
Abstract
The process of information systems development (ISD) has been studied before to enhance generated information systems. It has been recognised recently that the use of knowledge management (KM) methodologies in ISD, so-called knowledge-based information systems (KIS), supports the acquisition and representation of knowledge, both from application domains and development processes. This is important when huge amounts of data from application domains require processing and massive knowledge is buried in the processes. A particular example of this problem lies in the wind industry, where offshore wind farms collect a massive amount of data, yet there is a lack of knowledge about the processes generating the data, which is overwhelming operators. However, there is a gap between KM and ISD, which still needs to be closed.
This chapter will attempt to bridge this gap in a step-by-step manner to analyse information to create knowledge in the following way.
Firstly, within the framework, we consider an organisation as a complex intelligent agent to handle internal and external information.
Secondly, we consider how the KM methods can be integrated with ISD, through those intelligent agents or multi-agents, to handle the domain and process knowledge.
Finally, we define a conceptual model of a KIS to support the ISD to derive enterprise-wide knowledge, experience and decision-making in a data-intensive and complex wind farm management. We develop a prototype KIS model and implement it on working wind farm data to evaluate and validate the proposed approach.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Information system development (ISD) is used to enhance business processes through information technologies (IT). According to (Xia and Lee 2005), ISD usually involves the analysis, design and implementation of IT systems and applications to support business functions. These steps are all typically knowledge-intensive and require diverse expertise. In addition, knowledge management (KM) becomes a factor for success in today’s economy, where knowledge is fundamental for delivering benefit. Global organisations are developing KM projects to harvest knowledge from their processes to remain innovative and competitive (Abdullah et al. 2006). Usually, there is a great deal of information within organisations but a lack of knowledge (Grundspenkis 2006). Information and knowledge assets are intellectual capital, which can provide commercial potential for organisations if well utilised (Apshvalka and Grundspenkis 2005). Therefore, current research on ISD emphasises the integration of KM, and it can be seen as the intersection between KM and ISD, as shown in Fig. 43.1.

Intersection of KM and ISD
The concept of knowledge integration in ISD was first proposed by Grant (1996). After that, it remained a theoretical development with little attention paid to practice. In 2003 Benko and McFarlan introduced real options theory to represent an instance of successful knowledge integration. A relevant paper in 2005 was (Fichman et al. 2005) based on rich secondary analyses of multi-case data. In 2006, (Tiwana et al. 2006) was one of the earliest management information system studies using conjoint research design and one of the first empirical tests of real options theory.
In addition, the Enterprise Knowledge Development–Change Management Method (EKD–CMM) was introduced in Nurcan and Colette (2003) to provide a multiple and dynamically constructed way of organising and guiding enterprise knowledge modelling and the organisational change processes. The method was built on the notion of labelled graph intentions and strategies called a map and associated guidelines. In 2006, an experimental study was conducted (Meso et al. 2006) to determine whether appropriately matching a methodology to a business application developed more effective knowledge-based processes among team members. The results suggested that ISD should include knowledge or cognitive elements.
The goal of integrating KM into ISD is to provide knowledge creation, storage, use/reuse and transfer to support an organisation’s problem-solving and decision-making. This can also help to change an organisation’s management strategy to be more competitive in a rapidly changing environment. There are technical difficulties involved in the development of KM and ISD integration, for example, data processing, knowledge discovery and knowledge utilisation, but these can be resolved using IT and artificial intelligence (AI) techniques.
This chapter attempts to bridge the gap between KM and ISD by a step-by-step approach to analyse information to create knowledge. This chapter then applies that approach to an industrial case study from wind industry. Firstly, a method of organisation using intelligent agents is proposed. Secondly, this chapter considers how KM can be integrated with the information system using intelligent agents and multi-agents. Finally, this chapter describes a model of a knowledge-based information system (KIS) that could be a structure to support the management of a real wind farm (WF), as well as supporting enterprise-wide knowledge, experience and decision-making.
The goal of this research is to develop a prototype of KIS model and to implement it into a working WF information system to evaluate and validate the proposed framework.
2 Organisation as Intelligent Agent
Agents are a valuable tool in ISD and KM. A widely accepted definition of an agent is defined as follows:
An agent is an entity that can be viewed as perceiving its environment through sensors and acting upon that environment through effectors (Russell and Norvig 2003).
Agents can be natural or artificial. For example, a human agent has eyes and ears for sensors and hands and legs for effectors; a robotic agent could have camera for a sensor and wheels for effectors; a software agent has data as its percept and actions. All agents are knowledge workers, and their decisions respond to their environment. A generic agent is shown in Fig. 43.2.

