustical Society of America, 29(12), 1312–1317.
Zwislocki, J. (1962). Analysis of the middle-ear function. Part I: Input impedance. The Journal of the Acoustical Society of America, 34(9B), 1514–1523.
Zwislocki, J. (1963). Analysis of the middle-ear function. Part II: Guinea-pig ear. The Journal of the Acoustical Society of America, 35(7), 1034–1040.
Acknowledgments
This work has been funded by the Canadian Institutes of Health Research, the Natural Sciences and Engineering Research Council (Canada), and the Research Fund of Flanders (Belgium). We wish to acknowledge the profound contributions of Shyam M. Khanna to middle ear mechanics. W. R. J. Funnell and W. F. Decraemer in particular wish to thank him for his tremendous support as we were beginning our careers and for continuing to be an outstanding role model as a scientist and as a person. We also wish to express our sense of loss at the premature passing of Saumil Merchant. He was an important part of the interface between the clinic and us engineers and physicists.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer Science+Business Media New York
About this chapter
Cite this chapter
Funnell, W.R.J., Maftoon, N., Decraemer, W.F. (2013). Modeling of Middle Ear Mechanics. In: Puria, S., Fay, R., Popper, A. (eds) The Middle Ear. Springer Handbook of Auditory Research. Springer, New York, NY. https://doi.org/10.1007/978-1-4614-6591-1_7
Download citation
DOI: https://doi.org/10.1007/978-1-4614-6591-1_7
Published:
Publisher Name: Springer, New York, NY
Print ISBN: 978-1-4614-6590-4
Online ISBN: 978-1-4614-6591-1
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)