Agents interact with environment through sensors and effectors (Russell and Norvig 2003)
From the systems theory point of view, any organisation can be considered as a set of objects together with relationships between them (Grundspenkis and Kirikova 2005). Some organisations try to develop information systems to harvest knowledge and remain innovative and competitive. As new situations appear, knowledge is gained, new technologies are introduced and new solutions are developed. There is a trend for ISD to integrate such knowledge with the goal of making rational decisions and taking the best possible action. Thus, the interpretation of an organisation as a whole, using the intelligent agent concept, is obvious.
In computer science, an intelligent agent is an autonomous entity which observes and acts upon an environment and directs its activity towards achieving goals using learning or knowledge (Russell and Norvig 2003). An intelligent organisation can be considered as a combination of intelligent agents perceiving the current state of the environment, using its sensors for knowledge acquisition. Knowledge about the current state of an organisation and its goal state can be used to determine actions, which can be applied, through effectors, to the organisation’s environment. This output is determined on the basis of percept and knowledge captured into the intelligent agents’ knowledge base. An example of the interpretation of an organisation in terms of intelligent agents is shown in Fig. 43.3.

An organisation as an intelligent agent
From an intelligent agent’s point of view, the KIS means knowledge acquisition, processing and use for rational decision-making, choosing the best action and generating new knowledge. The main functions of a KIS can be characterised as follows:
-
Detection of information and knowledge (sensors)
-
Storage of detected information and knowledge (knowledge base)
-
Decision-making (inference engine)
-
Retrieval, visualisation of knowledge and actions (effectors)
An organisation’s business processes are supported by intelligent agent activities, such as decision-making and action. Intelligent agents should provide possible solutions and alternatives, theoretically satisfactory to support the organisation’s business processes.
3 Proposed Model Using Multi-agents
More detailed examination of the business processes inside an organisation reveals that there will be many different people and subsystems doing diverse tasks required by the organisation. Therefore, a multi-agent system (MAS), which consists of multiple interacting intelligent agents, will be needed to solve problems that are too difficult or impossible for an individual agent. A proposed KIS model which combines KM and MAS is shown in Fig. 43.4.

KIS framework
As shown in Fig. 43.4, the conceptual framework of a KIS consists of two main parts: a KM and a MAS for business process support. The KMS is an integrated set of technologies, hardware and software, to provide knowledge acquisition, storage, processing, retrieval and representation. The KM is usually supported by AI techniques. The purpose of adding KM into the KIS is to identify intellectual capital of the organisation and organise that knowledge to make it easily accessible and applicable. The MAS is a physical or virtual environment where intelligent agents of the organisation may communicate with each other for effective knowledge sharing and distribution to achieve the business process goals.
4 Case Study
In order to study these KM–ISD integration issues, it would be desirable to apply the proposed approach to a real-world scenario. The following section applies the approach to a large wind farm (WF) to demonstrate the concept of the proposed KIS.
4.1 Large Wind Farms
The wind industry is currently the fastest growing renewable electrical energy source around the world (The Economics of Wind Energy 2009; Tavner 2008). A large WF will contain 100–500 wind turbines (WTs). Each of them is an autonomous, robotic electric generator of 2–5 MW output connected to an electrical power system. Revenue is earned from the WF for the MWh of electrical energy generated, and current revenue for large WFs is about £60/MWh generated. The WF will have a complex signal conditioning and data acquisition (SCADA) system to control this renewable power station which could generate 1.4–35 GWh per day equivalent to £84k–2.16M revenue per day (Feng et al. 2010).
Each WT has 100–400 input/output (I/O) signals and alarms, which are monitored every 10 min providing the necessary monitoring and control environment to manage the power station. Therefore, a WF of 100–500 such WTs could produce 10,000–200,000 items of signal and alarm data every 10 min.
With the increase of wind energy development, especially the increase in the number of offshore WFs, where maintenance access is difficult, the operation and maintenance (O&M) of these huge autonomous, robotic structures is gaining financial importance, as any downtime due to faults will lead to a loss of revenue. This heightens the need for a comprehensive KIS that can use existing WT monitoring systems to provide advanced O&M management services.
4.2 Basic Concepts
This section provides a formal description of the WF.
Definition 1 (WF):
A WF is defined as follows:
where F is a WF containing a collection of WT T with n different attributes \( {f_1},1 \leqslant i \leqslant n \), for example, location, number of WTs and maximum power output.
Definition 2 (WT):
A WF can have many WTs; thus, T is defined as follows:
where \( {t_i},1 \leqslant i \leqslant n \) denotes the characteristics of individual WTs; see below.
Definition 3 (Subsystem):
Each WT has one or more subsystems:
where \( {s_i},1 \leqslant i \leqslant n \) denotes individual WT subsystem, for example, a pitch system, gearbox or generator.
Definition 4 (Component):
Each subsystem contains one or more components:
where \( {c_i},1 \leqslant i \leqslant n \) denotes individual components of a subsystem, for example, for the pitch system, an encoder, a blade or the rotor hub.
Definition 5 (Component attributes):
Each component has some attributes:
where \( c{a_i},1 \leqslant i \leqslant n \) denotes the component attributes, for example, the value of the blade angle.
The key objective for developing a KIS for a WF is to offer a comprehensive solution that exceeds the operational and management potential of existing conventional monitoring systems, such as SCADA or condition monitoring systems (CMS), with the aim of reducing O&M costs and raising WF generation revenue by reducing downtime. The main functions of a KIS for a WF would include:
-
Monitoring: Use existing WT monitoring systems, SCADA and CMS, to display current WT and WF performance.
-
Problem-solving: Assist experts to diagnose WT or WF failures.
-
Decision-making: Using advanced AI to detect incipient WT or WF faults early.
-
Planning and prediction: Maintenance to be scheduled based on the early detection of incipient WT or WF faults.
4.3 Exploring the WF Case Study
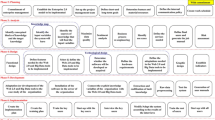
To achieve the “knowledge-based” KIS and meet these objectives, a collaborative structure is proposed that connects to the WF database. A prototype model of the WF KIS system architecture is show in Fig. 43.5.

Model for the WF KIS system architecture
The system architecture includes four main components, from the left to right of Fig. 43.5: resources, KM, agents and a user interface. Each of these components corresponds to a logical step in KIS implementation.
-
Resources consist of a primary database and knowledge libraries. In this component, all data are transformed and saved in the same format to make the data easily accessible and improve efficiency.
-
KM consists of algorithm, information discovery, exploration, representation, sharing and utilisation functions adapted to extract knowledge and solve problems. These will be supported by AI techniques, such as artificial neural networks (ANN), pattern recognition and generic algorithms.
-
Agents will provide activities such as learning, questions and answers, explanations, information retrieval, resource management and documentation.
-
Finally, the user interface is an agent consisting of tools for WF operators and maintainers for visualising the data structure and displaying results. The use of data visualisation techniques will be emphasised because it will bring additional exploratory data analysis techniques appropriate to complex WF data. The data visualisation tools will provide for the large dimensional datasets the following: data clustering and projection for feature extraction, visualisation and interpretation.
For the WF operator and maintainer, the main goal of the KIS will be the acquisition of knowledge, for monitoring, decision-making, problem-solving, planning and prediction, with the aim of reducing O&M costs and raising WF generation revenue by reducing downtime.
5 Implementation
The research is a part of a larger activity to improve offshore WF availability and involves accessing 2 terabytes of real WT data. In order to process such large amounts of data, a dedicated server consisting of 2 processors, 48 gigabytes of memory and 8-terabyte hard drives, was constructed in School of Engineering and Computing Sciences, Durham University. The initial research has developed a client/server-based prototype application in which the server-side is used to handle data and process client requests, while the client-side is on a user’s PC, allowing users to request server content or services. The initial objectives of this research focus on the following two problems:
-
Massive data processing: To handle 2 TB real WT data and also feature with information extraction to resolve data noise and randomness.
-
Knowledge representation and support decision-making: Use the human expertise knowledge base for problem-solving and decision-making.
5.1 Results
At the current stage of the implementation, the prototype KIS can handle large data size with fast visualisation and interaction. For a typical WF binary data set, it can display up to 300 MB of data at a time without significant performance problem. An example of it in operation is shown in Fig. 43.6a. The prototype KIS also includes “buffering”, “dynamic display” and “data aggregation”.
-
Buffering: Apart from loading the data into the viewport, the client-side temporarily holds adjacent viewport data to reduce data loading time and enhance user interactions, for example, for zooming in/out or for scrolling through moving data. This is shown in Fig. 43.6b.
-
Dynamic display: If the user viewport resolution is less than the requested data size, it is not necessary to display all data. Requested data can be down-sampled, using, for example, an average calculation, on server-side before being transferred to client-side.
-
Data aggregation: The KIS provides statistical data aggregation techniques, such as average, ignore betweens, first or last of data, for the user to down-sample and enhance data visualisation.

(a) Screenshot of the system implementation work on WF SCADA data; (b) Buffering technique
The initial research investigated the following techniques:
-
Regression analysis for data processing
-
Artificial neural network (ANN) solutions for decision-making
-
Self-organising feature mapping (SOM) for data clustering
Figure 43.7 shows regression analysis being applied for WT power curve fitting, which is proving useful for processing and detecting WT failures (Harman and Raftery 2003; Feng et al. 2011). Note that in Fig. 43.6a, polynomial curve fitting was used over a limited range to obtain a good WT power curve. Figure 43.8 shows an ANN being used to analyse SCADA alarms. This analysis is done on a WT with known pitch failure to prove the benefit and the challenges of such an approach. Figure 43.9 shows a self-organising map (SOM) being used to cluster SCADA data from the pitch mechanism of a WT in order to detect pitch faults without expert supervision.

Regression analysis for WT power curve fitting from SCADA data

ANN for SCADA alarm analysis for WT pitch mechanism fault detection

SOM SCADA data clustering for WT pitch mechanism fault detection
6 Conclusion
This chapter has identified a role for KM and MAS for the implementation of a large WF knowledge-based ISD. Several conceptual models for the configuration of the proposed KIS are discussed. Firstly, the organisation as a whole is interpreted as an intelligent agent, using its own knowledge base for knowledge capture. Secondly, how MASs may support an organisation’s KM is discussed. Finally, a case study for the proposed KIS system architecture for a large WF is presented.
Considerable future works are needed to achieve results in implementing the proposed KIS for large WFs; the potential for using intelligent agents, MAS and KM to develop a more intelligent information system has been demonstrated in a number of real WT downtime scenarios. These will be presented in the full paper. We intend that the proposed KIS with MAS will serve as a platform to investigate the development of more intelligent information systems.
References
Abdullah MS, Kimble C, Benest I, Paige R (2006) Knowledge-based systems: a re-evaluation. J Knowl Manage 10(3):127
Apshvalka D, Grundspenkis J (2005) Personal knowledge management and intelligent agent perspective. In: Proceedings of the 14th international conference on information systems development pre-conference-ISD, Karlstad, Sweden, 14–17 August 2005
Benko C, McFarlan W (2003) Connecting the dots: aligning projects with objectives in unpredictable times. Harvard Business School Press, Boston
Feng Y, Tavner PJ, Long H (2010) Early experiences with UK round 1 offshore wind farms. Proc Inst Civil Eng Energy 163(4):167–181
Feng Y, Qiu Y, Crabtree C, Long H, Tavner PJ (2011) Use Of SCADA and CMS Signals for failure detection & Diagnosis of a wind turbine gearbox. In: EWEA, 2011, Brussels, Belgium
Fichman R, Keil M, Tiwana A (2005) Beyond valuation: real options thinking in IT project management. Calif Manage Rev 47(2):74–100
Grant R (1996) Prospering in dynamically-competitive environments: organizational capability as knowledge integration. Org Sci 7(4):375–387
Grundspenkis J (2006) Agent-based framework for modelling of organization and personal knowledge from knowledge management perspective. In: Knowledge enterprise: intelligent strategies in product design, manufacturing, and management, proceedings of PROLAMAT. Springer, Boston, pp 62–70
Grundspenkis J, Kirikova M (2005) Impact of the intelligent agent paradigm on knowledge management. In: Leondes CT (ed) Intelligent knowledge-based systems, vol 1, Knowledge-based systems. Kluwer, Boston
Harman KD, Raftery PG (2003) Analytical techniques for understanding the performance of operational wind farms. In: EWEC, 2003, Madrid, Spain
Meso P, Madey G, Troutt MD, Liegle J (2006) The knowledge management efficacy of matching information systems development methodologies with application characteristics—an experimental study. J Syst Softw 79(1):15–28
Nurcan S, Colette R (2003) A multi-method for defining the organizational change. Inf Softw Technol 45(2):61
Russell SJ, Norvig P (2003) Artificial intelligence: a modern approach, 2nd edn. Prentice Hall, Upper Saddle River, Chapter 2. ISBN 0-13-790395-2
Tavner PJ (2008) Wind power as a clean-energy contributor. Energy Policy 36(12):4397–4400
The Economics of Wind Energy (2009) A report by the European Wind Energy Association. Krohn S (ed). Poul-Erik Morthorst. Shimon Awerbuch
Tiwana A, Keil M, Fichman R (2006) IS project continuation in escalation situations: a real options model. Decis Sci J 37(3):357–391
Xia W, Lee G (2005) Complexity of information systems development projects: conceptualization and measurement development. J Manage Inf Syst 22(1):45–83
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer Science+Business Media New York
About this paper
Cite this paper
Chen, B., Song, W.W., Feng, Y., Qiu, Y., Tavner, P. (2013). Knowledge-Based Information Systems: A Wind Farm Case Study. In: Pooley, R., Coady, J., Schneider, C., Linger, H., Barry, C., Lang, M. (eds) Information Systems Development. Springer, New York, NY. https://doi.org/10.1007/978-1-4614-4951-5_43
Download citation
DOI: https://doi.org/10.1007/978-1-4614-4951-5_43
Published:
Publisher Name: Springer, New York, NY
Print ISBN: 978-1-4614-4950-8
Online ISBN: 978-1-4614-4951-5
eBook Packages: Computer ScienceComputer Science (R0)